애플리케이션 프로그래밍
본 장에서는 OpenFrame NDB 사용한 프로그램의 구조, 실행 환경 정의, 명령어 사용법에 대해서 기술한다.
1. 개요
NDB 애플리케이션은 NDB에서 제공되는 기능을 이용하여 NDB 데이터베이스에 정보를 저장하거나 저장된 정보를 처리하는 프로그램이다. 애플리케이션은 여러 가지 프로그래밍 언어를 이용하여 작성될 수 있으며, 각 언어별로 NDB에서 제공되는 기능을 사용하기 위한 방법은 다르다. 본 장에서는 COBOL 언어를 사용하여 NDB 애플리케이션을 작성하는 경우에 대해서만 설명한다.
하나의 언어를 이용해서 NDB 애플리케이션을 작성할 수 있다면, 다른 언어를 사용하는 경우라도 쉽게 NDB 애플리케이션을 작성할 수 있을 것이다.
다음은 NDB 데이터베이스에 대한 입출력 조작을 위한 명령을 보여주는 표이다.
-
NDB 매크로 제어 명령
직접 데이터베이스의 정보를 조작하는 명령이 아니라 애플리케이션에서 NDB를 사용하는 구간의 시작과 끝을 나타내기 위한 명령어이다.
명령어 설명 가상 데이터베이스를 개방(open)하여 애플리케이션에서 지정된 가상 데이터베이스를 사용하기 위해 필요한 환경을 준비한다.
가상 데이터베이스의 사용을 폐쇄(close)한다.
-
데이터 조작 명령 (DML: Database Manipulation Language)
데이터베이스의 정보를 조작하기 위한 명령이다.
명령어 설명 데이터베이스에 저장되어 있는 레코드를 지정된 세트에 참여하도록 연결한다.
DISCONNECT 명령어를 이용해서 레코드를 해당 레코드가 연결되어 있는 세트와 연결을 끊는다.
데이터베이스에서 레코드를 삭제한다.
둘 다 데이터베이스에 저장된 레코드를 검색하기 위한 명령어이다.
데이터베이스에 저장된 레코드의 내용을 변경한다.
데이터베이스에 하나의 레코드를 저장한다.
2. NDB 애플리케이션 구조
NDB는 기본적으로 클라이언트/서버 구조로 구성된다. NDB 애플리케이션은 클라이언트 프로세스로서 동작하고, NDB 클라이언트 라이브러리를 사용하여 NDB 서버에 데이터베이스를 조작하기 위한 명령을 요청한다.
다음 그림은 NDB 애플리케이션이 동작하는 환경을 보여준다.
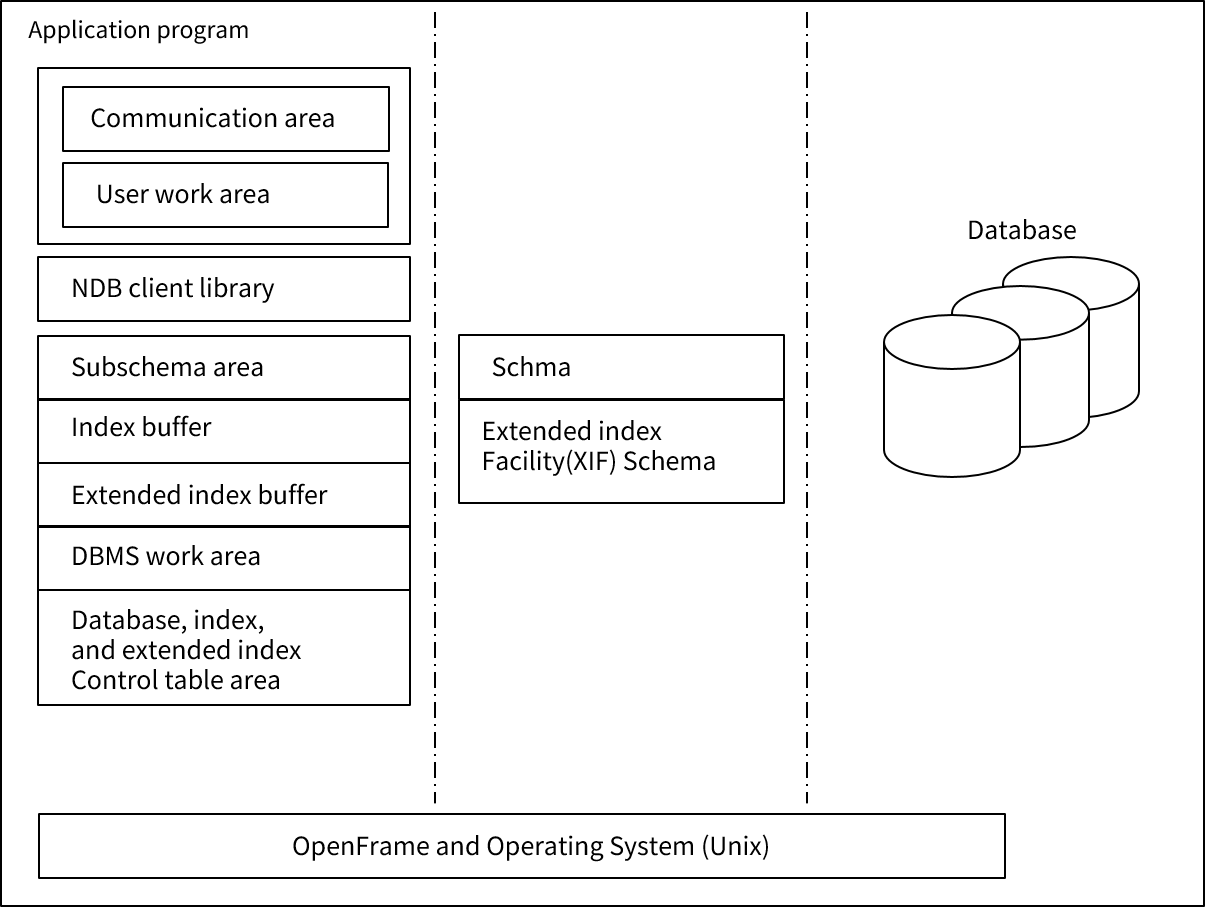
NDB 애플리케이션에서 사용자가 작성하는 가장 주요한 부분은 데이터베이스를 조작하기 위한 NDB 명령을 포함하는 애플리케이션 로직이다. 이외에도 데이터베이스에 레코드를 저장하거나 데이터베이스로부터 검색한 레코드를 저장하기 위한 사용자 작업 영역(User Work Area), 그리고 데이터베이스에 명령을 요청하고 명령의 수행 결과 등의 정보를 공유하기 위한 통신 영역(Communication Area)이 애플리케이션에 포함되어야 한다.
2.1. 사용자 작업 영역
사용자 작업 영역(User Work Area)은 데이터베이스와 애플리케이션 사이의 레코드 입출력을 위한 메모리 상의 영역이다. 애플리케이션이 데이터베이스에 레코드를 저장하는 경우 사용자 작업 영역에 저장된 레코드가 데이터베이스에 저장된다. 반대로 애플리케이션이 데이터베이스로부터 레코드를 검색하는 경우 검색된 레코드는 사용자 작업 영역에 놓인다. 사용자 작업 영역은 애플리케이션이 사용하는 서브스키마에 포함된 레코드 타입 별로 할당되어야 한다.
2.2. 통신 영역
통신 영역(Communication Area)은 FCOM(File Management Communication Area)이라고도 불린다. 이는 데이터베이스와 애플리케이션 사이의 통신을 위해 아래와 같이 약속된 형태의 정보를 갖는 메모리 영역이다.
다음은 COBOL 언어로 기술된 FCOM 영역의 구조이다.
01 FCOM.
02 FILLER PIC X (16).
02 VDBNAME PIC X (8).
02 RDNAME PIC X (12).
02 MCRCD PIC S9 (4) COMP.
02 MCRCTL PIC S9 (4) COMP.
02 FILLER PIC S9 (4) COMP.
02 SETCNT PIC S9 (4) COMP.
02 FILLER PIC S9 (4) COMP.
02 DBESCB.
03 MCRTYP PIC XX.
03 DBSCB PIC 99.
03 DBECB PIC 99.
02 FILLER PIC S9 (4) COMP.
02 PAGENO PIC S9 (9) COMP.
02 FILLER PIC S9 (4) COMP.
02 SNAPCTL PIC S9 (4) COMP.
02 FILLER PIC X (8).
02 TRNCTR PIC S9 (9) COMP.
02 PGCS PIC X (8).
02 PGCSRN PIC X (12).
02 SETTYP OCCURS 3 TIMES.
03 STNAME PIC X(12).
03 SETCTL.
04 ARRAYNO PIC S9 (4) COMP.
다음은 FCOM 영역의 주요 필드에 대한 설명이다.
-
VDBNAME
애플리케이션이 개방(open)하여 사용하고 있는 가상 데이터베이스(virtual database, subschema)의 이름이 VDBNAME 필드에 저장된다. 애플리케이션은 VDBNAME 필드 값을 참조할 수는 있지만 변경하면 안 된다.
-
RDNAME
DML 명령에 지정된 레코드 이름이 RDNAME 필드에 저장되어 데이터베이스로 전달된다. 애플리케이션은 RDNAME 필드 값을 참조할 수는 있지만 변경하면 안 된다.
PGCSRN 필드에 저장된 레코드 이름은 데이터베이스가 명령을 수행한 결과로 변경하거나 검색한 레코드의 이름이 설정되는 반면, RDNAME 필드에는 사용자가 요청한 명령에 지정된 레코드의 이름이 저장된다. 따라서 명령의 수행 도중에 에러의 발생 등으로 PGCSRN이 설정되지 않은 경우에도 RDNAME 필드에는 사용자가 명령에 지정한 레코드 이름이 그대로 남아 있게 된다.
-
MCRCTL
데이터베이스 조작 명령에 지정된 옵션의 종류를 나타내는 코드 값이 MCRCTL 필드에 설정된다.
제어코드 (16진) 명령 의미 0000
FIND/GET
레코드 순차 검색, 계층관계 이용
CONNECT
레코드를 모든 세트에 연결
DISCONNECT
레코드를 모든 세트로부터 연결 해제
ERASE
지정된 레코드만을 삭제
STORE
레코드를 저장하기만 함
0001
FIND/GET
레코드 순차 검색, 계층관계 이용, 역방향
CONNECT
레코드를 모든 세트에 연결, 레코드 이름 지정
DISCONNECT
레코드를 모든 세트로부터 연결 해제, 레코드 이름 지정
ERASE
지정된 오너 레코드와 다른 오너 레코드에 속하지 않은 모든 멤버 레코드 삭제
STORE
레코드를 저장, 관련된 모든 세트에 연결
0002
FIND/GET
레코드 순차 검색, 계층관계 이용, 오너 레코드 검색
CONNECT
오너 레코드를 모든 관련된 세트에 연결
DISCONNECT
오너 레코드를 모든 관련된 세트로부터 연결 해제
0003
FIND/GET
직접 검색, 리스트 구조 세트
CONNECT
레코드를 지정된 세트에 연결
DISCONNECT
레코드를 지정된 세트로부터 연결 해제
ERASE
모든 연관된 레코드를 삭제
STORE
레코드를 저장, 지정된 세트에 연결
0010
FIND/GET
직접 검색, 인덱스 혹은 랜덤 레코드 키 사용
0011
직접 검색, 확장 인덱스 사용 (보조 키 사용)
0012
중복 키 레코드 검색, 인덱스 혹은 랜덤 레코드 키 사용
0013
중복 키 레코드 검색, 확장 인덱스 사용 (보조 키 사용)
0020
FIND/GET
가장 작은 인덱스 레코드 검색, Range
0021
가장 작은 인덱스 레코드 검색, Subrange
0022
가장 작은 확장 인덱스 레코드 검색, Range
0023
가장 작은 확장 인덱스 레코드 검색, Subrange
0024
순차 검색, 인덱스 레코드, Range
0025
순차 검색, 인덱스 레코드, Subrange
0026
순차 검색, 확장 인덱스 레코드, Range
0027
순차 검색, 확장 인덱스 레코드, Subrange
0028
가장 큰 확장 인덱스 레코드 검색, Range
0029
가장 큰 확장 인덱스 레코드 검색, Subrange
002A
역순 검색, 확장 인덱스 레코드, Range
002B
역순 검색, 확장 인덱스 레코드, Subrange
0030
FIND/GET
Range의 맨 앞 레코드 검색
0031
Subrange의 맨 처음 레코드 검색
0032
지정된 Range의 최근에 검색된 레코드 검색
0033
지정된 Subrange의 최근에 검색된 레코드 검색
0034
지정된 Range에서 순차 검색
0035
지정된 Subrange에서 순차 검색
0036
지정된 Range의 최근에 검색된 위치에서 순차 검색
0037
지정된 Subrange의 최근에 검색된 위치에서 순차 검색
0040
FIND/GET
(PGCS) 주소 지정에 의한 직접 검색
-
MCRTYP
사용자가 데이터베이스 명령을 실행하면, 데이터베이스는 요청된 명령에 해당하는 명령 타입 코드를 이 필드에 설정한다. 에러나 예외상황이 발생한 경우 MCRTYP 필드의 값을 검사하면 어떤 명령을 실행 중에 해당 에러나 예외상황이 발생하였는지를 알 수 있다. (Size: 2 bytes, Data format: Character)
명령 코드 데이터베이스 조작 명령 CN
CONNECT
DC
DISCONNECT
ER
ERASE
FD
FIND
FN
FINISH
GT
GET
MD
MODIFY
RD
READY
ST
STORE
-
DBSCB, DBECB
데이터베이스 조작 명령을 실행하는 과정에 예외상황이 발생하면 이는 DBSCB 및 DBECB 필드를 통해서 애플리케이션에 전달된다. 발생한 예외상황에 따라서 DBSCB와 DBECB에 각각 2바이트 숫자로 정의된 코드가 설정된다. DBSCB와 DBECB 필드를 함께 묶어서 DBESCB라고 한다.
