1. Input-Output section
Input-Output section의 정확한 내용은 File organization과 Access method에 따라 다르다. 자세한 내용은 ORGANIZATION clause와 ACCESS MODE clause의 설명을 참고한다.
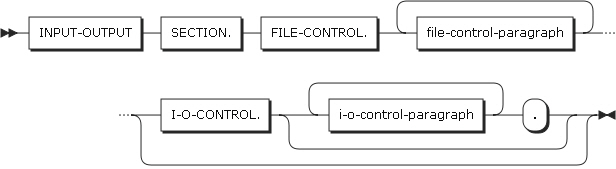
Input-Output section은 반드시 Environment division에 기술되어야 하며 2개의 paragraph을 포함한다.
-
FILE-CONTROL
-
FILE-CONTROL 키워드는 FILE-CONTROL paragraph를 지정한다. 이 키워드는 FILE-CONTROL paragraph 의 처음에 한 번만 나타난다.
-
FILE-CONTROL paragraph은 FILE-CONTROL 키워드가 기술되더라도 프로그램 내에 정의된 파일이 없으면 생략할 수 있다.
-
FILE-CONTROL paragraph는 물리적인 파일을 지정한다.
-
-
I-O-CONTROL
-
I-O-CONTROL 키워드는 I-O-CONTROL paragraph를 지정한다.
-
I-O-CONTROL paragraph는 COBOL 프로그램과 외부의 데이터 셋의 효율적인 데이터 전송에 필요한 정보를 기술한다.
-
1.1. FILE-CONTROL paragraph
FILE-CONTROL paragraph는 COBOL 프로그램에서 각각의 파일을 외부 데이터 셋과 연결시키고, File organization, Access method 및 다른 정보들을 기술한다.
다음은 가능한 file organization과 access method에 대한 설명이다.
| File organization | Access method |
|---|---|
Sequential |
Non-VSAM, VSAM |
Relative |
