기타 유틸리티
본 장에서는 기타 유틸리티에 대해 기술한다.
1. 개요
다음은 기타 유틸리티 목록이다. 각 유틸리티에 대한 설명은 해당 절에서 자세하게 기술한다.
| 프로그램명 | 설명 |
|---|---|
데이터셋의 레코드별 차이점을 보여준다. |
|
SORT 유틸리티 프로그램을 이용하여 1개의 JOB STEP에서 복수의 데이터셋을 다양한 방법으로 출력한다. |
|
JCL에 기술된 내용이 정상적으로 실행되는지 확인하기 위해 사용하는 테스트용 유틸리티 프로그램이다. |
|
TSO 커맨드를 실행하고 Batch 애플리케이션에서 사용하는 데이터베이스로의 connection 처리를 담당한다. |
|
직접 엑세스 볼륨의 데이터셋을 복사한다. |
|
터미널에 입력하는 커맨드에 대한 약어를 지정한다. |
2. DSDIFF
데이터셋의 레코드별 차이점을 보여주는 유틸리티 프로그램이다.
OpenFrame 설치 후 또는 유틸리티나 라이브러리 등의 각종 모듈을 업데이트한 후에 실시하는 검증 테스트로서 수행 결과 데이터셋이 예상대로 생성되었는지 확인하기 위한 용도로 사용할 수 있다.
2.1. FD 설정
FD 설정 항목은 다음과 같다.
| 항목 | 설명 |
|---|---|
SYSIN FD |
비교 대상 데이터셋의 fdname 목록을 기술한다. 리스트의 구분자로 콤마(,)를 사용한다. 예) AA,BB,CC: AA와 BB 그리고 CC를 비교한다. |
TARGET FD |
비교할 데이터셋을 정의한다. 이 비교 데이터셋은 SYSIN FD에 기술한 fdname 목록에 포함되어야 한다. |
2.2. 명령어 설정
SYSIN FD에 기술하는 데이터셋 리스트의 구문은 다음과 같다.
fdname,fdname[fdname,....]
이와 같이 SYSIN FD에 데이터셋 리스트를 기술하는 것 외에 설정해야 하는 명령어는 없다.
2.3. 사용예제
다음은 U01, U02 FD 두 개의 레코드를 비교하여 차이점을 보여주는 예이다.
\DSDIFF EX DSDIFF \ FD LIST=DA,VOL=VOL001,TRK=10,SOUT=A \ FD COIN=* U01,U02 \ FD U01=DA,VOL=VOL001,FILE=OFTEST.SORT.U01 \ FD U02=DA,VOL=VOL001,FILE=OFTEST.SORT.U02 \ JEND
2.4. 유의사항
레코드 길이가 다르면 가장 짧은 레코드의 레코드 길이까지의 데이터가 모두 일치하더라도 서로 다른 레코드로 판단한다.
DSDIFF 유틸리티 프로그램을 실행한 결과는 다음과 같다.
-
정상적으로 실행한 경우
애플리케이션에서 받은 코드를 반환한다.
-
에러가 발생한 경우
해당 에러 메시지를 LIST FD에 출력하고 에러에 해당하는 코드를 반환한다.
DSDIFF 유틸리티 프로그램에서 발생할 수 있는 에러 코드는 다음과 같다.
코드 설명 20
레코드에서 한 개 이상의 차이가 있을 경우에 해당한다.
40
SYSIN으로 주어진 fdname이 존재하지 않거나 데이터셋 I/O 에러 등의 OpenFrame 혹은 UNIX 에러를 의미한다.
3. ICETOOL
SORT 유틸리티 프로그램을 이용하여 1개의 JOB STEP에서 여러 개의 데이터셋을 다양한 방법으로 출력하기 위해 사용하는 유틸리티 프로그램이다. TOOLIN FD로 주어진 명령어에 따라 SORT 유틸리티 프로그램을 이용하여 데이터를 처리한다.
ICETOOL 유틸리티 프로그램은 다음과 같은 주요기능을 제공한다.
-
정렬된 입력 데이터셋의 복사본을 생성한다.
-
수정되었거나 수정되지 않은 입력 데이터셋의 복사본을 생성한다.
-
수정되었거나 수정되지 않은 입력 데이터셋의 레코드 카운트를 출력한다.
-
문자와 숫자 필드값 또는 유일한 값이 발생한 총 횟수 등의 다양한 기준으로 입력 데이터셋을 포함하고 있는 출력 데이터셋을 생성한다.
-
서로 다른 포맷의 레코드 필드를 병합하여 하나 또는 여러 개의 레코드로 출력한다.
3.1. FD 설정
FD 설정 항목은 다음과 같다.
| 항목 | 설명 |
|---|---|
TOOLMSG |
ICETOOL의 출력 메시지를 저장한다. |
DFSMSG |
ICETOOL이 SORT 프로그램을 내부적으로 사용하면서 출력되는 메시지를 저장한다. |
TOOLIN |
ICETOOL 명령어를 기술한다. |
infd |
ICETOOL의 입력 데이터셋을 기술한다. TOOLIN에서 FROM(infd)를 통해 infd를 사용하도록 지정한다. |
outfd |
ICETOOL의 COPY, SELECT, SORT 수행에서 사용할 출력 데이터셋을 기술한다. TOOLIN에서 TO(outfd)를 통해 outFD를 사용하도록 지정한다. |
savefd |
ICETOOL의 SELECT 수행에서 사용할 출력 데이터셋을 기술한다. TOOLIN에서 DISCARD(savefd)를 통해 saveFD를 사용하도록 지정한다. |
countfd |
ICETOOL의 COUNT 수행에서 사용할 출력 데이터셋을 기술한다. |
xxxxCNTL |
ICETOOL에서 내부적으로 사용할 SORT 유틸리티 명령어를 기술한다. TOOLIN에서 USING xxxx를 통해 xxxxCNTL FD를 사용하도록 지정한다. |
3.2. 명령어 설정
본 절에서는 ICETOOL에서 설정 가능한 명령어에 대해 설명한다.
-
COPY
infd로 주어진 입력 데이터를 한 개 이상의 outfd로 복사한다. USING 절을 통해 xxxxCNTL을 사용하여 SORT 유틸리티를 구동할 수도 있다.
COPY 명령어의 구문은 다음과 같다.
