ProSortの構文
本章では、ProSortのスクリプトでサポートする構文について説明します。
1. 概要
ProSortの構文は以下のカテゴリに区分されます。
-
演算方法
構文 説明 SORTやCOPY演算実行時のキー・フィールドを設定します。SORTの整列順序(昇順、降順)も設定します。
MERGE演算実行時のキー・フィールドを設定します。MERGEのマージ順序(昇順、降順)も設定します。
SORTとMERGEの演算方法を設定したり、オプションの情報(SKIPREC、STOPAFT)などを設定します。
-
レコードのフィルター処理
構文 説明 演算に含めるレコードの条件を設定します。
演算に含まれないレコードの条件を設定します。
複数の出力に含むまたは除くレコードの条件を追加設定します。
-
レコードの再フォーマット処理
構文 説明 演算を実行する前、レコードの形式を再設定します。
演算を実行した後、レコードの形式を再設定します。
複数の出力でレコードの形式を再設定します。
-
追加機能およびオプション
構文 説明 SORT演算、MERGE演算、レコードのフィルター処理、レコードの再フォーマット処理を実行するとき、ALTSEQ変換テーブルを使用します。
-
SORT、MERGE、INCLUDE、OMIT:AQ形式でALTSEQ変換テーブルを使用します。
-
INREC、OUTREC、OUTFIL OUTREC:TRAN=ALTSEQでALTSEQ変換テーブルを使用します。
ユーザーが任意にソート順序を設定します。
入力データの予想サイズを設定します。
レコード形式を設定します。
ProSortを終了し、END文以降の構文を無視します。
入力レコードを含んでいるファイルのパスを設定します。
指定したファイルの内容をスクリプトに挿入します。
演算を実行するとき使用するメモリのサイズを設定します。
ProSortのスクリプトを利用してユーザー出口関数を登録します。
同一キーを持つレコードの合計を設定します。
外部ソートで使用する一時ファイルが位置するディレクトリを設定します。
-
2. ALTSEQ
ALTSEQ変換テーブルを使用して特定文字のソート順序の一部を変更します。ALTSEQ構文はソートまたはマージ演算をするとき、ソート順序を調整する目的のみで使われ、実際に出力される文字列には影響を与えません。
ALTSEQ変換テーブルは以下の方法で使用できます。
-
SORT、MERGE、INCLUDE、OMITの場合
AQ形式を使用します。既存のデータはALTSEQ構文によって変換され、演算に適用されます。これを利用してキーの順序を変更したりフィルタリングの条件を変えて適用できます。
-
INREC、OUTREC、OUTFILE OUTRECの場合
TRAN=ALTSEQを使用して文字を変換します。既存のデータはALTSEQ構文によって変換され、次のプロセスに適用されます。
ALTSEQの詳細は以下のとおりです。
-
構文
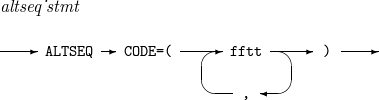 ALTSEQ
ALTSEQ -
構成要素
構成要素 説明 ff
変換する文字を2桁の16進数で表示したものです。
tt
変換された文字を2桁の16進数で表示したものです。
-
例
以下は、文字のX'5B’をX’EA’に変更してSORT演算を実行する例です。
SORT FILEDS=(1,8,AQ,A) ALTSEQ CODE=(5BEA)
以下は、文字のX'5B’をX’EA’に変更してMERGE演算を実行する例です。
MERGE FIELDS=(1,8,AQ,A) ALTSEQ=(5BEA)
以下は、COPY演算を実行し、レコードのうち1~80バイトを切断して出力する例です。ソート順序で文字のX'00’はX'40’に変換されます。
SORT FIELDS=(COPY) ALTSEQ CODE=(0040) OUTREC FIELDS=(1,80,TRAN=ALTSEQ)