에러나 예외상황 없이 명령이 정상적으로 수행된 경우에는 DBSCB와 DBECB 필드 둘 다 '00’이 설정된다. 예외나 에러가 발생한 경우에는 애플리케이션은 DBSCB 및 DBECB에 설정된 값에 따라서 적절한 조치를 취할 수 있도록 프로그램 되어야 한다.
예외상황별 DBSCB 및 DBECB에 설정되는 코드와 이에 대한 자세한 설명은 에러 코드를 참고한다.
-
PAGENO
PAGENO 필드는 논리 페이지 번호를 인자로 필요로 하는 데이터베이스 조작 명령을 실행할 때 입력 값으로 사용된다. 이 논리 페이지 번호는 사용자 랜덤 엔트리 레코드의 검색이나 저장할 때 사용된다.
-
PGCS
프로그램 현재 상태(PGCS)는 애플리케이션에서 최근에 처리된 레코드가 저장되어 있는 주소 값을 갖고 있다. 데이터베이스 조작 명령을 실행하면 데이터베이스는 PGCS의 값이 명령의 대상이 되는 레코드를 가리키도록 갱신한다. 이 PGCS 값을 이용하여 애플리케이션은 동일한 레코드를 추후에 다시 검색할 수 있다. 또한 PGCS의 값은 CONNECT나 DISCONNECT 명령의 대상 레코드를 지정하기 위한 인자로 사용된다.
PGCS가 가리키는 레코드는 트랜잭션이 종료 또는 취소되는 경우에 다른 애플리케이션 의해서 삭제될 수 있다. 트랜잭션의 종료나 취소가 일어나기 전에 PGCS 값을 ‘0’으로 설정하여 이러한 상황을 피할 수 있다. 특정 레코드를 가리키는 PGCS 값은 하나의 애플리케이션에서 저장되고 다시 사용되는 경우가 일반적이다. 하지만 PGCS 값의 저장과 재사용이 서로 다른 애플리케이션에서 이루어지는 경우 애플리케이션은 PGCS 값이 올바른지 여부를 확인해야 한다.
-
PGCSRN
PGCSRN(Program Current Status Record Name) 필드는 PGCS 필드가 가리키는 레코드의 레코드 이름을 갖는다.
-
Others
FCOM 영역의 나머지 필드들은 NDB 애플리케이션을 처리하는 언어 처리기에서 내부적으로 사용되거나 데이터베이스와 애플리케이션 간의 내부적인 용도로 사용된다. 이러한 필드들에 대한 사용자 프로그램에서의 참조나 변경은 허용되지 않는다.
3. 데이터베이스 조작 에러 조치
애플리케이션에 의해서 요청된 데이터베이스 조작 명령의 실행 결과는 FCOM 통신 영역의 DBSCB와 DBECB 필드를 통해서 반환된다. 애플리케이션은 DBSCB와 DBECB의 값을 조사하여 발생한 예외상황별로 필요한 조치를 취할 수 있다.
다음은 예외상황에 따른 심각도이다.
| DBSCB | DBECB | 이벤트 | 의미 |
|---|---|---|---|
=0 |
=0 |
Normal |
정상적으로 실행되었다. |
!=0 |
=0 |
Minor exception |
애플리케이션은 주의 및 경고에 대한 조치를 취해야 한다. |
!=0 |
!=0 |
Moderate exception |
에러상황이지만 적절한 조치가 취해지면 프로그램이 계속 수행된다. |
=0 |
!=0 |
Sever exception |
심각한 에러상황으로 트랜잭션이 취소되었다. |
애플리케이션에서 데이터베이스 조작 명령 이후의 예외상황 처리 방법은 다음과 같다.
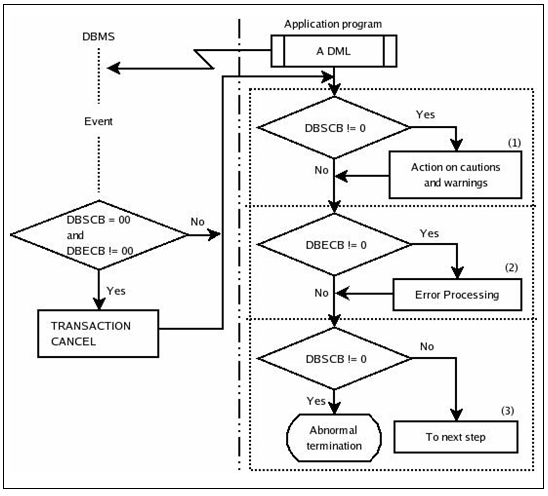
위의 그림에서 (1), (2), (3)에 해당하는 처리 루틴은 애플리케이션의 목적에 맞게 사용자에 의해 작성될 수 있다. DBSCB 및 DBESCB의 값에 따라서 사용자가 작성한 예외상황 처리 루틴이 데이터베이스에 의해서 호출된다.
아래는 COBOL로 작성된 NDB 애플리케이션의 예외 처리 방법에 대한 예제이다. COBOL 언어에서는 데이터베이스 조작의 예외 처리를 위해서 USE FOR DB-EXCEPTION, USE FOR DEAD-LOCK의 구문과 IF DB-EXCEPTION 명령을 지원한다.
...
PROCEDURE DIVISION.
DECLARATIVES.
DB-ERR-RTN SECTION.
USE FOR DB-EXCEPTION.
AAA.
IF DBSCB=00 GO TO AAA-1.
TRANSACTION CANCEL.
AAA-1.
DISPLAY 'DBSCB=' DBSCB 'DBECB=' DBECB.
AAA-EXIT.
EXIT.
DEAD-LOCK-RTN SECTION.
USE FOR DEAD-LOCK.
BBB.
DISPLAY 'DEAD-LOCK OCCURRED - PGCS=' PGCS 'PGCSRN=' PGCSRN ...
BBB-EXIT.
EXIT.
END DECLARATIVES.
...
TRANSACTION-POINT.
TRANSACTION END.
TRANSACTION START.
...
MOVE 100 TO ENTRY-REC-KEY.
GET ANY 'AREC'
IF DB-EXCEPTION IS 13 GO TO NO-REC.
...
NO-REC.
STORE 'A'.
...
다음은 NDB 애플리케이션에서 예외처리를 위해 사용되는 구문과 명령에 대한 설명이다.
| 항목 | 설명 |
|---|---|
USE FOR DB-EXCEPTION |
예외상황 처리 루틴을 COBOL 프로그램 PROCEDURE DIVISION의 DECLARATIVES와 END DECLARATIVES 구문 사이에 USE FOR DB-EXCEPTION 속성을 갖는 섹션으로 작성한다. |
IF DB-EXCEPTION |
IF DB-EXCEPTION 문을 이용하여 minor 및 moderate 에러상황이 발생했는지 확인할 수 있다. 즉, IF DB-EXCEPTION 문이 만족하는 경우 DBSCB 필드 값은 0이 아닌 값으로 설정되어 있다. 모든 데이터베이스 조작 명령 다음에 IF DB-EXCEPTION 문을 이용하여 올바른 처리가 되었는지 확인하고 예외상황별로 필요한 처리를 해준다. |
USE FOR DEAD-LOCK |
교착상태는 심각한 예외상황의 하나이며, DBSCB=00, DBECB=88이 FCOM 통신 영역에 반환된다. 교착 상태가 발생하면 트랜잭션은 자동적으로 취소되고, 사용자가 USE FOR DEAD-LOCK으로 정의한 예외 처리 루틴이 호출된다. 교착 상태에 대한 예외 처리 루틴이 정의되지 않은 상태에서 교착 상태가 발생하면 애플리케이션은 비정상 종료된다. |
4. 애플리케이션 실행 환경 정의
NDB 애플리케이션이 실행되는 환경은 ADL PED 명령에 의해서 정의된다.
PED 명령의 다음과 같은 구문을 이용해서 애플리케이션의 실행 환경을 제어할 수 있으며, 이는 애플리케이션의 성능 및 보안 측면에서 중요한 역할을 한다.
4.1. ACCESS MODE
애플리케이션이 데이터베이스 조작 명령을 요청하면 데이터베이스는 PED 명령에 지정된 접근모드에 따라서 애플리케이션에 의한 데이터베이스 접근을 배타적으로 제어한다.
PED에 지정할 수 있는 접근모드는 다음과 같다.
| 접근모드 | 설명 |
|---|---|
READ-ONLY(RO) |
데이터베이스에 대한 검색만을 허용하는 경우 설정하는 접근모드다. RO 접근모드가 설정되면 애플리케이션은 FIND 및 GET 명령만 사용할 수 있다. 배타적인 데이터베이스 접근 제어 및 트랜잭션 관리가 필요하지 않은 애플리케이션인 경우에 대해서만 이 접근모드를 지정한다. |
EXCLUSIVE-READ(ER) |
데이터베이스에 대한 검색만을 허용하는 경우 설정하는 모드이다. ER 접근모드가 설정되면 애플리케이션은 FIND 및 GET 명령만 사용할 수 있다. 이 접근모드가 설정된 경우 특정 애플리케이션이 검색하려는 데이터 레코드를 다른 애플리케이션이 데이터 구조를 변경하지 않고 내용만을 갱신하고 있는 경우에는 배타적인 접근 제어 없이 동시에 검색이 수행된다. 하지만 데이터 구조를 변경하는 명령과는 배타적인 접근 제어가 수행된다. NDB에서는 FIND 및 GET 명령만 허락된다는 점을 제외하면 UPDATE와 동일한 배타적인 접근 제어가 수행된다. |
COMPLETELY EXCLUSIVE-READ(CER) |
데이터베이스에 대한 검색만을 허용하는 경우 설정하는 모드이다. CER 접근모드가 설정되면 애플리케이션은 FIND 및 GET 명령만 사용할 수 있다. 이 접근모드가 설정된 경우 특정 애플리케이션이 검색하려는 데이터 레코드를 다른 애플리케이션이 데이터 구조 변경의 여부와 상관없이 변경하고 있는 경우에는 배타적인 접근 제어가 수행된다. NDB에서는 FIND 및 GET 명령만 허락된다는 점을 제외하면 UPDATE와 동일한 배타적인 접근 제어가 수행된다. |
MODIFY(MD) |
데이터베이스에 대한 검색과 갱신을 허용하는 경우 설정하는 모드이다. MD 접근모드가 설정되면 애플리케이션은 FIND, GET, MODIFY 명령만을 사용할 수 있다. 데이터베이스에 저장된 데이터 구조의 변경 없이 레코드 내용만을 갱신하는 경우 이 접근모드를 지정할 수 있다. 이 접근모드는 데이터의 정합성을 보장한다. 이 접근모드가 설정된 경우 특정 애플리케이션이 데이터 구조의 변경이 없는 갱신 중인 레코드를, RO나 ER 이외의 접근모드를 사용하는 다른 애플리케이션이 접근하려는 경우에는 배타적인 접근 제어가 수행된다. NDB에서는 FIND, GET, MODIFY 명령만 허락된다는 점을 제외하면 UPDATE와 동일한 배타적인 접근 제어가 수행된다. |
UPDATE(UP) |
데이터베이스에 대한 모든 명령을 허용하는 경우 설정하는 모드이다. UP 접근모드가 설정되면 애플리케이션은 FIND, GET, MODIFY, ERASE, CONNECT, DISCONNECT, STORE 명령을 모두 사용할 수 있다. 데이터베이스에 저장된 데이터 구조의 변경을 수반하는 명령을 실행하는 경우 이 접근모드를 지정해야 한다. 이 접근모드는 데이터의 정합성을 보장한다. UP 접근모드의 애플리케이션이 처리 중인 레코드를, RO 접근모드 이외의 접근모드를 사용하는 다른 애플리케이션이 접근하려는 경우 배타적인 접근 제어가 수행된다. |
CREATE(CR) |
데이터베이스를 생성하는 애플리케이션에 대해서 이 접근모드를 지정한다. |
다음 표는 NDB에서 동시에 여러 애플리케이션이 하나의 데이터에 접근하는 경우 각 애플리케이션의 접근모드에 따라서 동일한 데이터에 대한 접근이 동시에 수행 가능한 경우와 그렇지 않은 경우를 보여준다.