COPY FROM(infd) TO(outfd,[outfd,...]) | USING(xxxx) | {TO(outfd,[outfd,....]) USING(xxxx)} [VSAMTYPE(x)] [SERIAL]항목 설명 FROM
COPY 문을 수행할 입력 데이터셋을 지정한다.
TO
COPY 문을 수행한 후 저장할 출력 데이터셋을 지정한다.
outfd에는 모두 동일한 결과가 저장된다.
TO와 USING은 동시에 기술될 수 있으며, 둘 중 하나는 반드시 기술되어야 한다.
USING
COPY에서 사용할 SORT 유틸리티 명령어를 기술한다.
USING이 있는 경우에는 반드시 xxxxCNTL FD를 기술해야 한다.
VSAMTYPE
실제 기능은 하지 않으나 에러를 발생시키지 않도록 지원하고 있다.
SERIAL
실제 기능은 하지 않으나 에러를 발생시키지 않도록 지원하고 있다.
-
COUNT
입력 데이터셋의 레코드 카운트를 출력한다. USING이 있는 경우에는 재편집된 뒤의 레코드 카운트를 출력한다.
COUNT 명령어의 구문은 다음과 같다.
COUNT FROM(infd) [USING(xxxx)] [EMPTY] [WRITE(countfd)] [TEXT('string')] [DIGITS(d)]항목 설명 FROM
COUNT 문을 수행할 입력 데이터셋을 지정한다.
USING
COUNT에서 사용할 SORT 유틸리티 명령어를 기술한다.
EMPTY
-
입력 데이터셋이 빈 데이터셋인 경우 RC=20을 리턴한다.
-
입력이 빈 데이터셋이 아닌 경우에는 RC=10을 리턴한다.
WRITE(countfd)
countfd를 지정한다. countfd는 레코드 카운트를 출력하는 데이터셋의 fdname을 의미한다. countfd FD의 포맷은 FB로만 지정이 가능하다.
TEXT('string')
countfd 데이터셋에 문자열을 출력한다. 레코드 카운트는 해당 문자열 뒤에 출력된다. TEXT는 WRITE가 있는 경우에만 사용할 수 있다.
DIGITS(d)
레코드 카운트가 몇 자리 수로 출력될지 지정한다.
DIGITS가 없는 경우에 기본값은 15이다.
-
-
SELECT
infd로 주어진 입력 데이터를 주어진 조건에 따라 필터하여 tofd에 저장하거나 필터를 통과하지 못한 데이터를 savefd에 저장할 수 있다.
SELECT 명령어의 구문은 다음과 같다.
SELECT FROM(infd) TO(outfd) | DISCARD(savefd) | {TO(outfd) DISCARD(savefd)} ON(p,m,f)[,ON(p,m,f),...] ALLDUPS | NODUPS | HIGHER(x) | LOWER(x) | EQUAL(x) | FIRST | LAST | FIRSTDUP | LASTDUP [VSAMTYPE(x)] [UZERO] [USING(xxxx)]항목 설명 FROM
입력 데이터셋 이름을 기술한다.
TO
필터된 레코드를 저장할 출력 데이터셋 이름을 기술한다.
DISCARD
필터 후 버려질 레코드를 저장할 데이터셋 이름을 기술한다.
ON
SELECT 문이 적용될 필드를 정의한다. p Byte부터 m Byte만큼 f 포맷에 대해 SELECT 문을 적용한다.
ALLDUPS
ON으로 지정된 필드의 값이 입력 데이터셋 내에서 중복되는 레코드만 저장한다.
NODUPS
ON으로 지정된 필드의 값이 입력 데이터셋 내에서 중복되지 않는 레코드만 저장한다.
HIGHER
ON으로 지정된 필드의 값이 입력 데이터셋 내에서 x번 초과로 나타나는 레코드만 저장한다.
LOWER
ON으로 지정된 필드의 값이 입력 데이터셋 내에서 x번 미만으로 나타나는 레코드만 저장한다.
EQUAL
ON으로 지정된 필드의 값이 입력 데이터셋 내에서 x번 나타나는 레코드만 저장한다.
FIRST
ON으로 지정된 필드의 값이 입력 데이터셋 내에서 유일한 레코드와 중복되는 레코드 중에서 위에서부터 첫번째 레코드만 저장한다.
LAST
ON으로 지정된 필드의 값이 입력 데이터셋 내에서 유일한 레코드와 중복되는 레코드 중에서 위에서부터 마지막 레코드만 저장한다.
FIRSTDUP
ON으로 지정된 필드의 값이 입력 데이터셋 내에서 중복되는 레코드 중에서 위에서부터 첫번째 레코드만 저장한다.
LASTDUP
ON으로 지정된 필드의 값이 입력 데이터셋 내에서 중복되는 레코드 중에서 위에서부터 마지막 레코드만 저장한다.
VSAMTYPE
실제 기능은 하지 않으나 에러를 발생시키지 않도록 지원하고 있다.
UZERO
실제 기능은 하지 않으나 에러를 발생시키지 않도록 지원하고 있다.
USING
SELECT 문에서 사용할 SORT 유틸리티 명령어를 기술한다.
-
SORT
입력 데이터셋을 정렬하여 하나 이상의 출력 데이터셋으로 출력한다. 입력 데이터셋을 정렬 및 재편집하기 위해 SORT 유틸리티를 호출한다.
SORT 명령어의 구문은 다음과 같다.
SORT FROM(infd) USING(xxxx) [TO(outfd,[outfd,...])] [VSAMTYPE(x)] [SERIAL]항목 설명 FROM
SORT 문을 수행할 입력 데이터셋을 지정한다.
USING
SORT 문에서 사용할 SORT 유틸리티 명령어를 기술한다. SORT에서는 USING이 반드시 명시되어야 하며 xxxxCNTL FD 문은 SORT 명령문을 포함해야 한다.
TO
SORT 문을 수행한 후 저장할 출력 데이터셋을 지정한다. outfd에는 모두 동일한 결과가 저장된다.
VSAMTYPE
실제 기능은 하지 않으나 에러를 발생시키지 않도록 지원하고 있다.
SERIAL
실제 기능은 하지 않으나 에러를 발생시키지 않도록 지원하고 있다.
