ProSort 실행 절차
본 장에서는 ProSort의 실행 절차를 설명한다.
1. SORT, COPY 연산
ProSort에서 SORT 및 COPY 연산을 실행하는 절차는 다음과 같다.
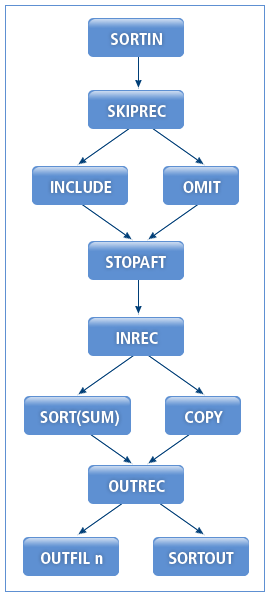
다음은 SORT 및 COPY 연산의 실행 절차에 대한 설명이다.
-
SKIPREC
SORT 연산을 수행하기 전에 스킵할 레코드의 개수를 지정하는 옵션이며, 지정한 값 이후부터 레코드를 입력받는다.
다음은 6번째 레코드부터 입력을 받아 다음 프로세스를 진행하는 예이다.
SKIPREC = 5
-
특정 조건의 레코드만 포함하거나 또는 특정 조건의 레코드를 제외한다.
옵션 설명 INCLUDE
특정 조건의 레코드만 포함하고, 나머지 레코드는 제외한다.
OMIT
특정 조건의 레코드는 제외하고, 나머지 레코드만 포함한다.
특정 조건은 관계식과 관계식을 논리 연산자로 조합하여 논리식으로 구성한다. 관계식은 비교, 문자열 비교, 비트 연산, 날짜 비교로 나뉜다.
관계식 설명 비교
필드와 필드 간의 비교 또는 필드와 상수와의 비교를 할 수 있다.
문자열 비교
문자열을 비교한다.
비트 연산
한 개 또는 두 개의 이진수를 비트 단위로 연산한다.
날짜 비교
날짜를 비교한다.
다음의 관계식은 레코드의 p1의 위치에서 m1의 길이를 갖고, f1의 포맷을 가진 필드와 p2의 위치에서 m2의 길이를 갖고 f2의 포맷을 가진 필드를 비교하는 조건을 나타낸다.
p1, m1, f1, {EQ|NE|GT|GE|LT|LE}, p2, m2, f2적용할 수 있는 연산자로는 EQ, NE, GT, GE, LT, LE가 있다.
연산자 설명 EQ
필드가 일치하는지 검사한다.
NE
필드가 일치하지 않는지 검사한다.
GT
왼쪽이 오른쪽보다 더 큰지 검사한다.
GE
왼쪽이 오른쪽보다 크거나 같은지 검사한다.
LT
왼쪽이 오른쪽보다 작은지 검사한다.
LE
왼쪽인 오른쪽보다 작거나 같은지 검사한다.
다음은 5 ~ 12byte의 부동소수점 숫자가 13 ~ 20byte의 부동소수점 숫자보다 크거나 105 ~ 108byte의 부동소수점 숫자가 상수 1000보다 작거나 같은 조건을 갖는 레코드를 포함하는 예이다.
INCLUDE COND=(5,8,GT,13,8,|,105,4,LE,1000),FORMAT=CSF
-
STOPAFT
1, 2번의 절차를 수행한 후, 레코드의 개수가 지정된 개수를 초과하지 않을 때까지 레코드의 입력을 받는다.
다음은 1000개의 레코드까지만 다음 프로세스로 전달하는 예이다.
STOPAFT = 1000
-
입력된 레코드를 주어진 포맷으로 변환한다. 입력된 레코드는 INREC에서 지정한 필드로 변환되어 새로운 레코드로 변환된다. 이때 필드는 상수(constant) 또는 (p,m)의 형태로 입력된 레코드의 일부, (p,m,f,to)로 입력된 레코드의 포맷을 변환한 필드 등으로 구성한다. INREC를 수행한 이후의 작업은 INREC에서 변환된 레코드를 기준으로 처리된다.
다음은 입력 레코드의 10 ~ 12byte, 20 ~ 27byte, 33 ~ 43byte, 5byte를 새로운 레코드로 생성하는 예이다.
INREC FIELDS=(10,3,20,8,33,11,5,1)
다음은 입력 레코드의 20 ~ 23byte, 12 ~ 14byte를 새로운 레코드로 변환하는 예이다.
INREC FIELDS=(20,4,12,3) SORT FIELDS=(1,4,D,5,3,D),FORMAT=CH
-
SORT(SUM), COPY
입력된 레코드를 주어진 키의 정보로 정렬한다. 정렬에 사용되는 키는 필드로 정의되고 각각의 필드는 p, m, f, s 형태로 정의된다.