| Access mode for the first program | ||||||
|---|---|---|---|---|---|---|
Access mode for the second program |
RO |
ER |
CER |
MD |
UP |
CR |
RO |
O |
O |
O |
O |
O |
O |
ER |
O |
O |
O |
O |
X |
X |
CER |
O |
O |
O |
X |
X |
X |
MD |
O |
O |
X |
X |
X |
X |
UP |
O |
X |
X |
X |
X |
X |
CR |
O |
X |
X |
X |
X |
X |
-
범례
구분 설명 O
두 프로그램에서 동시에 동일한 데이터에 대한 접근이 가능
X
두 프로그램에서 동시에 동일한 데이터에 대한 접근이 불가능
4.2. BUFFER
데이터베이스에 접근하기 위해서 애플리케이션은 다음과 같은 3가지 버퍼를 정의해야 한다.
-
페이지 버퍼(Page Buffer, 미지원)
-
인덱스 버퍼(Index Buffer, 미지원)
-
확장 인덱스 버퍼(Extended Index Buffer, 미지원)
각 버퍼의 크기 및 개수는 PED 명령을 이용하여 애플리케이션 별로 정의될 수 있다. PED 명령에 버퍼를 정의하는 구문이 생략된 경우에는 접근하는 데이터베이스에 정상적으로 접근하기 위해 필요한 최소의 버퍼가 사용된다.
Fujitsu AIM/DB와 달리 OpenFrame NDB에서는 레코드 단위로 I/O를 수행하기 때문에 버퍼를 사용하지 않는다. 인덱스 및 확장 인덱스를 위한 버퍼는 사용하지 않는다. 따라서 버퍼의 크기 및 개수를 정의하기 위한 PED 명령의 PAGE BUFFER, INDEX BUFFER clause, - EXTENDED BUFFER clause 구문들 역시 무시된다.
버퍼의 존재 자체는 데이터베이스의 기능이 아닌 구현 기법상의 문제이다. 즉 기능적인 관점에서 이 3가지 버퍼 없이도 OpenFrame NDB는 Fujitsu AIM/DB에서와 동일한 기능을 제공할 수 있다.
4.3. EXCLUSION/INCLUSION SCHEMA
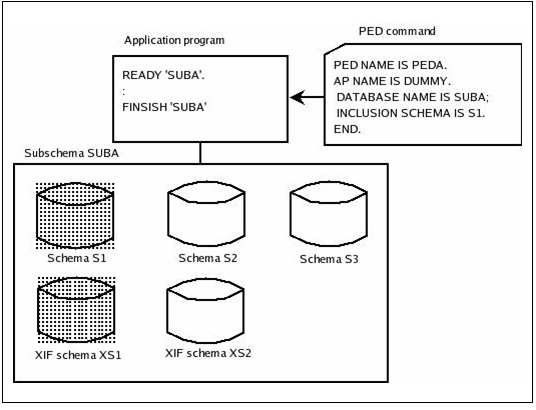
PED 명령의 INCLUSION SCHEMA 구문과 EXCLUSION SCHEMA 구문을 이용하여 애플리케이션이 사용하는 가상 데이터베이스에 포함된 스키마 중에서 일부의 스키마만을 사용할 수 있도록 선택할 수 있다. 즉, 애플리케이션 별로 사용할 수 있는 스키마를 제한할 수 있다.
애플리케이션과 연관된 PED 명령에 이 구문들이 지정되지 않은 경우에는 애플리케이션은 가상 데이터베이스에 포함된 모든 스키마를 사용할 수 있다. 결과적으로 관리자는 애플리케이션이 사용하지 않는 데이터베이스 스키마를 독자적으로 관리할 수 있다. 애플리케이션이 사용중인 스키마에 해당하는 데이터베이스에 대해서는 데이터베이스 스키마의 속성을 변경하거나 재편성(reorganize)할 수 없다.
다음 그림은 서브스키마 SUBA에 포함된 스키마중에서 스키마 S1만을 애플리케이션에서 사용하도록 제한하고 있다.
4.4. EXCLUSION/INCLUSION SUBRANGE
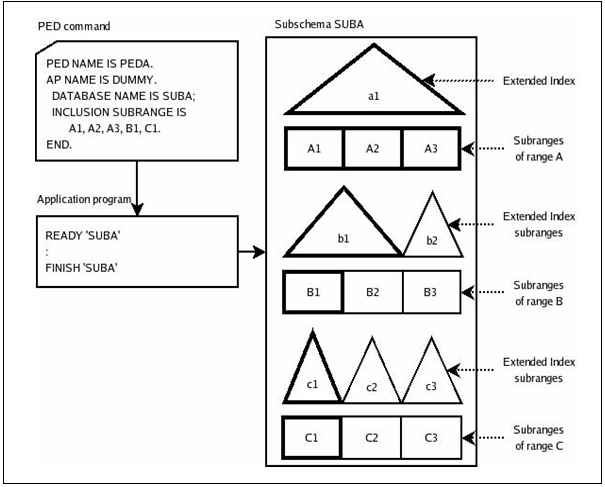
PED 명령의 INCLUSION SUBRANGE 구문과 EXCLUSIONN SUBRANGE 구문을 이용하여 애플리케이션이 사용하는 가상 데이터베이스에 포함된 Subrange 중에서 일부의 Subrange만을 사용할 수 있도록 선택할 수 있다. 즉, 애플리케이션 별로 사용할 수 있는 Subrange를 제한할 수 있다. 애플리케이션과 연관된 PED 명령에 이 구문들이 지정되지 않은 경우에는 애플리케이션은 가상 데이터베이스에 포함된 모든 Subrange를 사용할 수 있다.
결과적으로 관리자는 애플리케이션이 사용하지 않는 Subrange를 독자적으로 관리할 수 있다. 애플리케이션이 사용중인 Subrange에 대해서는 해당 Subrange의 속성을 변경하거나 재편성할 수 없다.
다음 그림은 서브스키마 SUBA에 포함된 Subrange 중에서 일부만을 사용하도록 제한하고 있다. 특정 Subrange가 사용되는 경우 이와 관련된 확장 인덱스 Subrange 역시 동시에 사용된다.
5. 레코드 순서와 데이터베이스 현재 상태
애플리케이션은 데이터베이스에 저장된 레코드들을 일정한 순서에 따라서 처리한다. 레코드들이 검색되는 순서는 검색에 사용되는 명령의 종류와 지정된 인자에 의해 결정된다.
순차 검색에 있어서, 검색에 사용되는 명령의 종류와 인자가 정해져 있는 경우에는 현재 상태에 따라 다음에 검색될 레코드가 결정된다. 이 현재 상태는 사용되는 검색 기법, 레코드 타입 및 세트 타입에 따라서 현재 처리 중인 레코드의 위치를 기억하고 있다.
데이터베이스는 순차 검색할 때 현재 상태를 이용하므로 다음에 검색할 레코드를 바로 알아낼 수 있다. PGCS를 제외한 나머지 현재 상태는 애플리케이션에서 직접 변경할 수 없으며, 이들은 데이터베이스 조작 명령을 실행하는 과정에서 데이터베이스에 의해 내부적으로 관리된다.
다음은 데이터베이스에서 순차 검색에 사용되는 현재 상태의 종류에 대한 설명이다.
| 상태 | 설명 |
|---|---|
PGCS |
애플리케이션의 현재 상태(PGCS)는 가장 최근에 처리된 레코드의 위치 주소를 갖는다. 하나의 애플리케이션당 하나의 PGCS가 존재한다. PGCS 값은 데이터베이스 조작 명령 이후에 FCOM 통신 영역의 PGCS 필드에 반환된다. 사용자는 FCOM 통신 영역의 PGCS 필드에 직접 값을 설정할 수 있다. |
RDCS |
레코드 타입 별로 하나의 레코드 현재 상태(Record Type Current Status)가 존재한다. RDCS는 특정 레코드 타입의 레코드 중에서 가장 최근에 처리된 레코드의 위치 주소를 갖는다. |
STCS |
세트 타입 별로 하나의 세트 현재 상태(Set Type Current Status)가 존재한다. STCS는 특정 세트에 포함된 레코드 중에서 가장 최근에 처리된 레코드의 위치 주소를 갖는다. |
IXCS |
인덱스 엔트리를 갖는 레코드 타입 별로 인덱스 현재 상태(Index Current Status)가 존재한다. IXCS는 특정 타입의 인덱스 엔트리 레코드 중에서 가장 최근에 처리된 레코드의 위치 주소를 갖는다. |
XICS |
확장 인덱스 타입 별로 하나의 확장 인덱스 현재 상태(Extended Index Current Status)가 존재한다. XICS는 특정 확장 인덱스에 의해 확장 인덱스가 되는 레코드 타입의 레코드 중에서 가장 최근에 처리된 레코드의 위치 주소를 갖는다. |
RGCS |
하나의 애플리케이션에는 하나의 Range 현재 상태(Range Current Status)가 존재한다. RGCS는 가장 최근에 애플리케이션에서 검색한 레코드의 위치 주소를 갖는다. |
6. NDB 명령어
본 절에서는 각 NDB 명령어의 기능과 명령을 작성하는 방법에 대해서 설명한다.
6.1. READY
가상 데이터베이스를 개방(open)하여 애플리케이션에서 지정된 가상 데이터베이스를 사용하기 위해 필요한 환경을 준비한다.
-
Format
READY [subschema-name].
-
애플리케이션이 사용할 가상 데이터베이스의 이름을 subschema-name에 지정한다.
-
subschema-name이 생략된 경우 애플리케이션의 선언부에 지정된 서브스키마 이름이 사용된다.
-
subschema-name이 지정된 경우 애플리케이션의 선언부에 지정된 서브스키마 이름과 일치해야 한다.
-
-
General rules
-
READY 이외의 다른 데이터베이스 조작 명령어(DML)는 READY 이전에 실행될 수 없다.
-
READY 명령으로 가상 데이터베이스를 개방한 애플리케이션은 필요한 데이터베이스 조작이 모두 완료되었을 때 FINISH 명령어로 해당 가상 데이터베이스를 폐쇄해야 한다.
-
애플리케이션의 서브 프로그램에서는 GET이나 STORE 등의 명령을 사용하여 READY나 FINISH 명령 없이 데이터베이스에 접근할 수 있다. 반면 메인 프로그램은 READY 또는 FINISH 명령어를 호출해야 한다.
-
READY 명령 실행 중 에러가 발생하면 애플리케이션은 비정상 종료된다.
-
6.2. FINISH
가상 데이터베이스의 사용을 폐쇄(close)한다.
-
Format
FINISH [subschema-name].
-
폐쇄할 가상 데이터베이스의 이름을 subschema-name에 지정한다.
-
subschema-name이 생략된 경우 애플리케이션의 선언부에 지정된 서브스키마 이름이 사용된다.
-
subschema-name이 지정된 경우 애플리케이션의 선언부에 지정된 서브스키마 이름과 일치해야 한다.
