데이터셋 유틸리티
본 장에서는 데이터셋 유틸리티에 대해 기술한다.
1. 개요
다음은 데이터셋 유틸리티 목록이다. 각 유틸리티에 대한 설명은 해당 절에서 자세하게 기술한다.
| 프로그램명 | 설명 |
|---|---|
일본어 파일을 편집하는 유틸리티 프로그램이다. |
|
2개의 SDS나 PDS를 비교조건을 통해 비교 후 그 결과를 출력하는 유틸리티 프로그램이다. |
|
테스트 데이터 셋을 생성하는 유틸리티 프로그램이다. |
|
순차 데이터셋 또는 PDS의 멤버를 복사하는 유틸리티 프로그램이다. |
|
순차 데이터 셋이나 PDS의 전체 또는 일부를 실제 출력할 형식으로 데이터를 생성하는 유틸리티 프로그램이다. |
|
1개 이상의 PDS에 대해서 멤버들을 전체 또는 일부만 복사하거나 병합하는 유틸리티 프로그램이다. |
|
PDS의 데이터셋 정보와 멤버 리스트 또는 볼륨 정보와 볼륨에 포함된 데이터셋 리스트를 제공하는 유틸리티 프로그램이다. |
|
Non-VSAM 데이터 셋을 명령어에서 지정한 볼륨으로 이동 또는 복사하는 유틸리티 프로그램이다. |
|
Non-VSAM 데이터 셋을 관리하는 유틸리티 프로그램이다. |
|
BACKUP과 RESTORE 명령을 통해 데이터 셋이나 볼륨의 백업 및 복원 기능을 사용하는 유틸리티 프로그램이다. |
|
VSAM과 Non-VSAM 데이터셋 및 카탈로그 정보를 생성하고 관리하는 유틸리티 프로그램이다. |
2. JRQJAFE
일본어 파일을 편집하는 유틸리티 프로그램이다.
JRQJAFE는 다음과 같은 기능을 수행할 수 있다.
-
일본어 데이터를 이용하기 쉬운 형식으로 KSDS 데이터셋을 작성한다.
-
일본어 데이터셋의 내용을 수정한다.
-
일본어 데이터를 인쇄한다.
2.1. DD 설정
DD 설정 항목은 다음과 같다.
| 항목 | 설명 |
|---|---|
SYSPRINT DD |
JRQJAFE 메시지가 저장되는 데이터셋을 지정한다. |
SYSIN DD |
JRQJAFE의 제어문을 입력하는 데이터셋을 정의한다. |
SYSLIST DD |
JRQJAFE의 인쇄 데이터셋을 정의한다. |
임의의 DD |
JRQJAFE의 일본어 파일을 정의한다. |
2.2. 명령어 설정
본 절에서는 SYSIN DD에서 설정하는 JRQJAFE의 명령어에 대해서 설명한다.
-
MODE
후속하는 제어문의 일본어 파일을 미리 지정해 둔다. MODE 제어문의 유효한 범위는 MODE 제어문과 ENDMODE 제어문으로 둘러싸인 부분이다. 이 범위에 있는 제어문의 오퍼랜드에는 MODE 제어문에서 지정한 일본어 파일 정의 파라미터를 중복해서 기술하면 안 된다.
MODE 명령어 구문 다음과 같다.
[label] MODE {IN(ddname) | OUT(ddname) | INOUT(ddname) | IN(ddname),OUT(ddname)}항목 설명 IN
입력 일본어 데이터셋을 정의한다.
OUT
출력 일본어 데이터셋을 정의한다.
INOUT
입출력 일본어 데이터셋을 정의한다.
IN,OUT
입력 일본어 데이터셋과 출력 일본어 데이터셋을 정의한다.
-
ENDMODE
MODE 제어문의 기능의 유효 범위의 종료를 지시한다.
ENDMODE 명령어 구문 다음과 같다.
ENDMODE
-
DEFINE
일본어 파일을 작성, 갱신하는 입력 데이터 내에서 사용하고 있는 KIS 코드 외자를 정의한다.
DEFINE 명령어 구문 다음과 같다.
[label] DEFINE KIS
항목 설명 DEFINE
현재 파싱만 지원한다.
-
DEND
DEFINE 제어문의 기능의 유효 범위의 종료를 지시한다.
DEND 명령어 구문 다음과 같다.
[label] DEND
항목 설명 DEND
현재 파싱만 지원한다.
-
CHGIN
입력 데이터셋을 제어 데이터 입력 데이터셋(SYSIN DD 문으로 정의된 데이터셋)로부터 다른 데이터셋으로 새로 바꾼다.
CHGIN 명령어 구문 다음과 같다.
[label] CHGIN IN(ddname)
항목 설명 IN
새로 지정할 입력 데이터셋을 정의한다.
-
ADD
일본어 파일의 작성을 지시한다. 일본어 파일을 작성하기 위한 데이터는 이 제어문에 이어 준다.
ADD 명령어 구문 다음과 같다.
[label] ADD [OUT(ddname)], FIELD((number[,A][,L]) (number[,{A|B|K}][,{L|R}])] ...) [,{KLIST[({1|2})]|LIST|NOLIST}] [,{MSG | NOMSG}]항목 설명 OUT
작성된 일본어 파일의 데이터셋을 정의한다.
MODE 제어문에 OUT 오퍼랜드가 지정되고 있는 경우는, 이 오퍼랜드를 기술해서는 안 된다.
FIELD
작성된 일본어 파일의 한 레코드 내의 필드 구성을 정의한다. 안쪽의 괄호로 묶어진 것이 레코드 내의 한 필드에 대응하고 있다. 첫 번째의 필드는 key로 취급한다.
-
number
대응하는 필드의 문자수를 지정한다. 이 필드가 K(일본어) 필드이면 한 문자에 대해 2Bytes, A(영숫자·가나) 필드이면 한 문자에 대해 1Byte를 점유한다.
-
{A|B|K}
필드 내에 들어갈 수 있는 데이터의 종류를 지정한다.
-
A : EBCDIC 코드(영숫자·가나 코드)를 넣는 것을 나타낸다.
-
B : 바이너리 데이터(수치)를 넣는 것을 나타낸다.
-
K : JEF 코드(일본어 코드)를 넣는 것을 나타낸다.
파라미터가 생략되었을 경우는 K가 지정된 것으로 한다. 다만, 첫 번째의 필드는 key로 취급하므로 A 필드가 아니면 안된다(이 파라미터가 생략되어도 A가 지정된 것으로 한다). 각각의 속성을 가지는 필드를 A 필드, B 필드, K 필드라고 부른다.
-
-
{L|R}
필드에 데이터를 넣을 때 채우는 위치를 지정한다.
-
L : 왼쪽 채우기로 넣는 것을 나타낸다.
-
R : 오른쪽 채우기로 넣는 것을 나타낸다.
왼쪽(오른쪽) 채우기는 필드에 들어갈 수 있는 데이터를 왼쪽(오른쪽)으로부터 차례로 꺼내 필드의 왼쪽(오른쪽)으로부터 순서에 채우는 것을 의미한다. 또, 이것들 각각의 속성을 가지는 필드를 왼쪽 채우기 필드라고 한다. 본 파라미터가 생략되었을 경우는 L이 지정된 것으로 한다.
-
KLIST | LIST | NOLIST
작성된 일본어 파일의 내용을 인쇄 데이터 세트에 출력할지 어떨지를 지정한다. 이 오퍼랜드가 생략되었을 경우는 NOLIST가 지정된 것으로 한다.
-
KLIST[({1|2})] : 현재 파싱만 지원한다.
-
LIST : 통상의 라인 프린터에 출력 하는 것을 지시한다(SYSLIST DD를 참조한다).
-
NOLIST : 출력하지 않는 것을 지시한다.
MSG | NOMSG
메시지 데이터셋에 출력하는 정보의 레벨을 지정한다. 이 오퍼랜드가 생략되었을 경우는 MSG가 지정된 것으로 한다.
각 항목은 다음의 정보만 출력한다.
-
MSG : 입력된 ADD 제어문, 통지 메시지, 입력 데이터의 리스트, 이 제어문으로 작성한 일본어 파일의 레코드 수를 출력한다.
-
NOMSG : 입력된 ADD 제어문. 통지 메시지를 출력한다.
-
-
FORMAT
본 유틸리티에게 주는 데이터의 입력 형식을 정의한다.
FORMAT 명령어 구문 다음과 같다.
[label] FORMAT [RDLM('Delimiter')][, FDLM('Delimiter')] FIELDS((number[,A]), (number[,{A | KIS | JEF | N }])[, (number[,{A | KIS | JEF | N }])]...) SAME항목 설명 RDLM
입력 데이터를 레코드 단위로 구분할 때 사용하는 문자를 지정한다.
생략되었을 경우는 레코드 단락 문자로서 세미콜론(;)이 지정된 것으로 한다.
FDLM
입력 데이터를 필드 단위로 구분할 때 사용하는 문자를 지정한다.
생략되었을 경우는 필드 단락 문자로서 쉼표(,)가 지정된 것으로 한다.
FIELDS
정형 입력 형식에서 데이터를 입력하는 것을 지정한다. 안쪽의 괄호로 묶어진 것이 각 필드에 대한 입력 데이터의 형식을 나타낸다.
문자수는 각 필드에 대한 입력 데이터의 문자수를 지정한다. 입력 데이터의 형식이 A, N, KIS의 경우는 한 문자가 1Byte이며, 입력 데이터의 형식이 JEF의 경우는 한 문자가 2Bytes이다.
-
A : 영숫자 코드로 데이터를 입력하는 것을 지시한다.
-
KIS : 현재 파싱만 지원한다.
-
JEF : JEF 코드(직접 한자 지정)로 데이터를 입력하는 것을 지시한다.
-
N : 일본어 항목 코드로 데이터를 입력하는 것을 지시한다.
A, KIS, JEF, N의 선택 파라미터가 생략되었을 때는 KIS가 지정된 것으로 한다. 첫 번째의 필드에 대한 데이터는 키로 취급하므로 본 파라미터가 생략되어도 A가 지정된 것으로 한다.
SAME
입력 형식과 출력 형식이 같을 경우 지정한다. 작성 또는 갱신 중의 일본어 파일의 레코드 형식과 같은 형식이 아니면 안된다.
-
-
UPDATE
일본어 파일의 갱신을 지시한다.
UPDATE 명령어 구문 다음과 같다.
[label] UPDATE [{INOUT(ddname1)|IN(ddname2),OUT(ddname)}}] [,{KLIST[({1|2})] | LIST | NOLIST] [,{MSG | NOMSG | KMSG[({1|2})]}]항목 설명 INOUT
갱신 대상의 일본어 파일을 직접 갱신하는 경우에 그 데이터셋을 정의한다. 갱신 대상의 일본어 파일이 VSAM 데이터셋일 때 밖에 지정할 수 없다.
MODE 제어문에 INOUT 오퍼랜드가 지정되고 있는 경우는 이 오퍼랜드를 지정해서는 안 된다.
IN,OUT
갱신 대상의 일본어 파일이 입력용과 출력용으로 나뉘고 있는 경우 각각의 일본어 파일의 데이터셋을 정의한다.
-
ddname2 : 입력용 일본어 파일을 정의한다.
-
ddname : 출력용 일본어 파일을 정의한다.
갱신 대상의 일본어 파일이 순서 데이터셋 또는 VSAM 데이터셋도 지정할 수 있지만, 입력용과 출력용의 데이터 세트의 형식이 달라서는 안 된다. 덧붙여 갱신 대상의 일본어 파일이 순서 데이터셋의 경우는 이 지정 밖에 할 수 없다. 또, MODE 제어문에 IN, OUT 오퍼랜드가 지정되고 있는 경우 이 오퍼랜드를 지정해서는 안 된다.
KLIST | LIST | NOLIST
갱신된 일본어 파일의 내용을 인쇄 데이터셋에 출력할지 여부를 설정한다.
생략되었을 경우는 NOLIST가 지정된 것으로 한다.
-
KLIST[({1|2})] : 파싱만 지원한다.
-
LIST : 통상의 라인 프린터에 출력하는 것을 지시한다.
-
NOLIST : 출력하지 않는 것을 지시한다.
MSG | NOMSG | KMSG
메시지 데이터셋에 출력하는 정보의 레벨을 지정한다. 생략되었을 경우는 MSG가 지정된 것으로 한다. KMSG는 파싱만 지원한다.
각 항목은 다음의 정보를 출력한다.
-
MSG : 입력된 UPDATE 제어문과 그 보조 제어문의 리스트, 통지 메시지, 입력된 갱신 데이터의 리스트, 삽입/추가된 레코드의 정보, 갱신된 레코드의 갱신 전과 갱신 후의 정보를 출력한다.
-
NOMSG : 입력된 UPDATE 제어문과 그 보조 제어문의 리스트, 통지 메시지를 출력한다.
-
KMSG [({1|2})] : 파싱만 지원한다.
-
-
CHANGE|CHG
일본어 파일 내의레코드의 특정 필드를 수정한다.
CHANGE 명령어 구문 다음과 같다.
[label] {CHANGE|CHG} 'key' ,field-num ,location[*length] ,/charatorline/항목 설명 key
수정하는 레코드의 key의 값을 캐릭터 라인으로 지정한다.
field-num
수정하는 필드의 레코드 내의 상대 위치를 번호로 지정한다.
-
key : 필드라고 생각하지 않는 것으로 한다.
-
field-num : 레코드 내에서 제일 왼쪽에 있는 필드를 1으로 하여, 오른편으로 가는에 따라 1씩 늘어가는 것으로 한다.
location[*length]
-
location : 수정하는 캐릭터 라인의 필드 내의 문자 위치를 지정한다. 수정하는 캐릭터 라인이 2 문자 이상의 경우는 왼쪽단의 문자 위치를 지정한다. 문자 위치는 필드 내의 왼쪽에서 오른쪽으로 세어 필드 내에서 제일 왼쪽에 있는 문자의 문자 위치를 1으로 한다. 문자 위치에 0을 지정했을 경우는 필드 전체의 수정을 지시한 것으로 한다.
-
length : 수정하는 캐릭터 라인의 길이를 문자수로 지정한다. 문자의 길이를 생략했을 경우는 옮겨놓는 데이터(캐릭터 라인)의 문자수가 된다. 또, 문자의 길이에 0 을 지정했을 경우는 지정된 문자의 직전에 삽입된다.
/charactor line/
수정에 의해 옮겨놓는 데이터를 캐릭터 라인 또는 공백으로 지정한다.
-
-
PRINT
일본어 파일의 내용을 인쇄 데이터셋에 출력한다.
PRINT 명령어 구문 다음과 같다.
[label] PRINT {'key1'|TOP}[:{'key2'|BOT}] [,IN(ddname)] [,SELFLD(fieldnum[,fieldnum]...)] [,LINE] [,{KCHAR[({1|2})] | CHAR}]항목 설명 'key1'|TOP : 'key2' | BOT
출력하는 레코드의 key의 값을 캐릭터 라인으로 지정한다.
key 캐릭터 라인 1, key 캐릭터 라인 2가 지정되었을 경우는 key 캐릭터 라인 1으로부터 key 캐릭터 라인 2까지의 사이에 있는 모든 키의 값을 가지는 레코드가 출력 처리의 대상이 된다. 다만, key 캐릭터 라인 1≤ key 캐릭터 라인 2가 아니면 안 된다.
TOP 및 BOT는 특별한 레코드를 나타내는 경우에 이용한다.
-
TOP : 일본어 파일 내의 선두의 레코드를 의미한다.
-
BOT : 일본어 파일 내의 최종의 레코드를 의미한다.
IN
내용을 출력하는 일본어 파일의 데이터셋을 정의한다.
MODE 제어문에 IN 오퍼랜드가 지정되고 있는 경우는 이 오퍼랜드를 기술해서는 안 된다.
SELFLD
현재 파싱만 처리한다.
LINE
현재 파싱만 처리한다.
KCHAR | CHAR
현재 파싱만 처리한다.
-
2.3. 사용예제
FORMAT의 FIELDS 양식으로 입력된 JRQ.INPUT을 ADD의 FIELDS 양식으로 JRQ.OUTPUT 데이터셋에 추가하는 예이다.
//JRQADD JOB CLASS=A,MSGLEVEL=(1,1)
//STEP01 EXEC PGM=JRQJAFE
//INJRQ DD DISP=OLD,DSN=JRQ.INPUT
//OUTJRQ DD DSN=JRQ.OUTPUT,DISP=(OLD,KEEP)
//SYSOUT DD SYSOUT=*
//SYSIN DD *
ADD OUT(OUTJRQ),FIELDS((8),(12,K,R),(8,A),(6,A), -
(1,A),(6,A),(6,A),(21,A))
FORMAT FIELDS((8),(24,A),(8),(6),(1),(6),(6),(21))
CHGIN IN(INJRQ)
END
/*
다음은 INPUT DD 없이 ADD 문 뒤에 오는 INSTREAM DATA로 사용하여 ADD하는 예이다.
//JRQADD JOB CLASS=A,MSGLEVEL=(1,1)
//STEP01 EXEC PGM=JRQJAFE
//OUTJRQ DD DSN=JRQ.OUTPUT,DISP=(OLD,KEEP)
//SYSOUT DD SYSOUT=*
//SYSIN DD *
ADD OUT(OUTJRQ),FIELDS((8),(12,K,R),(8,A),(6,A), -
(6,A))
'AAAAAAAA',K'注文集計表 ',' ','000000','000000';
'AAAA0020',K'注文集計表 ','STEP00 ','000000','000000';
'AAAA0030',K'注文集計表 ','STEP00 ','000000','000000';
'AAAA0100',K'注文集計表 ','STEP00 ','000000','000000';
'AAAA0101',K'注文集計表 ','STEP00 ','000000','000000';
'00000000',K'注文集計表 ',' ','000000','000000';
END
/*
다음은 JRQ.OUTPUT 데이터셋의 AAAA0020의 key를 갖는 레코드를 갱신하는 예이다.
//JRQUP JOB CLASS=A,MSGLEVEL=(1,1) //STEP01 EXEC PGM=JRQJAFE //OUTJRQ DD DSN=JRQ.OUTPUT,DISP=(OLD,KEEP) //JIMLIB DD DSN=JRQ.INPUT,DISP=SHR //SYSOUT DD SYSOUT=* //SYSIN DD * UPDATE INOUT(OUTJRQ) CHG 'AAAA0020',2,2,/FFF QWEQRW/ FORMAT FIELDS((8),(24,A),(8),(6)) END /*
다음은 데이터셋 JRQ.INPUT에서 AAAAAAAA 를 KEY로 가지는 레코드부터 ABBB0100를 KEY로 가지는 레코드까지 JRQ.PRI 데이터셋에 출력하는 예이다.
//JRQPRI JOB CLASS=A,MSGLEVEL=(1,1) //STEP01 EXEC PGM=JRQJAFE //INJRQ DD DSN=JRQ.INPUT,DISP=(OLD,KEEP) //SYSLIST DD DSN=JRQ.PRI,DISP=(NEW,CATLG),DCB=(RECFM=VB,LRECL=84) //SYSOUT DD SYSOUT=* //SYSIN DD * PRINT 'AAAAAAAA':'ABBB0100',IN=INJRQ END /*
2.4. 유의사항
JRQJAFE 유틸리티 프로그램이 Batch 애플리케이션을 실행한 결과는 다음과 같다.
-
정상적으로 실행한 경우
Batch 애플리케이션에서 받은 코드를 반환한다.
-
에러가 발생한 경우
해당 에러 메시지를 SYSPRINT DD에 출력하고 에러에 해당하는 코드를 반환한다.
JRQJAFE 유틸리티 프로그램에서 발생할 수 있는 에러 코드는 다음과 같다.
코드 설명 8
Warning 형태의 에러로, 다음의 경우가 해당된다.
-
데이터셋을 찾을 수 없는 경우
12
Unrecoverable 형태의 에러로, 다음의 경우가 해당된다.
-
데이터셋 관련(pgmdd, open/close, read/write) 에러
-
SYSIN DD 명령어 문법 에러
-
기타 JRQJAFE 유틸리티 프로그램 에러
16
시스템 에러와 관련된 에러로, 다음의 경우가 해당된다.
-
OpenFrame 시스템 라이브러리 초기화 실패
-
3. JSDCOMPR
2개의 SDS나 PDS를 비교조건을 통해 비교 후 그 결과를 출력하는 유틸리티 프로그램이다.
JSDCOMPR 유틸리티 프로그램은 다음과 같은 기능을 수행할 수 있다.
-
두 SDS를 비교한다.
-
두 PDS를 비교한다.
-
PDS의 특정 멤버만 선택해서 비교한다.
-
비교의 결과가 불일치할 경우 그 결과를 프린트한다.
3.1. DD 설정
DD 설정 항목은 다음과 같다.
| 항목 | 설명 |
|---|---|
SYSPRINT DD |
JSDCOMPR 메시지가 저장되는 데이터셋을 기술한다. |
SYSUT1 DD |
비교하는 순차 데이터셋이나 PDS 타입의 입력 데이터셋을 기술한다. |
SYSUT2 DD |
비교되는 순차 데이터셋이나 PDS 타입의 입력 데이터셋을 기술한다. |
SYSIN DD |
JSDCOMPR 명령어를 기술한다. |
3.2. 명령어 설정
본 절에서는 SYSIN DD에서 설정하는 JSDCOMPR의 명령어에 대해서 설명한다.
-
COMPARE
비교하는 데이터셋의 편성, 비교 처리의 중단에 관한 지시, 비교하는 레코드나 필드 등을 지정하는 제어문이다.
COMPARE 명령어 형식은 다음과 같다.
[label] COMPARE [FIELD=(length[,starting-location])] [,LIMIT=n] [,MAXNAME=n] [,STRTAFT=n] [,STOPAFT=n] [,TYPORG={PS|PO}]항목 설명 FIELD
레코드 내의 필드를 비교할 경우에 설정한다. 이 지정을 생략 했을 경우 레코드 전체가 비교된다. 여러 개를 지정할 때 동시에 여러 필드를 비교한다.
-
length : 비교하는 필드의 길이를 설정한다.
-
starting-location : 레코드 내의 필드가 시작되는 위치를 설정한다.
LIMIT
레코드의 비교하는 중 동일하지 않은 연속한 레코드의 수가 지정한 값과 일치했을 때 레코드의 비교를 중지한다. 여러 멤버를 지정했을 경우 다음 멤버의 비교를 개시한다.
SDS 또는 1개의 멤버를 비교할 때는 처리를 종료한다.
설정값은 1~ 32760의 10진수로 설정한다. 이 지정을 생략했을 경우나 0으로 입력했을 경우 LIMIT=10이 지정된 것으로 간주한다.
MAXNAME
MEMBER 제어문으로 지정하는 멤버명의 수 이상의 값을 설정한다.
설정값은 1~32760의 10진수로 설정한다. MEMBER 제어문이 없는 경우 지정해도 무시한다.
STRTAFT
순차 데이터셋을 비교하기 전 스킵할 논리 레코드의 개수를 설정한다.
데이터셋의 n+1번째 논리 레코드부터 비교된다. 레코드의 범위는 32760를 초과하지 않으며, 초과할 경우 에러 메시지를 출력한다.
생략한 경우 첫 레코드부터 비교한다.
STOPAFT
비교할 순차 데이터셋의 논리 레코드 개수를 설정한다.
순서 데이터셋 또는 구분 데이터셋 각 멤버의 비교하는 레코드 수를 설정한다.
레코드의 범위는 32760를 초과하지 않으며, 초과할 경우 에러메시지를 출력한다.
생략한 경우 최종 레코드까지 비교한다.
TYPORG
입력 데이터셋이 순차 데이터셋(PS)인지 분할 데이터셋(PO)인지 기술한다.
(기본값: PS)
-
-
MEMBER
입력 데이터셋이 PDS일 때 비교하는 멤버의 멤버명을 지정하는 제어문이다.
-
모든 멤버를 비교할 때는 생략할 수 있다.
-
모든 멤버를 비교할 때는 이름이 같은 경우만 비교한다.
이 제어문으로 지정한 멤버명의 수 이상을 COMPARE 제어문의 MAXNAME 파라미터로 지정해야 한다.
[label] MEMBER NAME={member-name | (SYSUT1-member-name,SYSUT2-member-name)}[,...]항목 설명 NAME
비교하는 멤버의 멤버명을 설정한다.
-
member-name : SYSUT1과 SYSUT2의 멤버명이 같은 경우 설정한다.
-
SYSUT1-member-name, SYSUT2-member-name : SYSUT1과 SYSUT2의 멤버명이 다른 경우 설정한다.
-
-
LABELS
유저 라벨의 처리할 때 기술한다. 파싱만 지원한다.
-
EXITS
출구 루틴을 사용할 때 기술한다. 파싱만 지원한다.
3.3. 사용예제
다음은 필드를 지정해서 데이터를 비교하는 예이다. JSDCOMPR.TEST.INPUT01과 JSDCOMPR.TEST.INPUT02의 첫 필드부터 11번째 필드와 15번째 필드부터 길이 5만큼의 필드를 비교한다.
불일치한 경우 그 결과를 출력해준다.
//TEST JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JOBSTEP EXEC PGM=JSDCOMPR
//SYSUT1 DD DSNAME=JSDCOMPR.TEST.INPUT01,DISP=(SHR)
//SYSUT2 DD DSNAME=JSDCOMPR.TEST.INPUT02,DISP=(SHR)
//SYSPRINT DD SYSOUT=A
//SYSIN DD *
COMPARE FIELD=11,FIELD(5,15),TYPORG=PS
/*
다음은 레코드를 지정해서 데이터를 비교하는 예이다. JSDCOMPR.TEST.INPUT01과 JSDCOMPR.TEST.INPUT02의 2번째 레코드까지 비교를 스킵하고 3번째 레코드부터 7개의 레코드를 비교한다. 불일치하는 연속한 레코드의 수가 3과 일치했을 때 비교를 중지한다. 불일치한 경우 그 결과를 출력해준다.
//TEST JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JOBSTEP EXEC PGM=JSDCOMPR
//SYSUT1 DD DSNAME=JSDCOMPR.TEST.INPUT01,DISP=(SHR)
//SYSUT2 DD DSNAME=JSDCOMPR.TEST.INPUT02,DISP=(SHR)
//SYSPRINT DD SYSOUT=A
//SYSIN DD *
COMPARE LIMIT=3,STRTAFT=2,STOPAFT=7,TYPORG=PS
/*
다음은 멤버명이 같은 멤버를 지정해서 데이터를 비교하는 예이다. JSDCOMPR.TEST.INPUT01과 JSDCOMPR.TEST.INPUT02의 멤버 A, B, C를 비교한다. 불일치한 경우 그 결과를 출력해준다.
//TEST JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JOBSTEP EXEC PGM=JSDCOMPR
//SYSUT1 DD DSNAME=JSDCOMPR.TEST.INPUT01,DISP=(SHR)
//SYSUT2 DD DSNAME=JSDCOMPR.TEST.INPUT02,DISP=(SHR)
//SYSPRINT DD SYSOUT=A
//SYSIN DD *
COMPARE MAXNAME=3,TYPORG=PO
MEMBER NAME=A,B,C
/*
다음은 멤버명이 다른 멤버를 지정해서 데이터를 비교하는 예이다. JSDCOMPR.TEST.INPUT01의 멤버 A,B,D와 JSDCOMPR.TEST.INPUT02의 멤버 A,C,D를 비교한다. 불일치한 경우 그 결과를 출력해준다.
//TEST JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JOBSTEP EXEC PGM=JSDCOMPR
//SYSUT1 DD DSNAME=JSDCOMPR.TEST.INPUT01,DISP=(SHR)
//SYSUT2 DD DSNAME=JSDCOMPR.TEST.INPUT02,DISP=(SHR)
//SYSPRINT DD SYSOUT=A
//SYSIN DD *
COMPARE MAXNAME=4,TYPORG=PO
MEMBER NAME=A,(B,C),D
/*
3.4. 유의사항
JSDCOMPR 유틸리티 프로그램이 Batch 애플리케이션을 실행한 결과는 다음과 같다.
-
정상적으로 실행한 경우
Batch 애플리케이션에서 받은 코드를 반환한다.
