데이터셋 마이그레이션
본 장에서는 데이터셋을 마이그레이션하는 방법에 대해 기술한다.
1. 개요
본 절에서는 Mainframe 환경에서 운용되던 데이터셋을 OpenFrame 환경에서 운용되도록 하기 위해 수행되어야 하는 데이터셋 전환 작업에 대해 설명한다.
데이터셋은 논리적으로 연결된 데이터 레코드의 집합이다. 여기서 레코드는 애플리케이션에서 사용되는 정보의 기본 단위를 의미한다. 데이터셋은 종류에 따라서 크게 Non-VSAM 데이터셋과 VSAM 데이터셋으로 구분된다.
|
데이터셋에 대한 자세한 내용은 OpenFrame Base "데이터셋 안내서"를 참고한다. |
-
Non-VSAM 데이터셋
Non-VSAM 데이터셋의 PDS, GDG, SAM 데이터셋, ISAM 데이터셋의 전환 방법은 다음과 같다.
구분 설명 PDS
PDS는 디렉터리와 멤버로 구성된 데이터셋이다. PDS 자체는 pdsgen 툴 또는 dscreate 툴을 사용하여 생성하고, PDS 데이터셋 안의 각 멤버 파일은 dsmigin 전환 툴로 문자 집합을 전환한다.
GDG
GDG는 세대(generation)로 구성된 데이터셋의 그룹이다. GDG 항목 자체는 gdgcreate 툴을 사용하여 카탈로그에 등록하고, GDS는 개별 SAM 데이터셋 전환 방법에 따라 전환 작업을 수행한다.
SAM 데이터셋
일반적인 Non-VSAM 데이터셋인 SAM 데이터셋은 COBOL Copybook 등의 자료를 참고해서 데이터셋 전환 스키마(DataSet Conversion Schema)를 먼저 작성한 후 dsmigin 전환 툴을 사용하여 OpenFrame 데이터셋으로 적재(import)한다.
ISAM 데이터셋
ISAM 데이터셋은 OpenFrame에서 지원하고 있으며, VSAM KSDS로 대체하여 사용할 수도 있다.
-
VSAM 데이터셋
VSAM 데이터셋의 KSDS, ESDS, RRDS, LDS의 전환 방법은 다음과 같다.
구분 설명 KSDS
KSDS는 먼저 idcams 툴의 DEFINE CLUSTER 명령어로 OpenFrame VSAM 데이터셋을 정의한다. 그리고 dsmigin 툴의 RECATALOG 옵션으로 데이터를 VSAM 데이터셋으로 적재한다.
ESDS
ESDS의 전환 절차는 앞의 KSDS의 전환 절차와 동일하다.
RRDS
RRDS은 각 레코드별로 레코드 번호가 부여되어 있다. 만약 데이터셋의 중간에 누락된 레코드 번호가 없다면 VSAM KSDS의 전환 절차와 동일하게 전환이 가능하다. 하지만 중간에 누락된 레코드 번호가 있는 경우 별도의 RRDS 적재 프로그램을 작성해서 전환을 수행해야 한다.
LDS
현재 VSAM LDS는 OpenFrame에서 지원되지 않는다. VSAM LDS 지원에 대한 고객의 요청이 있는 경우 TmaxSoft 기술 지원에 문의한다.
Mainframe에서 운용되던 데이터셋을 OpenFrame에서 그대로 운용하기 위해서는 데이터셋 전환 작업을 거치게 되는데, 데이터셋 전환 작업은 다음과 같이 데이터셋의 종류에 따라 전환 방법이 다르다.
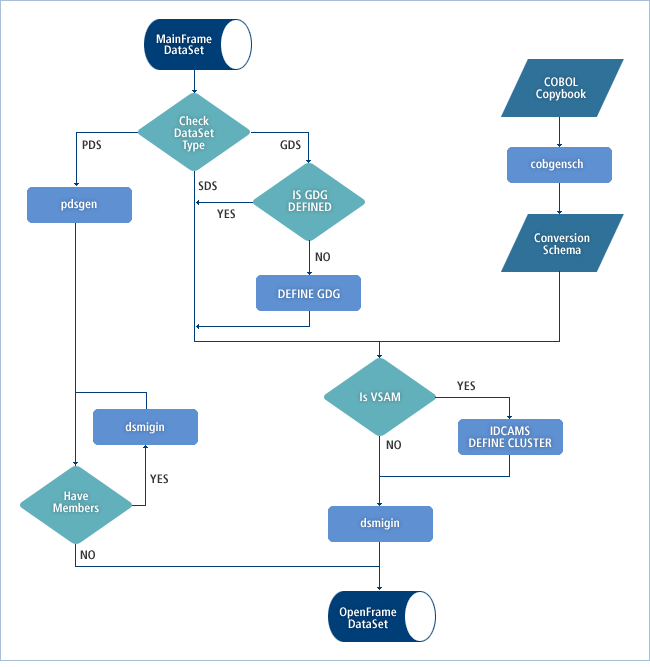
2. Non-VSAM 데이터셋 마이그레이션
OpenFrame에서 일반적인 Non-VSAM 데이터셋의 전환 절차는 다음과 같다.