-
-
General rules
-
FINISH 명령어의 실행 중에 에러가 발생하면 애플리케이션은 비정상 종료된다.
-
6.3. CONNECT
데이터베이스에 저장되어 있는 레코드를 지정된 세트에 참여하도록 연결한다. 즉, PGCS가 가리키는 레코드를 STCS가 가리키는 세트에 연결한다.
-
Format
CONNECT [record-name|unique-name-1] TO {{{set-name|unique-name-2} [NEXT|PRIOR|integer|AT unique-name-3]}...|ALL}.-
record-name이나 unique-name-1에 PGCS가 가리키는 레코드 타입의 이름을 지정한다. 이를 지정한 경우 실제 PGCS가 가리키는 레코드 타입의 이름과 일치해야 한다.
-
set-name이나 unique-name-2에 레코드를 연결할 세트 타입의 이름을 지정한다.
-
NEXT, PRIOR, integer, AT unique-name-3 중에 하나를 지정하여 레코드를 연결될 세트 상에서 어느 위치에 연결할지를 지정한다.
-
리스트 구조 세트에 대해서는 정수치(integer) 혹은 정수 변수(AT unique-name-3)를 지정할 수 있다.
-
링 구조 세트에 대해서는 NEXT나 PRIOR를 지정할 수 있다. unique-name-3은 alphanumeric 혹은 numeric 변수로 다음과 같다.
-
alphanumeric 변수이고 링 구조 세트인 경우 그 길이는 1이어야 한다.
-
변수에 지정 가능한 값은 다음과 같다.
구분 설명 N
EXT를 의미한다.
P
PRIOR를 의미한다.
공백(blank)
공백을 지정하는 경우 시스템은 연결 위치를 사용자가 지정하지 않은 것으로 간주한다.
-
numeric 변수이고 리스트 구조 세트인 경우 부호형 4자리 숫자(signed 4-digit number)형으로 정수 값을 가져야 한다. (미지원)
-
-
TO ALL을 지정하면 해당 레코드 타입을 멤버로 포함하는 모든 세트 타입에 레코드를 연결한다(READY에 지정된 서브스키마에 정의된 레코드와 세트 타입 중에서 해당 레코드를 멤버로 갖는 모든 세트 타입을 의미한다).
-
-
General rules
-
record-name이나 unique-name-1에 지정되는 레코드 타입은 READY 명령어를 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
set-name이나 unique-name-2에 지정되는 세트 타입은 READY 명령어를 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
record-name이나 unique-name-1에 지정되는 레코드 타입은 스키마에 정의되어 있어야 하고, 해당 레코드 타입은 set-name이나 unique-name-2에 지정된 세트의 멤버 레코드로 정의되어 있어야 한다.
-
지정된 레코드는 지정된 세트의 STCS가 가리키는 위치에 연결되기 때문에 CONNECT 명령 전에 해당 세트의 STCS가 먼저 설정되어 있어야 한다.
-
지정된 레코드는 다음 연결 위치에 연결된다.
-
링 구조 세트에 대해서 NEXT 혹은 PRIOR가 지정된 경우 연결 위치는 STCS가 가리키는 위치의 첫 번째 다음 혹은 이전 위치이다. CONNECT 명령에 NEXT나 PRIOR를 통한 연결 위치 지정은 스키마에 정의된 FIRST, LAST, NEXT, PRIOR와 같은 연결 위치 지정보다 우선한다.
-
리스트 구조 세트에 대해서 정수 값이 지정된 경우 주어진 정수 값에 해당하는 위치가 연결 위치가 된다.
-
unique-name-3이 numeric 변수인 경우는 위의 정수 값이 지정된 경우와 동일하게 처리된다.
-
-
TO ALL이 지정된 경우 포함하여 연결 위치가 생략된 경우 연결 위치는 세트의 구조에 따라 결정된다. 링 구조인 경우 스키마의 SET subentry의 INSERTION 절에 정의된 연결 위치가 된다. 리스트 구조인 경우 STCS가 가리키는 위치가 연결 위치가 된다.
-
6.4. DISCONNECT
DISCONNECT 명령어를 이용해서 레코드를 해당 레코드가 연결되어 있는 세트와 연결을 끊는다.
-
Format
DISCONNECT [record-name|unique-name-1] FROM {{set-name|unique-name-2}...|ALL}.-
PGCS가 가리키는 레코드의 레코드 타입 이름을 record-name이나 unique-name-1를 이용하여 지정한다. 지정한 경우 PGCS가 가리키는 실제 레코드의 레코드 타입 이름과 일치해야 한다.
-
set-name이나 unique-name-2에 레코드의 연결을 끊을 세트 타입의 이름을 지정한다.
-
FROM ALL을 지정하면 지정된 레코드를 포함하는 모든 세트 타입으로부터 레코드의 연결을 끊는다(READY에 지정된 서브스키마에 포함된 레코드와 세트 타입 중에서 해당 레코드를 멤버로 갖는 모든 세트 타입을 의미한다).
-
-
General rules
-
record-name이나 unique-name-1에 지정된 레코드 타입은 READY 명령을 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
set-name이나 unique-name-2에 지정된 세트 타입은 READY 명령을 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
record-name이나 unique-name-1에 지정된 레코드 타입은 스키마에 정의되어 있어야 한다(해당 레코드 타입은 set-name이나 unique-name-2에 지정된 세트의 멤버 레코드로 정의되어 있어야 한다).
-
6.5. ERASE
ERASE 명령어는 데이터베이스에서 레코드를 삭제한다. 세트에 참여하고 있는 여러 개의 레코드를 한번의 명령으로 삭제하는 것이 가능하다. 여러 개의 레코드를 삭제하는 경우는 명령문에 지정된 기본 삭제 레코드(deletion base record)와 이 레코드의 멤버 레코드들이 삭제된다. 삭제할 대상이 되는 레코드는 RDCS에 의해 가리켜진다.
-
Format
ERASE {record-name|unique-name} [{SELECTIVE|ALL}].-
삭제할 레코드나 기본 삭제 레코드의 타입 이름을 record-name 이나 unique-name에 지정한다. record-name이나 unique-name에 지정된 레코드 타입의 RDCS가 가리키는 레코드가 기본 삭제 레코드가 된다.
-
삭제되는 레코드들의 범위는 SELECTIVE 혹은 ALL 구문의 지정에 따라 달라진다.
-
-
General rules
-
record-name이나 unique-name에 지정된 레코드 타입은 READY 명령어를 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
다음과 같은 3가지의 삭제 방식이 존재한다:
-
ALL이나 SELECTIVE 구문이 지정되지 않은 경우 지정된 레코드 타입의 RDCS가 가리키는 기본 삭제 레코드만 삭제된다.
-
SELECTIVE 구문이 지정된 경우 기본 삭제 레코드는 삭제된다. 위의 기본 삭제 레코드가 멤버 레코드들을 갖는 세트의 오너 레코드인 경우 다른 세트에 연결되지 않은 모든 멤버 레코드들이 함께 삭제된다. 이처럼 삭제되는 멤버 레코드가 다시 그 하위에 다른 멤버 레코드를 갖는 경우 다른 세트에 연결되지 않은 하위의 멤버 레코드들도 반복적으로 모두 삭제된다.
-
ALL 구문이 지정된 경우 기본 삭제 레코드는 삭제된다. 이 기본 삭제 레코드가 멤버 레코드들을 갖는 세트의 오너 레코드인 경우 이 세트에 연결된 모든 멤버 레코드가 삭제된다. 삭제된 멤버 레코드가 다시 그 하위에 다른 멤버 레코드를 갖는 경우 다시 해당 멤버 레코드 하위의 모든 멤버 레코드가 삭제된다.
-
-
6.6. GET/FIND
GET과 FIND는 둘 다 데이터베이스에 저장된 레코드를 검색하기 위한 명령어이다.
인덱스 순차 혹은 확장 인덱스 순차 검색의 경우 FIND 명령어는 검색한 레코드의 인덱스 키에 해당하는 데이터 항목 값만을 사용자 작업 영역으로 얻어온다. 또한 FIND 명령어는 논리적으로 연결된 레코드(logically concatenation/connected record)는 얻어오지 않는다. 반면 GET 명령어는 레코드의 모든 데이터 항목을 얻어온다. 또한 GET 명령어는 논리적으로 연결된 레코드들도 함께 얻어온다는 차이가 있다.
레코드가 저장된 방식과 저장된 레코드에 접근하는 방식에 따라서 여러 가지 검색 방법이 존재한다.
다음은 NDB에서 제공하는 검색 방법이다.
| 검색 방법 | 설명 | |
|---|---|---|
Direct retrieval by entry key value |
엔트리 키 값을 이용한 직접 검색 |
|
Indexed entry |
인덱스 엔트리 키 값을 이용하는 검색 방법 |
|
Random entry |
랜덤 엔트리 키 값을 이용하는 검색 방법 |
|
Extended index entry |
확장 인덱스 엔트리의 키 값을 이용하는 검색 방법 |
|
Record retrieval with duplicate key values |
중복 키 값을 갖는 레코드 검색 |
|
System entry method |
시스템 세트를 이용하는 검색 방법 |
|
Set retrieval |
세트에서의 검색 방법 |
|
Sequential retrieval based on STCS |
세트에서의 순차 검색 |
|
Owner retrieval |
세트의 오너 레코드 검색 |
|
Retrieval by integer |
리스트 구조 세트에서 정수 값에 의한 검색 |
|
Indexed sequential retrieval |
인덱스 순차 검색 |
|
Indexed sequential retrieval |
인덱스 순차 검색 |
|
Extended index sequential retrieval |
확장 인덱스 순차 검색 |
|
Range sequential retrieval |
Range에서의 검색 |
|
Non-CRP range sequential retrieval |
일반 Range에서의 순차 검색 |
|
CRP range sequential retrieval |
CRP Range에서의 순차 검색 |
|
Direct retrieval using PGCS |
PGCS에 의한 직접 검색 |
PGCS에 의한 직접 검색 |
위에 나열된 각각의 검색 방법에 대해서 다음 절에 구체적으로 설명되어 있다. 사용되는 검색 방법은 명령어 뒤에 지정되는 옵션 및 구문에 의해 구분된다.
6.6.1. GET/FIND ANY
GET/FIND ANY 명령어는 지정된 엔트리 키를 이용하여 레코드에 대한 직접 검색을 수행한다.
-
Format
Format-1은 인덱스 엔트리 혹은 랜덤 엔트리 검색에 사용되고, Format-2는 확장 인덱스 엔트리 검색에 사용된다.
-
Format-1
엔트리 메소드를 사용하지 않는 레코드(non-entry method record)의 확장 인덱스가 기본 엔트리(primary entry)로 정의되어 있지 않고, 확장 인덱스에 의한 보조 엔트리(secondary entry)가 하나만 정의된 경우 Format-1을 확장 인덱스 엔트리 검색에 사용할 수 있다.
{GET|FIND} ANY {record-name-1|unique-name-1}. -
Format-2
{GET|FIND} ANY {record-name-2|unique-name-2|RECORD} WITHIN {extended-index-name|unique-name-3} INDEX.
-
-
General rules
-
검색할 인덱스 엔트리(혹은 랜덤 엔트리) 레코드의 타입 이름을 record-name-1, unique-name-1에 저장한다.
-
Format-2를 사용하는 경우 검색할 레코드의 타입 이름을 지정할 필요가 없다. 명시적으로 레코드 타입 이름을 지정하지 않는 경우 레코드 타입 이름 대신에 RECORD라고 지정한다.
-
record-name-2와 unique-name-2에는 extended-index-name이나 unique-name-3으로 지정된 확장 인덱스가 인덱스하는 레코드 타입 이름을 지정한다.
-
검색에 사용할 확장 인덱스의 이름을 extended-index-name 또는 unique-name-3에 지정한다.
-
record-name-1, record-name-2, unique-name-1, unique-name-2에 지정된 레코드 타입 이름은 READY할 때에 지정된 서브스키마에 포함되어 있어야 한다. 이 명령을 실행하기 전에 검색할 레코드의 엔트리 키 값을 사용자 작업 영역에 미리 설정한다.
-
검색할 레코드가 저장되어 있는 Range가 Subrange를 가지고 있는 경우 이 명령어를 실행하기 전에 Subrange를 선택하기 위한 위치 키(subrange location key)값을 미리 설정한다. 단 확장 인덱스 엔트리를 검색 할 때에는 확장 인덱스가 서브 레인지로 분할되어 있지 않다면 위치 키(subrange location key)값을 설정할 필요는 없다.