-
에러가 발생한 경우
해당 에러 메시지를 SYSPRINT DD에 출력하고 에러에 해당하는 코드를 반환한다.
JSDCOMPR 유틸리티 프로그램에서 발생할 수 있는 에러 코드는 다음과 같다.
코드 설명 8
동일하지 않은 레코드가 1개 이상 있을 경우 복귀 코드는 8이다.
동일하지 않은 레코드가 LIMIT 파라미터로 지정한 값 이상 있을 때 해당된다.
-
PDS인 경우 다음의 멤버를 처리한다. 복귀 코드는 8이다.
12
동일하지 않은 레코드가 LIMIT 파라미터로 지정한 값 이상 있을 때 해당된다.
-
SDS인 경우에만 해당된다.
Unrecoverable 형태의 에러로, 다음의 경우가 해당된다.
-
데이터셋 관련(pgmdd, open/close, read/write) 에러
-
SYSIN DD 명령어 문법 에러
-
기타 JSDCOMPR 유틸리티 프로그램 에러
16
시스템 에러와 관련된 에러로, 다음의 경우가 해당된다.
-
OpenFrame 시스템 라이브러리 초기화 실패
-
4. JSDDG
테스트 데이터셋을 생성하는 유틸리티 프로그램이다. SYSIN DD에 데이터의 패턴을 지정하여 테스트 데이터셋을 생성한다.
4.1. DD 설정
DD 설정 항목은 다음과 같다.
| 항목 | 설명 |
|---|---|
SYSPRINT DD |
JSDDG 메시지를 저장하는 데이터셋을 정의한다. |
user_defined_name1 DD |
JCL이 저장된 입력 데이터셋이나 데이터셋의 멤버를 기술한다. |
user_defined_name2 DD |
새로 생성된 JCL을 저장할 데이터셋이나 데이터셋의 멤버를 기술한다. |
SYSIN DD |
JSDDG의 명령어를 기술한다. |
4.2. 명령어 설정
본 절에서는 SYSIN DD에서 설정하는 JSDDG의 명령어에 대해서 설명한다.
-
DSD
DSD 명령어는 JSDDG를 통해 실행하는 명령어의 시작을 의미하며, 테스트 데이터 생성에 이용할 입력 데이터셋과 테스트 데이터가 출력될 출력 데이터셋을 지정한다. 최소 1개 이상의 DSD가 존재해야 하며 END문으로 끝나야 한다.
DSD 명령문의 구문은 다음과 같다.
[label] DSD OUTPUT=(ddname) [,INPUT=(ddname1[,ddname2][,...])]항목 설명 OUTPUT
출력 데이터셋의 DD를 지정한다.
INPUT
입력으로 이용할 데이터셋들의 DD를 지정한다.
-
FD
테스트 데이터가 출력될 출력 데이터의 필드 형식을 지정한다.
FD 명령문의 구문은 다음과 같다.
[label] FD NAME=name ,LENGTH=length [,STARTLOC=starting-location] [,FROMLOC=from-location] [,FILL={'character'|X'nn'}] [,{FORMAT=pattern[,CHARACTER=character] |PICTURE=length,{'character-string'|P'n'|B}}] [,SIGN=sign] [,ACTION={FX|RO|RP|SL|SR|TL|TR|WV} [,INDEX=n[,CYCLE=n][,RANGE=n]]항목 설명 NAME
필드의 이름을 지정한다. CREATE 명령의 NAME 문을 사용하여 필드 이름을 지정할때 이용된다.
LENGTH
필드의 길이를 지정한다.
STARTLOC
출력될 레코드 내에 필드의 시작위치를 지정한다.
FROMLOC
입력되는 레코드 내에 필드의 시작위치를 지정한다. 입력으로 사용할 데이터셋이 존재할 때에만 유효하다.
FILL
기본적으로 필드를 채울 값을 지정한다.
작은따옴표(' ') 안에 character를 두거나 헥사 값을 입력하는 2가지 방법이 있다.
-
character 형식 : 1Byte 문자만 입력한다.
-
X’nn 형식 : 헥사 2자리로 입력한다. (예: FILL=X'40' 또는 FILL=X’FF' )
FORMAT
필드를 채울 패턴을 지정한다.
pattern 항목에는 다음의 값을 설정할 수 있다.
-
AL : 알파벳을 패턴으로 사용한다. (Alphabetic)
-
AN : 알파벳과 숫자를 패턴으로 사용한다. (Alphanumeric)
-
BI : 바이너리를 패턴으로 사용한다. (Binary number)
-
CO : Collating sequence를 패턴으로 사용한다. (현재 지원하지 않는다)
-
PD : PACKED DECIMAL을 패턴으로 사용한다. (10자리까지 표현이 가능하며 10자리 이후는 0x00으로 초기화)
-
RA : 무작위의 바이너리를 패턴으로 사용한다. (Random number)
-
ZD : ZONED DECIMAL을 패턴으로 사용한다. (18자리까지 표현이 가능하며 18자리 이후는 0x30으로 초기화)
CHARACTER
패턴의 시작 문자를 지정한다. FORMAT 항목을 AL또는 AN 으로 지정한 경우에는 각각 알파벳 및 알파벳과 숫자만 사용할 수 있도록 제한된다.
PICTURE
사용자가 패턴을 직접 정의하여 사용한다. LENGTH에서 지정한 필드 길이만큼 지정하며 LENGTH의 길이보다 크게 지정이 되면 그 이후 패턴은 무시된다(위에서 기술한 FORMAT 문과 같이 사용하지 않는다).
SIGN
PACKED DECIMAL이나 바이너리 필드의 부호를 결정한다.
ACTION
필드의 내용이 변경되는 방법을 지정한다.
-
FX : 고정된 내용이 출력 레코드에 포함된다.
-
RO : PICTURE에서 지정한 패턴이 왼쪽으로 한 칸씩 이동하다 마지막 문자까지 도달한 경우 다시 오른쪽으로 한 칸씩 이동하며 본 위치로 돌아온 후 다시 왼쪽으로 이동한다.
-
RP : 바이너리를 패턴으로 사용한다. 문자가 한 칸씩 왼쪽으로 이동한다. 필드의 마지막 Byte는 기존의 첫 Byte 문자나 위의 FORMAT에서 지정된 패턴에 따라 계속 이어진다.
-
SL : 왼쪽 방향으로 패턴을 옮겨나간다. 문자가 한 개만 남은 경우 초기 필드 상태로 돌아간 후 계속 옮겨간다.
-
SR : 오른쪽 방향으로 패턴을 옮겨나간다. 문자가 한 개만 남은 경우 초기 필드 상태로 돌아간 후 계속 옮겨간다.
-
TL : 필드의 왼쪽 문자부터 지우며 길이를 줄인다. 문자가 한 개만 남은 경우 초기 필드 상태로 돌아간 후 계속 줄여간다.
-
TR : 필드의 오른쪽 문자부터 지우며 길이를 줄인다. 문자가 한 개만 남은 경우 초기 필드 상태로 돌아간 후 계속 줄여간다.
-
WV : PICTURE에서 지정한 패턴이 왼쪽으로 한 칸씩 이동한다. 끝까지( 빈칸이 아닌 캐릭터가 필드의 첫 Byte에 위치) 도달한 후 계속 이동한다.
INDEX
레코드가 추가될 때마다 필드 값을 증가시킬 십진수를 지정한다.
FORMAT이 ZD, PD, BI이거나 PICTURE를 지정한 경우에 이용할 수 있다. 단, PICTURE의 'character-string’의 뒷 부분은 숫자형으로 구성되어야 한다.
-
CYCLE : INDEX가 적용될 레코드 단위를 지정한다. CYCLE=3이라면 레코드가 3개 추가될 때마다 필드의 값이 증가한다. 생략되면 1로 간주한다.
-
RANGE : 필드의 값의 최고치를 지정한다. INDEX에 의해 증가한 필드 값이 이 값을 초과하는 경우 필드의 값은 기존 값 그대로 갖게 된다. 생략되면 무한히 증가한다.
-
-
REPEAT
REPEAT 명령문은 CREATE 명령문 그룹이 몇 번 반복되어 실행할지 지정한다.
REPEAT 명령문의 구문은 다음과 같다.
[label] REPEAT QUANTITY=number[,CREATE=number]
항목 설명 QUANTITY
CREATE 명령문의 그룹이 반복될 횟수를 지정한다.
CREATE
CREATE 명령문의 그룹을 구성하는 CREATE 명령문의 갯수를 지정한다.
(기본값: 1)
-
CREATE
CREATE 명령문은 출력 데이터셋의 레코드 구성을 정의한다.
CREATE 명령문의 구문은 다음과 같다.
[label] CREATE [QUANTITY=n] [,FILL={'character'|X'nn'}] [,INPUT={ddname|SYSIN[({cccc|$$$E})]}] [,PICTURE=length,startloc,{'character-string'| P'n'|B'n'}] [,NAME={(namelist)| (namelist-or-(copygroup))} [,EXIT=routinename]항목 설명 QUANTITY
CREATE문에 의해서 생성될 레코드 개수를 지정한다. (기본값: 1)
FILL
기본적으로 필드를 채울 값을 지정한다.
작은따옴표(' ') 안에 character를 두거나 헥사 값을 입력하는 2가지 방법이 있다.
-
character 형식 : 1Byte 문자만 입력한다.
-
X’nn 형식 : 헥사 2자리로 입력한다. (예: FILL=X'40' 또는 FILL=X’FF' )
INPUT
입력으로 이용할 데이터셋들의 DD를 지정한다.
DD 대신 SYSIN을 통해 입력 데이터를 직접 JCL 내에 기술할 수 있으며 데이터의 끝은 '$$$E’로 표시한다. SYSIN의 'cccc' 기능은 지원하지 않는다.
-
예)
CREATE 문에서 SYSIN을 통한 입력 데이터 '1234567890’를 지정하는 경우
CREATE QUANTITY=2,INPUT=SYSIN 1234567890 $$$E
PICTURE
사용자가 패턴을 직접 정의한다.
NAME
입력으로 사용할 namelist를 기술한다.
namelist만으로 기술하거나, namelist와 copygroup를 혼용할 수 있다.
-
namelist는 NAME 항목으로 구성되며, NAME 항목은 FD 명령에서 NAME 문으로 지정한 필드이다.
-
copygroup은 (COPY=n,name1[,name2] [,…]) 형식으로 구성되고, COPY 문에 정의된 값은 COPY 문 다음에 올 NAME의 반복 횟수이다. 예로 NAME=(COPY=3, 필드NAME1)문의 의미는 NAME=(필드NAME1,필드NAME1,필드NAME1)과 동일하다.
사용방법은 다음과 같다.
-
필드NAME1
-
필드NAME1, 필드NAME2,….
-
필드NAME1, (COPY=2, 필드NAME2), 필드NAME3
-
필드NAME1, (COPY=2, 필드NAME2), 필드NAME3, (COPY=4, 필드NAME4)
EXIT
현재 지원하지 않는다.
-
-
END
END 명령문은 DSD 명령문과 한쌍을 이루며, 명령문의 끝을 의미한다.
END 명령문의 구문은 다음과 같다.
[label] END
4.3. 사용예제
다음은 2개의 CREATE 명령문을 사용하여 각각의 필드에 맞추어 OUTPUT DD에 저장하는 예이다.
첫 번째 CREATE 명령문은 총3개의 필드명(REC01NAME, REC01FD01, REC01FD02)을 가지고 1줄을 출력한다. 두 번째 CREATE 명령문은 총4개의 필드명(EC02NAME, REC02FD01, REC02FD02, REC02FD03)을 가지고 2줄을 출력한다.
//GENDAT0 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP1 EXEC PGM=JSDDG
//OUTPUT DD DSN=JSDDG.DATASET.OUT01,DISP=(NEW,CATLG,DELETE),
// DCB=(RECFM=VB,LRECL=32760)
//SYSIN DD DATA
DSD OUTPUT=(OUTPUT)
FD NAME=REC01NAME,LENGTH=12,PICTURE=12,'RECORD01 '
FD NAME=REC01FD01,LENGTH=7,PICTURE=7,'A000001',INDEX=1
FD NAME=REC01FD02,LENGTH=4993,FORMAT=AL,ACTION=TL
FD NAME=REC02NAME,LENGTH=12,PICTURE=12,'RECORD02 '
FD NAME=REC02FD01,LENGTH=7,PICTURE=7,'A000001',INDEX=1,CYCLE=2
FD NAME=REC02FD02,LENGTH=8,PICTURE=8,'AM000001',INDEX=1
FD NAME=REC02FD03,LENGTH=4985,FORMAT=AL
REPEAT QUANTITY=131072,CREATE=2
CREATE QUANTITY=1,NAME=(REC01NAME,REC01FD01,REC01FD02)
CREATE QUANTITY=2,NAME=(REC02NAME,REC02FD01,REC02FD02,REC02FD03)
END
/*
//SYSPRINT DD SYSOUT=*
다음은 앞의 예제에 대한 결과로 생성된 출력 데이터셋의 레코드로 총 레코드건수는 393,216건, 각 레코드의 길이는 5012 Byte이다.
RECORD01 A000001ABCDEFGHIJKLMNOPQRSTUVWXYZ... RECORD02 A000001AM000001ABCDEFGHIJKLMNOPQR... RECORD02 A000001AM000002ABCDEFGHIJKLMNOPQR... RECORD01 A000002 BCDEFGHIJKLMNOPQRSTUVWXYZ... RECORD02 A000002AM000003ABCDEFGHIJKLMNOPQR... RECORD02 A000002AM000004ABCDEFGHIJKLMNOPQR... RECORD01 A000003 CDEFGHIJKLMNOPQRSTUVWXYZ... RECORD02 A000003AM000005ABCDEFGHIJKLMNOPQR... RECORD02 A000003AM000006ABCDEFGHIJKLMNOPQR... RECORD01 A000004 DEFGHIJKLMNOPQRSTUVWXYZ... RECORD02 A000004AM000007ABCDEFGHIJKLMNOPQR... RECORD02 A000004AM000008ABCDEFGHIJKLMNOPQR... RECORD01 A000005 EFGHIJKLMNOPQRSTUVWXYZ... RECORD02 A000005AM000009ABCDEFGHIJKLMNOPQR... RECORD02 A000005AM000010ABCDEFGHIJKLMNOPQR... RECORD01 A000006 FGHIJKLMNOPQRSTUVWXYZ... RECORD02 A000006AM000011ABCDEFGHIJKLMNOPQR... RECORD02 A000006AM000012ABCDEFGHIJKLMNOPQR... RECORD01 A000007 GHIJKLMNOPQRSTUVWXYZ... RECORD02 A000007AM000013ABCDEFGHIJKLMNOPQR... RECORD02 A000007AM000013ABCDEFGHIJKLMNOPQR... ... RECORD01 A131071 ... RECORD02 A131071AM262141ABCDEFGHIJKLMNOPQR... RECORD02 A131071AM262142ABCDEFGHIJKLMNOPQR... RECORD01 A131072 ... RECORD02 A131072AM262143ABCDEFGHIJKLMNOPQR... RECORD02 A131072AM262144ABCDEFGHIJKLMNOPQR...
4.4. 유의사항
JSDDG 유틸리티 프로그램이 Batch 애플리케이션을 실행한 결과는 다음과 같다.
-
정상적으로 실행한 경우
Batch 애플리케이션에서 받은 코드를 반환한다.
-
에러가 발생한 경우
해당 에러 메시지를 SYSPRINT DD에 출력하고 에러에 해당하는 코드를 반환한다.
JSDDG 유틸리티 프로그램에서 발생할 수 있는 에러 코드는 다음과 같다.
코드 설명 08
제어문 처리 중 에러가 발생한 경우다.
진행 중인 데이터의 생성을 바로 중지하고, 다음 DSD 문을 처리한다.
12
입출력 데이터셋에 관한 처리 중 에러가 발생한 경우다. 유틸리티를 즉시 중지한다.
16
Unrecoverable 형태의 에러로 다음의 경우가 해당된다. 유틸리티를 즉시 중지한다.
-
SYSIN DD 명령어 문법 에러
-
OpenFrame 시스템 라이브러리 초기화 실패
-
기타 JSDDG 유틸리티 프로그램 에러
-
5. JSDGENER
순차 데이터셋 또는 PDS의 멤버를 복사하는 유틸리티 프로그램이다.
JSDGENER 유틸리티 프로그램으로 다음과 같은 기능을 수행할 수 있다.
-
순차 데이터셋이나 PDS의 멤버를 복사한다.
-
순차 데이터셋으로부터 PDS를 생성한다.
-
기존의 PDS에 멤버를 추가한다.
-
입력 레코드를 편집한다.
5.1. DD 설정
DD 설정 항목은 다음과 같다.
| 항목 | 설명 |
|---|---|
SYSPRINT DD |
JSDGENER의 메시지가 저장되는 데이터셋을 정의한다. |
SYSUT1 DD |
입력 데이터셋을 정의하며, 순차 데이터셋이나 PDS의 멤버가 될 수 있다. |
SYSUT2 DD |
출력 데이터셋을 정의하며, 순차 데이터셋이나 PDS의 멤버 또는 PDS가 될 수 있다. |
SYSIN DD |
JSDGENER의 명령어를 정의한다. |
5.2. 명령어 설정
JSDGENER 유틸리티가 제공하는 기능을 수행하기 위한 명령어를 SYSIN DD에 기술한다. SYSIN DD에 어떠한 명령어도 기술되지 않은 경우는 SYSUT1의 데이터셋을 SYSUT2의 데이터셋으로 복사하는 기능을 제공한다.
본 절에서는 SYSIN DD에서 설정하는 JSDGENER의 명령어에 대해서 설명한다.
-
GENERATE
MEMBER와 RECORD의 매개변수에 대한 설정을 한다. GENERATE 문의 구문은 다음과 같다.
[label] GENERATE [,MAXNAME=n] [,MAXFLDS=n] [,MAXGPS=n] [,MAXLITS=n]항목 설명 MAXNAME
최대 멤버 수를 지정한다. 1 ~ 3276개의 멤버를 지정할 수 있다.
MAXFLDS
레코드의 최대 필드 수를 지정한다. 1 ~ 4095개까지 지정할 수 있다.
MAXGPS
레코드의 최대 IDENT 개수를 지정한다. 1 ~ 2520개까지 지정할 수 있다.
MAXLITS
레코드의 필드에서 사용되는 리터럴의 최대 캐릭터 개수를 지정한다. 1 ~ 2730개까지 지정할 수 있다.
-
MEMBER
PDS의 여러 멤버를 가지고 출력 레코드가 생성될 경우, 생성할 멤버 개수만큼 MEMBER 문이 필요하다.
MEMBER 문의 구문은 다음과 같다.
[label] MEMBER NAME=(name[,alias1][,alias2][,...])
항목 설명 NAME
생성할 멤버의 이름을 기술한다.
|
현재 JSDGENER 유틸리티의 MEMBER 문 중 Alias는 실제 기능은 하지 않으나 에러를 발생시키지 않도록 지원하고 있다. |
-
RECORD
입력 레코드에 대해서 어떻게 처리할 것인지 조건을 기술한다.
RECORD 문의 구문은 다음과 같다.
[label] RECORD [IDENT=(length,'name',input-location)] [,FIELD=([length], [{input-location|'literal'}], [conversion], [output-location])] [,FIELD=...]항목 설명 IDENT
MEMBER 문이 RECORD 문 전에 나왔을 경우 그 멤버에 복사될 입력 레코드에 대한 조건을 나타내고 같은 레코드의 FIELD에 대해서 적용될 입력 레코드를 구별한다. 레코드의 input-location에서 length만큼의 값과 name 값을 비교하여 값이 같으면 멤버의 마지막 레코드가 되거나 FIELD가 적용되는 마지막 레코드가 된다.
-
length : name을 식별하기 위한 길이를 최대 8Bytes까지 지정할 수 있다.
-
'name' : 마지막 레코드를 식별하기 위한 값으로서 반드시 작은따옴표( ' ' ) 안에 기술되어야 한다.
-
Input-location : 입력 레코드에서 name 값과 비교할 FIELD의 첫 번째 시작 위치를 지정한다.
FIELD
레코드 편집을 위한 정보를 기술한다.
입력 레코드에서 input-location 위치부터 length만큼의 데이터를 출력 레코드의 output-location 위치에 쓰거나 리터럴을 length만큼 출력 레코드의 output-location 위치에 쓴다.
-
length : 처리되는 입력 필드의 길이 또는 리터럴의 길이를 기술한다.
-
input-location : 처리되는 필드의 시작위치를 지정한다.
-
'literal' : output-location에 위치해야 하는 리터럴을 지정한다.
-
conversion : 파라미터로 CG, CV, GC, GV, HE, PZ, VC, VG, ZP를 사용할 수 있으며, 현재는 ZP, PZ만 기능을 수행한다.
-
ZP : Zoned Decimal 값을 Packed Decimal로 변환한다.
-
PZ : Packed Decimal 값을 Zoned Decimal로 변환한다.
-
-
output-location : 출력 레코드에 쓰여질 시작 위치를 지정한다.
-
5.3. 사용예제
다음은 순차 데이터셋을 복사하는 예이다.
SYSIN DD에 명령어가 기술되어있지 않으므로 순차 데이터셋인 TEST.INPUT을 TEST.COPY로 복사하고, JSDGENER의 메시지는 JOB에서 사용하는 메시지 클래스에 저장한다.
//COPY JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //COPYSDS EXEC PGM=JSDGENER //SYSUT1 DD DSNAME=TEST.INPUT,DISP=(SHR,KEEP) //SYSUT2 DD DSNAME=TEST.COPY,DISP=(NEW,CATLG), // DCB=(RECFM=FB,LRECL=120 ,BLKSIZE=120) //SYSPRINT DD SYSOUT=* //SYSIN DD DUMMY
다음은 순차 데이터셋으로 새 멤버를 갖는 PDS를 구성하는 예이다.
순차 데이터셋인 TEST.INPUT을 MEMBER1, MEMBER2, MEMBER3으로 나누어 새로 생성한 PDS TEST.PDS01에 저장한다.
//CREATE JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//NEWPDS EXEC PGM=JSDGENER
//SYSUT1 DD DSNAME=TEST.INPUT,DISP=(SHR,KEEP)
//SYSUT2 DD DSNAME=TEST.PDS01,DISP=(NEW,CATLG),
// DCB=(DSORG=PO,RECFM=FB,LRECL=120,BLKSIZE=120)
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
GENERATE MAXNAME=3,MAXGPS=2
MEMBER NAME=MEMBER1
GROUP1 RECORD IDENT=(8,'firstxxx',30)
MEMBER NAME=MEMBER2
GROUP2 RECORD IDENT=(8,'secondxx',30)
MEMBER NAME=MEMBER3
/*
TEST.INPUT에서 입력 레코드의 30번째 위치부터 37번째까지의 값을 순차 검색하여 ‘firstxxx’인 레코드가 나타나면 ‘firstxxx’ 레코드를 포함하여 현재까지 검색된 레코드를 MEMBER1에 복사한다. 그리고 ‘firstxxx’ 레코드 다음 레코드부터 다시 ‘secondxx’ 레코드를 검색하기 시작한다.
‘secondxx’ 레코드가 검색되면 ‘firstxxx’ 레코드 이후부터 ‘secondxx’ 레코드를 포함하여 검색한 모든 레코드를 MEMBER2에 복사하고 ‘secondxx’ 레코드 이후의 모든 레코드는 MEMBER3에 복사된다.
다음은 기존의 PDS에 멤버를 추가하는 예이다.
//MERGE JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//MERGEPDS EXEC PGM=JSDGENER
//SYSUT1 DD DSNAME=TEST.INPUT2,DISP=(SHR,KEEP)
//SYSUT2 DD DSNAME=JSDGENER.TEST.PDS01,DISP=(OLD,KEEP)
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
GENERATE MAXNAME=2,MAXGPS=1
MEMBER NAME=MEMX
GROUP1 RECORD IDENT=(11,'endofrecord',15)
MEMBER NAME=MEMY
/*
순차 데이터셋인 TEST.INPUT2의 레코드에서 15번째 Byte부터 25번째 Byte까지 레코드의 값을 ‘endofrecord’와 비교하여 값이 일치하면 검색한 모든 레코드를 MEMX에 복사하고, ‘endofrecord’ 레코드 이후의 모든 레코드는 MEMY에 복사한다. 그리고 기존의 PDS TEST.PDS01에 PDS 멤버로 MEMX와 MEMY를 추가한다.
다음은 입력 레코드를 수정하는 예이다. TEST.INPUT3 레코드를 수정하여 TEST.EDIT0로 복사한다.
//EDIT JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//EDIT EXEC PGM=JSDGENER
//SYSUT1 DD DSNAME=TEST.INPUT3,DISP=(SHR,KEEP)
//SYSUT2 DD DSNAME=JSDGENER.TEST.EDIT01,DISP=(NEW,CATLG),
// DCB=(RECFM=FB,LRECL=80,BLKSIZE=80)
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
GENERATE MAXGPS=1,MAXFLDS=4,MAXLITS=10
RECORD IDENT=(8,'firstmem',1),FIELD=(50,76,,31),
FIELD=(30,20,,1)
RECORD FIELD=(70,41,,11),FIELD=(10,'**********',,1)
/*
앞의 예제에서 2개의 RECORD 문 중 첫 번째 RECORD의 IDENT 조건에 의해서 순차적으로 입력 레코드의 첫 번째 Byte부터 8Bytes의 값으로 'firstmem’이 나올 때까지 모든 레코드에 대해 FIELD 조건을 적용한다. 즉, 다음 그림과 같이 입력 레코드의 76번째 Byte 위치부터 50Bytes 길이만큼의 값을 출력 레코드의 31번째 Byte 위치에 복사하고 입력 레코드의 20번째 Byte 위치부터 30Bytes 길이의 값을 출력 레코드의 첫 번째 Byte 위치에 복사한다.
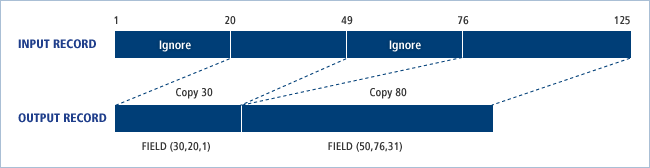
IDENT 조건에 맞는 레코드가 처리되고 난 다음부터는 두 번째 RECORD 문이 다음 그림과 같이 적용된다. 입력 레코드의 41번째 Byte 위치부터 70Bytes 길이만큼의 값을 출력 레코드의 11번째 Byte 위치에 복사하고 출력 레코드의 처음 10Bytes는 리터럴 ‘**********'로 복사한다.
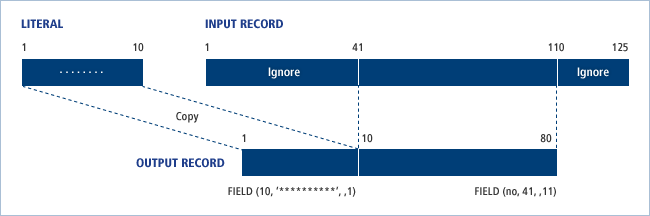
5.4. 유의사항
JSDGENER 유틸리티 프로그램이 Batch 애플리케이션을 실행한 결과는 다음과 같다.
-
정상적으로 실행한 경우
Batch 애플리케이션에서 받은 코드를 반환한다.
-
에러가 발생한 경우
해당 에러 메시지를 SYSPRINT DD에 출력하고 에러에 해당하는 코드를 반환한다.
JSDGENER 유틸리티 프로그램에서 발생할 수 있는 에러 코드는 다음과 같다.
코드 설명 12
Unrecoverable 형태의 에러로, 다음의 경우가 해당된다.
-
데이터셋 관련(pgmdd, open/close, read/write) 에러
-
SYSIN DD 명령어 문법 에러
-
기타 JSDGENER 유틸리티 프로그램 에러
16
시스템 에러와 관련된 에러로, 다음의 경우가 해당된다.
-
OpenFrame 시스템 라이브러리 초기화 실패
-
6. JSDPTPCH
순차 데이터셋이나 PDS의 전체 또는 일부를 실제 출력할 형식으로 데이터를 생성하는 유틸리티 프로그램이다.
JSDPTPCH 유틸리티 프로그램은 다음과 같은 경우에 사용될 수 있다.