-
전환 대상 파악 및 원본 다운로드
-
데이터셋 레이아웃 분석
-
데이터셋 전환 스키마
-
목적 데이터셋 전환
-
PDS 데이터셋 전환
-
GDG BASE 정의
-
가변 길이 데이터셋 전환
-
데이터셋 전환 검증
2.1. 전환 대상 파악 및 원본 다운로드
프로젝트 사이트에서 전환 대상이 되는 데이터셋의 목록을 작성하는 것은 성공적인 프로젝트 수행을 위해 매우 중요한 일이다. JCL이나 PROCEDURE를 분석해서 대상 목록을 작성하는 방법도 가능하지만, 대규모 프로젝트에서 OpenFrame으로의 전환이 이루어지면서 불필요해지거나, SMS 정책 또는 보안 정책과 관련하여 데이터셋 명칭이 변경되는 경우도 종종 있으므로 고객사에 정보를 요청하여 정확한 목록을 얻는 것이 필요하다.
전환 대상 데이터셋이 정해지면 대상 데이터셋에 대해 호스트(운영 중인 Mainframe)에서 사용하고 있는 데이터셋 원본을 다운받는다. 단, 호스트에서 데이터셋을 다운받을 때 데이터셋을 ASCII 형태로 받으면 특수문자, SOSI, 2Byte 문자들이 제대로 전환이 이뤄지지 않아 문제가 발생하므로, 가급적이면 호스트에서 사용하고 있는 EBCDIC 형태 그대로 데이터셋을 다운받는다.
2.2. 데이터셋 레이아웃 분석
데이터셋에 대한 전환이 정확하게 이루어지려면 해당 데이터셋에 대한 레이아웃 분석이 가장 중요하다. 현재 운영 중인 데이터셋의 경우에는 COBOL Copybook이나 데이터베이스 스키마를 조사하여 데이터셋 레이아웃 정보 추출이 가능하지만 오래된 데이터셋인 경우에는 데이터셋을 직접 열람하지 않고서는 정확한 레이아웃에 대한 분석이 어렵다.
일반적으로는 고객사에서 데이터셋에 대한 레이아웃 정보를 관리하므로 고객사로부터 레이아웃 정보를 제공받아 데이터셋 전환 작업을 수행하는 것이 일반적이다.
일반적인 경우 하나의 데이터셋의 모든 레코드는 하나의 레이아웃의 적용을 받지만, 일부 데이터셋의 경우 각 레코드들이 서로 다른 레이아웃의 적용을 받는 경우도 존재한다. 이러한 경우는 보통 COBOL 재정의문(REDEFINE)에 의해 여러 레이아웃이 생기거나 데이터셋의 레코드 자체가 가변 길이인 경우에 발생한다.
2.3. 데이터셋 전환 스키마
데이터셋 레이아웃 정보는 고객사의 운영상의 편의에 따라 여러가지 다양한 형태로 제공된다. 이러한 다양한 형태의 레이아웃을 모두 지원할 수 없으므로 다음과 같은 표준 COBOL Copybook 형태로 전환하여 사용한다.
Mainframe에서 데이터셋을 처리하는 응용 프로그램은 COBOL로 작성하는 경우가 가장 일반적이기 때문에 대부분의 경우 기존에 작성되어 있는 COBOL Copybook을 그대로 활용할 수 있다. COBOL Copybook 형태의 레코드 레이아웃 정보가 없는 경우 다른 형태로 정의되어 있는 레코드 레이아웃 정보를 COBOL Copybook 형태로 새로 작성해야 한다. Mainframe에서 COBOL Copybook 형태가 아닌 다른 형태의 레코드 레이아웃 정의 방법은 사상적으로 COBOL Copybook으로 정의하는 것과 유사하므로 어려운 작업은 아니다.
|
추가적으로 AIM DB의 마이그레이션의 편의를 위해 COBOL Copybook이 아닌 AIM DB 스키마 정보를 참조하여 AIM DB 언로드(UNLOAD) 데이이터 셋의 전환에 필요한 스키마를 생성해 주는 ndbgensch 툴이 제공된다. 자세한 내용은 데이터베이스 마이그레이션 을 참고한다. |
<XTBC106.cpy>
01 I1.
05 KYAKUMEI-KN PIC X(0018).
05 BTN-CD PIC X(0004).
05 KYAKU-NO PIC X(0007).
05 ATUKAI-CD PIC X(0003).
05 MDY-CD PIC X(0003).
05 YAKU-YMD PIC S9(0009) COMP-3.
05 UKEW-YMD PIC S9(0009) COMP-3.
05 KOYU-MEI-CD PIC S9(0005) COMP-3.
05 KAISU PIC S9(0005) COMP-3.
05 GO .
10 GO-1 PIC X(0001).
10 GO-2 PIC X(0001).
10 GO-3 PIC X(0001).
데이터셋 레이아웃 정보를 나타내는 COBOL Copybook 파일 <XTBC106.cpy>이 있는 경우 다음과 같이 cobgensch 툴을 사용해서 데이터셋 전환 스키마 파일을 생성할 수 있다.
