ProSort 문법
본 장에서는 ProSort Script에서 지원하는 문법을 설명한다.
1. 개요
ProSort의 문법은 다음의 종류로 구분된다.
-
연산의 방법
문법 설명 SORT나 COPY 연산을 할 때 키 필드를 설정한다. SORT의 순서(오름차순, 내림차순)도 설정한다.
MERGE 연산을 할 때 키 필드를 설정한다. MERGE의 순서(오름차순, 내림차순)도 설정한다.
SORT와 MERGE 연산 방법을 설정하거나, 옵션 정보(SKIPREC, STOPAFT) 등을 설정한다.
-
Record Filtering
문법 설명 연산에 포함하는 레코드의 조건을 설정한다.
연산에 포함되지 않는 레코드의 조건을 설정한다.
여러 출력에서 포함되거나 포함되지 않을 레코드의 조건을 추가적으로 설정한다.
-
Record Reformatting
문법 설명 연산을 수행하기 전에 레코드의 형식을 다시 설정한다.
연산을 수행한 후 레코드의 형식을 다시 설정한다.
여러 출력에서 레코드의 형식을 다시 설정한다.
-
추가 기능 및 옵션
문법 설명 SORT 연산, MERGE 연산, Record Filtering, Record Reformatting을 할 때 ALTSEQ 변환 테이블을 사용한다.
-
SORT, MERGE, INCLUDE, OMIT : AQ 포맷으로 ALTSEQ 변환 테이블을 사용한다.
-
INREC, OUTREC, OUTFIL OUTREC : TRAN=ALTSEQ로 ALTSEQ 변환 테이블을 사용한다.
사용자가 임의로 정렬 순서를 설정한다.
입력 데이터의 예상 크기를 설정한다.
레코드의 형태를 설정한다.
ProSort를 종료하고, END 구문 이후의 구문들은 무시한다.
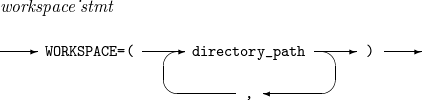
입력 레코드를 포함하고 있는 파일의 경로를 설정한다.
지정한 파일의 내용을 스크립트에 삽입한다.
연산을 수행할 때 사용할 수 있는 메모리의 크기를 설정한다.
ProSort Script를 이용하여 User Exit Function을 등록한다.
동일한 키를 갖는 레코드의 합을 설정한다.
외부 정렬에서 사용하는 임시 파일(temporary file)이 위치할 디렉터리를 설정한다.
-
2. ALTSEQ
ALTSEQ 변환 테이블을 사용하여 특정 문자의 정렬 순서의 일부분을 변경하는 문법이다. ALTSEQ 문법은 정렬 또는 병합 연산을 할 때 정렬 순서를 조정하는 목적으로만 사용되며, 실제 출력되는 문자열에는 영향을 주지 않는다.
ALTSEQ 변환 테이블은 다음과 같은 방법으로 사용할 수 있다.
-
SORT, MERGE, INCLUDE, OMIT의 경우
AQ 포맷을 사용한다. 기존의 데이터는 ALTSEQ 문법을 통해 변환되어 연산에 적용된다. 이를 이용해 키의 순서를 변경하거나 필터링의 조건을 다르게 적용할 수 있다.
-
INREC, OUTREC, OUTFIL OUTREC의 경우
TRAN=ALTSEQ를 통해 문자를 변환한다. 기존의 데이터는 ALTSEQ 문법을 통해 변환되어 다음 프로세스에 적용된다.
ALTSEQ의 세부 사항은 다음과 같다.
-
문법
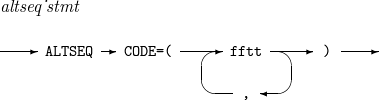 ALTSEQ
ALTSEQ -
구성요소
구성요소 설명 ff
변환할 문자를 두 자리의 16진수로 표시한 것이다.
tt
변환된 문자를 두 자리의 16진수로 표시한 것이다.
-
예제
다음은 문자 X'5B’를 X’EA’로 변경하여 SORT 연산을 수행하는 예이다.
SORT FILEDS=(1,8,AQ,A) ALTSEQ CODE=(5BEA)
다음은 문자 X'5B’를 X’EA’로 변경하여 MERGE 연산을 수행하는 예이다.
MERGE FIELDS=(1,8,AQ,A) ALTSEQ=(5BEA)
다음은 COPY 연산을 수행하고, 레코드 중 1 ~ 80byte를 잘라 출력하는 예이다. 정렬 순서에서 문자 X'00’은 X'40’으로 변환된다.
SORT FIELDS=(COPY) ALTSEQ CODE=(0040) OUTREC FIELDS=(1,80,TRAN=ALTSEQ)
3. COLSEQ
사용자가 임의로 정렬 순서를 설정하는 문법이다. SORT 또는 MERGE 연산을 하는 과정에서 정렬을 수행하기 위해 문자열 간을 비교한다.
정수 간의 크기 비교(예: 1 < 2)는 직관적인데 반해 문자열 간의 비교는 사용자가 직접적으로 파악하기가 어렵다. 문자열 간의 비교를 제대로 파악하기 위해서는 별도의 규칙이 필요하다. 이러한 규칙을 정렬 순서라고 한다.
예를 들어 9와 A를 ASCII 코드로 표현할 때에는 '9' < 'A' 이지만, EBCDIC 코드로 표현할 때에는 'A' < '9' 이다. ASCII, EBCDIC 코드 외에도 사용자가 임의로 정렬 순서를 설정할 수 있다. 이는 COLSEQ 문법을 통해 설정할 수 있다.
COLSEQ의 세부 사항은 다음과 같다.
-
문법
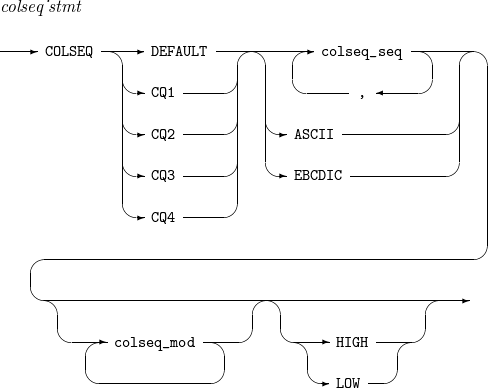
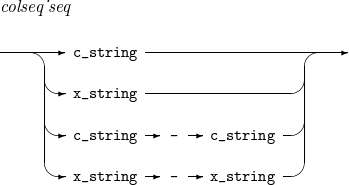
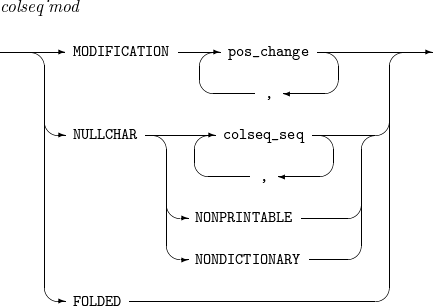
 COLSEQ
COLSEQ -
구성요소
구성요소 설명 DEFAULT
CH형 필드에 대한 디폴트 정렬 순서를 설정한다.
CQ1
CQ1형 필드에 대한 정렬 순서를 설정한다.
CQ2
CQ2형 필드에 대한 정렬 순서를 설정한다.
CQ3
CQ3형 필드에 대한 정렬 순서를 설정한다.
CQ4
CQ4형 필드에 대한 정렬 순서를 설정한다.
ASCII
ASCII 코드로 정렬 순서를 설정한다.
EBCDIC
EBCDIC 코드로 정렬 순서를 설정한다.
HIGH
정렬 순서가 지정되지 않은 문자들은 정렬 순서가 지정된 문자들보다 collation value가 크다(즉, 우선 순위가 낮다).
LOW
정렬 순서가 지정되지 않은 문자들은 정렬 순서가 지정된 문자들보다 collation value가 작다(즉, 우선 순위가 높다).
c_string
C’x1' 또는 C’x1x2'. 여기서 x1과 x2는 임의의 문자이다(단, 작은따옴표 등 몇 가지 특수문자는 제외).
x_string
X’x1x2' 또는 X’x1x2x3x4'. 여기서 x1, …, x4는 임의의 16진 문자이다.
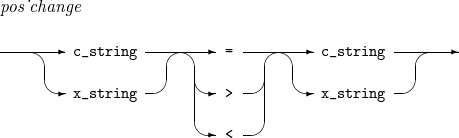
MODIFICATION
좌변 문자의 collation value를 우변 문자와 같게(=), 또는 우변의 문자보다 작게(<), 또는 우변의 문자보다 크게(>) 지정한다.
NULLCHAR
정렬 시 무시할 문자들을 지정한다. 정렬 과정에서 해당 문자들을 빼고 정렬 키를 생성한다.
NONPRINTABLE
화면에 표시되지 않는 제어 문자들을 지칭한다.
NONDICTIONARY
알파벳, 숫자, 공백, 탭을 제외한 모든 문자들을 지칭한다.
FOLDED
모든 알파벳 소문자는 자신에 상응하는 대문자와 같은 collation value를 갖는다.
-
예제
-
순서의 지정
사용자는 문자를 나열하거나 문자의 범위(Range)로 순서를 지정할 수 있다. 범위를 사용할 때에는 같은 형태와 길이로 문자를 지정해야 한다.
다음은 허용되는 예이다.
C'a'-C'z' C'AA'-C'AB' X'010f'-X'010f' X'10'-X'20'
다음은 허용되지 않는 예이다.
C'a'-X'0f' C'A'-C'각'
-
MODIFICATION
다음은 문자 a가 문자 z와 같은 collation value를 갖는 예이다.
COLSEQ CQ1 ASCII MODIFICATION C'a' = C'z'
다음은 문자 a의 collation value를 문자 d의 collation value보다 크되 문자 e의 collation value보다는 작게 지정하는 예이다.
COLSEQ CQ1 ASCII MODIFICATION C'a' > C'd'
예를 들어 오름차순 정렬이라면 a, b, c, d, e, f와 같은 레코드는 b, c, d, a, e, f 순으로 정렬된다.
다음은 위와 동일한 결과가 나타나는 예로서, 문자 a의 collation value를 문자 e의 collation value보다 작되 문자 d의 collation value보다는 크게 지정한다.
COLSEQ CQ1 ASCII MODIFICATION C'a' < C'e'
-
NULLCHAR
다음은 알파벳 소문자 a가 없는 것처럼 동작하는 예이다.
COLSEQ CQ1 ASCII NULLCHAR C'a'
예를 들어 오름차순 정렬이라면 aE, Da, aCa, aaBa, aaAaa와 같은 레코드는 aaAaa, aaBa, aCa, Da, aE 순으로 정렬된다. COLSEQ 문에 NULLCHAR, HIGH, LOW 중 어느 하나도 지정되어 있지 않을 경우 COLSEQ 문에 기술되지 않은 모든 문자가 NULLCHAR로 자동 지정된다.