-
SPLICE
베이스 레코드를 기준으로 하여 매칭되는 오버레이 레코드 필드로 덮어쓴다. 이 기능을 이용해 다른 형태의 여러 개의 입력 레코드들을 여러 정보를 가진 하나의 출력 레코드로 통합할 수 있다.
ON으로 레코드 매칭을 검사하여 매칭되는 레코드 중 첫 번째 레코드는 베이스 레코드가 되고 다른 레코드들은 오버레이 레코드가 된다(옵션이 지정되지 않은 경우에는 마지막 레코드가 오버레이 레코드가 된다).
오버레이 레코드에 WITH로 지정된 필드가 베이스 레코드의 필드를 덮어쓴다. WITH 필드를 제외한 베이스 레코드의 나머지 필드들은 그대로 유지된다. 결과적으로 출력 레코드는 베이스 레코드와 오버레이 레코드의 조합으로 이루어진다.
SPLICE FROM(infd) TO(outfd) ON(p,m,f)[,ON(p,m,f),...] WITH(p,m)[,WITH(p,m),...] [WITHALL] [KEEPNODUPS] [USING(xxxx)]항목 설명 FROM
입력 데이터셋 이름을 기술한다.
TO
통합된 레코드를 저장할 출력 데이터셋 이름을 기술한다.
ON
레코드 매칭이 적용될 필드를 정의한다. p Byte부터 m Byte만큼 f 포맷에 대해 매칭을 검토한다.
WITH
오버레이 레코드에서 지정한 필드의 위치와 길이만큼 베이스 레코드를 덮어쓴다. WITH를 여러 번 사용하여 여러 개의 필드를 덮어쓸 수 있다.
WITHALL
모든 오버레이 레코드에 대해 각각 베이스 레코드를 덮어쓴다. WITHALL이 없으면 마지막 오버레이 레코드만 베이스 레코드를 덮어쓴다.
KEEPNODUPS
매칭되지 않는 레코드들도 삭제되지 않고 출력되도록 한다. KEEPNODUPS가 명시되지 않으면 매칭되지 않는 레코드들은 삭제된다.
USING
SPLICE 문에서 사용할 SORT 유틸리티 명령어를 기술한다.
3.3. 사용예제
다음은 OFTEST.ICETOOL.IN00을 CPY1CNTL FD에 주어진 SORT 스크립트를 이용하여 OFTEST.ICETOOL.OUT00.COPY로 복사하는 예이다.
\ICECOPY EX ICETOOL \ FD ICEIN=DA,VOL=VOL001,FILE=OFTEST.ICETOOL.IN00 \ FD ICEOUT=DA,VOL=VOL001,FILE=OFTEST.ICETOOL.OUT00.COPY \ FD TOOLMSG=DA,VOL=VOL001,TRK=10,SOUT=A \ FD DFSMSG=DA,VOL=VOL001,TRK=10,SOUT=A \ FD LIST=DA,VOL=VOL001,TRK=10,SOUT=A \ FD TOOLIN=* COPY FROM(ICEIN) TO(ICEOUT) USING(CPY1) \ FD CPY1CLTL=* SORT FIELDS=COPY \ JEND
다음은 OFTEST.ICETOOL.IN00을 CPY1CNTL FD에 주어진 SORT 스크립트를 이용하여 재편집 후 레코드 카운트를 OFTEST.ICETOOL.OUT01.COUNT로 출력하는 예이다. 이때 레코드 카운트는 'OUTPUT RECORD COUNT = ' 뒤에 9자리의 수로 출력된다.
\ICECOUNT EX ICETOOL
\ FD ICEIN=DA,VOL=VOL001,FILE=OFTEST.ICETOOL.IN00
\ FD CNT00=DA,VOL=VOL001,FILEOFTEST.ICETOOL.OUT01.COUNT
\ FD TOOLMSG=DA,VOL=VOL001,TRK=10,SOUT=A
\ FD DFSMSG=DA,VOL=VOL001,TRK=10,SOUT=A
\ FD LIST=DA,VOL=VOL001,TRK=10,SOUT=A
\ FD TOOLIN=*
COUNT FROM(ICEIN) USING(CPY1) WRITE(CNT00) -
TEXT('OUTPUT RECORD COUNT = ') DIGITS(9)
\ FD CPY1CNTL=*
SORT FIELDS=COPY
INCLUDE COND=(16,2,CH,EQ,C'08')
\ JEND
다음은 OFTEST.ICETOOL.IN01을 CPY1CNTL FD에 주어진 SORT 스크립트를 이용하여 OFTEST.ICETOOL.OUT01.ICECPY1과 OFTEST.ICETOOL.OUT01.ICECPY2로 복사하는 예이다.
OFTEST.ICETOOL.OUT01.ICECPY2에서 레코드의 16번째 Byte부터 2Byte (16~17Byte)를 문자키로 전체 데이터셋에서 중복되면 OFTEST.ICETOOL.OUT01.ICESAVE로 저장하고, 중복되지 않으면 OFTEST.ICETOOL.OUT01.ICETO에 저장한다.
\ICECOPY EX ICETOOL \ FD ICEIN=DA,VOL=VOL001,FILE=OFTEST.ICETOOL.IN01 \ FD ICECPY1=DA,VOL=VOL001,FILE=OFTEST.ICETOOL.OUT01.ICECPY1 \ FD ICECPY2=DA,VOL=VOL001,FILE=OFTEST.ICETOOL.OUT01.ICECPY2 \ FD ICETO=DA,VOL=VOL001,FILE=OFTEST.ICETOOL.OUT01.ICETO \ FD ICESAVE=DA,VOL=VOL001,FILE=OFTEST.ICETOOL.OUT01.ICESAVE \ FD TOOLMSG=DA,VOL=VOL001,TRK=10,SOUT=A \ FD DFSMSG=DA,VOL=VOL001,TRK=10,SOUT=A \ FD LIST=DA,VOL=VOL001,TRK=10,SOUT=A \ FD TOOLIN=* COPY FROM(ICEIN) TO(ICECPY1,ICECPY2) USING(CPY1) SELECT FROM(ICECPY2) TO(ICETO) DISCARD(ICESAVE) ON(16,2,CH) NODUPS \ FD CPY1CNTL=* SORT FIELDS=COPY \ JEND
4. IEFBR14
JCL에 기술된 내용이 정상적으로 실행되는지 확인하기 위해 사용하는 테스트용 유틸리티 프로그램이다.
