Non-VSAM 데이터셋
본 장에서는 레코드 포맷, DCB 구조체, 순차 데이터셋, 구분 데이터셋, 세대 데이터 그룹 등 Non-VSAM 데이터셋의 특징과 종류에 대해서 설명한다.
1. 개요
Non-VSAM 데이터셋이란 IBM Mainframe에서 VSAM 데이터셋이 나오기 이전에 사용되던 모든 데이터셋을 Non-VSAM 데이터셋이라고 한다. 따라서 VSAM 데이터셋이 아닌 데이터셋은 모두 Non-VSAM 데이터셋이다.
OpenFrame에서 Non-VSAM 데이터셋은 UNIX의 파일 시스템으로 대응되고, 각각의 데이터셋 유형에 따른 액세스 메소드(Access Method)는 별도의 OpenFrame 인터페이스로 제공된다.
2. 레코드 포맷
OpenFrame에서는 다음과 같은 4가지 형태의 레코드 포맷을 지원한다.
-
고정 길이 (RECFM=F)
-
가변 길이 (RECFM=V)
-
라인 순차 (RECFM=L)
-
불확정 (RECFM=U)
라인 순차 레코드 포맷과 불확정 레코드 포맷을 제외한 나머지 레코드 포맷은 RECFM 파라미터에 ‘B’를 추가함으로써 블록 I/O를 할 수 있다. 데이터 블록은 디스크 볼륨에 데이터가 기록되기 전 여러 개의 레코드를 묶어서 하나의 블록으로 구성한 것을 의미한다.
OpenFrame에서는 RECFM 파라미터에 'B’가 별도로 지정되어 있지 않아도, 실제 디스크에 I/O을 수행할 때에는 내부 버퍼를 이용한 버퍼링을 수행한다.
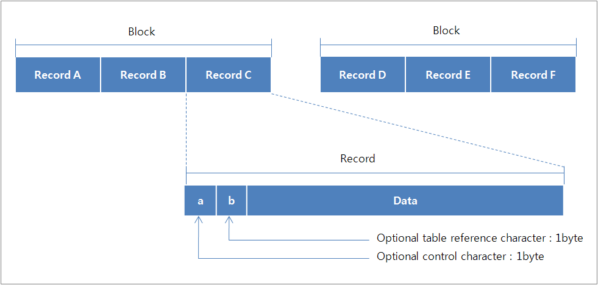
고정 길이 레코드 포맷
한 데이터셋에 있는 모든 레코드의 크기는 동일하고 블록 I/O(RECFM=FB)를 지원한다. 블록 I/O가 아닌 경우에 하나의 레코드는 하나의 블록으로 간주된다.
각각의 레코드는 한 블록 안에서 별도의 레코드 분리자(record separator)없이 연속적으로 저장된다. 순차적으로 레코드를 읽는 경우 한 블록 안에서 한 번에 레코드의 크기 만큼씩 읽어낸다.
선택 제어 문자(Optional Control Character)는 각 레코드를 프린터로 출력할 때 캐리지를 제어하는 문자이다. 그리고 선택 테이블 참고 문자(Optional Table Reference Character)는 레코드를 출력할 때 폰트를 선택하기 위해 사용되는 코드이다.
가변 길이 레코드 포맷
가변 길이 데이터셋에 포함되어 있는 각각의 레코드는 서로 길이가 다를 수 있다. 가변 길이 레코드 포맷의 경우 블록 I/O(RECFM=VB)와, Spanned 포맷(RECFM=VS)을 같이 사용할 수 있다.
Spanned 포맷은 논리 레코드의 길이가 지정된 블록 크기보다 큰 경우에 세그먼트 단위로 잘라서 디스크에 저장하는 포맷이다. OpenFrame에서 Spanned 포맷이 지정되어 있는 경우 논리 레코드의 길이가 블록 크기보다 큰 경우에도 읽기/쓰기 동작이 문제없이 지원된다. 이것은 논리 레코드를 세그먼트 단위로 잘라서 저장하기 때문이 아니라, Mainframe과는 다른 방식으로 블록 I/O를 구현했기 때문이다.
