Statement
본 장에서는 OpenFrame PL/I의 Statement 사용법에 대해서 설명한다.
1. ALLOCATE statement(약어: ALLOC)
ALLOCATE statement는 피제어 변수(Controlled variable) 또는 기저부 변수(Based variable)의 스토리지를 할당한다.
1.1. 피제어 변수의 ALLOCATE statement
ALLOCATE statement는 피제어 변수(Controlled variable)에 대한 스토리지를 할당한다. Controlled 파라미터들도 할당될 수 있다. ALLOCATE statement에 피제어 변수의 배열의 bound, 문자열 길이를 기술할 수 있다.
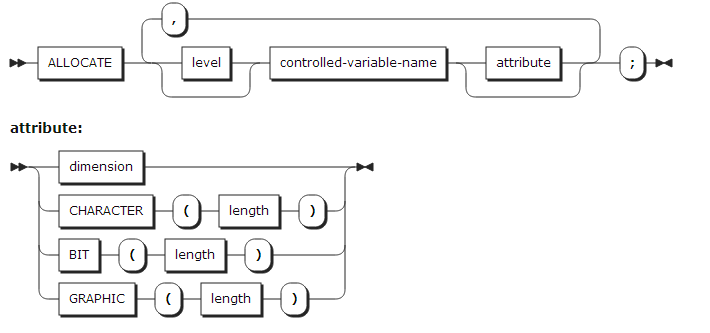
배열의 bound와 문자열의 길이는 ALLOCATE statement가 실행되는 시점에서 evaluated된다.
-
ALLOCATE statement 나 DECLARE또는 DEFAULT statement에 필요한 크기 정보와 문자열 길이 정보가 기술되어 있어야 한다.
-
ALLOCATE statement에서 DIMENSION 속성이나 문자열 길이가 기술된다면, 변수 선언에 기술된 속성을 대신한다.
-
ALLOCATE statement에서 bound, 문자열 길이가 애스터리스크(*)로 기술되어 있다면, 현재 세대의 정보를 사용한다. 만약 현재 세대의 변수가 없다면 해당 정보는 undefined가 되고 프로그램은 에러가 된다.
-
ALLOCATE statement에서 기술된 DIMENSION 속성은 선언된 dimension의 차원 숫자에 맞게 기술되어야 한다. 즉, 1차원 배열이면 DIMENSION 속성이 1개 기술되어야 하고, 2차원 배열이면 2개, ..., n 차원 배열이면 n개의 DIMENSION 속성이 기술되어야 한다.
-
BIT, CHARACTE, GRAPHIC 속성은 반드시 DECLARE statement에 기술된 속성과 같아야 한다.
다음은 ALLOCATE statement를 사용한 예이다.
DCL X(M,N) CHAR(L) CTL; M = 10; N = 5; L = 100; ALLOCATE X(5,5) CHAR(200);

2. ASSIGN statement
Assignment statement는 표현식을 계산하여 그 결과 값을 하나 이상의 target 변수에 저장한다. 이때, target 변수 또는 의사 변수(Pseudo variable)의 속성이 source의 속성과 다를 수가 있으므로, 데이터 변환이 발생할 수도 있다.

| 항목 | 설명 |
|---|---|
reference |
target 변수 또는 의사 변수를 기술한다. |
expression |
Source의 표현식이다. |
BY NAME |
Structure assigment에 사용되는 옵션이다. 자세한 사항은 "Assignment 실행"을 참고한다. |
복합 assignment statement
복합 assignment statement는 복합 연산자를 이용하여 assignment를 수행한다.