실제로 유틸리티가 수행하는 처리는 없다. 즉, 아무런 처리도 하지 않는 빈 프로그램을 JOB STEP에서 실행해 봄으로써 JCL이 올바로 작성이 되었는지, JOB 환경에서 처리되어야 하는 FD 문의 처리 및 데이터셋의 할당과 같은 일이 정상적으로 수행이 되고 있는지 알아보기 위한 용도로 사용될 수 있다. 혹은 데이터셋을 신규로 생성하거나 삭제하는 처리만 수행하는 목적의 JOB STEP인 경우에도 사용할 수 있다.
5. KEQEFT01
데이터베이스를 사용하는 Batch 애플리케이션을 JCL로 실행하려고 할 때 애플리케이션이 실행되기 전에 데이터베이스 시스템으로 접속해주는 유틸리티 프로그램이다.
데이터베이스를 사용하는 업무용 COBOL 애플리케이션의 소스에 데이터베이스 시스템 접속에 필요한 시스템 이름, 사용자 이름, 패스워드 등과 같은 정보를 코딩하지 않고 데이터베이스 시스템 접속에 필요한 모든 정보는 KEQEFT01 유틸리티 프로그램의 입력 스크립트에 지정한다.
KEQEFT01 유틸리티 프로그램에서 사용하는 TSS 스크립트의 PROGRAM 옵션에 정의된 PROGRAM은 Shared Object의 형태로 컴파일해야 한다. KEQEFT01 유틸리티 프로그램은 OpenFrame 데이터베이스 접속 유틸리티 프로그램으로서 TSS 명령어를 사용하여 Batch 작업을 처리할 수 있도록 한다.
OpenFrame에서 제공하는 KEQEFT01 유틸리티 프로그램은 Batch 애플리케이션(TSS 스크립트의 PROGRAM 옵션에 정의된 PROGRAM)을 실행시키기 위한 데이터베이스와의 접속 기능만을 제공하고 DB2 시스템 명령어는 무시된다.
|
Batch 애플리케이션을 컴파일하는 방법에 대해서는 OpenFrame "마이그레이션 안내서"를 참고한다. |
5.1. DD 설정
DD 설정 항목은 다음과 같다.
| 항목 | 설명 |
|---|---|
SYSTSPRT DD |
KEQEFT01 유틸리티 프로그램의 처리 결과나 에러 메시지가 출력된다. 단, SYSTSPRT DD가 준비되기 전에 발생하는 에러 메시지는 SYSOUT DD로 출력된다. |
SYSTSIN DD |
KEQEFT01 유틸리티 프로그램의 입력 스크립트를 지정해주는 DD이다. |
5.2. 명령어 설정
본 절에서는 KEQEFT01 명령어에 대해 설명한다.
-
DSN
TSS 명령어인 DSN은 새로운 DSN(DB2 Command Processor) 세션을 시작하는 명령어로 다음과 같은 서브 명령어가 존재한다.
명령어 설명 RUN
사용자 애플리케이션을 실행한다.
END
데이터베이스 접속 종료하고 TSS로 복귀한다.
현재 KEQEFT01 유틸리티의 DSN 명령어에서는 다음의 서브 명령어에 대해 에러를 발생시키지 않도록 형식적으로만 지원하고 있다.
명령어 설명 ABEND
DSN 세션을 종료하고 ABEND 코드를 반환한다.
BIND
애플리케이션 패키지 또는 플랜을 생성한다.
DCLGEN
SQL 문장과 정의 테이블을 생성한다.
FREE
애플리케이션 패키지 또는 플랜을 삭제한다.
REBIND
기존 패키지 또는 플랜을 재생성한다.
SPUFI
SQL 파일을 입력으로 받아 SQL 프로세서를 실행한다.
DSN 세션이 연결되어 있는 동안에는 데이터베이스 명령어와 주석을 입력할 수 있다. 데이터베이스 명령어는 하이픈(-)으로 시작하고 주석은 애스터리스크(*)로 시작한다.
DSN 세션이 연결되어있는 동안 OpenFrame에서 사용할 수 있는 데이터베이스 명령어는 다음과 같다.
명령어 설명 DISPLAY
데이터베이스에 대한 상태 정보를 출력한다.
START
지정된 데이터베이스를 사용한다.
STOP
지정된 데이터베이스를 사용하지 않는다.
Mainframe에서 제공하는 데이터베이스 명령어는 많지만 그 중에서 자주 사용되는 몇몇 데이터베이스 명령어에 대해서는 OpenFrame에서 실제 기능은 하지 않으나 에러를 발생시키지 않도록 지원하고 있다.
DSN 명령어 구문은 다음과 같다.
DSN [SYSTEM(DSN|subsystem-name)] [RETRY(0|integer)]항목 설명 SYSTEM
데이터베이스 서브 시스템의 이름을 지정한다.
값을 지정하지 않은 경우 디폴트로 SYSTEM(DSN)을 사용하며 지정된 데이터베이스 서브 시스템 이름은 OpenFrame 환경설정에 ikjeft01 서브젝트, SYSTEM:{subsystem-name} 섹션의 DBTYPE, DBAUTH, DATABASE, INSTANCE, USERNAME, PASSWORD or ENPASSWD 키의 VALUE 항목이 설정되어 있어야 한다.
RETRY
데이터베이스 서브 시스템의 접속 시도 횟수를 지정한다.
접속 시도는 매 30초마다 일어나며 값을 지정하지 않은 경우 디폴트로 RETRY(0)이 적용되어 최대 120번 접속을 시도한다.
-
RUN
DSN 서브 명령어인 RUN은 SQL 문장을 포함하는 애플리케이션을 실행한다.
RUN 서브 명령어 구문은 다음과 같다.
RUN PROGRAM(program-name) [PLAN(plan-name)] [LIBRARY(library-name)] [PARMS(parameter-string)] RUN [LIBRARY(library-name)] [PARMS(parameter-string)]항목 설명 PROGRAM
실행하려고 하는 프로그램 이름을 지정한다.
PLAN
KEQEFT01 유틸리티에서는 해당 파라미터에 대해 에러를 발생시키지 않도록 지원하고 있다.