3. COLSEQ
ユーザーが任意にソート順序を設定します。SORTまたはMERGE演算を実行する過程でソートを実行するため、文字列間を比較します。
整数間のサイズ比較(例:1<2)は直感的であるに対し、文字列間の比較はユーザーが直接把握することができません。文字列間の比較を正確に把握するには別途の規則が必要です。こうした規則をソート順序といいます。
たとえば、9とAをASCIIコードで表現するときは'9' < 'A’であるものの、EBCDICコードで表現するときは’A' < '9’です。ASCII、EBCDICコード以外にもユーザーが任意にソート順序を設定できます。これはCOLSEQ構文を使用して設定できます。
COLSEQの詳細は以下のとおりです。
-
構文
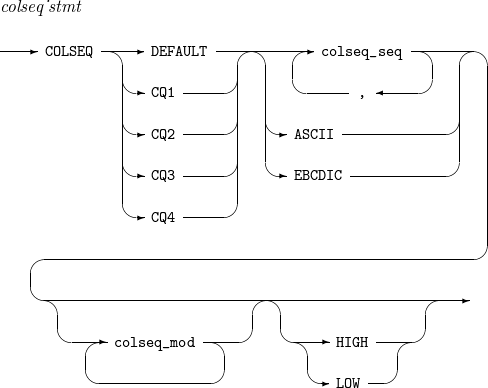

 COLSEQ
COLSEQ -
構成要素
構成要素 説明 DEFAULT
CH型フィールドのデフォルトのソート順序を設定します。
CQ1
CQ1型フィールドのソート順序を設定します。
CQ2
CQ2型フィールドのソート順序を設定します。
CQ3
CQ3型フィールドのソート順序を設定します。
CQ4
CQ4型フィールドのソート順序を設定します。
ASCII
ASCIIコードでソート順序を設定します。
EBCDIC
EBCDICコードでソート順序を設定します。
HIGH
ソート順序が設定されていない文字は、ソート順序が設定された文字より照合順序の値(collation value)が大きいです。(つまり、優先順位が低いです)
LOW
ソート順序が設定されていない文字は、ソート順序が設定された文字より照合順序の値(collation value)が小さいです。(つまり、優先順位が高いです)
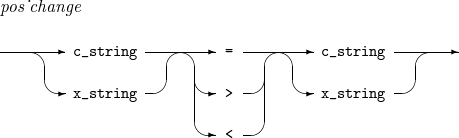
c_string
C’x1' または C’x1x2'。ここで、x1と x2は任意の文字です(ただし、引用符を含む一部の特殊文字を除く)
x_string
X’x1x2' または X’x1x2x3x4'。ここで、x1, ..., x4は任意の16進文字です。
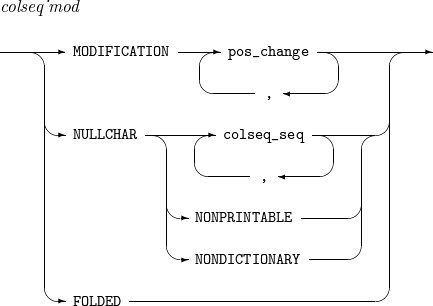
MODIFICATION
左側の文字の照合順序の値を右側の文字と等しく(=)設定するか、右側の文字より小さく(<)、または大きく(>)設定します。
NULLCHAR
ソート時に無視する文字を設定します。ソートする際に当該文字を除いてソート・キーを作成します。
NONPRINTABLE
画面に表示されない制御文字を示します。
NONDICTIONARY
英字、数字、空白、タブを除くすべての文字を示します。
FOLDED
すべての英文字の小文字はそれに対応する大文字と同じ照合順序の値を持ちます。
-
例
-
順序の指定
ユーザーは文字の列挙や文字の範囲(Range)で順序を指定できます。範囲を使用するときには同じ形式と長さで文字を指定する必要があります。
以下は、使用例です。
C'a'-C'z' C'AA'-C'AB' X'010f'-X'010f' X'10'-X'20'
以下は、使用できない例です。
C'a'-X'0f' C'A'-C'각'
-
MODIFICATION
以下は、文字aが文字zと同じ照合順序の値を持つ例です。
COLSEQ CQ1 ASCII MODIFICATION C'a' = C'z'
以下は、文字aの照合順序の値を文字dの照合順序の値より大きく、また文字eの照合順序の値よりは小さく指定する例です。
COLSEQ CQ1 ASCII MODIFICATION C'a' > C'd'
たとえば、昇順ソートの場合は、a、b、c、d、e、fのようなレコードは、b、c、d、a、e、fの順にソートされます。
以下は、上記と同じ結果を出す例であり、文字aの照合順序の値を文字eの照合順序の値より小さく、また文字dの照合順序の値よりは大きく指定します。