-
사용자 랜덤 함수를 이용하는 경우 이 명령을 실행하기 전에 사용자 랜덤 함수의 결과 값인 논리 페이지 번호를 FCOM의 PAGENO 변수에 설정한다.
-
extended-index-name이나 unique-name-3에 지정된 확장 인덱스에 대해서 PED 명령의 EXTENDEDINDEX BUFFER 절에 NOT USED 속성을 지정할 수 없다.
-
인덱스 엔트리 혹은 확장 인덱스 엔트리를 검색할 때에는 인덱스 및 확장 인덱스가 사용되므로 저장된 레코드들에 대한 인덱스 및 확장 인덱스가 검색 이전에 생성되어 있어야 한다.
-
Format-2에서 extended-index-name 혹은 unique-name-3만 지정되어 있고 레코드 이름이 명시적으로 주어져 있지 않은 경우라도, 지정된 확장 인덱스가 인덱스하는 레코드 타입은 READY할 때에 지정된 서브스키마에 포함되어 있어야 한다.
-
인덱스 엔트리, 랜덤 엔트리, 확장 인덱스 엔트리등 어떤 엔트리 방법을 이용할지는 레코드 타입 별로 SCHEMA 명령을 이용하여 정의된다.
-
6.6.2. GET/FIND DUPLICATE
GET/FIND DUPLICATE 명령어는 현재 검색 위치의 다음 레코드를 검색하여 동일한 엔트리 키 값을 갖는 모든 레코드들을 순차적으로 검색하기 위해 사용된다.
현재 검색 위치는 레코드 및 확장 인덱스 타입 별로 존재하는 RDCS 및 XICS에 의해 유지된다. 이 명령어는 현재 사용자 작업 영역에 저장되어 있는 엔트리 키 값과 현재 검색 위치의 다음 레코드의 엔트리 키 값이 동일한 경우에 현재 검색 위치의 다음 레코드를 사용자 작업 영역으로 얻어온다.
-
Format
인덱스 엔트리 혹은 랜덤 엔트리 레코드를 검색하는 경우 Format-1을 사용하고, 확장 인덱스 엔트리 레코드를 검색하는 경우 Format-2를 사용한다. AT END 구문에 프러시저 이름을 지정하면 검색하는 레코드가 존재하지 않는 경우 지정된 프러시저가 호출된다.
-
Format-1
{GET|FIND} DUPLICATE {record-name-1|unique-name-1} [AT END GO TO procedure-name]. -
Format-2
{GET|FIND} DUPLICATE {record-name-2|unique-name-2|RECORD} [WITHIN {extended-index-name|unique-name-3} INDEX] [AT END GO TO procedure-name].
-
-
General rules
-
검색할 인덱스 엔트리 혹은 랜덤 엔트리 레코드의 타입 이름을 record-name-1에 지정하고, 검색할 인덱스 엔트리 혹은 랜덤 엔트리 레코드의 타입 이름을 unique-name-1에 저장한다.
-
Format-2를 사용하는 경우 검색할 레코드의 타입 이름을 지정할 필요가 없다. 명시적으로 레코드 타입 이름을 지정하지 않는 경우 레코드 타입 이름 대신에 RECORD라고 지정한다.
-
record-name-2에는 extended-index-name이나 unique-name 3으로 지정된 확장 인덱스가 인덱스하는 레코드 타입 이름을 지정하고, unique-name-2에는 extended-index-name이나 unique-name-3으로 지정된 확장 인덱스가 인덱스하는 레코드 타입 이름을 저장한다.
-
6.6.3. System entry method
레코드를 검색하기 위해서 엔트리 키 데이터 항목의 값을 이용하는 다른 엔트리 기법과 달리, 시스템 엔트리 기법은 세트 구조를 이용하여 시스템 세트의 멤버 레코드를 얻음으로써 레코드를 검색한다.
STCS가 시스템 세트에 연결된 레코드를 가리키고 있다면, 시스템 엔트리 검색을 이용하여 STCS가 가리키는 레코드의 바로 다음 레코드(NEXT)나 이전(PRIOR) 레코드를 검색한다. STCS의 값이 설정되어 있지 않은 경우 시스템 엔트리 검색은 시스템 세트의 첫 번째 레코드를 검색한다.
-
Format
{GET|FIND} {NEXT|PRIOR} {record-name|RECORD|unique-name-1} WITHIN {set-name|unique-name-2} [AT END GO TO procedure-name].-
AT END 구문에 프러시저 이름을 지정하면 검색 결과, 해당하는 레코드가 더 이상 존재하지 않는 경우에(시스템 세트에 멤버 레코드가 하나도 없는 경우도 포함) 지정된 프러시저가 호출된다.
-
-
General rules
-
set-name이나 unique-name-2에 지정된 세트의 모든 멤버 레코드를 레코드 타입에 상관없이 검색하려면 RECORD를 지정한다.
-
set-name이나 unique-name-2에 지정된 세트의 멤버 레코드 중에서 특정한 레코드 타입의 레코드만을 검색하려는 경우 record-name이나 unique-name-1에 검색하려는 레코드의 타입 이름을 지정한다.
-
record-name이나 unique-name-1에 지정된 레코드 타입은 set-name이나 unique-name-2에 지정된 세트의 member record type 중에 하나로 정의되어 있어야 한다.
-
record-name이나 unique-name-1에 지정된 레코드 타입은 READY 명령어를 실행할 때에 지정된 서브스키마에 포함되어 있어야 한다.
-
set-name이나 unique-name-2에 지정된 세트 타입은 READY 명령어를 실행할 때에 지정된 서브스키마에 포함되어 있어야 한다.
-
시스템 세트의 멤버 레코드들을 저장하는 Range가 Subrange로 나뉘어 있는 경우 프로그램에서 실행될 맨 처음 시스템 엔트리 검색 이전에 Subrange를 선택하기 위한 위치 키(location key)값을 미리 사용자 작업 영역에 설정하고 이 명령어를 호출해야 한다.
-
6.6.4. GET/FIND WITHIN set
GET/FIND WITHIN set 명령어는 세트의 오너 레코드와 멤버 레코드 사이의 계층적인 관계하에서 레코드를 검색한다. 이 명령으로 검색되는 레코드는 STCS가 가리키는 레코드의 바로 다음(NEXT 지정 시) 레코드나 이전(PRIOR 지정 시) 레코드이다.
세트의 구조(링 구조 혹은 리스트 구조)에 상관없이 NEXT나 PRIOR를 지정하여 순차 검색을 할 수 있다. 이 명령어는 시스템 세트에 대해서도 사용할 수 있다.
|
앞 절의 시스템 엔트리 검색 명령어의 문법은 이 명령어의 문법과 동일하다. 또는 시스템 엔트리에 사용되는 시스템 세트도 세트의 일종으로 볼 수 있다. |
-
Format
{GET|FIND} {NEXT|PRIOR} {record-name|RECORD|unique-name-1} WITHIN {set-name|unique-name-2} [AT END GO TO procedure-name].-
AT END 구문이 지정된 경우 다음 조건 중 하나에 해당되면 지정된 프러시저가 호출된다.
-
검색 중인 세트의 마지막(혹은 처음) 레코드에서 NEXT(혹은 PRIOR)를 지정하여 순차 검색하는 경우
-
검색된 멤버 레코드가 세트에 연결되어 있지 않은 경우
-
검색된 오너 레코드가 멤버 레코드를 갖지 않고 있는 경우
-
-
-
General rules
-
set-name이나 unique-name-2에 지정된 세트의 모든 멤버 레코드를 레코드 타입에 상관없이 검색하려면 RECORD를 지정한다.
-
set-name이나 unique-name-2에 지정된 세트의 멤버 레코드 중에서 특정한 레코드 타입의 레코드만을 검색하려는 경우 record-name이나 unique-name-1에 검색할 레코드의 타입 이름을 지정한다.
-
record-name이나 unique-name-1에 지정된 레코드 타입은 set-name이나 unique-name-2에 지정된 세트의 멤버 레코드 타입 중에 하나로 정의되어 있어야 한다.
-
record-name이나 unique-name-1에 지정된 레코드 타입은 READY 명령어를 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
set-name이나 unique-name-2에 지정된 세트 타입은 READY 명령어를 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
이 명령어는 STCS의 값을 참조하므로 호출 전에 엔트리 검색 명령을 사용하여 STCS 값을 설정해 두어야 한다. 따라서 이 명령어는 특정 트랜잭션의 첫 번째 명령으로 사용될 수 없다. 이 제약은 시스템 세트를 이용하는 시스템 엔트리 검색 명령에는 예외적으로 적용되지 않는다. 시스템 엔트리 검색 명령에서는 이러한 경우 첫 번째 멤버 레코드를 검색한다.
-
지정된 세트가 링 구조인 경우 SCHEMA 명령어의 SET 부항목의 LINKED 구문에 PRIOR가 지정되어 있지 않더라도 해당 SET에 대해서 이 명령어를 실행할 때 PRIOR를 지정할 수 있다.
-
지정된 세트가 리스트 구조이고 record-name이나 unique-name-1에 레코드 타입 이름이 지정되면 지정된 레코드 타입의 레코드가 찾아질 때까지 검색이 이루어진다. 지정된 레코드가 없는 경우 세트의 끝(set end) 상태가 발생하고 DBSCB(Database Status Control Block)의 값이 11로 설정된다.
-
6.6.5. GET/FIND OWNER WITHIN set
GET/FIND OWNER 명령어를 이용하여 세트의 오너 레코드를 검색한다. 세트의 구조(링 혹은 리스트)에 상관없이 이 명령어를 사용하여 세트의 오너 레코드를 얻을 수 있다. 또한 이 명령어는 시스템 세트 타입에 대해서도 실행 가능하다.
-
Format
{GET|FIND} OWNER WITHIN {set-name|unique-name} [AT END GO TO procedure-name].-
AT END 구문이 지정된 경우 STCS가 가리키는 레코드가 지정된 세트에 연결되어 있지 않은 경우 지정된 프러시저가 호출된다.
-
-
General rules
-
set-name이나 unique-name에 지정된 세트 타입은 READY 명령어를 실행할 때에 지정된 서브스키마에 포함되어 있어야 한다.
-
이 명령은 STCS가 가리키는 세트의 오너 레코드를 검색하므로 호출 전에 STCS는 특정 세트 상의 위치를 가리키고 있어야 한다. 이 명령어를 실행하기 전에 엔트리 검색 명령을 사용해서 STCS의 값을 초기화해야 한다. 결과적으로 이 명령어는 특정 트랜잭션의 첫 번째 명령으로 사용될 수 없다. 이 제약은 시스템 세트가 대상인 경우에 예외적으로 적용되지 않는다. 특정 시스템 세트 타입에 해당하는 세트는 유일하기 때문이다.
-
SCHEMA 명령어를 이용하여 SET을 정의할 때 LINKED 절에 OWNER를 지정하지 않은 경우에도 링 구조 세트에 대한 오너 검색이 가능하다.
-
6.6.6. GET/FIND Integer WITHIN set
값에 의한 GET/FIND 명령어는 리스트 구조 세트의 멤버 레코드들 중에서 주어진 정수 값의 위치에 존재하는 멤버 레코드를 직접적으로 검색한다. 주어지는 정수 값은 1에서부터 시작하고 멤버 레코드의 위치 순서를 나타낸다. 순환 제어를 하기 위해서 음의 정수 값을 지정할 수도 있다.
-
Format
{GET|FIND} {integer|unique-name-1} {record-name|RECORD|unique-name-2} WITHIN {set-name|unique-name-3} [AT END GO TO procedure-name].-
AT END 구문이 지정된 경우 다음 조건 중 하나에 해당되면 지정된 프러시저가 호출된다.
-
STCS가 가리키는 레코드가 오너 레코드에 연결되지 않은 경우
-
integer나 unique-name-1에 지정된 값의 위치에 연결된 멤버 레코드가 존재하지 않는 경우
-
-
unique-name-1은 signed 4-digit numeric 변수여야 한다(즉, signed 2-byte binary item).
-
-
General rules
-
record-name이나 unique-name-2에 검색할 레코드 타입을 지정한다.
-
모든 레코드 타입을 얻기 위해서는 RECORD를 지정한다.
