VSAM 데이터셋
본 장에서는 VSAM 데이터 포맷, VSAM 데이터셋 유형, 보조 인덱스와 스피어 그리고 VSAM 데이터셋을 관리하는 방법에 대해서 설명한다.
1. 개요
1970년대 IBM은 3가지 데이터셋 구조(Sequential, Indexed, Direct-Access)를 통합한 새로운 액세스 메소드와 관련 유틸리티 프로그램을 개발한다. 이 새로운 액세스 메소드는 그 당시 가상 스토리지 운영체제(Virtual Storage Operating System)인 OS/VS1 그리고 OS/VS2와 연관되어 VSAM(Virtual Storage Access Method)이라고 불린다.
VSAM은 데이터가 저장되고 검색되는데 사용되는 기술인 액세스 메소드 중의 하나이다. VSAM은 GET/PUT 인터페이스를 사용해서 디스크 디바이스와 애플리케이션 사이에 데이터를 전송해 준다. 모든 VSAM 데이터셋은 카탈로그에 등록되어야 하며, 테이프 디바이스 볼륨에는 저장될 수 없다.
OpenFrame에서는 VSAM에 대응되는 제품으로 TSAM을 지원한다. TSAM은 하부 스토리지 기술로 데이터베이스를 사용한다. TSAM 클라이언트와 서버 사이에는 별도의 TSAM 프로토콜을 사용하기 때문에 SQL 오버헤드가 없다. 또한 대량 Batch 작업의 경우에 적합한 통신 프로토콜을 구현하는 등 성능에 대한 고려를 하고 있다.
2. VSAM 데이터 포맷
모든 VSAM 데이터셋에 저장되는 데이터 구조는 논리 레코드라는 단위로 정렬된다. 논리 레코드는 VSAM 인터페이스를 통해 사용자에게 전달되는 사용자 레코드이다.
VSAM 데이터셋에서 논리 레코드가 저장되는 방식은 Non-VSAM 데이터셋과 다르다. VSAM은 레코드를 Control Interval에 저장한다. Control Interval은 VSAM이 데이터 레코드와 레코드 제어 정보를 저장하는 디스크 디바이스의 연속적인 영역이다. VSAM 레코드를 읽을 때에는 해당 레코드가 포함되어 있는 전체 Control Interval을 메모리에 있는 VSAM I/O 버퍼에 읽어 들인다.
Control Interval
각각의 VSAM 데이터셋의 Control Interval 크기는 서로 다르지만 한 데이터셋에 있는 모든 Control Interval의 크기는 같다. 액세스 메소드 서비스의 DEFINE 명령어를 사용해서 VSAM 데이터셋의 Control Interval의 크기를 지정할 수 있다.
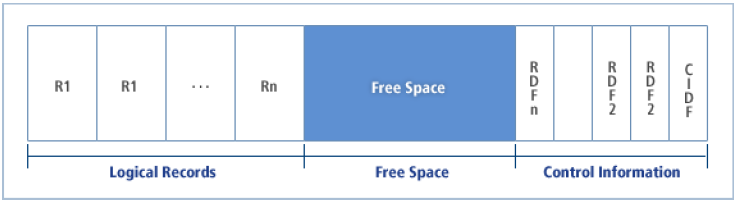
Control Interval은 다음과 같이 구성되어 있다.
-
논리 레코드(Logical Records)
-
여유 공간(Free Space)
-
제어 정보(Control Information)
제어 정보는 하나의 CIDF(Control Interval Definition Field)와 하나 또는 그 이상의 RDFs(Record Definition Fields)로 구성된다. CIDF는 4Bytes로 여유 공간의 크기와 위치가 기록된다. RDFs는 3Bytes로 각 레코드의 크기 정보가 저장된다.
다음은 Control Interval에서 사용하는 주요 용어에 대한 설명이다.
