OpenFrame NDB 구조와 기능
본 장에서는 OpenFrame NDB의 기본 구조 및 기능에 대해 기술하면서, Fujitsu AIM/DB와 다른 구조에 대해서 비교 설명한다.
1. NDB 구조
NDB는 네트워크 모델을 기반으로 한 데이터베이스로 Fujitsu Mainframe에서 이용되는 AIM/DB의 리호스팅을 위해 제작되었기 때문에 기본적으로는 Fujitsu AIM/DB의 기능과 구조를 따른다. 그러나 NDB는 RDB 기반으로 만들어졌기 때문에 AIM/DB와 구조가 조금 다르다.
NDB는 Logical Structure를 데이터베이스의 DDL과 DML의 SQL 조합으로 설계되었고, Physical Structure는 DBMS에 위임하여 처리하도록 구성되어있다. 여기서는 AIM/DB의 구조를 토대로 NDB의 구조를 설명한다.
AIM/DB의 구조는 크게 3가지로 나누어진다.
| 구분 | 설명 |
|---|---|
Logical Structure |
데이터 항목간의 논리적 관계를 기술한다. |
Locative Structure |
데이터를 논리적으로 어디에, 어떤 방식으로 저장할지를 기술한다. |
Physical Structure |
데이터가 물리적으로 저장되는 공간에 대해 기술한다. |
이외에 애플리케이션에서 데이터베이스들을 어떻게 바라볼지를 결정하는 Virtual Logical Structure가 있다. NDB 구조에 대한 자세한 내용은 다음 절에서 설명한다.
1.1. 스키마/서브스키마
데이터베이스를 이용하기 위해서 데이터베이스를 기술하는 방법이 필요하다. NDB에서는 AIM/DB의 데이터베이스 기술방법인 스키마와 서브스키마를 동일하게 사용한다. 스키마와 서브스키마는 ADL(AIM Description Language)로 표현할 수 있다.
| 구분 | 설명 |
|---|---|
스키마 |
실제 데이터베이스의 구조인 Logical Structure, Locative Structure, Physical Structure를 기술한다. |
서브스키마 |
데이터베이스 관리자가 데이터베이스를 바라보는 뷰(view)인 Virtual Logical Structure를 기술한다. 하나의 스키마는 하나의 데이터베이스만을 기술할 수 있으며, 하나의 서브스키마는 동시에 여러 개의 데이터베이스를 기술할 수 있기 때문에 여러 개의 데이터베이스를 포함한다. |
|
ADL을 이용한 스키마와 서브스키마 작성 방법 및 문법은 Fujitsu사의 “OS IV AIM ADL REFERENCE MANUAL(V20L10)”을 참고한다. |
2. Logical Structure
Logical Structure는 데이터베이스에 저장되는 레코드와 각 레코드들간의 관계 및 저장 형태에 대해 기술한다. Logical Structure를 구성하는 가장 기본적인 요소는 레코드와 세트이다. 이외에 논리 연결(Logical connection) 등의 특징이 있다. NDB는 Logical Structure를 RDB의 DDL, DML의 SQL의 조합으로 설계되었다.
2.1. 레코드
레코드(Record)는 데이터베이스를 접근할 때 가장 기본이 되는 데이터의 단위이다. 실제 의미가 있는 데이터를 담고 있는 정보의 단위를 레코드 또는 Record occurrence라 하고, 이 레코드들의 집합을 레코드 타입이라고 한다.
레코드 타입은 데이터 항목들로 구성된다. 각 데이터 항목에는 고유한 이름이 붙여지며, alphabet, numeric, alphanumeric과 같은 데이터 속성을 가진다. 레코드 타입 역시 레코드 타입의 이름, 엔트리 메소드 등 고유한 속성을 가지고 있다.
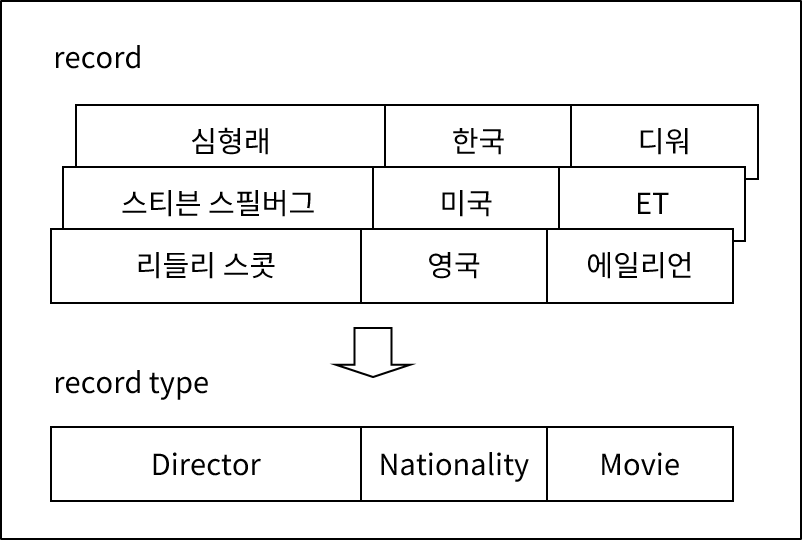
NDB에서 레코드 타입은 데이터베이스의 테이블로 구성된다. 레코드는 테이블의 Row로 구성되며, 데이터 항목은 테이블의 column으로 구성된다.