-
record-name이나 unique-name-2에 지정된 레코드 타입은 스키마에 정의되어 있어야 한다. 또한 해당 레코드 타입은 set-name이나 unique-name-3에 지정된 세트의 멤버 레코드로 정의되어 있어야 한다.
-
record-name이나 unique-name-2에 지정된 레코드 타입은 READY 명령어를 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
set-name이나 unique-name-3에 지정된 세트 타입은 READY 명령어를 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
이 명령어는 STCS의 값을 참조하므로 호출 전에 엔트리 검색 명령을 사용하여 STCS 값을 설정해두어야 한다. 따라서 이 명령어는 특정 트랜잭션의 첫 번째 명령으로 사용될 수 없다.
-
set-name이나 unique-name-3에 지정된 세트 타입은 리스트 구조를 가져야 한다.
-
integer나 unique-name-1에 지정된 정수 값은 다음에 기술된 값보다 큰 값을 가질 수 없다.
구분 설명 가상 세트(virtual set) 타입의 경우
멤버 레코드의 총 개수
축 세트(axis set) 타입의 경우
검색할 방향에 해당하는 축 세트 타입의 멤버 레코드 개수
-
6.6.7. GET/FIND WITHIN INDEX index
GET/FIND FIRST(index) 명령어는 지정된 Range의 레코드 중에서 가장 작은 인덱스 키 값을 갖는 레코드를 검색한다. IXCS를 참조하지는 않는다. GET/FIND NEXT(index) 명령어는 IXCS가 현재 가리키고 있는 레코드를 포함하는 인덱스 링 내에서 현재 레코드의 다음 레코드를 검색한다.
-
Format
{GET|FIND} {FIRST|NEXT} {record-name|unique-name} WITHIN INDEX [SUBRANGE] [AT END GO TO procedure-name].-
SUBRANGE가 지정된 경우 검색 대상이 되는 영역은 Subrange이다. 지정되지 않은 경우는 Range 전체가 검색 대상이 된다.
-
AT END 구문이 지정된 경우 검색 대상 영역의 모든 인덱스 레코드가 검색되어 더 이상 검색할 레코드가 존재하지 않는 경우 지정된 프러시저가 호출된다.
-
-
General rules
-
record-name이나 unique-name에 지정된 레코드 타입은 SCHEMA 명령어로 해당 레코드 타입을 정의할 때 인덱스 엔트리로 지정된 레코드 타입이어야 한다.
-
record-name이나 unique-name에 지정된 레코드 타입은 READY 명령어를 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
Range가 Subrange로 나뉘어져 있지 않은 경우에는 SUBRANGE를 지정할 수 없다.
-
FIRST와 SUBRANGE가 지정된 경우 검색할 Subrange를 선택하기 위한 위치 키 값이 사용자 작업 영역에 설정되어 있어야 한다.
-
NEXT를 지정한 경우 이 명령의 실행은 IXCS를 참조하므로 미리 설정되어 있어야 한다. 이 명령(NEXT)은 특정 트랜잭션의 첫 명령으로 사용될 수 없다.
-
레코드가 존재하지 않는 검색 대상 영역에 대해서 NEXT를 지정하여 이 명령을 실행하면 AT END 예외상황을 발생시킨다.
-
6.6.8. GET/FIND WITHIN INDEX extended-index(ascending order)
GET/FIND FIRST 및 NEXT(extended index) 명령어는 확장 인덱스 키에 대한 오름차순으로 레코드를 검색한다. 검색을 수행하기 위해서 확장 인덱스 엔트리가 사용된다.
-
Format
{GET|FIND} {FIRST|NEXT} {record-name|unique-name-1|RECORD} WITHIN {extended-index-name|unique-name-2} INDEX [SUBRANGE] [AT END GO TO procedure-name].-
SUBRANGE가 지정된 경우 확장 인덱스의 Subrange가 검색 대상 영역이 된다. 지정되지 않은 경우 Range 전체가 검색 대상이 된다.
-
AT END 구문이 지정된 경우 검색 대상 영역의 모든 레코드가 검색되어 더 이상 검색할 레코드가 존재하지 않는 경우 지정된 프러시저가 호출된다.
-
-
General rules
-
record-name이나 unique-name-1에 지정된 레코드 타입에 대해서 스키마 명령어에 확장 인덱스가 정의되어 있어야 한다.
-
record-name이나 unique-name-1에 지정된 레코드 타입은 READY 명령어를 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
검색할 레코드 타입을 명시적으로 지정할 필요는 없다. 명시적으로 지정하지 않는 경우에는 레코드 타입 이름 대신에 RECORD라고 지정한다.
-
record-name이나 unique-name-1이 지정된 경우 해당 레코드 타입은 extended-index-name이나 unique-name-2로 지정된 확장 인덱스에 의해서 인덱스 되어야 한다.
-
Range가 Subrange로 나뉘어져 있지 않은 경우에는 SUBRANGE를 지정할 수 없다.
-
FIRST와 SUBRANGE 구문이 모두 지정된 경우 검색할 Subrange를 선택하기 위한 위치 키 값이 사용자 작업 영역에 설정되어 있어야 한다. 여러 Subrange가 하나의 확장 인덱스 Subrange에 의해 인덱스 되는 경우에는 확장 인덱스 Subrange에 속하는 여러 Subrange 중에서 임의의 Subrange에 해당하는 위치 키를 설정하면 된다. 확장 인덱스가 Subrange로 나뉘어져 있지 않은 경우에는 위치 키 값을 설정하지 않아도 된다.
-
NEXT를 지정한 경우 이 명령어는 XICS를 참조하므로 미리 설정되어 있어야 한다. 이 명령은 특정 트랜잭션의 첫 명령으로 사용될 수 없다.
-
이 명령어를 사용하기 위해서 확장 인덱스가 미리 생성되어 있어야 한다.
-
검색 대상 영역에 레코드가 존재하지 않을 때 NEXT를 실행하면 이는 곧바로 AT END 예외상황을 발생시킨다. AT END 예외상황이 발생한 바로 다음에 PRIOR를 실행하면 가장 큰 확장 인덱스 키 값에 해당하는 레코드를 검색한다.
-
6.6.9. GET/FIND WITHIN INDEX extended-index(descending order)
GET/FIND LAST 및 PRIOR(extended index) 명령어는 확장 인덱스 키에 대한 내림차순으로 레코드를 검색한다. 검색의 수행에는 확장 인덱스 엔트리가 사용된다.
-
Format
{GET|FIND} {LAST|PRIOR} {record-name|unique-name-1|RECORD} WITHIN {extended-index-name|unique-name-2} INDEX [SUBRANGE] [AT END GO TO procedure-name].-
SUBRANGE가 지정된 경우 확장 인덱스의 Subrange가 검색 대상 영역이 된다. 지정되지 않은 경우 Range 전체가 검색 대상이 된다.
-
AT END 구문이 지정된 경우 검색 대상 영역의 모든 레코드가 검색되어 더 이상 검색할 레코드가 존재하지 않는 경우 지정된 프러시저가 호출된다.
-
-
General rules
-
record-name이나 unique-name-1에 지정된 레코드 타입에 대해서 SCHEMA 명령어에 확장 인덱스가 정의되어 있어야 한다.
-
record-name이나 unique-name-1에 지정된 레코드 타입은 READY 명령어를 실행할 때 지정된 Subrange에 포함되어 있어야 한다.
-
검색할 레코드 타입을 명시적으로 지정할 필요는 없다. 명시적으로 지정하지 않는 경우에는 레코드 타입 이름 대신에 RECORD라고 지정한다.
-
record-name이나 unique-name-1이 지정된 경우 해당 레코드 타입은 extended-index-name이나 unique-name-2로 지정된 확장 인덱스에 의해서 인덱스 되어야 한다.
-
Range가 Subrange로 나뉘어져 있지 않은 경우에는 SUBRANGE를 지정할 수 없다.
-
LAST와 SUBRANGE 구문이 모두 지정된 경우 검색할 Subrange를 선택하기 위한 위치 키 값이 사용자 작업 영역에 설정되어 있어야 한다. 여러 Subrange가 하나의 확장 인덱스 Subrange에 의해 인덱스되는 경우에는 확장 인덱스 Subrange에 속하는 여러 Subrange 중에서 임의의 Subrange에 해당하는 위치 키를 설정하면 된다. 확장 인덱스가 Subrange로 나뉘어져 있지 않은 경우에는 위치 키 값을 설정하지 않아도 된다.
-
PRIOR를 지정한 경우 이 명령어는 XICS를 참조하므로 미리 설정되어 있어야 한다. 이 명령어는 특정 트랜잭션의 첫 명령으로 사용될 수 없다.
-
이 명령어를 사용하기 위해서 확장 인덱스가 미리 생성되어 있어야 한다.
-
검색 대상 영역에 레코드가 존재하지 않을 때 PRIOR를 실행하면 이는 곧바로 AT END 예외상황을 발생시킨다. AT END 예외상황이 발생한 바로 다음에 NEXT를 실행하면 가장 작은 확장 인덱스 키 값에 해당하는 레코드를 검색한다.
-
6.6.10. GET/FIND WITHIN range(Non-CRP range)
GET/FIND FIRST 및 NEXT(Non-CRP range) 명령어는 CRP 속성을 갖지 않는 Range로부터 레코드를 검색한다. 레코드가 검색되는 순서는 실제로 해당 레코드들이 Range 내부에 저장된 물리적인 순서와 동일하다.
-
Format
{GET|FIND} {FIRST|NEXT} {record-name|unique-name-1|RECORD} WITHIN {range-name|unique-name-2} {RANGE|SUBRANGE} [AT END GO TO procedure-name].-
SUBRANGE가 지정된 경우 검색 대상이 되는 영역은 Subrange이다.
-
RANGE가 지정된 경우는 Range 전체가 검색 대상이 된다.
-
AT END 구문이 지정된 경우 검색 대상 영역의 모든 레코드가 검색되어 더 이상 검색할 레코드가 존재하지 않는 경우 지정된 프러시저가 호출된다.
-
-
General rules
-
record-name이나 unique-name에 지정된 레코드 타입은 READY 명령어를 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
검색할 레코드 타입을 명시적으로 지정할 필요는 없다. 명시적으로 지정하지 않는 경우에는 레코드 타입 이름 대신에 RECORD라고 지정한다.
-
Range가 Subrange로 나뉘어져 있지 않은 경우에는 SUBRANGE를 지정할 수 없다.
-
FIRST와 SUBRANGE 구문이 모두 지정된 경우 검색할 Subrange를 선택하기 위한 위치 키 값이 사용자 작업 영역에 설정되어 있어야 한다.
-
NEXT를 지정하는 경우 이 명령은 RDCS나 RGCS를 참조하므로 미리 설정되어 있어야 한다. 따라서 이 명령은 트랜잭션의 첫 명령으로 사용될 수 없다.
-
검색 대상 영역에 레코드가 존재하지 않는 경우 NEXT를 지정하여 이 명령을 수행하면 AT END 예외상황이 발생한다.
-
6.6.11. GET/FIND WITHIN range(CRP range)
GET/FIND FIRST 및 NEXT(CRP range) 명령어는 CRP 속성을 갖는 Range로부터 레코드를 검색한다. 레코드가 검색되는 순서는 실제로 해당 레코드들이 Range 내부에 저장된 물리적인 순서와 동일하다.
-
Format
{GET|FIND} {FIRST|NEXT} {record-name|unique-name-1|RECORD} WITHIN {range-name|unique-name-2} {RANGE|SUBRANGE} [USING CRP] [AT END GO TO procedure-name].-
SUBRANGE가 지정된 경우 검색 대상이 되는 영역은 Subrange 이다. RANGE가 지정된 경우는 Range 전체가 검색 대상이 된다.
-
AT END 구문이 지정된 경우 검색 대상 영역의 모든 레코드가 검색되어 더 이상 검색할 레코드가 존재하지 않는 경우 지정된 프러시저가 호출된다.
-
USING CRP 구문이 지정되면 검색영역의 범위를 제어하는 정보인 CRP 값이 변경된다. 지정되지 않은 경우에는 CRP 값은 변경되지 않는다.
-
-
General rules
-
record-name이나 unique-name에 지정된 레코드 타입은 READY 명령어를 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
검색할 레코드 타입을 명시적으로 지정할 필요는 없다. 명시적으로 지정하지 않는 경우에는 레코드 타입 이름 대신에 RECORD라고 지정한다.
