高度な機能
ユーザー・アプリケーションの処理に最適なOpenFrame HiDBデータベースを選択したら、次にOpenFrame HiDBの高度な機能を使用するかどうかを選択する必要があります。
本章ではOpenFrame HiDBの高度な機能である論理関係(Logical Relationship)と二次索引(Secondary Indices)について説明します。
1. 論理関係(Logical Relationship)
HiDBシステムでは、論理関係を通じて物理的に異なる2つのデータベースを結合して使用できる機能を提供します。それにより、論理関係に含まれている特定のセグメントに対して、付加的なアクセス方式を提供する新しい階層構造が定義されます。
データベース管理者は、論理関係に参加する物理データベースを使用して、論理データベースと呼ばれる新しいデータベースを定義します。論理データベースは、前述のようにアプリケーションに新しい階層構造の形式を提供します。
以下は、アプリケーションでよく使われるデータ・アクセス方式に従って、データベースを設計段階からPARTデータベースとORDERデータベースの2つの物理データベースで実装した例です。
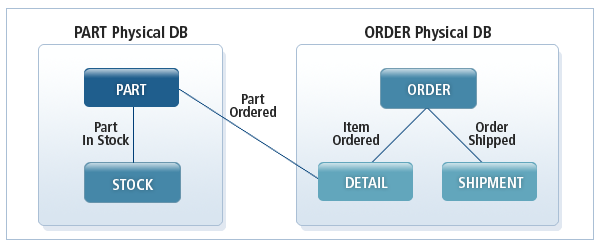
しかし、特定のアプリケーションでは、PARTデータベースのPARTセグメントとORDERデータベースのDETAILセグメント間の関係を使用する必要があるため、PARTデータベースとORDERデータベースの論理関係を定義します。
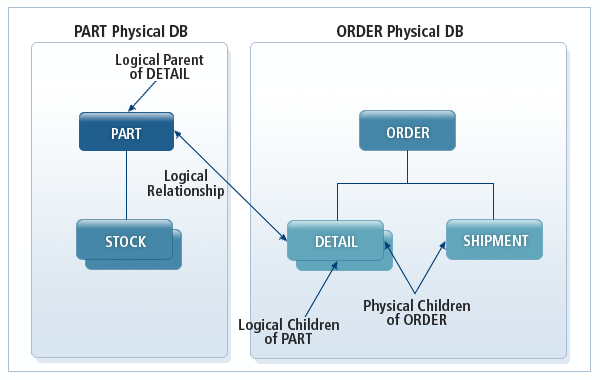
論理関係を定義する基本的な方法は、両方のデータベースと関連のある特定のセグメントを別のデータベースに存在する論理親セグメントと関連付けて、論理子セグメントとして指定する方法です。このように指定すると、論理子セグメントは物理親セグメントと論理親セグメントの2つの親セグメントを持つことになります。
以下の図に示したように、論理子セグメントであるDETAILのインスタンスが1つ追加されると、2つの階層構造に参加することになります。DETAILセグメント・インスタンスは、物理親セグメントであるORDERと論理親セグメントであるPARTを同時に持ちます。
付加的な2つの論理データベースを定義すると、以下の図のように新しい2つの論理データ構造が得られます。この新しいデータ構造は、1つのアプリケーションで同時に使用できます。
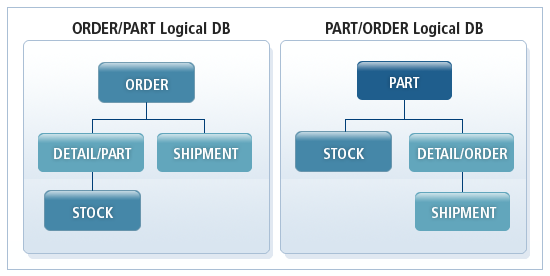
上記図のDETAIL/PARTは、論理子セグメントと論理親セグメントを連結して作成されたセグメントであり、DETAIL/ORDERは、論理子セグメントと物理親セグメントを連結して作成されたセグメントです。これらのセグメントを連結セグメント(Concatenated Segment)といいます。
同じ論理親セグメント・インスタンスを持つ論理子セグメント・インスタンスを論理ツイン・セグメントと呼びます。論理子セグメントにアクセスする方法は、物理親セグメントを通じてアクセスする方法と、論理親セグメントを通じてアクセスする方法の2つがあります。
OpenFrame HiDBシステムで論理関係を使用する理由は以下のとおりです。
-
論理関係は、特定のセグメントにアクセスする基本的なアクセス・パスとは異なるアクセス・パスをアプリケーションに提供します。たとえば、1つの物理データベースの特定のセグメントから別の物理データベースの関連セグメントに直接アクセスする方式を提供します。
-
論理関係は、代替階層データ構造をアプリケーションに提供します。これにより、アプリケーションは物理データベースのデータを目的に合わせて処理できます。
-
論理関係は、OpenFrame HiDBが物理的に分離された2つのデータベースに関連付けられているセグメントの関係を強制的に維持できるようにします。たとえば、論理子セグメントがある場合は、論理親セグメントを削除できないように設定し、論理親セグメントがない場合は、論理子セグメントを挿入できないように設定できます。