-
OCCURRENCE ID
레코드 테이블에 저장되는 개별 레코드 값(로우)에는 레코드를 식별하기 위한 8바이트 ID 값인 OCCURRENCE ID(OCC_ID)가 함께 포함되며, 이 값은 NDB 프로그램에서 레코드를 식별하기 위한 위치 정보인 PGCS 등으로 활용된다. OCCURRENCE ID는 레코드 타입을 식별하기 위한 ID와 개별 레코드 값을 저장할 때 RDB 시퀀스를 통해 부여되는 ID가 조합되어 결정되며, 따라서 각 레코드 타입 당 최대로 저장할 수 있는 레코드의 개수는 4바이트 부호없는 정수의 최댓값인 4294967295이다.
OCCURRENCE ID 중 레코드 값의 ID는 시퀀스를 통해 부여되기 때문에 기존 레코드를 삭제해도 삭제된 ID 값은 재사용되지 않는다. 따라서 최댓값에 근접할 경우 기존 레코드를 추출하고 다시 저장하는 재정렬 작업이 필요하다.
-
엔트리 메소드
NDB는 기본적으로 세트라는 계층적 구조를 따르고 있다. 따라서 각 레코드는 세트에 의한 계층 구조로 접근이 가능하다. 하지만 이 수직 구조의 최상위에 존재하는 레코드들은 세트를 이용하여 접근할 수 있는 방법이 없기 때문에 이러한 레코드들을 접근하기 위한 방법으로 엔트리 메소드가 존재한다.
NDB에서 지원하는 엔트리 메소드 종류는 다음과 같이 5가지가 있다.
-
Index entry method
레코드 내의 필드를 선택하여 이 필드를 키로 이용해 해당 레코드 테이블에 인덱스를 생성한다. Index entry method를 이용해 레코드에 접근할 때는 인덱스 키에 해당하는 필드들의 값을 이용해 레코드 테이블에서 직접 해당 레코드를 찾는다.
-
Extended Index entry method
Index entry method와 유사하다. 역시 레코드 내의 필드를 선택하여 이 필드를 키로 이용해 해당 레코드 테이블에 인덱스를 생성한다. Extended Index entry method를 이용해 레코드에 접근할 때는 확장 인덱스 키에 해당하는 필드들의 값을 이용해 레코드 테이블에서 직접 해당 레코드를 찾는다.
Extended Index에 대한 자세한 설명은 Extended Index를 참고한다.
-
Random entry method
Random entry method는 다음 표와 같이 User random entry method와 System random entry method로 나뉜다.
구분 설명 User random entry method
애플리케이션에서 User random function을 이용해 레코드의 페이지를 직접 구하는 방식이다. 레코드 테이블의 페이지번호 컬럼을 이용하여 접근한다.
System random entry method
AIM/DB에서는 레코드 내의 필드를 선택하여 이 필드를 키로 이용해 System random function을 이용해 입력 받은 키 값이 존재하는 레코드를 찾아간다. NDB에서는 해당 키를 이용해 직접 레코드를 직접 찾아간다.
-
System entry method
시스템 세트를 이용하여 레코드에 접근하는 방법이다. 시스템 세트는 오너 레코드 타입 없이 멤버 레코드만으로 링 구조를 이루는 세트이다. 따라서 오너에 대한 레코드 접근 없이 바로 멤버 레코드에 접근이 가능하다.
-
Direct retrieval method by PGCS
레코드의 위치, 즉 PGCS(Program Current Status)라는 값을 기억해 두었다가 이 PGCS 값을 이용하여 레코드에 바로 접근하는 방법이다. 레코드 타입과 위에 열거한 다른 엔트리 메소드에 상관없이 어떤 레코드라도 PGCS를 이용해 바로 접근할 수 있다.
-
2.2. 세트
세트(Set)는 레코드 간의 관계를 나타내며, 기본적으로 두 개의 레코드 타입이 상하 관계로 구성된다.
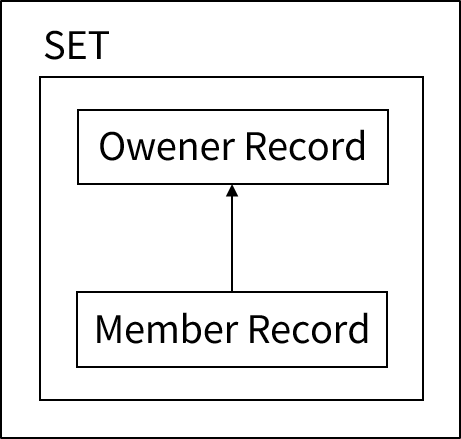
수직 관계에서 부모에 해당하는 레코드는 오너 레코드 타입이라 하고 자식에 해당하는 레코드는 멤버 레코드 타입이라고 한다. 멤버 레코드 타입으로 한 개 이상의 레코드 타입이 참여할 수 있는데 이러한 세트를 혼합 세트(mixed set)라고 부른다. 하지만 어떤 경우에든 오너 레코드 타입에는 단 하나의 레코드 타입만 올 수 있다.
레코드와 마찬가지로 세트 역시 세트의 이름, 세트에 참여하는 레코드 타입과 같은 고유의 속성을 가지고 있고 이러한 세트 형식을 일컬어 세트 타입이라고 한다.
오너 레코드 타입과 멤버 레코드 타입의 상하 관계에 의해 두 레코드 간에는 1:N의 관계가 성립된다. 오너 레코드 한 개와 멤버 레코드 여러 개로 이뤄진 레코드의 그룹을 Set occurrence라고 부른다.
Set occurrence를 구성하는 방법은 링 구조(Ring structure)와 리스트 구조(List structure)가 있다.