아래 명령어에서는 [-r] 옵션으로 레코드 길이를 54로 지정하였는데 이렇게 설정할 경우 COBOL Copybook 파일의 각 필드 길이를 더한 실제 레코드 길이와 일치하는지를 체크한다.
$ cobgensch XTBC106.cpy –r 54다음은 앞의 예제 파일 <XTBC106.cpy>를 cobgensch 툴을 실행시켜 생성된 데이터셋 전환 스키마 파일의 내용이다.
COBOL Copybook의 PIC 구문으로 구성된 각 문장들이 데이터셋 전환 스키마 형식으로 변환된 것을 확인할 수 있다. 위에서 사용된 PIC X 구문은 EBCDIC 문자를 ASCII 문자로 전환하기 위한 EBC_ASC 타입으로 지정되었고, PIC S9의 COMP-3 구문은 PACKED 타입으로 지정된 것을 볼 수 있다. 여기서 사용된 타입 외에 Zoned Decimal 값을 표현하는 ZONED 타입과 2Byte 문자를 나타내는 GRAPHIC 타입이 존재한다.
<XTBC106.conv>
* Schema Version 5.1 L1, 01, I1, NULL, 0, 1, L2, 05, KYAKUMEI-KN, EBC_ASC, 18, 1, L3, 05, BTN-CD, EBC_ASC, 4, 1, L4, 05, KYAKU-NO, EBC_ASC, 7, 1, L5, 05, ATUKAI-CD, EBC_ASC, 3, 1, L6, 05, MDY-CD, EBC_ASC, 3, 1, L7, 05, YAKU-YMD, PACKED, 5, 1, L8, 05, UKEW-YMD, PACKED, 5, 1, L9, 05, KOYU-MEI-CD, PACKED, 3, 1, L10, 05, KAISU, PACKED, 3, 1, L11, 05, GO, NULL, 0, 1, L12, 10, GO-1, EBC_ASC, 1, 1, L13, 10, GO-2, EBC_ASC, 1, 1, L14, 10, GO-3, EBC_ASC, 1, 1, * Condition L0, "\0", ( L1 L2 L3 L4 L5 L6 L7 L8 L9 L10 L11 L12 L13 L14 )
|
스키마 파일 구조에 대한 자세한 내용은 스키마 파일의 구조를 참고한다. |
2.4. 목적 데이터셋 전환
전환 대상이 되는 원본 데이터셋과 전환 스키마 파일이 있으면 dsmigin 툴을 사용하여 데이터셋 전환 작업을 수행한다. dsmigin 툴은 각 레코드 데이터의 코드 전환 작업 및 데이터셋의 카탈로그 등록 작업을 수행한다.
다음은 원본 파일 <XTB.T66.raw>과 전환 스키마 파일 <XTB.T66.conv>을 dsmigin 툴을 사용하여 <XTB.T66> 데이터셋을 생성하는 예이다.
$ dsmigin XTB.T66.raw XTB.T66 –s XTB.T66.conv –e JAK –l 800|
dsmigin 툴에 대한 자세한 내용은 OpenFrame Base "툴 참조 안내서"를 참고한다. |
2.5. PDS 전환
PDS는 디렉터리와 멤버 파일로 구성된 데이터셋으로 JCL 또는 PROC의 DSN 파라미터에 PDS 명칭과 함께 괄호로 둘러 싸인 멤버 이름으로 표기된다.
//SYSIN DD DSN=PLNI.EDVR.SYSIN(LNIYY01), // DISP=(SHR,PASS,KEEP)
PDS 데이터셋은 보통 실행 모듈을 관리하는 라이브러리 데이터셋으로 사용되거나 JCL, PROC, SYSIN 등의 파일을 관리하는 라이브러리 데이터셋으로 사용된다.
OpenFrame에서 PDS는 UNIX 파일 시스템의 디렉터리로 관리되며, pdsgen 또는 dscreate 툴로 생성할 수 있다.
다음은 dscreate 툴을 사용하여 TEST.PDS란 이름의 PDS를 생성하는 예이다.
$ dscreate -o PO TEST.PDSPDS를 생성할 때의 유의할 점은 SYSIN 타입의 데이터셋인 경우에는 반드시 레코드 포맷을 “L” 타입으로 명시해야 한다는 것이다. 레코드 포맷 “L” 타입은 Mainframe에서는 존재하지 않는 레코드 포맷으로 UNIX 플랫폼 환경에 맞추어 줄바꿈(linefeed)을 하나의 레코드 단위로 인식하기 위해 OpenFrame에서 지원하는 새로운 레코드 포맷이다.
실행 모듈을 관리하는 PDS에는 컴파일된 실행 모듈들을 해당 PDS의 디렉터리의 멤버로 저장하도록 한다. 그 밖의 JCL, PROC, SYSIN 등의 파일 관리 용도로 사용되는 PDS의 멤버 파일은 Mainframe에서 다운받은 EBCDIC 형태의 원본 파일을 dsmigin 툴을 사용하여 문자 집합을 전환한 다음 전환된 파일을 해당 PDS의 멤버로 저장하도록 한다.
2.6. GDG BASE 정의
GDG BASE 항목은 순수 카탈로그 항목으로 gdgcreate 툴로 생성할 수 있다. GDG BASE 항목을 생성할 때 GDG LIMIT 값은 고객사로부터 정확한 정보를 전달받아 생성하도록 한다.