VSAM |
Indexed |
VSAM |
Line sequential |
Text stream I-O |
FILE-CONTROL paragraph는 점(.)을 가진 FILE CONTROL 키워드로 시작한다.
Paragraph는 Data division 내의 FD와 SD로 기술된 개개의 파일에 대해서 하나씩의 entry를 포함해야 한다. 각 entry 안에서 SELECT clause는 반드시 처음에 나타나야 한다. 다른 clauses들은 어떤 순서로 나타나도 상관없다.
다음은 FILE-CONTROL paragraph에 대한 포맷이다.
-
Sequential file entries
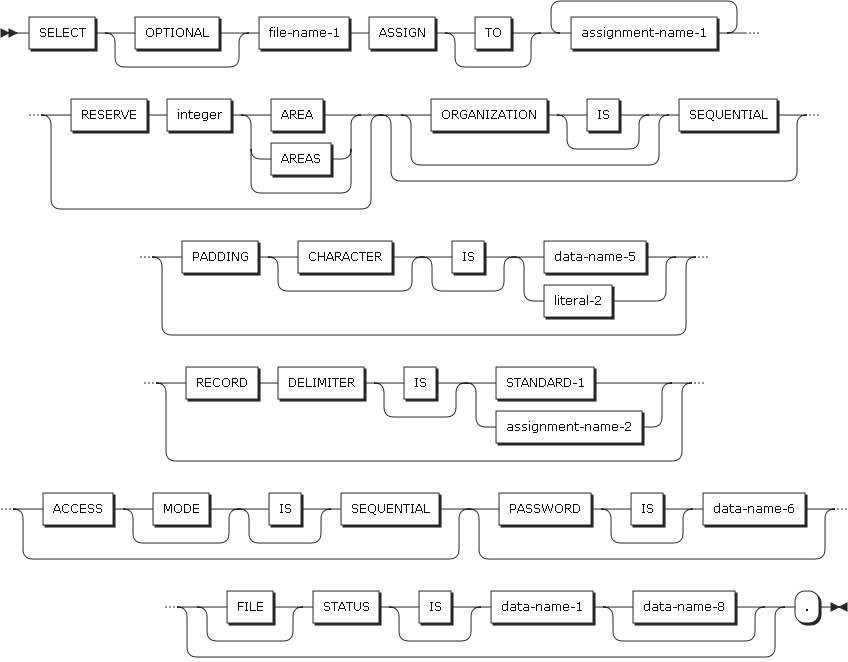 FILE-CONTROL Format 1
FILE-CONTROL Format 1 -
Indexed file entries
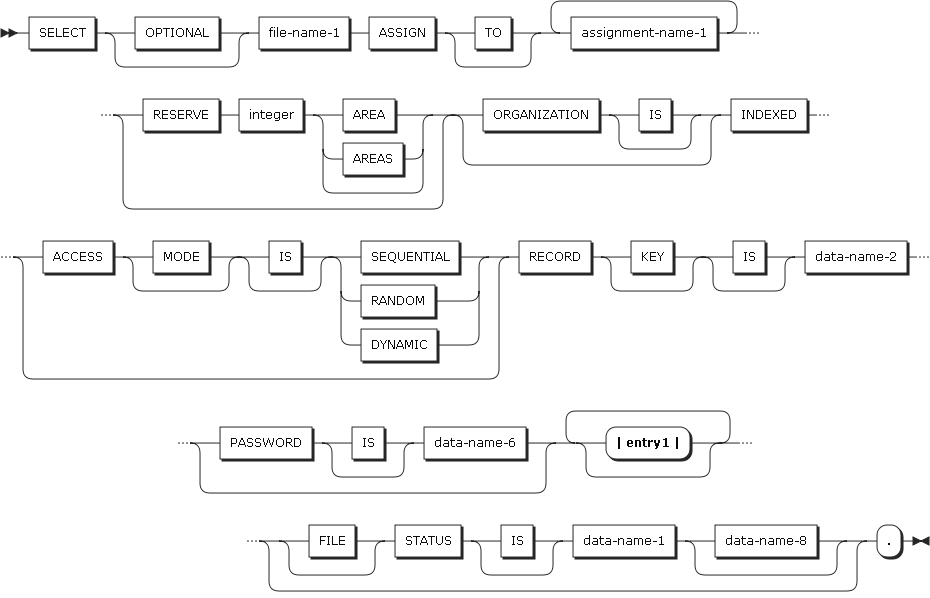 FILE-CONTROL Format 2
FILE-CONTROL Format 2 FILE-CONTROL Format 2 : entry
FILE-CONTROL Format 2 : entry -
Relative file entries
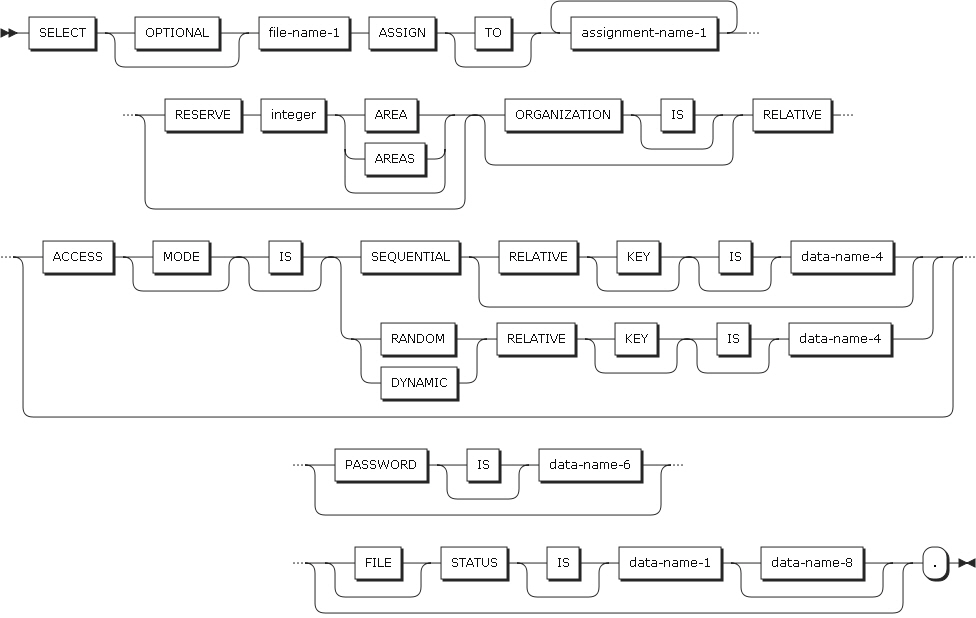 FILE-CONTROL Format 3
FILE-CONTROL Format 3 -
Line-sequential file entries
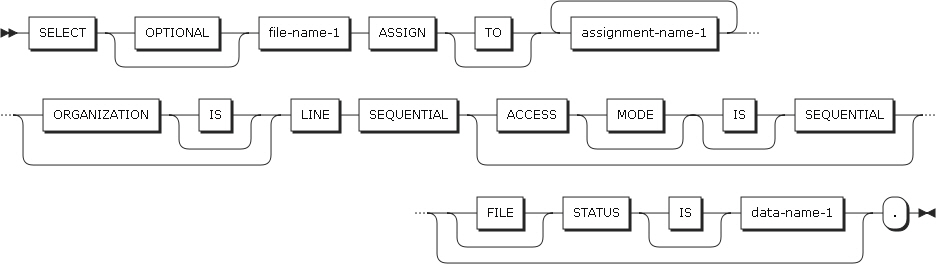 FILE-CONTROL Format 4
FILE-CONTROL Format 4
1.1.1. SELECT clause
SELECT clause은 COBOL 프로그램의 파일 identifier를 정의한다.
| 항목 | 설명 |
|---|---|
SELECT OPTIONAL |