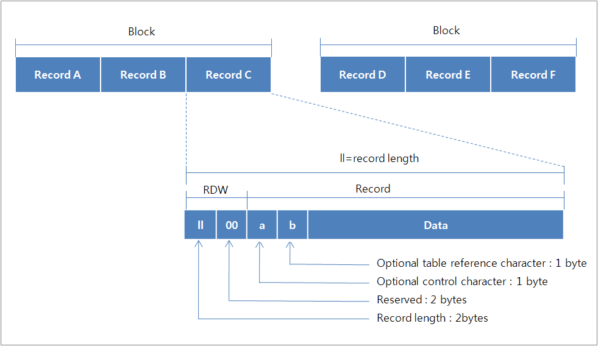
가변 길이 블록은 BDW(Block Descriptor Word)와 하나 이상의 논리 레코드로 구성되어 있다. BDW는 해당 블록을 부가적으로 설명하는 4Byte 크기의 필드이다. OpenFrame에서 BDW는 사용되지 않는다.
가변 길이 레코드는 RDW(Record Descriptor Word)와 데이터로 구성되어 있다. RDW는 해당 레코드를 부가적으로 설명하는 4Byte 크기의 필드이다. RDW의 1번째 2Byte는 RDW를 포함한 논리 레코드의 길이를 저장하고 3번째와 4번째 Byte는 모두 0으로 설정되어있다.
라인 순차 레코드 포맷
라인 순차 레코드 포맷은 UNIX의 텍스트 파일과 동일한 형태의 레코드 포맷을 의미한다. 블록 단위의 I/O는 지원하지 않고 한 데이터셋 안의 각각의 레코드는 라인피드 문자로 구분된다. OpenFrame/Batch 작업에서 사용되는 인스트림 데이터셋이나 SPOOL 출력 데이터셋은 라인 순차 레코드 포맷을 사용한다.
불확정 레코드 포맷
불확정 레코드 포맷은 특별히 정해진 포맷없이 I/O를 하기 위한 레코드 포맷이다. 불확정 레코드 포맷에서 하나의 블록은 하나의 레코드로 간주된다.
선택 제어 문자
JCL의 DD 문장이나 DCB 파라미터에는 데이터셋 레코드의 일부로서 선택 제어 문자가 포함되어 있는지 여부를 표시할 수 있다. 각각의 레코드 앞에 있는 1Byte의 출력 제어 문자는 데이터셋이 출력될 때에 캐리지 컨트롤을 담당한다. 이 1Byte의 문자는 데이터셋에 저장된 레코드의 일부이지만 출력될 때에는 나타나지 않는다. 이 제어 문자의 유무를 결정하는 것은 데이터 컨트롤 블록(DCB)의 RECFM 필드에 ‘M’ 또는 ‘A’라는 문자로 표기된다. ‘M’은 Machine 코드를 의미하고 ‘A’는 ANSI 코드를 의미한다.
3. DCB 구조체
OpenFrame에서는 애플리케이션이 데이터셋을 열기 전에 처리하려고 하는 모든 데이터셋에 대해 미리 데이터 컨트롤 블록(DCB)이 준비되어야 한다. 데이터 컨트롤 블록은 데이터셋에 대한 적절한 처리 정보가 담겨있는 구조체로서 JCL의 DD문이나 카탈로그에서 정보를 추출하여 구성된다.
일반적인 JCL Batch JOB을 실행하면 애플리케이션에서 필요로 하는 모든 데이터셋에 대한 컨트롤 블록은 JCL의 DD 문장으로부터 시스템 내부적으로 생성되어 애플리케이션에 전달된다. 하지만 동적 할당을 사용하는 IDCAMS(JSCVSUT/KQCAMS) 유틸리티와 같은 몇몇 유틸리티 프로그램의 경우에는 유틸리티 프로그램에서 직접 데이터 컨트롤 블록을 생성할 수도 있다.
다음은 데이터 컨트롤 블록에 지정되는 데이터셋 정보의 일부이다.
| 항목 | 설명 |
|---|---|
Block Size (BLKSIZE) |
입력과 출력을 하기 위한 데이터 블록의 최대크기를 지정한다. 특별히 지정되지 않으면 디바이스의 종류에 따라 32KB나 64KB가 기본적인 블록 사이즈로 사용된다. OpenFrame에서는 Block Size 파라미터를 형식적으로 지원하지만, 실제 디스크에 I/O를 수행할 때에는 OpenFrame 환경설정 중 ds 서브젝트, DATASET_DEFAULT 섹션의 NVSM_BUFFUR_SIZE 키에 등록되어 있는 버퍼 사이즈만큼 버퍼링을 한다. OpenFrame 환경설정에 대한 자세한 내용은 OpenFrame Base "환경설정 안내서"를 참고한다. |
Data Set Organization (DSORG) |
데이터셋의 구조를 지정한다. 다음과 같은 유형의 데이터셋 구조를 지정할 수 있다.
|
Record Format (RECFM) |
RECFM은 다음과 같은 레코드의 특징을 나타낸다.