| 용어 | 설명 |
|---|---|
Control Area |
VSAM 데이터셋의 연속적인 Control Interval을 여러 개 묶어서 Control Area라고 부른다. 실제 VSAM 데이터셋은 하나 또는 그 이상의 Control Area로 구성된다. 한 Control Area 안에 있는 Control Interval의 개수는 VSAM에 의해 결정된다. |
Splits |
여유공간이 없는 Control Interval에 레코드를 추가해야 하는 경우 해당 Control Interval에는 split이 일어난다. 해당 CI에 저장되어 있던 레코드의 절반 정도가 다른 CI로 옮겨지고 새로운 레코드는 원래 CI에 추가된다. |
Spanned Records |
Control Interval의 크기보다 큰 레코드를 Spanned 레코드라 일컬으며, 이러한 Spanned 레코드는 VSAM 데이터셋을 정의할 때 SPANNED라는 파라미터를 사용하여 한 레코드가 여러 Control Interval에 걸쳐서 저장되도록 한다. 데이터 레코드의 크기가 빈번하게 변동되는 데이터셋이나 평균 레코드의 크기가 Control Interval 크기에 비해 큰 데이터셋에서 Spanned 레코드를 사용하면 디스크 스페이스의 낭비를 줄일 수 있다. |
Component |
VSAM 데이터셋을 구성하는 개별 파트를 컴포넌트라고 한다. 컴포넌트에는 데이터 컴포넌트와 인덱스 컴포넌트가 있다. KSDS와 VRDS는 데이터 컴포넌트와 인덱스 컴포넌트를 가지고 있고, ESDS와 RRDS는 데이터 컴포넌트만을 가지고 있다. |
Cluster |
모든 VSAM 데이터셋은 클러스터로 정의된다. 클러스터는 최대 2개로 이루어진 관련된 컴포넌트의 집합이다. KSDS의 경우에 하나의 클러스터는 하나의 데이터 컴포넌트와 하나의 인덱스 컴포넌트로 이루어진다. RRDS와 ESDS 데이터셋은 인덱스 컴포넌트가 없는 클러스터로 간주되고, 일관성을 유지하기 위해서 데이터셋을 처리하는 데에 클러스터 이름이 사용된다. |
OpenFrame에서는 TSAM의 하부 스토리지 기술로 관계 데이터베이스를 사용하기 때문에 앞에서와 같은 Control Interval이나 Control Area 등의 기술이 사용되지는 않는다.
다음은 OpenFrame TSAM에서 VSAM 데이터셋을 지원하기 위해 사용되는 데이터베이스 요소에 대한 설명이다.
| Mainframe VSAM | OpenFrame TSAM | 설명 |
|---|---|---|
스토리지 볼륨 |
테이블 스페이스 |
볼륨별 테이블 스페이스 매핑 |
클러스터 |
테이블 |
클러스터 당 하나의 테이블 |
레코드 |
ROW |
한 레코드는 한 ROW로 매핑 |
3. VSAM 데이터셋 유형
VSAM은 인덱스나 레코드 번호 또는 상대 주소 순서에 따라 데이터 레코드를 저장하고 처리한다. 또한 고정길이 레코드와 가변길이 레코드에 대한 순차처리와 직접처리도 할 수 있다.
VSAM은 다음의 4가지 방식으로 데이터셋을 구성한다.
| 방식 | 설명 |
|---|---|
KSDS(Key Sequenced Data Set) |
키 순서 데이터셋이다. |
ESDS(Entry Sequenced Data Set) |
입력 순서 데이터셋이다. |
RRDS(Relative Record Data Set) |
레코드 번호별 데이터셋이다 RRDS는 레코드의 길이에 따라 다음의 2가지로 나뉜다.
|
LDS(Linear Data Set) |
리니어 데이터셋이다. TSAM에서는 LDS는 지원하지 않는다. Hitachi Mainframe에서는 LDS 유형을 FDS(Flat Data Set) 유형으로 구분한다. |
3.1. KSDS
KSDS(Key Sequenced Data Set)의 레코드들은 레코드의 키 순서에 따라서 데이터셋에 저장된다.
KSDS의 키는 레코드의 특정 필드를 말하며 다음과 같은 특성을 갖는다.
-
모든 레코드의 키 길이와 키 위치는 동일하다.
-
같은 키 값을 갖는 2개 이상의 레코드를 저장할 수 없다.
-
키 값이 저장된 이후에는 레코드의 키 값을 변경할 수 없다.
KSDS는 고정 길이의 레코드나 가변 길이의 레코드 모두를 지원한다. 새로운 레코드를 추가하는 경우 레코드는 키 값의 오름차순 순서에 맞는 위치에 삽입된다.
KSDS를 효율적으로 관리하기 위해서 VSAM은 데이터셋에 대해 데이터 자체를 저장하는 데이터 컴포넌트와 키 값의 순서로 레코드를 빠르게 접근하는 역할을 하는 인덱스 컴포넌트를 생성한다.
3.2. ESDS
ESDS(Entry Sequenced Data Set)는 레코드가 들어온 순서대로 저장된다는 점에서 Non-VSAM 데이터셋과 비슷한 점이 많다. 새로 추가되는 모든 레코드는 데이터셋의 맨 끝에 저장된다.
ESDS에 일단 저장된 레코드는 삭제가 불가능하다. 삭제하고자 하는 레코드의 내용 일부에 삭제 표시를 남기는 방법으로 해당 레코드를 애플리케이션에서 논리적으로 삭제 처리할 수 있다.
또한 ESDS에서 레코드의 갱신은 가능하지만 레코드의 길이는 변경될 수 없다. 레코드의 길이를 반드시 변경해야 하는 경우라면 앞에서 설명한 것처럼 애플리케이션 수준에서의 레코드 삭제를 표시하고 새로운 길이의 레코드를 데이터셋의 맨 뒤에 추가하는 방법을 사용해야 한다. 하지만 이와 같은 처리가 빈번할 것으로 예상되는 애플리케이션에서 사용되는 데이터셋이라면 처음부터 KSDS의 사용을 검토한다.