-
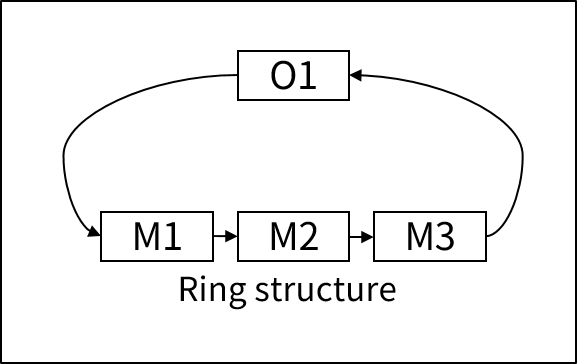
링 구조(Ring structure)
링 구조는 오너 레코드와 멤버 레코드가 링 형태로 이어져 있는 구조이다.
오너 레코드가 첫 번째 멤버 레코드를 가리키는 포인터를 가지고 있고 각 멤버 레코드는 그 다음 멤버 레코드를 가리키는 포인터를 지닌다. 그리고 마지막 멤버 레코드가 다시 오너 레코드를 가리키는 포인터를 가지고 있다.
-
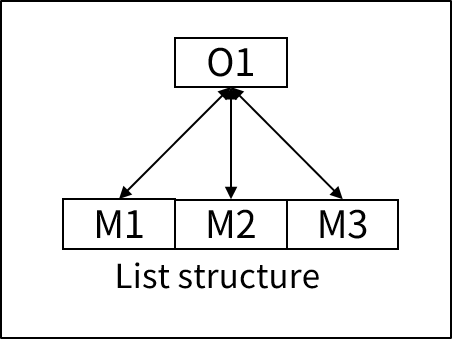
리스트 구조(List structure)
리스트 구조는 오너 레코드가 멤버 레코드를 리스트 형태로 가지고 있는 구조이다. 오너 레코드는 멤버로 참여하고 있는 모든 레코드들에 대한 포인터를 가지고 있고, 멤버 레코드는 오너 레코드를 가리키는 포인터만을 가지고 있다.
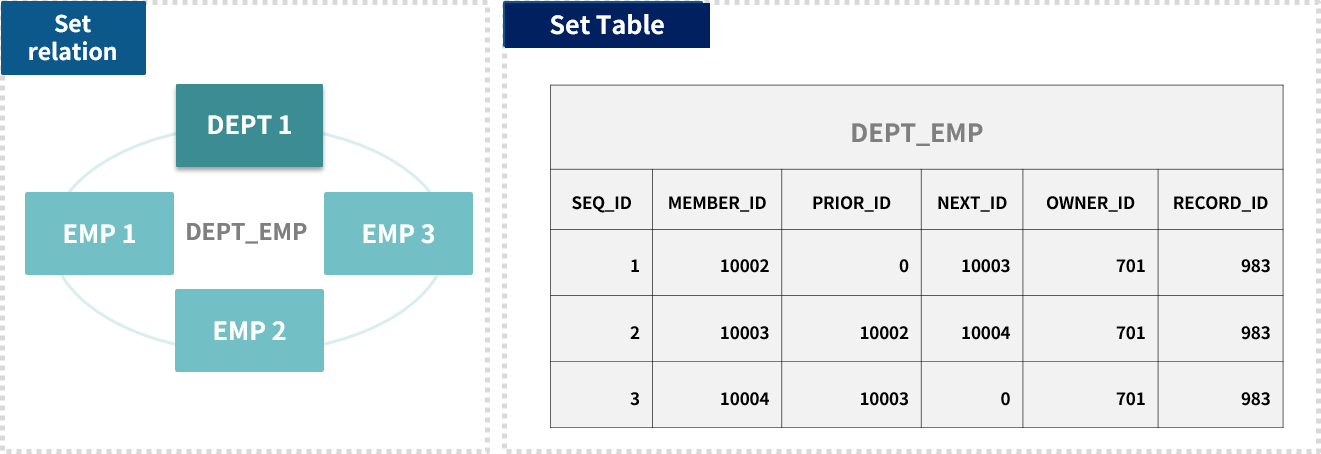
NDB에서는 Set occurrence를 RDB의 테이블로 구성하며, 각 레코드의 포인터 정보를 가지고 있다.
2.3. 논리 연결
같은 레코드 타입 내의 레코드들은 특정 필드에 대해 중복되는 값을 가질 수 있다. 이러한 중복된 필드와 중복되는 값을 갖는 레코드의 수가 많을수록 저장공간이 낭비된다.
논리 연결(Logical Connection)은 서로 다른 레코드 타입을 각 레코드에 존재하는 키를 이용하여 동시에 접근하는 것이다. 즉, 중복이 많은 필드를 새로운 레코드 타입으로 만들고 이를 기존의 레코드와 논리적으로 연결한다.
다음은 논리적으로 연결된 레코드 타입을 보여주는 그림이다.