-
Range가 Subrange로 나뉘어져 있지 않은 경우에는 SUBRANGE를 지정할 수 없다.
-
FIRST와 SUBRANGE 구문이 모두 지정된 경우 검색할 Subrange를 선택하기 위한 위치 키 값이 사용자 작업 영역에 설정되어 있어야 한다.
-
range-name이나 unique-name-2에 지정된 Range는 SCHEMA 명령어의 RANGE 항목에 의해 CRP 속성을 갖도록 정의되어 있어야 한다.
-
USING CRP 구문과 record-name이나 unique-name-2에 레코드 타입을 함께 지정할 수 있다. 이 경우 지정된 레코드 타입은 SCHEMA 명령의 해당 RANGE 항목의 최상위 오너 레코드로 정의되어 있어야 한다(range record 혹은 representative record 라고 부른다).
-
NEXT를 지정하는 경우 이 명령은 RDCS나 RGCS를 참조하므로 미리 설정되어 있어야 한다. 따라서 이 명령은 트랜잭션의 첫 명령으로 사용될 수 없다.
-
USING CRP 구문이 지정된 경우 RDCS나 RGCS에 대한 참조 없이 CRP가 가리키는 레코드가 검색된다. NEXT가 지정되어 있는 경우에도 USING CRP 구문이 지정된 경우 검색되는 레코드는 CRP에 의해 결정된다.
-
6.6.12. GET/FIND CURRENT
GET/FIND CURRENT 명령어는 PGCS가 가리키는 레코드를 검색한다. 이 검색 방법은 모든 레코드 타입 및 엔트리 기법에 대해서 사용될 수 있다.
GET이나 FIND 명령어를 이용하여 레코드를 검색하는 경우 실제로 레코드가 저장된 물리적인 위치를 나타내는 값이 PGCS에 반환된다. 이 값을 다른 곳에 저장해 두었다가 필요할 때 PGCS에 설정한 후에 이 명령을 실행하면 전에 검색했던 레코드를 다시 검색할 수 있다.
-
Format
{GET|FIND} CURRENT.-
PGCS에 기존에 레코드를 검색했을 때 반환된 값을 설정한 후에 이 명령을 실행해야 한다.
-
6.7. MODIFY
데이터베이스에 저장된 레코드의 내용을 변경한다. 지정된 레코드 타입의 RDCS에 의해 가리켜지는 레코드의 내용이 변경된다.
-
Format
MODIFY {record-name|unique-name}.-
레코드의 내용을 변경할 레코드 타입 이름을 record-name이나 unique-name에 지정한다.
-
record-name이나 unique-name에 지정된 레코드 타입의 RDCS가 가리키는 레코드의 내용이 변경된다.
-
-
General rules
-
record-name이나 unique-name에 지정된 레코드 타입은 READY 명령어를 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
인덱스 엔트리 키, 랜덤 엔트리 키 및 위치 키 값은 변경될 수 없다.
-
중복된 정렬 키 값을 허용하지 않는 정렬된 세트 타입에 대해서, 중복 키 값을 야기시키는 변경은 수행되지 않는다.
-
정렬된 세트 타입의 정렬 키 값은 변경 가능하다. 다만, 해당 세트 타입의 정렬 키를 구성하는 모든 데이터 항목(item)이 READY할 때에 지정된 서브스키마에 포함되어 있어야 한다.
-
중복된 확장 인덱스 키 값을 허용하지 않는 확장 인덱스에 대해서, 확장 인덱스 키 값의 중복을 야기하는 변경은 수행되지 않는다.
-
확장 인덱스 키 값의 변경은 가능하다. 다만, 확장 인덱스의 확장 인덱스 키를 구성하는 키를 구성하는 모든 데이터 항목(item)이 READY할 때에 지정된 서브스키마에 포함되어 있어야 한다.
-
압축된 데이터 항목의 크기 변경을 허용하는 방법에는 2가지가 있다.
-
첫 번째는 SCHEMA 명령의 RANGE 항목(entry)에 DIVIDED 절을 지정하는 것이다.
-
두 번째는 RANGE 항목의 TYPE 절에 RELOCATION을 지정하는 것이다.
-
이외의 Range에 대해서는 압축된 데이터 항목의 크기를 늘릴 수 없다. (미지원)
-
가변형 레코드의 내용을 변경하는 경우 애플리케이션은 변경할 데이터 자체와 해당 레코드에 대한 제어 정보를 사용자 작업 영역에 설정해주어야 한다. (미지원)
-
가변길이 레코드의 길이 변경을 허용하는 방법에도 2가지가 있다.
-
첫 번째는 SCHEMA 명령의 RANGE 항목(entry)에 DIVIDED 절을 지정하는 것이다.(미지원)
-
두 번째는 RANGE 항목의 TYPE 절에 RELOCATION을 지정하는 것이다. (미지원)
-
-
가변길이 레코드를 변경하는 경우 애플리케이션은 변경할 데이터 자체와 해당 레코드의 길이를 나타내는 제어 정보를 사용자 작업 영역에 (user work area)에 설정해주어야 한다. (미지원)
-
6.8. STORE
데이터베이스에 하나의 레코드를 저장한다. 하나의 STORE 명령어를 통해서 레코드의 저장과 해당 레코드를 멤버 레코드로서 세트에 연결하는 작업을 한번에 실행하도록 지정할 수 있다.
-
Format
-
Format-1
STORE {record-name|unique-name-1} TO {set-name|unique-name-2} AT END GO TO procedure-name. -
Format-2
STORE {record-name|unique-name-1} [TO {{{set-name|unique-name-2} {NEXT|PRIOR|integer|AT unique-name-3]}...|ALL}].-
레코드 타입 이름을 record-name이나 unique-name-1에 지정한다.
-
세트 타입 이름을 set-name이나 unique-name-2에 지정한다.
-
NEXT, PRIOR, integer, 혹은 AT unique-name-3을 이용해서 레코드가 세트에 연결될 때의 연결 위치를 지정한다.
-
레코드가 연결될 세트 타입을 명시적으로 지정하려는 경우 Format-1을 사용한다(지정된 세트 구조가 CIRCULAR 타입인 경우에는 레코드는 적어도 하나의 세트에는 연결되어 있어야 한다).
-
STORE 명령어로 리스트 구조 세트에 레코드를 저장하고 연결하는 경우 멤버를 저장할 수 있는 범위를 벗어나는 경우에는 AT END 절에 지정된 프러시저가 호출된다.
-
정수값(integer)으로 STORE일 경우에 저장하는 레코드를 세트에 연결할 때 정수값(integer)으로 연결 위치를 지정하기 위해서는 Format-2를 사용한다. 이 경우 set-name이나 unique-name-2로 지정된 세트 타입은 리스트 구조여야 한다. (미지원)
-
NEXT나 PRIOR를 지정하여 연결 위치를 지정하기 위해서는 Format-2를 사용한다. 이 경우 set-name이나 unique-name-2로 지정된 세트 타입은 링 구조여야 한다.
-
unique-name-3에는 alphanumeric 혹은 numeric 변수가 지정될 수 있고 각각의 경우 다음과 같이 처리된다.
-
alphanumeric 변수이고 링 구조 세트인 경우 그 길이는 1이어야 한다. 이 변수에 지정 가능한 값은 N, P, 공백 값이다. N은 NEXT를 의미하고, P는 PRIOR를 의미한다. 공백이 지정된 경우 시스템은 연결 위치를 사용자가 지정하지 않은 것으로 처리한다.
-
numeric 변수이고 리스트 구조 세트인 경우 부호형 4자리 숫자(signed 4-digit number)형으로 정수 값을 가져야 한다. (미지원)
-
-
TO ALL을 지정하면 저장하려는 레코드 타입을 멤버 레코드로 갖는 모든 세트에 레코드를 연결한다(READY할 때에 지정된 서브스키마에 포함된 세트 타입 중에서 저장하려는 레코드를 멤버로 하는 모든 세트 타입을 의미한다).
-
-
-
General rules
-
record-name이나 unique-name-1에 지정되는 레코드 타입은 READY 명령을 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
set-name이나 unique-name-2에 지정되는 세트 타입은 READY 명령을 실행할 때 지정된 서브스키마에 포함되어 있어야 한다.
-
record-name이나 unique-name-1에 지정되는 레코드 타입은 스키마에 정의되어 있어야 하고 해당 레코드 타입은 set-name이나 unique-name-2에 지정된 세트의 멤버 레코드로 정의되어 있어야 한다. 레코드는 STCS가 가리키는 Set occurrence에 연결된다.
-
저장하는 레코드는 특정 세트 상에서 연결되는 위치는 다음과 같으며 이는 TO 구문에 의해 지정된다.
-
링 구조 세트에 대해서 NEXT(혹은 PRIOR)가 지정된 경우 연결 위치는 STCS가 가리키는 위치의 바로 다음(혹은 이전) 위치이다. STORE 명령어의 TO 구문에 의해 지정되는 연결 위치 지정은 스키마에 정의된 기본 연결 위치 지정보다 우선한다.
-
리스트 구조 세트에 대해서 정수값이 지정된 경우 주어진 정수값에 해당하는 위치가 연결 위치가 된다. (미지원)
-
unique-name-3이 numeric 변수인 경우는 위의 정수값이 지정된 경우와 동일하게 처리된다. (미지원)
-
연결 위치가 지정되지 않았거나 TO ALL이 지정된 경우 링 구조인 경우 레코드는 SCHEMA 명령어의 SET 부항목(subentry)의 INSERTION 구문에 지정된 기본 연결 위치에 연결된다.
-
NORMAL 리스트 구조에서는 STCS가 가리키는 위치의 다음 위치에 연결된다.
-
CIRCULAR 리스트 구조에서의 레코드 연결 위치는 축 세트 타입(axis set type)이 가리키는 위치가 사용된다.
-
-
가변형 레코드를 저장하는 경우 애플리케이션은 저장할 데이터 자체와 해당 레코드에 대한 제어 정보를 사용자 작업 영역에 설정해주어야 한다. (미지원)
-
STORE 명령어는 레코드를 저장하고 해당 레코드를 세트에 연결하기 위해서 STCS를 참조한다. 때문에 모든 세트 타입의 STCS들은 레코드가 연결될 Set occurrence를 가리키고 있어야 한다.
-
예외적으로 시스템 세트 타입의 멤버 레코드를 저장하고 연결하는 경우에는 시스템 세트 타입의 Set occurrence는 유일하기 때문에 해당 시스템 세트 타입의 STCS가 설정되어 있지 않아도 된다. (미지원)
-
인덱스 엔트리 레코드 타입 이나 랜덤 엔트리 레코드 타입의 레코드를 저장하는 경우 인덱스 엔트리나 랜덤 엔트리의 키로 사용되는 데이터 항목이 READY할 때에 지정된 서브스키마에 포함되어 있어야 한다.
-
Range가 Subrange로 나뉘어 있는 경우 오너 레코드를 저장하거나 CSP(Current Store Point)에 의한 멤버 레코드를 저장하려면 위치 키가 사용자 작업 영역에 설정되어 있어야 한다(Range 오너 레코드의 위치 키 값을 사용자 작업 영역에 저장해야 한다).
-
인덱스 엔트리 레코드나 랜덤 엔트리 레코드를 저장하기 위해서는 사용자 작업 영역에 엔트리 키 값을 설정해야 한다.
-
사용자 랜덤 엔트리 레코드를 저장하기 위해서는 사용자 랜덤함수를 이용하여 계산된 논리 페이지 번호를 FCOM 영역의 PAGENO 변수에 설정해야 한다.
-
정렬 키를 지정하여 레코드를 저장하기 위해서는 해당 정렬 키의 값을 사용자 작업 영역에 설정해야 한다.
-
가변 길이 레코드를 저장하는 경우 애플리케이션은 저장할 데이터 자체와 해당 레코드의 길이 정보를 나타내는 제어 정보를 사용자 작업 영역에 설정해주어야 한다.
-
7. 에러 코드
애플리케이션은 데이터베이스 조작 명령을 실행한 후에 요청한 명령이 정상적으로 실행되었는지 여부를 확인해야 한다. 데이터베이스에 의한 명령 실행의 처리 결과는 FCOM 통신 영역의 DBSCB와 DBECB에 반환된다.