필드의 형태 설명 p
레코드의 위치로, byte와 bit 단위로 정의한다.
-
p가 4인 경우 : 4byte부터 필드가 시작된다.
-
p가 4.2인 경우 : 4byte의 2번째 bit부터 시작된다.
m
필드의 길이로, byte와 bit 단위로 정의한다.
f
포맷(format)을 정의한다.
s
오름차순 정렬 또는 내림차순 정렬을 정의한다.
INREC로 레코드가 변환된 경우에는 변환된 레코드를 기준으로 위치가 정해진다. EQUALS 옵션을 선언하면 동일한 키의 레코드들이 원래 순서로 나타나도록 보장하는 stable sort로 동작한다.
SUM 옵션이 있을 때에는 키가 같은 레코드에 지정된 필드 값의 합을 구한다. 지정된 필드가 없는 경우에는 중복된 키를 제거하는 역할만을 수행한다. SKIPREC, STOPAFT 옵션이 있을 때에는 이전 프로세스에서 진행한다.
다음은 2 ~ 6byte의 부동소수점 숫자의 키를 오름차순으로 정렬하는 예이다.
SORT FIELDS=(2,5,FS,A)
다음은 7025 ~ 2028byte의 ZD(zoned decimal fields)를 오름차순으로, 5048 ~ 5055byte의 ZD를 오름차순으로 정렬하는 예이다.
SORT FIELDS=(7025,4,ZD,A,5048,8,ZD,A),EQUALS
다음은 정렬 없이 복사하는 예이다.
SORT FIELDS=(COPY)
다음은 정렬이 수행된 결과의 키가 동일한 레코드에 대해 21 ~ 28byte의 PD(packed decimal fields)를, 11 ~ 14byte의 FI 필드의 합을 구하는 예이다.
SUM FIELDS=(21,8,PD,11,4,FI)
-
-
OUTREC
정렬된 레코드를 주어진 포맷으로 변환한다. INREC과 동일하게 사용된다. 단, INREC로 레코드가 이미 변환된 경우에는 변환된 레코드를 기준으로 위치가 정해진다. 자세한 내용은 SORT, COPY 연산의 4번 INREC을 참고한다.
-
OUTFIL
OUTFIL은 OUTFIL 연산에서 자세히 설명한다.
2. MERGE 연산
MERGE는 정렬된 여러 입력 파일을 병합하여 새롭게 정렬된 레코드를 출력한다. MERGE는 SKIPREC, STOPAFT 옵션을 제외하고는 SORT와 동일한 절차로 연산을 수행한다.
ProSort에서 MERGE 연산을 실행하는 절차는 다음과 같다.
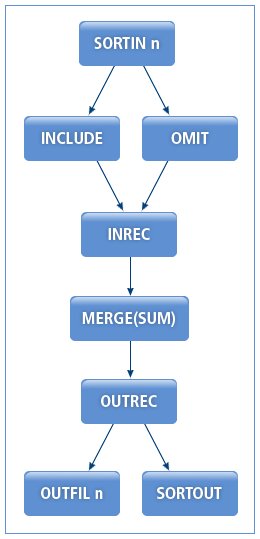
다음은 MERGE 연산의 실행 절차에 대한 설명이다.
-
INCLUDE, OMIT
SORT, COPY 연산의 2번 INCLUDE, OMIT을 참고한다.
-
INREC
SORT, COPY 연산의 4번 INREC을 참고한다.
-
MERGE(SUM)
주어진 키의 정보로 여러 입력 파일을 병합한다. 정상적인 처리 결과를 보장받기 위해서는 입력 파일의 키가 정렬되어 있어야 한다. 필드 및 옵션은 SORT와 동일하게 정의된다.
다음은 25 ~ 28byte의 ZD, 48 ~ 55byte의 ZD를 키로 정의하여 오름차순으로 입력 파일을 병합하는 예이다.
MERGE FIELDS=(25,4,A,48,8,A),FORMAT=ZD
-
OUTREC
MERGE 연산이 수행된 레코드를 주어진 포맷으로 변환한다. INREC과 동일하게 사용된다. 단, INREC로 레코드가 이미 변환된 경우에는 변환된 레코드를 기준으로 위치가 정해진다.
자세한 내용은 SORT, COPY 연산의 4번 INREC을 참고한다.
-
OUTFIL
OUTFIL은 OUTFIL 연산에서 자세히 설명한다.