블록 단위의 I/O를 지원하면 RECFM은 FB, VB와 같이 사용되고, Spanned 레코드를 지원하면 RECFM은 VS, VBS와 같이 사용된다. |
Record Length (LRECL) |
LRECL은 데이터셋 레코드의 길이를 지정한다. 만약 가변 길이 레코드 포맷 또는 불확정 레코드 포맷인 경우에는 최대 레코드 길이가 지정되어야 한다. |
4. SPACE 할당
Non-VSAM 데이터셋의 SPACE 사이즈를 할당하는 방법에 대해서 설명한다.
Primary Space와 Secondary Space 결정
Primary Space와 Secondary Space 사이즈는 다음의 순서에 따라 결정한다.
-
데이터 클래스의 AVGREC, AVGVAL, PRIMARY, SECONDARY 값 사용하는 경우
Primary Space = (PRIMARY * AVGVAL * AVGREC + 1023)/1024 Secondary Space = (SECONDARY * AVGVAL * AVGREC + 1023)/1024
항목 설명 PRIMARY
기본값 : 4096
SECONDARY
기본값 : 0
AVGVAL
CYL(768KB), TRK(48KB) 또는 LRECL에 지정한 값
-
JCL DD 문에 LIKE 또는 DCB=(dsname)가 지정된 경우
Model이 되는 데이터셋의 Primary Space와 Secondary Space 값을 사용한다.
-
JCL DD 문의 SPACE 파라미터가 지정된 경우
SPACE=(AVGVAL,PRIMARY,SECONDARY) 파라미터에 대해서 다음과 같이 설정한다.
Primary Space = (PRIMARY * AVGVAL * AVGREC + 1023)/1024 Secondary Space = (SECONDARY * AVGVAL * AVGREC + 1023)/1024
항목 설명 PRIMARY
기본값 : 4096
SECONDARY
기본값 : 0
AVGVAL
CYL(768KB), TRK(48KB) 또는 LRECL에 지정한 값
-
1~3 방법으로 Primary Space가 결정되지 않은 경우
Primary Space = 볼륨 디바이스의 Maximum Space 값 (MB 단위로 지정) Secondary Space = 0
Primary Space와 Secondary Space에서 최대 사이즈를 계산
결정된 Primary Space와 Secondary Space 값으로 최대 사이즈를 계산한다.
Data Set Size Limit = (Primary Space + Secondary Space * conf_extent_limit) * 1024
| 항목 | 설명 |
|---|---|
conf_extent_limit |
OpenFrame 환경설정 중 ds 서브젝트의 DATASET_DEFAULT 섹션의 NVSM_EXTENT_LIMIT 키의 VAUE 항목 값으로 Secondary Extent 가능 최대 회수를 의미한다. 설정하지 않으면 기본값은 15이다. ds 서브젝트의 DATASET_DEFAULT 섹션에 지정한 DATASET_SIZE_LIMIT 키의 VALUE 항목 값이 데이터셋 최대 사이즈(Data Set Size Limit )보다 작은 경우 DATASET_SIZE_LIMIT 키의 설정 값을 사용한다. 반대의 경우는 위에서 계산한 데이터셋 최대 사이즈를 사용한다. |
|
OpenFrame 환경설정에 대한 자세한 내용은 OpenFrame Base "환경설정 안내서"를 참고한다. |
5. 순차 데이터셋
순차 데이터셋은 OpenFrame 시스템에서 가장 일반적인 데이터셋으로서 레코드가 저장된 순서대로 데이터 처리가 가능한 데이터셋을 의미한다. 순차 데이터셋은 하드 디스크 볼륨이나 테이프 디바이스 볼륨에 저장될 수 있다.
순차 데이터셋의 생성
QSAM 또는 BSAM 액세스 메소드를 사용하면, 다음과 같은 절차를 거쳐 순차 데이터셋을 생성할 수 있다.
-
DCB 파라미터에 DSORG=PS라고 지정한다.
-
DD 문장에 데이터셋의 속성에 대해 기술한다.
-
데이터셋을 열고 PUT 또는 WRITE API를 실행한 후 닫는다.
