Advanced Features
Once you select the most suitable OpenFrame HiDB database type, you need to select advanced features of OpenFrame HiDB for your need.
This chapter describes logical relationship and secondary index, which are advanced features of OpenFrame HiDB.
1. Logical Relationship
HiDB supports logical relationship that allows you to relate and use two physically separated databases. A logical relationship defines a new hierarchical structure that provides an additional access path to segments.
A database administrator defines a new database called a logical database by using the physical database that participates in a logical relationship. Logical database provides a new hierarchy for applications to use.
The following figure illustrates two separate PART and ORDER databases that are designed with most frequently used data access paths (relationships).
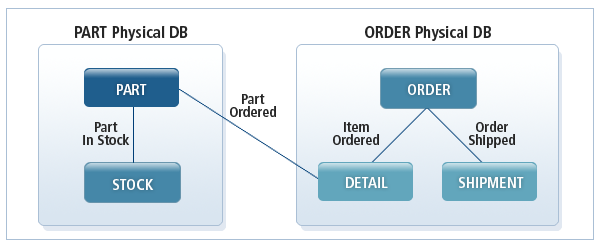
An application may need to use a relationship between the PART segment of the PART database and the DETAIL segment of the ORDER database. To achieve this, a logical relationship is created between the PART and ORDER databases.
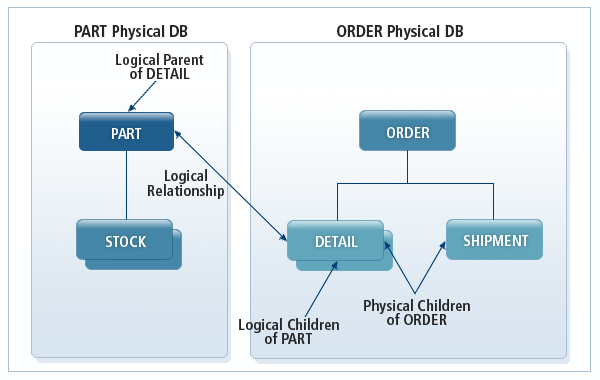
To establish a logical relationship, you first need to define the dependent segment as a logical child to the logical parent segment that exists in a different database. By doing this, the logical child segment will have a physical parent and a logical parent.
As shown in the following figure, a newly added instance of the DETAIL, a logical child segment, participates in two hierarchical structures. The DETAIL segment instance has ORDER as its physical parent segment and PART as its logical parent segment.
By defining two additional logical databases, two new logical data structures are generated as shown in the following figure. Both data structures can be used by a single application.
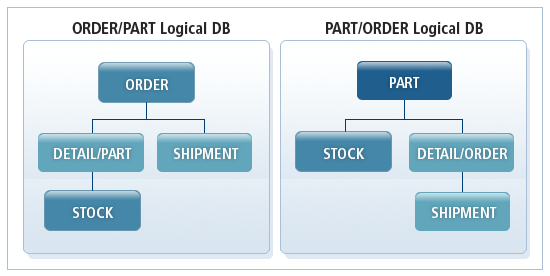
The DETAIL/PART segment shown in Two Additional Logical Databases is created by connecting a logical child segment and a logical parent segment. The DETAIL/ORDER segment is created by connecting a logical child segment to a physical parent segment. This type of segment is called a concatenated segment.
The instances with the same parent segment instances are called a logical twin segment. Logical child segments can be accessed through either a physical parent segment or a logical parent segment.
The advantages of using logical relationship are:
-
Provides applications with an alternate access path to a segment. For example, it provides a direct path from a segment in a physical database to a segment in another database.
-
Provides applications with an alternative hierarchical data structure. This allows applications to process the required data using a view of the data on the physical database.
-
Forcibly maintains the relationship between two logically related segments in HiDB. For example, a logical parent segment cannot be deleted if it has a logical child segment. Or, a logical child segment cannot be inserted if it does not have a logical parent segment.
On the other hand, logical relationship also has some disadvantages. Pointers must be managed to maintain logical relationships and this may cause performance degradation. Moreover, when a database is reorganized, other logically related databases must also be reorganized. Therefore, performance issues and administrative overheads must be taken into consideration for using logical relationship.
2. Secondary Indexes
A secondary index database provides another way to access segments in HiDB. Secondary indexes allow you to set an index based on any field, other than the key field in the root segment. Indexes provide faster access to data.
As shown in the following figure, the IMS catalog secondary index provides a fast access path to the PART and ORDER segments through the ORDER NUMBER index of the ORDER segment.
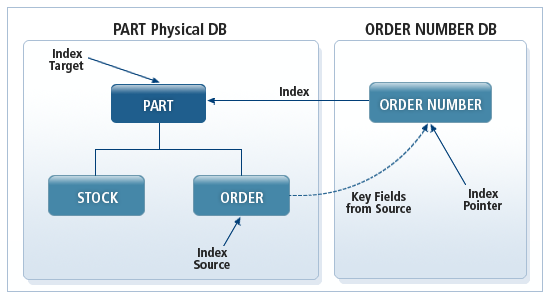
Secondary indexes can be implemented by defining a secondary index database in HiDB. The secondary index database uses secondary index key as its primary key and stores a pointer to the related segment in the main database.
Terms which are used to implement secondary index are as follows:
| Term | Description |
|---|---|
Index Source |
Main database segments where index keys, such as ORDER NUMBER, are stored as a data field. |
Index Pointer |
Stores the Index pointer segment in the secondary index database that points to the index target segment in the main database. An index pointer segment stores the field data of the index source segment as its key. |
Index Target |
The segment in the main database that is accessed by the secondary index. A secondary index key is made up of one to five fields of the index source segment. It is not necessary for the combination of these fields to be unique, but it is recommended that the search field has a unique value to reduce overhead. |
The following shows the system fields appended to the end of the search field to make it unique.
| Field | Description |
|---|---|
/SX variable |
Defines a unique value for the index source segment. |
/CX variable |
Specifies a concatenated key of the index source segment. |
The advantages of using secondary indexes are:
-
Allows applications to access records faster using a key other than the primary key defined in the database.
-
Allows applications to directly access an index target segment without having to read through the hierarchy.
-
Provides a separate index database for batch programs that process data using only the search fields.
On the other hand, secondary indexes also have some disadvantages. Secondary index databases must be updated every time an index source segment of the main database is updated. Moreover, there may be overhead in managing, backing up, and tuning the secondary index database with the main database.
Like with logical relationships, you must carefully consider whether or not the advantages of using secondary index outweigh the performance issues and administrative overheads.
If a segment field in the secondary index database contains a duplicate key value, you must specify an overflow data set for the index DBD to store the duplicate key. A duplicate key is stored and retrieved in LIFO (last-in-first-out) order.