LIBRARY
애플리케이션이 들어 있는 PDS 데이터 셋 이름을 지정한다. (약어: LIB)
PARMS
애플리케이션에 전달되어야 하는 파라미터 목록을 지정한다. (약어: PARM)
-
END
DSN 서브 명령어인 END는 DSN 세션을 종료하고 TSS로 복귀한다.
END 서브 명령어 구문은 다음과 같다.
END
5.3. 사용예제
다음은 DSN 세션에 대한 예로 MYDB 시스템으로 접속을 실패할 경우 매 30초마다 최대 5번까지 접속을 시도한다.
DSN SYSTEM (MYDB) RETRY (5)
다음은 DSN 시스템으로 접속하여 'TEST.RUNLIB.LOAD' 라이브러리에 있는 COBTEST1 프로그램을 실행시키는 예이다.
DSN SYSTEM (DSN)
RUN PROGRAM (COBTEST1) LIB ('TEST.RUNLIB.LOAD')
다음은 DSN 시스템으로 접속하여 'TEST.RUNLIB.LOAD' 라이브러리에 있는 COBTEST2 프로그램을 실행시키고 COBTEST2 프로그램의 파라미터로 '1234567890’을 전달하는 예이다.
DSN SYSTEM (DSN)
RUN PROGRAM (COBTEST2) PLAN (COBTEST2) -
LIB ('TEST.RUNLIB.LOAD') PARMS ('1234567890')
5.4. 관련 환경설정
데이터베이스의 시스템 이름과 데이터베이스 접속에 필요한 정보는 OpenFrame 환경설정의 ikjeft01 서브젝트에 기술한다. 자세한 내용은 OpenFrame Batch "환경설정 안내서"를 참고한다.
5.5. 유의사항
KEQEFT01 유틸리티 프로그램은 SYSTSIN DD에 TSS 스크립트를 지정해야 하며, 이때 TSS 스크립트 중 'PROGRAM' 옵션에 정의된 PROGRAM은 Shared Object 형식이어야 한다. 현재 KEQEFT01 유틸리티 프로그램은 셀스크립트나 실행 가능한 오브젝트는 지원이 되지 않는다.
DSN 명령어와 DSN 서브 명령어를 사용할 때에는 다음과 같은 파싱 규칙이 적용된다.
-
한 명령어를 다음 라인에 계속해서 적을 때에는 현재 라인의 마지막에 하이픈(-)을 적어준다.
다음은 여러 라인에 걸쳐 명령어를 사용한 DSN 서브 명령어의 예이다.
RUN PROGRAM(TECA251) - PLAN(TECA251) - LIB('MI.PROG.CLINK') - PARM('2')
KEQEFT01 유틸리티 프로그램이 Batch 애플리케이션(TSS 스크립트의 PROGRAM 옵션에 정의된 PROGRAM)을 실행한 결과는 다음과 같다.
-
정상적으로 실행한 경우
애플리케이션에서 받은 코드를 반환한다.
-
에러가 발생한 경우
해당 에러 메시지를 SYSTSPRT DD에 출력하고 각 에러에 해당하는 코드를 반환한다. 단, SYSTSPRT DD가 준비되기 전에 발생한 에러 메시지는 SYSOUT DD에 출력한다.
KEQEFT01 유틸리티 프로그램에서 발생할 수 있는 에러 코드는 다음과 같다.
코드 설명 12
Unrecoverable 유형의 에러로 다음의 경우에 해당한다.
-
데이터 셋 인증관련 준비과정에 실패한 경우
-
SYSTSIN DD가 제공되지 않은 경우
-
SYSTSPRT DD가 제공되지 않은 경우
-
SYSTSIN DD의 파일을 찾지 못한 경우
-
지원하지 않는 SYSTSIN DD의 바이너리 형식인 경우
-
SYSTSIN DD 스크립트 파싱 에러가 발생한 경우
-
적합하지 않은 TSS 명령어가 사용된 경우
-
RUN 명령에 PROGRAM이 기술되지 않은 경우
-
RUN 명령에 기술된 PROGRAM을 찾지 못한 경우
-
실행시켜야 할 애플리케이션을 찾지 못한 경우
-
지원하지 않는 애플리케이션 바이너리 형식
-
데이터베이스 접속에 실패한 경우
-
동적 메모리 LOAD(dlopen)에 실패한 경우
-
엔트리 포인트 검색(dlsym)에 실패한 경우
16
시스템 관련 에러(System Fault)로 다음의 경우에 해당한다.
-
OpenFrame 시스템 라이브러리 초기화에 실패한 경우
-
SYSTSPRT DD를 열지 못한 경우
-
SYSTSIN DD의 바이너리 형식 체크에서 에러가 발생한 경우
-
SYSTSIN DD를 열지 못한 경우
-
Temporary file을 생성하지 못한 경우
-
SYSTSIN DD에서 읽기 에러가 발생한 경우
-
애플리케이션의 바이너리 형식 체크에서 에러가 발생한 경우
-
데이터베이스 시스템 설정 읽기 에러
-
프로세스 분기(fork)에 실패한 경우
-
I/O 리다이렉트에 실패한 경우
-
6. LIBE
LIBE는 직접 엑세스 볼륨의 데이터셋을 복사하는 유틸리티 프로그램이다. PS(Physical Sequential), PO(Partitioned) 으로 구성된 데이터셋들만 입력 데이터셋으로 사용할 수 있다. 출력 데이터셋은 PS와 PO 구성만 허용한다. 현재 자기 테이프는 지원하지 않는다.
6.1. FD 설정
FD 설정 항목은 다음과 같다.
| 항목 | 설명 |
|---|---|
COIN |
제어문 입력 데이터셋이다. |
LIST |
출력 리스트 데이터셋이다. 복사한 블록 사이즈를 출력한다. |
U01 |
입력 데이터셋의 액세스명이다. 반드시 지정할 필요는 없고, 다른 이름으로도 가능하다. |
U02 |
출력 데이터셋의 액세스명이다. 반드시 지정할 필요는 없고, 다른 이름으로도 가능하다. |
6.2. 명령어 설정
LIBE 유틸리티가 제공하는 기능을 수행하기 위한 명령어는 COIN에 기술한다.
-
COIN에서의 LIBE COPY
이 구문은 데이터셋의 복사를 실행하며 단 한 번만 사용될 수 있다.