ESDS는 인덱스 컴포넌트를 포함하고 있지는 않지만, 보조 인덱스를 사용하는 것은 허용된다. 보조 인덱스에 대해서는 보조 인덱스와 스피어를 참고한다.
3.3. RRDS
고정 길이 레코드를 위한 RRDS(Relative Record Data Set)는 레코드들을 미리 구획 지어진 슬롯에 저장한다. 각 슬롯마다 번호가 부여되고, 레코드는 레코드에 주어진 번호에 해당하는 슬롯에 저장된다. RRDS의 데이터 블록 하나에는 여러 개의 고정 길이 슬롯이 만들어진다.
데이터 블록의 크기를 지정할 때에는 (레코드의 고정 길이 x 한 블록에 저장할 레코드의 개수 + 블록 관리에 사용되는 오버헤드 크기)만큼을 지정해 주는 것이 좋다. 그렇지 않으면 RRDS 데이터셋 내부에 사용될 수 없는 공간이 생긴다. 하지만 이 공간의 크기는 1개의 고정 길이 레코드보다 크지는 않기 때문에 큰 문제가 발생하지는 않는다.
RRDS는 고정 길이로 레코드를 저장하기 때문에 레코드의 번호만 알면 간단한 계산만으로 해당 레코드가 존재하는 위치를 알 수 있기 때문에 데이터 레코드로의 접근이 효율적이다. 하지만 저장되는 레코드의 길이가 고정되어 있다는 점과 레코드 번호를 가지고 데이터 레코드를 구분한다는 개념이 애플리케이션의 도메인에 적합하지 않은 경우가 많기 때문에 주로 한정된 수의 개체를 관리하는 특별한 경우에만 한하여 사용된다.
3.4. VRDS
VRDS는 가변 길이 레코드를 저장할 수 있는 RRDS이다. 사용자 관점에서 VRDS을 사용하는 방식은 RRDS을 사용하는 방식과 동일하다. 즉 사용 가능한 액세스 메소드와 레코드를 지정하기 위해서 제공해야 하는 인자가 동일하다. 하지만 VSAM 내부적인 입장에서는 VRDS 데이터셋을 처리하는 데에는 오히려 KSDS과 유사하게 인덱스 컴포넌트와 데이터 컴포넌트를 이용해서 레코드를 관리한다.
인덱스 컴포넌트가 필요한 이유는 각 레코드의 길이가 고정되어 있지 않기 때문에 레코드 번호만을 가지고 간단하게 원하는 레코드가 저장된 위치를 알아내는 것이 불가능하기 때문이다. 반면, KSDS의 관리와 다른 점은 KSDS에 대해서는 인덱스 컴포넌트의 키로 레코드의 일부인 키 영역을 사용하지만, VRDS에서는 레코드와는 별도로 사용자가 제공하는 레코드 번호를 인덱스 컴포넌트의 키로 사용한다. 인덱스 레코드의 인덱스 정보는 KSDS와 동일한 레코드 시작위치 주소(RBA)를 사용한다.
|
OpenFrame에서는 RRDS 만으로 고정 길이, 가변 길이 레코드를 모두 처리하기 때문에 VRDS는 지원하지 않는다. |
4. VSAM 데이터셋 이름
VSAM 데이터셋은 클러스터 이름과 컴포넌트 이름을 지정하여 생성할 수 있다.
OpenFrame 시스템에서 VSAM 데이터셋을 생성할 때, 클러스터 이름만 지정하고 컴포넌트 이름을 지정하지 않으면, 컴포넌트 이름 지정 규칙에 의해 이름을 생성한다.
컴포넌트의 이름은 다음의 3가지 규칙에 의해 지정된다.
-
클러스터의 마지막 이름 세그먼트가 "CLUSTER"인 경우
-
마지막 이름 세그먼트를 데이터 컴포넌트는 "DATA"로 변경
-
인덱스 컴포넌트는 "INDEX"로 변경
다음의 예제는 클러스터 이름이 'TMAX.TEST.KSDS01.CLUSTER’일 때 규칙에 의해 생성된 데이터 컴포넌트, 인덱스 컴포넌트의 이름을 보여준다.
클러스터 이름 : TMAX.TEST.KSDS01.CLUSTER 데이터 컴포넌트 : TMAX.TEST.KSDS01.DATA 인덱스 컴포넌트 : TMAX.TEST.KSDS01.INDEX
-
-
클러스터의 이름의 길이가 38자 보다 작거나 같은 경우
-
데이터 컴포넌트는 ".DATA"로 추가
-
인덱스 컴포넌트는 ".INDEX"를 추가
다음의 예제는 클러스터 이름이 TMAX.TEST.KSDS01.INFO일 때 규칙에 의해 생성된 데이터 컴포넌트, 인덱스 컴포넌트의 이름을 보여준다.