순차 데이터셋의 검색
순차 데이터셋에서 레코드를 읽기 위해서는 다음과 같은 절차를 따라한다.
-
DCB 파라미터에 DSORG=PS라고 지정한다.
-
DD 문장에 데이터셋의 위치를 지정한다.
-
데이터셋을 열고 GET 또는 READ API를 사용한 후 닫는다.
순차적으로 연결된 데이터셋
OpenFrame 시스템에서는 2개 이상의 데이터셋을 붙여서 마치 하나의 데이터셋처럼 연속적으로 검색할 수 있는 방법을 제공한다. 이것을 순차 연결(Sequential Concatenation)이라고 한다. 순차 연결된 데이터셋은 거꾸로 읽을 수 없으며, VSAM 데이터셋은 순차 연결을 지원하지 않는다.
아래의 예에서는 BSAM을 이용해 여러 개의 데이터셋을 순차 연결해서 사용하는 예를 보여준다.
//INPUT DD *
... (instream data set)
// DD DSN=IGKANG.MAIN.DATA,DISP=SHR
// DD DSN=IGKANG.SUPL.DATA,UNIT=3390,DISP=OLD,
BLKSIZE=4096
순차 데이터셋의 변경
순차 데이터셋을 변경하는 방법은 다음과 같이 2가지가 있다.
-
기존 레코드의 내용 변경(Update in place)
기존에 있는 레코드의 내용을 변경하려면 먼저 레코드의 내용을 읽고 처리한 다음 변경된 레코드의 내용을 원래 위치에 써야 한다. 이때 다음과 같은 규칙이 동일하게 적용된다.
-
기존의 레코드를 삭제할 수 없다.
-
데이터셋은 하드 디스크 볼륨에 있어야 한다.
-
-
데이터셋의 끝 부분에 새로운 레코드 추가(Extends the data set)
데이터셋의 끝 부분에 새로운 레코드를 추가하기 위해서는 DD 문장에 DISP=MOD를 지정해 주어야 하고, 데이터셋을 열 때 OUTPUT 모드로 열어야 한다. 그리고 나서 PUT이나 WRITE API를 사용할 수 있다. 순차 데이터셋에 신규 레코드 추가는 항상 맨 뒤의 레코드로서 추가된다. 레코드와 레코드 중간에 새로운 레코드를 삽입하는 것은 불가능하다.
6. 구분 데이터셋
구분 데이터셋(PDS)은 여러 개의 순차 구조를 가지는 멤버들과 각각의 멤버를 기술하는 디렉터리 항목으로 구성되며 하드 디스크 볼륨에만 저장된다.
각각의 멤버는 최대 8개의 문자로 이루어진 유일한 이름을 가지고 있으며, 멤버의 각 레코드는 순차적으로 읽기/쓰기가 가능하다.
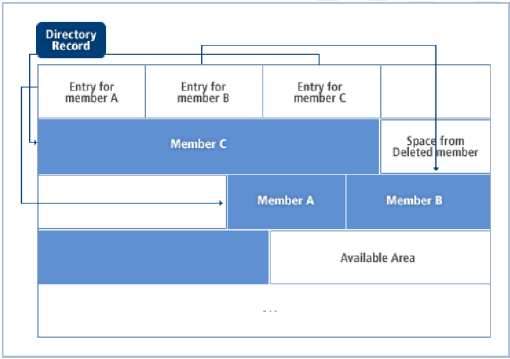
구분 데이터셋의 주요 장점은 전체 데이터셋을 검색하지 않고도 개별 멤버에 대한 접근이 가능하다는 점이다. 예를 들면 프로그램 라이브러리의 경우 PDS 각각의 멤버는 개별적으로 실행 가능한 프로그램이나 서브루틴이다. 필요에 따라서 각각의 멤버는 추가되거나 삭제가 가능하다.
OpenFrame에서는 구분 데이터셋을 UNIX 파일 시스템의 디렉터리로 매핑하고, 멤버는 해당 디렉터리 안에 존재하는 개별 파일로서 관리한다.
구분 데이터셋 생성
BSAM, QSAM, 또는 BPAM 액세스 메소드를 이용해서 구분 데이터셋이나 PDS의 멤버를 생성할 수 있다.
다음은 데이터셋을 생성하고 멤버를 추가하는 방법을 나타낸 예이다.
-
DCB 파라미터에 DSORG=PS라고 지정한다.