| 항목 | 설명 |
|---|---|
reference |
Target 변수 또는 의사 변수를 기술한다. |
compound operator |
Assignment가 수행되기 전 source와 target을 연산할 연산자를 기술한다. 복합 assignment statement에 사용 가능한 복합 연산자는 다음과 같다.
|
expression |
Source의 표현식이다. |
복합 assignment statement는 다음과 같이 수행된다.
X += 5; ==> X = X + 5; X *= Y - 1; ==> X = X * (Y - 1);
Target variable
Target variable은 element, 배열, 구조체 변수 또는 의사 변수가 될 수 있다.
-
배열
-
target은 스칼라 또는 구조체의 배열이어야 한다. source는 스칼라 표현식(Acalar expression)이거나 target과 같은 dimension과 bound를 가진 표현식이어야 한다.
-
-
구조체
-
BY NAME이 기술되어 있으면 각 target은 구조체이어야 하고, source 또한 구조체이어야 한다.
-
BY NAME이 없으면 각 target은 구조체이어야 하고, source는 스칼라 또는 target과 같은 구조의 구조체이어야 한다.
-
BY NAME이 없을 때 source를 NULL string("")으로 기술하게 되면 다음과 같이 처리된다.
-
모든 target은 '00’X로 채워진다.
-
모든 numeric target은 0이 된다.
-
모든 character, graphic target은 공백으로 채워진다.
-
-
Assignment 실행
-
배열
-
모든 Array 연산자(source & target)는 동일한 dimension과 bound를 가져야 한다.
-
Array assignment는 다음과 같이 loop로 확장된다.
DO I1 = LBOUND( target-variable, 1 ) to HBOUND( target-variable, 1 ); DO I2 = LBOUND( target-variable, 2 ) to HBOUND( target-variable, 2 ); ... DO IN = LBOUND( target-variable, N ) to HBOUND( target-variable, N ); generated element assignment ; END;
-
N은 target의 number of dimension이다. Generated element assignment에서는 I1 ~ IN을 subscript로 사용한다. Source가 스칼라이면 subscript는 적용되지 않는다.
-
-
구조체
-
BY NAME이 기술되지 않은 경우 다음과 같이 처리된다.
-
모든 연산자는 배열이어서는 안되고, 동일한 구조를 가진 구조체이어야한다. 멤버로 배열을 포함할 수는 있다.
-
각각의 멤버별로 assignment로 확장한다. 멤버가 n개이면 n개의 assignment가 실행된다.
-
멤버 assignment가 또다시 aggregate assignment이면 확장되어 처리된다.
-
-
BY NAME이 기술되면 다음과 같이 처리된다.
-
target 구조체의 첫 번째부터 멤버 이름과 같은 이름을 source 멤버에서 찾는다. 이때 멤버는 구조체의 바로 하위 레벨(child)만 찾는다. child의 child는 찾지 않는다.
-
찾지 못하면 두 번째 멤버, 세 번째 멤버 등등 찾을 때까지 반복한다.
-
찾았을 때 멤버가 구조체 또는 구조체의 배열이면 멤버에 대해 BY NAME 옵션을 가진 assignment로 처리된다.
-
찾은 멤버가 스칼라 또는 스칼라의 배열이면 element assignment를 수행한다.
-
다음 멤버에 대해 위의 작업을 동일하게 처리한다.
-
-
다음은 BY NAME을 사용한 구조체 assignment에 대한 예이다.
DCL 1 ONE, DCL 1 TWO, DCL 1 THREE 2 PART1, 2 PART1, 2 PART1, 3 RED, 3 BLUE, 3 RED, 3 ORANGE, 3 GREEN, 3 BLUE, 2 PART2, 3 RED, 3 BROWN, 3 YELLOW, 2 PART2, 2 PART2, 3 BLUE, 3 BROWN, 3 YELLOW, 3 GREEN; 3 YELLOW; 3 GREEN;
-
4. CALL statement
CALL statement는 서브 루틴을 호출한다.
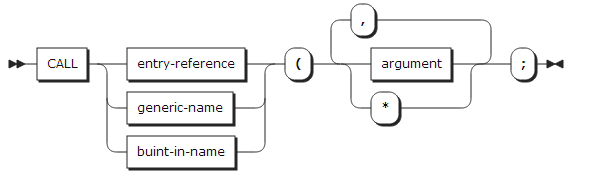
| 항목 | 설명 |
|---|---|
entry-reference |
호출될 서브 루틴 이름을 기술한다. |
generic-name |
GENERIC 속성을 가지고 선언된 변수 이름을 기술한다. |
built-in name |
내장함수의 이름을 기술한다. |
argument |
호출되는 서브 루틴에 전달하는 데이터 항목을 기술한다. |
5. CLOSE statement
CLOSE statement는 지정한 파일을 닫는다.
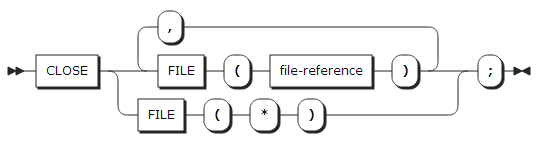
| 항목 | 설명 |
|---|---|
FILE |
대상이 되는 파일을 기술한다. 애스터리스크(*)를 사용하여 열린 파일을 모두 닫을 수 있다. |
6. DECLARE statement
DECLARE statement는 데이터 항목의 이름과 일부 또는 모든 속성을 기술할 수 있다. 명시적으로 속성이 기술되지 않고, 문맥적으로 속성을 결정할 수 없는 경우 default 속성이 적용된다.
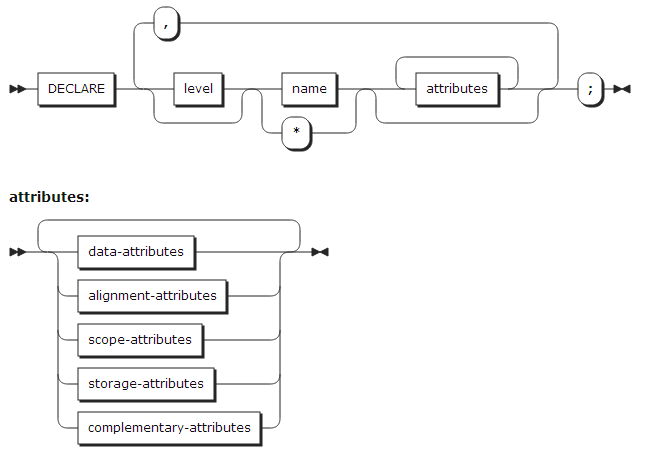
| 항목 | 설명 |
|---|---|
* |
스칼라, level-1 데이터의 이름으로 기술될 수 없다. |
attributes |
선언되는 데이터의 속성을 기술한다. 기술하는 순서는 관계없다. 자세한 내용은 데이터 타입과 속성을 참고한다. |
level |
양수인 정수이어야 한다. 스칼라, 배열 데이터를 선언할 때는 기술할 필요가 없고 level-1이 된다. |
name |
선언되는 데이터 이름을 기술한다. level-1 이름은 같은 블록 안에서 중복되어서는 안된다. |
|
Condition prefix와 level은 DECLARE statement에 기술되어서는 안된다. |
7. DEFAULT statement(약어: DFT)
DEFAULT statement는 속성 집합이 완전하지 않을 때 data-attribute default를 정의한다.
암시적인 선언과 문맥적인 선언 또는 부분적으로 완전한 명시적인 선언에 대해 DEFAULT statement가 적용되지 않는 속성은 Language-specified default에 의해 제공된다.
DEFAULT statement는 ENTRY나 FILE 속성으로 선언된 이름을 제외하고 모든 다른 속성 사양을 재정의한다. 하지만 VARIABLE를 암시하는 속성이 없는 이름은 DEFAULT statement가 적용되기 전에 PL/I에 의해 암시적으로 CONSTANT 속성이 제공된다. structure와 union의 요소는 qualified element의 이름이 아니라 요소의 이름에 따라서 디폴트 속성이 적용된다.