클러스터 이름 : TMAX.TEST.KSDS01.INFO 데이터 컴포넌트 : TMAX.TEST.KSDS01.INFO.DATA 인덱스 컴포넌트 : TMAX.TEST.KSDS01.INFO.INDEX
-
-
클러스터의 이름의 길이가 39자 보다 크거나 같은 경우
-
데이터 컴포넌트는 ".D"를 추가
-
인덱스 컴포넌트는 ".I"를 추가
다음의 예제는 클러스터 이름이 'TMAX.TEST.KSDS01.RESOURCE.FROM.REGION01’일 때 규칙에 의해 생성된 데이터 컴포넌트, 인덱스 컴포넌트의 이름을 보여준다.
클러스터 이름 : TMAX.TEST.KSDS01.RESOURCE.FROM.REGION01 데이터 컴포넌트 : TMAX.TEST.KSDS01.RESOURCE.FROM.REGION01.D 인덱스 컴포넌트 : TMAX.TEST.KSDS01.RESOURCE.FROM.REGION01.I
클러스터의 이름의 길이가 43~44자이면 3번째 규칙에 의해 컴포넌트 이름의 길이가 45~46자가 되고, 데이터셋 이름 길이 제한 에러가 발생한다. 따라서 VSAM 데이터셋의 이름은 클러스터 이름만 지정하고 컴포넌트 이름을 지정하지 않으면 42문자로 제한한다.
-
5. 보조 인덱스와 스피어
본 절에서는 보조 인덱스와 스피어의 개념에 대해서 설명한다.
5.1. 보조 인덱스
액세스 메소드 서비스를 사용하면 KSDS나 ESDS(베이스 클러스터)에 보조 인덱스(AIX: Alternate Index)를 정의할 수 있다. 보조 인덱스는 베이스 클러스터 레코드에 기본 키 이외의 키 필드로 접근할 수 있는 방법을 제공한다.
보조 인덱스를 사용하면 서로 다른 애플리케이션을 위해 동일한 정보를 담고 있는 데이터셋을 여러 개 복사해서 관리해야 하는 번거로움을 없애준다.
베이스 클러스터 레코드의 어느 부분이라도 보조 인덱스의 키가 될 수 있다. 심지어 베이스 레코드의 동일한 부분을 보조 키로 사용하는 여러 개의 보조 인덱스를 만드는 것도 가능하다. 보조 키는 베이스 클러스터 자체의 기본 키와는 달리 한 데이터셋 안의 레코드들 사이에서 유일할 필요는 없다. 즉, 하나의 보조 키에 대해서 여러 개의 레코드가 대응될 수 있지만 OpenFrame에서는 이를 지원하지 않는다.
보조 인덱스는 사실 인덱스 컴포넌트와 데이터 컴포넌트로 구성된 독립적인 KSDS이다. 보조 인덱스의 레코드에는 보조 키와 베이스 클러스터의 데이터를 가리키는 포인터 정보를 담고 있다. OpenFrame에서는 독립적인 KSDS가 아닌 베이스 클러스터 테이블에 데이터베이스 인덱스를 생성하는 방식으로 처리한다.
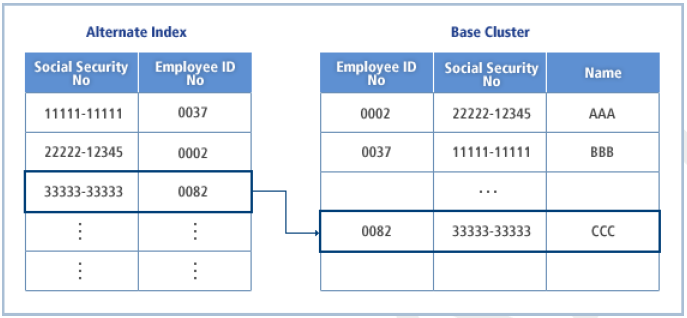
보조 인덱스 접근경로
보조 인덱스를 사용해서 KSDS나 ESDS를 처리하기 전에 먼저 접근경로(Path)가 정의되어야 한다(OpenFrame에서는 필수적인 작업은 아니다). 접근경로는 보조 인덱스를 이용해서 베이스 클러스터를 처리할 때 사용되는 카탈로그 항목이다.
접근경로는 IDCAMS(JSCVSUT/KQCAMS) 유틸리티의 DEFINE PATH 명령을 이용해서 정의할 수 있다. 각 보조 인덱스에 대해 적어도 1개 이상의 접근경로가 정의되어야 보조 인덱스를 통해 베이스 클러스터를 처리할 수 있다. 접근경로는 개념적으로 베이스 클러스터와 보조 인덱스의 쌍으로 볼 수 있다.