-
FOLDED
다음은 a ~ z, 0 ~ 9 순으로 정렬하는 예이다. 정렬 순서가 지정된 문자(알파벳 소문자와 숫자)를 제외한 모든 문자의 collation value를 정렬 순서가 지정된 문자의 collation value보다 크게 지정한다.
SORT FILEDS=(1,8,CQ1,A) COLSEQ CQ1 C'a'-C'z', C'0'-C'9' HIGH
다음은 더블 바이트 문자(double-byte character)인 X'010F’부터 X'01FF’까지의 순서로 정렬하는 예이다. 알파벳 소문자는 없는 것처럼 동작하며, 정렬 순서가 지정된 문자(X'010F' ~ X'01FF’와 알파벳 소문자)를 제외한 모든 문자의 collation value를 정렬 순서가 지정된 문자의 collation value보다 작게 지정한다.
SORT FILEDS=(1,4,CQ2,A) COLSEQ CQ2 X'010F'-X'01FF' NULLCHAR C'a'-C'z' LOW
-
4. DATASIZE
입력 데이터의 예상 크기를 설정하는 문법이다. 단, ProSort API를 이용하여 스크립트를 호출할 때에만 설정한다.
DATASIZE의 세부 사항은 다음과 같다.
-
문법
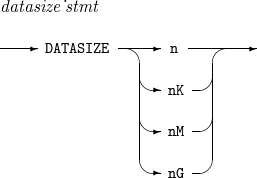 DATASIZE
DATASIZE -
구성요소
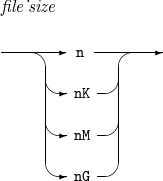
구성요소 설명 n
예상되는 입력 데이터의 크기를 n byte로 설정한다.
nK
예상되는 입력 데이터의 크기를 n KB 단위로 설정한다.
nM
예상되는 입력 데이터의 크기를 n MB 단위로 설정한다.
nG
예상되는 입력 데이터의 크기를 n GB 단위로 설정한다.
-
예제
다음은 입력 데이터의 예상 크기를 100MB로 설정하는 예이다.
DATASIZE 100M
5. DEFREC
레코드의 형태를 설정하는 문법이다.
DEFREC의 세부 사항은 다음과 같다.
-
문법
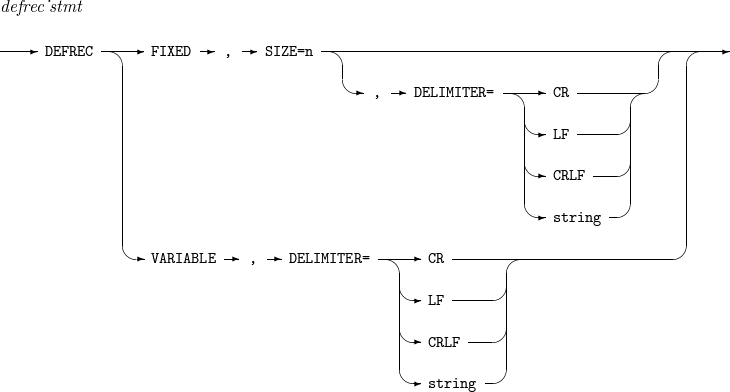 DEFREC
DEFREC -
구성요소
구성요소 설명 SIZE
입력 레코드의 길이를 지정한다.
DELIMITER
구분자를 지정한다. 현재는 개행 문자만 지원된다.
-
예제
다음은 고정 길이 레코드의 크기를 10으로 설정하는 예이다.
DEFREC FIXED, SIZE = 10
다음은 가변 길이 레코드의 구분자를 CR(carriage return)로 설정하는 예이다.
DEFREC VARIABLE, DELIMITER = CR
6. END
스크립트 실행을 종료한다.
END의 세부 사항은 다음과 같다.
-
문법
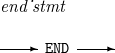 END
END -
구성요소
구성요소 설명 END
스크립트의 실행을 종료한다. 스크립트에서 END 문 이후에 등장하는 문장들은 실행되지 않는다.
7. INCLUDE, OMIT
특정 레코드를 포함하거나 제외할 때 사용하는 문법이다.
INCLUDE, OMIT의 세부 사항은 다음과 같다.
-
문법
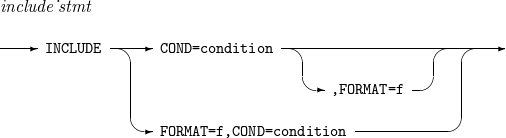 INCLUDE
INCLUDE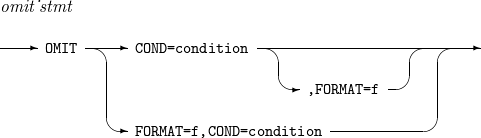 OMIT
OMIT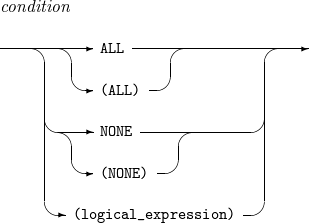

 INCLUDE, OMIT - condition
INCLUDE, OMIT - condition -
구성요소
구성요소 설명 condition
INCLUDE 문의 경우에는 레코드 포함 조건을, OMIT 문의 경우에는 레코드 배제 조건을 지정한다.
f
f1이나 f2가 생략된 경우 사용할 기본 포맷을 지정한다.
ALL
INCLUDE 문의 경우에는 모든 레코드를 포함하고, OMIT 문의 경우에는 어떤 레코드도 포함하지 않는다.
NONE
INCLUDE 문의 경우에는 어떤 레코드도 포함하지 않고, OMIT 문의 경우에는 모든 레코드를 포함한다.
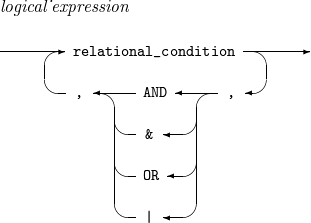
logical_expression
레코드 포함(배제) 조건을 지정하는 논리식이다.
논리식은 한 개 이상의 관계식들을 AND(또는 &), OR(또는 |), 괄호를 이용해 연결한 것이다. 연산자의 우선 순위는 괄호, AND(또는 &), OR(또는 |) 순이며, 왼쪽의 관계식부터 평가된다. AND(또는 &)로 연결된 논리식의 경우에는 이를 구성하는 관계식들이 모두 참인 경우에 논리식은 참이 된다. OR(또는 |)로 연결된 논리식의 경우에는 이를 구성하는 관계식들 중 한 개 이상이 참인 경우에 논리식은 참이 된다.
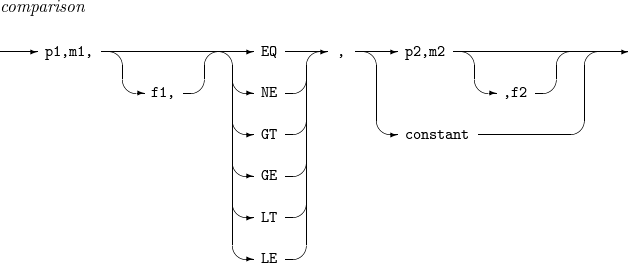
comparison
두 대상(비교 대상 1과 비교 대상 2로 설명한다)의 크기를 비교하는 관계식이다.
-
비교 대상 1은 입력 레코드의 p1 ~ (p1 + m1 - 1)번째 byte를 f1 포맷으로 해석한 값이다. f1이 생략된 경우 f 포맷으로 해석한다.
-
비교 대상 2는 입력 레코드의 p2 ~ (p2 + m2 - 1)번째 byte를 f2 포맷으로 해석한 값 또는 상수(constant)이다. f2가 생략된 경우 f 포맷으로 해석한다.
이때 사용할 수 있는 연산자는 다음과 같다.
-
EQ : 비교 대상 1과 비교 대상 2의 크기가 같으면 관계식은 참이 된다.
-
NE : 비교 대상 1과 비교 대상 2의 크기가 다르면 관계식은 참이 된다.
-
GT : 비교 대상 1이 비교 대상 2보다 크면 관계식은 참이 된다.
-
GE : 비교 대상 1이 비교 대상 2보다 크거나 같으면 관계식은 참이 된다.
-
LT : 비교 대상 1이 비교 대상 2보다 작으면 관계식은 참이 된다.
-
LE : 비교 대상 1이 비교 대상 2보다 작거나 같으면 관계식은 참이 된다.
-
constant
comparison을 구성하는 상수이다. 자세한 내용은 상수를 참고한다.
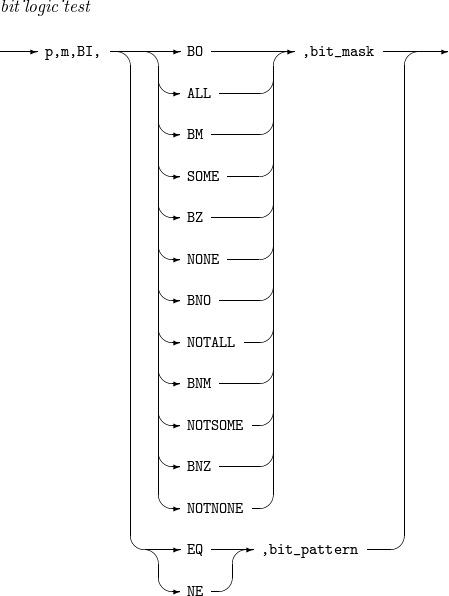
bit_logic_test
입력 레코드의 p ~ (p + m - 1)번째 byte를 BI 포맷으로 해석해서 비트 논리 검사를 수행하는 관계식이다.
-
비트 마스크(bit_mask)나 비트 패턴(bit_pattern)을 이용해 비트 논리 검사를 수행한다. 비트 마스크는 16진(X’x1…xn') 또는 이진(B’x1…xn') 형식의 문자열이다.
-
비트 마스크의 켜진(1) 비트 각각을 입력 필드의 같은 위치 상 비트와 비교한다. 이때 사용할 수 있는 연산자는 다음과 같다.
-
BO 또는 ALL : 비교에 참여한 비트가 전부 켜져 있으면 관계식은 참이 된다.
-
BM 또는 SOME : 비교에 참여한 비트 중 일부만 켜져 있으면 관계식은 참이 된다.
-
BZ 또는 NONE : 비교에 참여한 비트가 하나도 켜져 있지 않으면 관계식은 참이 된다.
-
BNO 또는 NOTALL : 비교에 참여한 비트가 전부 꺼져 있거나 일부가 켜져 있으면 관계식은 참이 된다.
-
BNM 또는 NOTSOME : 비교에 참여한 비트가 전부 켜져 있거나 전부 꺼져 있으면 관계식은 참이 된다.