COLSEQ CQ1 ASCII MODIFICATION C'a' < C'e'
-
NULLCHAR
以下は、英字の小文字aが存在しないかのように動作する例です。
COLSEQ CQ1 ASCII NULLCHAR C'a'
たとえば、昇順ソートの場合は、aE、Da、aCa、aaBa、aaAaaのようなレコードは、aaAaa、aaBa、aCa、Da、aEの順にソートされます。
COLSEQ文にNULLCHAR、HIGH、LOWのいずれも設定されていない場合、COLSEQ文に記述されていないすべての文字がNULLCHARとして自動設定されます。
-
FOLDED
以下は、a ~ z、0 ~ 9の順にソートする例です。ソート順序が設定された文字(英字の小文字と数字)を除くすべての文字の照合順序の値を、ソート順序が設定された文字の照合順序の値より大きく指定します。
SORT FILEDS=(1,8,CQ1,A) COLSEQ CQ1 C'a'-C'z', C'0'-C'9' HIGH
以下は、ダブルバイト文字のX'010F’からX'01FF’までの順序でソートする例です。英字の小文字は存在しないかのように動作し、ソート順序が設定された文字(X'010F' ~ X'01FF’と英字の小文字)を除くすべての文字の照合順序の値を、ソート順序が設定された文字の照合順序の値より小さく設定します。
SORT FILEDS=(1,4,CQ2,A) COLSEQ CQ2 X'010F'-X'01FF' NULLCHAR C'a'-C'z' LOW
-
4. DATASIZE
入力データの予想サイズを設定します。ただし、ProSort APIを利用してスクリプトを呼び出すときのみ設定します。
DATASIZEの詳細は以下のとおりです。
-
構文
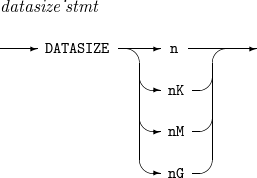 DATASIZE
DATASIZE -
構成要素
構成要素 説明 n
予想される入力データのサイズをバイト単位で設定します。
nK
予想される入力データのサイズをKB単位で設定します。
nM
予想される入力データのサイズをMB単位で設定します。
nG
予想される入力データのサイズをGB単位で設定します。
-
例
以下は、入力データの予想サイズを100MBに設定する例です。
DATASIZE 100M
5. DEFREC
レコード形式を設定します。
DEFRECの詳細は以下のとおりです。
-
構文
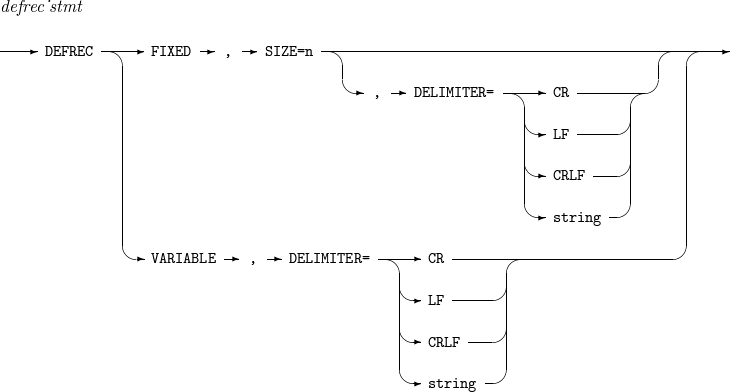 DEFREC
DEFREC -
構成要素
構成要素 説明 SIZE
入力レコードの長さを設定します。
DELIMITER
区切り文字を設定します。現在は改行文字のみサポートしています。
-
例
以下は、固定長レコードのサイズを10に設定する例です。
DEFREC FIXED, SIZE = 10
以下は、可変長レコードの区切り文字をCR(carriage return)に設定する例です。
DEFREC VARIABLE, DELIMITER = CR
6. END
スクリプトの実行を終了します。
ENDの詳細は以下のとおりです。
-
構文
 END
END -
構成要素
構成要素 説明 END
スクリプトの実行を終了します。スクリプトでEND文以降の構文は実行されません。
7. INCLUDE, OMIT
特定レコードを含めるか除外するときに使用します。
INCLUDE、OMITの詳細は以下のとおりです。
-
構文
 INCLUDE
INCLUDE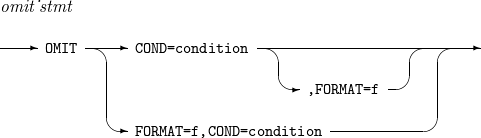 OMIT
OMIT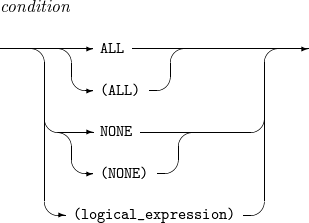


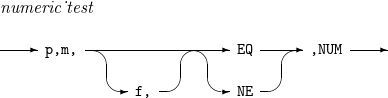 INCLUDE, OMIT - condition