애플리케이션이 처리를 위해 경로를 사용하게 되면 베이스 클러스터와 보조 인덱스 데이터셋이 함께 열린다. 베이스 클러스터와 이와 연관된 모든 보조 인덱스의 집합을 스피어(Sphere)라고 한다.
5.2. 스피어
베이스 클러스터와 이 베이스 클러스터에 대한 보조 인덱스들의 집합이 스피어(Sphere)이다. 베이스 클러스터에 대한 보조 인덱스는 자체적으로 하나의 보조 키와 다수 개의 기본 키를 갖는 레코드로 구성된 KSDS 클러스터이다.
스피어 개념을 도입하게 되면, 베이스가 되는 데이터셋에 대한 추가적인 액세스 메소드가 추가된다. 순차 액세스 메소드나 직접 액세스 메소드와 같은 구분이 아닌 베이스 데이터셋의 기본 키가 아닌 다른 키에 의한 액세스 메소드가 생긴다. 이것을 데이터에 대한 여러 개의 접근경로가 존재한다고 말한다.
실례로 COBOL 애플리케이션의 ALTERNATE KEY 구문에 의한 데이터셋의 사용을 대표적인 예로 볼 수 있다. VSAM 액세스 메소드는 KSDS나 ESDS에 대해 여러 개의 보조 키를 사용한 순차 및 직접 접근방법을 제공한다. 이와 같은 액세스 메소드를 접근경로를 이용한 액세스 메소드라고 한다.
6. VSAM 데이터셋 관리
VSAM 데이터셋은 액세스 메소드 서비스의 명령어를 사용해서 정의될 수 있다.
다음은 VSAM 데이터셋을 관리하는 방법에 대한 설명이다.
-
모든 VSAM 데이터셋은 카탈로그에 등록되어야 한다. 만약 새로운 카탈로그를 사용하고 싶다면 액세스 메소드 서비스의 DEFINE USERCATALOG 명령어를 사용해서 새로운 카탈로그를 생성한다.
-
VSAM 데이터셋은 액세스 메소드 서비스의 DEFINE CLUSTER 명령어를 사용하여 카탈로그에 정의하거나, JCL의 DISP, RECORG 파라미터를 사용해서 VSAM 데이터셋을 생성할 수 있다.
-
액세스 메소드 서비스의 REPRO 명령어를 사용하거나, 별도의 사용자 프로그램을 작성해서 VSAM 데이터셋에 데이터를 적재한다.
-
선택적으로 보조 인덱스를 베이스 클러스터에 연결해서 사용하길 원하면 액세스 메소드 서비스의 DEFINE ALTERNATEINDEX, DEFINE PATH 그리고 BLDINDEX 명령어를 사용한다.
앞의 모든 Step에서 VSAM 데이터셋에 대한 작업결과를 확인하기 위해서는 액세스 메소드 서비스의 LISTCAT이나 PRINT 명령어를 사용한다. LISTCAT이나 PRINT 명령어는 VSAM 데이터셋과 관련된 문제를 발견하고 수정하는 데에 유용하게 사용된다.
클러스터 개념
KSDS인 경우 클러스터는 데이터 컴포넌트와 인덱스 컴포넌트의 조합이다. 클러스터는 인덱스와 데이터 컴포넌트를 마치 하나의 컴포넌트인 것처럼 다룰 수 있도록 해준다. 고정길이 RRDS나 ESDS의 경우에는 인덱스 컴포넌트없이 데이터 컴포넌트 만으로 클러스터로 간주되나, 다른 데이터셋과의 통일성을 기하기 위해 데이터셋을 처리하기 위해 클러스터 이름이 주어지게 된다.
VSAM 데이터셋 정의
액세스 메소드 서비스의 DEFINE CLUSTER 명령어를 이용해서 VSAM 데이터셋을 정의할 수 있다.
클러스터가 정의될 때, 클러스터를 기술하기 위해 다음의 카탈로그 항목들이 등록된다.
-
클러스터를 하나의 컴포넌트인 것처럼 사용하기 위한 클러스터 항목
-
클러스터의 데이터 컴포넌트를 기술하기 위한 데이터 항목
-
KSDS인 경우 클러스터의 인덱스 컴포넌트를 기술하기 위한 인덱스 항목
클러스터의 모든 속성이 카탈로그에 기록된다. 카탈로그에는 데이터셋을 관리하거나 레코드 I/O를 하기 위한 모든 정보를 담아서 제공한다.