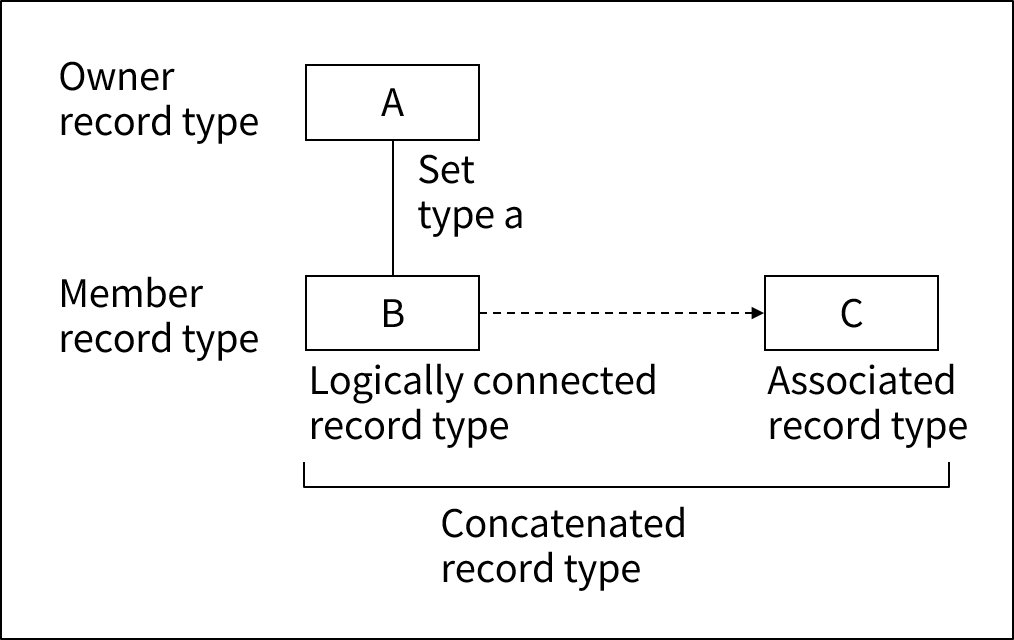
다음은 논리 연결을 기술하는데 사용되는 용어에 대한 설명이다.
| 구분 | 설명 |
|---|---|
Logically connected record type |
주축이 되는 레코드이다. |
Associated record type |
주축이 되는 레코드와 논리적으로 연결되는 레코드이다. |
Concatenated record type |
논리적으로 연결된 레코드 타입과 연합 레코드 타입의 총칭이다. |
|
위 그림의 실선은 세트(Set) 관계를 나타내고, 점선은 논리 연결 관계를 나타낸다. |
3. Locative Structure
AIM/DB에서는 Logical Structure에서 정의된 레코드들은 직접 접근 저장장치(DASD: Direct Access Storage Device)에 저장된다. 이때 레코드들을 저장하기 위해서는 페이지의 크기를 비롯하여 직접 접근 저장장치에 대한 특성을 고려해야 한다. 하지만 데이터베이스 관리자가 하드웨어의 물리적인 속성까지 고려하는 것은 불편할 뿐만 아니라 어려운 일이다.
따라서 Locative Structure라는 개념을 두어 저장공간의 물리적 특성을 고려하지 않고 논리적으로 저장 공간을 구성할 수 있다. Locative Structure에서는 어떤 레코드들이 어떤 순서로 Locative Address Space에 저장되는가를 정의한다.
Locative Structure를 정의하는 방법은 다음과 같이 2가지가 있다.
| 구분 | 설명 |
|---|---|
SLS(Single Locative Space) |
하나의 저장영역을 하나의 주소 체계로 관리한다. |
MLS(Multiple Locative Space) |
하나의 저장영역을 여러 개의 주소 체계로 관리한다. SLS에서 하나의 저장공간의 제한된 크기를 극복하기 위해 이용된다. |
NDB에서는 AIM/DB와는 달리 Logical Structure에서 정의된 레코드들이 데이터베이스의 테이블에 저장된다. 따라서 논리적으로 저장 공간을 구성할 필요가 없으며 SLS, MLS에 관계없이 저장된다.
본 안내서 상의 위치구조에 대한 내용은 SLS을 기준으로 AIM/DB의 Locative Structure의 개념과 NDB의 동작을 기술한다.
3.1. 페이지
페이지(Page)는 레코드를 저장할 수 있는 가장 작은 단위이다. 페이지는 물리 페이지와 논리 페이지로 나눌 수 있는데 한 개 이상의 물리 페이지가 모여 논리 페이지를 구성한다.
하나의 데이터셋에 존재하는 페이지들은 모두 크기가 같아야 하며, 하나의 range가 여러 개의 데이터셋에 나뉘어 저장될 때 각 데이터셋의 페이지 크기 역시 같아야 한다. 논리 페이지가 있는 주된 이유는 데이터베이스의 성능향상을 위해서다. 데이터베이스에 대한 I/O가 이루어질 때 물리 페이지 단위가 아닌 논리 페이지 단위로 실행하면 인접한 레코드에 대해 빠르게 접근할 수 있다.
NDB는 AIM/DB와는 달리 한 레코드가 테이블의 Row로 구성되기 때문에 레코드 단위로 I/O가 수행된다.
|
각 레코드 테이블에는 페이지 번호 컬럼이 존재하여 User random entry method를 사용하는 경우에 이용된다. |
3.2. Range
레코드가 저장되는 Logical address space가 특성과 접근 방법에 따라 독립적인 영역으로 나뉘어진 영역을 Range라고 한다. Range는 논리 페이지로 구성된다. 따라서 Range의 크기는 논리 페이지의 개수와 논리 페이지 내의 물리 페이지 개수와 크기로 결정된다.
Range는 prime 영역과 overflow 영역으로 나누어 진다. 기본적으로 레코드를 저장할 때, prime 영역을 이용하지만 prime 영역 내의 특정 논리 페이지에 새로운 레코드를 저장해야 할 필요가 있을 때, 이미 해당 논리 페이지가 가득 차 있다면 overflow 영역에서 하나의 물리 페이지를 가져와 사용할 수 있다. 이때 prime 영역의 해당 논리 페이지는 새로 추가된 물리 페이지를 포함하여 논리 페이지를 재구성하게 된다.
NDB에서는 Range는 포함되는 레코드 타입 정보를 메타로 관리하여, Range 단위의 조회시 해당하는 레코드 타입 정보를 이용하여 처리할 수 있다. 따라서 prime 영역이나 overflow 영역을 구분하여 처리하지 않는다.