반환된 DBSCB와 DBECB의 값에 따라서 예외상황 및 에러의 심각도는 다음과 같이 분류된다.
| 심각도 | DBSCB 값 | DBECB 값 |
|---|---|---|
Normal termination |
DBSCB=0 |
DBECB=0 |
Minor error |
DBSCB!=0 |
DBECB=0 |
Moderate error |
DBSCB!=0 |
DBECB!=0 |
Severe error |
DBSCB=0 |
DBECB!=0 |
-
Minor and Moderate errors
사소한 에러나 중간 정도 수준의 에러가 발생한 경우 데이터베이스는 트랜잭션을 강제 중단하지 않고 애플리케이션으로 실행 제어를 반환한다. 애플리케이션은 발생한 에러의 구체적인 종류에 따라서 트랜잭션을 계속하거나 중단할 수 있다.
-
Severe errors
심각한 수준의 에러가 발생하면 데이터베이스는 진행 중인 트랜잭션을 취소하고 애플리케이션으로 실행 제어를 반환한다. 일반적으로 심각한 에러가 발생한 경우 애플리케이션은 비정상적으로 종료한다.
심각한 에러는 DBECB의 값에 따라서 다음과 같이 분류된다.
DBECB 값 설명 20 ~ 29
처리할 레코드 및 세트에 관련된 불일치
30 ~ 39
기밀성 보호 오류
40 ~ 49
자원 할당 문제
50 ~ 59
데이터베이스 동작 문제
60 ~ 69
자원 접근 오류
70 ~
분산 데이터베이스 동작상의 문제
88
교착상태 발생
99
치명적인 오류 혹은 데이터베이스가 망가짐
7.1. 세부 에러 코드
다음은 에러의 심각도별 반환되는 에러 코드를 설명한다.
DBSCB 및 DBECB에 반환되는 에러 코드는 각각 2자리씩 총 4자리의 십진수로 이루어져 있다. 다음에 나열된 에러 코드의 앞의 2자리는 DBSCB의 값이고 뒤의 2자리는 DBECB의 값이다. 즉, 0111은 DBSCB=01이고 DBECB=11임을 의미한다.
-
No error
에러 코드 설명 0000
Normal termination.
명령의 정상적인 종료이다.
-
Minor error
에러 코드 설명 0100
Failed logical connection.
논리적으로 결합된 레코드 검색에 실패했다.
0200
Previously disconnected set found.
레코드를 세트로부터 연결해제 하는 과정에서 이미 연결해제 되어있는 세트가 존재한다. 연결해제 요청된 모든 세트로부터 레코드는 성공적으로 연결 해제된 상태이다.
0300
Record for deletion owns a member.
삭제 대상인 레코드 하위에 멤버 레코드가 있는 경우에 발생한다. 레코드의 삭제는 이루어지지 않은 상태이다.
0400
Orphan record in a logical structure.
레코드를 세트로부터 연결 해제한 결과로 해당 레코드를 계층적인 검색 방법(즉, 세트를 이용한 검색 방법)으로 추후에 다시 검색할 수 없게 되는 경우 발생한다. 세트를 이용한 검색 외에 엔트리 검색 방법으로 레코드에 다시 검색할 수 있는 경우는 해당하지 않는다. 반환시 연결해제는 이미 이루어진 상태로 해당 레코드에 대한 추가적인 처리가 필요하다(다른 세트에 연결을 한다던가 PGCS를 기억해두고 나중에 처리할 수 있다).
-
Moderate error
에러 코드 설명 0111
Logical connection failure and set end condition.
0100과 1111 예외상황이 동시에 발생했다.
1111
End condition on a set or an area.
세트의 맨 끝에서 세트 순차 검색으로 인해서 오너 레코드가 검색된 경우 발생한다. 혹은 Range, 인덱스, 확장 인덱스 순차 검색 및 DUPLICATE 검색할 때 더 이상 검색될 결과가 존재하지 않는 경우에 발생한다.
1212
No records found by position.
탐색 대상인 세트상의 지정된 위치나 방향에 레코드가 존재하지 않는 경우에 발생한다. 혹은 확장 인덱스상의 지정된 방향에 레코드가 존재하지 않는 경우에 발생한다.
1313
No records found by key value.
주어진 키 값에 의한 ANY 검색할 때 해당하는 레코드가 존재하지 않는 경우에 발생한다.
1414
Duplicate key values.
중복 키 값을 허락하지 않는 정렬 세트에 중복 키 값을 갖는 멤버 레코드를 연결하는 경우에 발생한다. 멤버 레코드와 세트의 연결은 수행되지 않는다. 유사한 상황으로, 중복 키 값을 허락하지 않는 엔트리 레코드 타입의 레코드를 저장할 때 이미 동일한 엔트리 키 값을 갖는 레코드가 존재하는 경우에 발생한다. 역시 중복 엔트리 키 값을 갖는 레코드의 저장은 수행되지 않는다.
1515
Range having a CRP but no storage area.
CRP-Range에 레코드를 저장할 수 있는 공간이 부족한 경우에 발생한다. 레코드의 저장은 수행되지 않는다. 레코드를 저장하기 위해서는 GET USING CRP 명령어를 이용하여 레코드를 읽어내어 새로운 레코드가 저장될 공간을 마련해주어야 한다.
1616
Set already connected.
레코드를 세트에 연결하는 과정에서 이미 레코드가 세트에 연결되어 있는 경우에 발생한다. 혹은 리스트 구조 세트의 특정 위치에 레코드를 연결할 때 이미 해당 위치에 다른 레코드가 연결되어 있는 경우에도 발생한다.
1717 (미지원)
Compressed data item, variable-type record or variable-length record update failure.
현재 데이터베이스에 저장된 레코드가 차지하는 공간보다 더 큰 공간을 차지하는 내용으로 레코드의 내용을 갱신하는 경우에 레코드를 저장하는 Range가 이런 경우를 허락하지 않도록 정의되어 있는 경우에 발생한다. 레코드 내용의 갱신은 수행되지 않는다. 갱신을 허락하기 위해서는 SCHEMA 명령을 사용하여 해당 Range의 속성을 변경해야 한다.
1818
Orphan record storage.
STORE 명령어의 실행과정에서 레코드를 저장은 성공적으로 수행되었지만 세트에 연결하는 과정에 실패하여 고아(orphan) 레코드가 생성된 경우에 발생한다. 0400 상황과 비슷하지만 0400은 DISCONNECT 명령에 의한 고아 레코드가 생성된 경우이며 1818은 레코드의 저장 시점부터 고아 레코드가 생성된다는 점에서 다르다.
-
Sever errors
에러 코드 설명 0021
Error in instruction issuance sequence.
데이터베이스 조작 명령의 순서가 잘못 프로그램 되어있거나 명령의 실행에 사용되는 간접적인 인자들(각종 현재상태들)이 제대로 설정되어 있지 않은 경우에 발생한다. 명령은 수행되지 않는다.
0022
Virtual database recognition error.
응용프로그래머의 착오에 의해서 데이터베이스 구조상으로 실행할 수 없는 명령이 요청된 경우에 발생한다.
0023
List set type member position error.
리스트 구조 세트의 존재하지 않는 멤버 위치가 지정된 경우 발생한다.
0024
PGCS specification error.
애플리케이션의 현재상태(PGCS)가 올바르게 설정되어 있지 않은 경우 발생한다. 이 예외상황은 0021이나 0022 예외상황 이후에 명확한 조치가 취해지지 않은 경우에 발생하기 쉽다.
0025
Specification inconsistent with a storage structure.
서로 다른 Subrange에 존재하는 세트들 사이의 연결이 금지된 경우에 이러한 연결을 형성하도록 하는 명령이 요청된 경우에 발생한다. 존재하지 않는 논리 페이지나 위치키(location key)가 명령에 지정된 경우에 발생한다. 확장 인덱스를 이용하는 검색 시에 확장 인덱스 Subrange가 데이터베이스의 Range나 Subrange와 연관되어 있지 않은 경우 발생한다.
0026
Invalid index key value specification.
허락된 최대값의 범위에 있지 않은 인덱스 키 값이 지정된 경우에 발생한다. 인덱스가 생성되지 않은 상태에서 인덱스 엔트리 레코드를 저장하는 경우에도 발생한다.
0027
Attempt made to edit fixed data in a record.
인덱스 엔트리 키, 랜덤 엔트리 키, 위치 키와 같이 변경할 수 없는 데이터 항목의 값을 갱신하려는 경우에 발생한다.
0028
Duplicate key values.
중복 키 값을 허락하지 않는 정렬 세트에 중복 키 값을 갖는 멤버 레코드를 연결하는 경우에 발생한다. 명령에 하나의 세트가 명시적으로 주어진 경우에는 1414가 발생한다. 이 경우는 연결대상이 명시적으로 주어지지 않은 경우로 문제를 일으키지 않는 일부 세트들에 대해서는 연결이 수행된 상태일 수 있다. 유사한 상황으로, 중복 키 값을 허락하지 않는 확장 인덱스 엔트리 레코드 타입의 레코드를 저장할 때 이미 동일한 엔트리 키 값을 갖는 레코드가 존재하는 경우에 발생한다. 역시 문제를 일으키지 않는 일부 확장 인덱스에는 이미 확장 인덱스 레코드가 저장된 상태일 수 있다.
0031
ADL definition(SUBSCHEMA or PED) error or application program error.
-
가상 데이터베이스(virtual database or subschema)에 포함되지 않은 레코드에 대한 접근을 시도한 경우이다.
-
PED 명령의 INCLUSION SCHEMA 구문에 포함되지 않은 데이터베이스(schema)에 대한 접근을 시도한 경우이다.
-
가변형 레코드의 키 데이터 항목이 필요한 명령을 키 데이터 항목을 선택하지 않고 요청한 경우 0022나 0024 예외상황 이후에 적절한 조치를 취하지 않은 경우에 이 예외상황이 발생하기 쉽다.
0032
Prohibited DML issued.
가상 데이터베이스(virtual database or subschema)에 포함된 레코드나 세트이지만 금지된 종류의 명령이 요청된 경우 발생한다.
0041
Prime area full.
레코드를 저장할 Range나 Subrange의 기본할당 영역의 사용 가능한 저장 공간의 크기가 충분하지 않아서 레코드를 저장할 수 없는 경우에 발생한다. 혹은 확장 인덱스의 기본할당 영역에 확장 인덱스 레코드를 저장할 때 이를 저장할 수 있는 저장 공간이 부족한 경우에 발생한다. 레코드나 확장 인덱스 레코드의 저장은 수행되지 않는다.
0042
Database overflow area full.
Range나 Subrange의 오버플로우 영역에 레코드를 저장하려는 경우에 남은 저장 공간의 크기가 충분하지 않아서 레코드를 저장할 수 없는 경우에 발생한다.
0043
Prime area disconnected.
데이터베이스의 기본할당 영역에 레코드를 저장하려 시도했으나 기본할당 영역에 추가 할당된 영역이 연결되어 있지 않아서 레코드를 저장할 수 없는 경우에 발생한다. 혹은 확장 인덱스의 기본할당 영역에 확장 인덱스 레코드를 저장할 때 확장 인덱스의 기본할당 영역에 추가 할당된 영역이 연결되어 있지 않아서 확장 인덱스 레코드를 저장할 수 없는 경우에 발생한다. 레코드나 확장 인덱스 레코드의 저장은 수행되지 않는다.
0044
Database overflow area disconnected.
오버플로우의 영역에 레코드를 저장하려는 경우에 해당 오버플로우 영역에 추가 할당된 영역이 연결되어 있지 않아서 레코드를 저장할 수 없는 경우 발생한다.
0051
Database operation error.
데이터셋, 베타적 제어 접근모드, 인덱스 및 확장 인덱스와 같이 데이터베이스가 정상적으로 동작하기 위한 환경에 문제가 있어서 정상적인 처리를 할 수 없는 경우에 발생한다.
0061
Input-output(I-O) access failure.
데이터베이스 명령 실행 중에 수행되는 입출력 동작이 실패하여 정상적인 처리를 할 수 없는 경우에 발생한다.
0062
Access attempted on an area closed on account of an error.
다른 에러나 예외에 의해서 사용할 수 없게 해제된 자원에 접근하는 경우에 발생한다.
0071
Remote database access, communication processing error.
원격 데이터베이스에 접근하기 위한 통신 처리에 문제가 있는 경우에 발생한다.
0072
Remote database, operation error on server-side.
원격 데이터베이스에 접근 시 원격지의 서버 시스템이 동작상의에러를 발견한 경우에 발생한다.
-