identifier:
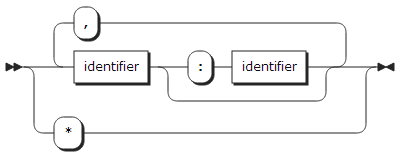
| 항목 | 설명 |
|---|---|
RANGE(identifier) |
같은 문자로 시작하는 이름들에 적용된다. |
RANGE(identifier : identifier) |
두 identifier로 지정된 문자로 시작하는 이름이나 두 알파벳 순서 사이에 있는 이름에 적용된다. |
RANGE(*) |
DEFAULT statement의 범위 안에 있는 모든 이름에 적용된다. |
DESCRIPTORS |
명시적 Entry 선언의 매개 변수 기술 목록에서 해당하는 매개 변수 기술에 포함되는 속성에 적용된다. 적어도 하나의 속성은 존재하여야 하고 NULL 기술에는 적용되지 않는다. RANGE() 위치에 RANGE() 대신 사용한다. |
attribute_specification |
|
블록 내에 DEFAULT statement은 여러 개가 올 수 있다.
DEFAULT statement가 적용되는 범위는 DEFAULT statement가 선언된 블록이다. 또, 같은 범위를 가지는 또다른 DEFAULT statement를 포함하지 않으면서, 같은 범위를 가지는DEFAULT statement가 있는 블록 안에 포함되지도 않은 모든 블록이 DEFAULT statement가 적용되는 범위이다. 즉, 같은 범위에 대한 DEFAULT statement가 선언된 블록이 있고, 블록 안에 있는 블록에서는 블록 내에서 선언된 같은 범위에 대한 DEFAULT statement의 속성이 먼저 그 블록 범위 내에서 적용이 된다.
내부 블록에서 DEFAULT statement은 명시적으로 선언된 이름에만 영향을 준다. 왜냐하면, 암시적 선언은 외부 프러시저의 ROCEDURE 문 다음에 이름이 기재되었을 때 DECLARE 문으로 선언된 것 처럼 암시적으로 선언 범위가 결정되기 때문이다.
다음의 예를 살펴보자.
X: PROC; LABEL1: DEFAULT RANGE(AB) FLOAT; Y: BEGIN; LABEL2: DEFAULT RANGE(ABC) FIXED; END X;
LABEL1의 DEFAULT statement의 범위는 프러시저 X와 프러시저 안에 포함된 begin-block Y이다. LABEL1의 DEFAULT statement에서 지정한 범위는 프러시저 X와 begin-block Y에 선언된 문자열 AB로 시작하는 모든 이름이다. 단, begin-block Y에서는 문자열 ABC로 시작하는 이름들은 제외한다. 문자열 ABC로 시작하는 이름들은 begin-block Y 내에서 적용된다.
8. DEFINE statement
DEFINE statement는 사용자가 PL/I 데이터 타입에 대해 별칭을 지정하거나 열거형 데이터 타입을 정의할 수 있다.
8.1. DEFINE ALIAS statement
DEFINE ALIAS statement는 사용자가 PL/I 데이터 타입에 대해 별칭을 정의할 수 있다.

| 항목 | 설명 |
|---|---|
alias-name |
별칭으로 사용할 이름을 지정한다. |
attributes |
별칭의 데이터 속성을 지정한다. |
다음은 DEFINE ALIAS statement를 이용하여 별칭을 정의하고, 별칭을 이용하여 변수를 선언하는 예제이다.
DEFINE ALIAS NAME CHAR(32); DECLARE COMPANY_NAME TYPE NAME;
8.2. DEFINE ORDINAL statement
DEFINE ORDINAL statement는 열거형 타입을 정의한다.

ordinal-value-list :
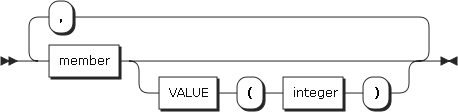
| 항목 | 설명 |
|---|---|
ordinal-name |
열거형 타입으로 사용할 이름을 지정한다. |
member |
열거형 타입의 멤버 이름을 지정한다. |
VALUE |
멤버의 값을 지정한다.
|
PRECISION |
VALUE의 PRECISION 속성을 지정한다. 만일 PRECISION 속성을 생략할 경우 VALUE 값을 기준으로 결정된다. |
SIGNED, UNSIGNED |
VALUE의 SIGNED, UNSIGNED 속성을 지정한다. |
다음은 DEFINE ORDINAL statement를 이용하여 열거형 타입을 정의하고, 열거형 변수를 선언하는 예제이다.
DEFINE ORDINAL LANG ( PLI, COBOL, ASSEMBLER, C, CPP ); DECLARE COMPILER ORDINAL LANG;
9. DELAY statement
DELAY statement는 프로그램의 수행을 정의한 시간만큼 일시적으로 중단한다.

| 항목 | 설명 |
|---|---|
expression |
중단할 시간을 정의한다. 정의한 값만큼 millisecond 단위로 중단한다. |
10. DELETE statement
DELETE statement는 데이터 셋으로부터 레코드를 삭제한다.

| 항목 | 설명 |
|---|---|
FILE |
삭제할 파일을 지정한다. 파일은 반드시 UPDATE 속성을 가져야 한다. |
KEY |
지정한 KEY에 해당하는 레코드를 삭제한다. KEY 옵션을 사용하기 위해서는 파일은 DIRECT 속성을 가지거나 SEQUENTIAL KEYED 속성을 가져야 한다. |
11. DISPLAY statement
DISPLAY statement는 메시지를 stdout으로 출력한다.

| 항목 | 설명 |
|---|---|
expresson |
필요한 경우 Character 문자열로 변환된다. 변환된 문자열이 출력된다. GRAPHIC 문자열은 변환되지 않는다. |
12. DO statement
DO statement는 여러 statement를 그룹으로 묶어 반복 수행을 위해 조건을 정의할 수 있다. DO statement는 END statement와 짝지어져야 하고, DO statement부터 END statement 안에 있는 statement들은 do-group으로 묶인다.
DO statement는 다음과 같은 4가지 유형이 있다.
-
Type 1
-
Type 2
-
Type 3
-
Type 4
Type 1
Type 1은 do-group을 정의하여 do-group안의 statement들을 수행한다. Type 1은 반복 수행을 위한 조건을 정의하지 않는다.