Range는 다음의 2가지 타입으로 나누어 진다.
| 구분 | 설명 |
|---|---|
Entry Range |
Entry record(Index entry method, Extended index entry method, Random entry method, System entry method에 해당하는 레코드)가 저장되는 Range이다. |
Normal Range |
Normal record가 저장되는 Range이다. |
3.3. Subrange
Range는 Subrange라는 더 작은 단위로 나누어질 수 있다. 같은 레코드 사이에서도 특성을 고려하여 서로 다른 Subrange에 저장할 수 있다. 예를 들면 도시라는 필드를 가진 레코드가 있다고 가정한다. 도시 필드에 “서울” 값이 들어간 레코드들과 “경기도” 값이 들어간 레코드들을 따로 저장할 때 Range를 Subrange로 나누어 저장할 수 있다.
Subrange의 크기 역시 Range와 마찬가지로 논리 페이지의 개수, 논리 페이지를 구성하는 물리 페이지의 개수와 크기로 결정된다. Range를 Subrange로 나누면 Subrange에서 prime 영역, overflow 영역, 보안 및 접근에 관한 설정을 할 수 있으며 Range에는 prime 영역을 제외한 overflow 영역 및 기타 설정을 할 수 있다.
Range를 Subrange로 나눌 때는 Range에 저장되는 최상위 레코드 내에 있는 필드들을 Location key로 지정해야 한다. 새로운 레코드가 저장될 때, 이 Location key에 따라 저장할 Subrange가 결정된다. Location key는 스키마의 range entry에 기술하고 각 Subrange가 저장할 레코드에 대한 Location key 값은 스키마의 Subrange entry에 기술한다.
NDB에서 Subrange는 Range와 마찬가지로 prime 영역, overflow 영역으로 나누어 저장하지 않는다. 레코드 테이블의 Location key에 해당하는 필드의 값에 따라 Subrange 단위의 구분을 처리할 수 있다.
3.4. Location Set
Location Set을 설명하기 위해 record type A와 record type B가 하나의 세트로 구성되어 있는 경우를 가정한다.
A가 오너 레코드 타입이고 B가 멤버 레코드 타입이다. 이때 record A는 range A에 저장되고 record B는 range B에 저장된다. 하나의 Set occurrence를 접근할 때, 각 레코드가 인접해 있는 것이 데이터베이스의 성능향상에 도움이 된다. 따라서 멤버 레코드인 B가 range B에 저장될 때 같은 Set occurrence에 속하는 레코드는 같은 논리 페이지에 저장함으로써 성능을 향상시킬 수 있다. 이러한 세트를 일컬어 Location Set이라고 한다.
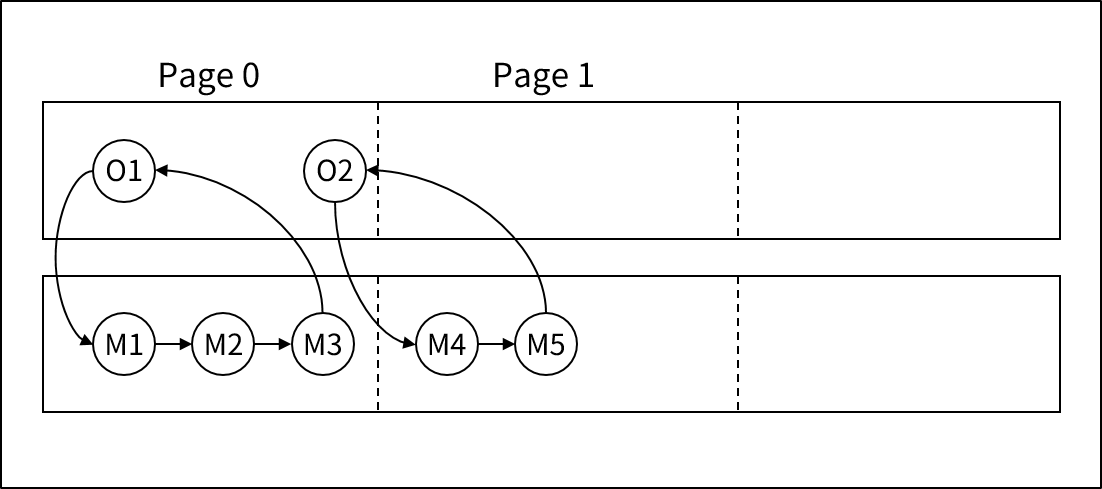
Location Set은 External Location Set과 Internal Location Set이 있다. External Location Set은 위에 설명한 예에 해당된다. Internal Location Set은 오너 레코드 타입과 멤버 레코드 타입이 같은 range에 저장되는 경우 멤버 레코드는 오너 레코드가 저장된 논리 페이지에 같이 저장되는 것이 효율적이다.
NDB는 세트를 데이터베이스의 테이블로 구성하여, Set occurrence를 접근할 때 SQL을 구성하여 접근한다. 따라서 Location Set으로 구성하지 않고도 Set occurrence를 빠르게 접근할 수 있으며, Location Set는 지원하지 않는다.