-
BNZ 또는 NOTNONE : 비교에 참여한 비트 중 켜져 있는 비트가 존재하면 관계식은 참이 된다.
-
-
비트 패턴은 B’x1…xn' 형식의 문자열이다. 여기서 x1, …, xn는 1, 0 또는 마침표(.)이다. 비트 패턴의 켜진(1) 비트와 꺼진(0) 비트 각각을 입력 필드의 같은 위치 상 비트와 비교한다.
이때 사용할 수 있는 연산자는 다음과 같다.
-
EQ : 비트 패턴의 켜진 비트 각각에 상응하는 입력 필드 비트가 전부 켜져 있을 뿐만 아니라, 비트 패턴의 꺼진 비트 각각에 상응하는 입력 필드 비트가 전부 꺼져 있으면 관계식은 참이 된다.
-
NE : 관계식의 결과는 EQ 연산자를 사용한 경우와 정반대이다.
-
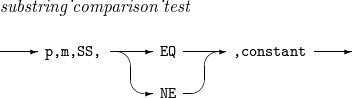
substring_comparison_test
입력 레코드의 p ~ (p + m - 1)번째 byte를 CH 포맷으로 해석해 문자열 상수(constant)와 부분 문자열 비교를 수행하는 관계식이다.
m이 문자열 상수의 길이보다 크면 입력 필드 내에서 문자열 상수를 찾고, 그렇지 않으면 문자열 상수 내에서 입력 필드 값을 찾는다.
이때 사용할 수 있는 연산자는 다음과 같다.
-
EQ : 비교 대상 간 부분 문자열 관계를 발견하면 관계식은 참이 된다.
-
NE : 관계식의 결과는 EQ 연산자를 사용한 경우와 정반대이다.
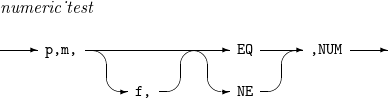
numeric_test
필드(입력 레코드의 p ~ (p + m - 1)번째 byte)가 숫자 형식인지 아닌지 판단하는 관계식이다.
x1y1...xmym
필드를 16진수로 표현한 결과가 위와 같다면, 연산자가 EQ인 경우 관계식의 결과는 다음과 같다.
-
f가 CSF(또는 FS)이거나 FORMAT=CSF(또는 FS) 기술된 경우 : x1=…=xm=3 이고 0≤y1,…,ym≤9이면 관계식은 참이 되고 그 외의 경우엔 관계식이 거짓이 된다.
-
f가 ZD이거나 FORMAT=ZD 기술된 경우 : x1=…=xm-1=3이고 xm∈{3,4,5,7} 이고 0≤y1,…,ym≤9이면 관계식은 참이 되고 그 외의 경우엔 관계식이 거짓이 된다.
-
f가 PD이거나 FORMAT=PD 기술된 경우 : 0≤x1,…,xm≤9이고 0≤y1,…,ym-1≤ 이고 ym∈{C,D,F} 이면 관계식은 참이 되고 그 외의 경우엔 관계식이 거짓이 된다.
연산자가 NE인 경우 관계식의 결과는 EQ 연산자를 사용한 경우와 정반대이다.
-
-
예제
다음은 5 ~ 12byte가 13 ~ 20 byte보다 크거나 105 ~ 108byte가 1000보다 작은 예이다.
INCLUDE COND=(5,8,GT,13,8,|,105,4,LE,1000),FORMAT=CSF
다음은 OK라는 문자열이 11 ~ 16byte 내에 있거나, 21 ~ 23 byte에 J69가 있는 예이다.
INCLUDE FORMAT=SS,COND(11,6,EQ,C'OK',OR,21,3,EQ,C'J69')
8. INFILE
입력 파일의 경로명과 예상 크기를 설정하는 문법이다.
INFILE의 세부 사항은 다음과 같다.
-
문법

 INFILE
INFILE -
구성요소
구성요소 설명 file_path
입력 파일의 경로명을 설정한다.
file_size
입력 파일의 예상 크기를 설정한다.
-
예제
다음은 입력 파일의 경로명을 IN으로, 예상 크기를 1MB로 설정하는 예이다.
INFILE=(IN,1M)
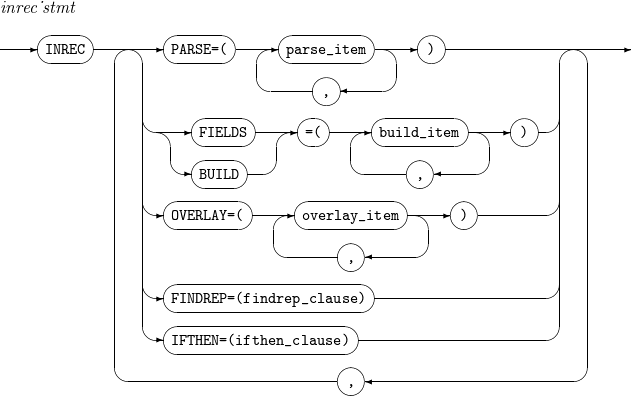
9. INREC, OUTREC
레코드의 형식을 다시 설정하는 문법이다. INREC는 SORT, MERGE, COPY 연산을 하기 전에 수행되며, OUTREC은 SORT, MERGE, COPY 연산을 한 후에 수행된다.
INREC, OUTREC의 세부 사항은 다음과 같다.
-
문법
 INREC
INREC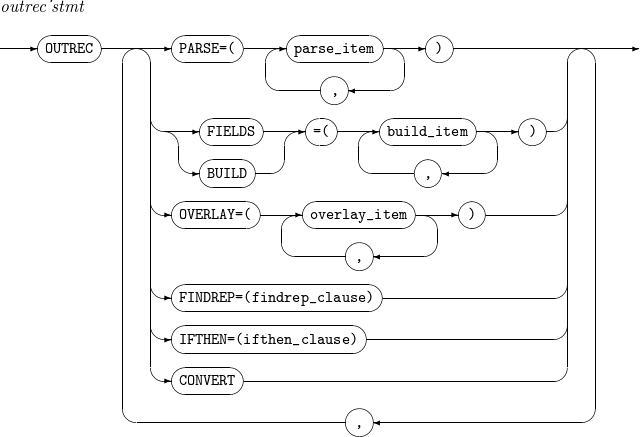 OUTREC
OUTREC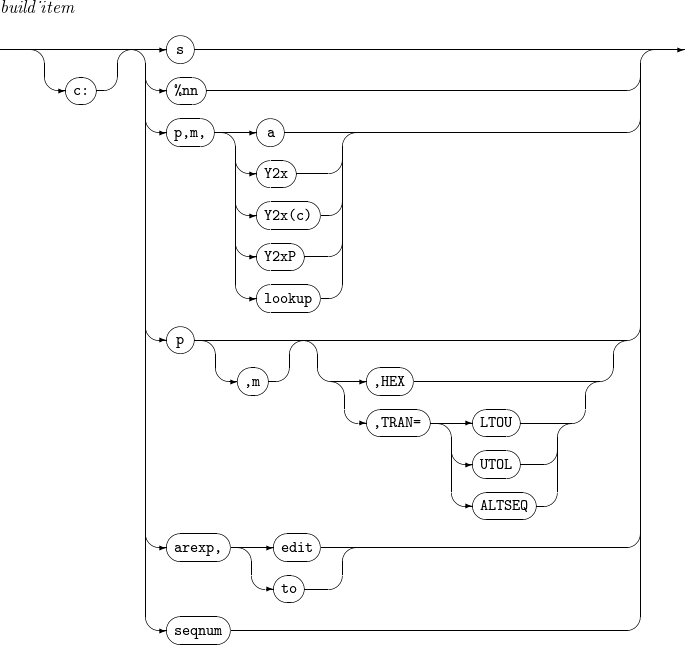
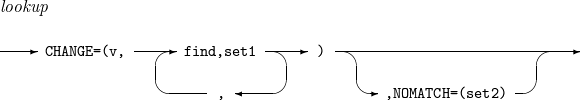

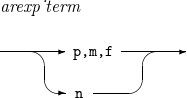
 INREC, OUTREC - build_item
INREC, OUTREC - build_item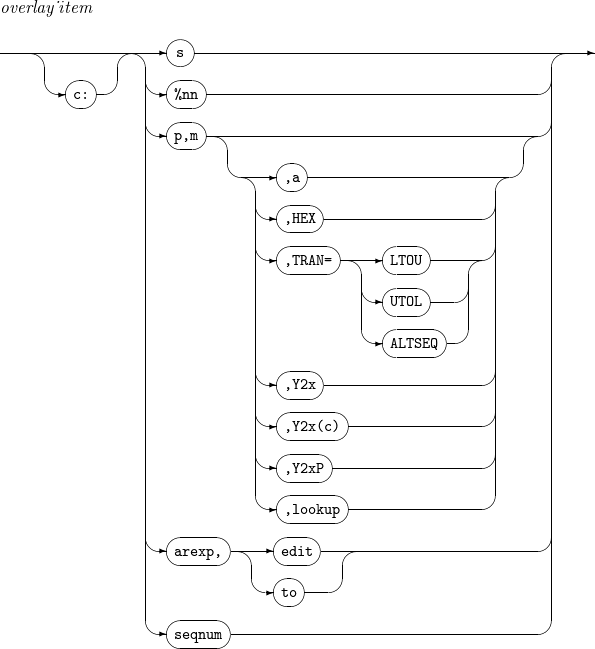 INREC, OUTREC - overlay_item
INREC, OUTREC - overlay_item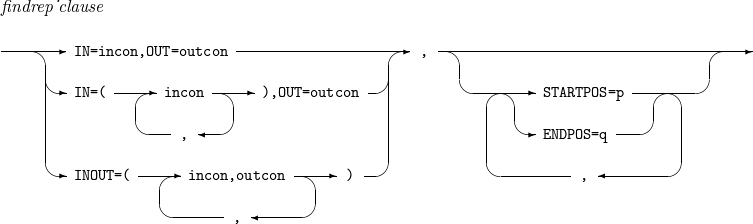 INREC, OUTREC - findrep_clause
INREC, OUTREC - findrep_clause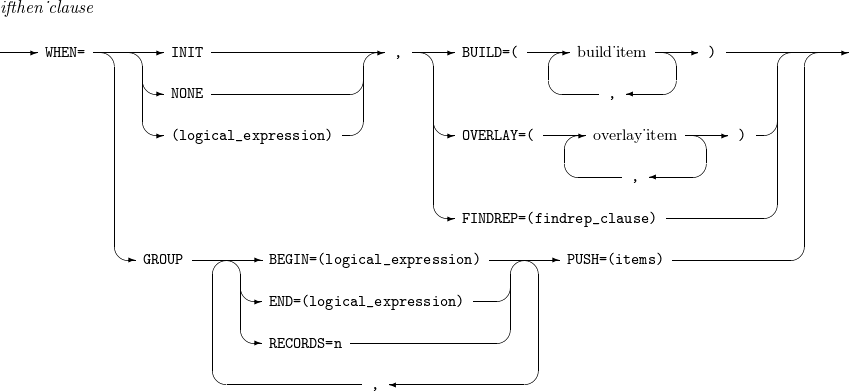 INREC, OUTREC - ifthen_clause
INREC, OUTREC - ifthen_clause -
구성요소
구성요소 설명 PARSE
parse_item의 설명을 참고한다.