-
DD 문장에서 데이터가 새로운 PDS의 멤버로 저장될 것이라고 지정해 준다. 즉, DSNAME=name(membername) 그리고 DISP=NEW라고 지정한다.
-
데이터셋을 열고 PUT이나 WRITE API를 실행한 후 닫는다.
다음은 구분 데이터셋을 생성하는 JCL 예제이다.
//PDSDD DD ---,DSNAME=MASTFILE(MEMBERK),SPACE=(TRK,(100,5,7)), // DISP=(NEW,CATLG),DCB=(DSORG=PS,RECFM=FB,LRECL=80),---
앞에서 DSORG=PS 대신 DSORG=PO를 지정하고, PUT API나 WRITE API 대신 STOW API를 사용하면 BPAM 액세스 메소드를 사용해서 PDS를 생성할 수 있다.
기존에 존재하는 PDS에 새로운 멤버를 추가하기 위해서는 앞에서와 동일한 단계를 실행하되, Disposition을 변경으로 지정해야 한다. (DISP=MOD)
한 번에 여러 개의 멤버를 추가하고 싶은 경우에는 다음의 단계를 따라 한다.
-
DCB 파라미터에 DSORG=PO라고 지정한다.
-
DD 문장에서 PDS 전체 데이터셋에 대한 위치를 지정한다.
-
데이터셋을 열고 STOW API를 사용해서 새로운 멤버를 추가한다.
PDS의 멤버 처리
PDS의 멤버는 일반 순차 데이터셋과 동일하기 때문에 순차 데이터셋을 처리하는 방법과 동일하게 PDS의 멤버에 대한 I/O를 수행할 수 있다. 하지만 디렉터리 항목에 대한 관리나 멤버에 대한 검색 등의 작업을 수행하기 위해 OpenFrame에서는 다음과 같은 별도의 API를 제공한다.
BLDL API를 사용하면 PDS의 디렉터리 항목에 대한 정보를 모두 조사해서 메모리에 읽어 온다. FIND API를 사용하면 레코드 포인터를 지정된 멤버의 위치로 이동시켜 준다. 반면에 STOW API는 새로운 멤버를 추가하거나, 기존의 멤버를 삭제하거나, 멤버의 이름을 변경할 수 있게 해준다. 위의 API를 사용하기 위해서는 DCB 파라미터에 DSORG=PO를 지정해 주어야 한다.
다음은 BPAM 액세스 메소드의 각 API에 대한 설명이다.
| API | 설명 |
|---|---|
BLDL |
디렉터리 리스트를 구성한다. BLDL API를 사용하면 디렉터리 항목에 대한 정보를 메모리에 읽어 온다. 이 정보를 이용하여 FIND API에서 PDS의 멤버를 접근할 수 있다. |
FIND |
멤버의 시작주소 위치를 가져온다. 특정한 멤버의 맨 앞으로 레코드 포인터를 이동시키기 위해서는 FIND API를 사용한다. 이후의 I/O 작업은 FIND에 의해 지정된 위치부터 수행된다. |
STOW |
디렉터리를 업데이트한다. 하나 이상의 멤버를 PDS에 추가하고 싶으면 STOW API를 사용해서 멤버에 해당하는 디렉터리 항목을 직접 PDS 디렉터리에 추가할 수 있다. STOW API를 사용하려면 DCB 파라미터에 반드시 DSORG=PO를 지정해 주어야 한다. |
PDS의 멤버 검색
PDS에서 특정한 멤버를 검색하고 싶은 경우 다음과 같이 BSAM이나 QSAM을 이용해서 작업을 수행할 수 있다.
-
DCB 파라미터에 DSORG=PS라고 지정한다.
-
DD 문장에서 기존에 있는 PDS의 멤버에 대해 기술한다. 즉, DSNAME=name(membername) 그리고 DISP=OLD, DISP=SHR, 또는 DISP=MOD라고 지정한다.
-
데이터셋을 열고 GET이나 READ API를 사용한 후 닫는다.
다음은 PDS의 멤버에 대해 처리하는 JCL 예제이다.
//PDSDD DD ---,DSN=MASTFILE(MEMBERK), // DISP=SHR,DCB=(DSORG=PS),---
7. 세대 데이터 그룹
OpenFrame에서는 서로 관련이 있는 연속적인 데이터셋을 카탈로깅하는 방법을 제공한다. 이것을 세대 데이터 그룹(GDG: Generation Data Group)이라고 말한다. GDG 안에 포함되어 있는 각각의 데이터셋은 세대 데이터셋(GDS: Generation Data Set) 또는 세대라고 말한다.