INCLUDE, OMIT - condition -
構成要素
構成要素 説明 condition
INCLUDE文はレコードを含む条件を、OMIT文はレコードを排除する条件を指定します。
f
f1またはf2が省略された場合に使用するデフォルト・フォーマットを指定します。
ALL
INCLUDE文はすべてのレコードを含み、OMIT文はいかなるレコードも含みません。
NONE
INCLUDE文はいかなるレコードも含まず、OMIT文はすべてのレコードを含みます。
logical_expression
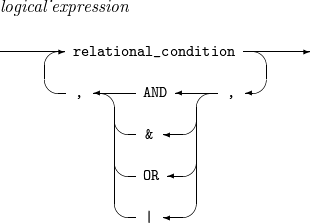
レコードを含む(除く)条件を指定する論理式です。
論理式は1つ以上の関係式をAND(または&)、OR(または|)、括弧を使用して結合したものです。
演算子の優先順位は、括弧、AND(または&)、OR(または|)の順であり、左の関係式から求められます。AND(または&)で結合された論理式は、論理式を構成する関係式がすべて真の場合に真になります。OR(または|)で結合された論理式は、論理式を構成する関係式のうち1つ以上が真の場合に真になります。
comparison
2つの対象(比較対象1と比較対象2)のサイズを比較する関係式です。
-
比較対象1は、入力レコードの p1 ~ (p1 + m1 - 1)番目のバイトをf1フォーマットで解析した値です。f1が省略された場合、fフォーマットで解析します。
-
比較対象2は、入力レコードの p2 ~ (p2 + m2 - 1)番目のバイトをf2フォーマットで解析した値または定数です。f2が省略された場合、fフォーマットで解析します。
使用可能な演算子は以下のとおりです。
-
EQ : 比較対象1と比較対象2のサイズが同じである場合、関係式は真になります。
-
NE : 比較対象1と比較対象2のサイズが異なる場合、関係式は真になります。
-
GT : 比較対象1が比較対象2より大きい場合、関係式は真になります。
-
GE : 比較対象1が比較対象2より大きいか同じである場合、関係式は真になります。
-
LT : 比較対象1が比較対象2より小さい場合、関係式は真になります。
-
LE : 比較対象1が比較対象2より小さいか同じである場合、関係式は真になります。
-
constant
comparisonを構成する定数です。詳細については、定数を参照してください。
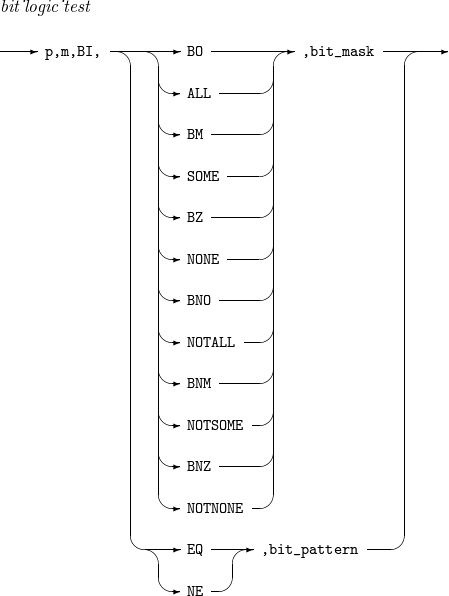
bit_logic_test
入力レコードのp ~ (p + m - 1)番目のバイトをBIフォーマットで解析してビット論理テストを行う関係式です。
-
ビットマスク(bit_mask)やビットパターン(bit_pattern)を利用してビット論理テストを行います。ビットマスクは16進(X’x1...xn')または2進(B’x1...xn')形式の文字列です。
-
ビットマスクのそれぞれのオン(1)ビットを入力フィールドの同じ位置上のビットと比較します。
使用可能な演算子は以下のとおりです。
-
BOまたはALL : 比較に参加したビットがすべてオンの場合、関係式は真になります。
-
BMまたはSOME : 比較に参加したビットの一部のみがオンの場合、関係式は真になります。
-
BZまたはNONE : 比較に参加したビットがいずれもオフの場合、関係式は真になります。
-
BNOまたはNOTALL : 比較に参加したビットがすべてオフであるか、一部がオンの場合、関係式は真になります。
-
BNMまたはNOTSOME : 比較に参加したビットがすべてオンであるか、すべてオフの場合、関係式は真になります。
-
BNZまたはNOTNONE : 比較に参加したビットのうちオンビットが存在する場合、関係式は真になります。
-
-