CONVERT
가변 길이 입력 레코드를 고정 길이 출력 레코드로 변환한다.
c
필드의 위치를 설정한다.
필드 앞의 미사용 공간은 blank로 채워진다. 예를 들어 30:C’Tmax’와 같이 지정하면, 컬럼 29까지 blank로 채워지며 컬럼 30 ~ 33에 'Tmax’가 삽입된다. 또 다른 예로, 20:5,1과 같이 지정하면, 컬럼 19까지 blank로 채워지며 컬럼 20에 입력 필드의 5번째 byte가 삽입된다.
s
분리 필드를 출력한다. 분리 필드는 다음 중 하나이다.
-
nX : 공백(X'20') n개를 출력한다. n을 생략하는 경우 n=1로 간주한다.
-
nZ : 널(X'00') n개를 출력한다. n을 생략하는 경우 n=1로 간주한다.
-
nC'…' : 작은 따옴표 안의 문자열을 n번 출력한다. n을 생략하는 경우 n=1로 간주한다.
-
nX'…' : 작은 따옴표 안에 16진수로 표현된 문자열을 n번 출력한다. n을 생략하는 경우 n=1로 간주한다.
-
DATE=(abcd) : 현재 날짜를 C’adbdc' 형식으로 출력한다. d는 구분자이다. a,b,c∈{M,D,Y,4} 이며, 각각의 의미는 다음과 같다.
-
M : 월(01~12)을 두 글자로 출력한다.
-
D : 일(01~31)을 두 글자로 출력한다.
-
Y : 년도의 마지막 두 자리를 출력한다.
-
4 : 년도를 네 글자로 출력한다.
-
-
&DATE=(abcd) : DATE=(abcd)와 동일하다.
-
DATE 또는 &DATE : DATE=(MDY/)와 동일하다.
-
DATENS=(abc) : 현재 날짜를 C’abc' 형식으로 출력한다. a,b,c∈{M,D,Y,4} 이며, 각각의 의미는 다음과 같다.
-
M : 월(01~12)을 두 글자로 출력한다.
-
D : 일(01~31)을 두 글자로 출력한다.
-
Y : 년도의 마지막 두 자리를 출력한다.
-
4 : 년도를 네 글자로 출력한다.
-
-
&DATENS=(abc) : DATENS=(abc)와 동일하다.
-
n/ : 레코드 구분자 n개를 출력한다. n을 생략하는 경우 n=1로 간주한다.
%nn
parse된 %nn label의 필드를 입력한다.
p,m
기존 필드의 위치 및 길이를 설정한다. 마지막 필드에 한해 m이 생략될 수 있다. m이 생략되면 기존 필드의 p번째 byte부터 레코드의 끝까지를 의미한다.
a
필드의 align 포맷을 의미한다.
align 포맷의 종류는 다음과 같다.
-
H : Half word aligned
-
F : Full word aligned
-
D : Double word aligned
HEX
16진수 형태의 값으로 변경된 결과를 출력한다.
예를 들어 문자열 AB의 경우 C1C2로 변경되어 출력된다.
TRAN= [LTOU | UTOL | ALTSEQ]
-
TRAN=LTOU일 경우에는 소문자를 대문자로 변환하고, TRAN=UTOL일 경우에는 대문자를 소문자로 변환한다.
-
TRAN=ALTSEQ일 경우에는 정의된 ALTSEQ 테이블을 변환한다.
lookup
필드에서 특정 문자열을 찾고, 그 결과에 따라 필드의 값을 변경한다.
-
v : 필드의 값을 변경한 후의 길이를 지정한다.
-
find : 필드에서 찾을 문자열을 지정한다. C’x1…xn', X’x1…xn' 또는 B’x1…xn' 형식이다.
-
set1 : 필드에서 find를 찾은 경우 필드의 값을 여기 지정된 값으로 변경한다. C’x1…xn' 또는 X’x1…xn' 형식의 상수이거나 p,m 형식의 필드이다.
-
set2 : 필드에서 find를 찾지 못한 경우 필드의 값을 여기 지정된 값으로 변경한다. C’x1…xn' 또는 X’x1…xn' 형식의 상수이거나 p,m 형식의 필드이다.
arexp
수식 연산 결과를 출력한다.
arexp_term
피연산자를 지정한다.
-
p,m,f : 필드의 위치, 길이와 포맷을 지정한다.
-
n : 정수 값을 지정한다.
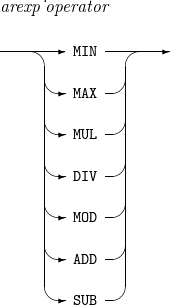
arexp_operator
연산자를 지정한다.
-
MIN : 피연산자들 중 작은 값이 연산 결과가 된다.
-
MAX : 피연산자들 중 큰 값이 연산 결과가 된다.
-
MUL : 피연산자들을 곱한 값이 연산 결과가 된다.
-
DIV : 좌측 피연산자를 우측 피연산자로 나눈 몫이 연산 결과가 된다.
-
MOD : 좌측 피연산자를 우측 피연산자로 나눈 나머지가 연산 결과가 된다.
-
ADD : 피연산자들을 더한 값이 연산 결과가 된다.
-
SUB : 좌측 피연산자에서 우측 피연산자를 뺀 값이 연산 결과가 된다.
연산자 우선순위는 다음과 같다.
-
MIN, MAX
-
MUL, DIV, MOD
-
ADD, SUB
edit
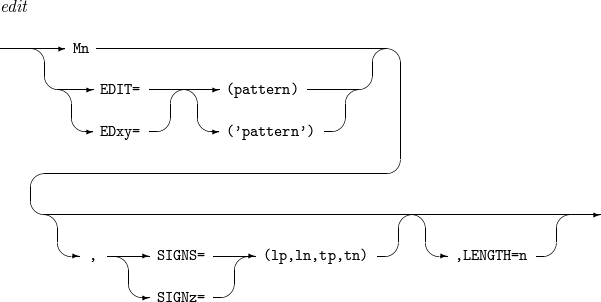
필드를 원하는 형식과 길이로 수정한다. 자세한 내용은 Edit Mask Patterns를 참고한다.
to
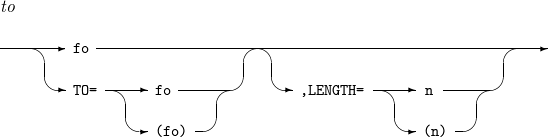
필드를 원하는 포맷(fo)과 길이(n)로 변경한다.
seqnum
정해진 규칙에 따라 순번을 출력한다.
-
n : sequence number를 몇 자리로 나타낼 것인지 지정한다.
-
fs : sequence number를 나타낼 문자열 형식을 지정한다.
-
START=j : sequence number 시작값을 j로 지정한다. 생략 시 START=1로 간주된다.
-
INCR=i : sequence number 증가값을 i로 지정한다. 생략 시 INCR=1로 간주된다.
-
RESTART=(p,m) : 명시한 필드가 이전 레코드의 필드와 일치하지 않을 경우 SEQNUM을 1으로 초기화한다.
findrep_clause
레코드에서 incon에 지정된 문자열을 찾아 outcon에 지정된 값으로 변경한다.
-
incon : 레코드에서 찾을 문자열을 지정한다. C’x1…xn', nC’x1…xn', X’x1…xn' 또는 nX’x1…xn' 형식이다.
-
outcon : 출력할 문자열을 지정한다. C'', C’x1…xn', nC’x1…xn', X’x1…xn' 또는 nX’x1…xn' 형식이다.
-
p : 검색 시작 위치를 지정한다.
-
q : 검색 종료 위치를 지정한다.
WHEN=INIT, [BUILD | OVERLAY | FINDREP]
모든 입력 레코드에 대해 BUILD, OVERLAY 또는 FINDREP 연산을 수행한다. WHEN이 INIT으로 설정된 IFTHEN 문이 수행된 후 다른 IFTHEN 문들이 수행된다.
WHEN=(logical_expression), [BUILD | OVERLAY | FINDREP]
입력 레코드가 특정 조건(logical_expression)에 맞는 경우 BUILD, OVERLAY 또는 FINDREP 연산 을 수행한다.
WHEN=GROUP
[,BEGIN=(logical_expression) |
,END=(logical_expression) |
,RECORDS=n]
,PUSH=(items)
모든 입력 레코드에 대해 BEGIN, END, RECORDS의 연산을 수행한다. 조건에 만족할 경우 레코드들은 GROUP에 할당/해제된다.
-
BEGIN=(logical_expression) : 레코드가 logical_expression을 만족하면 해당 레코드부터 GROUP이 할당된다.
-
END=(logical_expression) : 레코드가 logical_expression을 만족하면 해당 레코드 이후 GROUP이 해제된다.
-
RECORDS=n : 1개의 GROUP에 속하는 레코드의 갯수가 n개가 되면 GROUP이 끝난다.
-
PUSH=(items) : GROUP에 속할 경우 items에 명시된 내용을 OVERLAY한다. 아래는 items의 종류이다.
-
c:p,m : GROUP의 선두 레코드에서 p,m에 해당하는 값을 c position에 OVERLAY한다.
-
c:ID=n : 길이가 n인 GROUP ID를 나타낸다. 현재 GROUP의 ID를 c position에 OVERLAY한다.
-
c:SEQ=n : 길이가 n인 GROUP 내 레코드 sequence를 나타낸다. 현재 GROUP 내의 레코드 sequence를 c position에 OVERLAY한다.
-
-
-
예제
다음은 동일한 결과가 나타나는 예이다.
INREC FIELDS=(10,3,20,8) SORT FIELDS=(5,6,CH,A)
OUTREC FIELDS=(10,3,20,8) SORT FIELDS=(21,6,CH,A)
첫 번째 예의 결과는 입력 레코드의 10 ~ 12byte, 20 ~ 27byte를 새로운 레코드(11bytes)로 재구성하고, 재구성된 레코드의 5 ~ 10byte를 기준으로 오름차순 정렬을 한다. 두 번째 예의 결과는 입력 레코드의 21 ~ 26byte를 기준으로 오름차순 정렬을 한다.