문법만 검사한다. SELECT만 설정한 것과 동일하게 수행한다. |
file-name-1 |
Data division의 FD 또는 SD entry로 식별 가능해야 한다. COBOL의 사용자 정의명 규칙에 부합되어야 한다. 적어도 1개의 알파벳 문자를 포함해야 하고, 현재 프로그램 내에서 중복된 이름을 사용할 수 없다. |
1.1.2. ASSIGN clause
ASSIGN clause은 프로그램 내의 파일 이름을 실제의 외부 데이터 셋과 연결한다.
| 항목 | 설명 |
|---|---|
assignment-name-1 |
외부 데이터 셋 이름을 지정한다. JCL DD 문에 기술된 이름이나 파일 경로를 지정한다. sort/merge 파일이면 주석으로 처리된다. |
1.1.3. ORGANIZATION clause
ORGANIZATION clause은 파일의 논리적인 구조를 지정한다. 논리적인 구조는 파일이 생성되는 시점에서 구성되며 이후에는 변할 수 없다.
-
ORGANIZATION IS SEQUENTIAL (format 1)
-
ORGANIZATION IS INDEXED (format 2)
-
ORGANIZATION IS RELATIVE (format 3)
-
ORGANIZATION IS LINE SEQUENTIAL (format 4)
|
ORGANIZATION clause을 생략하면 컴파일러는 ORGANIZATION IS SEQUENTIAL으로 설정한다. |
파일이 생성될 때 organization이 구성되어야 한다. 파일이 한 번 생성되면, 확장은 될 수 있지만 organization은 변경될 수 없다.
-
Sequential organization
-
레코드의 물리적인 순서가 레코드의 순서를 결정한다. 파일이 확장되더라도 레코드 간의 선후관계는 변경되지 않는다.
-
레코드는 고정길이 또는 가변길이가 될 수 있다.
-
키는 존재하지 않는다.