Type 2와 Type 3
Type 2와 Type 3은 do-group을 정의하여 do-group 안의 statement들을 수행하며, 반복 수행을 위한 조건을 정의할 수 있다.
Type 2 :

Type 3 :

specification :
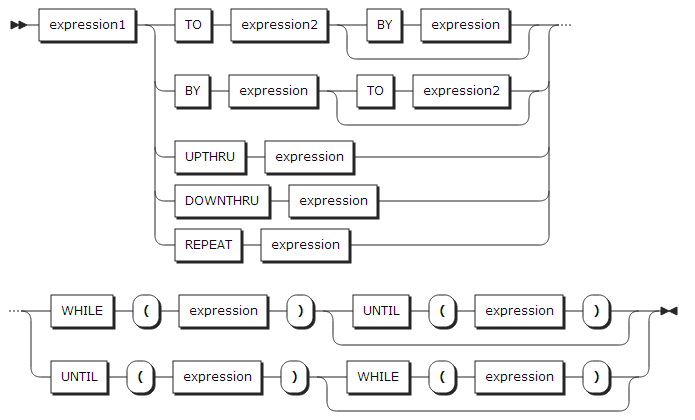
| 항목 | 설명 |
|---|---|
WHILE(expression) |
do-group이 수행되기 전 표현식을 계산하여 BIT string으로 변환한다. 어떤 BIT라도 1일 경우 do-group은 수행된다. 모든 BIT가 0이거나 string이 null일 경우 do-group은 수행되지 않는다. specification이 여러 번 반복될 경우 다음 specification이 수행된다. |
UNTIL(expression) |
do-group이 수행된 후 표현식을 계산하여 BIT string으로 변환한다. 모든 BIT가 0이거나 string이 null일 경우 do-group은 수행된다. 어떤 BIT라도 1일 경우 do-group은 수행되지 않는다. specification이 여러 번 반복 될 경우 다음 specification이 수행된다. |
reference |
do-group을 처음 수행하기 전 expression1의 값으로 초기화 된다. specification이 여러 번 반복될 경우 각 specification의 expression1의 값으로 초기화되고 do-group을 수행한다. |
expression1 |
reference의 초기 값을 정의한다. TO, BY, REPEAT가 생략될 경우 계속 expression1의 값을 가지면서 반복된다. |
TO expression2 |
reference의 종료 값을 정의한다. 참조의 값이 expression1부터 expression2의 범위를 넘을 경우 해당 do-group은 종료된다. TO expression2가 생략될 경우 WHILE, UNTIL 옵션에 의해 do-group이 종료되어야 한다. |
BY expression |
reference의 증감 값을 정의한다. do-group이 실행된 후 참조에 표현식 값만큼 더한 후 저장한다. TO expression2가 정의되어 있고 BY expression이 생략될 경우 기본값으로 BY 1이 지정된다. |
UPTHRU expression |
참조의 종료 값을 정의한다. do-group이 실행된 후 참조에 1을 더한 후 저장한다. TO 옵션과 다른 점은 TO 옵션은 do-group을 수행하기 전에 비교하지만, UPTHRU 옵션은 do-group을 수행한 후 비교한다. 따라서 UPTHRU 옵션은 do-group을 최소 한 번 이상 수행한다. |
DOWNTHRU expression |
참조의 종료 값을 정의한다. do-group이 실행된 후 참조에 1을 뺀 후 저장한다. TO 옵션과 다른 점은 TO 옵션은 do-group을 수행하기 전에 비교하지만, DOWNTHRU 옵션은 do-group을 수행한 후 비교한다. 따라서 DOWNTHRU 옵션은 do-group을 최소 한 번 이상 수행한다. |
REPEAT expression |
do-group이 수행된 후 표현식을 계산하여 참조에 저장하고 다시 do-group을 수행한다. WHILE이나 UNTIL 옵션에 의해 종료되기 전까지 do-group 수행을 반복한다. |
Type 4
Type 4는 do-group을 정의하여 do-group 안의 statement를 무한 반복 수행한다.

| 항목 | 설명 |
|---|---|
FOREVER |
LOOP와 동의어이다. |
LOOP |
무한 반복을 정의한다. 반복을 종료하기 위해서는 GOTO 또는 LEAVE statement를 사용하거나 프러시저 또는 프로그램을 종료해야 한다. |
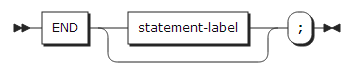
13. END statement
END statement는 하나 이상의 블록이나 그룹의 마지막을 지정한다. 모든 블록이나 그룹은 반드시 하나의 END statement를 가져야 한다.
| 항목 | 설명 |
|---|---|
statement-label |
END statement 앞에 기술된 가장 가까운 DO, SELECT, PACKAGE, BEGIN 또는 PROCEDURE statement의 label 이름을 기술하여 해당 블록이나 그룹의 마지막임을 표시한다. 이 항목이 기술되지 않으면 가장 가까운 블록이나 그룹 하나에 대하여 마지막임을 표시한다. |
14. ENTRY statement
ENTRY statement를 포함하는 프러시저는 모든 non-pointer 파라미터들이 BYADDR(pass by address)이어야한다.

| 항목 | 설명 |
|---|---|
entry-label |
프러시저의 부가적인 Entry point 이름이다. |
parameter- list |
Entry point에 대한 파라미터를 기술한다. |
returns-options |
Entry point의 RETURN 속성을 정의한다. |
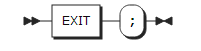
15. EXIT statement
EXIT statement는 현재 실행되고 있는 PL/I 프로그램을 종료한다. OpenFrame PL/I에서는 STOP statement와 동일한 처리를 한다.
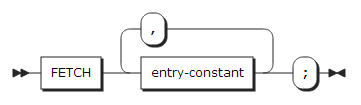
16. FETCH statement
FETCH statement는 프러시저에 대한 entry-point가 메모리에 없으면 동적으로 해당 프로그램을 로드한다.
| 항목 | 설명 |
|---|---|
entry-constant |
로드될 프러시저의 이름을 기술한다. |
17. FLUSH statement
FLUSH statement는 지정한 파일의 buffer를 flush한다. FLUSH statement를 사용하기 위해서는 반드시 파일에 BUFFERED 속성이 정의되어 있어야 한다.