다음은 INREC, OUTREC을 수행한 예이다.
INREC FIELDS=(14,4, 6,3) SORT FIELDS=(1,4,A, 5,3,A), FORMAT=AC OUTREC FIELDS=(3X, 1,4,H, 13:1,3, 5,2, 4X'61', X'0A')
입력 레코드: ABCDE567LMNOP1234
위의 예를 수행하면 다음과 같은 결과가 나타난다.
-
INREC을 수행한 후의 결과
구분 설명 1 ~ 4byte
입력 레코드의 14 ~ 17byte ('1234')
5 ~ 7byte
입력 레코드의 6 ~ 8byte ('567')
-
OUTREC을 수행한 후의 결과
구분 설명 1 ~ 3byte
Space characters (20 20 20 in HEX)
4byte
Half word alignment를 맞추기 위해 null character padding (00 in HEX)
5 ~ 8byte
INREC을 수행한 결과의 1 ~ 4byte ('1234')
9 ~ 12byte
Space characters (20 20 20 20 in HEX)
13 ~ 15byte
INREC을 수행한 결과의 1 ~ 3byte ('123')
16 ~ 17byte
INREC을 수행한 결과의 5 ~ 6byte ('56')
18 ~ 21byte
0x61 ('aaaa')
22byte
줄바꿈 문자 (0A in HEX)
-
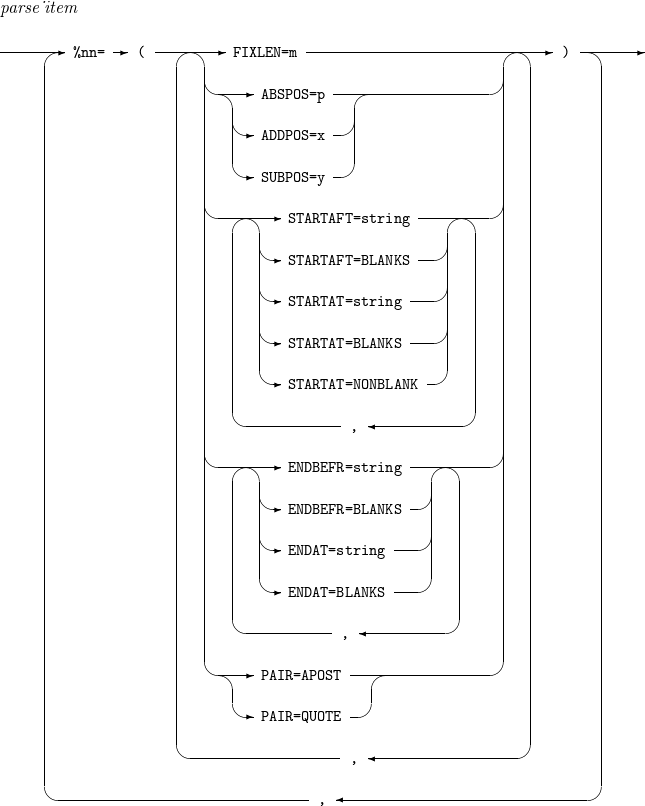
9.1. parse_item
parse_item의 세부 사항은 다음과 같다.
-
문법
 INREC, OUTREC - parse_item
INREC, OUTREC - parse_item -
구성요소
구성요소 설명 %nn
가변 길이 입력 레코드를 고정 길이 출력 레코드로 변환한다.
parse된 필드는 BUILD 또는 OVERLAY에서 (p,m)이 사용되는 곳에서 사용할 수 있다.
FIXLEN=m
parse된 필드의 길이를 지정한다. 이 속성은 모든 parse 필드에 존재해야한다.
ABSPOS=p
입력 레코드에서 parse 시작 포지션 p를 지정한다.
ADDPOS=x
입력 레코드에서 parse 시작 포지션이 x만큼 증가한다.
SUBPOS=y
입력 레코드에서 parse 시작 포지션이 y만큼 감소한다.
STARTAFT
-
STARTAFT=string : 입력 레코드의 첫 번째 string 이후부터 parse된 필드의 레코드가 시작한다.
-
STARTAFT=BLANKS : 입력 레코드의 선두부터 첫 번째 space들 이후부터 parse된 필드의 레코드가 시작한다.
STARTAT
-
STARTAT=string : 입력 레코드의 첫 번째 string을 포함하여 parse된 필드의 레코드가 시작한다.
-
STARTAT=BLANKS : 입력 레코드의 선두부터 첫 번째 space부터 parse된 필드의 레코드가 시작한다.
-
STARTAT=NONBLANK : 입력 레코드의 선두부터 space가 아닌 부분부터 parse된 필드의 레코드가 시작한다.
ENDBEFR
-
ENDBEFR=string : 입력 레코드의 첫 번째 string 전에 parse된 필드의 레코드가 끝난다.
-
ENDBEFR=BLANKS : 입력 레코드의 선두부터 첫 번째 space 전에 parse된 필드의 레코드가 끝난다.
ENDAT
-
ENDAT=string : 입력 레코드의 첫 번째 string을 포함하여 parse된 필드의 레코드가 끝난다.
-
ENDAT=BLANKS : 입력 레코드의 선두부터 첫 번째 space들을 포함하여 parse된 필드의 레코드가 끝난다.
PAIR
-
PAIR=APOST : apostrophe(')로 묶인 영역은 BLANK나 string으로 취급하지 않는다.
-
PAIR=QUOTE : quote(")로 묶인 영역은 BLANK나 string으로 취급하지 않는다.
-
10. INSERT
지정한 파일의 내용을 스크립트에 삽입하는 문법이다.
INSERT의 세부 사항은 다음과 같다.
-
문법
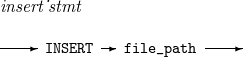 INSERT
INSERT -
구성요소
구성요소 설명 file_path
스크립트에 삽입할 파일의 경로명이다.
-
예제
다음은 ins.scr 파일의 내용을 스크립트에 삽입하는 예이다.
INSERT ins.scr
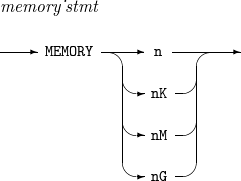
11. MEMORY
연산을 수행할 때 사용할 수 있는 메모리의 크기를 설정하는 문법이다.
MEMORY의 세부 사항은 다음과 같다.
-
문법
 MEMORY
MEMORY -
구성요소
구성요소 설명 n
연산을 수행할 때 메모리를 최대 n byte 사용하도록 설정한다.
nK
연산을 수행할 때 사용할 수 있는 메모리의 크기를 n KB 단위로 설정한다.
nM
연산을 수행할 때 사용할 수 있는 메모리의 크기를 n MB 단위로 설정한다.
nG
연산을 수행할 때 사용할 수 있는 메모리의 크기를 n GB 단위로 설정한다.
-
예제
다음은 64MB의 메모리를 설정하는 예이다.
MEMORY 64M
다음은 1GB의 메모리를 설정하는 예이다.
MEMORY 1G
12. MODS
ProSort Script를 이용하여 User Exit Function을 등록하는 문법이다.
|
User Exit Function에 대한 자세한 내용은 User Exit Function을 참고한다. |
MODS의 세부 사항은 다음과 같다.
-
문법
 MODS
MODS -
구성요소
구성요소 설명 func_name
등록할 함수명이다.
lib_path
동적으로 참조될 라이브러리 파일의 경로명이다.
lib_type
등록할 함수가 코볼 언어로 작성된 경우엔 C이고, 그 밖의 경우엔 N이다.
-
예제
다음은 User Exit Function E15에 exit_none 함수를 등록하고, User Exit Function E32에 exit_insert 함수를 등록하는 예이다. 동적으로 참조될 라이브러리 파일은 lib_exit.so로 설정한다.
MODS E15 = (exit_none, /path/lib_exit.so, N), E32 = (exit_insert, /path/lib_exit.so, N)
13. OPTION
USE_ALTERNATIVE_TP_TYPE 등의 옵션을 설정하는 문법이다.
OPTION의 세부 사항은 다음과 같다.
-
문법
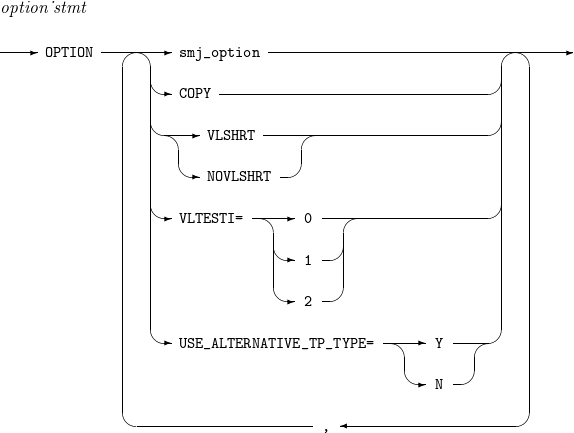 OPTION
OPTION -
구성요소
구성요소 설명 EQUALS
정렬 기준 필드의 값이 동일한 레코드가 다수 존재할 경우 이들을 동률(tie)이라고 한다. EQUALS 옵션을 지정하면 입력 레코드들을 정렬하는 과정에서 동률인 레코드들 간의 상대적 순서가 변경되지 않는다.
NOEQUALS
NOEQUALS 옵션을 지정하면 입력 레코드들을 정렬하는 과정에서 동률인 레코드들 간의 상대적 순서가 보존되지 않는다.
SKIPREC=n
입력 레코드들 중 첫 n개를 제외하고 나머지 레코드들을 E15 user exit나 INCLUDE / OMIT 문 처리 루틴에게 넘겨준다. (2.4.1절의 그림 참고)
STOPAFT=n
INREC 문 처리 루틴(INREC 문이 존재하는 경우)이나 SORT / COPY 문 처리 루틴(INREC 문이 존재하지 않는 경우)에게 n개의 레코드들을 넘겨주고 나면 더 이상의 레코드는 넘겨주지 않는다. (2.4.1절의 그림 참고)
[CENTURY | CENTWIN | Y2PAST] = [s | f]
Y2x 포맷 필드에는 네 자리 연도의 끝 두 자리만 저장되고, Y2PAST 옵션 값(century window)이 부족한 정보를 보완해 준다. CENTURY과 CENTWIN은 Y2PAST의 동의어이다.
Y2PAST 옵션의 값은 다음 두 형식 중 하나로 기술된다.
-
s : sliding century window로서, 0과 100 사이의 정수이다. Y2x 포맷 필드에 저장된 연도를 (현재 연도 - s) ~ (현재 연도 - s + 99) 사이의 값으로 해석한다.
-
f : fixed century window로서, 1000과 3000 사이의 정수이다. Y2x 포맷 필드에 저장된 연도를 f ~ (f + 99) 사이의 값으로 해석한다.