-
-
Indexed organization
-
파일의 각 레코드는 한 개 이상의 내부 키(key 데이터 항목)를 가진다. 각 키는 인덱스를 가지고 인덱스는 내부의 key 데이터 항목의 내용에 따라서 레코드를 찾을 수 있는 방법을 제공한다.
-
레코드는 고정길이 또는 가변길이가 될 수 있다.
-
각 레코드는 반드시 prime key 데이터 항목을 포함해야 한다.
레코드가 삽입, 갱신, 삭제될 때 해당 레코드는 prime key의 값으로 찾을 수 있다. 따라서, prime key 데이터 항목의 값은 유일해야 하며, 레코드가 갱신될 때 변경되지 않아야 한다. File-control paragraph의 RECORD KEY clause에 prime key 데이터 항목을 기술함으로써 프로그램에서 사용할 수 있도록 한다.
-
각 레코드는 하나 이상의 alternate key 데이터 항목을 가질 수도 있다.
각 alternate key는 읽어올 레코드를 식별하는 또 다른 방법을 제공한다. FILE-CONTROL paragraph의 ALTERNATE RECORD KEY clause에 alternate key 데이터 항목을 기술함으로써 프로그램에서 사용할 수 있도록 한다.
-
-
Relative organization
-
각각의 레코드는 relative record number에 의해 구분된다. relative record number는 레코드에 포함되어 있지는 않다.
-
Access method는 relative record number를 기반으로 레코드를 저장하고 가져온다.
-
파일에 위치한 레코드의 물리적인 순서는 각 레코드의 relative record number와는 상관이 없다.
-
레코드는 고정길이 또는 가변길이가 될 수 있다.
-
-
Line-sequential organization
-
각 레코드는 레코드의 마지막에 레코드 구분자를 가진다. 이 구분자는 레코드 길이에 계산되지 않는다.
-
레코드가 파일에 기록될 때 뒷 부분의 공백문자는 삭제되고 레코드 구분자가 추가된다.
-
레코드를 읽을 때 레코드 구분자는 삭제되고 레코드의 나머지 부분은 공백문자로 된다. EOF를 만나면 레코드의 나머지는 공백으로 채워진다.
-
New line 문자가 레코드 구분자가 된다.
-
|
컴파일러는 indexed organization이나 relative organization을 직접 제공하지 않는다. 만약, OpenFrame 파일 시스템과 연동하여 사용되는 경우에는 지원될 수 있다. |
1.1.4. ACCESS MODE clause
ACCESS MODE clause는 파일의 어느 레코드가 접근 가능한지를 정의한다. 생략되면 sequential access로 설정된다.
-
ACCESS MODE IS SEQUENTIAL
모든 포맷에 기술할 수 있다.
포맷 설명 Format 1: sequential
파일의 레코드는 파일이 생성되거나 확장될 때 만들어진 sequence에 의해 접근 가능하다.
Format 1은 오직 sequential access만 지원한다.
Format 2: indexed
파일의 레코드는 ascending record key의 순서에 따라 순차적으로 접근 가능하다.
Format 3: relative
파일의 레코드는 relative record number의 순서에 따라 순차적으로 접근 가능하다.
Format 4: line-sequential
파일의 레코드는 파일이 생성되거나 확장될때 만들어진 sequence에 의해 접근 가능하다.
Format 4는 오직 sequential access만 지원한다.
-
ACCESS MODE IS RANDOM
Format 2, Format 3에 대해 기술할 수 있다.
포맷 설명 Format 2: indexed
RECORD KEY 데이터 항목의 값에 따라 레코드에 접근 가능하다.
Format 3: relative
RELATIVE KEY 데이터 항목의 값에 따라 레코드에 접근 가능하다.
-
ACCESS MODE IS DYNAMIC
Format 2, Format 3에 대해 기술할 수 있다.