-
순차 데이터셋 또는 PDS 전체를 프린트한다.
-
PDS의 특정 멤버를 프린트한다.
-
순차 데이터셋 또는 PDS의 레코드 필드를 편집하여 프린트한다.
6.1. DD 설정
DD 설정 항목은 다음과 같다.
| 항목 | 설명 |
|---|---|
SYSPRINT DD |
JSDPTPCH 메시지가 저장되는 데이터셋을 기술한다. |
SYSUT1 DD |
순차 데이터셋이나 PDS 타입의 입력 데이터셋을 기술한다. |
SYSUT2 DD |
순차 데이터셋 타입의 출력 데이터셋을 기술한다. |
SYSIN DD |
JSDPTPCH 명령어를 기술한다. |
6.2. 명령어 설정
본 절에서는 SYSIN DD에서 설정하는 JSDPTPCH의 명령어에 대해서 설명한다.
-
PRINT
데이터를 프린트한다. PRINT 문은 가장 처음에 기술해야 하는 명령어로 여러 번 반복해서 지정할 수 없다.
PRINT 명령어 형식은 다음과 같다.
[label] PRINT [PREFORM=A] [,TYPORG={PS|PO}] [,CNTRL={n|1}] [,STRTAFT=n] [,STOPAFT=n] [,SKIP=n] [,MAXNAME=n] [,MAXFLDS=n] [,MAXGPS=n] [,MAXLITS=n] [,MAXLINE=n] [,OUTODR= TTR | ODIR]항목 설명 PREFORM
각 레코드의 첫 번째 Byte가 제어 문자를 의미하는지 기술한다.
데이터가 이미 프린트될 포맷으로 갖추었고 그 형태로 프린트되어야 한다는 것을 의미한다. PREFORM이 기술되면 TYPORG를 제외한 추가적인 PRINT 문의 모든 파라미터 설정은 무시되나, 문법 요소 체크는 수행한다.
앞의 명령어에서 사용된 A는 ASA 제어 문자를 의미한다.
TYPORG
입력 데이터셋이 순차 데이터셋(PS)인지 분할 데이터셋(PO)인지 기술한다.
(기본값: PS)
CNTRL
라인 스페이스 값을 설정한다.
라인 스페이스로 3을 설정할 경우 첫 번째 라인에는 데이터를 쓰고, 두 번째와 세 번째 라인에는 공백 라인을 프린트한다. 이와 같은 순서로 다음 데이터도 프린트된다. 현재는 라인 스페이스 값을 3까지만 허용한다. 허용범위 이외의 값은 모두 1로 인식하여 처리하게 된다. (기본값: 1)
STRTAFT
순차 데이터셋을 프린트하기 전 스킵할 논리 레코드의 개수를 지정한다.
데이터셋의 n+1번째 논리 레코드부터 프린트된다. 레코드의 범위는 32767를 초과하지 않으며, 초과할 경우 레코드가 있는 만큼만 처리하게 된다.
STOPAFT
프린트되어야 할 순차 데이터셋의 논리 레코드 개수를 지정한다.
최대 32767개의 논리 레코드를 설정할 수 있다.
만일 STOPAFT 문과 RECORD 문의 IDENT가 함께 기술되었다면 STOPAFT에 설정된 값을 만족하거나 IDENT에 의해 구분되는 레코드 그룹의 마지막일 때, 둘 중 먼저 해당되는 쪽이 나타났을 때, 현재 입력 데이터셋의 데이터 처리를 위한 명령어 수행이 종료된다.
SKIP
n번째 레코드마다 프린트되어야 함을 의미한다. (기본값: 1)
MAXNAME
MEMBER 문의 최대 멤버 개수를 지정한다. MEMBER 명령어가 있을경우 반드시 명시해야 한다. 설정값은 32767을 넘을 수 없다.
MAXFLDS
RECORD 문의 최대 FIELD 파라미터 개수를 지정한다. 설정값은 32767을 넘을 수 없다. (기본값: 20)
MAXGPS
최대 IDENT 파라미터 개수를 지정한다. 설정값은 32767을 넘을 수 없다.
(기본값: 20)
MAXLITS
RECORD 문의 IDENT 파라미터에 포함될 최대 리터럴 개수를 지정한다. 설정값은 32767을 넘을 수 없다. (기본값: 20)
MAXLINE
출력될 페이지의 최대 라인 수를 지정한다. (기본값: 60)
OUTODR
현재 파싱만 지원한다.
-
TITLE
출력되어야 할 타이틀이나 서브 타이틀을 기술한다.
JSDPTPCH에서는 TITLE 문에서 두 개의 ITEM을 기술할 수 있다. 첫 번째 ITEM 문은 타이틀을 두 번째 ITEM 문은 서브 타이틀을 정의한다. 기술된 타이틀과 서브 타이틀은 매 페이지마다 출력된다.
TITLE 명령어 구문은 다음과 같다.
[label] TITLE ITEM=('title'[,output-location]) [,ITEM=...]항목 설명 ITEM
title과 output-location은 다음과 같이 설정한다.
-
title : 타이틀이나 서브 타이틀에 대한 리터럴을 기술한다. 최대 40Bytes까지 지정할 수 있다.
-
output-location : 출력 레코드 상에서 ITEM의 리터럴이 놓여져야 할 위치를 지정한다.
-
-
MEMBER
입력 데이터셋이 PDS일 경우 특정 멤버의 데이터만 처리하고자 할 때 사용한다. MEMBER문을 사용하기 위해서는 PRINT 문의 MAXNAME을 설정해야 한다.
MEMBER 명령어 구문은 다음과 같다.
[label] MEMBER NAME=membername
항목 설명 NAME
PDS에서 프린트되어야 할 멤버 이름을 기술한다.
-
RECORD
프린트되어야 할 레코드의 그룹을 정의한다.
RECORD 명령어 구문은 다음과 같다.
[label] RECORD [IDENT=(length,'name',input-location)] [,FIELD=(length,[input-location],[conversion] [output-location])] [,FIELD=…]항목 설명 IDENT
레코드 그룹의 마지막 레코드를 식별한다. 레코드의 input-location에서 length만큼의 값과 name 값을 비교하여 값이 같으면 멤버의 마지막 레코드가 되거나 FIELD가 적용되는 마지막 레코드가 된다.
IDENT를 사용하기 위해서는 PRINT 문의 MAXGPS와 MAXLITS가 기술되어 있어야 한다.
-
length : 마지막 레코드를 식별하기 위한 길이를 지정한다. 최대 8Bytes까지 지정할 수 있다.
-
'name' : 마지막 레코드를 식별하기 위한 값으로 반드시 작은따옴표(‘ ‘) 안에 기술되어야 한다.
-
input-location : 입력 레코드에서 name 값과 처리할 데이터의 마지막 레코드를 식별할 필드의 첫 번째 시작위치를 지정한다.
FIELD
레코드 편집을 위한 정보를 기술한다.
입력 레코드 상에서 input-location 위치부터 length만큼의 데이터를 출력 레코드의 output-location 위치에 쓰거나 리터럴을 length만큼 출력 레코드의 output-location 위치에 쓴다.
FIELD를 사용하기 위해서는 PRINT 문의 MAXFLDS가 기술되어 있어야 한다.
-
length : 편집되어 처리되는 입력 필드의 길이 또는 리터럴의 길이를 기술한다.
-
input-location : 처리되는 필드의 시작위치를 기술한다.
-
output-location : 출력 레코드에 기록될 시작위치를 지정한다.
CONVERSION
레코드의 변환을 위한 정보를 기술한다. CV, PZ, VC, XE의 4가지 파라미터 값을 사용할 수 있다.
-
CV : SOSI 변환 없이 출력한다.
-
PZ : Packed 10진 데이터를 Zoned 10진 데이터로 변경하려 출력한다.
-
VC : 필드 선두에 0E, 후미에 0F를 추가해 출력한다.
-
XE : 16진 데이터로 변환하여 출력한다.
-
6.3. 사용예제
다음은 특정 멤버만 선택하여 지정한 프린트 형식으로 데이터를 출력하는 예이다. TEST.INPUT01의 멤버 중 MEMBER2의 레코드가 순차적으로 SYSUT2에 정의된 SYSOUT으로 출력된다. 만일 MEMBER2의 레코드의 21번째 Byte부터 8Bytes의 값이 'ENDRECORD’이면 이 레코드까지만 출력한다. 이 SYSOUT은 JOB이 종료된 후 OUTPUT PROCESSING을 통해 프린터기에서 프린트되며 이 데이터는 한 페이지에 30 라인씩 프린트된다.
//TEST JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//NEWPDS EXEC PGM=JSDPTPCH
//SYSUT1 DD DSNAME=TEST.INPUT01,DISP=(SHR,CATLG)
//SYSUT2 DD SYSOUT=A
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
PRINT TYPORG=PO,CNTRL=1,MAXLINE=30,MAXNAME=1,MAXLITS=10,MAXGPS=3
MEMBER NAME=MEMBER2
RECORD IDENT=(8,'ENDRECORD',21)
/*
6.4. 유의사항
JSDPTPCH 유틸리티 프로그램이 Batch 애플리케이션을 실행한 결과는 다음과 같다.
-
정상적으로 실행한 경우
Batch 애플리케이션에서 받은 코드를 반환한다.
-
에러가 발생한 경우
해당 에러 메시지를 SYSPRINT DD에 출력하고 에러에 해당하는 코드를 반환한다.
JSDPTPCH 유틸리티 프로그램에서 발생할 수 있는 에러 코드는 다음과 같다.
코드 설명 12
Unrecoverable 형태의 에러로 다음의 경우가 해당된다.
-
데이터셋 관련 (pgmdd, open/close, read/write) 에러
-
SYSIN DD 명령어 문법 에러
-
기타 JSDPTPCH 유틸리티 프로그램 에러
16
시스템 에러와 관련된 에러로 다음의 경우가 해당된다.
-
OpenFrame 시스템 라이브러리 초기화 실패
-
7. JSECOPY
1개 이상의 PDS에 대해서 멤버들을 전체 또는 일부만 복사하거나 병합하는 유틸리티 프로그램이다.
JSECOPY 유틸리티 프로그램으로 다음과 같은 기능을 수행할 수 있다.
-
PDS에 대해 복사 또는 병합 기능을 수행한다.
-
PDS의 특정 멤버만 선택해서 복사하고, 선택된 멤버 이름을 재정의한다.
-
PDS의 특정 멤버만 제외하고 복사한다.
-
PDS 멤버를 교체한다.
7.1. DD 설정
DD 설정 항목은 다음과 같다.
| 항목 | 설명 |
|---|---|
SYSPRINT DD |
JSECOPY 메시지를 저장하는 데이터셋을 정의한다. |
SYSUT1 DD 또는 user_defined_name1 DD |
PDS 타입의 입력 데이터셋을 정의한다. |
SYSUT2 DD 또는 user_defined_name2 DD |
PDS 타입의 출력 데이터셋을 정의한다. |
SYSIN DD |
JSECOPY 명령어를 정의한다. |
7.2. 명령어 설정
JSECOPY에서는 2가지 방법으로 명령어를 설정할 수 있다. JCL의 EXEC 문의 PARM 파라미터를 이용하여 명령어를 기술하거나 JCL의 SYSIN 문에 명령어를 기술할 수 있다.
[참고]
다음과 같은 명령어 약자를 사용할 수 있다.
| 명령어 | 약어 |
|---|---|
COPY |
C |
EXCLUDE |
E |
SELECT |
S |
OUTDD |
O |
INDD |
I |
LIST |
L |
MEMBER |
M |
-
EXEC 문 PARM 파라미터 설정
EXEC 문의 PARM 파라미터 명령어 구문은 다음과 같다.
//[stepname] EXEC PGM=JSECOPY[,PARM=<parms>]
PARM 파라미터의 parms 값으로 다음 3가지 중 하나의 명령어를 설정한다.
명령어 설명 COPY
SYSUT1 데이터셋을 SYSUT2 데이터셋으로 복사한다.
REPLACE
출력 데이터셋에 있는 멤버와 같은 이름으로 복사할 경우 이 명령어가 있으면 오버라이드하고 그렇지 않으면 복사하지 않는다.
LIST
복사된 멤버들의 이름을 SYSPRINT에 기록한다. (기본값: YES)
EXEC 문의 PARM 파라미터에 COPY나 REPLACE를 설정하면 SYSIN DD에 설정한 명령어는 무시된다.
-
COPY
PDS의 멤버를 복사한다. SYSIN DD의 COPY 명령어 구문은 다음과 같다.
[label] COPY OUTDD=DDNAME, INDD=[(]{DDNAME|(DDNAME,R)}[,...][)] [,LIST={YES|NO}]항목 설명 OUTDD
출력 데이터셋을 위한 DD 이름을 기술한다.
INDD
입력 데이터셋을 위한 DD 이름을 기술한다.
출력 데이터셋에 복사하려는 멤버가 이미 존재하고 있는 경우 R(REPLACE) 파라미터가 있으면 오버라이드하고 없으면 복사하지 않는다.
LIST
SYSPRINT에 복사한 멤버들의 이름을 기록하고 기본값은 YES이다. 만약 LIST가 기술되지 않으면 EXEC PARM의 내용이 적용된다.
-
INDD
COPY 문 다음에 설정하며, 설정한 순서로 입력 데이터셋을 출력 데이터셋으로 새로운 COPY 작업을 수행한다. COPY 문의 서브 명령어로 쓰이는 INDD에 대해서는 여러 개의 입력 데이터셋에 대하여 각각 EXCLUDE 문이나 SELECT 문을 적용하기 어렵지만, INDD 문을 사용하면 여러 개의 입력 데이터셋에 대하여 각각 EXCLUDE 문과 SELECT 문을 사용할 수 있다.
-
EXCLUDE
EXCLUDE 문은 COPY 문 다음에 설정하며, COPY 문을 수행할 때 입력 데이터셋에서 특정 멤버를 제외한다. 이 구문은 아래 나오는 SELECT 문과 함께 사용할 수 없다. EXCLUDE 문과 SELECT 문 모두 지정하지 않으면, 데이터셋 전체에 대한 COPY 작업을 수행한다.
EXCLUDE 문의 구문은 다음과 같다.
[label] EXCLUDE MEMBER=[(] name1[,name2][,...][)]
항목 설명 MEMBER
복사하지 않을 멤버의 이름을 기술한다. 해당 멤버들은 COPY 문을 수행할 때 복사 대상에서 제외된다.
-
SELECT
SELECT 문은 COPY 문 다음에 설정하며, 입력 데이터셋의 특정 멤버를 선택하여 새로운 이름으로 COPY 작업을 수행한다.
SELECT 문의 구문은 다음과 같다.
[label] SELECT MEMBER=({name1|(name1,newname1[,R])|(name1,,R)} [,{name2|(name2,newname2[,R])|(name2,,R)}][,...])항목 설명 MEMBER
name 필드에 기술한 입력 데이터셋의 멤버를 newname 필드에서 지정한 새로운 이름으로 복사한다. newname 필드를 지정하지 않은 경우 name 필드에 기술한 멤버명과 동일한 이름을 사용한다.
R(REPLACE) 파라미터를 선택하면 입력 데이터셋의 멤버 이름과 출력 데이터셋의 멤버 이름이 같을 경우 입력 데이터셋의 멤버를 출력 데이터셋의 멤버로 오버라이드한다.
7.3. 사용예제
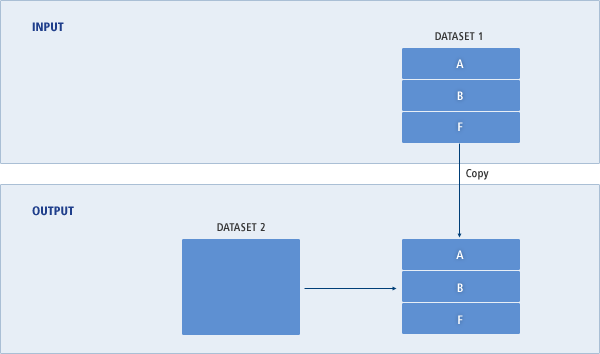
다음은 PDS DATASET1을 PDS DATASET2로 전체 데이터셋을 복사하는 예이다.
//COPYALL JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //JOBSTEP EXEC PGM=JSECOPY //SYSPRINT DD SYSOUT=A //SYSUT1 DD DSNAME=DATASET1,DISP=(SHR,KEEP) //SYSUT2 DD DSNAME=DATASET2,UNIT=disk,VOL=SER=200000, // DISP=(NEW,CATLG) //SYSIN DD DUMMY
다음처럼 DATASET1의 모든 멤버 A, B, F가 PDS DATASET2로 모두 복사된다.
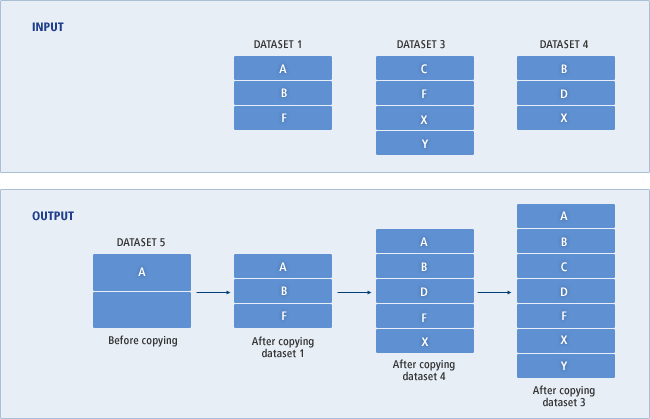
다음은 4개의 데이터셋을 병합하는 예이다. 이미 존재하고 있는 데이터셋 DATASET5에 DATASET1, DATASET3, DATASET4의 멤버가 복사되어 병합된다. SYSIN DD의 명령어 INDD 순서에 따라 DATASET1이 먼저 복사되고, DATASET4, DATASET3의 순서로 복사된다.
//MERGE JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JOBSTEP EXEC PGM=JSECOPY
//SYSPRINT DD SYSOUT=A
//IN01 DD DSNAME=DATASET1,DISP=(SHR,KEEP)
//IN02 DD DSNAME=DATASET3,DISP=(SHR,KEEP)
//OUT01 DD DSNAME=DATASET5,DISP=(SHR,KEEP)
//IN03 DD DSNAME=DATASET4,DISP=(SHR,KEEP)
//SYSIN DD *
COPYOPER COPY OUTDD=OUT01
INDD=IN01
INDD=IN03
INDD=IN02
/*
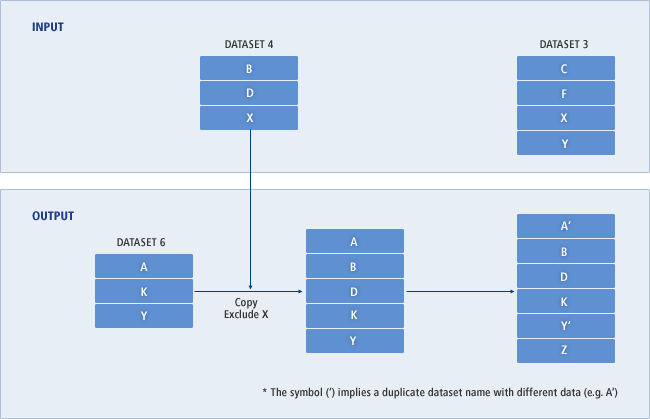
JSECOPY가 시작되기 전 DATASET5에는 A라는 멤버가 존재하고 있다. DATASET1이 최초로 복사되는데 A라는 멤버는 이미 OUTPUT에 있고, REPLACE 조건이 없으므로 A는 복사되지 않고 B와 F만 복사된다. 다음으로 DATASET4가 복사되는데 멤버 B 역시 이미 OUTPUT에 있으므로 복사되지 않고 멤버 D와 X만 복사된다. 마지막으로 DATASET3이 복사된다. 멤버 F와 X가 이미 OUTPUT에 있으므로 복사되지 않고 멤버 C와 Y만 복사된다.
다음 그림은 위의 예제를 실행하면서 출력 데이터셋에 멤버가 복사되는 과정과 최종 복사된 멤버를 보여준다.
다음은 입력 데이터셋에서 특정 멤버를 선택하거나 제외하여 복사하는 예이다.
MERGE EXEC PGM=JSECOPY
//IN01 DD DSNAME=DATASET4,DISP=(SHR,KEEP)
//IN02 DD DSNAME=DATASET3,DISP=(SHR,KEEP)
//OUT01 DD DSNAME=DATASET6,DISP=(OLD,KEEP)
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
COPYOPER COPY OUTDD=OUT01
INDD=IN01
EXCLUDE MEMBER=X
INDD=IN02
SELECT MEMBER=((F,Z),(C,A,R),(Y,,R))
/*
JSECOPY가 실행되기 전에 DATASET6에는 멤버 A, K, Y가 있다. INDD=IN01에 의해 먼저 DATASET4가 복사되는데, EXCLUDE문에 의해 멤버 X는 제외하고, 멤버 B와 D가 복사된다. INDD=IN02에 의해 DATASET3이 복사된다. SELECT 문에 의해 멤버 F가 새로운 이름 Z로 복사되고, 멤버 C가 새로운 이름 A로 복사된다. 이때 DATASET6에 이미 멤버 A가 있으므로 내용을 오버라이드한다. 만약 REPLACE가 지정되지 않았다면, 복사하지 않고 다음 처리로 넘어간다. 마지막으로 멤버 Y가 기존 멤버 Y를 오버라이드한다.
다음 그림은 앞의 예제를 실행하면서 출력 데이터셋에 멤버가 복사되는 과정과 최종 복사된 멤버를 보여준다.
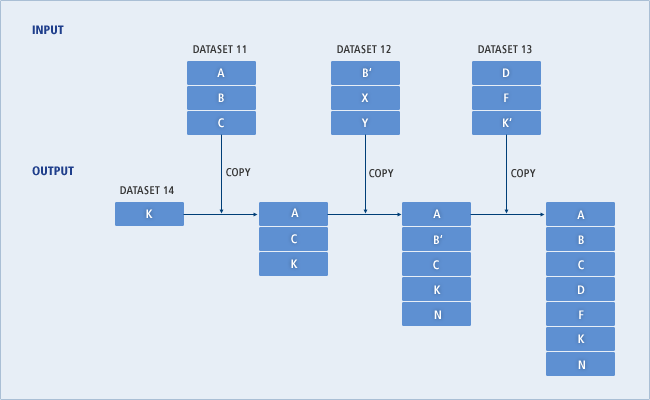
다음은 INDD 문을 사용하여 여러 개의 INPUT을 다르게 처리하는 경우의 예이다.
//INDD01 EXEC PGM=JSECOPY
//IN01 DD DSNAME=DATASET11,DISP=(SHR,KEEP)
//IN02 DD DSNAME=DATASET12,DISP=(SHR,KEEP)
//IN03 DD DSNAME=DATASET13,DISP=(SHR,KEEP)
//OUT01 DD DSNAME=DATASET14,DISP=(OLD,KEEP)
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
COPYOPER COPY OUTDD=OUT01
INDD=IN01
EXCLUDE MEMBER=B
INDD=IN02
SELECT MEMBER=((B,,R),(Y,N))
INDD=IN03
/*
IN01 DD에 정의된 데이터셋 DATASET11로부터 멤버 B를 제외한 다른 멤버 A와 C를 복사한다. IN02 DD에 정의된 데이터셋 DATASET12로부터 멤버 B를 교체하고, 멤버 Y의 이름을 바꾸어 N으로 복사한다. IN03 DD에 정의된 데이터셋 DATASET13으로부터 전체 멤버를 복사한다. 단, 같은 이름의 멤버가 이미 존재할 경우 교체하지 않는다.
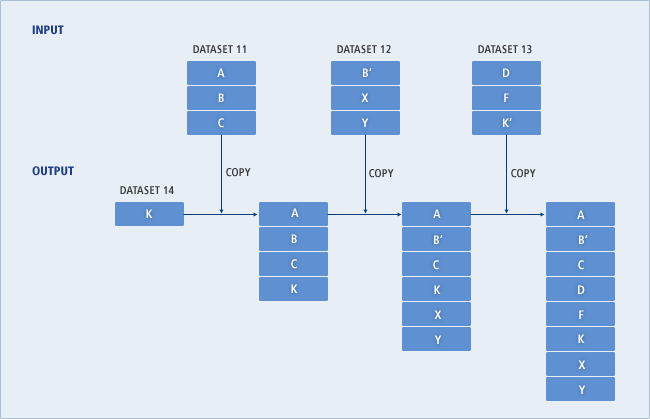
다음은 COPY 문의 서브 명령어로 INDD를 사용하는 경우의 예이다.
//INDD02 EXEC PGM=JSECOPY //IN01 DD DSNAME=DATASET11,DISP=(SHR,KEEP) //IN02 DD DSNAME=DATASET12,DISP=(SHR,KEEP) //IN03 DD DSNAME=DATASET13,DISP=(SHR,KEEP) //OUT01 DD DSNAME=DATASET14,DISP=(OLD,KEEP) //SYSPRINT DD SYSOUT=* //SYSIN DD * COPYOPER COPY OUTDD=OUT01,INDD=(INO1,(IN02,R),IN03) /*
IN01 DD에 정의된 데이터셋 DATASET11로부터 전체 멤버를 복사한다. 단, 같은 이름의 멤버가 이미 존재할 경우 교체하지 않는다. IN02 DD에 정의된 데이터셋 DATASET12로부터 전체 멤버를 복사한다. 멤버 B는 교체된다. IN03 DD에 정의된 데이터셋 DATASET13으로부터 전체 멤버를 복사한다. 같은 이름의 멤버가 이미 존재할 경우 교체하지 않는다.
7.4. 유의사항
JSECOPY 유틸리티 프로그램이 Batch 애플리케이션을 실행한 결과는 다음과 같다.
-
정상적으로 실행한 경우
Batch 애플리케이션에서 받은 코드를 반환한다.
-
에러가 발생한 경우
해당 에러 메시지를 SYSPRINT DD에 출력하고 에러에 해당하는 코드를 반환한다.
JSECOPY 유틸리티 프로그램에서 발생할 수 있는 에러 코드는 다음과 같다.
코드 설명 12
Unrecoverable 형태의 에러로 다음의 경우가 해당된다.
-
데이터셋 관련 (pgmdd, open/close, read/write) 에러
-
SYSIN DD 명령어 문법 에러
-
기타 JSECOPY 유틸리티 프로그램 에러
16
시스템 에러와 관련된 에러로 다음의 경우가 해당된다.
-
OpenFrame 시스템 라이브러리 초기화 실패
-
8. JSGLIST
PDS의 데이터셋 정보와 멤버 리스트 또는 볼륨 정보와 볼륨에 포함된 데이터셋 리스트를 제공하는 유틸리티 프로그램이다.
JSGLIST 유틸리티 프로그램으로 다음과 같은 기능을 수행할 수 있다.
-
PDS 정보와 PDS 멤버 리스트를 확인한다.
-
볼륨의 디스크 정보와 데이터셋 리스트를 확인한다.
8.1. DD 설정
DD 설정 항목은 다음과 같다.
| 항목 | 설명 |
|---|---|
SYSPRINT DD |
JSGLIST 메시지가 저장되는 데이터셋을 정의한다. |
SYSIN DD |
JSGLIST의 명령어를 정의한다. |
8.2. 명령어 설정
본 절에서는 SYSIN DD에서 설정하는 JSGLIST의 명령어에 대해서 설명한다.
-
LISTPDS
PDS 정보와 멤버 리스트를 보여준다. LISTPDS 명령어 구문은 다음과 같다.
[label] LISTPDS DDNAME=(ddname[,ddname[,...]]) | DSNAME=(name[,name[,...]]) [,VOL=anyname=serial] [, DUMP | FORMAT ]항목 설명 DDNAME
리스트해야 할 PDS의 데이터셋을 정의한 DD명을 지정한다.
최대 55개의 DD명을 지정할 수 있다. DD명이 1개일 경우는 괄호를 생략해도 괜찮다. VOL 파라미터와 함께 사용할 수 없다.
DSNAME
PDS의 데이터셋 이름을 지정한다. 최대 10개의 데이터셋 이름을 지정할 수 있다.