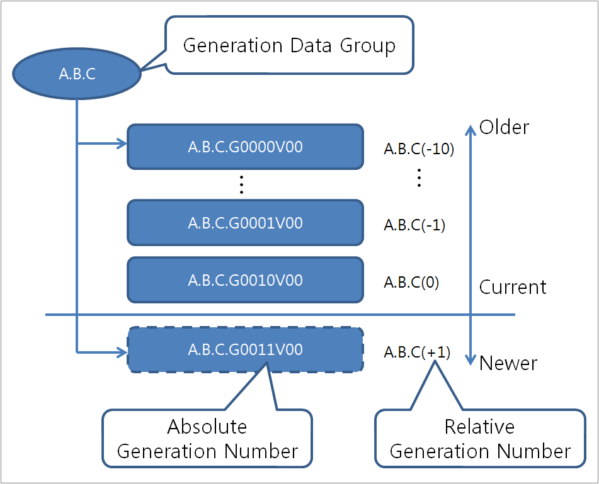
세대 데이터셋은 순차 데이터셋으로만 구성될 수 있으며 구분 데이터셋이나 VSAM 데이터셋은 세대 데이터셋이 될 수 없다.
서로 관련이 있는 데이터셋을 세대 데이터 그룹으로 묶음으로서 다음과 같은 장점을 얻을 수 있다.
-
같은 그룹에 있는 데이터셋은 같은 이름으로 참고될 수 있다.
-
시스템은 데이터셋의 세대를 순서대로 관리할 수 있다.
-
오래된 세대의 데이터셋은 자동으로 시스템에서 삭제된다.
세대 데이터셋은 자신의 연령을 의미하는 절대 이름과 상대 이름을 가지고 있다. 카탈로그 관리 시스템은 절대 세대 이름만을 사용한다. 연령이 많은 데이터셋은 작은 절대 숫자를 가지고 있다. 상대 이름의 경우 가장 최신의 데이터셋은 (0), 그 다음 최신 데이터셋은 (-1) 등과 같이 숫자로 표시된다. 상대 이름은 새로운 세대(+1)을 카탈로깅하기 위해서도 사용될 수 있다.
세대 데이터 그룹(GDG) BASE는 세대 데이터셋이 카탈로깅되기 전에 카탈로그에 등록되어야 한다. 각 세대 데이터 그룹은 카탈로깅되어 있는 GDG BASE 항목에 의해 대표된다. gdgcreate 툴 프로그램을 사용하면 GDG BASE를 카탈로그에 등록할 수 있다.
|
gdgcreate 프로그램에 대한 자세한 내용은 OpenFrame Base "툴 참조 안내서"를 참고한다. |
7.1. 절대 세대번호
절대 세대번호와 버전번호는 GDG의 특정한 세대를 표현하기 위해 사용된다. 절대 세대번호와 버전번호는 GxxxxVyy와 같은 형태를 가지고 있다. 여기에서 xxxx는 네 자리 세대번호(0001부터 9999까지)이고 yy는 2자리 버전번호(00부터 99까지)를 의미한다.
절대 세대번호와 버전번호에 대한 예를 들면 아래와 같다.
예) A.B.C.G0001V00
A.B.C라는 세대 데이터 그룹에서 세대번호 1, 버전번호 0번의 데이터셋을 의미한다.
예) A.B.C.G0009V01
A.B.C라는 세대 데이터 그룹에서 세대번호 9, 버전번호 1번의 데이터셋을 의미한다.
시스템은 세대번호를 자동으로 관리해준다. 유지되는 세대의 최대 개수는 GDG BASE에 정의된 한도(Limit)에 따라 결정된다. 예를 들어 한도가 10인 GDG인 경우에는 최대 10개의 항목이 GDG에 의해 관리된다.
버전번호는 GDG에 의한 세대 관리를 방해하지 않으면서 일반적인 데이터셋 처리작업을 할 수 있도록 해준다. 예를 들어 3개의 세대가 관리되는 GDG에서 2번째 세대를 업데이트하고 싶은 경우 G0002번 세대 V00번 버전을 G0002번 세대 V01번 버전으로 바꿀 수 있다. 한 세대에는 오직 한 버전만 GDG에 의해 관리된다.