| 항목 | 설명 |
|---|---|
FILE |
대상이 되는 파일을 기술한다. 애스터리스크(*)를 사용하여 열린 파일을 모두 flush할 수 있다. |
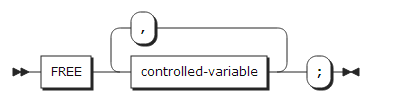
18. FORMAT statement
FORMAT statement는 Edit-directed I/O에서 사용할 format list를 지정할 수 있다.

| 항목 | 설명 |
|---|---|
label |
R-format item에서 지정할 label을 정의한다. 자세한 사항은 R-format을 참고한다. |
format list |
Edit-directed I/O에서 사용할 format list를 정의한다. |

20. GET statement
GET statement는 스트림으로부터 레코드를 읽어온다. 스트림은 데이터 셋의 레코드나 문자열에서 가져올 수 있다.
데이터 셋으로부터 데이터를 읽을 경우 GET statement의 문법은 다음과 같다.
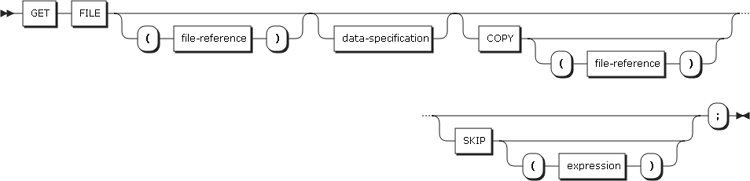
| 항목 | 설명 |
|---|---|
FILE |
대상 파일을 지정한다. 만약 파일이 생략될 경우 SYSIN 파일이 지정된다. |
data-specification |
Data specification을 참고한다. |
COPY |
읽어들인 스트림을 지정된 파일에 그대로 저장한다. 만일 파일이 생략될 경우 SYSPRINT 파일이 지정된다. |
SKIP (expression) |
표현식 값만큼 데이터를 건너뛰고 다음 데이터를 가져온다. 표현식이 생략될 경우 기본값은 1이다. |
문자열으로부터 데이터를 읽을 경우 GET statement의 문법은 다음과 같다.

| 항목 | 설명 |
|---|---|
STRING |
대상 문자열을 지정한다. |
data-specification |
Data specification을 참고한다. |
21. GOTO statement
GOTO statement는 label이 정의된 위치로 프로그램의 제어를 이동한다.
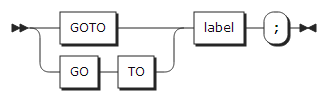
| 항목 | 설명 |
|---|---|
label |
label은 label 상수나 label 변수가 될 수 있다. label 변수일 경우 GOTO statement를 수행할 시점에 저장된 값을 참조하여 이동한다. |
GOTO 할 대상은 동일한 블록 내의 label이나 바깥 블록이 될 수 있다. 또한 ON-unit 안에서 바깥 블록으로 GOTO 할 수 있다.
다음과 같은 상황에서는 GOTO를 사용할 수 없다.
-
안쪽 프러시저에서 바깥 프러시저로 GOTO
-
바깥 블록이나 프러시저에서 안쪽 블록이나 프러시저로 GOTO
-
FORMAT statement로의 GOTO
22. IF statement
IF statement는 조건을 판정하여 그 결과에 따라 분기를 나눌 수 있다.

| 항목 | 설명 |
|---|---|
expression |
참 또는 거짓을 판별할 expression이다. '&'와 '|'를 이용하여 여러 개의 조건을 기술할 수 있다. |
unit |
조건이 따라 수행될 statement들을 기술한다. unit은 하나의 statement, do-group 또는 begin-block이 될 수 있다. 조건이 참이 되면 THEN에 기술된 unit이 수행되고, 거짓일 경우 ELSE에 기술된 unit이 수행되거나 ELSE가 없을 경우 IF statement가 종료된다. |
Short-circuit evaluation
다음과 같은 경우 IF statement의 표현식은 "short-circuited" 될 수 있다.
-
만일 IF statement의 표현식들이 OR로 묶여 있고, 첫 번째 표현식의 evaluation 결과가 참일 경우 두 번째 표현식은 evaluation 하지 않고 THEN에 기술된 unit이 수행된다.
-
만일 IF statement의 표현식들이 AND로 묶여 있고, 첫 번째 표현식의 evaluation 결과가 거짓일 경우 두 번째 표현식은 evaluation 하지 않고 ELSE에 기술된 unit이 수행되거나 IF statement가 종료된다.
Short-circuit evaluation은 IF statement 뿐만 아니라 SELECT statement에도 적용된다.
23. ITERATE statement
ITERATE statement는 수행하고 있는 do-group을 건너 뛰고 다음 반복 조건의 do-group를 수행한다.
ITERATE statement는 반드시 do-group 안에서 사용되어야 한다.

| 항목 | 설명 |
|---|---|
label-constant |
label은 반드시 DO statement의 label이어야 한다. 만일 label이 생략되면, ITERATE statement를 포함하고 있는 가장 가까운 do-group을 건너뛴다. |
24. LEAVE statement
LEAVE statement는 수행하고 있는 do-group을 탈출한다. LEAVE statement는 반드시 do-group 안에서 사용되어야 한다.
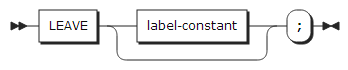
| 항목 | 설명 |
|---|---|
label-constant |
label은 반드시 DO statement의 label이어야 한다. 만일 label이 생략되면, LEAVE statement를 포함하고 있는 가장 가까운 do-group을 탈출한다. |
25. LOCATE statement
LOCATE statement는 다음에 기록할 Output buffer의 위치를 기저부 변수(Based variable)을 통해 접근할 수 있도록 포인터(pointer)로 지정한다.