다음은 gdgcreate 툴을 사용하여 GDG BASE를 정의하는 예이다.
$ gdgcreate -l 255 TEST.GDG01GDG BASE 항목이 특정 사용자 카탈로그에 등록되면 연관된 모든 GDS(GDG 그룹 내의 데이터셋) 데이터셋은 동일한 사용자 카탈로그에 등록된다. 만약 GDG BASE 항목을 생성하지 않고 GDS 데이터셋에 대한 카탈로깅을 시도하면 AMS_ERR_GDG_NOT_REGISTERED (-4025) 에러가 발생한다.
2.7. 가변 길이 데이터셋 전환
가변 길이 데이터셋의 전환 절차는 일반적인 데이터셋의 전환 절차와 동일하다. 단, 데이터셋 레이아웃을 분석하고 전환 스키마를 생성하는 작업은 주의를 해야 한다.
가변 길이 데이터셋의 경우 Mainframe에서 다운받은 원본 데이터셋은 다음 그림과 같이 순차파일의 형태와 동일하다. 단, 각 레코드는 4Byte로 이루어진 RDW(Record Descriptor Word)와 그 뒤에 따라오는 데이터로 구성되어 있다. RDW의 첫 2Byte에는 RDW 4Byte를 포함한 레코드 길이 정보를 담고 있고, 나머지 2Byte는 0으로 이루어져 있다. 이러한 RDW의 레코드 정보를 이용하여 레코드의 시작과 끝을 구분지을 수 있다.

가변 길이 데이터셋에 대한 전환 스키마의 경우 고정 길이 데이터셋과 마찬가지로 데이터셋의 레이아웃을 COBOL Copybook 형태로 정리하고, 이것을 cobgensch 툴을 사용하여 전환 스키마를 생성한다. 단, 프로젝트 상황에 따라 COBOL Copybook 형태로 정리하는 단계를 건너 뛰고 다음과 같은 전환 스키마 파일을 바로 작성해서 사용하기도 한다.
* Schema Version 5.1 L1, 01, V-REC, NULL, 0, 1, L2, 05, REC-KEY, EBC_ASC, 8, 1, L3, 05, ODO-LEN, COPY, 2, 1, L4, 05, ODO-FLD, NULL, 0, 4000, ODO-LEN L5, 07, ODO-DAT, EBC_ASC, 1, 1, * Condition L0, "\0", ( L1 L2 L3 L4 L5 )
앞의 스키마 파일 ODO-FLD가 ODO-LEN 필드의 값에 따라 길이가 변화는 가변 데이타 셋의 예제이다. 각 레코드의 변환 작업을 수행하며 해당 레코드의 ODO-LEN 필드 값을 읽어 ODO-FLD의 반복 횟수 및 데이터셋의 길이가 결정된다. 원본 데이터셋과 전환 스키마 파일이 준비되었으면 고정 길이 데이터셋과 동일하게 dsmigin 툴을 사용하여 데이터셋 전환 작업을 수행한다.
다음은 원본 파일 <TEST.VAR.raw>과 전환 스키마 파일 <TEST.VAR.conv>을 dsmigin 툴을 사용하여 전환되어 저장될 데이터셋 <TEST.VAR>을 생성하는 예이다.
$ dsmigin TEST.VAR.raw TEST.VAR –s TEST.VAR.conv –e JP -f VB
3. VSAM 데이터셋 마이그레이션
OpenFrame에서 일반적인 VSAM 데이터셋의 전환 절차는 다음과 같다.
-
idcams 툴의 DEFINE CLUSTER 명령어로 비어있는 VSAM 데이터셋을 정의한다.
-
dsmigin 툴의 RECATALOG 옵션으로 데이터를 VSAM 데이터셋으로 적재한다.
위의 방법으로 전환되지 않는 데이터셋은 별도의 데이터셋 적재 프로그램을 작성해서 전환해야 한다. 데이터셋의 중간에 누락된 레코드 번호가 있는 VSAM RRDS 데이터셋이 이 경우에 해당한다.
3.1. VSAM 데이터셋 정의
VSAM 데이터셋은 idcams 툴의 DEFINE CLUSTER 명령으로 정의할 수 있다.
다음은 idcams 툴을 사용하여 VSAM 데이터셋을 정의하는 예이다.
$ idcams DEFINE CLUSTER -n TEST.KSDS -o KS -k 6,0 -l 250,250
|
3.2. VSAM 데이터셋 적재
VSAM 데이터셋을 적재하는 방법으로 dsmigin 툴을 사용할 수 있다. 다만, Non-VSAM 데이터셋을 마이그레이션 하는 방법과는 달리 우선 idcams 툴의 DEFINE CLUSTER 명령으로 VSAM 데이터셋을 정의한 후, dsmigin 툴의 -R(Recatalog) 옵션으로 마이그레이션해야 한다.
다음은 dsmigin 툴을 사용하여 <XTB.XY1315>라는 Non-VSAM 데이터셋의 모든 레코드 데이터를 <TEST.VSAM.KSDS>라는 VSAM 데이터셋으로 적재하는 예이다.