LIBE의 COIN에서 COPY 명령어 구문은 다음과 같다.
/ COPY ,IN=[{U01|input_access}],[OUT={U02|output_access}] [,REP] [,NEWNAME=output_dataset_newname]항목 설명 IN
입력 데이터셋의 액세스명을 지정한다.
OUT
출력 데이터셋의 액세스명을 지정한다.
REP
출력 데이터셋이 이미 존재하는 경우 덮어쓰기 위해 지정한다.
NEWNAME
복사할 때 새로운 모듈명을 부가할 경우에 지정한다.
출력 파일이 일반 데이터셋일 때는 지정할 수 없다. 입력 데이터셋이 일반 데이터셋(SDS)이고 출력파일이 구분 데이터셋(PDS)일 경우에 반드시 지정한다.
-
MODE, ENDMODE
MODE와 ENDMODE는 같이 지정되어야 하고 MODE에서는 Output_Dataset을 지정할 수 있다.
MODE와 ENDMODE 명령어 형식은 다음과 같다.
/ MODE OUT=U02 / COPY ,IN=U01,NEWNAME=EX01,REP / ENDMODE
-
COMPARE
두 데이터셋의 레코드를 비교하는 명령어이다.
/ COPY ,IN=[{U01|input_access}],[COMP={U02|output_access}] [,LIMIT={10|number}]항목 설명 IN
입력 데이터셋의 액세스명을 지정한다.
COMP
비교 대상 데이터셋의 액세스명을 지정한다.
LIMIT
차이가 발생한 레코드 수의 한계점을 지정한다. 차이가 발생한 레코드 수가 지정한 숫자 이상이 되면 에러로 처리된다.
-
FIN
LIBE 유틸리티 제어문의 마지막을 나타내는 구문이며 생략 가능하다.
FIN 명령어 형식은 다음과 같다.
/ FIN
6.3. 사용예제
다음은 카탈로그된 일반 데이터셋(SDS)을 직접 액세스 볼륨에 신규 일반 데이터셋으로 복사하는 예이다.
\ JOB LIBE01 \ EX LIBE \ FD LIST=DA,VOL=WORK,TRK=(10,10),SOUT=T \ FD U01=DA,VOL=VOL001,FILE=LIBE.TEST.EX1 \ FD U02=DA,VOL=VOL001,FILE=LIBE.TEST.EX2,CYL=(1800,100,RLSE) \ FD COIN=* / COPY ,IN=U01,OUT=U02 / FIN \ JEND
다음은 카탈로그된 일반 데이터셋을 직접 액세스 볼륨에 기존에 존재하는 일반 데이터셋으로 복사하는 예이다.
\ JOB LIBE02 \ EX LIBE \ FD LIST=DA,VOL=WORK,TRK=(10,10),SOUT=T \ FD U01=DA,VOL=VOL001,FILE=LIBE.TEST.EX1 \ FD U02=DA,VOL=VOL001,FILE=LIBE.TEST.EX2 \ FD COIN=* / COPY ,IN=U01,OUT=U02,REP / FIN \ JEND
다음은 카탈로그된 일반 데이터셋들을 직접 액세스 볼륨에 PDS의 멤버로 복사하는 예이다.
\ JOB LIBE03 \ EX LIBE \ FD LIST=DA,VOL=WORK,TRK=(10,10),SOUT=T \ FD U01=DA,VOL=VOL001,FILE=LIBE.TEST.PS1 \ FD U02=DA,VOL=VOL001,FILE=LIBE.TEST.PS2 \ FD U03=DA,VOL=VOL001,FILE=LIBE.TEST.PS3 \ FD U04=DA,VOL=VOL001,FILE=LIBE.TEST.PO4,FCB=(DSORG=PO) \ FD COIN=* / MODE OUT=U04 / COPY ,IN=U01,NEWNAME=SDTPD1,REP / COPY ,IN=U02,NEWNAME=SDTPD2,REP / COPY ,IN=U03,NEWNAME=SDTPD3,REP / ENDMODE / FIN \ JEND
다음은 카탈로그된 PDS의 모든 멤버들을 직접 액세스 볼륨에 일반 데이터셋으로 복사하는 예이다.
\ JOB LIBE04 \ EX LIBE \ FD LIST=DA,VOL=WORK,TRK=(10,10),SOUT=T \ FD U01=DA,VOL=VOL001,FILE=LIBE.TEST.PO1,FCB=(DSORG=PO) \ FD U02=DA,VOL=VOL001,FILE=LIBE.TEST.PS2 \ FD COIN=* / COPY ,IN=U01,OUT=U02 또는 COPY +,IN=U01,OUT=U02 / FIN \ JEND
다음은 카탈로그된 PDS의 멤버 중에 이름이 TEST1인 멤버를 직접 액세스 볼륨에 일반 데이터셋으로 복사하는 예이다.
\ JOB LIBE05 \ EX LIBE \ FD LIST=DA,VOL=WORK,TRK=(10,10),SOUT=T \ FD U01=DA,VOL=VOL001,FILE=LIBE.TEST.PO1,FCB=(DSORG=PO) \ FD U03=DA,VOL=VOL001,FILE=LIBE.TEST.PS3 \ FD COIN=* / COPY TEST1+,IN=U01,OUT=U03 (단, TEST1 뒤에 아무 문자열이 없는 경우에 한함) 또는 COPY (TEST1),IN=U01, OUT=U03 / FIN \ JEND
다음은 카탈로그된 PDS의 멤버 중에 이름이 TEST1과 TEST2인 멤버를 직접 액세스 볼륨에 일반 데이터셋으로 복사하는 예이다.
\ JOB LIBE06 \ EX LIBE \ FD LIST=DA,VOL=WORK,TRK=(10,10),SOUT=T \ FD U01=DA,VOL=VOL001,FILE=LIBE.TEST.PO1,FCB=(DSORG=PO) \ FD U04=DA,VOL=VOL001,FILE=LIBE.TEST.PS4 \ FD COIN=* / COPY (TEST1,TEST2),IN=U01,OUT=U04 / FIN \ JEND
다음은 카탈로그된 PDS의 멤버 중 이름에 TEST가 포함된 멤버를 직접 액세스 볼륨에 일반 데이터셋으로 복사하는 예이다.