| 항목 | 설명 |
|---|---|
FILE |
대상 파일을 지정한다. 파일은 반드시 OUTPUT SEQUENTIAL BUFFERED 속성을 가져야 한다. |
based variable |
Output buffer로 접근할 수 있는 기저부 변수를 정의한다. |
SET |
Output buffer의 주소를 저장할 포인터를 지정한다. |
KEYFROM |
기록할 레코드의 키를 지정한다. KEYFROM 옵션을 사용하기 위해서는 파일은 KEYED 속성을 가져야 한다. Indexed 데이터 셋에서는 KEYFROM의 값이 CHARACTER로 변환되고, Relative 데이터 셋에서는 FIXED DECIMAL로 변환된다. |
|
레코드는 LOCATE statement를 수행할 시점에 기록되지 않고, FLUSH statement를 사용하여 버퍼를 비우거나 다음 LOCATE statement를 수행할 때 기록된다. 따라서 LOCATE statement를 수행하더라도 데이터 셋에 기록될 레코드는 기저부 변수를 통해 계속 수정될 수 있다. |
26. NULL statement
NULL statement는 아무런 실행을 하지 않는다. 보통 THEN, ELSE, WHEN, OTHER에 기술하여 실행하는 경우 해당 조건에서는 아무 일도 하지 않도록 하는데 사용된다.
27. ON statement
ON statement는 조건이 발생했을 때 지정한 ON-unit을 수행하도록 ON-unit을 등록한다.
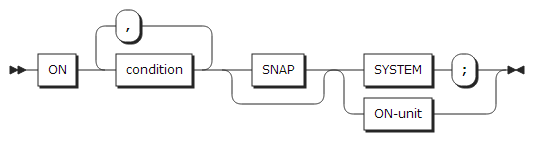
| 항목 | 설명 |
|---|---|
condition |
하나 이상의 조건을 지정한다. 조건에 대한 설명은 조건 종류를 참고한다. |
SNAP |
지원되지 않음 |
SYSTEM |
해당 조건에 대해서 기본 동작을 수행하도록 지정한다. 기본 동작에 대한 설명은 조건 종류를 참고한다. |
ON-unit |
해당 조건이 발생했을 때, 수행될 statement들을 기술한다. ON-unit은 하나의 statement 또는 begin-block이 될 수 있다. ON-unit은 ON statement를 수행할 때 수행되지 않고, 해당 조건의 발생 조건이 만족되었을 때 수행된다. |
등록한 조건의 발생조건을 만족했을 때 ON-unit이 수행되며 같은 조건을 여러 번 등록하게 되면, 제일 마지막에 등록된 ON statement의 ON-unit이 실행되게 된다. ON statement로 등록한 조건은 ON statement가 포함된 블록이나 프러시저가 종료될 때 해제되며, REVERT statement를 통해서 사용자가 직접 해제할 수 있다.
다음은 ZERODIVIDE 조건을 등록하는 예제이다.
ON ZERODIVIDE
BEGIN;
DISPLAY('ZERODIVIDE condition raised');
END;
A = B / 0;
ZERODIVIDE 조건은 0으로 나눌 때 발생하는 조건이다. "A = B / 0" 구문에 의해 ZERODIVIDE 조건이 발생하게 되고, ON statement로 등록한 ON-unit이 수행되어 DISPLAY 문장이 수행된다.
28. OPEN statement
OPEN statement는 지정한 파일을 연다.
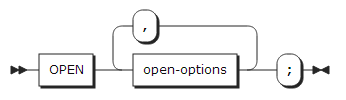
open-options :
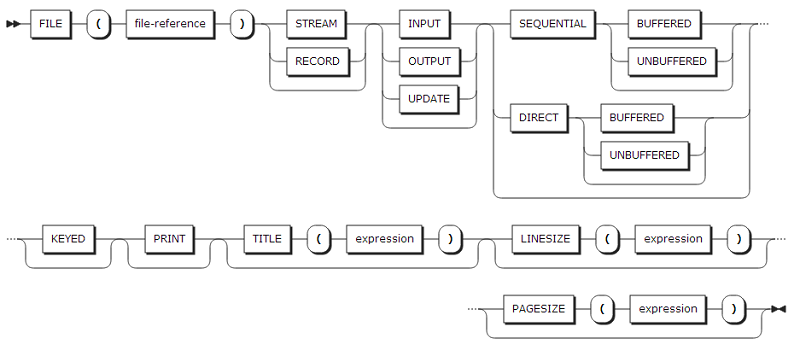
| 항목 | 설명 |
|---|---|
FILE |
대상이 되는 파일을 기술한다. |
FILE 속성 |
자세한 설명은 "File"을 참고한다. |
TITLE |
JCL에 기술된 외부 데이터 셋의 DD 이름을 지정한다. |
LINESIZE |
한 라인의 길이를 정의한다. 스트림이 LINESIZE에 지정한 값를 넘을 경우 다음 라인의 첫 번째 컬럼으로 이동한다. LINESIZE 옵션은 STREAM OUTPUT 파일에만 사용할 수 있다. (기본값: 120) |
PAGESIZE |
한 페이지당 라인의 개수를 정의한다. 라인의 크기가 PAGESIZE의 값을 넘을 경우 ENDFILE 조건이 발생한다. PUT statement에서 PAGE format item이나 PAGE 옵션을 사용하여 새로운 페이지로 시작할 수 있다. (기본값: 60) |
파일을 열기 위해서는 명시적으로 OPEN statement를 사용하거나, 파일이 열려 있지 않은 상태에서 READ, WRITE, REWRITE, DELETE, LOCATE, PUT, GET statement를 사용할 때 내부적으로 열린다. OPEN statement로 명시적으로 열 때 FILE 속성을 정의하여 DECLARE할 때 정의한 FILE 속성을 재정의할 수 있다.
다음은 OPEN statement를 사용하여 FILE 속성을 재정의하는 예제이다.
DECLARE TEST FILE RECORD OUTPUT; OPEN FILE(TEST) STREAM INPUT; CLOSE FILE(TEST); OPEN FILE(TEST);
첫 번째 OPEN statement에서 TEST는 STREAM, INPUT 속성을 가진다. 파일을 닫게 되면 열 때 적용한 FILE 속성은 사라지게 되고, 다음에 열 때에는 적용되지 않는다. 따라서 두 번째 OPEN statement에서는 DECLARE statement에서 지정한 RECORD, OUTPUT 속성을 가진다.
|
선언할 때 정의한 FILE 속성과 열 때 정의한 FILE 속성이 충돌날 경우 에러가 발생한다. |
29. OTHERWISE statement
OTHERWISE statement에 대한 자세한 내용은 SELECT statement를 참고한다.
30. PACKAGE statement
PACKAGE statement는 오직 변수 선언, DEFAULT statement, 프러시저 블록들만 포함할 수 있다. 현재 OpenFrame PL/I는 프러시저 블록들만 포함할 수 있고, PACKAGE statement의 옵션은 지원하지 않는다.