3. OUTFIL 연산
OUTFIL은 SORT, MERGE, COPY 연산의 결과로 출력된 레코드를 여러 가지 조건으로 다시 출력한다.
ProSort에서 OUTFIL 연산을 실행하는 절차는 다음과 같다.
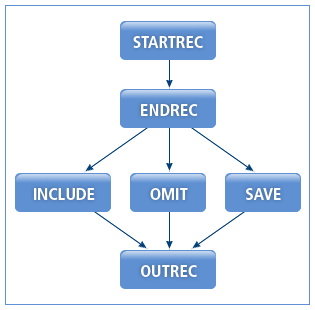
다음은 OUTFIL 연산의 실행 절차에 대한 설명이다.
-
STARTREC
출력 레코드 중 지정한 개수를 앞에서부터 제외한다.
-
ENDREC
출력 레코드 중 지정한 개수를 뒤에서부터 제외한다.
-
INCLUDE, OMIT, SAVE
특정 조건의 레코드를 제외하거나 포함한다. SAVE 옵션이 있을 때에는 자신을 제외한 모든 OUTFIL에서 제외되지 않은 조건의 레코드만 포함한다.
다음은 8 ~ 13byte의 문자열 필드가 ACCTNG인 레코드는 파일 GP1에 출력하고, 8 ~ 13byte의 문자열 필드가 DVPMNT인 레코드는 파일 GP2에 출력하는 예이다.
OUTFIL INCLUDE=(8,6,CH,EQ,C’ACCTNG’),FNAMES=GP1 OUTFIL INCLUDE=(8,6,CH,EQ,C’DVPMNT’),FNAMES=GP2 OUTFIL SAVE,FNAMES=NOT1OR2
-
OUTREC
출력 레코드를 주어진 포맷으로 변환한다.
4. User Exit Function
User Exit Function은 함수를 ProSort Script 또는 ProSort API를 이용하여 등록할 수 있다. 또한 SORT, MERGE, COPY 연산을 수행할 때 레코드를 삽입, 변환, 삭제할 수 있다.
User Exit Function은 이전 단계에서 전달된 레코드를 편집하여 다음 단계로 전달한다. 마지막 레코드 이후부터는 NULL이 함수에 전달된다.
SORT, MERGE, COPY 연산은 ProSort API를 통해 레코드를 직접 입력하는 경우에만 동작하고, 파일을 통해 레코드를 입력 받는 경우에는 동작하지 않는다.
User Exit Function의 세부 사항은 다음과 같다.
-
프로토타입
int user_exit_func (void *rec_addr, int rec_len, int input_no, void **ret_rec_addr, int *ret_rec_len); -
파라미터
파라미터 용도 설명 *rec_addr
입력
이전 단계에서 전달된 레코드 주소의 포인터이다.
rec_len
입력
이전 단계에서 전달된 레코드의 길이이다.
input_no
입력
SORTIN의 번호로, MERGE 연산의 User Exit Function E32에서만 사용할 수 있다.
**ret_rec_addr
출력
변환 또는 삽입된 레코드의 주소로, 포인터의 형태로 전달된다.
*ret_rec_len
출력
변환 또는 삽입된 레코드의 길이로, 포인터의 형태로 전달된다.
-
반환값
반환값 설명 0
No Action의 의미이며, 레코드의 변환 없이 다음 단계를 수행한다.
**ret_rec_addr 및 *ret_rec_len 파라미터에 입력받은 *rec_addr및 rec_len의 주소를 그대로 전달한다.
4
Delete Record의 의미이며, 레코드를 삭제한다. 삭제된 레코드는 다음 단계로 전달되지 않는다.
8
Do Not Return의 의미이며, 다음 레코드부터 User Exit Function을 수행하지 않는다.
12
Insert Record의 의미이며, 반환된 레코드를 삽입한다. 삽입된 레코드는 다음 단계로 바로 전달되지 않고, 다시 User Exit Function을 수행하여 변환되거나 삭제된다. 기존의 레코드는 삽입된 레코드가 다음 단계로 전달된 후, 다시 처리된다.
16
Terminate Prosort의 의미이며, ProSort를 종료한다. 수행 중인 작업을 모두 종료한다.
20
Record Altered의 의미이며, 변경된 레코드로 다음 단계를 수행한다. 입력받은 *rec_addr, rec_len, input_no의 정보를 이용하여 레코드를 변환한 후, 변환된 레코드의 주소 및 길이를 **ret_rec_addr, *ret_rec_len 파라미터에 전달한다.
|
4.1. User Exit Function을 포함하는 SORT, COPY 연산
ProSort에서 User Exit Function과 함께 SORT 및 COPY 연산을 실행하는 절차는 다음과 같다.