しかし、論理関係を使用すると、論理関係に使用されるポインターの管理のため性能低下が発生する可能性があります。また、データベースを再編成する場合は、論理的に連結されている他のデータベースも一緒に再編成される必要があります。したがって、論理関係の使用を決定する前に、論理関係の使用によって発生する可能性のある性能上の問題や管理業務の増加などについて十分に考慮しなければなりません。
2. 二次索引(Secondary Indices)
HiDBシステムは、二次索引データベースを使用して特定のセグメントにアクセスする付加的な方法を提供します。各二次索引は、ルート・セグメントのキーを使用した方式以外のアクセス方式を提供します。このようなアクセス方式は、既存の方法に比べてより迅速なデータの取得を実現します。
以下の図のように、PARTセグメントとORDERセグメントはORDERセグメントに格納されているORDER NUMBERを基準にして迅速なアクセスが可能です。
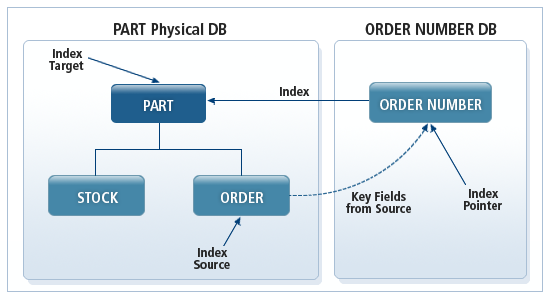
二次索引は、OpenFrame HiDBシステムに二次索引データベースを定義することによって実装されます。このデータベースは二次索引のキーを主キーとし、主データベースに存在する特定のセグメントを指すポインターを格納します。
以下は、二次索引の実装に使用されるセグメントです。
| 用語 | 説明 |
|---|---|
Index Source |
ORDER NUMBERなどの索引キーがデータ・フィールドとして格納されている主データベース・セグメントを意味します。 |
Index Pointer |
主データベースのIndex Targetセグメントを指す索引データベースのセグメントを意味します。なお、Index Sourceセグメントから取得したフィールド・データをキーとして格納します。 |
Index Target |
二次索引機能によって初めてアクセスされる主データベースのセグメントを意味します。 二次索引のキーは、1つから5つまでのIndex Sourceセグメントのフィールドで構成されます。このように組み合わせた検索フィールド値は、オーバーヘッドを減らすために、なるべく一意の値で定義することをお勧めします。 |
以下は、検索フィールドの末尾に付けられ、検索フィールドが一意の値を持つようにするシステム・フィールドです。
| フィールド | 説明 |
|---|---|
/SX変数 |
Index Sourceセグメントを一意として定義するシステム変数です。 |
/CX変数 |
Index Sourceセグメントの連結キー(Concatenated Key)です。 |
以下は、HiDBシステムで二次索引を使用する理由です。
-
データベースが定義されるとき、指定された主キー以外のキーを使用してデータベース・レコードに迅速にアクセスできます。
-
Index Targetセグメントにアクセスするとき、データベースのすべての階層を走査せず、すぐにアクセスできます。
-
検索フィールドの情報だけで処理するバッチ・プログラムで、索引データベースを別途に使用できるというメリットがあります。
ただし、二次索引を使用すると、主データベースのIndex Sourceセグメントが変更されるたびに、索引データベースも同時に更新しなければなりません。また、二次索引データベースを主データベースと一緒にモニタリング、バックアップ、チューニングする管理業務が増えます。
論理関係と同様、二次索引を使用する場合は、二次索引の特長、性能上の問題、管理業務の増加などを十分に考慮してから使用してください。
二次索引のセグメント・フィールドに重複するキー値が存在する場合は、索引DBDでオーバーフロー・データセットを指定して処理するようにします。重複するキーの保存および検索は、LIFO(後入先出法)の順で処理されます。