| 항목 | 설명 |
|---|---|
condition_prefix |
PACKAGE statment에 기술된 조건 접두사(Condition prefix)는 패키지 안의 모든 프러시저에 적용된다. 자세한 내용은 조건(Condition)의 조건 접두사 설명을 참고한다. |
package_name |
패키지 이름을 기술한다. |
31. PUT statement
PUT statement는 레코드를 스트림으로 생성한다. 스트림은 데이터 셋의 레코드나 문자열에 저장될 수 있다.
데이터 셋으로 데이터를 저장할 경우 PUT statement의 문법은 다음과 같다.
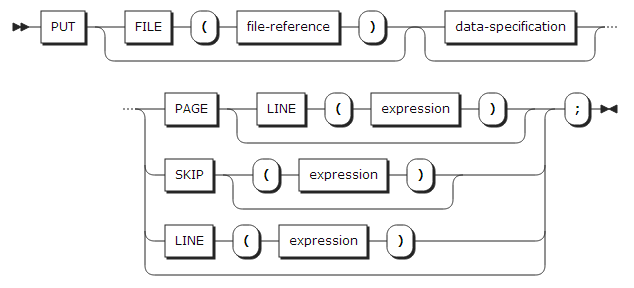
| 항목 | 설명 |
|---|---|
FILE |
대상 file을 지정한다. 파일이 생략될 경우 SYSPRINT 파일이 지정된다. |
data-specification |
Data specification을 참고한다. |
SKIP (expression) |
표현식 값만큼 라인을 건너뛴다. 표현식이 생략될 경우 기본값은 1이다. |
LINE (expression) |
표현식 값에 해당하는 라인으로 이동한다. LINE 옵션을 사용하기 위해서는 반드시 파일에 PRINT 속성이 정의되어 있어야 한다. |
PAGE |
새로운 페이지를 시작한다. 라인은 1로 초기화된다. PAGE 옵션을 사용하기 위해서는 반드시 파일에 PRINT 속성이 정의되어 있어야 한다. |
문자열로 데이터를 저장할 경우 PUT statement의 문법은 다음과 같다.

| 항목 | 설명 |
|---|---|
STRING |
대상 문자열을 지정한다. |
data-specification |
Data specification을 참고한다. |
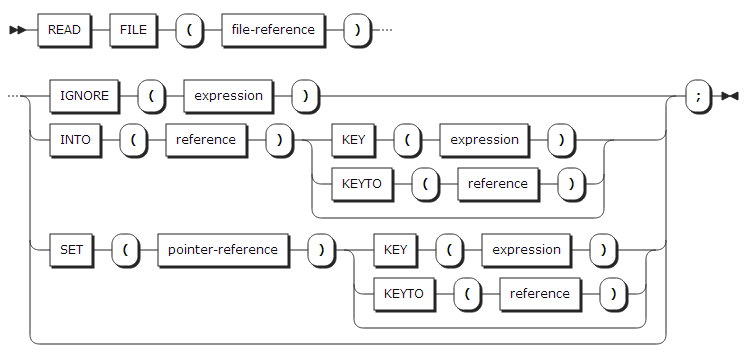
32. READ statement
READ statement는 데이터 셋으로부터 레코드를 읽어온다. 읽어 온 레코드를 지정한 변수에 저장하거나 포인터(pointer)로 지정할 수 있다.
| 항목 | 설명 |
|---|---|
FILE |
읽어올 파일을 지정한다. 파일은 INPUT 또는 UPDATE 속성을 가져야 한다. |
IGNORE |
표현식 값만큼 레코드를 무시한다. 계산된 표현식 값이 n이면 IGNORE 옵션을 수행한 뒤에는 n+1번째 레코드를 읽는다. |
INTO |
읽어온 레코드를 지정한 변수에 저장한다. 변수가 배열이나 구조체일 경우 반드시 스토리지 상에 연결되어 있어야 한다. |
SET |
읽어온 레코드를 지정한 포인터로 가리키게 한다. |
KEY |
지정한 KEY에 해당하는 레코드를 읽어온다. KEY 옵션을 사용하기 위해서는 파일은 DIRECT 속성을 가지거나 SEQUENTIAL KEYED 속성을 가져야 한다. |
KEYTO |
레코드를 읽어올 때 해당 레코드의 키 값도 같이 읽어온다. KEYTO 옵션을 사용하기 위해서는 파일은 SEQUENTIAL KEYED 속성을 가져야 한다. |
33. RETURN statement
RETURN statement는 프러시저의 실행을 종료한다. 프로그램의 실행은 호출한 곳으로 돌아간다.