COPY
COPY 연산을 수행한다.
MSGPRT
메시지 출력 대상을 지정한다(별칭: PRINT). ProSort에서는 문법 오류만 검사한다.
VLSHRT
SORT, MERGE, FILTER (INCLUDE, OMIT), SUM 연산에서 지정된 필드가 입력 레코드에 없거나 일부만 존재하는 경우의 동작을 정의한다. 자세한 내용은 예제를 참고한다.
NOVLSHRT
SORT, MERGE, FILTER (INCLUDE, OMIT), SUM 연산에서 지정된 필드가 입력 레코드에 없거나 일부만 존재하는 경우의 동작을 정의한다. 옵션을 설정하지 않으면 디폴트는 NOVLSHRT가 된다. 자세한 내용은 예제를 참고한다.
VLTESTI=(0 | 1 | 2)
INCLUDE나 OMIT 연산에서, 지정된 필드가 입력 레코드에 없거나 일부만 존재하는 경우의 동작을 정의한다.
다음은 설정 항목에 대한 설명이다.
-
0 : INCLUDE나 OMIT 연산에서 지정된 모든 필드들의 전체 범위가 입력 레코드에 존재해야 한다. 그렇지 않으면 에러를 발생시킨다. VLTESTI 옵션이 지정되지 않은 경우엔 마치 VLTESTI=0으로 지정된 것처럼 동작한다.
-
1 : INCLUDE 연산의 경우 지정된 필드가 입력 레코드에 없거나 일부만 존재하면 해당 레코드를 출력하지 않는다. OMIT 연산의 경우 지정된 필드가 입력 레코드에 없거나 일부만 존재하면 해당 레코드를 출력한다.
-
2 : INCLUDE나 OMIT 연산에서 지정된 필드가 입력 레코드에 없거나 일부만 존재하면 관계식을 '거짓’으로 판단한다.
USE_ALTERNATIVE_TP_TYPE
TP 데이터 타입의 경우 양수를 표현하는 2가지 방식이 있다. 자세한 내용은 Miscellaneous를 참고한다.
-
-
예제
VLSHRT를 설정한 경우 각 연산은 다음과 같이 동작한다.
-
SORT, MERGE
지정된 필드가 입력 레코드에 없거나 일부만 존재하는 경우 binary zero로 채워 연산한다.
SORT FIELDS=(1,2,CH,A) 입력: A B AA BB 출력: A AA B BB
-
INCLUDE, OMIT
지정된 필드가 입력 레코드에 없거나 일부만 존재하는 경우 해당 관계식을 false로 연산한다.
INCLUDE COND=(1,2,CH,EQ,C'AA') 입력: A AA B BB 출력: AA
-
SUM
지정된 필드가 입력 레코드에 없거나 일부만 존재하는 경우 해당 레코드를 SUM 연산에서 제외한다.
SORT FIELDS=(1,1,CH,A) SUM FIELDS=(2,2,ZD) 입력: A03 A04 B B05 C 출력: A07 B05
-
14. OUTFIL
SORT, MERGE, COPY 연산의 결과를 다양하게 출력하는 문법이다. (별칭: OUTFILE)
OUTFIL의 세부 사항은 다음과 같다.
-
문법
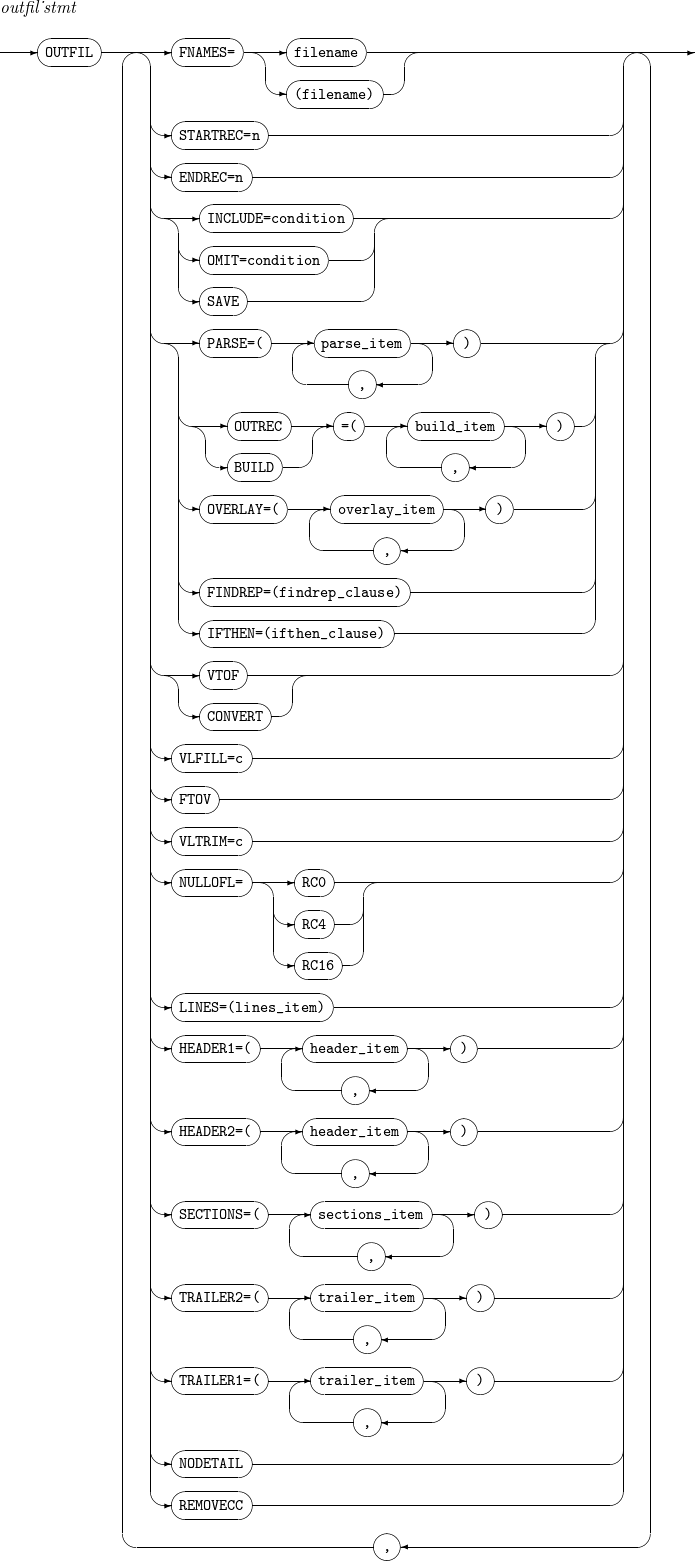 OUTFIL
OUTFIL -
구성요소
outfil_element의 리스트로 다양한 출력 방법을 정의한다.
구성요소 설명 filename
출력할 파일의 이름을 정의한다.
STARTREC=n
연산 결과의 레코드 중 n번째 레코드부터 출력한다.
ENDREC=n
연산 결과의 레코드 중 n번째 레코드까지 출력한다. STARTREC 옵션이 선언된 경우 STARTREC 옵션 이후부터 n번째 레코드까지 출력한다.
INCLUDE=condition
연산 결과의 레코드 중 조건에 맞는 레코드만 출력한다. 자세한 내용은 INCLUDE, OMIT를 참고한다.
OMIT=condition
연산 결과의 레코드 중 조건에 맞는 레코드를 제외한다. 자세한 내용은 INCLUDE, OMIT를 참고한다.
SAVE
다른 OUTFIL에서 INCLUDE 또는 OMIT의 조건으로 출력된 레코드를 제외하고 남은 레코드를 출력한다.
OUTREC 또는 BUILD
INREC, OUTREC을 참고한다.
OVERLAY
INREC, OUTREC을 참고한다.
FINDREP
INREC, OUTREC을 참고한다.
IFTHEN
INREC, OUTREC을 참고한다.
VTOF 또는 CONVERT
가변 길이 입력 레코드를 고정 길이 출력 레코드로 변환한다.
VLFILL=c
필드가 입력 레코드에 없거나 일부만 존재하는 경우, 우측을 문자 c로 채운다.
FTOV
고정 길이 입력 레코드를 가변 길이 출력 레코드로 변환한다.
VLTRIM=c
결과 레코드의 맨 우측에 한 개 혹은 그 이상의 문자 c가 존재하면 이를 제거한다.
NULLOFL= [RC0 | RC4 | RC16]
연산 결과의 레코드 건수가 0건인 경우의 동작을 지정한다.
-
RC0 : 반환값을 0으로 설정하고 이후의 연산을 계속한다.
-
RC4 : 반환값을 4로 설정하고 이후의 연산을 계속한다.
-
RC16 : 연산을 중단하고 16을 반환한다.
LINES=n
보고서 출력 시 한 페이지에 출력되는 줄 수를 n으로 지정한다.
HEADER1
문서 머리말을 정의한다. 자세한 내용은 header_item을 참고한다.
HEADER2
페이지 머리말을 정의한다. 자세한 내용은 header_item을 참고한다.
SECTIONS
section에 정의된 데이터가 변경될 때마다 header 또는 trailer를 삽입한다. SECTION은 sections_item을 통해 여러 개로 정의될 수 있다. 자세한 내용은 sections_item을 참고한다.
TRAILER2
페이지 꼬리말을 정의한다. 자세한 내용은 trailer_item을 참고한다.
TRAILER1
문서 꼬리말을 정의한다. 자세한 내용은 trailer_item을 참고한다.
NODETAIL
결과 레코드들 중 데이터 레코드는 제외하고 보고서만 출력한다.
REMOVECC
결과 레코드에서 ANSI 제어 문자는 제외하고 출력한다.
-
-
예제
다음은 연산 결과 중 15 ~ 20byte가 AAA인 레코드는 파일 AAA에, 15 ~ 20byte가 BBB인 레코드는 파일 BBB에, 나머지 레코드는 UNKNOWN에 출력하는 예이다.
OUTFIL INCLUDE=(15,6,AC,EQ,C'AAA'), FNAMES=AAA OUTFIL INCLUDE=(15,6,AC,EQ,C'BBB'), FNAMES=BBB OUTFIL SAVE, FNAME=UNKNOWN
14.1. header_item
header_item의 세부 사항은 다음과 같다.