$ dsmigin XTB.XY1315 TEST.KSDS –s XTB.XY1315.conv –e JP -R
이전 버전에서는 마이그레이션 툴을 사용하여 VSAM 데이터셋을 적재하는 방식을 지원하지 않았기 때문에, IDCAMS 유틸리티의 REPRO 명령을 사용하여 SAM 형식의 Non-VSAM 데이터셋을 VSAM 데이터셋으로 복사하는 방식을 사용했다.
|
현재 버전에서는 dsmigin 툴을 사용하여 VSAM 데이터셋을 적재하는 방식을 지원하므로 IDCAMS 유틸리티를 사용하는 것보다 dsmigin 툴을 사용하는 것을 권장한다. |
3.3. 데이터셋 적재 프로그램 작성
데이터셋의 중간에 누락된 레코드 번호가 있는 VSAM RRDS의 경우와 같이 dsmigin 툴을 사용하여 데이터셋을 적재할 수 없는 경우에는 별도의 적재 프로그램을 작성해서 데이터셋을 적재시켜 주어야 한다.
데이터셋 전환 절차는 다음과 같다.
-
Mainframe에서 다운받은 원본 데이터셋을 dsmigin 툴을 사용하여 문자 집합을 전환한다.
-
idcams 툴의 DEFINE CLUSTER 명령어로 비어있는 VSAM 데이터셋을 정의한다.
-
마지막으로 데이터셋 적재 프로그램을 실행시켜 데이터셋을 적재한다.
데이터셋 적재 프로그램을 작성할 때에는 UNIX 플랫폼에서 가장 널리 사용되는 C 언어를 사용해서 작성한다.
|
레코드 WRITE 함수를 호출해 개별 레코드를 정확한 키 위치에 적재시키는 프로그램 작성은 OpenFrame Base "데이터셋 안내서"의 부록 "데이터셋 I/O API"의 내용을 참고한다. |
4. 정적 변환과 동적 변환
OpenFrame에서는 데이터셋을 마이그레이션하는 방식으로 정적 변환과 동적 변환처리의 2가지 방식이 있다. 데이터셋을 마이그레이션할 때에는 데이터셋의 스키마 정보를 확인하여 정적 변환으로 마이그레이션을 할 것인지 동적 변환으로 할 것인지 결정해야 한다.
4.1. 정적 변환과 동적 변환의 비교
-
정적 변환
정적 변환은 데이터셋에 대한 마이그레이션을 수행할 때 사용자가 최초에 $$COND 조건에 지정한 마이그레이션 경로 중 하나를 결정한 후 나머지 모든 레코드가 이 경로 정보를 이용하여 마이그레이션을 진행하는 변환이다.
-
동적 변환
동적 변환은 마이그레이션을 수행할 때에 '동적 변환 테이블’을 관리하면서 사용자가 지정한 $$COND 조건을 모든 그룹 아이템에 대해 체크를 하면서 이에 대한 정보를 '동적 변환 테이블’에 변경을 하면서 $$COND 조건에 대한 분석이 완료된 후 이 정보를 이용하여 마이그레이션을 진행하는 변환이다.
동적 변환은 모든 그룹 아이템마다 $$COND 조건을 판별하기 때문에 정적 변환보다 상대적으로 성능이 낮다. 하지만 동적 변환을 반드시 사용해야하는 경우에는 정적 변환을 사용할 수 없으며, 동적 변환 사용을 권장하는 경우에는 정적 변환을 사용할 수 있지만, 동적 변환을 사용하면 정적 변환에 비해 간결하게 스키마 정보를 생성할 수 있다. 이외의 경우에는 필요에 따라 동적 변환을 사용할 수 있다.
4.2. 동적 변환을 반드시 사용해야하는 경우
다음의 경우에는 반드시 동적 변환을 지정해야 한다.
-
스키마 파일을 생성하는 Copybook 내의 $$COND 조건을 판별하는 필드가 OCCURS 내에 있는 경우
$$COND 조건을 판별하는 필드가 OCCURS 내에 있는 경우 정적 변환을 사용하면 첫 번째 OCCURS의 값을 보고 변환할 마이그레이션 경로를 결정하게 된다. 만약, 첫 번째 OCCURS 이후의 조건을 판별하는 필드의 값이 첫 번째와 상이한 경우에도 처음 지정한 마이그레이션 경로로 변환 처리를 하므로 정상적인 변환처리가 되지 않을 수도 있다.
01 A OCCURS 10 TIMES.
05 KBN PIC X.
05 B1 PIC N(3)
05 B2 PIC X(6) REDEFINES B1.
$$COND : KBN : "1" : B1
$$COND : KBN : !"1" : B2
4.3. 동적 변환 사용을 권장하는 경우
다음의 경우에는 정적 변환을 사용할 수 있지만, 동적 변환을 이용하면 좀더 효율적으로 스키마 파일을 생성할 수 있다.
-
조건을 판별하는 항목에 따른 변환 대상 항목이 LIST 형태로 존재하는 경우
$$COND 조건을 만족하는 경우에 변환 대상 항목이 LIST 형태로 존재하는 경우 정적 변환을 이용하면 모든 항목을 기술해야 한다. 이론적으로 이 숫자는 최소한 2^n만큼 작성해 한다. 하지만, 동적 변환을 이용하면 이를 2*n만큼으로 줄일 수가 있다.
