고급 기능
사용자 애플리케이션의 처리에 가장 잘 맞는 OpenFrame HiDB 데이터베이스 유형을 결정했다면, 이번 장에서는 OpenFrame HiDB의 부가적인 고급 기능을 사용할 것인지에 대해 결정해야 한다.
본 장에서는 OpenFrame HiDB의 고급 기능인 Logical Relationship(논리적 관계)과 Secondary Indices(보조 인덱스)에 대해 설명한다.
1. Logical Relationship
HiDB 시스템에서는 Logical Relationship을 통해 물리적으로 서로 다른 2개의 데이터베이스를 연결해서 사용할 수 있는 기능을 제공한다. 이에 따라 Logical Relationship에 포함되어 있는 특정 세그먼트에 대해 부가적인 접근 방법을 제공하는 새로운 계층 구조가 정의된다.
데이터베이스 관리자는 Logical Relationship에 참여하는 물리 데이터베이스를 사용해서 논리 데이터베이스라고 불리는 새로운 데이터베이스를 정의한다. 논리 데이터베이스는 애플리케이션에게 앞서 언급한 새로운 계층 구조에 대한 형식을 제공한다.
다음은 애플리케이션에서 자주 사용하는 데이터 접근 방법에 따라, 설계 단계에서 PART 데이터베이스와 ORDER 데이터베이스 2개의 물리적인 데이터베이스로 구현한 예이다.
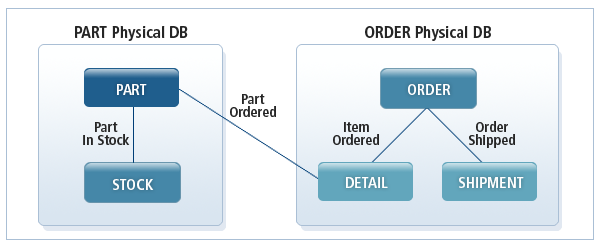
하지만 특정 애플리케이션에서는 PART 데이터베이스의 PART 세그먼트와 ORDER 데이터베이스의 DETAIL 세그먼트 사이의 관계를 사용할 필요가 있다. 따라서 PART 데이터베이스와 ORDER 데이터베이스 사이에 Logical Relationship을 정의한다.
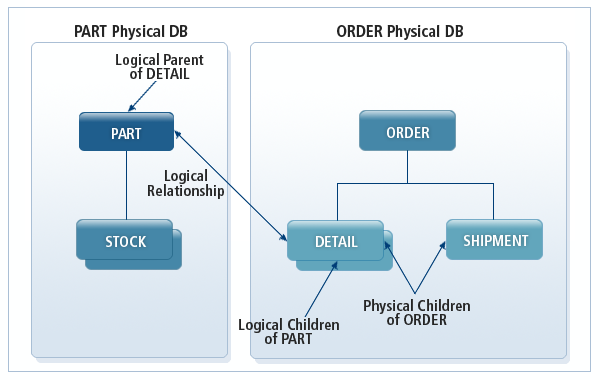
Logical Relationship을 정의하는 기본적인 방법은 양쪽 데이터베이스에 모두 관계가 있는 특정 세그먼트를 다른 데이터베이스에 있는 논리 부모 세그먼트와 연결함으로써 논리 자식 세그먼트로 지정하는 것이다. 이렇게 지정하면 논리 자식 세그먼트는 물리 부모 세그먼트와 논리 부모 세그먼트의 2개의 부모 세그먼트를 갖게 된다.
다음 그림에서 보면 논리 자식 세그먼트인 DETAIL의 인스턴스가 1개 추가되면, 2개의 계층 구조에 모두 참여하게 된다. DETAIL 세그먼트 인스턴스는 동시에 물리 부모 세그먼트인 ORDER와 논리 부모 세그먼트인 PART를 갖는다.
부가적인 2개의 논리 데이터베이스를 정의함으로써, 다음 그림과 같이 새로운 2개의 논리 데이터 구조를 얻을 수 있다. 이 새로운 데이터 구조는 한 애플리케이션에서 동시에 사용될 수도 있다.
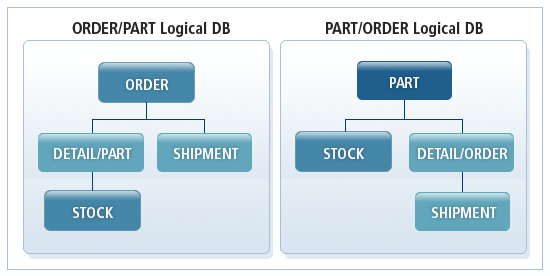
위 그림의 DETAIL/PART는 논리 자식 세그먼트와 논리 부모 세그먼트를 연결해서 만들어진 세그먼트이고, DETAIL/ORDER는 논리 자식 세그먼트와 물리 부모 세그먼트를 연결해서 만들어진 세그먼트이다. 이러한 세그먼트를 연쇄 세그먼트(Concatenated Segment)라고 한다.
같은 논리 부모 세그먼트 인스턴스를 갖는 논리 자식 세그먼트 인스턴스들을 논리 트윈 세그먼트라고 한다. 논리 자식 세그먼트는 2가지 다른 접근경로를 통해 접근될 수 있다. 하나는 물리 부모 세그먼트를 통해서 접근하는 방식이고, 다른 하나는 논리 부모 세그먼트를 통해서 접근하는 방식이다.
HiDB 시스템에서 Logical Relationship을 사용하는 이유는 다음과 같다.
-
Logical Relationship은 애플리케이션에게 특정 세그먼트에 접근하는 기본 접근경로 이외의 다른 접근경로를 제공해 준다. 예를 들면, 한 물리 데이터베이스의 특정 세그먼트에서 다른 물리 데이터베이스의 연관된 세그먼트로 바로 접근할 수 있는 방법을 제공한다.