액세스 메소드 서비스를 이용해서 VSAM 데이터셋을 정의할 때 다음과 같은 파라미터를 지정할 수 있다.
| 파라미터 | 설명 |
|---|---|
INDEXED|NOINDEXED|NUMBERED |
VSAM 데이터셋의 유형을 지정한다.
|
RECORDSIZE |
평균 또는 최대 데이터 레코드의 길이를 지정한다. 고정 길이 데이터셋인 경우 평균 레코드 길이와 최대 레코드 길이를 같게 지정한다. |
KEYS |
KSDS에서 레코드 내 키의 위치와 길이를 지정한다. |
CATALOG |
클러스터가 정의될 카탈로그 이름을 지정한다. |
VOLUMES |
클러스터를 위한 공간이 할당될 볼륨 시리얼을 지정한다. |
RECORDS | KILOBYTES | MEGABYTES | TRACKS | CYLINDERS |
클러스터를 위한 디스크 공간의 크기를 지정한다. |
CONTROLINTERVALSIZE |
VSAM이 사용할 컨트롤 인터벌의 크기를 지정한다. OpenFrame에서는 지원하지 않는다. |
SPANNED |
레코드가 컨트롤 인터벌에 걸쳐서 저장될 수 있는지 여부를 결정한다. OpenFrame에서는 지원하지 않는다. |
또한, JCL의 DISP 파라미터와 RECORG 파라미터를 이용해 VSAM 데이터셋을 정의할 수 있다. 아래는 JCL을 통해 KSDS를 정의하는 예시이다.
//DD1 DD DSN=NEW.DATASET,DISP=(NEW,KEEP,DELETE),RECORG=KS,LRECL=80
VSAM 데이터셋 적재
VSAM 데이터셋이 정의되면, 소스 데이터셋으로부터 정의된 VSAM 데이터셋에 레코드를 적재할 수 있다. 적재되는 VSAM 데이터셋의 유형에 따라 소스 데이터셋은 특정한 순서대로 정렬되어 있어야 한다.
-
ESDS 데이터셋에 적재되는 데이터 레코드
특별히 정해진 순서가 없다. 레코드의 특정 필드에 의해서가 아니라 레코드가 추가된 순서대로 정렬된다.
-
KSDS 데이터셋에 적재되는 데이터 레코드
입력 데이터셋에 중복되는 키 없이 오름차순으로 정렬되어 있어야 한다.
-
RRDS 데이터셋에 적재되는 데이터 레코드
오름차순으로 정렬되어 있어야 한다. 만약 순차적으로 적재되는 경우에는 VSAM이 순서대로 상대 레코드 번호를 부여한다.
데이터셋 적재 방법에는 다음의 2가지가 있다.
-
REPRO를 이용한 데이터셋 적재
액세스 메소드 서비스의 REPRO 명령을 사용하면 순차 데이터셋이나 VSAM 데이터셋으로부터 레코드를 추출해서 모든 VSAM 데이터셋에 적재할 수 있다.
-
프로그램을 작성해서 데이터셋 적재
프로그램을 작성해서 KSDS 데이터셋에 적재하기 위해서는 우선 데이터 레코드를 키 순서대로 정렬한 후 순차적으로 저장한다.
보조 인덱스 정의
보조 인덱스는 연관된 베이스 레코드의 보조키 순서대로 인덱스 항목을 저장하고 있는 또 하나의 KSDS 데이터셋이다. 보조 인덱스는 클러스터의 데이터 컴포넌트에 있는 레코드를 찾아가는 또다른 방법을 제공한다.
보조 인덱스는 KSDS 클러스터나 ESDS 클러스터에 대해 정의될 수 있다. 보조 인덱스를 구성하는 절차는 아래와 같다.
-
DEFINE CLUSTER 명령어를 사용해서 베이스 클러스터를 정의한다.
-
REPRO 명령을 사용하거나 프로그램을 작성해서 베이스 클러스터를 적재한다.
-
DEFINE ALTERNATEINDEX 명령을 사용해서 보조 인덱스를 정의한다.
-
DEFINE PATH 명령을 이용해 보조 인덱스를 베이스 클러스터에 연결한다.
-
BLDINDEX 명령을 이용해 보조 인덱스를 구성한다.
|
PATH를 정의하여 보조 인덱스를 베이스 클러스터에 연결하고 BLDINDEX 명령으로 보조 인덱스를 구성하는 것은 OpenFrame에서는 필수적인 작업이 아니다. |
VSAM은 보조 인덱스를 기술하기 위해 다음 3개의 카탈로그 항목을 이용한다.
-
보조 인덱스를 KSDS 데이터셋으로 기술하기 위한 보조 인덱스 항목
-
보조 인덱스의 데이터 컴포넌트를 기술하기 위한 데이터 항목
-
보조 인덱스의 인덱스 컴포넌트를 기술하기 위한 인덱스 항목
유일하지 않는 키를 갖는 보조 인덱스를 정의할 때에는 레코드 크기를 최대한 크게 지정하여 모든 유일하지 않는 키를 처리할 수 있도록 해야 한다. 같은 보조 키를 갖는 모든 레코드들의 기본 키 값들은 하나의 보조 인덱스 레코드에 저장된다.