포맷 설명 Format 2: indexed
파일의 레코드는 input-output statement의 사용 방법에 따라 sequentially 또는 randomly 접근될 수 있다.
Format 3: relative
파일의 레코드는 input-output statement의 사용 방법에 따라 sequentially 또는 randomly 접근될 수 있다.
1.1.5. RECORD KEY clause
RECORD KEY clause (Format 2)는 indexed file의 prime RECORD KEY를 정의하는 데이터 항목을 기술한다. Prime RECORD KEY 데이터 항목의 값은 유일해야 한다.
-
data-name-2
-
Prime RECORD KEY 데이터 항목이다 .
-
파일의 record description entry에 기술되어 있어야 한다.
다음의 데이터 범주를 가질 수 있다.
-
Alphanumeric
-
Numeric
-
Numeric-edited
-
Alphanumeric-edited
-
Alphabetic
-
External floating-point
-
Internal floating-point
-
DBCS
-
-
data-name-2는 variable-occurrence 데이터 항목을 포함한 그룹 항목을 참조해서는 안된다. data-name-2는 qualified될 수 있다.
-
data-name-2의 data description과 레코드 내에서의 상대적인 위치는 파일이 정의될 때의 키의 위치와 같아야 한다.
-
1.1.6. ALTERNATE RECORD KEY clause
ALTERNATE RECORD KEY clause(Format 2)는 indexed file의 alternative RECORD KEY를 정의하는 데이터 항목을 기술한다.
-
data-name-3
-
ALTERNATE RECORD KEY 데이터 항목이다 .
-
파일의 record description entry에 기술되어 있어야 한다.
다음의 데이터 범주를 가질 수 있다.
-
Alphanumeric
-
Numeric
-
Numeric-edited
-
Alphanumeric-edited
-
Alphabetic
-
External floating-point
-
Internal floating-point
-
DBCS
-
-
data-name-3는 variable-occurrence 데이터 항목을 포함한 그룹 항목을 참조해서는 안된다. data-name-3는 qualified될 수 있다.
-
data-name-3의 data description과 레코드 내에서의 상대적인 위치는 파일이 정의될 때의 키의 위치와 같아야 한다.
-
|
DUPLICATES phrase가 기술되지 않으면, ALTERNATE RECORD KEY 데이터 항목이 참조하는 내용은 파일 내에서 유일해야 한다. |
1.1.7. RELATIVE KEY clause
RELATIVE KEY clause (Format 3)는 relative file의 relative record number를 지정하는 데이터 항목을 기술한다.
| 항목 | 설명 |
|---|---|
data-name-4 |
Unsigned integer 데이터 항목이어야 하고, PICTURE phrase에 기호 P를 포함해서는 안된다. data-name-4는 파일의 record description entry에 기술되어서는 안된다. 즉, RELATIVE KEY는 레코드의 일부분이 아니다. data-name-4는 qualified될 수 있다. ACCESS IS SEQUENTIAL일 때 START statement를 사용한다면 data-name-4가 필요하다. ACCESS IS RANDOM과 ACCESS IS DYNAMIC인 경우 항상 필요하다. |
1.1.8. FILE STATUS clause
FILE STATUS clause은 입출력 statement의 수행에 대한 결과를 알려준다. FILE STATUS clause가 기술되면 해당 파일에 대한 입출력 동작이 수행된 후 결과 값을 file status key 데이터 항목에 저장한다.
| 항목 | 설명 |
|---|---|
data-name-1 |
File status key 데이터 항목은 working-storage, local-storage 또는 linkage section에 다음 중 하나로 정의될 수 있다.
data-name-1은 PICTURE 기호 'P’를 호함해서는 안된다. data-name-1은 qualified 될 수 있다. data-name-1은 가변적인 위치에 놓여져서는 안된다. 즉, OCCURS DEPENDING ON clause를 포함한 데이터 항목 다음에 와서는 안된다. |
data-name-8 |
문법 검사만 이루어지고 사용되지 않는다. |