03 A OCCURS 10 TIMES.
05 KBN1 PIC X.
05 B1 PIC N(3).
05 B2 PIC X(6) REDEFINES B1.
05 C1 PIC X(5).
05 C2 PIC 9(5) REDEFINES C1.
05 D1 PIC X(5).
05 D2 PIC 9(5) REDEFINES D1
<정적 변환을 이용한 $$COND 조건 기술>
$COND : KBN1 : X"01" : B1, C1, D1
$COND : KBN1 : X"02" : B1, C1, D2
$COND : KBN1 : X"03" : B1, C2, D1
$COND : KBN1 : X"04" : B1, C2, D2
$COND : KBN1 : X"05" : B2, C1, D1
$COND : KBN1 : X"06" : B2, C1, D2
$COND : KBN1 : X"07" : B2, C2, D1
$COND : KBN1 : X"08" : B2, C2, D2<동적 변환을 이용한 $$COND 조건 기술>
$COND : KBN1 : X"01", X”02”, X”03”, X”04” : B1
$COND : KBN1 : X"04", X”05”, X”06”, X”07” : B2
$COND : KBN1 : X"01", X”02”, X”05”, X”06” : C1
$COND : KBN1 : X"03", X”04”, X”07”, X”08” : C2
$COND : KBN1 : X"01", X”03”, X”05”, X”07” : D1
$COND : KBN1 : X"02”, X”04”, X”06”, X”08” : D24.4. 동적 변환 사용 방법 및 처리 순서
데이터셋을 마이그레이션을 하기위해 동적 변환 처리를 해야한다면, 먼저 동적 변환 스키마를 생성해야 한다. cobgensch에서 동적 변환 스키마를 생성하는 옵션은 -D를 지정한다.
$ cobgensch -D XXX.scm동적 변환 스키마를 생성하면 dsmigin 툴을 이용하여 동적 변환 마이그레이션을 수행한다. dsmigin을 수행할 때 별도의 옵션을 지정하지 않아도 생성된 스키마 정보를 이용하여 변환한다.
$ dsmigin EBCDIC ASCII -s XXX.scm|
cobgensch와 dsmigin 툴에 대한 자세한 설명은 OpenFrame Base "툴 참조 안내서"를 참조한다. |
5. 데이터셋 전환 예제
데이터셋 전환 예제는 고정 길이 데이터셋, 가변 길이 데이터셋, 재정의문이 사용되는 데이터셋으로 나누어서 살펴본다.
5.1. 고정 길이 데이터셋
다음은 레코드 길이가 16이고 3개의 레코드를 가지고 있는 Mainframe EBCDIC 데이터셋 <FL.SAMPLE.raw>이다.

다음의 COBOL Copybook <FL.SAMPLE.cpy> 형태의 예제를 통해 해당 데이터셋의 레이아웃 정보를 파악할 수 있다.
<FL.SAMPLE.cpy>
01 FIXEDLENGTH.
05 KEY PIC X(4).
05 TYPE PIC X(6).
05 DATA.
10 EBCDATA PIC X(3).
10 ZONEDDATA PIC S9(3).
데이터셋의 레이아웃 정보가 파악되면, 다음과 같이 cobgensch 툴을 사용하여 전환 스키마 파일을 생성한다.
$ cobgensch FL.SAMPLE.cpycobgensch 툴을 실행시킨 결과의 전환 스키마 파일은 다음과 같다.
<FL.SAMPLE.conv>
* Schema Version 5.1 L1, 01, FIXEDLENGTH, NULL, 0, 1, L2, 05, KEY, EBC_ASC, 4, 1, L3, 05, TYPE, EBC_ASC, 6, 1, L4, 05, DATA, NULL, 0, 1, L5, 10, EBCDATA, EBC_ASC, 3, 1, L6, 10, ZONEDDATA, ZONED, 3, 1, * Condition L0, "\0", ( L1 L2 L3 L4 L5 L6 )
원본 데이터셋과 전환 스키마 파일이 준비되면 dsmigin 툴을 사용해서 데이터셋 전환 작업을 수행한다.
$ dsmigin FL.SAMPLE.raw FL.SAMPLE.TEST –s FL.SAMPLE.conv –l 16전환이 완료되면 마지막으로 dsview 툴을 사용하여 원하는 결과가 나왔는지 확인한다.

5.2. 가변 길이 데이터셋
다음과 같이 가변 길이 레코드를 가진 Mainframe 데이터셋을 예제로 설명한다.
00000001..AAAAAAAAAAAA 00000002..BBBB 00000003..CCCCCCCCCCCCCCCCCCCCC
Mainframe에서 다운받은 데이터셋 <VB.SAMPLE.raw>의 형태는 다음 그림과 같이 각 레코드 맨 처음에 4Byte의 RDW(Record Description Word)를 포함하고 있다.

해당 데이터셋의 레이아웃 정보는 Copybook에 다음과 같이 나타난다.