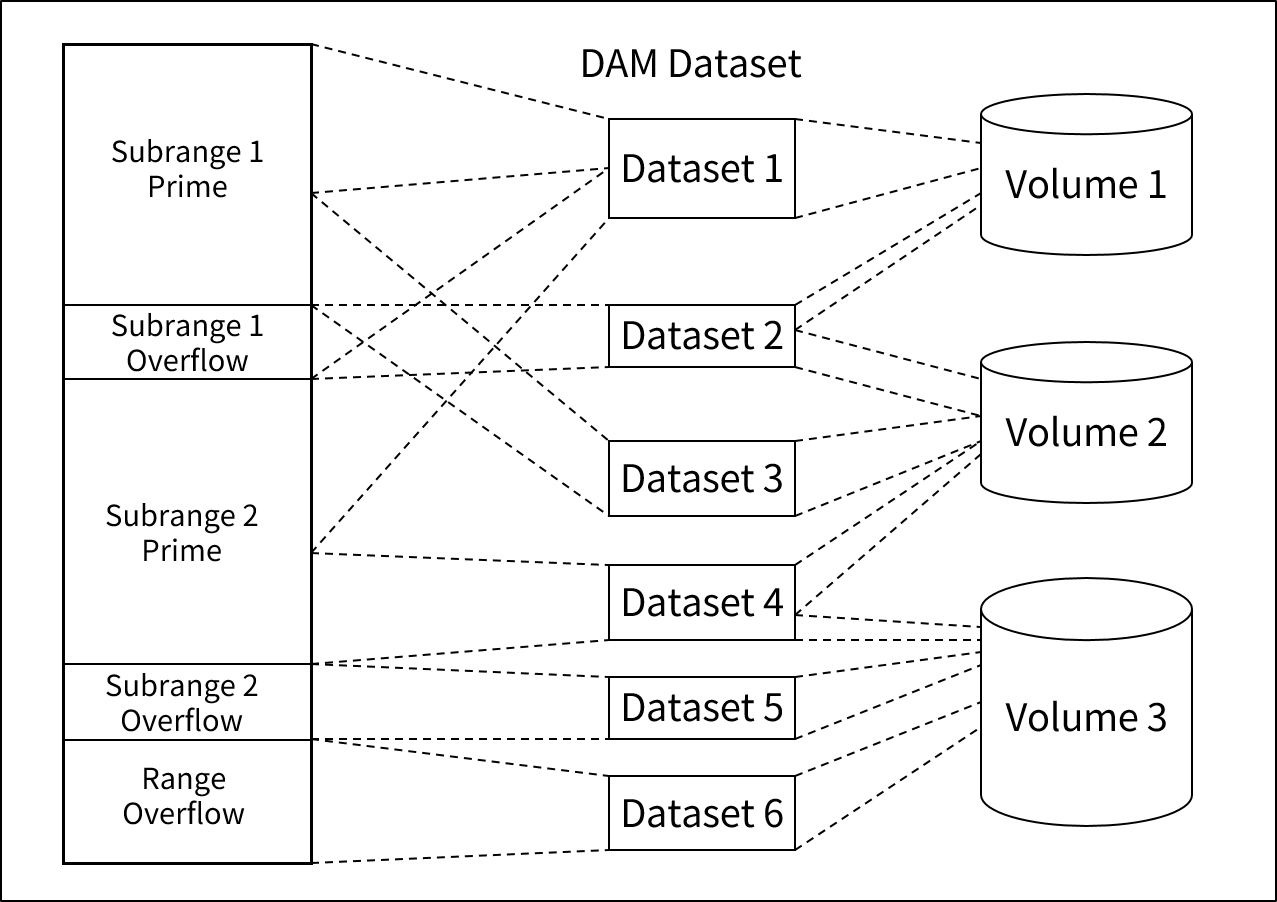
4. Physical Structure
Locative Structure가 Locative Address Space 내에 데이터가 논리적으로 어떻게 정렬되는지를 정의했다면 Physical Structure는 Locative Address Space를 직접 접근 저장장치에 어떻게 할당되는지를 기술한다.
NDB는 레코드를 데이터베이스의 테이블로 저장한다. 즉, Physical Structure은 DBMS에 위임하여 처리하기 때문에 AIM/DB와는 다르다. 여기서는 AIM/DB의 Physical Structure에 대해서 간단하게 기술한다.
5. Virtual Logical Structure
하나의 데이터베이스는 많은 레코드 타입을 포함하고 있다. 따라서 애플리케이션에서 이 레코드들을 모두 접근할 가능성은 크지 않다.
실제 애플리케이션을 개발하는 프로그래머가 개발 중인 애플리케이션에서 접근하는 레코드 타입에 대해서만 알 수 있도록 서브스키마를 제공한다. 서브스키마는 스키마에 정의된 데이터베이스에 대한 정보 중에서 필요한 부분만을 발췌하여 기술한다.
스키마는 Logical Structure, Locative Structure, Physical Structure를 지정하지만 서브스키마에서는 스키마의 Logical Structure에서만 선별한다. 따라서 응용 프로그래머는 데이터베이스가 어떻게 구성되어있는지 자세히 알지 않고서도 애플리케이션을 작성할 수 있다. 이것을 Virtual Logical Structure라고 한다. Virtual Logical Structure는 데이터베이스에서 이용할 레코드 타입과 세트 타입을 선택할 수 있으며, 레코드 내의 필드 역시 필요한 부분만 선택하거나 재정의할 수 있다.
6. Multiple Locative Space(MLS)
NDB는 레코드를 테이블에 저장하여 range에 대한 제한은 없으며, 한 레코드 타입당 1024GB의 레코드 수 제한이 있다. 즉 SLS, MLS 구분이 없이 방대한 양의 데이터를 저장할 수 있다. 여기서는 AIM/DB의 MLS 특징에 대해서만 설명한다.