VOL
DSNAME에 기술한 데이터셋에 포함된 볼륨 시리얼(볼륨명)을 기술한다.
anyname에 볼륨의 디바이스명을 지정하거나 원하는 이름으로 지정한다. 설정한 anyname은 문법을 맞추기 위한 것으로 실제로는 무시된다.
DUMP | FORMAT
출력 형식을 지정한다. 설정 정보에 따른 출력 정보는 예제를 참고한다.
-
DUMP : 멤버명, 데이터 크기, 최근 수정 날짜, 생성 날짜, 레코드 포맷, 블록 크기, 레코드 길이를 표 형태로 출력한다.
-
FORMAT : 멤버명, 데이터 크기, 최근 수정 날짜, 생성날짜, 레코드 포맷, 블록 크기, 레코드 길이를 항목별로 출력한다.
다음은 출력 형식별 출력 정보 예제이다.
-
DUMP
***** DIRECTORY INFORMATION ON VOL 100000 ***** DSNAME ----- SYS1.JCLLIB MEMBER DATASIZE LAST-UPDATE LAST-UPDATE CREATE DATASET RECORD BLOCK RECORD DATE TIME DATE ORGANIZATION FORMAT SIZE LENGTH (*ALIAS) 182739 357 20190904 152901 20191015 PO FB 4096 80 191727 68 20190904 152901 20191015 PO FB 4096 80 ... -
FORMAT
------------------------------------------------------------------------------ MEMBER NAME : 182739 DATASIZE : 357 LAST UPDATE DATE(TIME) : 20190904(152901) CREATE DATE : 20191015 RECORD FORMAT : FB BLOCK SIZE : 4096 RECORD LENGTH : 80 ...
-
-
LISTVTOC
주어진 볼륨에 해당하는 디스크 정보와 데이터셋 리스트를 보여준다.
LISTVTOC 명령어 구문은 다음과 같다.
[label] LISTVTOC [,VOL=anyname=serial] [,DSNAME=(name[,name[,...]])] [,SORT]항목 설명 VOL
조회하고자 하는 볼륨 시리얼을 기술한다.
anyname에 볼륨의 디바이스명을 지정하거나 원하는 이름으로 지정한다. 설정한 anyname은 문법을 맞추기 위한 것으로 실제로는 무시된다.
DSNAME
데이터셋 리스트에 포함할 데이터셋 이름을 기술한다.
최대 10개의 데이터셋 이름을 지정할 수 있다.
DSNAME 파라미터가 없으면 조회하려는 볼륨에 있는 모든 데이터셋 리스트가 조회된다.
SORT
데이터셋 이름의 EBCDIC 순서에 따라 리스트가 출력된다.
DSNAME 파라미터와 함께 지정할 수 없다.
8.3. 사용예제
다음은 DDNAME을 이용하여 PDS 정보와 멤버 리스트를 확인하는 예이다.
TEST DD에서 지정한 PDS DATASET의 정보와 멤버 리스트를 FORMAT 형식으로 SYSPRINT에 기록한다.
//LISTPDS JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP01 EXEC PGM=JSGLIST
//SYSPRINT DD SYSOUT=*
//TEST DD DSNAME=TESTDATA,DISP=OLD
//SYSIN DD *
LISTPDS DDNAME=TEST,FORMAT
/*
다음은 PDS 정보와 멤버 리스트를 확인하는 예이다.
PDS DATASET1과 DATASET2의 정보와 멤버 리스트를 SYSPRINT에 기록한다.
//LISTPDS JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1),
//STEP01 EXEC PGM=JSGLIST
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
LISTPDS DSNAME=(DATASET1,DATASET2),VOL=disk=100000
/*
다음은 볼륨의 디스크 정보와 데이터셋 리스트를 확인하는 예이다.
볼륨 시리얼이 100000인 볼륨에 대한 디스크 정보와 데이터셋 리스트를 SYSPRINT에 기록한다.
//LISTVOL JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP01 EXEC PGM=JSGLIST
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
LISTVTOC VOL=disk=100000
/*
8.4. 유의사항
JSGLIST 유틸리티 프로그램이 Batch 애플리케이션을 실행한 결과는 다음과 같다.
-
정상적으로 실행한 경우
Batch 애플리케이션에서 받은 코드를 반환한다.
-
에러가 발생한 경우
해당 에러 메시지를 SYSPRINT DD에 출력하고 에러에 해당하는 코드를 반환한다.
JSGLIST 유틸리티 프로그램에서 발생할 수 있는 에러 코드는 다음과 같다.
코드 설명 12
Unrecoverable 형태의 에러로 다음의 경우가 해당된다.
-
데이터셋 관련 (pgmdd, open/close, read/write) 에러
-
SYSIN DD 명령어 문법 에러
-
기타 JSGLIST 유틸리티 프로그램 에러
16
시스템 에러와 관련된 에러로 다음의 경우가 해당된다.
-
OpenFrame 시스템 라이브러리 초기화 실패
-
9. JSGMOVE
Non-VSAM 데이터셋을 명령어에서 지정한 볼륨으로 이동 또는 복사하는 유틸리티 프로그램이다.
JSGMOVE 시스템 유틸리티 프로그램으로 다음과 같은 기능을 수행할 수 있다.
-
SDS, PDS 데이터셋을 동일한 볼륨이나 다른 볼륨으로 이동 또는 복사한다.
-
볼륨 내에 존재하는 모든 데이터셋들을 다른 볼륨으로 이동 또는 복사한다.
-
데이터셋의 일부 이름을 지정하여 해당 조건에 해당하는 데이터셋들을 처리한다.
-
PDS의 특정 멤버를 처리 대상에서 추가 또는 배제하거나 멤버명을 변경하여 처리한다.
|
카탈로그에 등록된 데이터셋을 동일한 볼륨에서 이동 또는 복사하려는 경우에는 반드시 데이터셋 이름을 변경해야 한다. |
JSGMOVE는 2가지 종류의 명령어로 분류된다.
-
기능 명령어
실제로 사용자가 수행하려는 특정 작업을 나타내는 명령어이다.
명령어 설명 데이터셋을 이동(복사)한다.
데이터셋 그룹을 이동(복사)한다.
PDS 데이터셋을 이동(복사)한다.
볼륨 내에 존재하는 모든 데이터셋을 이동(복사)한다.
-
보조 명령어
기능 명령어 중 MOVE(COPY) PDS 명령어의 경우 다음의 보조 명령어를 함께 사용할 수 있다.
명령어 설명 처리 대상 PDS 데이터셋과 멤버를 추가한다.
처리 대상 PDS 데이터셋과 멤버에서 제외시킨다.
PDS 멤버의 교체를 지정한다.
처리 대상 PDS 멤버를 선택하여 지정한다.
9.1. DD 설정
DD 설정 항목은 다음과 같다.
| 항목 | 설명 |
|---|---|
SYSPRINT DD |
JSGMOVE의 메시지가 저장되는 데이터셋을 지정한다. |
SYSIN DD |
JSGMOVE에서 사용하는 명령어를 기술한다. |
9.2. 기능 명령어
본 절에서는 JSGMOVE의 기능 명령어에 대해서 설명한다.
-
MOVE(COPY) DSNAME
데이터셋의 이동 또는 복사를 지정하는 명령어이다.
MOVE(COPY) DSNAME 명령어 구문은 다음과 같다.
[label] {MOVE|COPY} DSN[AME]=name ,TO=device=volser [,FROM=device=volser] [,UNCATLG] [,CATLG] [,RENAME=name] [,FROMDD=dd-name] [,TODD=dd-name] [,UNLOAD] [,COPYAUTH]항목 설명 DSNAME=name
이동 또는 복사할 데이터셋 이름을 지정한다.
TO=device=volser
이동 또는 복사할 데이터셋의 출력 디바이스 이름과 볼륨을 지정한다.
device는 볼륨의 디바이스 이름을 지정하게 되나 문법을 맞추기 위한 것으로 실제로는 무시된다.
FROM=device=volser
이동 또는 복사할 원본 데이터셋이 존재하는 볼륨을 지정한다.
device는 볼륨의 디바이스 이름을 지정하게 되나 문법을 맞추기 위한 것으로 실제로는 무시된다.
MOVE 명령에서 FROM을 지정하게 되면 원본 데이터셋의 카탈로그 정보를 삭제하지 않고 출력 데이터셋은 카탈로그하지 않는다. 따라서 입력 데이터셋이 카탈로그되어 있으면 FROM은 지정하지 않는 것이 좋다.
UNCATLG
이동 또는 복사 처리 후 데이터셋 카탈로그 정보의 삭제를 지정한다. 원본 데이터셋이 카탈로그 되어 있지 않을 때는 지정하지 않도록 한다.
기본적으로 입력 데이터셋의 카탈로그 정보는 삭제되나 복사한 데이터셋의 카탈로그 삭제 방법은 명령어별로 다음과 같은 차이가 있다.
-
MOVE의 경우 복사한 데이터셋은 카탈로그하지 않는다.
-
COPY의 경우 복사 한 데이터셋의 카탈로그는 CATLG 명령의 지정에 따른다.
-
FROM 명령이 지정되면 UNCATLG는 무시 처리된다.
CATLG
COPY 명령을 기술한 경우에만 효력이 발생하며 복사한 데이터셋을 카탈로그에 등록한다.
RENAME과 FROM 지정을 생략한 경우 복사한 데이터셋을 카탈로그시키기 위하여 원본 데이터셋은 카탈로그에서 삭제한다.
RENAME=name
출력 데이터셋의 새로운 이름을 지정한다.
동일한 볼륨 내에서 이동 또는 복사하는 경우 RENAME을 반드시 지정해야 한다.
FROMDD=dd-name
DCB 정보와 LABEL 정보를 주는 DD 문의 DD 이름을 지정하는 항목이다.
(미지원 기능)
TODD=dd-name
DCB 정보와 LABEL 정보를 주는 DD 문의 DD 이름을 지정하는 항목이다.
(미지원 기능)
UNLOAD
입력 데이터셋을 언로드 형식으로 변환해 이동, 복사하는 것을 지정하는 항목이다. (미지원 기능)
COPYAUTH
출력 데이터셋의 권한정보를 입력 데이터셋의 권한정보와 같게 만들 때 지정하는 항목이다. ( 미지원 기능)
-
-
MOVE(COPY) DSGROUP
데이터셋 이름의 시작부터 특정위치까지의 일부 이름을 기술하여 해당 조건에 맞는 모든 데이터셋들의 이동 또는 복사를 지정하는 명령어이다.
MOVE(COPY) DSGROUPNAME 명령어 구문은 다음과 같다.
[label] {MOVE|COPY} DSGROUP=name ,TO=device=volser [,PASSWORD] [,UNCATLG] [,CATLG] [,TODD=dd-name] [,UNLOAD]항목 설명 DSGROUP=name
이동 또는 복사할 데이터셋의 일부 이름을 지정한다.
예를 들어 DSGROUP을 TEST라고 지정한 경우 TEST.PDS, TEST.SDS.A01과 같은 점(.)으로 구분된 첫 이름이 TEST로 시작되는 모든 데이터셋들을 선택하여 처리한다. 만약 데이터셋의 전체 이름을 기술한 경우는 그 데이터셋만 처리한다.
TO=device=volser
이동 또는 복사할 데이터셋의 출력 디바이스 이름과 볼륨을 지정한다.
device는 볼륨의 디바이스 이름을 지정하게 되나 문법을 맞추기 위한 것으로 실제로는 무시된다.
PASSWORD
OpenFrame에서는 미지원하는 기능으로 지정하더라도 무시된다.
원래는 작업 대상 데이터셋이 비밀번호로 관리되는 경우 해당 데이터셋의 이동, 복사를 지정한다.
UNCATLG
이동 또는 복사 처리 후 데이터셋 카탈로그 정보의 삭제를 지정한다. 원본 데이터셋이 카탈로그 되어 있지 않을 때는 지정하지 않도록 한다.
기본적으로 입력 데이터셋의 카탈로그 정보는 삭제되나 복사한 데이터셋의 카탈로그 삭제 방법은 명령어별로 다음과 같은 차이가 있다.
-
MOVE의 경우 복사한 데이터셋은 카탈로그하지 않는다.
-
COPY의 경우 복사한 데이터셋의 카탈로그는 CATLG 명령의 지정에 따른다.
-
FROM 명령이 지정되면 UNCATLG는 무시 처리된다.
CATLG
COPY 명령을 기술한 경우에만 효력이 발생하며 복사한 데이터셋을 카탈로그에 등록한다. 복사한 데이터셋을 카탈로그시키기 위하여 원본 데이터셋은 카탈로그에서 삭제한다.
TODD=dd-name
DCB정보와 LABEL 정보를 주는 DD 문의 DD 이름을 지정하는 항목이다.
(미지원 기능)
UNLOAD
출력 데이터셋의 권한정보를 입력 데이터셋의 권한정보와 같게 만들 때 지정하는 항목이다. (미지원 기능)
-
-
MOVE(COPY) PDS
PDS 데이터셋의 이동 또는 복사를 지정하는 명령어이다.
MOVE(COPY) PDS 명령어 구문은 다음과 같다.
[label] {MOVE|COPY} PDS=name ,TO=device=volser [,FROM=device=volser] [,EXPAND=n] [,UNCATLG] [,CATLG] [,RENAME=name] [,FROMDD=dd-name] [,TODD=dd-name] [,UNLOAD] [,COPYAUTH]항목 설명 PDS=name
이동 또는 복사할 PDS 데이터셋 이름을 지정한다.
TO=device=volser
이동 또는 복사할 PDS 데이터셋의 출력 디바이스 이름과 볼륨을 지정한다.
device는 볼륨의 디바이스 이름을 지정하게 되나 문법을 맞추기 위한 것으로 실제로는 무시된다.
FROM=device=volser
이동 또는 복사할 원본 데이터셋이 존재하는 볼륨을 지정한다.
device는 볼륨의 디바이스 이름을 지정하게 되나 문법을 맞추기 위한 것으로 실제로는 무시된다.
MOVE 명령에서 FROM을 지정하게 되면 원본 데이터셋을 삭제하지 않고 출력 데이터셋은 카탈로그하지 않는다. 따라서 입력 데이터셋이 카탈로그 되어 있으면 FROM은 지정하지 않는 것을 권장한다.
EXPAND=n
이동, 복사하는 PDS 데이터셋의 블록 할당의 증가값을 지정하는 항목이다. (미지원 기능)
UNCATLG
이동 또는 복사 처리 후 데이터셋 카탈로그 정보의 삭제를 지정한다. 원본 데이터셋이 카탈로그되어 있지 않을 때는 지정하지 않도록 한다.
기본적으로 입력 데이터셋의 카탈로그 정보는 삭제되나 복사한 데이터셋의 카탈로그 삭제 방법은 명령어별로 다음과 같은 차이가 있다.
-
MOVE의 경우 복사한 데이터셋은 카탈로그하지 않는다.
-
COPY의 경우 복사한 데이터셋의 카탈로그는 CATLG 명령의 지정에 따른다.
-
FROM 명령이 지정되면 UNCATLG는 무시하고 처리된다.
CATLG
COPY 명령을 기술한 경우에만 효력이 발생하며 복사한 데이터셋을 카탈로그에 등록한다.
RENAME과 FROM 지정을 생략한 경우 복사한 데이터셋을 카탈로그시키기 위하여 원본 데이터셋은 카탈로그에서 삭제한다.
RENAME=name
출력 데이터셋의 새로운 이름을 지정한다.
동일한 볼륨 내에서 이동 또는 복사하는 경우 RENAME 문을 반드시 지정해야 한다.
FROMDD=dd-name
DCB 정보와 LABEL 정보를 주는 DD 문의 DD 이름을 지정하는 항목이다.
(미지원 기능)
TODD=dd-name
DCB 정보와 LABEL 정보를 주는 DD 문의 DD 이름을 지정하는 항목이다.
(미지원 기능)
UNLOAD
입력 데이터셋을 언로드 형식으로 변환해 이동, 복사하는 것을 지정하는 항목이다. (미지원 기능)
COPYAUTH
출력 데이터셋의 권한 정보를 입력 데이터셋의 권한 정보와 같게 만들 때 지정하는 항목이다. (미지원 기능)
-
-
MOVE(COPY) VOLUME
지정한 볼륨 내에 존재하는 모든 데이터셋의 이동 또는 복사를 지정하는 명령어이다.
MOVE(COPY) VOLUME 명령어 구문은 다음과 같다.
[label] {MOVE|COPY} VOL[UME]=device=volser ,TO=device=volser [,PASSWORD] [,CATLG] [,TODD=dd-name] [,UNLOAD]항목 설명 VOLUME=device=volser
이동 또는 복사할 볼륨의 디바이스 이름과 이름을 지정한다.
device는 볼륨의 디바이스 이름을 지정하게 되나 문법을 맞추기 위한 것으로 실제로는 무시된다.
TO=device=volser
이동 또는 복사할 볼륨의 출력 디바이스 이름과 볼륨을 지정한다.
device는 볼륨의 디바이스 이름을 지정하게 되나 문법을 맞추기 위한 것으로 실제로는 무시된다.
PASSWORD
작업 대상 데이터셋이 비밀번호로 관리되는 경우 해당 데이터셋의 이동, 복사를 지정하는 항목이다. (미지원 기능)
CATLG
COPY 명령인 경우에만 복사한 후 데이터셋을 카탈로그정보에 등록한다.
복사한 데이터셋을 카탈로그시키기 위하여 원본 데이터셋은 카탈로그에서 삭제한다.
TODD=dd-name
DCB 정보와 LABEL 정보를 주는 DD 문의 DD 이름을 지정하는 항목이다.
(미지원 기능)
UNLOAD
입력 데이터셋을 언로드 형식으로 변환해 이동, 복사하는 것을 지정하는 항목이다. (미지원 기능)
9.3. 보조 명령어
본 절에서는 JSGMOVE의 보조 명령어에 대해서 설명한다.
-
INCLUDE
MOVE(COPY) PDS 명령어와 함께 사용하며, 이동 또는 복사 대상 데이터셋과 멤버를 추가하는 명령어이다. INCLUDE 명령어 구문은 다음과 같다.
[label] INCLUDE DSN[AME]=name ,MEMBER=name [,FROM=device=volser] ])}항목 설명 DSNAME=name
추가할 PDS 데이터셋의 이름을 지정한다.
MEMBER=name
지정한 PDS 데이터셋의 추가할 멤버명을 지정한다.
FROM=device=volser
이동 또는 복사할 원본 PDS 데이터셋이 존재하는 볼륨을 지정한다.
device는 볼륨의 디바이스 이름을 지정하게 되나 문법을 맞추기 위한 것으로 실제로는 무시된다.
-
EXCLUDE
MOVE(COPY) PDS 명령어와 함께 사용하며, 지정된 PDS 데이터셋의 멤버 중에서 특정 멤버를 처리 대상에서 제외시키는 명령어이다.
EXCLUDE 명령어 구문은 다음과 같다.
[label] EXCLUDE MEMBER=name
항목 설명 MEMBER=name
이동 또는 복사 대상의 PDS 데이터셋 멤버 중에서 제외시킬 멤버 이름을 지정한다.
-
SELECT
MOVE(COPY) PDS 명령어와 함께 사용하며, 지정된 PDS 데이터셋의 멤버 중에서 특정 멤버만을 이동 또는 복사시키는 명령어이다.
SELECT 명령어 구문은 다음과 같다.
[label] SELECT MEMBER={(name[,name][,...]) | ((name,newname),[,(name,newname)][,...])}항목 설명 MEMBER=name
이동 또는 복사 대상으로 지정한 PDS 데이터셋 멤버 중에서 선택하여 처리할 멤버명을 지정한다.
(name,newname)
이동 또는 복사 대상으로 지정한 PDS 데이터셋 멤버 중에서 선택하여 처리할 멤버명과 처리 후 변경 멤버명을 지정한다.
-
REPLACE
MOVE(COPY) PDS 명령어와 함께 사용하며, 지정된 PDS 데이터셋의 멤버 중 특정 멤버를 제외시켜 다른 데이터셋의 동일한 이름을 가진 멤버로 교체시키는 명령어이다.
REPLACE 명령어 구문은 다음과 같다.
[label] REPLACE DSN[AME]=name ,MEMBER=name [,FROM=device=volser]항목 설명 DSNAME=name
교체할 멤버가 속해 있는 PDS 데이터셋 이름을 지정한다.
MEMBER=name
이동 또는 복사 대상으로 지정한 PDS 데이터셋 멤버 중에서 선택하여 처리할 멤버명과 처리 후 변경 멤버명을 지정한다.
FROM=device=volser
지정한 데이터셋이 있는 볼륨을 지정한다. 이동 또는 복사할 원본 PDS 데이터셋이 존재하는 볼륨을 지정한다.
device는 볼륨의 디바이스 이름을 지정하게 되나 문법을 맞추기 위한 것으로 실제로는 무시된다.
9.4. 사용예제
DEFVOL 볼륨에 존재하고 카탈로그에 등록되어 있는 TEST.DS01 데이터셋과 TEST.DS02 데이터셋을 볼륨 100000으로 이동하는 예제이다. TEST.DS01은 다시 카탈로그에 등록되나 TEST.DS02는 카탈로그에 등록되지 않는다.
//MOVE10 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP1 EXEC PGM=JSGMOVE
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
MOVE DSNAME=TEST.DS01,TO=3390=100000
MOVE DSNAME=TEST.DS02,TO=3390=100000,UNCATLG
/*
DEFVOL 볼륨에 존재하며 카탈로그에 등록되지 않은 TEST.DS01 데이터셋과 TEST.DS02 데이터셋을 볼륨 100000으로 복사하는 예제이다. 복사 후에도 TEST.DS01은 카탈로그에 등록되지 않는다. TEST.DS02 또한 CATLG를 지정하였으나 원본이 카탈로그에 등록되지 않았으므로 역시 카탈로그에 등록 처리하지 않는다.
//COPY20 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP1 EXEC PGM=JSGMOVE
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
COPY DSNAME=TEST.DS01,FROM=3380=DEFVOL,TO=3390=100000
COPY DSNAME=TEST.DS02,FROM=3380=DEFVOL,TO=3390=100000,CATLG
/*
카탈로그에 등록되어 있는 TEST.DS01 데이터셋을 TEST.DS02로 이름을 변경하여 DEFVOL 볼륨에서 100000 볼륨으로 복사하는 예제이다.
//COPY30 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP1 EXEC PGM=JSGMOVE
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
COPY DSNAME=TEST.DS01,FROM=3380=DEFVOL,TO=3390=100000,
RENAME=TEST.DS02
/*
TEST.PDS01 PDS 데이터셋의 멤버인 A를 제외하여 DEFVOL 볼륨에서 200000 볼륨으로 이동하는 예제이다. 이 때 100000 볼륨의 TEST.PDS02의 멤버인 D를 추가하여 처리한다.
//MOVE40 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP1 EXEC PGM=JSGMOVE
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
MOVE PDS=TEST.PDS01,FROM=3380=DEFVOL,
TO=3390=200000
EXCLUDE MEMBER=A
INCLUDE DSNAME=TEST.PDS02,MEMBER=D,
FROM=3390=100000
/*
카탈로그에 등록되지 않은 TEST.PDS01 PDS 데이터셋을 DEFVOL 볼륨에서 100000 볼륨으로 복사하는 예제이다. TEST.PDS02의 멤버 A로 교체하여 복사하고 멤버 C를 추가하여 복사한다.
//COPY50 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP1 EXEC PGM=JSGMOVE
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
COPY PDS=TEST.PDS01,FROM=3380=DEFVOL,
TO=3390=200000
REPLACE DSNAME=TEST.PDS02,MEMBER=A
INCLUDE DSNAME=TEST.PDS02,MEMBER=C
/*
TEST.PDS01 PDS 데이터셋을 TEST.PDS02 데이터셋으로 이름을 변경하여 DEFVOL 볼륨에서 100000 볼륨으로 복사하는 예제이다. 복사 대상 멤버는 A, B, C가 되며 B 멤버의 경우 X로 이름을 바꾸어 복사한다.
//COPY60 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP1 EXEC PGM=JSGMOVE
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
COPY PDS=TEST.PDS01,RENAME=TEST.PDS02,
TO=3390=100000,
FROM=3380=DEFVOL
SELECT MEMBER=(A,(B,X),C)
/*
카탈로그에 등록되어 있는 데이터셋 중 MOVE.TEST01, MOVE.PDS, MOVE.SDS91과 같이 MOVE로 시작되는 모든 데이터셋을 100000 볼륨으로 이동하는 예제이다.
//MOVE70 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //STEP1 EXEC PGM=JSGMOVE //SYSPRINT DD SYSOUT=* //SYSIN DD * MOVE DSGROUP=MOVE,TO=3390=100000 /*
DEFVOL 볼륨에 존재하는 모든 데이터셋들을 100000 볼륨으로 이동하는 예제이다.
//MOVE80 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP1 EXEC PGM=JSGMOVE
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
MOVE VOLUME=3380=DEFVOL,
TO=3390=100000
/*
9.5. 유의사항
JSGMOVE 유틸리티 프로그램의 결과는 다음과 같다.
-
정상적으로 실행한 경우
코드 0을 반환한다.
-
에러가 발생한 경우
해당 에러 메시지를 SYSPRINT DD에 출력하고 에러에 해당하는 코드를 반환한다.
JSGMOVE 유틸리티 프로그램에서 발생할 수 있는 에러 코드는 다음과 같다.
코드 설명 4
명령을 성공적으로 수행하지 못하는 경우 발생하는 에러 코드이다.
8
복구 가능한 에러가 발생한 경우 코드이다.
12
복구 불가능한 에러 발생한 경우이다.
해당 에러가 발생하면 유틸리티를 종료한다.
16
SYSIN이나 SYSPRINT를 열 수 없는 경우 발생하는 에러 코드이다.
해당 에러가 발생하면 유틸리티를 종료한다.
10. JSGPROGM
Non-VSAM 데이터셋을 관리하는 유틸리티 프로그램이다.
JSGPROGM 시스템 유틸리티 프로그램으로 다음과 같은 기능을 수행할 수 있다.
-
데이터셋 또는 PDS의 멤버를 해당 볼륨에서 물리적으로 삭제한다.
-
데이터셋을 카탈로그 또는 언카탈로그 한다.
10.1. DD 설정
DD 설정 항목은 다음과 같다.
| 항목 | 설명 |
|---|---|
SYSPRINT DD |
JSGPROGM 메시지가 저장되는 데이터셋을 지정한다. |
SYSIN DD |
JSGPROGM의 명령어를 지정한다. |
10.2. 명령어 설정
본 절에서는 SYSIN DD에서 설정하는 JSGPROGM의 명령어에 대해서 설명한다.
-
SCRATCH
디스크 볼륨에 저장된 물리적인 파일(데이터셋이나 PDS의 멤버)을 제거한다. SCRATCH 대상 데이터셋이 카탈로그에 등록되어있는 경우 카탈로그 정보도 함께 삭제한다.
SCRATCH 명령어 구문 다음과 같다.
[label] SCRATCH {VTOC|[DSNAME|DSN]=name}, VOL=anyname=serial [,MEMBER=name][,SYS]항목 설명 VTOC
지정한 볼륨에 존재하는 모든 데이터셋을 삭제하고자 할 때 사용한다.
DSNAME|DSN
삭제하고자 하는 데이터셋 이름을 지정한다.
VOL
삭제하고자 하는 데이터셋의 볼륨을 지정한다.
anyname에 볼륨의 디바이스 이름을 지정하거나 원하는 이름으로 지정한다. 설정한 anyname은 문법을 맞추기 위한 것으로 실제로는 무시된다.
MEMBER
PDS의 멤버만 삭제하고자 할 때 사용하며, 삭제할 멤버의 이름을 지정한다.
SYS
임시 데이터셋만을 삭제하고자 할 때 사용하는 파라미터이다.
예를 들어 데이터셋 이름이 앰퍼샌드(&) 문자로 시작한다면 삭제 대상이 된다. 이 항목은 VTOC을 지정했을 때에만 유효하다.
-
CATLG
카탈로그에 Non-VSAM 데이터셋의 기본정보를 등록한다.
CATLG 명령어 구문은 다음과 같다.
[label] CATLG [DSNAME|DSN]=name, VOL=anyname=serial항목 설명 DSNAME | DSN
카탈로그에 등록할 데이터셋 이름을 지정한다.