\ JOB LIBE07 \ EX LIBE \ FD LIST=DA,VOL=WORK,TRK=(10,10),SOUT=T \ FD U01=DA,VOL=VOL001,FILE=LIBE.TEST.PO1,FCB=(DSORG=PO) \ FD U05=DA,VOL=VOL001,FILE=LIBE.TEST.PS5 \ FD COIN=* / COPY TEST+,IN=U01,OUT=U05 / FIN \ JEND
다음은 카탈로그된 PDS의 멤버 중 이름에 ABC, DEF가 포함되지 않은 멤버를 직접 액세스 볼륨에 일반 데이터셋으로 복사하는 예이다.
\ JOB LIBE08 \ EX LIBE \ FD LIST=DA,VOL=WORK,TRK=(10,10),SOUT=T \ FD U01=DA,VOL=VOL001,FILE=LIBE.TEST.PO1,FCB=(DSORG=PO) \ FD U06=DA,VOL=VOL001,FILE=LIBE.TEST.PS6 \ FD COIN=* / COPY ^(ABC,DEF),IN=U01, OUT=U06 / FIN \ JEND
다음은 카탈로그된 PDS의 모든 멤버들을 직접 액세스 볼륨에 PDS의 멤버로 복사하는 예이다.
\ JOB LIBE09 \ EX LIBE \ FD LIST=DA,VOL=WORK,TRK=(10,10),SOUT=T \ FD U01=DA,VOL=VOL001,FILE=LIBE.TEST.PO1,FCB=(DSORG=PO) \ FD U02=DA,VOL=VOL001,FILE=LIBE.TEST.PO2,FCB=(DSORG=PO) \ FD COIN=* / COPY ,IN=U01, OUT=U02 또는 COPY +,IN=U01, OUT=U02 / FIN \ JEND
다음은 카탈로그된 PDS의 멤버 중에 이름이 TEST1인 멤버를 직접 액세스 볼륨에 PDS의 멤버로 복사하는 예이다.
\ JOB LIBE10 \ EX LIBE \ FD LIST=DA,VOL=WORK,TRK=(10,10),SOUT=T \ FD U01=DA,VOL=VOL001,FILE=LIBE.TEST.PO1,FCB=(DSORG=PO) \ FD U03=DA,VOL=VOL001,FILE=LIBE.TEST.PO3,FCB=(DSORG=PO) \ FD COIN=* / COPY TEST1+,IN=U01,OUT=U03 (단, TEST1 뒤에 아무 문자열이 없는 경우에 한함) 또는 COPY (TEST1),IN=U01,OUT=U03 / FIN \ JEND
다음은 카탈로그된 PDS의 멤버 중에 이름이 TEST1과 TEST2인 멤버를 직접 액세스 볼륨에 PDS의 멤버로 복사하는 예이다.
\ JOB LIBE11 \ EX LIBE \ FD LIST=DA,VOL=WORK,TRK=(10,10),SOUT=T \ FD U01=DA,VOL=VOL001,FILE=LIBE.TEST.PO1,FCB=(DSORG=PO) \ FD U04=DA,VOL=VOL001,FILE=LIBE.TEST.PO4,FCB=(DSORG=PO) \ FD COIN=* / COPY (TEST1,TEST2),IN=U01,OUT=U04 / FIN \ JEND
다음은 카탈로그된 PDS의 멤버들 중 이름에 TEST가 포함된 멤버를 직접 액세스 볼륨에 PDS의 멤버로 복사하는 예이다.
\ JOB LIBE12 \ EX LIBE \ FD LIST=DA,VOL=WORK,TRK=(10,10),SOUT=T \ FD U01=DA,VOL=VOL001,FILE=LIBE.TEST.PO1,FCB=(DSORG=PO) \ FD U05=DA,VOL=VOL001,FILE=LIBE.TEST.PO5,FCB=(DSORG=PO) \ FD COIN=* / COPY TEST+,IN=U01,OUT=U05 / FIN \ JEND
다음은 카탈로그된 PDS의 멤버들 중 이름에 ABC, DEF가 포함되지 않은 멤버를 직접 액세스 볼륨에 PDS의 멤버로 복사하는 예이다.
\ JOB LIBE13 \ EX LIBE \ FD LIST=DA,VOL=WORK,TRK=(10,10),SOUT=T \ FD U01=DA,VOL=VOL001,FILE=LIBE.TEST.PO1,FCB=(DSORG=PO) \ FD U06=DA,VOL=VOL001,FILE=LIBE.TEST.PO6,FCB=(DSORG=PO) \ FD COIN=* / COPY ^(ABC,DEF),IN=U01, OUT=U06 / FIN \ JEND
다음은 COMPARE 명령으로 두 데이터셋의 레코드를 비교하는 예이다.
\ JOB LIBE13 \ EX LIBE \ FD LIST=DA,VOL=WORK,TRK=(10,10),SOUT=T \ FD U01=DA,VOL=VOL001,FILE=LIBE.COMP.TEST01 \ FD U06=DA,VOL=VOL001,FILE=LIBE.COMP.TEST06 \ FD COIN=* / COMPARE IN=U01,COMP=U06,LIMIT=999 / FIN \ JEND
6.4. 유의사항
LIBE 유틸리티의 COPY 기능을 사용할 때 일반데이터셋인지 PDS인지 정확히 파악 후에 사용한다.
LIBE유틸리티 프로그램을 실행한 결과는 다음과 같다.
-
정상적으로 실행한 경우
유틸리티의 정상 종료 코드 10을 반환한다.
-
경고 및 에러가 발생한 경우
해당 에러 메시지를 LIST FD에 출력하고 에러에 해당하는 코드를 반환한다.
LIBE 유틸리티 프로그램에서 발생할 수 있는 에러 코드는 다음과 같다.
코드 설명 20
COPY 명령을 수행하는 중 입력 데이터셋에 레코드가 존재하지 않을 때 경고 메시지와 함께 반환된다.
30
데이터셋 관련 함수에서 에러가 발생한 경우, COMPARE 명령 수행 중 차이가 발생한 레코드 수가 LIMIT와 같거나 많은 경우, 유틸리티 내에 로직에서 에러가 발생한 경우를 의미한다.
50
COIN으로 주어진 JCL이 문법에 맞지 않아 발생한 경우(Parsing Error)를 의미한다.