6.1. MLS 특징
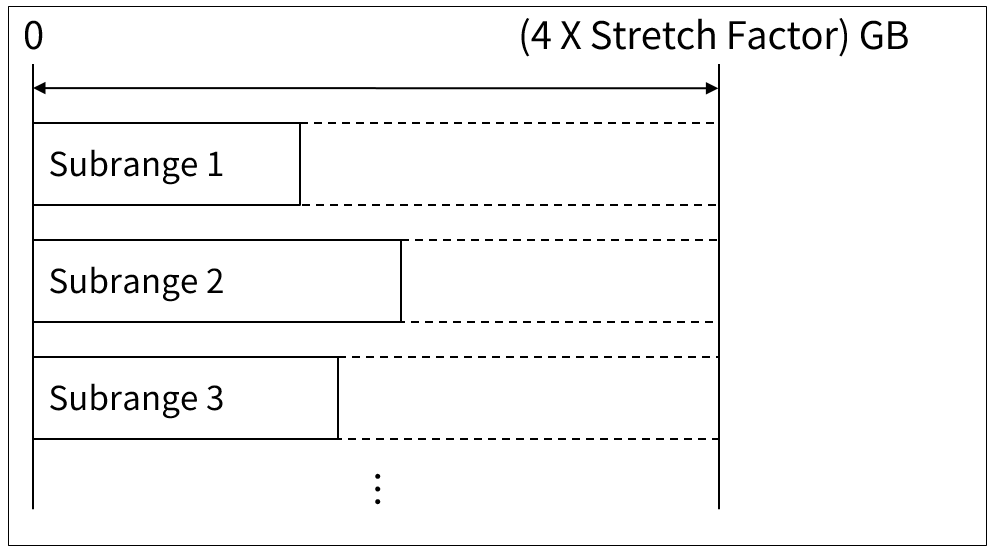
SLS/DB의 최대 용량은 128GB(STRETCH factor 32 적용하는 경우)이다. 방대한 양의 데이터를 저장하고자 할 때는 이 용량도 부족할 수 있다. 이를 해결할 수 있는 방법이 MLS/DB를 사용하는 것이다. MLS에서는 각 Subrange가 독립적인 주소 체계를 갖는다. 즉, 각 Subrange는 128GB의 크기를 가질수 있다.
이와 같은 방대한 크기의 MLS/DB를 생성하는 데는 시간이 많이 걸린다. 이에 AIM/DB에서는 MLS/DB를 한 번에 생성하는 것이 아니라 Subrange 단위로 생성을 할 수 있다.
6.2. MLS와 SLS 차이
AIM/DB에서 MLS/DB는 기본적으로 Subrange 단위의 처리(예: 재편성)를 할 수 있다는 장점이 있다. 그렇기에 몇 가지 제약이 존재한다.
-
Set 관계가 Range를 넘어설 수 없다.
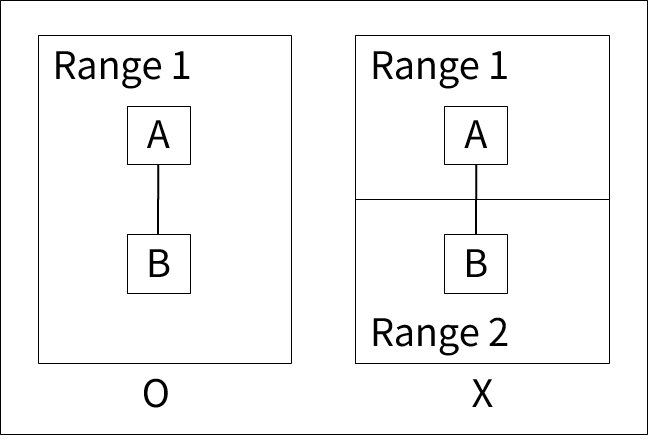 MLS/DB의 SET관계
MLS/DB의 SET관계 -
Range가 Subrange로 나뉜 경우 range에는 overflow 영역을 이용할 수 없으며 Subrange의 overflow 영역만을 사용해야 한다.
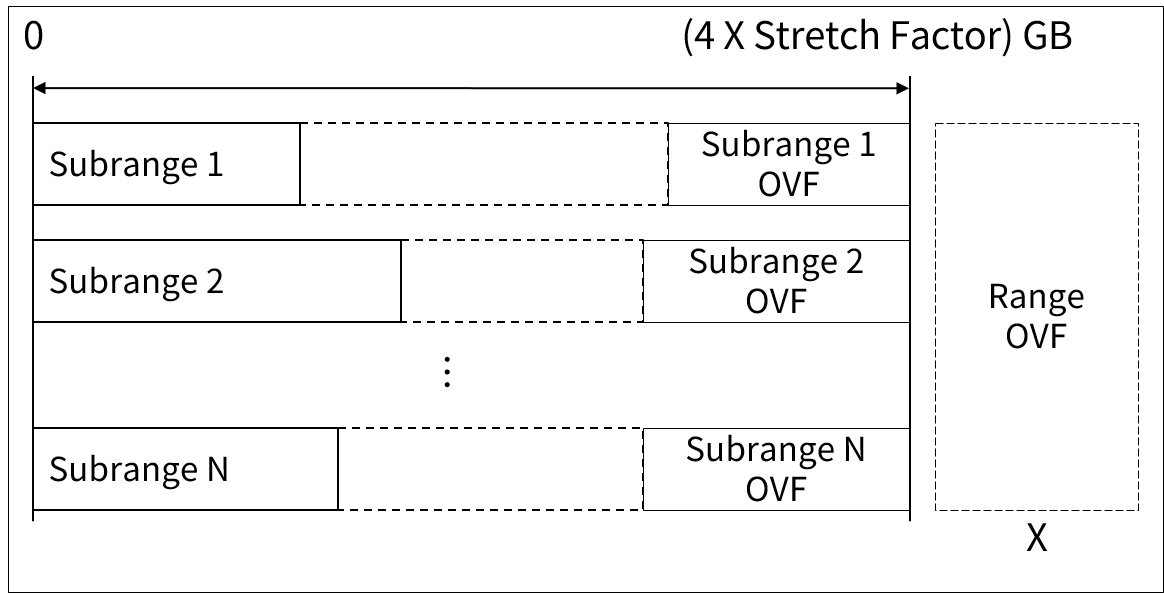 MLS/DB의 overflow 영역 이용
MLS/DB의 overflow 영역 이용 -
Extended index를 생성함에 있어 각 Subrange마다 독립적으로 생성한다.