-
문법
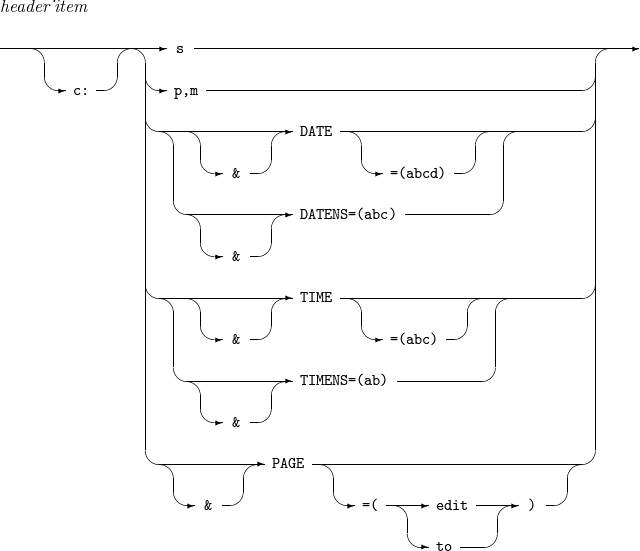 OUTFIL - header_item
OUTFIL - header_item -
구성요소
구성요소 설명 s
n’xx…x' 형태로 문자열이 몇 번 반복되는지를 설정한다.
p,m
시작 위치 및 길이를 의미하며, 필드를 표시한다.
DATENS=(abc)
날짜의 표현 형식을 정의한다. 세 글자로 구성되며, 각 글자는 M, D, Y, 4 중 하나의 값을 갖는다. 단, 각 글자는 두 번 이상 정의할 수 없다.
-
M : 월(01~12)
-
D : 일(01~31)
-
Y : 연도의 마지막 두 자리
-
4 : 4자리 연도(0001~9999)
abc에 표현된 글자 순으로 토큰(년, 월, 일)을 표시한다. 예를 들어 DATENS=(DMY)로 설정한 경우 2009년 6월 3일은 030609와 같이 표현된다.
DATE=(abcd)
날짜의 표현 형식을 정의한다. 네 글자로 구성된다.
-
첫 세 글자 : DATENS의 abc와 동일하다.
-
마지막 글자 : 각 토큰(년, 월, 일) 사이에 삽입되는 구분자(delimitor)이다.
예를 들어 DATE=(4MD-)로 설정한 경우 2009년 6월 3일은 2009-06-03과 같이 표현된다.
TIMENS=(ab)
시간의 표현 형식을 정의한다. 12, 24 중 하나의 값을 갖는다.
-
ab가 24이면, 시간은 hhmmss(24-hour clock)로 표현된다.
-
hh : 시(00~23)
-
mm : 분(00~59)
-
ss : 초(00~59)
예를 들어 오후 4시 15분 37초는 161537과 같이 표현된다.
-
-
ab가 12이면, 시간은 hhmmss xx(12-hour clock)로 표현된다.
-
hh : 시(01~12)
-
mm : 분(00~59)
-
ss : 초(00~59)
-
xx : 오전이면 am, 오후이면 pm으로 표현된다.
예를 들어 오후 4시 15분 37초는 041537 pm으로 표현된다.
-
TIME=(abc)
시간의 표현 형식을 정의한다. 세 글자로 구성된다.
-
첫 두 글자 : TIMENS의 ab와 동일하다.
-
마지막 글자 : 각 토큰( 시, 분, 초) 사이에 삽입되는 구분자이다.
예를 들어 TIME=(12.)로 설정한 경우 오후 4시 15분 37초는 04.15.37 pm으로 표현된다.
PAGE
페이지 번호를 출력한다. edit와 to는 INREC, OUTREC을 참고한다.
-
14.2. sections_item
sections_item의 세부 사항은 다음과 같다.
-
문법
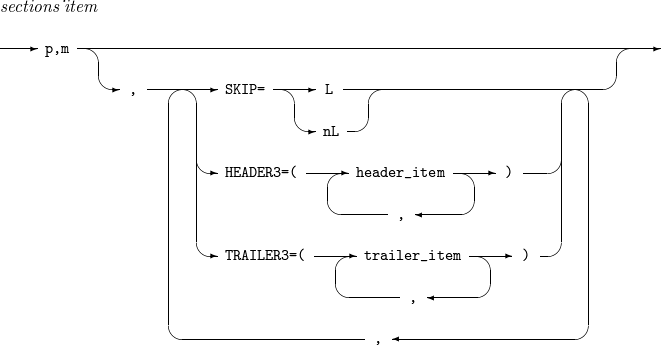 OUTFIL - sections_item
OUTFIL - sections_item -
구성요소
구성요소 설명 p,m
출력 레코드의 p ~ (p + m - 1)번째 byte를 섹션 필드로 삼는다.
첫 레코드를 출력하기 전에 첫 섹션의 머리말을 출력한다. 현재 레코드의 섹션 필드의 값이 바로 이전 레코드의 섹션 필드의 값과 다르면, 이전 섹션의 꼬리말과 현재 섹션의 머리말을 출력한다. 마지막 레코드를 출력하고 나서 마지막 섹션의 꼬리말을 출력한다. edit와 to는 INREC, OUTREC을 참고한다.
SKIP=L
한 섹션이 끝나고 다음 섹션이 시작되기 전에 빈 줄 한 개를 출력한다.
SKIP=nL
한 섹션이 끝나고 다음 섹션이 시작되기 전에 빈 줄 n개를 출력한다.
HEADER3
섹션 머리말을 정의한다. 자세한 내용은 header_item을 참고한다.
TRAILER3
섹션 꼬리말을 정의한다. 자세한 내용은 trailer_item을 참고한다.
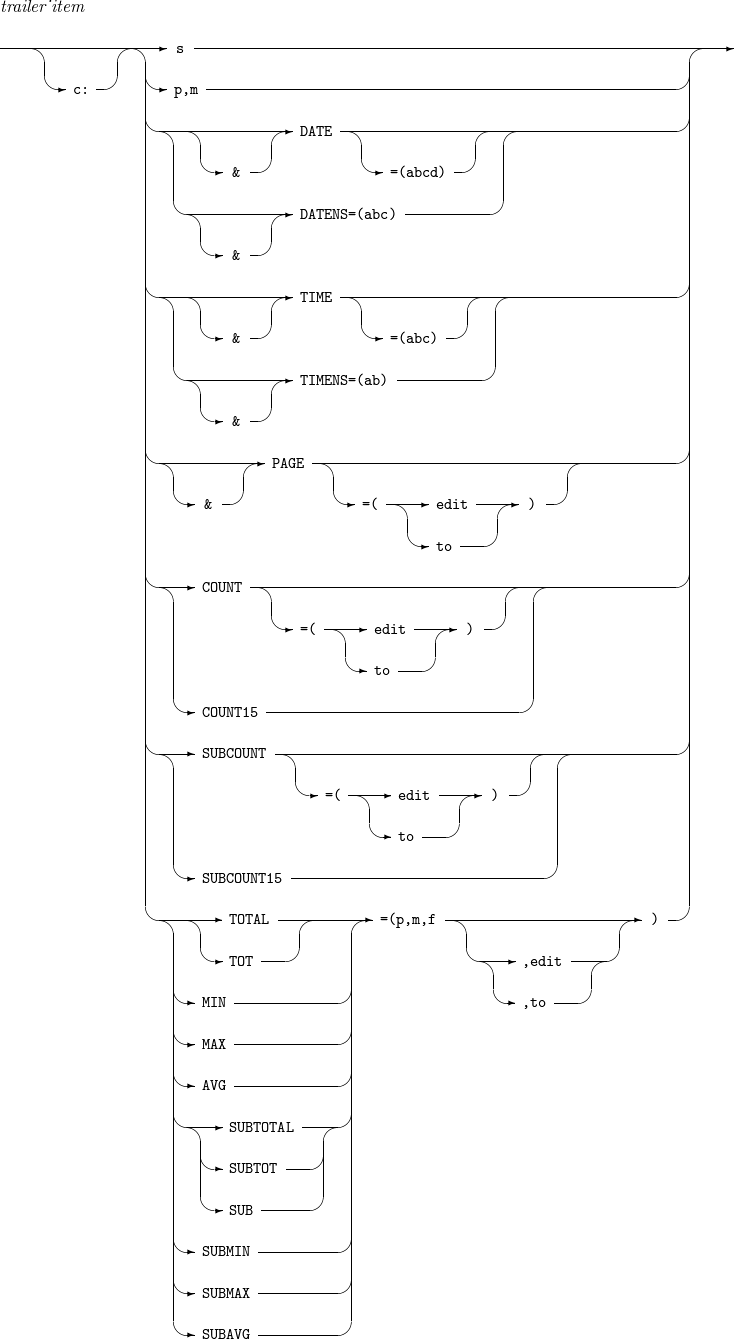
14.3. trailer_item
trailer_item의 세부 사항은 다음과 같다.
-
문법
 OUTFIL - trailer_item
OUTFIL - trailer_item -
구성요소
구성요소 설명 s
header_item을 참고한다.
p,m
header_item을 참고한다.
DATENS=(abc)
header_item을 참고한다.
DATE=(abcd)
header_item을 참고한다.
TIMENS=(ab)
header_item을 참고한다.
TIME=(abc)
header_item을 참고한다.
PAGE
header_item을 참고한다.
COUNT
-
문서 꼬리말의 경우
전체 출력 레코드의 개수를 출력한다.
-
페이지 꼬리말의 경우
현재 페이지에 출력된 레코드의 개수를 출력한다. 섹션 꼬리말의 경우 현재 섹션에 출력된 레코드의 개수를 출력한다.
edit와 to는 INREC, OUTREC을 참고한다. edit와 to가 기술되어 있지 않으면 여덟 자리 정수 형식으로 출력한다.
COUNT15
열다섯 자리 정수로 출력한다는 점을 제외하면 COUNT와 동일하다.
SUBCOUNT
-
문서 꼬리말의 경우
전체 출력 레코드의 개수를 출력한다.
-
페이지 꼬리말의 경우
현재 페이지까지 출력된 레코드의 누적 개수를 출력한다. 섹션 꼬리말의 경우 현재 섹션까지 출력된 레코드의 누적 개수를 출력한다.
edit와 to는 INREC, OUTREC을 참고한다. edit와 to가 기술되어 있지 않으면 여덟 자리 정수 형식으로 출력한다.
SUBCOUNT15
열다섯 자리 정수로 출력한다는 점을 제외하면 SUBCOUNT와 동일하다.
TOTAL 또는 TOT
출력 레코드의 p ~ (p + m - 1)번째 byte를 집계 필드로 삼는다.
-
문서 꼬리말의 경우
전체 출력 레코드의 집계 필드를 f 포맷으로 해석한 값들의 총합을 출력한다.
-
페이지 꼬리말의 경우
현재 페이지에 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 총합을 출력한다.
-
섹션 꼬리말의 경우
현재 섹션에 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 총합을 출력한다.
edit와 to는 INREC, OUTREC을 참고한다.
MIN
출력 레코드의 p ~ (p + m - 1)번째 byte를 집계 필드로 삼는다.