-
Logical Relationship은 애플리케이션을 위한 대체 계층 데이터 구조를 제공한다. 이를 통해 애플리케이션은 자신의 목적에 적합하게 물리 데이터베이스의 데이터를 바라보는 관점을 가지고 데이터를 처리할 수 있다.
-
Logical Relationship은 HiDB가 물리적으로 분리된 2개의 데이터베이스의 연관된 세그먼트 관계를 강제적으로 유지할 수 있도록 한다. 예를 들어, 논리 자식 세그먼트가 있는 경우에는 논리 부모 세그먼트를 삭제할 수 없게 설정하거나, 논리 부모 세그먼트가 없을 때는 논리 자식 세그먼트를 삽입하지 못하게 설정할 수 있다.
하지만 Logical Relationship을 사용하면 Logical Relationship에 사용되는 포인터를 관리하는데 성능지연 사유가 발생할 수 있고, 데이터베이스를 재편성하는 경우에는 논리적으로 연결된 다른 데이터베이스도 같이 재편성되어야 한다. 따라서 Logical Relationship을 사용하기 전에 Logical Relationship에 의해 발생할 수 있는 성능 문제와 관리업무 증가 등을 충분히 고려해서 사용을 결정해야 한다.
2. Secondary Indices
HiDB 시스템은 Secondary Index 데이터베이스를 사용해서 특정 세그먼트에 접근하는 부가적인 방법을 제공한다. 각각의 Secondary Index는 루트 세그먼트 키를 이용해서 데이터베이스 레코드에 접근하는 방식 이외의 서로 다른 접근방식을 제공한다. 이렇게 접근하는 방식은 일반적으로 데이터를 보다 빨리 얻을 수 있도록 해준다.
다음 그림과 같이 PART 세그먼트와 ORDER 세그먼트는 ORDER 세그먼트에 저장되어 있는 ORDER NUMBER를 기준으로 빨리 접근할 수 있다.
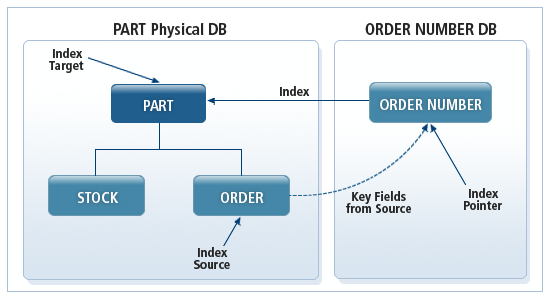
Secondary Index는 HiDB 시스템에 Secondary Index 데이터베이스를 정의함으로써 구현할 수 있다. 이 데이터베이스에는 Secondary Index 키를 주요 키로 하고 메인 데이터베이스에 있는 특정 세그먼트를 가리키는 포인터가 저장된다.
Secondary Index를 구현하는데 사용되는 세그먼트는 다음과 같다.
| 세그먼트 | 설명 |
|---|---|
Index Source |
ORDER NUMBER 등과 같은 인덱스 키가 데이터 필드로 저장되어 있는 메인 데이터베이스 세그먼트를 의미한다. |
Index Pointer |
메인 데이터베이스의 Index Target 세그먼트를 가리키는 인덱스 데이터베이스의 세그먼트를 의미한다. Index Pointer 세그먼트는 Index Source 세그먼트에서 얻은 필드 데이터를 키로 저장한다. |
Index Target |
Secondary Index 기능에 의해 처음으로 접근되는 메인 데이터베이스의 세그먼트를 의미한다. Secondary Index의 키는 한 개에서 다섯 개까지 Index Source 세그먼트의 필드로 구성된다. 이렇게 조합되는 검색 필드는 반드시 유일할 필요는 없지만 오버헤드를 줄이기 위해 유일한 값을 가지도록 만드는 것을 권장한다. |
다음은 검색 필드의 뒤에 붙여져 검색 필드가 유일한 값을 갖도록 만들어 주는 시스템 필드들이다.
| 필드 | 설명 |
|---|---|
/SX 변수 |
Index Source 세그먼트를 유일하게 정의해 주는 시스템 변수이다. |
/CX 변수 |
Index Source 세그먼트의 연쇄 키(Concatenated Key)이다. |
HiDB 시스템에서 Secondary Indices를 사용하는 이유는 다음과 같다.
-
데이터베이스가 정의될 때에 지정된 주요 키 이외의 키로 데이터베이스 레코드에 보다 빨리 접근할 수 있다.
-
Index Target 세그먼트에 접근할 때, 데이터베이스 계층을 전체적으로 따라가지 않고 바로 접근할 수 있다.
-
검색 필드 정보만 가지고 처리하는 배치 프로그램에서 인덱스 데이터베이스를 별도로 사용할 수 있는 장점이 있다.
단, Secondary Indices를 사용할 경우 메인 데이터베이스의 Index Source 세그먼트가 변경될 때마다 인덱스 데이터베이스를 같이 갱신해 주어야 하는 부담이 있다. 또한, Secondary Index 데이터베이스를 메인 데이터베이스와 같이 모니터링 및 백업하고 튜닝해야 하는 관리 업무가 증가한다.
Logical Relationship과 마찬가지로 Secondary Indices를 사용하기 위해서는 시스템의 장점과 함께 성능 문제와 관리업무 증가 등의 단점을 충분히 고려해서 사용을 결정해야 한다.
Secondary Index의 세그먼트 필드에 중복되는 키 값이 존재하는 경우는 INDEX DBD에서 오버플로우 데이터셋을 지정하여 처리하도록 한다. 중복되는 키의 저장 및 조회는 LIFO(후입선출) 순서로 처리된다.