보조 인덱스 관리
VSAM은 보조 인덱스가 항상 베이스 클러스터와 동기화되어 있다고 생각한다. 그래서 매번 데이터셋을 열 때마다 동기화되어 있는지 여부를 체크하지 않는다.
보조 인덱스를 정의할 때 UPGRADE 속성을 지정한 경우 보조 인덱스와 연결된 베이스 클러스터가 변경될 때, 보조 인덱스도 같이 변경해 준다. 이 경우 베이스 클러스터가 출력 모드로 열릴 때, 자동으로 베이스 클러스터에 연관된 모든 보조 인덱스도 같이 열린다.
OpenFrame에서는 베이스 클러스터 테이블에 데이터베이스 인덱스를 생성하는 방식으로 보조 인덱스를 생성하기 때문에 UPGRADE / NOUPGRADE 속성을 지원하지 않지만 기본적인 동작은 UPGRADE 속성을 부여한 것과 동일하다.
접근경로 정의
보조 인덱스가 정의된 후 DEFINE PATH 명령을 이용해서 베이스 클러스터와 보조 인덱스와의 관계를 만들어야 한다. 접근경로는 베이스 클러스터와 보조 인덱스의 쌍을 지칭한다. 접근경로를 통해서 데이터셋에 접근하는 경우 JCL의 DSNAME 파라미터에 접근경로명을 적는다.
사용자 프로그램에서 접근경로로 데이터를 처리하는 경우 보조 인덱스와 베이스 클러스터가 동시에 열린다. 베이스 클러스터의 데이터는 보조 인덱스의 키를 통해서 읽히거나 쓰여진다.
카탈로그 항목 리스트
VSAM 데이터셋이 정의되고 난 후 액세스 메소드 서비스의 LISTCAT 명령어를 사용하면 카탈로그에 등록된 항목의 일부 또는 전부를 조회할 수 있다.
LISTCAT 명령어는 카탈로그에 등록된 다음과 같은 정보를 보여준다.
-
SMS 속성을 포함한 모든 객체의 속성
-
생성일자와 만료일자
-
데이터셋의 구조
-
데이터셋 사용에 대한 통계
-
공간 할당 정보 및 볼륨 정보
데이터셋 복사
여러 가지 이유로 데이터셋을 복사하거나 2개의 데이터셋을 하나로 합칠 필요가 있다. 예를 들면, 테스트용 복사 데이터셋을 만들 경우 다른 목적으로 2개의 복사본을 만들 경우가 있다. 또는 데이터셋을 갱신하기 전에 백업용으로 복사를 해둘 필요도 있다. 이런 경우에 액세스 메소드 서비스의 REPRO 명령을 사용해서 데이터셋을 복사할 수 있다.
다음과 같은 경우에 REPRO를 이용하여 데이터셋을 복사할 수 있다.
-
VSAM 데이터셋을 복사해서 새로운 VSAM 데이터셋을 만들 경우
-
순차 데이터셋을 복사해서 새로운 순차 데이터셋을 만들 경우
-
순차 데이터셋을 복사해서 VSAM 데이터셋으로 변환하는 경우
-
VSAM 데이터셋을 복사해서 순차 데이터셋으로 변환하는 경우
-
VSAM 데이터셋을 복사해서 자동으로 REORGANIZE하는 경우
-
PDS나 PDSE(Partitioned DataSet Extended)의 개별 멤버를 복사하는 경우
KSDS 데이터셋으로 복사하는 경우 입력 데이터셋의 데이터 레코드는 중복되는 키 없이 오름차순으로 정렬되어 있어야 한다.
VSAM 데이터셋이 키 순서대로 복사되는 경우 다음과 같은 재구성(reorganization)이 자동으로 수행된다.
-
논리 레코드의 물리적인 위치 정렬
-
데이터셋 내부적인 여유공간의 분배
-
VSAM 인덱스 컴포넌트의 재구성
데이터셋 출력
데이터셋을 사용하는 중에 문제가 발생한 경우 액세스 메소드 서비스의 PRINT 명령어를 사용하면 VSAM 데이터셋의 일부 또는 전체 레코드를 출력해 볼 수 있다.
출력은 논리 레코드의 데이터 내용만이 출력되며, 시스템이 관리하는 제어 필드는 출력되지 않는다. 출력되는 각각의 레코드는 다음 중 하나의 방법으로 구분된다.