-
문서 꼬리말의 경우
전체 출력 레코드의 집계 필드를 f 포맷으로 해석한 값들의 최소값을 출력한다.
-
페이지 꼬리말의 경우
현재 페이지에 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 최소값을 출력한다.
-
섹션 꼬리말의 경우
현재 섹션에 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 최소값을 출력한다.
edit와 to는 INREC, OUTREC을 참고한다.
MAX
출력 레코드의 p ~ (p + m - 1)번째 byte를 집계 필드로 삼는다.
-
문서 꼬리말의 경우
전체 출력 레코드의 집계 필드를 f 포맷으로 해석한 값들의 최대값을 출력한다.
-
페이지 꼬리말의 경우
현재 페이지에 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 최대값을 출력한다.
-
섹션 꼬리말의 경우
현재 섹션에 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 최대값을 출력한다.
edit와 to는 INREC, OUTREC을 참고한다.
AVG
출력 레코드의 p ~ (p + m - 1)번째 byte를 집계 필드로 삼는다.
-
문서 꼬리말의 경우
전체 출력 레코드의 집계 필드를 f 포맷으로 해석한 값들의 평균값을 출력한다.
-
페이지 꼬리말의 경우
현재 페이지에 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 평균값을 출력한다.
-
섹션 꼬리말의 경우
현재 섹션에 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 평균값을 출력한다.
edit와 to는 INREC, OUTREC을 참고한다.
[SUBTOTAL | SUBTOT | SUB]
출력 레코드의 p ~ (p + m - 1)번째 byte를 집계 필드로 삼는다.
-
문서 꼬리말의 경우
전체 출력 레코드의 집계 필드를 f 포맷으로 해석한 값들의 총합을 출력한다.
-
페이지 꼬리말의 경우
현재 페이지까지 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 총합을 출력한다.
-
섹션 꼬리말의 경우
현재 섹션까지 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 총합을 출력한다.
edit와 to는 INREC, OUTREC을 참고한다.
SUBMIN
출력 레코드의 p ~ (p + m - 1)번째 byte를 집계 필드로 삼는다.
-
문서 꼬리말의 경우
전체 출력 레코드의 집계 필드를 f 포맷으로 해석한 값들의 최소값을 출력한다.
-
페이지 꼬리말의 경우
현재 페이지까지 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 최소값을 출력한다.
-
섹션 꼬리말의 경우
현재 섹션까지 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 최소값을 출력한다.
edit와 to는 INREC, OUTREC을 참고한다.
SUBMAX
출력 레코드의 p ~ (p + m - 1)번째 byte를 집계 필드로 삼는다.
-
문서 꼬리말의 경우
전체 출력 레코드의 집계 필드를 f 포맷으로 해석한 값들의 최대값을 출력한다.
-
페이지 꼬리말의 경우
현재 페이지까지 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 최대값을 출력한다.
-
섹션 꼬리말의 경우
현재 섹션까지 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 최대값을 출력한다.
edit와 to는 INREC, OUTREC을 참고한다.
SUBAVG
출력 레코드의 p ~ (p + m - 1)번째 byte를 집계 필드로 삼는다.
-
문서 꼬리말의 경우
전체 출력 레코드의 집계 필드를 f 포맷으로 해석한 값들의 평균값을 출력한다.
-
페이지 꼬리말의 경우
현재 페이지까지 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 평균값을 출력한다.
-
섹션 꼬리말의 경우
현재 섹션까지 출력된 레코드의 집계 필드를 f 포맷으로 해석한 값들의 평균값을 출력한다.
edit와 to는 INREC, OUTREC을 참고한다.
-
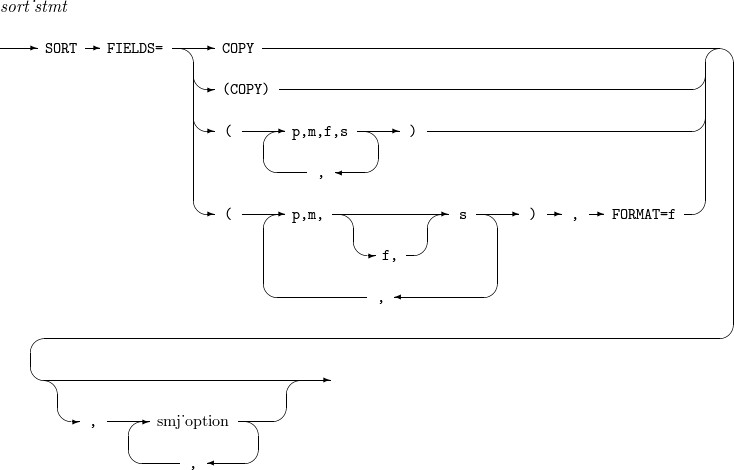
15. SORT, MERGE
SORT 및 MERGE 연산은 필드 리스트와 추가적인 OPTION으로 구성하는 문법이다. 필드 리스트에서 모두 동일한 format를 사용할 때에는 format의 정보를 필드 리스트 뒤에 한 번만 설정할 수 있다.
SORT, MERGE의 세부 사항은 다음과 같다.
-
문법
 SORT
SORT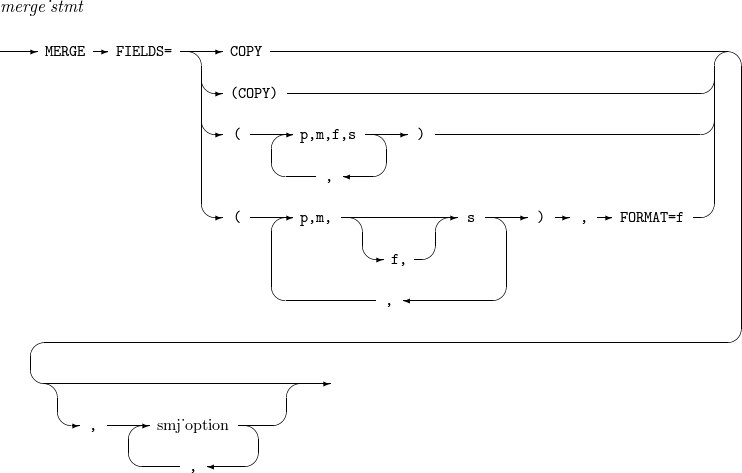 MERGE
MERGE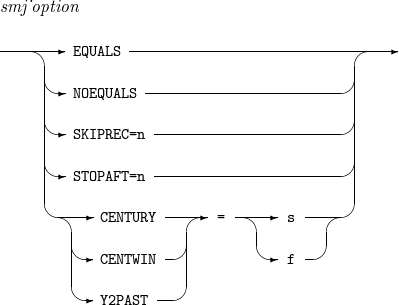 SORT, MERGE - smj_option
SORT, MERGE - smj_option -
구성요소
구성요소 설명 COPY
SORT 연산 대신 COPY 연산을 수행한다. 자세한 내용은 OPTION의 COPY 옵션을 참고한다.
p,m,f,s
입력 레코드의 p ~ (p + m - 1)번째 byte를 f 포맷으로 해석한 값을 기준으로 레코드들을 오름차순(s가 A인 경우) 또는 내림차순(s가 D인 경우) 정렬한다.
f가 생략된 경우 FORMAT 옵션에 지정된 포맷을 사용한다.
smj_option
OPTION을 참고한다.
-
예제
다음은 3 ~ 10byte의 ZD를 오름차순으로, 40 ~ 45byte의 AC를 내림차순으로 정렬하는 예이다.
SORT FIELDS=(3,8,ZD,A,40,6,AC,D)
다음은 3 ~ 10byte의 ZD를 오름차순으로, 40 ~ 45byte의 AC를 내림차순으로 정렬하는 예이다. 동일한 키인 경우 입력할 때 정렬 순서를 보장하는 stable sort로 수행한다.
SORT FIELDS=(3,8,ZD,A,40,6,AC,D), EQUALS
다음은 3 ~ 10byte의 ZD를 오름차순으로, 40 ~ 45byte의 AC를 내림차순으로 정렬하는 예이다. 추가로 SKIPREC, STOPAFT 옵션을 적용하여 101 ~ 300 사이의 레코드만 정렬하여 출력한다.
SORT FIELDS=(3,8,ZD,A,40,6,AC,D), SKIPREC = 100, STOPAFT = 200
다음은 25 ~ 28byte, 48 ~ 55byte의 모든 ZD를 오름차순으로 병합하는 예이다.
MERGE FIELDS=(25,4,A,48,8,A),FORMAT=ZD
다음은 COPY 연산만을 수행하는 예이다.
MERGE FIELDS=COPY
SORT FIELDS=COPY
16. SUM
SORT 또는 MERGE 연산을 수행한 후, 동률인 레코드들 중 하나만 출력하되, 지정된 영역(합계 필드)에는 동률인 레코드들의 합계 필드의 총합이 출력되도록 하는 문법이다.
SUM의 세부 사항은 다음과 같다.
-
문법
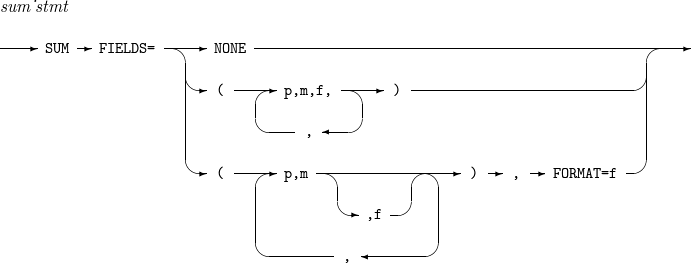 SUM
SUM -
구성요소
구성요소 설명 NONE
SORT 또는 MERGE 연산을 수행한 후, 동률인 레코드들 중 하나만 출력한다.
p,m,f
입력 레코드의 p ~ (p + m - 1)번째 byte를 합계 필드로 지정한다.
동률인 레코드들 중 하나만 출력하되, 출력 레코드의 p ~ (p + m - 1)번째 byte에는 동률인 레코드들의 합계 필드를 f 포맷으로 해석한 값들의 총합을 f 포맷으로 출력한다. f가 생략된 경우 FORMAT 옵션에 지정된 포맷을 사용한다.
-
예제
다음은 21byte에 위치한 8byte PD를, 11byte에 위치한 4byte fixed integer fields를 합계 필드로 설정하는 예이다.
SUM FIELDS=(21,8,PD,11,4,FI)
다음은 합계 필드가 없는 경우를 설정하는 예이다. 동일한 키를 가지는 중복된 레코드만 제거한다.
SUM FIELDS=NONE
다음은 41byte에 위치한 8byte ZD를, 49byte에 위치한 4byte ZD를 합계 필드로 설정하는 예이다.
SUM FIELDS=(41,8,49,4),FORMAT=ZD