<VB.SAMPLE.cpy>
01 V-REC.
05 REC-KEY PIC X(8).
05 ODO-LEN PIC S9(4) COMP.
05 ODO-FLD OCCURS 4000 TIMES
DEPENDING ON ODO-LEN.
07 ODO-DAT PIC X(1).
주어진 Copybook을 입력으로 해서 cobgensch 툴을 실행하면 다음과 같은 전환 스키마 파일을 얻을 수 있다.
* Schema Version 5.1 L1, 01, V-REC, NULL, 0, 1, L2, 05, REC-KEY, EBC_ASC, 8, 1, L3, 05, ODO-LEN, COPY, 2, 1, L4, 05, ODO-FLD, NULL, 0, 4000, ODO-LEN L5, 07, ODO-DAT, EBC_ASC, 1, 1, * Condition L0, "\0", ( L1 L2 L3 L4 L5 )
원본 데이터셋과 전환 스키마가 준비되면 dsmigin 툴을 사용하여 해당 데이터셋을 다음과 같이 전환한다.
$ dsmigin VB.SAMPLE.raw VB.SAMPLE.TEST –s VB.SAMPLE.conv –e JAK -f VB<VB.SAMPLE.raw>는 다운받은 원본 파일이고, <VB.SAMPLE.TEST>는 전환되어 저장될 데이터셋이며, <VB.SAMPLE.conv>는 전환 스키마 파일이다.
5.3. 재정의문(REDEFINES)이 사용되는 데이터셋
다음과 같이 재정의문(REDEFINES)이 들어있는 레이아웃을 가진 데이터셋의 경우에는 어떤 조건에 의해서 분기하는지에 대한 정보가 있어야 한다.
01 A.
05 B PIC X(01).
05 C PIC X(05).
05 D REDEFINES C.
10 E PIC X(02).
10 F PIC X(03).
만약 필드 B의 값이 A인 경우에만 REDEFINE된 D의 정보를 참조하고 그 외 나머지 경우에는 C의 정보를 참조하는 경우 COPYBOOK에 $$COND라는 조건 구문을 추가해야 한다.
$$COND 구문을 사용하는 방법은 다음과 같다.
$$COND : NAME_01 : VALUE_01 [: NAME_02 : VALUE_02 … ] : REDEFINE_NAME [...]-
$$COND
-
레이블로서 조건 구문의 시작을 나타낸다.
-
-
NAME_01 : VALUE_01
-
필드명과 그 필드에 해당하는 조건값을 차례로 입력한다. 각 항목을 구분하기 위하여 콜론(:)을 구분 문자로 사용한다. dsmigin 툴을 사용하여 마이그레이션할 때 VALUE_#에 사용되는 조건값은 이미 정의되어 있는 NAME_# 필드 항목의 포맷으로 자동 변환된다. 따라서 사용자는 EBCDIC, ZONED, PACKED 등 해당 필드의 포맷을 고려하지 않고 ASCII 값을 따옴표(") 안에 입력하면 된다.
-
NAME_# : VALUE_# 조건이 다수 개 사용될 경우에도 각 조건을 구분 문자인 콜론(:)으로 분리한다.
-
-
REDEFINE_NAME
-
해당 조건이 성립되었을 경우 실행할 1개 또는 다수의 REDEFINE 필드명을 지정하면, 조건문 작성이 완료된다.
-
조건 구문에 값을 입력할 때 값의 타입을 명시적으로 지정하여 해당 필드의 타입을 사용하지 않고 원하는 타입으로 변환할 수 있다.
-
사용자 지정 필드 타입은 다음과 같다.
타입 설명 ! (느낌표)
NOT EQUALITY를 체크한다.
'(empty)'
해당 필드의 디폴트 타입으로 변환한다.
'A'
입력한 값을 ASCII 문자 그대로 사용한다.
'E'
EBCDIC 문자로 변환한다.
'P' or 'UP'
Packed Decimal 또는 Unsigned Packed Decimal 포맷으로 변환한다.
'Z' or 'UZ'
Zoned Decimal 또는 Unsigned Zoned Decimal 포맷으로 변환한다.
'G'
GRAPHIC(2Byte) 문자로 변환한다.
'H'
입력한 값을 Hexadecimal 값으로 변환한다. (예: H"123" → 0x7B)
'X'
입력한 2Byte 값을 1Byte Hexa값으로 변환한다. (예: X"12AB" → 0x12 0xAB)
-
Packed 또는 Zoned Decimal에 대한 조건값을 지정하는 경우 해당 필드가 Signed와 Unsigned Deical 값 중 어떤 포맷을 사용하는지를 고려하여 조건값의 타입을 지정해야 한다. 예를 들어, Packed Decimal 필드 맨 끝 자리 수의 Hexa값이 '0x0C'(양수) 또는 '0x0D'(음수)로 지정되었을 경우 'P' 타입을 지정하여 Signed Packed Decimal 포맷으로 조건값을 변환해야 한다. 반대로 마지막 Hexa값이 '0x0F’인 경우에는 'UP' 타입을 지정하여 Unsigned Packed Decimal 포맷으로 변환해야 한다.