VOL
데이터셋의 볼륨을 지정한다.
anyname에 볼륨의 디바이스 이름을 지정하거나 원하는 이름으로 지정한다. 설정한 anyname은 문법을 맞추기 위한 것으로 실제로는 무시된다.
-
UNCATLG
카탈로그에 등록되어 있는 Non-VSAM 데이터셋을 언카탈로그한다.
UNCATLG문을 사용하여 카탈로그에 등록된 특정 데이터셋을 삭제할 수는 있지만 볼륨에 저장되어 있는 물리적인 파일은 삭제할 수 없다. 볼륨에 저장되어있는 파일을 삭제하고자 하면 SCRATCH문을 사용해 물리적 파일을 삭제하고 난 후 UNCATLG문을 사용하여 카탈로그에 등록된 데이터셋 정보를 삭제한다.
UNCATLG 명령어 구문은 다음과 같다.
[label] UNCATLG DSNAME=name
항목 설명 DSNAME
카탈로그에서 삭제할 데이터셋 이름을 지정한다.
10.3. 사용예제
볼륨 시리얼 넘버가 100000인 VTOC에 존재하는 임시 데이터셋을 삭제하는 예이다.
//CATALOG JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP1 EXEC PGM=JSGPROGM
//SYSPRINT DD SYSOUT=*
//VOLDD DD VOL=SER=100000,DISP=OLD
//SYSIN DD *
SCRATCH VTOC,VOL=SER=100000,SYS
/*
다음은 카탈로그에 시리얼 넘버가 100000인 볼륨에 존재하는 TEST01 데이터셋을 등록하는 예이다.
//CATALOG JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP1 EXEC PGM=JSGPROGM
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
CATLG DSNAME=JSGPROGM.TEST01,VOL=SER=100000
/*
다음은 시리얼 넘버가 100000인 볼륨에서 TEST01 데이터셋을 삭제한 후, 카탈로그에 등록되어있는 TEST01 데이터셋을 삭제하는 예이다.
//CATALOG JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP1 EXEC PGM=JSGPROGM
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
SCRATCH DSNAME=JSGPROGM.TEST01,VOL=SER=100000
UNCATLG DSNAME=JSGPROGM.TEST01
/*
10.4. 유의사항
JSGPROGM 유틸리티 프로그램이 Batch 애플리케이션을 실행한 결과는 다음과 같다.
-
정상적으로 실행한 경우
Batch 애플리케이션에서 받은 코드를 반환한다.
-
에러가 발생한 경우
해당 에러 메시지를 SYSPRINT DD에 출력하고 에러에 해당하는 코드를 반환한다.
JSGPROGM 유틸리티 프로그램에서 발생할 수 있는 에러 코드는 다음과 같다.
코드 설명 8
Warning 형태의 에러로, 다음의 경우가 해당된다.
-
데이터셋을 찾을 수 없는 경우
12
Unrecoverable 형태의 에러로, 다음의 경우가 해당된다.
-
데이터셋 관련(pgmdd, open/close, read/write) 에러
-
SYSIN DD 명령어 문법 에러
-
기타 JSGPROGM 유틸리티 프로그램 에러
16
시스템 에러와 관련된 에러로, 다음의 경우가 해당된다.
-
OpenFrame 시스템 라이브러리 초기화 실패
-
|
유사한 유틸리티 프로그램으로는 KQCAMS가 있다. |
11. KBKARCS
KBKARCS 유틸리티는 BACKUP과 RESTORE 명령을 통해 주로 천재지변에 의한 시스템 손상의 대비나 중요한 데이터의 보호 등의 목적을 위한 데이터셋이나 볼륨의 백업 및 복원 기능을 사용하는 유틸리티 프로그램이다.
BACKUP 명령은 JCL의 컨트롤 문장에서 기술한 데이터셋이나 볼륨을 하나의 데이터셋으로 묶어 지정된 볼륨 디렉터리에 저장하고, RESTORE 명령은 BACKUP 처리한 데이터셋을 원래의 상태로 풀어서 지정한 볼륨 디렉터리에 복원시킨다. 이때 내부적으로는 UNIX에서 제공하는 tar 프로그램을 사용한다.
OpenFrame에서는 BACKUP 명령을 처리할 때 BACKUP 대상 데이터셋의 카탈로그 정보를 별도의 메타정보 파일로 구성하여 BACKUP 대상 데이터셋과 함께 묶어두며, RESTORE 명령을 처리할 때 이 메타정보 파일을 먼저 읽어 BACKUP 처리 당시의 카탈로그 정보로 복원시킨다.
11.1. DD 설정
BACKUP과 RESTORE의 DD 설정 항목은 다음과 같다.
-
BACKUP
항목 설명 SYSIN DD
BACKUP 명령어와 그와 관련된 옵션들을 기술한다.
FROM DD를 위한 DD
SYSIN DD에 기술한 컨트롤 문장 중 FROM DD 문으로 지정한 DD 이름과 같으며 백업 상 데이터셋들의 볼륨정보가 기술된 DD이다.
TO DD를 위한 DD
SYSIN DD에 기술한 컨트롤 문장 중 TO DD 문으로 지정한 DD 이름과 같으며 새로 생성할 백업 데이터셋의 정보가 기술된 DD이다.
-
RESTORE
항목 설명 SYSIN DD
RESTORE 명령어와 그와 관련된 옵션들을 기술한다.
FROM DD를 위한 DD
SYSIN DD에 기술한 컨트롤 문장 중 FROM DD 문으로 지정한 DD 이름과 같으며 복원 대상 백업 데이터셋이 기술된 DD이다.
TO DD를 위한 DD
SYSIN DD에 기술한 컨트롤 문장 중 TO DD 문으로 지정한 DD 이름과 같으며 복원된 데이터셋을 어느 볼륨에 저장할 것인지 지정한다.
11.2. 명령어 설정
BACKUP과 RESTORE의 명령어는 다음과 같이 설정한다.
-
BACKUP
하나 이상의 Non-VSAM 데이터셋이나 볼륨을 하나의 데이터셋으로 백업 처리하는 명령어이다.
BACKUP 명령어 구문은 다음과 같다.
BACKUP VOLUME | DATASET(dsname[,dsname,...]) [FROM(DD(ddname))] TO(DD(ddname)) [LIST] [DELETE]항목 설명 VOLUME
볼륨 백업을 실시한다. DATASET문과 함께 기술할 수 없다.
DATASET
파일 백업을 실시한다.
데이터셋 이름은 하나 이상 기술할 수 있으며, 와일드카드 문자를 이용하여 백업 대상 데이터셋을 필터링할 수도 있다. 와일드카드 문자에 대한 자세한 내용은 참고의 와일드카드 문자 필터링 예제를 참고한다.
FROM DD
백업 대상 볼륨의 DD 이름을 기술한다.
TO DD
백업 처리의 출력 볼륨의 DD 이름을 기술한다.
LIST
백업 처리가 완료된 데이터셋의 정보를 SYSPRINT DD 문으로 지정된 파일에 출력한다.
DELETE
백업 처리가 완료된 데이터셋에 대해 삭제 처리한다.
-
RESTORE
하나의 파일로 백업 처리된 데이터셋을 원래의 Non-VSAM 형식의 데이터셋으로 복원한다.
RESTORE 명령어 구문은 다음과 같다.
RESTORE DATASET(dsname[,dsname,...]) FROM(DD(ddname)) [TO(DD(ddname))] [RENAME((old_name,new_name),...)] LIST항목 설명 DATASET
백업 처리된 데이터셋에서 복원할 데이터셋 이름 하나 이상을 기술한다.
와일드카드 문자를 이용하여 복원 대상 데이터셋을 필터링할 수 있다. 와일드카드 문자에 대한 자세한 내용은 참고의 와일드카드 문자 필터링 예제를 참고한다.
FROM DD
복원 처리할 볼륨의 DD 이름을 기술한다.
TO DD
복원 처리시 저장될 볼륨의 DD 이름을 기술한다.
LIST
복원 처리가 완료된 데이터셋의 정보를 SYSPRINT DD 문으로 지정된 파일에 출력한다.
RENAME
특정한 데이터셋 이름을 변경해서 복원하는 경우 복원 대상의 데이터셋 이름과 변경할 데이터셋 이름을 명시한다. 와일드 카드를 지정할 수 있지만, OpenFrame의 제약 사항으로 % 만 사용할 수 있다.
11.3. 사용예제
다음은 여러 개의 Non-VSAM 데이터셋을 BACKUP 기능을 이용하여 하나의 데이터셋으로 묶어 백업 처리하는 예이다.
KBKARCS.TEST01, KBKARCS.TEST02, KBKARCS.TEST03 데이터셋을 OUTDD에서 기술한 데이터셋 KBKARCS.BACKUPED.DS로 묶어 백업 처리하고 백업된 데이터셋들을 삭제한다.
/**********************************************************************
//*** KBKARCS LOGICAL BACKUP ***
//*********************************************************************
//KBK01 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JS010 EXEC PGM=KBKARCS
//INDD DD VOL=SER=100000,UNIT=SYSDA,DISP=SHR
//OUTDD DD DSN=KBKARCS.BACKUPED.DS,UNIT=3380,DISP=(NEW,CATLG,DELETE)
//SYSIN DD *
BACKUP DATASET(KBKARCS.TEST01,KBKARCS.TEST02,KBKARCS.TEST03),
FROM(DD(INDD)),TO(DD(OUTDD)),DELETE
/*
//SYSPRINT DD SYSOUT=*
*
다음은 백업된 데이터셋을 Non-VSAM 데이터셋으로 복원하는 예이다.
KBKARCS.TEST01, KBKARCS.TEST02, KBKARCS.TEST03 데이터셋을 KBKARCS.BACKUPED.DS 데이터셋에서 풀어 복원하고 복원된 데이터셋 리스트를 출력한다.
//*********************************************************************
//*** KBKARCS LOGICAL RESOTRE ***
//*********************************************************************
//KBK02 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JS010 EXEC PGM=KBKARCS
//INDD DD DSN=KBKARCS.BACKUPED.DS,DISP=OLD
//DASD1 DD VOL=SER=100000,UNIT=3380,DISP=OLD
//SYSIN DD *
RESTORE DATASET(KBKARCS.TEST01,KBKARCS.TEST02,KBKARCS.TEST03),
FROM(DD(INDD)),TO(DD(OUTDD)),LIST
/*
//SYSPRINT DD SYSOUT=*
11.4. 유의사항
OpenFrame에서 KBKARCS 유틸리티 프로그램은 Non-VSAM 형식의 데이터셋만 처리가 가능하며 VSAM 형식의 데이터셋은 지원하지 않는다.
[참고]
DATASET 문에서 백업 또는 복원 대상 데이터셋 이름에 대하여 와일드카드 문자를 이용한 필터링이 가능하다.
| 필터키 | 설명 |
|---|---|
* (single asterisk) |
기본적으로 1개의 Qualifier와 매치한다. 또한 1개의 Qualifier 내의 0개 이상의 문자와 매치할 수 있다. |
** (double asterisk) |
0개 이상의 Qualifier와 매치한다. |
? |
Qualifier 내의 1개의 문자와 매치한다. |
% (percent) |
0개 이상의 Qualifier와 매치한다. % 이후에 문자를 지정할 수 없다. |
Qualifier는 period(.) 사이에 기술된 수식어로 데이터셋 이름을 구성하는 요소를 말한다. 예를 들어 데이터셋 이름이 SYS.LIB인 경우 SYS1과 LIB이라는 2개의 Qualifier를 소유한다고 말한다.
와일드카드 문자를 이용한 필터링의 예는 다음과 같다.
| Filtering Dataset | Filtering 대상 Dataset | Filtering 비대상 Dataset |
|---|---|---|
SYS1.*.LIST |
SYS1.TEST.LIST, SYS1.LIB.LIST |
SYS.TEST.LIST.TEMP, SYS1.LIST |
SYS1.LIB.*.* |
SYS1.LIB.LIST.TEMP, SYS1.LIB.A.B |
SYS1.LIB.LIST, SYS1.LIB.A.B.C |
SYS.*IB.LIST |
SYS.LIB.LIST, SYS1.IB.LIST |
SYS.LIBA.LIST, SYS.LIB.LIST.TEMP |
**.LIST |
SYS1.LIST, SYS1.LIB.LIST, SYS1.A.B.C.LIST |
SYS1.LIST.TEMP, SYS1.LIB.LISTA |
USER.LIB.** |
USER.LIB.LIST.TEMP, USER.LIB |
USER.LIBTEST.LIST, USER.LIBLIST |
SYS1.**.LIST |
SYS1.A.B.C.LIST, SYS1.LIST |
SYS1.LIST.ERR, SYS1.TEST.LIST.ERR |
**.*LIST |
SYS1.TEST.LIST, SYS1.TEST.A.B.OKLIST |
SYS1.LIST.ERR, SYS1.TEST.OKLIST.TEMP |
*.*.L*B |
SYS1.TEST.LIB, USER.LIB.LISTB, A.B.LB |
SYS1.TEST.LIBTEMP, SYS1.USER.LIB.TEMP |
%.LIST |
A.LIST, B.LIST |
AA.LIST, BB.LIST, LIST |
USER%.* |
USER1.LIST, USERA.LIST |
USEROK.LIST, USER1.OK.LIST, USER.LIST |
*%%* |
AA, BB, TEST, USER |
A, B, TEST.USER |
KBKARCS 유틸리티 프로그램이 Batch 애플리케이션을 실행한 결과는 다음과 같다.
-
정상적으로 실행한 경우
애플리케이션에서 받은 코드를 반환한다.
-
에러가 발생한 경우
해당 에러 메시지를 SYSPRINT DD에 출력하고, 각 에러에 해당하는 코드를 반환한다.
KBKARCS 유틸리티 프로그램에서 발생할 수 있는 에러 코드는 다음과 같다.
코드 설명 8
프로그램 수행 중 특정 데이터셋에서 에러가 발생하였으나 다른 데이터셋에 대한 처리는 정상적으로 수행한 경우이다.
12
Unrecoverable 유형의 에러로 에러가 발생하여 정상적으로 수행하지 않은 경우이다.
12. KQCAMS
KQCAMS는 OpenFrame의 VSAM과 Non-VSAM 데이터셋 및 카탈로그 정보를 생성하고 관리하는 유틸리티 프로그램이다.
SYSIN DD에 입력된 각 명령은 각각의 명령이 의미하는 작업을 수행하기 위한 명령어와 이를 위한 각종 옵션 또는 파라미터들로 구성된다. KQCAMS는 실행할 명령들을 SYSIN DD에서 읽어 들여 동작한다.
OpenFrame의 KQCAMS 프로그램은 기존 Mainframe의 KQCAMS 명령을 그대로 사용하여 OpenFrame의 VSAM 데이터셋과 Non-VSAM 데이터셋 그리고 카탈로그를 대상으로 동작한다. 사용자 입장에서 Mainframe의 KQCAMS와 동일한 작업을 수행한다.
KQCAMS 명령어는 다음과 같이 분류된다.
-
기능 명령어
실제로 사용자가 수행하려는 특정 작업을 나타내는 명령어이다.
명령어 설명 이미 정의되어 있는 데이터셋 또는 카탈로그 자체의 속성을 변경한다.
다음의 데이터셋 오브젝트(또는 카탈로그 엔트리)를 정의하기 위해 사용한다.
VSAM과 Non-VSAM 데이터셋 및 카탈로그를 제거한다.
카탈로그와 VSAM 데이터셋을 이식 가능한 데이터셋으로 반출하거나 백업 데이터셋을 생성한다.
EXPORT 명령으로 생성된 이식 가능한 카탈로그와 VSAM 데이터셋을 반입하거나 백업된 상태의 데이터셋을 원래의 상태로 복원한다.
카탈로그에 등록된 VSAM과 Non-VSAM 데이터셋에 대한 정보를 보여준다.
VSAM과 Non-VSAM 데이터셋에 저장되어 있는 레코드를 출력하여 보여준다.
VSAM과 Non-VSAM 데이터셋의 내용을 복사한다.
VSAM 데이터셋의 비정상 종료(close)로 인해 잘못된 데이터셋 정보로 카탈로그 되어 있는지 확인하고 올바르게 수정한다.
VSAM 데이터셋을 종료할 때 해당 데이터셋의 마지막 위치와 레코드 수 등의 통계정보가 카탈로그에 저장된다. 정상적으로 종료되지 않은 경우 카탈로그 정보와 실제 데이터셋의 상태 정보가 일치하지 않을 수 있으므로, VERIFY 명령으로 이러한 불일치를 올바르게 변경할 수 있다.
-
보조 명령어
일련의 KQCAMS 명령어들의 실행을 제어하기 위한 보조 성격의 명령어이다.
명령어 설명 실행된 명령의 컨디션 코드 값(LASTCC 또는 MAXCC)에 따라 다음에 실행할 명령을 분기하기 위해 사용한다.
아무 동작도 발생시키지 않는 문법적 용도의 명령이다.
IF-THEN-ELSE 명령의 THEN이나 ELSE 다음에 특별한 작업을 수행하지 않는다는 것을 명시적으로 나타내기 위해서 사용한다.
MAXCC나 LASTCC의 값을 특정한 값으로 강제 설정하기 위해 사용한다.
프로그램 실행 중 CANCEL 명령어를 만나면 KQCAMS의 실행이 중지되고, CANCEL 명령 이후의 나머지 명령들은 처리되지 않는다.
PARM
KQCAMS가 실행되는 동안에 적용되는 옵션 및 파라미터 값을 지정한다.
(미지원 기능)
-
비기능 명령어
에러가 발생하지 않도록 처리하지만 실제 기능하지 않는 명령어이다.
명령어 설명 특정 데이터셋에 대한 보조 인덱스를 생성한다.
특정 클러스터에 대한 인덱스 및 데이터 컴포넌트의 무결성을 검사한다.
12.1. 코딩 규약
KQCAMS을 이용하여 코딩할 때 공통적으로 적용되는 규약은 다음과 같다.
-
하이픈 (-)
하나의 명령을 여러 라인에 걸쳐서 작성할 경우, 라인의 맨 뒤에 하이픈(-)을 입력하고 그 다음 라인에 계속 이어서 명령의 나머지 부분을 코딩한다. 하이픈(-)은 키워드나 파라미터 값의 중간에 코딩할 수 없으며 일반적으로 키워드나 파라미터 값의 경계가 되는 부분에 라인이 계속 이어진다는 의미로 사용한다.
하이픈(-)을 사용하여 코딩하는 예는 다음과 같다.
LISTCAT ENT( - TEST.CLUS1 - TEST.KSDS1 - TEST.RRDS1 - TEST.SDS1)
여러 라인에 걸쳐서 작성된 명령어의 맨 마지막 라인에는 하이픈(-)을 코딩하지 않도록 주의한다.
-
주석
주석은 KQCAMS 명령 사이에 입력할 수 있다. 단, 키워드나 파라미터 값의 중간에는 주석이 올 수 없다.
주석에 특별한 기능은 없지만 하나의 명령으로 간주되기 때문에 명령 중간에 주석을 추가하는 경우에는 해당 라인의 맨 뒤에 하이픈(-)을 입력해야 한다. 주석은 공백이나 콤마(,)와 같이 KQCAMS 문법에서 필드를 구분하는 역할도 하므로 ‘/*’와 ‘*/’ 사이에 입력한다.
다음은 주석을 기술한 올바른 예이다.
/* This is KQCAMS Comment */ /* This is multi line Comment comment continued from above line */ LISTCAT ENT( /* Comment 1 */ - TEST.KSDS1 /* Comment 3 */ - TEST.SDS1 /* Comment 4 */ ) /* Comment 5 */
IF-THEN-ELSE 문의 중간에 주석을 사용하는 경우에는 주석에 의해서 IF-THEN-ELSE 구조가 의도하지 않은 위치에서 끝나지 않도록 주의해야 한다.
12.2. DD 설정
OpenFrame의 KQCAMS는 JCL을 통해 Batch 작업으로 실행하는 방식과 UNIX 시스템의 명령어 라인에서 직접 실행하는 인터랙티브 방식을 모두 지원한다.
-
JCL을 통한 JOB 실행(using JCL as JOB)
JCL을 통해서 JOB의 한 STEP으로서 KQCAMS를 실행하는 경우 KQCAMS는 다음과 같은 DD 문을 사용한다.
항목 설명 SYSIN DD
KQCAMS가 실행할 명령을 기술한다.
데이터셋의 레코드 길이는 72컬럼을 넘을 수 없으며, 명령이 길어질 경우 하이픈(-)을 사용한다.
SYSPRINT DD 또는
SYSOUT DD
KQCAMS 실행 결과와 실행 중 발생한 주의를 필요로 하는 정보성 메시지, 경고 메시지 그리고 에러 메시지 등을 저장할 데이터셋을 기술한다.
SYSPRINT DD를 기술하지 않거나 지정 데이터셋의 할당, 열기에 실패한 경우 KQCAMS는 아무런 명령도 수행하지 않고 종료되며 컨디션 코드 16을 반환한다.
추가적인 DD
KQCAMS 명령 중에서 일부는 JCL에 기술된 DD를 통해 명령의 대상이 되는 ddname이나 entryname을 간접적으로 지정할 수 있다. 이 경우 KQCAMS는 데이터셋을 동적으로 할당하지 않고 JOB의 실행을 제어하는 tjclrun에 의해 JOB 레벨에서 미리 할당된 데이터셋을 승계 받아 사용한다.
일반적으로 명령어의 대상이 되는 데이터셋을 지정하는 파라미터는 JCL에 기술된 ddname을 이용하여 FILE(ddname) 형태의 파라미터 이름을 갖는다.
KQCAMS에서 동적 할당을 이용하여 데이터셋을 지정하는 파라미터는 DATASET(entryname) 형태의 파라미터 이름을 갖는다.
다음은 앞에서 설명한 추가적인 DD에 대한 예로, REPRO BLDINDEX PRINT의 파라미터를 이용하여 JCL에서 할당된 데이터셋을 승계 받아서 동작하도록 한다.
INFILE(ddname), OUTFILE(ddname)
다음은 REPRO BLDINDEX PRINT의 파라미터로, KQCAMS에서 동적으로 데이터셋을 할당하여 동작하는 예이다.
INDATASET(entryname), OUTDATASET(entryname)
JCL을 통해서 JOB의 한 STEP으로 KQCAMS를 실행시키기 위해서는 KQCAMS를 호출하는 JOB STEP에 앞에서 설명한 DD를 기술하고 EXEC PGM에 KQCAMS를 지정한 후 해당 JCL을 전송(submit)한다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //REPRO EXEC PGM=KQCAMS //INDD DD DSN=VSAM.KSDS1,DISP=(OLD,KEEP) //OUTDD DD DSN=VSAM.KSDS2,DISP=SHR //SYSPRINT DD SYSOUT=* //SYSIN DD * REPRO INFILE(INDD) - OUTFILE(OUTDD) - SKIP(50000) COUNT(10000) /* // -
명령어 라인에서 실행(using from Command line)
UNIX 시스템의 명령어 라인에서 KQCAMS를 직접 실행한다. 이 경우 SYSIN DD 및 SYSPRINT DD 대신에 표준 입출력 스트림(stdin/stdout/stderr)을 사용하여 작동한다. 즉, stdin으로부터 KQCAMS 명령어를 읽어 들여 명령어 단위로 실행하고, stdout/stderr로는 작업의 결과 및 에러 메시지를 출력하는 인터랙티브한 인터프리터 방식이다.
UNIX 시스템의 명령어 라인에 다음과 같은 명령을 실행하면 KQCAMS는 DEFINE.TEST.CLUS1.CMD라는 VSAM 데이터셋을 제거하고 다시 정의하는 동작을 한다.
$ KQCAMS < DEFINE.TEST.CLUS1.CMDDEFINE.TEST.CLUS1.CMD는 일반적인 UNIX 텍스트 파일로 아래와 같은 내용을 담고 있다.
DELETE TEST.CLUS1 CLUSTER DEFINE CLUSTER - (NAME(TEST.CLUS1) - VOLUMES(100000) - INDEXED - KEYS(07 0) - CYL(70 10) - RECORDSIZE(200 200) - SHR(2 3)) - DATA (NAME(TEST.CLUS1.DATA) - CONTROLINTERVALSIZE(4096) ) - INDEX(NAME(TEST.CLUS1.INDEX) - CONTROLINTERVALSIZE(4096) )DEFINE.TEST.CLUS1.CMD 파일은 KQCAMS UNIX 명령어 라인에서 stdin 리다이렉션을 보여준다.
-
제약 사항 (Limitation)
DD(ddname)를 통해 할당된 데이터셋을 승계하여 사용하기 위해서는 OpenFrame Batch 환경, 특히 tjclrun을 필요로 한다. 따라서 JCL을 통해 JOB STEP으로 KQCAMS를 실행하는 경우에 가능했던 ddname을 사용한 데이터셋의 지정이 UNIX 시스템의 명령어 라인에서는 불가능하다.
UNIX 명령어를 실행하는 경우 KQCAMS 명령의 대상이 되는 데이터셋을 지정하기 위해서는 항상 DATASET(entryname) 형태로 지정하여 사용해야 한다.
12.3. 기능 명령어
본 절에서는 KQCAMS 기능 명령어의 사용법에 대해서 설명한다.
-
ALTER
DEFINE 문으로 카탈로그에 이미 등록되어 있는 데이터셋과 카탈로그 엔트리의 정보 일부를 변경할 수 있다. ALTER 명령어 구문은 다음과 같다.
ALTER entryname [EMPTY|NOEMPTY] [FILE(ddname)] [LIMIT(limit)] [NULLIFY( [OWNER] [RETENTION])] [OWNER(ownerid)] [ROLLIN] [SCRATCH|NOSCRATCH] [SHAREOPTIONS(crossregion[ crosssystem])] [STORAGECLASS(class)] [STRNO(number)] [TO(date)|FOR(days)] [CATALOG(catname)]항목 설명 entryname
속성을 변경하고자 하는 기존 데이터셋이나 카탈로그 엔트리의 entryname을 지정한다.
ROLLIN
GDG 베이스와의 연관(association)이 아직 이루어지지 않은 상태(deferred rolled-in state)이거나, 끊어진 상태(rolled off state)에 있는 GDS에 대해서 GDG 베이스와 연관된 상태(rolled-in state)로 변경할 때 지정한다.
CATALOG
entryname으로 지정된 카탈로그 엔트리를 찾을 때 사용할 카탈로그를 명시적으로 지정한다. 지정하지 않는 경우에는 카탈로그 검색 순서에 따라서 결정된다.
카탈로그 엔트리 타입과 카탈로그 엔트리에 해당하는 사용자 데이터셋에 데이터가 적재되어 있는지 여부에 따라서 변경 가능한 속성과 변경 불가능한 속성이 있다.
다음은 OpenFrame KQCAMS의 ALTER 명령이 지원하는 각 카탈로그 엔트리 타입에 따른 변경 가능한 속성을 요약한 표이다. ‘O’로 표시되어 있는 곳이 변경 가능한 속성이다.
엔트리 타입
변경가능 속성
AIX
AIX DATA
AIX INDEX
CLUSTER
CLUSTER DATA
CLUSTER INDEX
PATH
UCAT DATA
UCAT INDEX
NON-VSAM
GDG
NEWNAME
-
-
-
-
-
-
O
-
-
O
-
EMPTY
-
-
-
-
-
-
-
-
-
-
O
NOEMPTY
-
-
-
-
-
-
-
-
-
-
O
LIMIT
-
-
-
-
-
-
-
-
-
-
O
NULLIFY
-
-
-
-
-
-
O
-
-
O
O
OWNER
-
-
-
-
-
-
O
-
-
O
O
ROLLIN
-
-
-
-
-
-
-
-
-
O
-
RETENTION
-
-
-
-
-
-
O
-
-
O
O
SCRATCH
-
-
-
-
-
-
-
-
-
-
O
NOSCRATCH
-
-
-
-
-
-
-
-
-
-
O
TO
-
-
-
-
-
-
O
-
-
O
O
FOR
-
-
-
-
-
-
O
-
-
O
O
변경하고자 하는 카탈로그 엔트리에 새로운 속성값을 지정하기 위해서는 각 파라미터 외에도 변경할 대상이 되는 카탈로그 엔트리를 지정하기 위한 파라미터가 필요하다.