7. FASP
FASP는 WebTerminal을 포함한 터미널에서 OFGW로 접속할 때, 전체 커맨드를 약어로 등록하여 약어 입력만으로 전체 커맨드를 입력한 것과 동일한 결과를 내도록 처리하는 유틸리티이다.
|
7.2. 명령어 설정
FASP 유틸리티가 제공하는 기능을 수행하기 위해서는 SLIB에 명령어를 기술한다.
| 커맨드 | 설명 |
|---|---|
CCFTAB |
해당 커맨드는 지원하지 않으며 무시된다. |
CCFCMD |
커맨드의 라벨명을 커맨드의 약어로 처리한다. 이외의 파라미터는 무시한다. |
CCFPARM |
PARM 파라미터가 DATA이고, 디폴트 파라미터로 정의된 값을 커맨드로 처리한다. 이외의 다른 파라미터에 대해서는 무시한다. |
CCFEND |
문장에 대한 마지막을 기술한다. VTAM에 등록하려면 이 문장이 반드시 기술되어야 한다. |
기타 |
이외의 다른 커맨드에 대해서는 지원하지 않으며 무시된다. |
7.3. 사용예제
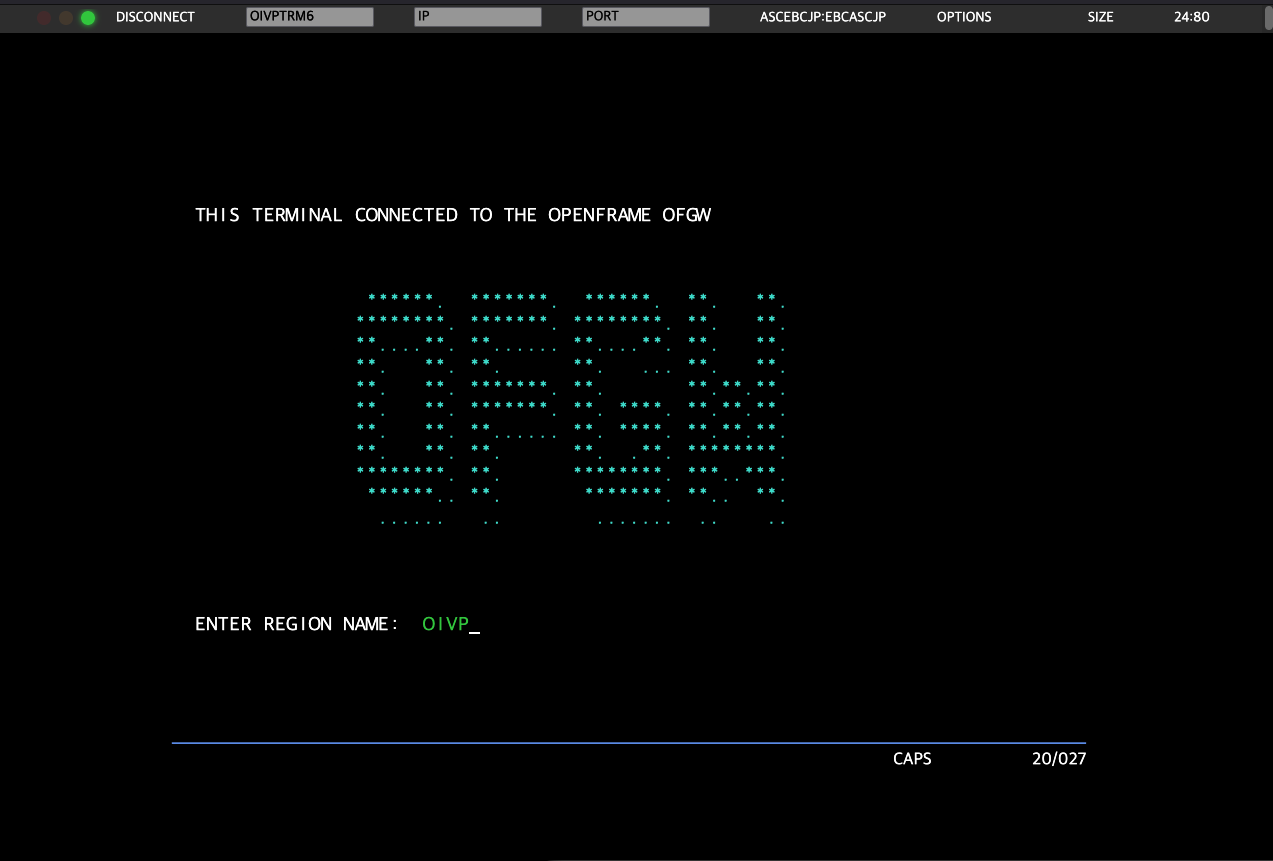
다음은 'LOGON AIM,,OIVPPROC' 커맨드를 약어 'OIVP’로 지정하는 명령이다. FASP를 수행한 결과는 vtamrgadm의 '-l' 옵션으로 조회 가능하며, 터미널에 접속하여 'OIVP’를 입력하면 'LOGON AIM,,OIVP’를 입력한 것과 동일하게 처리된다.
-
JCL 예제
\ JOB FASPTEST \ EX FASP,RSIZE=3000 \ PARA OBJ,NODECK \ FD LIST=DA,VOL=DEFVOL,SOUT=A,CYL=(3,2) \ FD SLIB=* OIVP CCFCMD CMD=OIVP,REP=LOGON,FORMAT=PL1 CCFPARM PARM=APPLID,DEFAULT=OIVP CCFPARM PARM=DATA,DEFAULT='LOGON AIM,,OIVPPROC' CCFEND \/ -
JCL 수행 후의 vtamrgadm 예제
[root@oframe test]# vtamrgadm -l VTAM REGION ALIAS infomation ===================================================================================================================== NO. NAME TYPE FORMAT APPLID RGMAP LAST_UPDT_TIME --------------------------------------------------------------------------------------------------------------------- 1 OIVP LOGON PL1 OIVP LOGON AIM,,OIVPPROC 2025/02/17 11:28:22.628375 =====================================================================================================================
vtamrgadm 툴에 대해서는 OpenFrame Base "툴 참조 안내서"를 참조한다.
-
WebTerminal 예제
FASP로 등록한 약어를 WebTerminal에 입력하는 화면이다.