세대 데이터셋을 카탈로그에 등록하는 경우에는 절대 이름과 상대 이름을 둘 다 사용할 수 있다. 세대가 등록된 경우에는 그 세대의 세대번호와 버전번호가 GDG 엔트리에 등록된다. 버전번호가 V00 이외의 세대 데이터셋을 등록하려면 절대 세대와 버전번호를 사용해야 한다.
7.2. 상대 세대번호
세대를 지정할 때 절대 세대와 버전번호를 사용해서 지정하는 방법 대신 상대적인 세대번호를 사용할 수 있다. 상대 세대번호를 사용하려면 GDG 이름 뒤에 괄호로 둘러쌓인 숫자를 지정해 주면 된다. 예를 들면 A.B.C(-1), A.B.C(+1), A.B.C(0)과 같다.
상대 세대번호가 주어지면 시스템은 가장 최근에 등록된 절대 세대번호를 참고해서 주어진 상대 세대번호에 해당하는 절대 세대번호를 찾는다. 예를 들어, 이전 작업에서 A.B.C.G0005V00이 마지막으로 카탈로깅된 세대 데이터셋이라면, A.B.C(+1)이 주어진 경우 시스템은 A.B.C.G0006V00의 절대 번호를 할당할 것이다.
7.3. 다중 Step 작업에서의 유의사항
다중 Step 작업에서 데이터셋을 카탈로깅하거나 언카탈로깅할 때에는 IEHPROGM(JSGPROGM)이나 다른 사용자 프로그램을 사용하지 않고, 순전히 JCL만을 이용해야 한다. IEHPROGM(JSGPROGM) 프로그램이나 사용자 프로그램 실행 중에 할당된 데이터셋은 데이터셋 할당 관리시스템에게 보고가 되지 않아, 이후의 작업 스텝에서 데이터셋의 현재 상태를 잃어버리게 되어서 충돌이 생기는 등 문제가 발생할 수 있다.
이전에 카탈로깅된 세대 데이터셋의 상대번호를 이용해서 참고하게 되면 상대번호는 다음과 같은 의미를 가진다.
-
A.B.C(0)은 가장 최근에 등록된 항목을 가리킨다.
-
A.B.C(-1)은 가장 최근에 등록된 항목의 이전 항목이다.
JCL을 사용해서 데이터셋의 카탈로깅 작업이 일어나면, 모든 실제 카탈로깅은 JOB STEP이 종료될 때 수행된다. 하지만 상대 세대번호는 실제 작업이 종료될 때까지 유지된다. 따라서 다음과 같은 현상이 일어날 수 있다.
-
JCL에서 사용되는 상대 세대번호는 Batch JOB 수행 중에는 항상 동일한 세대 데이터셋을 가리킨다.
-
세대 데이터셋에 대해 성공적으로 GDG에 카탈로깅이 끝난 스텝을 재실행 시킬 경우에 JCL을 submit 하기 전에 상대 세대번호를 모두 변경해야 한다. 예를 들어, Step을 재시작하기 전 A.B.C(+1)은 A.B.C(0)으로, A.B.C(0)은 A.B.C(-1)로, 그리고 A.B.C(-1)은 A.B.C(-2)로 바꾸어 주어야 한다.
8. 테이프 볼륨 이용
Non-VSAM 데이터셋은 테이프 디바이스 볼륨에 위치할 수 있다. VSAM 데이터셋이 저장되는 것은 지원하지 않는다.
OpenFrame에서의 테이프 볼륨은 실제 물리적 테이프 디바이스를 이용하는것 과는 무관하다. OpenFrame의 테이프 볼륨은 DASD 위에 위치할 수도 있으며 가상으로 테이프 볼륨을 이용하는 방식이다. volmgr를 통해 볼륨을 생성하는 과정에서 테이프 디바이스에 볼륨을 생성하는 것으로 테이프 볼륨을 생성할 수 있다. 테이프 디바이스를 정의할 때, 디바이스 타입 번호를 3480으로 지정해야 한다.
volmgr define device -dn 0010 -dt 3480 -dg STAPE
이후 이 테이프 디바이스에 속하는 논리 테이프 볼륨과 논리 테이프에 속하는 물리 테이프 볼륨을 정의한다.
volmgr define volume -v STAPE1 -dn 0010 volmgr define volume -v ST0001 -lv STAPE1 -t
논리 테이프 볼륨에 속하는 물리 테이프 볼륨은 둘 이상 생성할 수 있으며, 필요에 따라 볼륨을 스위치 하여 사용할 수 있다.
volmgr update volume -v STAPE1 -pv ST0002
8.1. 파일 순서번호
OpenFrame에서는 테이프 볼륨의 파일 순서번호를 이용한 접근 방식을 지원한다.