다음은 TESTCAT이라는 카탈로그에 등록된 TEST.GDG1란 이름의 GDG의 최대 세대 수를 255로, 만료일자를 2006년의 300번째 날짜로 속성을 변경하는 예이다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //ALTGDG EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * ALTER TEST.GDG1 - LIMIT(255) - TO(2006300) - CATALOG(TESTCAT) /* //
-
DEFINE
DEFINE 명령에서 공통적으로 사용 가능한 파라미터는 다음과 같다.
DEFINE Commands NAME(entryname) {CYLINDERS(primary[secondary])| KILOBYTES(primary[secondary])| MEGABYTES(primary[secondary])| RECORDS(primary[secondary])| TRACKS(primary[secondary])} VOLUMES(volser[volser...]) [CONTROLINTERVALSIZE(size)] [DATACLASS(class)] [MANAGEMENTCLASS(class)] [OWNER(ownerid)] [RECATALOG|NORECATALOG] [RECORDSIZE(average maximum)] [STORAGECLASS(class)] [TO(date)|FOR(days)]) [DATA (...)] [INDEX (...)] [CATALOG(catname)]항목 설명 NAME
DEFINE 명령으로 생성 또는 정의하려는 카탈로그 객체의 이름을 지정한다.
VOLUMES
데이터셋을 생성하는 경우 데이터셋을 저장할 볼륨의 볼륨 일련번호를 지정한다.
DATACLASS
데이터 클래스 값(1~8글자)을 지정한다.
데이터 클래스는 SMS(Storage Management Subsystem)에서 정의하며 새로운 데이터셋을 생성할 때 사용할 여러 가지 속성들을 가지고 있다.
데이터 클래스를 지정하는 경우 데이터 클래스에 정의된 DEFINE 속성들은 지정하지 않아도 된다. 지정한 데이터 클래스에 정의된 속성과 DEFINE 명령에 명시적으로 지정된 속성이 다른 경우는 DEFINE 명령에 지정된 속성이 우선한다.
MANAGEMENTCLASS
관리 클래스 값(1~8글자)을 지정한다.
관리 클래스는 SMS에서 정의하며 생성되는 데이터셋의 관리작업에 영향을 주는 TO나 FOR와 같은 여러 가지 속성을 가지고 있다.
DEFINE 명령에 TO나 FOR가 명시적으로 지정되어 있고 관리 클래스에서도 동일한 속성이 있는 경우는 데이터 클래스와는 달리 관리 클래스에 정의된 값이 우선한다.
OWNER
데이터셋의 소유자를 지정한다.
RECATALOG|
NORECATALOG
클러스터나 보조 인덱스의 데이터 및 인덱스 컴포넌트, Non-VSAM 데이터셋에 해당하는 카탈로그 엔트리를 기존의 VVDS에 저장되어 있는 정보를 기반으로 다시 생성한다. 클러스터나 보조 인덱스의 경우 VVDS에 존재하는 VVR(VSAM VOLUME RECORD)의 내용이 카탈로그 엔트리 재생성에 사용된다.
이때 일부 VVR에 포함되지 않는 정보는 DEFINE 명령을 통해 직접 기술해 주어야 한다. 이러한 파라미터로는 INDEXED, NONINDEXED, NUMBERED 등의 VSAM 레코드 구성을 지정하는 파라미터와 해당 데이터셋이 원래 생성되었던 VOLUMES 파라미터, VRDS의 경우 RECORDSIZE 파라미터, ALTERNATEINDEX의 경우 NAME, RELATE, VOLUME 파라미터가 있다.
생성하는 카탈로그 엔트리가 Non-VSAM 데이터셋인 경우는 VOLUMES 및 DEVICETYPES 파라미터를 DEFINE 명령을 통해 직접 지정해야 한다. PATH의 경우에는 VVDS에 저장되는 정보가 없으므로 DEFINE 명령에 NAME과 PATHENTRY 파라미터만 지정하면 RECATALOG가 가능하다.
RECORDSIZE
CLUSTER, ALTERNATEINDEX, USERCATALOG를 생성할 때 해당 데이터셋에 저장될 레코드의 크기를 average와 maximum으로 지정한다.
두 값을 동일하게 지정하면 고정 길이 레코드(Fixed Length Record)를 의미한다.
-
USERCATALOG에 지정된 이 파라미터는 무시된다. USERCATALOG는 VSAM이 처리하는 데이터셋이기 때문에 VSAM은 USERCATALOG의 RECORDSIZE 파라미터로 항상 (4096 32600)을 사용한다.
-
CLUSTER에 대해서는 이 파라미터가 생략된 경우 SPANNED 파라미터가 지정되어 있으면 (4096 32600)이 기본값으로 사용되고 그렇지 않은 경우 (4089 4089)가 기본값으로 사용된다.
-
ALTERNATEINDEX에 대해서 이 파라미터가 생략된 경우는 항상 (4089 32600)이 기본값으로 사용된다. ALTERNATEINDEX는 일반적으로 많은 수의 NONUNIQUE KEY가 존재하는 점을 고려해서 VSAM 내부적으로 SPANNED가 지정된 KSDS처럼 처리된다. 즉, ALTERNATEINDEX에는 SPANNED 파라미터는 무시된다.
STORAGECLASS
스토리지 클래스 값(1~8)을 지정한다.
스토리지 클래스는 SMS에서 정의하며 생성되는 데이터셋에 할당되는 저장소 용량과 관련된 속성을 가지고 있다. 스토리지 클래스를 지정하는 경우 필수 파라미터인 CYLINDERS와 같은 스토리지 할당 크기를 지정하는 파라미터를 지정하지 않아도 된다.
DEFINE 명령에 직접 스토리지 할당량이 지정되고 스토리지 클래스에 정의된 값과 다른 경우 스토리지 클래스에 정의된 값이 우선한다.
TO|FOR
데이터셋 및 카탈로그 엔트리를 생성할 때 해당 객체의 만료일자를 지정한다.
-
TO : 만료일자를 지정한다.
-
FOR : 유효일수를 지정한다. 생성일로부터 유효일수를 더한 날짜가 만료일자가 된다.
DATA, INDEX
CLUSTER, ALTERNATEINDEX, USERCATALOG와 같이 데이터 컴포넌트와 인덱스 컴포넌트를 가질 수 있는 VSAM 클러스터를 생성하는 경우 데이터 컴포넌트와 인덱스 컴포넌트 각각에 대해서 별도로 위에서 설명한 파라미터(일부 해당하는 파라미터)를 따로 지정할 수 있다.
예를 들어 저장소 할당 크기를 나타내는 CYLINDERS 파라미터는 DEFINE CLUSTER할 때 CLUSTER의 서브 파라미터로서 지정해도 되고 DATA나 INDEX 컴포넌트의 서브 파라미터로서 지정해도 된다. 이렇게 별도로 지정한 경우 컴포넌트 별로 따로 적용하는 것이 가능하다면 컴포넌트 별로 다른 값이 적용된다.
CATALOG
DEFINE 명령으로 정의하는 카탈로그 엔트리가 등록될 카탈로그 이름을 지정한다.
생략하면 해당 JOB의 STEPCAT이나 JOBCAT에 지정된 카탈로그 또는 카탈로그 엔트리 이름의 일부를 ALIAS로 사용하는 USERCATALOG가 있는 경우 해당 USERCATALOG에 등록된다.
마지막까지 등록할 카탈로그가 결정되지 않으면 마스터 카탈로그에 등록한다. 자세한 사항은 OpenFrame Base "데이터셋 안내서"의 "통합 카탈로그"에서 카탈로그 검색 순서를 참고한다.
-
|
DEFINE 명령별로 지정 가능한 실제 파라미터의 종류는 각각의 DEFINE 명령 절에서 설명한다. 본 절에서는 공통적으로 사용하는 파라미터에 관해 설명한다. |
-
DEFINE ALIAS
Non-VSAM 데이터셋이나 사용자 카탈로그의 별칭으로 사용할 ALIAS를 카탈로그에 생성한다. ALIAS에 해당하는 카탈로그 엔트리 역시 원래의 데이터셋 이름과 별칭만을 포함하고 있다. 별도의 사용자 데이터를 저장하기 위한 데이터셋은 존재하지 않는다.
사용자 카탈로그를 제외한 VSAM 데이터셋에 대한 ALIAS는 생성할 수 없다.
DEFINE ALIAS 명령어 구문은 다음과 같다.
DEFINE ALIAS (NAME(aliasname) RELATE(entryname) SYMBOLICRELATE(entryname)) [CATALOG(catname)]항목 설명 NAME
생성할 ALIAS 이름을 지정한다.
RELATE
ALIAS가 가리키는 실제 엔트리의 entryname을 지정한다.
CATALOG
생성할 ALIAS를 등록할 카탈로그 지정한다.
다음은 TEST.NVSAM1의 ALIAS로 TEST.ALIAS1을 생성하고 TESTCAT 카탈로그에 등록하는 예이다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //DEFALI EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * DEFINE ALIAS(NAME(TEST.ALIAS1) - RELATE(TEST.NVSAM1)) - CATALOG(TESTCAT) /* //
-
DEFINE ALTERNATEINDEX
DEFINE ALTERNATEINDEX(이하 AIX) 명령을 이용하여 특정 데이터셋(BASE CLUSTER)에 대한 별도의 인덱스 방법을 제공하는 AIX 데이터셋을 정의한다.
VSAM은 베이스 클러스터에 레코드가 추가되거나 삭제 또는 변경되는 경우, 이와 연관된 AIX들에 대해서 자동적으로 변경을 수행하여 AIX가 지속적으로 올바르게 베이스 클러스터에 대한 별도의 인덱스를 수행할 수 있도록 한다. 내부 구조 상 AIX 데이터셋도 하나의 KSDS 클러스터 구조를 갖는 데이터셋이므로 DEFINE AIX에 사용되는 대부분의 파라미터는 DEFINE CLUSTER의 파라미터와 동일하다.
DEFINE AIX 명령어 구문과 주요 파라미터는 다음과 같다.
DEFINE AIX (NAME(entryname) RELATE(entryname) {CYLINDERS(primary[secondary])| KILOBYTES(primary[secondary])| MEGABYTES(primary[secondary])| RECORDS(primary[secondary])| TRACKS(primary[secondary])} VOLUMES(volser[ volser...]) [CONTROLINTERVALSIZE(size)] [DATACLASS(class)] [FILE(ddname)] [KEYS(length offset|64 0)] [OWNER(ownerid)] [RECATALOG|NORECATALOG] [RECORDSIZE(average maximum| 4086 32600)] [TO(date)|FOR(days)] [UNIQUEKEY|NONUNIQUEKEY] [UPGRADE|NOUPGRADE]) [DATA ({CYLINDERS(primary[secondary])| KILOBYTES(primary[secondary])| MEGABYTES(primary[secondary])| RECORDS(primary[secondary])| TRACKS(primary[secondary])| [VOLUMES(volser[ volser...])] [CONTROLINTERVALSIZE(size)] [FILE(ddname)] [KEYS(length offset)] [NAME(entryname)] [OWNER(ownerid)] [RECORDSIZE(average maximum)] [UNIQUEKEY|NONUNIQUEKEY])] [INDEX ({CYLINDERS(primary[ secondary])| KILOBYTES(primary[secondary])| MEGABYTES(primary[secondary])| RECORDS(primary[secondary])| TRACKS(primary[secondary])| [VOLUMES(volser[ volser...])] [CONTROLINTERVALSIZE(size)] [FILE(ddname)] [NAME(entryname)] [OWNER(ownerid)])] [CATALOG(catname)]항목 설명 RELATE
현재 정의하는 AIX와 연관된 베이스 클러스터 데이터셋 이름을 지정한다.
베이스 클러스터로 사용할 데이터셋은 VSAM 데이터셋 중에서 KSDS와 ESDS 구조의 데이터셋만 가능하다.
AIX를 정의하기 위해서는 미리 베이스 클러스터로 사용할 데이터셋을 DEFINE CLUSTER 명령을 이용해서 만들어야 한다.
RECORDSIZE
AIX 데이터셋 클러스터 자체의 레코드 크기를 지정한다. SPANNED 파라미터를 지정한 경우 최대 32760의 값까지 지정할 수 있다.
UNIQUEKEY|
NONUNIQUEKEY
정의하려는 AIX의 키 값이 데이터셋 전체에서 유일한지 여부를 지정한다.
베이스 클러스터인 KSDS 데이터셋은 항상 UNIQUEKEY만 지정할 수 있지만 AIX를 만드는 경우는 NONUNIQUEKEY도 지정할 수 있다.
NONUNIQUEKEY가 지정되면 하나의 보조키와 여러 개의 기본키로 이루어진 레코드가 AIX 데이터셋 클러스터 자체의 레코드로 저장된다.
UPGRADE
정의하려는 AIX 클러스터의 베이스 클러스터가 변경된 경우 AIX 클러스터의 내용을 동시에 변경하여 항상 AIX 클러스터의 내용이 베이스 클러스터에 대해 올바른 보조 인덱스를 유지한다.
다음은 VSAM.KSDS1에 대해 보조 인덱스 VSAM.AIX1을 생성하는 예이다.
보조 인덱스 VSAM.AIX1 레코드의 오프셋 44에서 시작되는 7Bytes 부분을 보조키로 한다. 보조키는 유일하지 않으며 베이스 클러스터가 변경될 때 자동적으로 업그레이드된다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //DEFAIX EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * DEFINE AIX (NAME(VSAM.AIX1) - RELATE(VSAM.KSDS1) - UPGRADE - NONUNIQUEKEY - RECORDSIZE(80 80) KEYS(7 44) - VOL(VOL100) - SHR(2 3)) /* //
-
DEFINE CLUSTER
DEFINE CLUSTER 명령을 사용해서 VSAM 데이터셋을 정의하며, 필수적인 속성과 부가적인 속성들을 함께 지정할 수 있다.
DEFINE CLUSTER 명령어 구문과 주요 파라미터는 다음과 같다.
DEFINE CLUSTER (NAME(entryname) {CYLINDERS(primary[secondary])| KILOBYTES(primary[secondary])| MEGABYTES(primary[secondary])| RECORDS(primary[secondary])| TRACKS(primary[secondary])| VOLUMES(vvolser[volser...]) [CONTROLINTERVALSIZE(size)] [DATACLASS(class)] [FILE(ddname)] [INDEXED|LINEAR|NONINDEXED|NUMBERED] [KEYS(length offset| 64 0] [MANAGEMENTCLASS(class)] [OWNER(ownerid)] [RECATALOG|NORECATALOG] [RECORDSIZE(average maximum)] [SPANNED|NONSPANNED] [STORAGECLASS(class)] [TO(date)|FOR(days)]) [DATA({CYLINDERS(primary[secondary])| KILOBYTES(primary[secondary])| MEGABYTES(primary[secondary])| RECORDS(primary[secondary])| TRACKS(primary[secondary])} [VOLUMES(vvolser[ volser...])] [CONTROLINTERVALSIZE(size)] [FILE(ddname)] [KEYS(length offset)] [NAME(entryname)] [OWNER(ownerid)] [RECORDSIZE(average maximum)] [SPANNED|NONSPANNED])] [INDEX({CYLINDERS(primary[secondary])| KILOBYTES(primary[secondary])| MEGABYTES(primary[secondary])| RECORDS(primary[secondary])| TRACKS(primary[secondary])} [VOLUMES(vvolser[volser...])] [CONTROLINTERVALSIZE(size)] [FILE(ddname)] [NAME(entryname)] [OWNER(ownerid)])] [CATALOG(catname)]항목 설명 VOLUMES
데이터셋이 위치할 볼륨을 지정한다.
INDEXED | NONINDEXED | NUMBERED
KSDS, ESDS, RRDS 등 데이터셋의 구조를 지정한다.
VRDS의 경우는 NUMBERED를 지정하고 RECORDSIZE를 가변길이로 지정한다.
KEYS
INDEXED 구조에서 데이터셋의 한 레코드 상에서 키가 되는 부분의 위치와 키의 길이를 지정한다.
RECORDSIZE
데이터 당 레코드의 평균 길이와 최대 길이를 지정한다.
평균 길이와 최대 길이 값을 다른 값으로 지정하면 가변길이 레코드임을 의미한다.
CONTROLINTERVALSIZE
VSAM 데이터셋의 레코드를 관리하기 위해 사용할 블록의 크기를 지정한다.
지정하지 않으면 다른 파라미터들의 값을 기반으로 VSAM이 내부적으로 값을 정하게 된다. SPANNED 파라미터를 지정하지 않은 경우, CONTROLINTERVALSIZE는 최대길이의 레코드를 충분히 포함할 만큼 크게 지정해야 한다.
SPANNED
이 파라미터가 정의된 데이터셋은 CONTROLINTERVALSIZE 보다 더 긴 레코드를 저장할 수 있다.
NUMBERED 구조의 데이터셋인 RRDS와 VRDS에 대해서는 이 파라미터를 사용할 수 없다.
다음은 VSAM.KSDS1이라는 INDEXED 구조의 데이터셋을 생성하는 예이다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //DEFCLUS EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * DEFINE CLUSTER (NAME(VSAM.KSDS1) - INDEXED - KEYS(10 0) - VOL(VOL100) - SPEED - ORDERED - SHR(2 3)) - INDEX (NAME (VSAM.KSDS1.I)) - DATA (NAME(VSAM.KSDS1.D) - CISZ(4096) - RECSZ(350 350)) /* //VSAM.KSDS1에 저장되는 레코드는 350Bytes의 고정길이를 갖고 키 필드는 레코드 상에서 맨 앞의 10Bytes에 위치하며, VSAM.KSDS1 데이터셋을 구성하는 인덱스와 데이터 컴포넌트의 이름을 각각 명시적으로 지정하고 있다.
-
DEFINE GDG (Generation Data Group)
GDG에 해당하는 카탈로그 엔트리를 카탈로그에 생성한다.
GDG의 한 세대(Generation)에 해당하는 Non-VSAM 데이터셋 GDS와 달리 GDG에 해당하는 실제 데이터셋은 존재하지 않는다. GDG 카탈로그 엔트리는 추후 해당 GDG 그룹에 속하게 될 여러 GDS를 관리하기 위한 정보만을 갖는 카탈로그 엔트리이다.
DEFINE GDG를 수행한 결과로는 아무런 데이터셋도 생성되지 않고, 단순히 해당 GDG 그룹을 관리하기 위한 카탈로그 엔트리가 카탈로그에 추가된다.
DEFINE GDG 명령어 구문은 다음과 같다.
DEFINE GENERATIONDATAGROUP (NAME(entryname) LIMIT(limit) [EMPTY|NOEMPTY] [OWNER(ownerid)] [SCRATCH|NOSCRATCH] [TO(date)|FOR(days)]) [CATALOG(catname)]항목 설명 NAME
생성할 GDG 베이스의 이름을 지정한다.
LIMIT
생성하는 GDG에 몇 개까지의 GDS 멤버를 포함할 수 있는지 그 최댓값을 지정한다. 예를 들어 100이라고 지정하면 100개를 초과하는 GDS를 생성할 수 없다. GDG 멤버는 1부터 255까지 생성할 수 있다.
EMPTY|
NOEMPTY
GDG 베이스가 GDS 멤버를 포함할 수 있는 최댓값에 도달했을 경우 전체 GDS와 GDG 베이스 간의 연관(association)을 끊으려면(rolled off status) EMPTY를 지정한다.
NOEMPTY를 지정하면 가장 오래된 GDS만 연관이 끊기고 새로운 GDS를 베이스에 포함시킨다. GDG 베이스와 연관이 끊어진 GDS는 단순한 Non-VSAM 데이터셋으로 간주된다.
OWNER
생성할 GDG 베이스의 소유자를 명시적으로 지정한다.
SCRATCH|
NOSCRATCH
GDG 베이스에 포함될 수 있는 GDS 멤버 한계에 도달한 경우 EMPTY와 NOEMPTY 속성에 따라서 전체 혹은 가장 오래된 GDS 데이터셋과 GDG 베이스간의 연관이 끊어질 때(rolled off) 해당 GDS가 사용하는 데이터를 지울지(SCRATCH) 아니면 그냥 둘지(NOSCRATCH)를 지정한다.
TO|FOR
GDG 그룹의 유효일을 설정한다.
-
TO : 유효일의 마지막 날짜를 율리우스 날짜 형태로 지정한다. (2006년 1월 1일은 2006001로 지정)
-
FOR : 날짜수를 지정한다. (30을 지정할 경우 오늘부터 30일 간을 의미)
CATALOG
생성할 GDG 베이스가 등록될 카탈로그의 이름을 지정한다.
다음은 GDS 멤버를 100개까지 포함할 수 있는 TEST.GDG1이라는 이름의 GDG 베이스를 생성하고 2006년 12월 31일까지를 GDG 베이스의 유효기간으로 설정하여 TESTCAT이라는 카탈로그에 등록하는 예이다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //DEFGDG EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * DEFINE GDG (NAME(TEST.GDG1) - LIMIT(100) - TO(2006365)) - CATALOG(TESTCAT) /* // -
-
DEFINE NONVSAM
일반적인 PS(Physical Sequential) 타입의 Non-VSAM 데이터셋을 생성하고 만들어진 데이터셋을 카탈로그에 등록한다.
GDG에 속하는 하나의 GDS는 Non-VSAM 데이터셋이기 때문에 DEFINE NONVSAM 명령을 사용해서 GDS를 생성할 수 있다.
DEFINE NONVSAM 명령어 구문은 다음과 같다.
DEFINE NONVSAM (NAME(entryname) DEVICETYPES(devtype [devtype ...]) VOLUMES(volser [volser ...]) [OWNER(ownerid)] [RECATALOG|NORECATALOG] [TO(date)|FOR(days)]) [CATALOG(catname)]항목 설명 NAME
만들어질 Non-VSAM 데이터셋의 이름을 지정한다. 이름 규칙에 대한 자세한 내용은 OpenFrame Base "데이터셋 안내서"를 참고한다.
GDG에 속하는 GDS를 생성하기 위해서는 GDGname.GxxxxVyy의 형태로 entryname을 지정해야 한다. 예를 들면 TEST.GDG1.G0001V00에서 Gxxxx는 세대번호이고, Vyy는 버전번호이다.
DEVICETYPES
Non-VSAM 데이터셋이 저장될 볼륨의 디바이스 타입을 지정한다.
3380, 3390, 3480과 같은 디바이스 타입을 지정해야 한다. SYSDA와 같은 에소테릭 디바이스 그룹(esoteric device group)은 사용할 수 없다.
VOLUMES
Non-VSAM 데이터셋을 저장할 볼륨의 볼륨 일련번호를 지정한다.
CATALOG
Non-VSAM 데이터셋의 카탈로그 엔트리 정보가 등록될 카탈로그를 지정한다.
OWNER
Non-VSAM 데이터셋의 소유자를 명시적으로 지정한다.
RECATALOG| NORECATALOG
Non-VSAM 데이터셋에 해당하는 VVDS와 이미 존재하는 데이터셋을 카탈로그에만 새로 등록하는 경우에는 RECATALOG를 지정한다. 기본값은 NORECATALOG으로 새로 데이터셋을 생성한다.
TO|FOR
Non-VSAM 데이터셋의 유효일을 설정한다.
-
TO : 유효일의 마지막 날짜를 율리우스 날짜 형태로 지정한다. (2006년 1월 1일은 2006001로 지정)
-
FOR : 날짜수를 지정한다. (30을 지정할 경우 오늘부터 30일간을 의미)
다음은 Non-VSAM 데이터셋인 TEST.NVSAM1을 생성하고 TESTCAT 카탈로그에 등록하는 예이다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //DEFNVS EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * DEFINE NONVSAM (NAME(TEST.NVSAM1) - VOLUMES(100000)) - CATALOG(TESTCAT) /* // -
-
DEFINE PATH
DEFINE PATH 명령을 통해서 베이스 클러스터에 대한 직접적인 접근 경로를 정의하거나 보조 인덱스를 경유하여 베이스 클러스터에 접근하는 간접적인 접근 경로를 정의한다.
DEFINE PATH 명령어 구문은 다음과 같다.
DEFINE PATH (NAME(entryname) [PATHENTRY(entryname)] [OWNER(ownerid)] [RECATALOG|NORECATALOG] [TO(date)|FOR(days)]) [CATALOG(catname)]항목 설명 NAME
DEFINE PATH 문으로 현재 정의하는 PATH의 이름을 지정한다.
PATHENTRY
PATH가 AIX와 베이스 클러스터의 쌍으로 이루어지는 경우에는 AIX 데이터셋의 이름을 지정한다.
베이스 클러스터 자체에 대한 PATH를 정의하는 경우라면 베이스 클러스터 데이터셋의 이름을 지정하며 베이스 클러스터 데이터셋 본래의 인덱스 방법을 지칭하는 단순한 별칭으로 생각할 수 있다. 하지만 하나의 베이스 클러스터에 여러 개의 PATH를 정의할 수 있기 때문에 실제로 액세스할 때 적용되는 속성을 달리 지정하는 용도로 사용할 수 있다.
OWNER
접근 경로의 소유자를 명시적으로 지정한다.
RECATALOG|
NORECATALOG
RECATALOG를 지정할 때 이름이 동일한 접근 경로가 이미 존재하더라도 해당 접근 경로를 지우고 다시 접근 경로를 만든다.
NORECATALOG를 지정하면 새로운 접근 경로인 경우만 생성될 수 있다.
TO|FOR
접근 경로의 유효일을 설정한다.
-
TO : 유효일의 마지막 날짜를 율리우스 날짜 형태로 지정한다. (2006년 1월 1일은 2006001로 지정)
-
FOR : 날짜수를 지정한다. (30을 지정할 경우 오늘부터 30일간을 의미)
다음은 보조 인덱스 VSAM.AIX1을 경유하여 VSAM.AIX1의 베이스 클러스터에 접근하는 접근경로(PATH)인 VSAM.PATH1을 생성하는 예이다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //DEFPATH EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * DEFINE PATH (NAME(VSAM.PATH1) - PATHENTRY(VSAM.AIX1)) /* //다음은 보조 인덱스를 경유하지 않고 직접 베이스 클러스터에 접근하는 접근경로 VSAM.PATH2를 정의하는 예이다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //DEFPATH EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * DEFINE PATH (NAME(VSAM.PATH2) - PATHENTRY(VSAM.KSDS1)) /* //DEFINE PATH에 관한 자세한 내용은 OpenFrame Base"데이터셋 안내서"를 참고한다.
-
-
DEFINE USERCATALOG/MASTERCATALOG
시스템에서 제공하는 하나의 마스터 카탈로그 외에 여러 개의 사용자 카탈로그를 별도로 사용할 수 있다. 모든 데이터셋에 관한 메타정보를 마스터 카탈로그에 모두 등록하는 경우 마스터 카탈로그의 크기가 필요 이상으로 커지게 되므로 시스템의 성능저하를 초래할 수 있다.
DEFINE USERCATALOG 명령으로 시스템 마스터 카탈로그와 비슷한 용도로 사용할 수 있는 사용자 카탈로그를 생성할 수 있다. 이는 마스터 카탈로그의 서브 카탈로그로 생각할 수 있다.
생성된 사용자 카탈로그에 대한 정보는 다시 마스터 카탈로그에 저장된다. 사용자 카탈로그의 서브 카탈로그로 또 다른 사용자 카탈로그를 생성하는 것은 불가능하다. 사용자 카탈로그는 한 레벨로만 생성할 수 있으며, 모든 사용자 카탈로그는 마스터 카탈로그에만 등록되고, 다른 사용자 카탈로그에는 등록될 수 없다. 일반적으로 사용자 카탈로그는 사용자 별로 생성하거나 관련 부서 또는 업무별로 생성한다.
OpenFrame에서는 마스터 카탈로그는 설치 과정중에 자동으로 생성된다. 사용자 카탈로그를 추가로 생성하는 경우에는 KQCAMS의 DEFINE USERCATALOG 명령을 사용한다.
DEFINE USERCATALOG 명령어 구문과 주요 파라미터는 다음과 같다.