Zoned Decimal에 대한 조건 값을 지정하는 경우 Packed Decimal과는 달리 Zoned Decimal 필드의 맨 끝 자리 수의 Hexa값이 '0xC0'(양수) 또는 '0xD0'(음수)로 지정되어 있을 경우 'Z' 타입을 지정하여 Signed Zoned Decimal 포맷으로 조건 값을 변환해야 한다. 그리고 마지막 Hexa값이 '0xF0’인 경우에는 'UZ' 타입을 지정하여 Unsigned Zoned Decimal 포맷으로 변환해야 한다.
-
다음은 앞서 봤던 재정의문이 들어있는 Copybook에 $$COND 조건 구문을 사용한 예이다.
01 A.
05 B PIC X(01).
05 C PIC X(05).
05 D REDEFINES C.
10 E PIC X(02).
10 F PIC X(03).
$$COND : B : "A" : D
cobgensch 툴은 $$COND 문장의 정보를 참조해서 dsmigin 툴이 사용할 수 있는 전환 스키마를 생성한다.
다음은 생성된 전환 스키마 예이다.
* Schema Version 5.1 L1, 01, A, NULL, 0, 1, L2, 05, B, EBC_ASC, 1, 1, L3, 05, C, EBC_ASC, 5, 1, L4, 05, D, NULL, 0, 1, # REDEFINES C L5, 10, E, EBC_ASC, 2, 1, L6, 10, F, EBC_ASC, 3, 1, * Condition L2, "A", ( L1 L2 L4 L5 L6 ) L0, "\0", ( L1 L2 L3 )
이렇게 생성된 스키마 파일을 이용해서 데이터셋의 레코드를 전환하면, 데이터셋 각 레코드의 필드 B의 위치에 있는 값에 따라 전환 규칙이 적용되어 데이터셋이 전환된다.
Copybook에서 작성했던 조건을 제외한 1개의 조건이 더 생성된 것을 볼 수 있는데, 마지막 줄에 생성된 'L0’은 레이블을 가진 조건은 디폴트로 실행되는 조건 구문이다.
5.4. 여러 레이아웃을 사용하는 데이터셋
복수의 레이아웃을 사용하는 데이터셋의 경우에는 이전 섹션에서 설명한 재정의문(REDEFINES)을 처리하는 것과 유사한 방식으로 조건 구문을 작성해야 한다.
01 AAA-A.
03 BBB-A.
05 DATA-1 PIC X(01).
05 DATA-2 PIC X(04).
05 DATA-A REDEFINES DATA-2.
07 DATA-A1 PIC 9(02).
07 DATA-A2 PIC X(02).
01 AAA-B.
03 BBB-B.
05 DATA-3 PIC 9(01).
05 DATA-4 PIC 9(04).
05 DATA-D REDEFINES DATA-4.
07 DATA-D1 PIC 9(01).
07 DATA-D2 PIC X(03).
위와 같이 01 레벨의 항목이 여러 개 존재할 때 1번째 이후의 레이아웃을 사용하기 위해서는 재정의문 처리와 동일하게 $$COND 구문을 사용해야 한다.
특정 레이아웃을 사용하기 위한 $$COND 구문을 작성하는 방법은 다음과 같다.
$$COND : DATA-3 : "B" : AAA-B다음은 2번째 레이아웃에 있는 재정의문을 함께 지정하기 위해 작성한 $$COND 구문이다.
$$COND : DATA-3 : "D" : AAA-B DATA-D다음은 cobgensch 툴을 사용하여 생성한 스키마 파일이다.
* Schema Version 5.1 L1, 01, AAA-A, NULL, 0, 1, L2, 03, BBB-A, NULL, 0, 1, L3, 05, DATA-1, EBC_ASC, 1, 1, L4, 05, DATA-2, EBC_ASC, 4, 1, L5, 05, DATA-A, NULL, 0, 1, # REDEFINES DATA-2 L6, 07, DATA-A1, U_ZONED, 2, 1, L7, 07, DATA-A2, EBC_ASC, 2, 1, L8, 01, AAA-B, NULL, 0, 1, L9, 03, BBB-B, NULL, 0, 1, L10, 05, DATA-3, U_ZONED, 1, 1, L11, 05, DATA-4, U_ZONED, 4, 1, L12, 05, DATA-D, NULL, 0, 1, # REDEFINES DATA-4 L13, 07, DATA-D1, U_ZONED, 1, 1, L14, 07, DATA-D2, EBC_ASC, 3, 1, * Condition L10, "B", ( L8 L9 L10 L11 ) L10, "D", ( L8 L9 L10 L12 L13 L14 ) L0, "\0", ( L1 L2 L3 L4 )
생성된 스키마 파일을 보면 01 레벨을 포함하고 있는 2개의 레이아웃이 포함되어 있으며, 디폴트 조건을 제외하고 $$COND 구문으로 작성한 조건들이 모두 2번째 01 레벨 항목인 필드 AAA-B부터 시작하는 것을 확인할 수 있다.
이렇게 생성된 스키마 파일을 이용하면, 재정의문을 사용한 것과 같이 필드 DATA-3의 위치에 있는 값에 따라 전환 규칙이 적용되어 다수의 레이아웃을 사용하는 데이터셋도 전환할 수 있다.