-
expression을 가지는 RETURN statement는 OPTIONS(MAIN)을 가지는 프러시저에 사용되어서는 안된다.
-
expression을 가지지 않는 RETURN statement는 RETURNS options을 가지는 프러시저에 사용되어서는 안된다.
-
RETURNS options을 가지는 프러시저는 반드시 한 개 이상의 RETURN statement를 포함해야 한다.
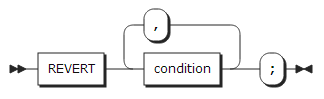
34. REVERT statement
REVERT statement는 ON statement를 사용하여 등록한 ON-unit을 해제한다.
| 항목 | 설명 |
|---|---|
condition |
하나 이상의 조건을 지정한다. 조건에 대한 설명은 조건 종류를 참고한다. |
REVERT statement는 현재 블록이나 프러시저에 등록된 ON-unit을 해제하며, 현재 블록이나 프러시저에 등록된 ON-unit이 없을 경우 REVERT statement는 수행되지 않는다. 상위 블록이나 프러시저에서 등록한 ON-unit은 해제할 수 없다.
다음은 REVERT statement를 이용하여 등록한 ON-unit을 해제하는 예제이다.
ON ZERODIVIDE
BEGIN;
DISPLAY('ZERODIVIDE condition raised');
END;
REVERT ZERODIVIDE;
A = B / 0;
"A = B / 0;" 구문에 의해 ZERODIVIDE 조건이 발생하지만, ON statement로 등록한 ON-unit이 REVERT statement로 해제되어 해당 ON-unit은 수행되지 않는다. 현재 등록되어 있는 ON-unit이 없을 경우 조건 특성에 따라 default action을 수행하는데, ERROR 조건을 발생시키거나 프로그램 수행을 계속한다. ZERODIVIDE는 default action으로 ERROR 조건을 발생시킨다.
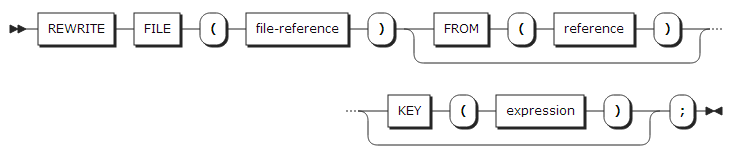
35. REWRITE statement
REWRITE statement는 데이터 셋의 레코드를 갱신한다.
| 항목 | 설명 |
|---|---|
FILE |
갱신할 파일을 지정한다. 파일은 반드시 UPDATE 속성을 가져야 한다. |
FROM |
레코드를 기록할 변수를 지정한다. 변수가 만일 배열이나 구조체일 경우 반드시 스토리지 상에 연결되어 있어야 한다. |
KEY |
지정한 KEY에 해당하는 레코드를 갱신한다. KEY 옵션을 사용하기 위해서는 파일은 DIRECT 속성을 가지거나 SEQUENTIAL KEYED 속성을 가져야 한다. |
36. SELECT statement
SELECT statement는 조건을 판정하여 그 결과에 따라 다중 분기를 나눌 수 있다.
SELECT statement는 1개 이상의 WHEN statement와 0 또는 1개의 OTHERWISE statement를 포함 할 수 있으며, SELECT statement는 END statement와 짝지어져야 한다.

| 항목 | 설명 |
|---|---|
SELECT (expression) |
SELECT 다음에 오는 expression은 계산되어 저장된다. |
WHEN (expression) unit |
WHEN 다음에 1개의 expression을 기술하거나 '&'와 '|'를 이용해서 여러 개의 expression들을 기술 가능하며, 각 expression은 계산되어 SELECT statement의 expression과 비교된다. WHEN Statement의 expression이 하나라도 SELECT statement의 expression과 동일할 경우 해당 unit이 수행된다. |
OTHERWISE unit |
SELECT 다음에 오는 expression이 모든 WHEN statement의 expression와 동일하지 않을 경우 OTHERWISE statement가 수행된다. OTHERWISE statement가 존재하지 않을 경우 SELECT statement는 종료된다. |
unit |
WHEN이나 OTHERWISE statement를 만족할 경우 수행될 statement들을 기술한다. unit은 하나의 statement, do-group 또는 begin-block이 될 수 있다. |
37. SIGNAL statement
SIGNAL statement는 사용자가 직접 ON-unit을 수행하도록 조건을 발생시킨다.

| 항목 | 설명 |
|---|---|
condition |
조건을 지정한다. 조건에 대한 설명은 조건 종류를 참고한다. |
사용자가 등록한 ON-unit이 있을 경우 해당 ON-unit을 수행하며, 사용자가 지정한 ON-unit이 없을 경우 내부적으로 지정된 default action을 수행하게 된다.
다음은 SIGNAL statement를 사용하여 사용자가 직접 ON-unit을 수행시키는 예제이다.
ON ZERODIVIDE
BEGIN;
DISPLAY('ZERODIVIDE condition raised');
END;
SIGNAL ZERODIVIDE;
SIGNAL statement로 인해 ZERODIVIDE 조건의 ON-unit이 수행된다. I/O 관련 조건의 경우 해당 조건이 발생하더라도 파일이 다를 경우 해당 ON-unit은 수행되지 않는다.
38. STOP statement
STOP statement는 현재 실행되고 있는 PL/I 프로그램을 종료한다. OpenFrame PL/I에서는 EXIT statement와 동일한 처리를 한다.
39. WHEN statement
WHEN statement에 대한 자세한 내용은 SELECT statement를 참고한다.
40. WRITE statement
WRITE statement는 데이터 셋에 레코드를 쓴다.
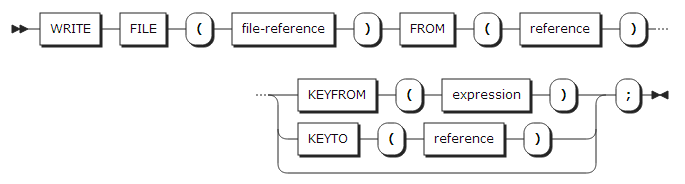
| 항목 | 설명 |
|---|---|
FILE |
기록할 파일을 지정한다. 파일은 OUTPUT 또는 UPDATE 속성을 가져야 한다. |
FROM |
레코드를 기록할 변수를 지정한다. 변수가 배열이나 구조체일 경우 반드시 스토리지 상에 연결되어 있어야 한다. |
KEYFROM |
기록할 레코드의 키를 지정한다. KEYFROM 옵션을 사용하기 위해서는 파일은 KEYED 속성을 가져야 한다. Indexed 데이터 셋에서는 KEYFROM의 값이 CHARACTER로 변환되고, Relative 데이터 셋에서는 FIXED DECIMAL로 변환된다. |
KEYTO |
레코드를 기록할 때 다음 기록될 키 값을 저장한다. KEYTO 옵션을 사용하기 위해서는 파일은 SEQUENTIAL KEYED 속성을 가져야 한다. |