-
ESDS 데이터셋인 경우 상대 Byte 주소(RBA)
-
KSDS 데이터셋인 경우 키 값(KEY)
-
RRDS 데이터셋인 경우 레코드 번호(RRN)
데이터셋 삭제
액세스 메소드 서비스의 DELETE 명령어를 사용하면 데이터셋 또는 카탈로그를 삭제할 수 있다. DELETE 명령어는 데이터셋이 있던 볼륨에서 데이터셋을 제거하고 카탈로그에서 데이터셋 항목을 삭제한다.
Browsing
다음은 브라우징과 관련하여 지원되는 인터페이스이다.
| 인터페이스 | 설명 |
|---|---|
START_BR |
TSAM에서 임의의 레코드를 읽을 때와 같은 방식으로 브라우징을 시작한다. 브라우저의 포인터만 초기화하고 레코드를 읽지는 않는다. |
READ_NEXT |
START_BR 인터페이스로 정해진 시작위치부터 레코드를 순차적으로 읽는다. |
READ_PREV |
데이터셋을 역순으로 읽는다. |
RESET_BR |
브라우징이 시작되면 현재 브라우징하는 포인터를 변경한다. 단순히 READ_NEXT 또는 READ_PREV 인터페이스의 파라미터인 RIDFLD를 변경해도 바로 브라우징 포인터가 변경된다. |
Transaction
트랜잭션은 한 번에 처리되어야 할 하나 이상의 일련의 작업의 묶음을 나타내는 논리적인 작업 단위이다.
다음은 트랜잭션과 관련하여 지원되는 인터페이스이다.
| 인터페이스 | 설명 |
|---|---|
COMMIT |
현재 트랜잭션을 Commit할 때 사용한다. |
ROLLBACK |
현재 트랜잭션을 Rollback할 때 사용한다. |
중간 Commit
OpenFrame의 TSAM은 RDB 테이블로 구현되어 있기 때문에 작업 내용을 테이블에 반영하기 위해 DB에 Commit을 요청해야 한다. 이 때 배치 작업 등에서 갱신 사항이 너무 많이 쌓여 성능이 저하되는 문제를 방지하기 위해 OpenFrame은 1024개의 명령마다 작업한 내용을 DB에 Commit하며, 최종적으로 작업이 정상적으로 종료되었을 때 남은 수정사항을 한번 더 Commit한다.
이 때문에 Job이 실행 도중 비정상 종료되더라도 중간 Commit 간격을 넘은 데이터의 경우 Rollback되지 않고 DB에 반영되기 때문에 데이터셋의 상태는 Job이 실행되기 전과 다를 수 있다. 또한 호스트 시스템의 VSAM은 Non-VSAM과 마찬가지로 수정한 내용이 저장 공간에 바로 반영되기 때문에 OpenFrame의 동작과 차이가 있다.
7. VSAM 형식의 ISAM/BDAM 데이터셋
ISAM 데이터셋은 내부적으로 VSAM의 KSDS 데이터셋 유형으로 매핑한다.
BDAM 데이터셋은 OpenFrame 환경설정 중 ds 서브젝트 DATASET_DEFAULT 섹션의 USE_BDAM_AS_TSAM 키의 VALUE 항목값을 'YES’로 지정한 경우에 내부적으로 VSAM 형식으로 생성하며, 기본적으로 RRDS 유형으로 매핑하지만 ACTUAL KEY를 사용하는 BDAM 데이터셋은 KSDS 유형으로 매핑한다.
내부적으로는 VSAM 이지만 실제로는 Non-VSAM 데이터셋이기 때문에 VSAM과는 다르게 볼륨 이름이 다르면서 동일한 이름의 데이터셋을 생성할 수가 있다. 따라서 생성되는 RDB 테이블 이름은 V{VOLUME_NAME}_{DATASET_NAME} 으로 생성이 되며, 앞의 'V’는 볼륨 이름이 숫자로 시작할 수 있기 때문에 테이블 이름이 숫자로 시작하는 것을 방지하기 위해 고정 문자 V가 붙는다.
앞에 'V’가 붙는 것은 테이블 이름과 이와 관련된 SQL에만 적용되는 사항이며, Copybook 파일과 같이 해당 데이터셋과 관련된 파일들이 존재하는 경우에 파일 이름은 'V’가 없는 {VOLUME_NAME}_{DATASET_NAME} 이다.
다음의 예제는 볼륨 이름과 ISAM 데이터셋 또는 USE_BDAM_AS_TSAM 키의 VALUE 항목값을 'YES’로 지정한 경우의 BDAM 데이터셋 이름이 다음과 같을 때, 각 항목의 이름이 어떻게 구성되는지 보여준다.
볼륨 이름 : DEFVOL ISAM/BDAM 데이터셋 이름 : TMAX.TEST.DATASET RDB 테이블 이름 : VDEFVOL_TMAX_TEST_DATASET VSAM 라이브러리 파일 이름 : DEFVOL_TMAX_TEST_DATASET.tbc Copybook 파일 이름 : DEFVOL_TMAX.TEST.DATASET.cpy