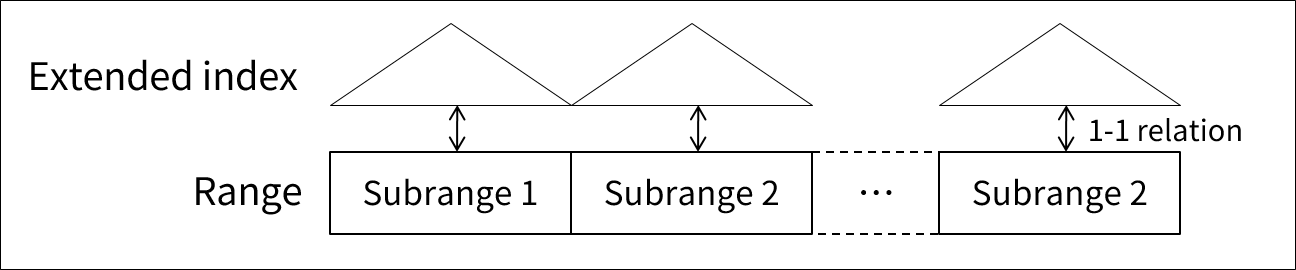 MLS/DB의 Extended index 매핑
MLS/DB의 Extended index 매핑
6.3. Extended Index
흔히 책에서 특정 내용을 찾아가고자 할 때 사용할 수 있는 방법은 목차로부터 찾아가는 방법과 색인으로부터 찾아가는 방법이 있다. 목차로부터 해당 내용을 찾아 가는 것이 NDB에서 이용되는 Index entry method라면 Extended Index는 색인으로부터 해당 내용을 찾아가는 것에 해당된다.
6.3.1. Extended Index 구조
AIM/DB에서 Extended Index는 일반 레코드와 비슷하게 처리된다. 단지 레코드의 내용이 다른 레코드의 인덱스 정보라는 점이 다르다. 다시 말해 Extended index key와 레코드가 위치한 주소 등이 데이터 항목이 되고, 이 데이터 항목들이 모인 것이 Extended Index record인 것이다. 따라서 Extended Index 역시 레코드가 저장될 때와 마찬가지로 Logical Structure, Locative Structure, Physical Structure를 가지고 있다.
하지만 NDB에서는 Extended Index에 대하여 Locative Structure를 두지 않고 Physical Structure에 포함되는 구조로 이루어져 있다. NDB에서 Extended Index record의 구조는 레코드 테이블의 index를 생성하여 처리하며, AIM/DB에서와 동일한 검색 결과를 제공할 수 있다.
6.3.2. Independent Index Routing
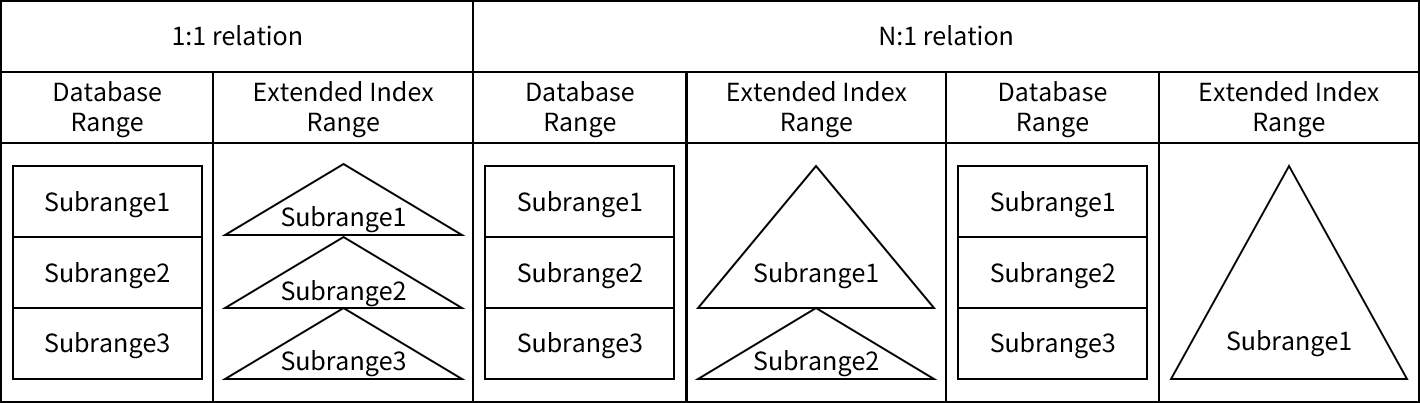
Extended Index를 생성할 때 각 Subrange 마다 따로 Extended Index를 생성하거나, 혹은 모든 Subrange를 합쳐 하나의 Range에 대해 Extended Index를 생성할 수 있다. 또한 Range의 Subrange를 여러 개씩 모아 따로 Extended Index를 생성할 수 있다.
AIM/DB에서 하나의 Extended Index는 하나의 Range에 저장되고, 이 Extended Index range는 앞서 설명한 Extended Index를 생성한 단위대로 서로 다른 Subrange로 나뉘어 저장된다. 하지만 NDB에서는 Extended Index의 Range와 Subrange의 실체는 존재하지 않고, 본 장에서 설명한 레코드 테이블의 index를 생성하여 처리한다.