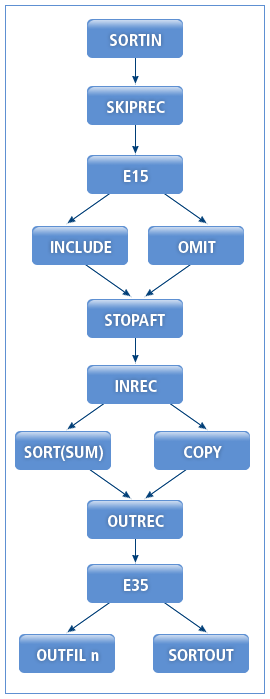
SORT 및 COPY 연산에서는 User Exit Function E15를 등록하여 입력된 레코드를 편집할 수 있다. User Exit Function E35는 OUREC를 수행한 이후의 레코드부터 편집할 수 있다.
4.2. User Exit Function을 포함하는 MERGE 연산
ProSort에서 User Exit Function과 함께 MERGE 연산을 실행하는 절차는 다음과 같다.
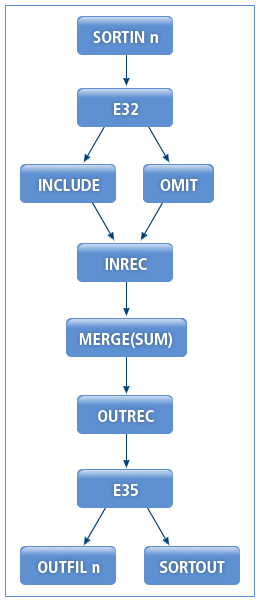
MERGE 연산에서는 User Exit Function E32를 등록하여 입력된 레코드를 편집할 수 있다. User Exit Function E35는 OUREC를 수행한 이후의 레코드부터 편집할 수 있다.
4.3. User Exit Function 예제
본 절에서는 User Exit Function을 사용하여 함수를 기능별로 수행하는 예를 기술한다.
모든 레코드의 전달
다음은 모든 레코드를 그대로 전달하는 함수의 예이다.
static int
exit_none(const void *rec_addr,
const int rec_len,
int file_no,
void **ret_rec_addr,
int *ret_rec_len)
{
if (rec_addr == NULL)
return 8; /* do not return */
*ret_rec_addr = (void *) rec_addr;
*ret_rec_len = rec_len;
return 0; /* no action */
}
모든 레코드의 삭제
다음은 모든 레코드를 삭제하는 함수의 예이다.
static int
exit_delete(const void *rec_addr,
const int rec_len,
int file_no,
void **ret_rec_addr,
int *ret_rec_len)
{
if (rec_addr == NULL)
return 8; /* do not return */
return 4;
}
모든 레코드의 삽입
다음은 모든 레코드를 복사하여 삽입하는 함수의 예이다. 레코드 a,b,c가 이전 단계에서 전달되면 a,a,b,b,c,c의 형태로 다음 단계에 전달된다.
static int
exit_insert(const void *rec_addr,
const int rec_len,
int file_no,
void **ret_rec_addr,
int *ret_rec_len)
{
static char buf[REC_LEN];
static int inserted = 0;
/* 삽입된 레코드는 편집하지 않는다. */
if (inserted) {
inserted = 0;
*ret_rec_addr = (void *) rec_addr;
*ret_rec_len = rec_len;
return 0; /* no action */
}
if (rec_addr == NULL)
return 8; /* do not return */
memcpy (buf, rec_addr, REC_LEN);
*ret_rec_addr = buf;
*ret_rec_len = rec_len;
inserted = 1;
return 12; /* insert record */
}
마지막 레코드의 삽입
다음은 마지막 레코드를 추가로 3개 삽입하는 함수의 예이다. 레코드 a,b,c가 이전 단계에서 전달되면 a,b,c,c,c,c의 형태로 다음 단계에 전달된다.
static int
exit_insert_to_end(const void *rec_addr,
const int rec_len,
int file_no,
void **ret_rec_addr,
int *ret_rec_len)
{
static char buf[256];
static int buf_rec_len;
static insert_cnt = 0;
if (rec_addr != NULL) {
memcpy(buf, rec_addr, rec_len);
buf_rec_len = rec_len;
*ret_rec_addr = buf;
*ret_rec_len = buf_rec_len;
return 0; /* do not action */
}
if (insert_cnt >= 3) /* 3개까지 레코드를 추가한다. */
return 8; /* do not return */
*ret_rec_addr = buf;
*ret_rec_len = buf_rec_len;
insert_cnt++;
return 12; /* 레코드 삽입 */
}