DEFINE USERCATALOG (NAME(entryname) {CYLINDERS(primary[secondary])| KILOBYTES(primary[secondary])| MEGABYTES(primary[secondary])| RECORDS(primary[secondary])| TRACKS(primary[secondary])} VOLUME(volser) [CONTROLINTERVALSIZE(size)] [DATACLASS(class)] [FILE(ddname)] [MANAGEMENTCLASS(class)] [OWNER(ownerid)] [RECORDSIZE(average maximum|4086 32400)] [STORAGECLASS(class)] [TO(date)|FOR(days)]) [DATA ({CYLINDERS(primary[secondary])| KILOBYTES(primary[secondary])| MEGABYTES(primary[secondary])| RECORDS(primary[secondary])| TRACKS(primary[secondary])} [CONTROLINTERVALSIZE(size)] [RECORDIZE(average maximum|4086 32400)])] [INDEX ({CYLINDERS(primary[secondary])| KILOBYTES(primary[secondary])| MEGABYTES(primary[secondary])| RECORDS(primary[secondary])| TRACKS(primary[secondary])} [CONTROLINTERVALSIZE(size)])] [CATALOG(mastercatname)]항목 설명 NAME
생성할 사용자 카탈로그의 이름을 지정한다.
VOLUME
사용자 카탈로그가 저장될 볼륨을 지정한다.
RECORDSIZE
사용자가 지정한 RECORDSIZE 파라미터는 무시되고, 기본 카탈로그 구조를 갖는(Basic Catalog Structure) 데이터셋의 기본적인 레코드 크기(4086 32400)가 사용된다.
CATALOG
생성된 사용자 카탈로그가 등록될 마스터 카탈로그의 이름을 지정한다. 생략해도 시스템의 마스터 카탈로그에 자동으로 등록된다.
-
DELETE
VSAM 데이터셋과 Non-VSAM 데이터셋 그리고 이외에 카탈로그된 데이터셋 항목을 제거하기 위해 DELETE 명령을 사용한다.
DELETE 명령은 이미 존재하는 항목을 지우는 역할을 하기 때문에 많은 파라미터를 요구하지 않는다. 제거하려는 항목의 이름과 해당 항목의 카탈로그 엔트리 타입만을 필요로 한다.
DELETE 명령어 구문은 다음과 같다.
DELETE (entryname [entryname ...]) [ALIAS| ALTERNATEINDEX| CLUSTER| GENERATIONDATAGROUP| NONVSAM| PATH| TRUENAME| USERCATALOG] [ERASE|NOERASE] [FILE(ddname)] [PURGE|OPURGE] [CATALOG(catname)]항목 설명 entryname
제거할 데이터셋이나 카탈로그 엔트리의 이름을 지정한다.
괄호 안에 여러 개의 이름을 지정하면 한번의 명령으로 다수의 엔트리를 제거할 수 있다.
entryname으로 지정된 데이터셋은 배타적으로(DISP=OLD) 할당된다.
ALIAS|
ALTERNATEINDEX|
CLUSTER|
GENERATIONDATAGROUP|
NONVSAM|
PATH|
TRUENAME|
USERCATALOG
ALIAS는 ALIAS Entry Type이다.
제거할 카탈로그 엔트리의 엔트리 타입을 지정한다.
엔트리 타입 지정은 필수적이지 않지만, 엔트리 타입을 지정하면 실수로 이름이 동일한 의도하지 않은 항목을 제거하는 실수를 방지할 수 있다.
AIX, CLUSTER, PATH, TRUENAME은 VSAM 데이터셋의 엔트리 타입이고 나머지는 Non-VSAM 데이터셋의 엔트리 타입이다.
ERASE|NOERASE
엔트리 타입이 CLUSTER이거나 AIX인 데이터셋을 제거하는 경우에 해당 데이터셋의 실제 내용을 0으로 채울지 여부를 지정한다.
FILE
제거할 데이터셋을 지정한다.
FILE(ddname) 으로 데이터셋을 지정하는 경우 ddname은 KQCAMS를 호출한 JCL의 DD 문을 통해 할당된 ddname을 지정해야 한다.
PURGE|NOPURGE
데이터셋을 정의할 때 지정한 사용기간에 관계없이 데이터셋 엔트리를 제거할지 여부를 지정한다.
PURGE를 지정한 경우 사용기간에 관계없이 데이터셋 엔트리를 제거한다.
NOPURGE를 지정한 경우는 유지기간이 만료된 엔트리만을 대상으로 제거를 수행하며, 만료되지 않은 엔트리에 대해서는 제거하지 않는다. 생략된 경우 NOPURGE가 지정된 것으로 처리된다.
데이터셋의 사용기간(retention period)은 DEFINE 명령의 TO 및 FOR 파라미터로 지정된다.
CATALOG
삭제할 카탈로그 엔트리 정보가 등록되어 있는 카탈로그를 지정한다.
다음은 VSAM 데이터셋 엔트리 타입의 VSAM.KSDS1과 VSAM.KSDS2를 지정한 사용기간에 관계없이 삭제하는 예이다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //DELCLUS EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * DELETE (VSAM.KSDS1 VSAM.KSDS2) - CLUSTER - ERASE - PURGE /* //
-
EXPORT
EXPORT 명령을 이용하여 VSAM CLUSTER나 ALTERNATE INDEX를 외부로 이식 가능한 데이터셋으로 반출할 수 있다. 카탈로그 데이터셋 자체를 백업하기 위해서 사용된다.
EXPORT 명령어 구문은 다음과 같다.
EXPORT entryname {OUTFILE(ddname)|OUTDATASET(entryname)} [INFILE(ddname)]항목 설명 entryname
EXPORT할 카탈로그 엔트리의 entryname을 지정한다. entryname으로 지정된 반출 대상 데이터셋은 배타적으로(DISP=OLD) 할당된다.
OUTFILE|
OUTDATASET
EXPORT 결과로 생성될 데이터셋을 지정한다. EXPORT 결과로 생성된 데이터셋을 카탈로그 상에 새로 만들기를 원하거나 이미 카탈로그 되어있는 경우는 entryname을 사용하고, 실행환경에서 KQCAMS 호출 전에 미리 할당되어있는 데이터셋에 생성되기를 원하는 경우는 ddname을 사용한다.
OUTDATASET 파라미터를 이용해서 지정한 데이터셋은 배타적으로(DISP=OLD) 할당된다.
INFILE
EXPORT할 데이터셋을 지정한다.
INFILE(ddname) 으로 데이터셋을 지정하는 경우 ddname은 KQCAMS를 호출한 JCL의 DD 문을 통해 할당된 ddname을 지정해야 한다.
다음은 카탈로그 TESTCAT을 TESTCAT.BACKUP으로 EXPORT하는 예이다. 카탈로그의 내용을 반출하여 백업한다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //BACKCAT EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //BACK DD DSN=TESTCAT.BACKUP,DISP=OLD //SYSIN DD * EXPORT TESTCAT - OUTFILE(BACK) /* //
-
IMPORT
IMPORT 명령을 이용하면 EXPORT 명령을 사용해서 생성한 백업이나 외부의 이식 가능한 데이터셋으로부터 다시 데이터셋을 복원하거나 새로 생성할 수 있다.
IMPORT 명령어 구문은 다음과 같다.
IMPORT {INFILE(ddname)|INDATASET(entryname)} {OUTFILE(ddname)|OUTDATASET(entryname)} [INTOEMPTY] [OBJECTS((entryname [MANAGEMENTCLASS(class)] [NEWNAME(newname)] [STORAGECLASS(class)] [VOLUMES(volser[ volser...])]) [(entryname...)...])] [CATALOG(catname)]항목 설명 INFILE|INDATASET
IMPORT할 소스 데이터셋을 지정한다.
KQCAMS 호출 전에 실행환경에서 미리 할당된 데이터셋을 사용하려는 경우에는 ddname을 지정하고 KQCAMS 내부적으로 할당하려는 경우에는 entryname을 사용한다.
INDATASET 파라미터를 이용하여 지정된 소스 데이터셋은 배타적으로(DISP=OLD) 할당된다.
OUTFILE|OUTDATASET
KQCAMS 호출 전에 실행환경에서 미리 할당된 데이터셋을 사용하려는 경우에는 ddname을 지정하고 KQCAMS 내부적으로 할당하려는 경우에는 entryname을 사용한다.
OUTDATASET 파라미터를 이용하여 지정된 데이터셋은 배타적으로(DISP=OLD) 할당된다.
INTOEMPTY
IMPORT 결과로 데이터를 받아들이는 데이터셋이 카탈로그에 등록되어 있거나 데이터셋에는 존재하지만 저장 공간이 할당되지 않은 상태인 경우(empty dataset) IMPORT 명령은 기본적으로 실패하게 된다. 이것을 무시하고 IMPORT 명령 수행 중에 필요한 저장 공간을 확보하여 명령을 성공시키기를 원하는 경우는 INTOEMPTY를 지정한다.
OBJECTS
IMPORT 작업을 수행하는 과정에서 부수적으로 IMPORT 원본 데이터셋에 기록된 정보 중에서 일부를 변경하는 작업을 수행할 수 있다. 이때 변경하고자 하는 entryname과 적용할 새로운 속성을 지정한다. 여러 개의 entryname에 대해서 반복적으로 지정할 수 있다.
CATALOG
IMPORT 과정 중에 카탈로깅이 필요한 경우 사용할 카탈로그를 지정한다.
다음은 TESTCAT.BACKUP이라는 백업 데이터셋의 내용을 카탈로그 TESTCAT으로 IMPORT하는 예이다. TESTCAT.BACKUP에 저장된 내용을 이용하여 카탈로그 TESTCAT을 복원한다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //IMPCAT EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //BACK DD DSN=TESTCAT.BACKUP,DISP=OLD //SYSIN DD * IMPORT INFILE(BACK) - OUTDATASET(TESTCAT) /* //
-
LISTCAT
LISTCAT 명령을 사용해서 카탈로그에 정의된 데이터셋에 관한 다양한 정보를 출력할 수 있다.
다음과 같은 그룹으로 관련 정보를 정리해서 보여준다.
-
엔트리 객체의 속성
-
생성, 변경, 만료시간 정보
-
보호(protection) 관련 정보
-
데이터셋 액세스 통계 정보
-
저장공간 할당 정보
-
데이터셋의 구조에 관한 정보
LISTCAT 명령어 구문은 다음과 같다.
LISTCAT [ALIAS] [ALTERNATEINDEX] [CLUSTER] [DATA] [GENERATIONDATAGROUP] [INDEX] [NONVSAM] [PATH] [USERCATALOG] [ENTRIES(entryname[ entryname...])|LEVEL(level)] [NAME|HISTORY|VOLUME|ALLOCATION|ALL] [CATALOG(catname)]항목 설명 ALIAS,
ALTERNATEINDEX,
CLUSTER, DATA,
GENERATIONDATAGROUP,
INDEX, NONVSAM, PATH,
USERCATALOG
지정된 종류의 카탈로그 엔트리에 대해서만 LISTCAT 정보를 출력하도록 하기 위한 파라미터이다.
예를 들어 LISTCAT CLUSTER라고 지정하는 경우 카탈로그 엔트리 타입이 CLUSTER인 엔트리에 대한 정보만 출력한다.
두 개 이상의 엔트리 타입을 지정하는 것도 가능하다. LISTCAT DATA INDEX라고 지정하면 카탈로그 엔트리 타입이 DATA이거나 INDEX인 엔트리에 대한 정보만 출력된다.
파라미터를 지정하지 않는 경우 카탈로그 엔트리 타입에 대한 필터링을 하지 않고 모든 타입의 엔트리 정보를 모두 출력한다.
이와는 별도로 ENTRIES 파라미터를 지정하는 경우 엔트리 타입이 일치하더라도 엔트리 이름이 ENTRIES 파라미터에 지정된 이름을 만족하지 않는 엔트리들에 대한 정보는 출력되지 않는다.
ENTRIES|LEVEL
LISTCAT 명령의 대상이 되는 카탈로그 엔트리명을 지정한다.
-
ENTRIES : 카탈로그에 존재하는 엔트리 이름 중에서 지정된 entryname과 이름이 일치하고 세그먼트 개수도 일치하는 이름만 명령의 대상으로 지정된다.
-
LEVEL : 카탈로그에 존재하는 엔트리 이름 중에서 지정된 entryname과 이름의 앞부분이 일치하는 이름이 명령의 대상으로 지정된다. 사용자가 지정한 entryname의 세그먼트 개수보다 많은 세그먼트 개수를 갖는 이름들도 명령의 대상으로 지정된다.
ENTRIES와 LEVEL의 사용 예는 다음과 같다.
-
카탈로그가 다음의 엔트리 이름들을 가지고 있는 경우
1. A.A.B 2. A.B.B 3. A.B.B.C 4. A.B.B.C.C 5. A.C.C 6. A.D 7. A.E 8. A
-
ENTRIES(A.*)를 지정한 경우, 6, 7이 명령의 대상으로 선택된다.
-
ENTRIES(A.*.B)를 지정한 경우, 1, 2가 명령의 대상으로 선택된다.
-
LEVEL(A.*.B)를 지정한 경우, 1, 2, 3, 4가 명령의 대상으로 선택된다.
-
LEVEL(A)를 지정한 경우, 1,2,3,4,5,6,7이 모두 명령의 대상으로 선택된다.
-
애스터리스크(*)는 해당 세그먼트의 모든 이름과 일치한다.
-
NAME|HISTORY|
VOLUME|
ALLOCATION|ALL
위의 엔트리 타입 필터 및 ENTRIES 파라미터로 지정되는 엔트리 이름 조건을 만족하는 카탈로그 엔트리에 대한 정보를 출력하는데 있어서 얼마나 자세한 레벨의 정보까지 출력할지를 지정한다.
순서대로 NAME을 지정하면 가장 기본적인 정보만이 출력되고 ALL을 지정하면 모든 해당 엔트리에 대한 정보가 출력된다.
CATALOG
LISTCAT 명령의 대상이 카탈로그의 이름을 지정한다. 위의 ENTRIES나 LEVEL로 지정하는 entryname은 여기에서 지정하는 카탈로그에서 검색된다.
다음은 VSAM.KSDS1의 모든 엔트리에 대한 정보를 출력하는 예이다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //LISTC EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * LISTCAT ENTRIES(VSAM.KSDS1) ALL /* //
다음은 앞의 LISTCAT 명령을 실행한 결과로 출력되는 내용(SYSPRINT)이다.
CLUSTER ------------- VSAM.KSDS1 HISTORY CREATION ----------------- 20191021 DATASET-OWNER -------------- NOUSER EXPIRATION ---------------- (EMPTY) RELEASE ------------------- (EMPTY) VSAM QUIESCED ----- (NOT-SUPPORTED) ASSOCIATIONS DATA ---------------- VSAM.KSDS1.DATA INDEX --------------- VSAM.KSDS1.INDEX DATA ---------------- VSAM.KSDS1.DATA HISTORY CREATION ----------------- 20191021 DATASET-OWNER -------------- NOUSER EXPIRATION ---------------- (EMPTY) RELEASE ------------------- (EMPTY) ASSOCIATION CLUSTER ------------- VSAM.KSDS1 ATTRIBUTES AVGLRECL ---------------------- 350 MAXLRECL --------------------- 350 KEYLEN ------------------------- 10 RKP ----------------------------- 0 AXRKP --------------------------- 0 CISIZE -------------------- (EMPTY) INDEXED NON-SPANNED UNIQUEKEY STATISTICS REC-DELETED --------------- (EMPTY) REC-INSERTED -------------- (EMPTY) REC-RETRIEVED ------------- (EMPTY) REC-TOTAL ----------------- (EMPTY) REC-UPDATED --------------- (EMPTY) TIMESTAMP ------------------ (NULL) USER-DATA-SIZE ------------ (EMPTY) ALLOCATION HI-A-RBA ------------------------ 0 HI-U-RBA ------------------------ 0 VOLUMES DEVTYPE -------------------- (NULL) VOLSER --------------------- 100000 INDEX --------------- VSAM.KSDS1.INDEX HISTORY CREATION ----------------- 20191021 DATASET-OWNER -------------- NOUSER EXPIRATION ---------------- (EMPTY) RELEASE ------------------- (EMPTY) ASSOCIATION CLUSTER ------------- VSAM.KSDS1 ATTRIBUTES AVGLRECL ---------------------- 350 MAXLRECL --------------------- 350 KEYLEN ------------------------- 10 RKP ----------------------------- 0 CISIZE -------------------- (EMPTY) STATISTICS INDEX: ENTRIES/SECT ------------ (EMPTY) HI-LEVEL-RBA ------------ (EMPTY) LEVELS ------------------ (EMPTY) SEQ-SET-RBA ------------- (EMPTY) REC-DELETED --------------- (EMPTY) REC-INSERTED -------------- (EMPTY) REC-RETRIEVED ------------- (EMPTY) REC-TOTAL ----------------- (EMPTY) REC-UPDATED --------------- (EMPTY) TIMESTAMP ------------------ (NULL) ALLOCATION HI-A-RBA ------------------------ 0 HI-U-RBA ------------------------ 0 VOLUMES DEVTYPE -------------------- (NULL) VOLSER --------------------- 100000 -
-
PRINT
VSAM 및 Non-VSAM 데이터셋에 저장되어있는 레코드들을 출력하여 보여준다.
PRINT 명령어 구문은 다음과 같다.
PRINT {INFILE(ddname)|INDATASET(entryname)} [CHARACTER|DUMP|HEX] [FROMKEY(key)|FROMADDRESS(address)|FROMNUMBER(number)|SKIP(number)] [OUTFILE(ddname)] [TOKEY(key)|TOADDRESS(address)|TONUMBER(number)|COUNT(number)]항목 설명 INFILE|INDATASET
PRINT 명령을 이용하여 내용을 출력할 데이터셋을 지정한다.
INFILE을 이용해서 지정하는 경우 JCL을 통해 미리 할당된 ddname을 지정해야 한다.
INDATASET을 이용해서 지정하는 경우 KQCAMS에서 직접 데이터셋을 할당하며 배타적(DISP=OLD) 할당을 한다.
CHARACTER|
DUMP|
HEX
PRINT 출력내용의 포맷을 지정한다.
-
CHARACTER : 스트링 형태로 레코드의 내용을 출력한다.
-
DUMP : 오른쪽에는 16진수로 왼쪽에는 스트링 형태를 나란히 출력한다.
-
HEX : 16진수 형태로 출력한다.
아무런 포맷도 지정하지 않은 경우는 기본적으로 DUMP 포맷으로 출력한다.
FROMKEY|
FROMADDRESS|
FROMNUMBER|SKIP
PRINT문은 REPRO문과 비슷한 파라미터를 통해서 사용자가 출력할 레코드의 범위를 지정할 수 있다. 각 파라미터의 의미는 바로 뒤에 설명되는 REPRO 명령의 해당 파라미터와 동일하다.
OUTFILE
SYSPRINT가 아닌 다른 DD에 PRINT 결과를 출력할 경우에 사용한다.
PRINT 명령을 통해서 출력한 데이터셋의 내용을 저장할 별도의 데이터셋을 지정하고 JCL을 통해 미리 할당된 ddname을 지정해야 한다.
이 파라미터를 생략하면 기본적으로 PRINT 명령은 SYSPRINT로 출력한다.
TOKEY|TOADDRESS|TONUMBER|COUNT
PRINT는 REPRO와 비슷한 파라미터를 통해서 출력할 레코드의 범위를 사용자가 지정할 수 있다. 각 파라미터의 의미는 REPRO 명령의 해당 파라미터와 동일하다.
다음은 TEST.KSDS1에 저장된 레코드를 DUMP 포맷으로 출력하는 예이다. 출력되는 레코드의 범위는 키 값이 0000000099인 첫 레코드부터 10개이다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //PRINT EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * PRINT INDATASET(TEST.KSDS1) DUMP - FROMKEY(0000000099) COUNT(10) /* //다음은 위의 JCL을 실행한 결과, SYSPRINT에 출력된 내용이다.
KEY OF RECORD = 30303030303030303939 0000: 3030 3030 3030 3030 3939 7265 636F 7264 *0000000099record* 0010: 3030 3030 3030 3030 3939 *0000000099 * KEY OF RECORD = 30303030303030313030 0000: 3030 3030 3030 3031 3030 7265 636F 7264 *0000000100record* 0010: 3030 3030 3030 3031 3030 *0000000100 * KEY OF RECORD = 30303030303030313031 0000: 3030 3030 3030 3031 3031 7265 636F 7264 *0000000101record* 0010: 3030 3030 3030 3031 3031 *0000000101 * KEY OF RECORD = 30303030303030313032 0000: 3030 3030 3030 3031 3032 7265 636F 7264 *0000000102record* 0010: 3030 3030 3030 3031 3032 *0000000102 * KEY OF RECORD = 30303030303030313033 0000: 3030 3030 3030 3031 3033 7265 636F 7264 *0000000103record* 0010: 3030 3030 3030 3031 3033 *0000000103 * KEY OF RECORD = 30303030303030313034 0000: 3030 3030 3030 3031 3034 7265 636F 7264 *0000000104record* 0010: 3030 3030 3030 3031 3034 *0000000104 * KEY OF RECORD = 30303030303030313035 0000: 3030 3030 3030 3031 3035 7265 636F 7264 *0000000105record* 0010: 3030 3030 3030 3031 3035 *0000000105 * KEY OF RECORD = 30303030303030313036 0000: 3030 3030 3030 3031 3036 7265 636F 7264 *0000000106record* 0010: 3030 3030 3030 3031 3036 *0000000106 * KEY OF RECORD = 30303030303030313037 0000: 3030 3030 3030 3031 3037 7265 636F 7264 *0000000107record* 0010: 3030 3030 3030 3031 3037 *0000000107 * KEY OF RECORD = 30303030303030313038 0000: 3030 3030 3030 3031 3038 7265 636F 7264 *0000000108record* 0010: 3030 3030 3030 3031 3038 *0000000108 * PRINT 10 record(s) KQCAMS: PRINT OK
-
-
REPRO
DEFINE 명령을 통해서 데이터셋이 이미 정의되어 있다면 REPRO 명령을 이용해서 VSAM과 Non-VSAM 데이터셋의 내용을 다른 데이터셋에 저장할 수 있다. 이 명령에 사용되는 VSAM 데이터셋은 카탈로그에 등록되어 있어야 하지만 Non-VSAM 데이터셋의 경우는 카탈로그에 등록되어 있지 않아도 된다.
Mainframe의 카탈로그는 일반적으로 하나의 KSDS 클러스터에 저장되어 있기 때문에 REPRO 명령은 카탈로그 내용 자체를 복사하는 용도로 사용될 수 있다.
REPRO 명령을 이용하지 않고 일반적인 애플리케이션을 이용해서 레코드를 데이터셋에 저장하는 경우도 매우 일반적이나 REPRO 명령은 레코드의 내용에 상관하지 않고 주로 관리목적으로 데이터셋을 복사하는 용도로 사용된다.
REPRO 명령어 구문은 다음과 같다.
REPRO {INFILE(ddname)|INDATASET(entryname)} {OUTFILE(ddname)|OUTDATASET(entryname)} [ENTRIES(entryname [entryname...])|LEVEL(level)] [FROMKEY(key)|FROMADDRESS(address)|FROMNUMBER(number)|SKIP(number)] [MERGECAT|NOMERGECAT] [REPLACE|NOREPLACE] [REUSE|NOREUSE] [TOKEY(key)|TOADDRESS(address)|TONUMBER(number)|COUNT(number)]항목 설명 INFILE|INDATASET
복사할 원본 데이터셋을 지정한다.
INFILE의 경우 JCL을 통해서 명시된 ddname을 값으로 지정해야 하는 반면 INDATASET 파라미터를 사용하는 경우에는 데이터셋의 카탈로그에 등록된 엔트리 이름을 지정해야 한다.
INDATASET 파라미터를 이용해서 지정한 원본 데이터셋은 배타적으로(DISP=OLD) 할당된다.
OUTFILE|OUTDATASET
원본 데이터셋을 복사한 후 저장할 대상 데이터셋을 지정한다.
OUTFILE 파라미터의 값으로는 ddname을 지정해야 하며, OUTDATASET 파라미터의 값으로는 카탈로그된 엔트리 이름을 지정해야 한다.
OUTDATASET 파라미터를 이용해서 지정한 대상 데이터셋은 배타적으로(DISP=OLD) 할당된다.
ENTRIES|LEVEL
REPRO 명령을 이용하여 카탈로그를 복사하는 경우에 복사 대상이 되는 카탈로그 엔트리명을 지정한다. 이 경우 2개의 카탈로그 사이에 카탈로그 엔트리 이름들만 복사된다. 실제 카탈로그 엔트리가 가리키는 데이터셋에 대한 복사를 의미하지는 않는다.
-
ENTRIES : 카탈로그에 존재하는 엔트리 이름 중에서 지정된 entryname과 이름이 일치하고 세그먼트 개수도 일치하는 이름만이 명령의 대상으로 지정된다.
-
LEVEL : 카탈로그에 존재하는 엔트리 이름 중에서, 지정된 entryname과 이름의 앞부분이 일치하는 이름이 명령의 대상으로 지정된다. 즉, 사용자가 지정한 entryname의 세그먼트 개수보다 많은 세그먼트 개수를 갖는 이름들도 명령의 대상으로 지정된다.
ENTRIES와 LEVEL의 사용 예는 다음과 같다.
-
카탈로그가 다음의 엔트리 이름들을 가지고 있는 경우
1. A.A.B 2. A.B.B 3. A.B.B.C 4. A.B.B.C.C 5. A.C.C 6. A.D 7. A.E 8. A
-
ENTRIES(A.*)를 지정한 경우, 6, 7이 명령의 대상으로 선택된다.
-
ENTRIES(A.*.B)를 지정한 경우, 1, 2가 명령의 대상으로 선택된다.
-
LEVEL(A.*.B)를 지정한 경우, 1, 2, 3, 4가 명령의 대상으로 선택된다.
-
LEVEL(A)를 지정한 경우, 1,2,3,4,5,6,7이 모두 명령의 대상으로 선택된다.
-
애스터리스크(*)는 해당 세그먼트의 모든 이름과 일치한다.
-
FROMKEY|
FROMADDRESS|
FROMNUMBER|SKIP
데이터셋 전체를 모두 복사하지 않고 해당 데이터셋의 일부 레코드만을 복사하기 위해 복사할 대상을 한정한다.
각각 특정 키와 주소 그리고 레코드 번호 이후의 레코드를 대상으로 복사하고, SKIP 파라미터는 첫 레코드부터 number개의 레코드는 복사하지 않고 number개 다음 레코드부터 복사작업의 대상으로 한다. 즉, 복사작업의 시작이 되는 레코드를 지정한다.
MERGECAT|
NOMERGECAT
REPRO 명령으로 일반 데이터셋 이외에도 카탈로그를 담고 있는 특수한 데이터셋을 대상으로 복사작업을 수행할 수 있다.
-
MERGECAT : 소스 카탈로그의 레코드를 타깃 카탈로그로 복사한 후에 소스 카탈로그 상에서 레코드를 제거한다.
-
NOMERGECAT : 단순히 복사만 진행되고 원본 카탈로그에서 카탈로그 레코드는 삭제되지 않는다.
이 파라미터가 생략된 경우에는 NOMERGECAT가 기본값으로 사용된다. NOMERGECAT을 지정하는 경우 타깃 카탈로그는 비어 있어야 한다.
REPLACE|NOREPLACE
소스 데이터셋을 타깃 데이터셋으로 복사하는 과정에서 타깃 데이터셋에 이미 동일한 레코드가 있는 경우의 처리방법을 지정한다.
-
REPLACE : 기존의 레코드를 새로운 레코드로 대체한다.
-
NOREPLACE : 중복 레코드가 발견되었다는 에러 메시지만 나타나고 타깃 데이터셋의 중복 레코드에 복사하지 않는다.
생략할 경우 기본 값은 NOREPLACE이다.
REUSE|NOREUSE
카탈로그가 아닌 VSAM 데이터셋이 타깃 데이터셋인 경우에 사용한다.
-
REUSE : 해당 타깃 데이터셋에 이미 레코드가 들어있더라도 맨 처음부터 레코드를 추가한다 (HURBA를 0인 상태로 열고 쓰기동작을 한다).
-
NOREUSE : 타깃 데이터셋의 마지막 레코드 이후부터 레코드를 추가하여 기존에 있던 데이터셋의 레코드를 놔둔 상태로 타깃 데이터셋에 레코드를 복사한다.