파일 순차번호를 이용하기 위해서는 OpenFrame 환경설정 중 ds 서브젝트, DATASET_DEFAULT 섹션의 USE_TAPE_FILESEQ 키의 VAUE 항목 값을 YES로 설정해야 한다.
ofconfig update -n NODE1 -s ds -sec DATASET_DEFAULT -k USE_TAPE_FILESEQ -v YES
파일 순차번호는 JCL을 통해 데이터셋에 접근하는 경우 이용할 수 있다. XSP 시스템에서 순서번호는 FILE에 기술하고, 그 외의 시스템에서는 DD 문의 LABEL에 기술한다. 순서번호를 이용하게 되면, 기본적으로 테이프 볼륨에서 순서번호로 이동하여 데이터셋을 찾게 된다. 부수적으로 데이터셋 이름은 순서번호의 위치에 존재하는 데이터셋과의 정합 여부를 확인하는데 이용하거나 신규 데이터셋을 생성하는 경우 이용된다. 순서번호가 생략된 경우에는 데이터셋 이름으로 테이프 볼륨에서 검색을 하여 데이터셋의 위치를 찾아가고, 지정한 데이터셋 이름이 존재하지 않으면 순서번호 1번으로 간주된다.
8.2. 데이터셋 삭제
파일 순서번호를 이용하지 않는 테이프 데이터셋의 삭제는 DASD에 존재하는 데이터셋의 삭제와 같다. 여기서는 파일 순서번호를 이용할 경우의 데이터셋 삭제 방식에 대해 기술한다.
실제 테이프 디바이스에서 새로운 데이터셋 혹은 기존의 데이터셋에 신규 레코드를 작성하는 경우 그 뒤에 존재하는 데이터셋들은 파괴가 되는 특징을 가지고 있다. OpenFrame에서도 이와 같은 특징을 지원한다. 실제 테이프의 물리적 특징에 따라 삭제되는 것은 아니며, 테이프 데이터셋에 대한 OPEN(OUTPUT 모드)이 이루어지는 시점에 현재 데이터셋 이후에 존재하는 파일 순서번호의 데이터셋들은 모두 삭제 처리한다. 단, 카탈로그에 등록된 경우 카탈로그는 그대로 남아있는다.
테이프 데이터셋의 경우 JOB의 DISP를 통한 삭제는 불가능하다. Mainframe에서 테이프 데이터셋에 대한 DISP으로 DELETE를 금지하고 있다. OpenFrame에서는 DELETE를 지정할 수는 있으나 내부적으로 KEEP으로 변환되어 삭제 처리가 되지 않는다. 단, dsdelete 툴을 통한 삭제는 가능하다. dsdelete 툴을 이용하여 데이터셋을 삭제할 때 해당 데이터셋과 그 이후에 존재하는 데이터셋이 모두 삭제된다.
8.3. 유의 사항
다음은 테이프 볼륨을 이용하는 유의사항에 대한 설명이다.
-
테이프 볼륨 Lock
OpenFrame에서는 파일 순서번호를 이용하는 경우에 한해 테이프 볼륨을 보호하기 위해 데이터셋 Lock뿐만 아니라 볼륨 Lock을 걸고 있다. 따라서 여러 개의 JOB에서 동시에 하나의 테이프 볼륨을 이용할 수 없다. 다만, 현재 OpenFrame에서 제공하는 Lock의 특성상, 동일한 응용 프로그램에서 하나의 테이프 볼륨에 존재하는 여러 개의 데이터셋을 동시에 이용을 방지하지는 못한다. 이런 경우 데이터셋 이용에 문제가 생길 수 있으므로 주의가 필요하다.
-
DCB Handling 이용 시 주의사항
파일 순서번호를 이용하는 경우 DCB Handling API 사용에 주의가 필요하다. 파일 순서번호를 이용하는 경우 테이프 데이터셋에 대한 DCB는 INPUT 모드를 가정하여 생성이 된다. OUTPUT 모드로 이용하려는 테이프 데이터셋에 대해서는 OPEN하기 전까지 올바른 정보를 가지고 있지 않을 수 있다. 따라서 DCB Information 함수들과 Get Attributes 함수들은 테이프 데이터셋의 OPEN 후에 수행하도록 한다.