기존 레코드를 REUSE한다기보다 데이터셋 레코드를 저장하는데 사용되는 공간을 REUSE한다.
TOKEY|TOADDRESS
TONUMBER|COUNT
복사작업의 대상이 되는 레코드를 제한한다. 복사작업의 대상이 되는 마지막 레코드를 지정한다.
다음은 VSAM.KSDS1 데이터셋의 50001번 레코드부터 10000개의 레코드를 VSAM.KSDS2 데이터셋으로 복사하는 예이다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //REPRO EXEC PGM=KQCAMS //INDD DD DSN=VSAM.KSDS1,DISP=(OLD,KEEP) //OUTDD DD DSN=VSAM.KSDS2,DISP=SHR //SYSPRINT DD SYSOUT=* //SYSIN DD * REPRO INFILE(INDD) - OUTFILE(OUTDD) - SKIP(50000) COUNT(10000) /* //
-
-
VERIFY
애플리케이션에서 VSAM 데이터셋을 개방하고 사용하는 과정에서 비정상적인 종료에 의해서 종료처리가 정확하게 되지 않은 경우 해당 VSAM 데이터셋이 카탈로그에 기록되는 메타정보를 부정확한 값으로 기록할 수 있다.
이러한 이유로 카탈로그에 문제가 발생한 경우 VERIFY 명령은 문제가 되는 VSAM 데이터셋에 대해서 올바른 메타정보를 가지고 있는지 확인하고, 지정된 데이터셋에 대한 카탈로그 정보가 잘못된 경우 올바른 값으로 갱신한다.
VERIFY 명령은 VSAM 데이터셋에 대해서만 동작한다.
VERIFY 명령어 구문은 다음과 같다.
VERIFY FILE(ddname)|DATASET(entryname)
항목 설명 FILE|DATASET
VERIFY 명령의 대상이 되는 데이터셋을 지정한다.
FILE을 사용하는 경우 JCL을 통해 할당된 데이터셋의 ddname을 지정해야 한다.
DATASET을 이용하여 지정하는 경우는 KQCAMS에서 지정된 데이터셋을 직접 할당하며 공유(DISP=SHR) 할당을 한다.
다음은 TEST.CLUS1 데이터셋의 카탈로그 정보를 확인하는 예이다.
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //VSTEP EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //TESTDD DD DSN=TEST.CLUS1,DISP=OLD //SYSIN DD * VERIFY FILE(TESTDD) /* //
12.4. 보조 명령어
한 번의 KQCAMS 실행으로 여러 개의 KQCAMS 명령을 수행할 수 있다.
보조 명령어(Modal command)는 여러 개의 KQCAMS 명령을 수행하기 위해서 필요한 기능을 제공하는 명령어로 실제로 카탈로그 엔트리나 오브젝트에 대해 처리하는 기능 명령어와 구분된다.
|
현재 KQCAMS의 보조 명령어 중 PARM은 지원하지 않는다. |
-
IF-THEN-ELSE
실행된 명령의 결과 코드 값(LASTCC 혹은 MAXCC)에 따라서 다음에 실행할 명령을 분기하기 위해서 사용된다. IF와 THEN 사이에는 조건분기할 때 평가되는 조건을 지정해야 한다. 조건은 컨디션 코드(Condition Code)와 특정 상수의 비교를 통해서 기술한다.
예를 들어 LASTCC > 8라고 지정하면 컨디션 코드 변수 중의 하나인 LASTCC 값이 8보다 큰 경우를 의미한다.
IF-THEN-ELSE 명령어 구문은 다음과 같다.
IF {Condition Code} {operator} {number} THEN[command| DO command set END] [ELSE[command| DO command set END]]Condition Code에 지정 가능한 값과 의미는 다음과 같다.
값 설명 LASTCC
가장 최근에 실행된 명령의 실행 결과값을 저장하는 KQCAMS에서 사용하는 변수이다. 성공적인 경우의 LASTCC는 0의 값을 갖고, 무시할 수 있는 경고가 발생한 경우의 값은 4이다. 심각한 문제가 발생한 경우 더 큰 값을 갖게 된다.
MAXCC
현재 실행 중인 명령보다 앞서서 실행된 명령의 실행 결과 값 중에서 가장 큰 값을 저장하는데 사용하는 변수이다.
Operator
컨디션 코드의 값을 평가하기 위한 연산자이다.
지정 가능한 값과 의미는 하단의 "참고"에 있는 비교연산자 표를 참고한다.
THEN 문에는 IF 문이 참인 경우 실행할 KQCAMS 명령을 기술하고, ELSE 문에는 IF 문이 거짓인 경우 실행할 명령을 기술한다. 만약 IF 문이 거짓일 경우 실행할 명령이 없다면 ELSE문을 생략할 수 있다.
IF-THEN-ELSE 구문은 조건에 따라서 다른 명령을 수행하는 하나의 KQCAMS 명령으로 간주된다. 따라서 IF-THEN-ELSE 구문을 여러 라인에 걸쳐서 기술하는 경우는 하이픈(-)을 적절히 사용해야 한다.
다음은 LASTCC의 값이 8과 동일한 경우, MAXCC에 0을 설정하는 프로그램의 일부분을 예로 보여준다. 실제 IF-THEN 문이 동작하는 것을 보여주기 위해서 LASTCC를 8로 설정했으며 IF-THEN 문이 실행될 때는 LASTCC 값이 8이므로 THEN 뒤의 SET MAXCC-0이 실행된다. 이 상태에서 KQCAMS를 종료하면 최종적인 MAXCC 값을 보고하고 종료하므로 실행된 결과를 확인할 수 있다.
SET LASTCC=8 IF LASTCC=8 THEN SET MAXCC=0
다음은 LASTCC의 값이 4보다 큰 경우 TEST.SDS1의 엔트리 정보를 가져오고, LASTCC가 4보다 크지 않은 경우 TEST.SDS2의 엔트리 정보를 가져오는 예이다. 일반적으로 SET LASTCC의 위치에 다른 KQCAMS 명령어를 실행하여 그 결과에 의해서 LASTCC가 설정되고, 그 결과에 따라서 조건적으로 명령을 실행한다. 본 예제에서는 IF-THEN-ELSE 문의 동작을 테스트하기 위해 강제로 IF문 전에 LASTCC의 값을 0으로 설정하였다. IF 문의 결과에 따라 TEST.SDS2가 LISTCAT된다.
SET LASTCC=0 IF LASTCC > 4 - THEN - LISTCAT ENT(TEST.SDS1) ELSE - LISTCAT ENT(TEST.SDS2)
-
Null
Null은 아무 동작도 발생하지 않는 문법적인 용도의 명령으로 다음과 같은 2가지 목적으로 사용된다.
-
IF-THEN-ELSE 구문의 문법에 어긋나지 않고 THEN이나 ELSE에 아무런 명령도 지정하지 않을 경우에 사용한다.
-
Null이 IF-THEN-ELSE 구문 외에서 사용된 경우는 빈 라인으로 처리된다.
THEN이나 ELSE 뒤에서 라인을 변경하는 경우 라인이 계속 이어지는 것을 의미하는 하이픈(-)을 지정하지 않는다. 하이픈(-)을 지정하면 KQCAMS는 THEN이나 ELSE문 다음에 명령이 있는 것으로 가정하고 처리하기 때문에 의도한대로 명령의 분기가 되지 않는다.
다음은 LASTCC가 4보다 큰 경우에 수행하는 명령은 없으며, LASTCC가 4보다 작은 경우에는 TEST.SDS2의 엔트리 정보를 가져오는 예이다.
SET LASTCC=0 IF LASTCC > 4 - THEN ELSE LISTCAT ENT(TEST.SDS2)
-
-
SET
MAXCC나 LASTCC의 값을 강제로 특정한 값으로 설정하는데 사용한다. 주로 특정 경고 수준의 컨디션 코드를 무시하고 JCL에서 KQCAMS 이후의 STEP을 계속 실행하기 위한 용도로 사용된다.
다음은 LASTCC의 값이 8과 동일한 경우 MAXCC의 값을 0으로 강제 설정하는 예이다.
DEL STEP에서 TEST.SDS1이 없는 경우 DEL STEP은 반환코드 8을 반환하고 종료하므로 DEF STEP은 수행되지 않는다. TJES의 설정이나 JOB에 기술된 COND에 따라 달라질 수 있지만, 반환코드가 8인 경우 DEF STEP을 처리하지 않고 JOB이 ABEND 처리되는 경우를 방지하려면 MAXCC를 0으로 강제 설정함으로써 뒤따르는 DEF STEP이 실행되게 할 수 있다.
//DEL EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * DELETE TEST.SDS1 IF LASTCC=8 THEN SET MAXCC=0 /* //DEF EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * DEFINE NONVSAM (NAME(TEST.SDS1) VOLUMES(100000)) /* //
-
CANCEL
CANCEL 명령어를 만나면 KQCAMS의 실행이 종료되어 CANCEL 명령 이후의 나머지 명령은 처리되지 않는다.
다음 예제는 LASTCC가 4인 경우 다음 THEN 명령을 수행하는 중 CANCEL이 실행되어 KQCAMS의 실행을 종료하는 프로그램의 일부이다.
LISTCAT ENTRIES(MUST.EXIST.SDS) IF LASTCC=4 THEN CANCEL ...
LISCAT으로 지정한 카탈로그 엔트리가 존재하지 않는 경우 컨디션 코드는 4이다. 컨디션 코드가 4인 경우는 메시지 레벨 조건 코드이므로 다음 KQCAMS 명령을 계속 실행하게 된다.
앞의 예제는 MUST.EXIST.SDS이라는 데이터셋이 없는 경우 더 이상 다음 명령을 실행하지 않고 곧 바로 IF 조건이 만족하는 경우 CANCEL 명령을 실행하여 KQCAMS의 실행을 종료한다.
12.5. 비기능 명령어
KQCAMS의 동작을 위해 실제 기능은 하지 않으나 에러가 발생하지 않도록 처리되는 명령이다.
-
BLDINDEX
BLDINDEX 명령은 본래 기존에 존재하는 데이터셋에 대한 보조 인덱스를 구성하는 명령이다. BLDINDEX 명령은 내부적으로 보조 인덱스 클러스터에 하나의 보조 키와 다수 개의 기본 키로 구성되는 레코드를 적재하는 역할을 담당한다.
OpenFrame에서는 데이터셋의 보조 인덱스 구성을 Tibero의 인덱스 기능을 통해 구현하고 있으므로, 이 명령은 실제로 아무 행동도 수행하지 않는다.
BLDINDEX 명령어 구문에서 지정할 수 있는 파라미터는 다음과 같다.
BLDINDEX {INFILE(ddname)|INDATASET(entryname)} {OUTFILE(ddname)|OUTDATASET(entryname)} [CATALOG(catname)]항목 설명 INFILE|
INDATASET
보조 인덱스를 구성하는데 사용할 베이스 클러스터를 지정한다.
-
INFILE : KQCAMS 호출 전에 실행환경에 의해서 미리 할당된 데이터셋을 사용하는 경우에는 ddname을 사용한다.
-
INDATASET : KQCAMS 자체적으로 데이터셋을 할당하는 경우에는 entryname을 사용한다. INDATASET 파라미터를 이용해서 지정한 베이스 클러스터는 배타적으로(DISP=OLD) 할당된다.
OUTFILE|
OUTDATASET
BLDINDEX 결과로 구성되는 보조 인덱스 클러스터를 지정한다. BLDINDEX 전에 보조 인덱스는 미리 DEFINE되어야 한다.
-
OUTFILE : KQCAMS 호출 전에 실행환경에 의해서 미리 할당된 데이터셋을 사용하는 경우에는 ddname을 사용한다.
-
OUTDATASET : KQCAMS 자체적으로 데이터셋을 할당하는 경우에는 entryname을 사용한다. OUTDATASET 파라미터를 이용해서 지정한 보조 인덱스 클러스터는 배타적으로(DISP=OLD) 할당된다.
CATALOG
entryname으로 지정된 카탈로그 엔트리를 찾을 때 사용할 카탈로그를 명시적으로 지정한다. 지정하지 않는 경우에는 카탈로그 검색 순서에 따라 결정된다.
다음은 VSAM.KSDS1의 보조 인덱스인 VSAM.AIX1을 구성하는 예이다.
//JOB03 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //BLDAIX EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //BASE DD DSN=VSAM.KSDS1,DISP=OLD //AIX DD DSN=VSAM.AIX1,DISP=OLD //SYSIN DD * BLDINDEX INFILE(BASE) - OUTFILE(AIX) /* // -
-
EXAMINE
EXAMINE 명령은 KSDS의 인덱스와 데이터 영역의 무결성을 분석하고 그 결과를 출력하는 명령이다.
OpenFrame에서 이 명령은 실제로 아무 동작도 수행하지 않는다.
EXAMINE 명령어 구문에서 지정할 수 있는 파라미터는 다음과 같다.
EXAMINE {NAME(clustername)} [{INDEXTEST|NOINDEXTEST}] [{DATATEST|NODATATEST}] [ERRORLIMIT(value)]항목 설명 NAME
무결성 검사를 수행할 KSDS 또는 사용자 카탈로그 명칭을 지정한다.
INDEXTEST|
NOINDEXTEST
지정된 클러스터의 인덱스 컴포넌트에 대해 무결성 검사 수행 여부를 결정한다.
-
INDEXTEST : 인덱스 컴포넌트의 무결성 검사를 수행한다. (기본값)
-
NOINDEXTEST : 인덱스 컴포넌트의 무결성 검사를 수행하지 않는다.
DATATEST|
NODATATEST
지정된 클러스터의 데이터 컴포넌트에 대해 무결성 검사 수행 여부를 검사한다.
-
DATATEST : 데이터 컴포넌트의 무결성 검사를 수행한다.
-
NODATATEST : 데이터 컴포넌트의 무결성 검사를 수행하지 않는다. (기본값)
ERRORLIMIT
명령 수행 결과로 출력될 오류 제한 개수를 value로 지정한다.
다음은 VSAM.KSDS1에 대해 EXAMINE 명령을 수행하는 예이다.
//JOB EXEC PGM=KQCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * EXAMINE - NAME(VSAM.KSDS1) - INDEXTEST - DATATEST - ERRORLIMIT(350) /* -
12.6. 관련 환경설정
KQCAMS 관련 환경설정은 OpenFrame 환경설정의 idcams 서브젝트에서 한다. 설정 내용을 변경하여 KQCAMS의 몇 가지 동작을 사용자의 요구에 맞게 조정할 수 있다.
|
환경설정 항목에 대한 자세한 내용은 OpenFrame Batch "환경설정 안내서"를 참고한다. |
[참고]
다음은 KQCAMS의 명령 중에서 실제 기능은 하지 않으나 에러가 발생하지 않도록 처리되는 파라미터에 대한 표이다.
| 명령어 | 파라미터 |
|---|---|
ALTER |
[ACCOUNT(account–info)] |
[ADDVOLUMES(volser[ volser…])] |
|
[BUFFERSPACE(size)] |
|
[BUFND(number)] |
|
[BUFNI(number)] |
|
[BWO(TYPECICS|TYPEIMS|NO)] |
|
[CCSID(value)] |
|
[CODE(code)] |
|
[ECSHARING|NOECSHARING] |
|
[ERASE|NOERASE] |
|
[EXCEPTIONEXIT(entrypoint)] |
|
[FILEDATA(TEXT|BINARY)] |
|
[FREESPACE(CI-percent[ CA-percent])] |
|
[FRLOG(NONE[ REDO])] |
|
[INHIBIT|UNINHIBIT] |
|
[KEYS(length offset)] |
|
[LOCK|UNLOCK] |
|
[LOG(NONE|UNDO|ALL)] |
|
[LOGSTREAMID(logstream)] |
|
[MANAGEMENTCLASS(class)] |
|
[NULLIFY([AUTHORIZATION(MODULE|STRING)] [BWO] [CODE] [EXCEPTIONEXIT] [LOG] [LOGSTREAMID] |
|
[RECORDSIZE(average maximum)] |
|
[REMOVEVOLUMES(volser[ volser…])] |
|
[REUSE|NOREUSE] |
|
[ROLLIN] |
|
[SHAREOPTIONS(crossregion[ crosssystem])] |
|
[STORAGECLASS(class)] |
|
[STRNO(number)] |
|
[TYPE(LINEAR)] |
|
[UNIQUEKEY|NONUNIQUEKEY] |
|
[UPDATE|NOUPDATE] |
|
[UPGRADE|NOUPGRADE] |
|
[WRITECHECK|NOWRITECHECK] |
|
DEFINE |
[ACCOUNT(account–info)] |
[BUFFERSPACE(size)] |
|
[BWO(TYPECICS|TYPEIMS|NO)] |
|
[ERASE|NOERASE] |
|
[EXCEPTIONEXIT(entrypoint)] |
|
[FILE(ddname)] |
|
[FREESPACE(CI-percent[ CA-percent])] |
|
[FRLOG(NONE[| REDO])] |
|
[LOG(NONE|UNDO|ALL)] |
|
[LOGSTREAMID(logstream)] |
|
[MODEL(entryname[ catname])] |
|
[REUSE|NOREUSE] |
|
[SHAREOPTIONS(crossregion[ crosssystem])] |
|
[SPEED|RECOVERY] |
|
[WRITECHECK|NOWRITECHECK]) |
|
[UPDATE|NOUPDATE] |
|
[CYLINDERS(primary[secodnary])] |
|
[KILOBYTES(primary[secodnary])] |
|
[MEGABYTES(primary[secodnary])] |
|
[RECORDS(primary[secodnary])] |
|
[TRACKS(primary[secodnary])] |
|
[CONTROLINTERVALSIZE(size)] |
|
DELETE |
[LIBRARYENTRY|NVR| PAGESPACE|OLUMEENTRY|VVR] |
[ERASE|NOERASE] |
|
[FORCE|NOFORCE] |
|
[PURGE|NOPURGE] |
|
[RECOVERY|NORECOVERY] |
|
[SCRATCH|NOSCRATCH] |
|
EXPORT |
[CIMODE|RECORDMODE] |
[ERASE|NOERASE] |
|
[INHIBITSOURCE|NOINHIBITSOURCE] |
|
[INHIBITTARGET|NOINHIBITTARGET] |
|
[PURGE|NOPURGE] |
|
[TEMPORARY|PERMANENT] |
|
IMPORT |
[ALIAS|NOALIAS] |
[ERASE|NOERASE] |
|
[LOCK|UNLOCK] |
|
[OBJECTS ([FILE(ddname)])] |
|
[PURGE|NOPURGE] |
|
[SAVRAC|NOSAVRAC] |
|
LISTCAT |
[LIBRARYENTRIES(libent)] |
[PAGESPACE] |
|
[VOLUMEENTRIES(volent)] |
|
[EXPIRATION(days)] |
|
[FILE(ddname)] |
|
[LIBRARY(libname)] |
|
[OUTFILE(ddname)] |
|
[DBCS] |
|
[INSERTSHIFT((offset1 offset2)[(offset1 offset2 )…])|INSERTALL] |
|
[SKIPDBCSCHECK((offset1 offset2) [(offset1 offset2)…])|NODBCSCHECK] |
|
REPRO |
[DBCS] |
[ERRORLIMIT(value)] |
|
[FILE(ddname)] |
|
[INSERTSHIFT((offset1 offset2)[(offset1 offset2 )…])| INSERTALL] |
|
[SKIPDBCSCHECK((offset1 offset2)[(offset1 offset2 )…])| NODBCSCHECK] |
|
[VOLUMEENTRIES(entryname)] [ENCIPHER ({EXTERNALKEYNAME(keyname)|INTERNALKEYNAME(keyname)|PRIVATEKEY} [CIPHERUNIT(number|1)] [DATAKEYFILE(ddname)|DATAKEYVALUE(value)] [SHIPKEYNAMES(keyname[ keyname…])] [STOREDATAKEY|NOSTOREDATAKEY] [STOREKEYNAME(keyname)] [USERDATA(value)])] |
|
[DECIPHER({DATAKEYFILE(ddname)| DATAKEYVALUE(value)|SYSTEMKEY} [SYSTEMDATAKEY(value)] [SYSTEMKEYNAME(keyname)])] |
DEFINE 서브 명령어의 경우 다음과 같다.
| 서브 명령어 | 파라미터 |
|---|---|
ALIAS |
(SYMBOLICRELATE(entryname)) |
ALTERNATEINDEX |
(BUFFERSPACE(size)] |
[ERASE|NOERASE] |
|
[EXCEPTIONEXIT(entrypoint)] |
|
[FREESPACE(CI-percent[CA-percent]| 0 0)] |
|
[MODEL(entryname[catname])] |
|
[REUSE|NOREUSE] |
|
[SHAREOPTIONS(crossregion[crosssystem]| 1 3)] |
|
[SPEED|RECOVERY] |
|
[WRITECHECK|NOWRITECHECK]) |
|
[DATA ([ATTEMPTS(number)] [AUTHORIZATION(entrypoint[ string])] [BUFFERSPACE(size)] [CODE(code)] [ERASE|NOERASE] [EXCEPTIONEXIT(entrypoint)] [FREESPACE(CI-percent[CA-percent])] [MODEL(entryname[catname])] [REUSE|NOREUSE] [SHAREOPTIONS(crossregion[crosssystem])] [SPEED|RECOVERY] [WRITECHECK|NOWRITECHECK])] |
|
[INDEX ([ATTEMPTS(number)] [AUTHORIZATION(entrypoint[string])] [CODE(code)] [EXCEPTIONEXIT(entrypoint)] [MODEL(entryname[catname])] [REUSE|NOREUSE] [SHAREOPTIONS(crossregion[crosssystem])] [WRITECHECK|NOWRITECHECK])] |
|
CLUSTER |
([ACCOUNT(account–info)] |
[BUFFERSPACE(size)] |
|
[BWO(TYPECICS|TYPEIMS|NO)] |
|
[ERASE|NOERASE] |
|
[EXCEPTIONEXIT(entrypoint)] |
|
[FREESPACE(CI-percent[CA-percent]|0 0)] |
|
[FRLOG(NONE[| REDO])] |
|
[LOG(NONE|UNDO|ALL)] |
|
[LOGSTREAMID(logstream)] |
|
[MODEL(entryname[catname])] |
|
[REUSE|NOREUSE] |
|
[SHAREOPTIONS(crossregion[crosssystem]|1 3)] |
|
[SPEED|RECOVERY] |
|
[WRITECHECK|NOWRITECHECK]) |
|
[DATA ([BUFFERSPACE(size)] [ERASE|NOERASE] [EXCEPTIONEXIT(entrypoint)] [FREESPACE(CI-percent[CA-percent])] [MODEL(entryname[catname])] [REUSE|NOREUSE] [SHAREOPTIONS(crossregion[crosssystem])] [SPEED|RECOVERY] [WRITECHECK|NOWRITECHECK])] |
|
[INDEX ([EXCEPTIONEXIT(entrypoint)] [MODEL(entryname[catname])] [REUSE|NOREUSE] [SHAREOPTIONS(crossregion[crosssystem])] [WRITECHECK|NOWRITECHECK])] |
|
GENERATIONDATAGROUP |
([SCRATCH|NOSCRATCH]) |
NONVSAM |
([COLLECTION] |
[FILESEQUENCENUMBERS(number[number…])]) |
|
PATH |
([MODEL(entryname[catname])]) |
USERCATALOG |
([BUFFERSPACE(size|3072)] |
[BUFND(number)] |
|
[BUFNI(number)] |
|
[ECSHARING|NOECSHARING] |
|
[FREESPACE(CI-percent[CA-percent ]|0 0)] |
|
[ICFCATALOG|VOLCATALOG] |
|
[LOCK|UNLOCK] |
|
[MODEL(entryname[catname])] |
|
[SHAREOPTIONS(crossregion[crosssystem]| 3 4)] |
|
[STRNO(number|2)] |
|
[WRITECHECK|NOWRITECHECK]) |
|
[DATA ([BUFFERSPACE(size)] [BUFND(number)] [FREESPACE(CI-percent[ CA-percent])] [WRITECHECK|NOWRITECHECK])] |
|
[INDEX ([BUFNI(number)] [WRITECHECK|NOWRITECHECK])] |
[비교연산자]
다음은 IF-THEN-ELSE 명령어의 operator 항목에서 쓰이는 비교연산자에 대한 표이다.
| 연산자 | 부호 | 의미 |
|---|---|---|
EQ |
= |
같다. |
LE |
<= |
작거나 같다. |
LT |
< |
작다. |
GT |
> |
크다. |
GE |
>= |
크거나 같다. |
NE |
!= |
같지 않다. |
12.7. 유의사항
컨디션 코드(Condition Code)는 KQCAMS가 각각의 명령을 실행한 결과가 정상인지 아니면 명령실행 중에 에러가 발생했는지를 나타내는 일종의 에러코드이다. 발생 가능한 컨디션 코드는 0, 4, 8, 12, 16이고 큰 값일수록 명령 실행에 중대한 문제가 있었음을 나타낸다. 각 컨디션 코드 값에 대한 설명은 다음과 같다.
| 코드 | 의미 |
|---|---|
0 |
명령을 정상적으로 처리한 경우 반환되는 코드이며 일부 정보성 메시지가 출력될 수 있다. |
4 |
명령이 완벽하게 처리되지 않았지만 이를 무시하고 추가적인 명령을 수행해도 영구적으로 에러를 발생시키지 않을 것이라고 판단되는 상태로, 추가적인 명령의 수행이 가능하며 경고성 메시지가 함께 출력된다. 예를 들어 LISCAT 명령이 실행될 때 사용자가 지정한 카탈로그 엔트리가 존재하지 않는 경우 컨디션 코드는 4로 설정되고 다음 메시지가 출력된다. KQCAMS: No specified catalog entry found: NOT.EXIST.SDS |
8 |
명령이 의미하는 동작의 일부를 수행하지 않았지만 결과적으로 사용자가 원하는 상태와 동일한 결과로 귀결되는 경우에 해당하는 상태로 추가적인 명령의 수행이 가능하다. 예를 들어 DELETE 명령에 지정한 데이터셋이 존재하지 않는 경우 실제로 DELETE 명령의 완전한 실행은 수행되지 않았지만 결과적으로 지정한 데이터셋이 없다는 상태는 동일하게 된다. 이 경우 추가적인 명령의 실행에 문제는 없으므로 컨디션 코드는 8로 설정되고 경고성 메시지가 출력된다. KQCAMS(WARNING): No such catalog entry - 'NOT.EXIST.SDS' |
12 |
명령의 수행 과정 중 에러가 있어서 꼭 수행되어야 하는 동작이나 기능을 완료할 수 없는 경우에 발생한다. 이러한 에러(logical error)는 동시에 지정할 수 없는 논리적으로 불일치하는 파라미터를 지정하는 경우이거나 꼭 지정되어야 하는 필수 파라미터가 생략된 경우 혹은 데이터셋의 키 길이, 레코드 크기 등으로 지정한 값이 올바르지 않을 때 발생한다. 이러한 상황이 발생한 경우 컨디션 코드는 12로 설정되고 에러 메시지가 출력된다. KQCAMS(ERROR): {error description or logical error code}
|
16 |
현재 명령을 수행하는 과정에서 심각한 에러가 발생하여 사용자가 지정한 나머지 명령을 실행할 수 없는 경우에 반환되는 컨디션 코드 값이다. 다음과 같은 경우에 해당 코드가 발생한다.
|
-
조건 코드 변수명 (LASTCC와 MAXCC)
KQCAMS는 LASTCC 및 MAXCC라는 변수에 컨디션 코드 값을 저장한다.
LASTCC에는 최근 실행한 명령의 컨디션 코드가 저장되고, MAXCC에는 기존에 발생한 컨디션 코드 중에서 가장 큰 값이 저장된다. LASTCC 및 MAXCC는 SET 명령을 이용해서 사용자가 직접 설정할 수 있다.
다음은 NOT.EXIST.SDS 데이터셋을 삭제한 후 LASTCC의 값이 8이면 강제적으로 MAXCC를 0으로 설정하는 예이다.
DELETE NOT.EXIST.SDS IF LASTCC = 8 THEN SET MAXCC=0 DEFINE ...