ビットパターンはB’x1...xn' 形式の文字列です。x1, ..., xnは、1、0またはピリオド(.)です。ビットパターンのオン(1)ビットとオフ(0)ビットをそれぞれ入力フィールドの同じ位置上のビットと比較します。
使用可能な演算子は以下のとおりです。
-
EQ : ビットパターンのオンビットそれぞれに対応する入力フィールドのビットがすべてオンであると同時に、ビットパターンのオフビットそれぞれに対応する入力フィールドのビットがすべてオフの場合、関係式は真になります。
-
NE : 関係式の結果は、EQ演算子を使用した場合と反対になります。
-
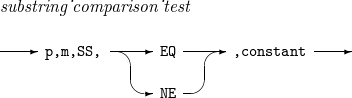
substring_ comparison_test
入力レコードのp ~ (p + m - 1)番目のバイトをCH型で解析して文字列定数と部分文字列の比較を行う関係式です。
-
mが文字列定数の長さより大きい場合、入力フィールド内で文字列定数を探し、そうでない場合は、文字列定数内で入力フィールド値を探します。
使用可能な演算子は以下のとおりです。
-
EQ : 比較対象間で部分文字列関係を見つけた場合、関係式は真になります。
-
NE : 関係式の結果は、EQ演算子を使用した場合と反対になります。
-
numeric_test
フィールド(入力レコードのp ~ (p + m - 1)番目のバイト)が数字形式であるかどうかを判断する関係式です。
x1y1...xmym
フィールドを16進数で表現した結果が上記のようであれば、演算子がEQの場合、関係式の結果は以下のとおりです。
-
fがCSF(またはFS)であるか、FORMAT=CSF(またはFS)が記述された場合 : x1=...=xm=3であり、0≤y1,...,ym≤9であれば、関係式は真になり、それ以外の場合は関係式は偽になります。
-
fがZDであるか、FORMAT=ZDが記述された場合 : x1=...=xm-1=3であり、xm∈{3,4,5,7}であり、0≤y1,…,ym≤9であれば、関係式は真になり、それ以外の場合は関係式は偽になります。
-
fがPDであるか、FORMAT=PDが記述された場合 : 0≤x1,...,xm≤9であり、0≤y1,...,ym-1≤ であり、ym∈{C,D,F} であれば、関係式は真になり、それ以外の場合は関係式は偽になります。
演算子がNEの場合の関係式の結果は、EQ演算子を使用した場合と反対になります。
-
-
例
以下は、5~12バイトが13~20バイトより大きいか105~108バイトが1000より小さい例です。
INCLUDE COND=(5,8,GT,13,8,|,105,4,LE,1000),FORMAT=CSF
以下は、OKという文字列が11~16バイト内にあるか、21 ~ 23バイトにJ69がある例です。
INCLUDE FORMAT=SS, COND(11,6, EQ, C'OK', OR, 21, 3, EQ, C'J69')
8. INFILE
入力ファイルのパス名と予想サイズを設定します。
INFILEの詳細は以下のとおりです。
-
構文

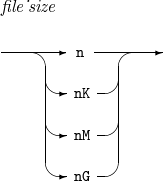 INFILE
INFILE -
構成要素
構成要素 説明 file_path
入力ファイルのパス名を設定します
file_size
入力ファイルの予想サイズを設定します
-
例
以下は、入力ファイルのパス名をINに、予想サイズを1MBに設定する例です。
INFILE=(IN,1M)
9. INREC, OUTREC
レコードの形式を再設定します。INRECはSORT、MERGE、COPY演算をする前に実行され、OUTRECはSORT、MERGE、COPY演算をした後に実行されます。
INREC、OUTRECの詳細は以下のとおりです。
-
構文
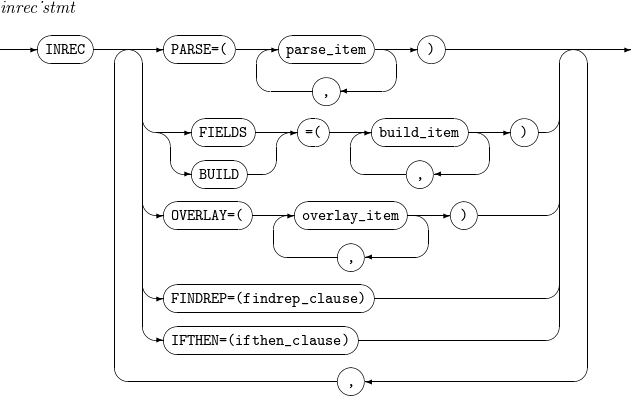 INREC
INREC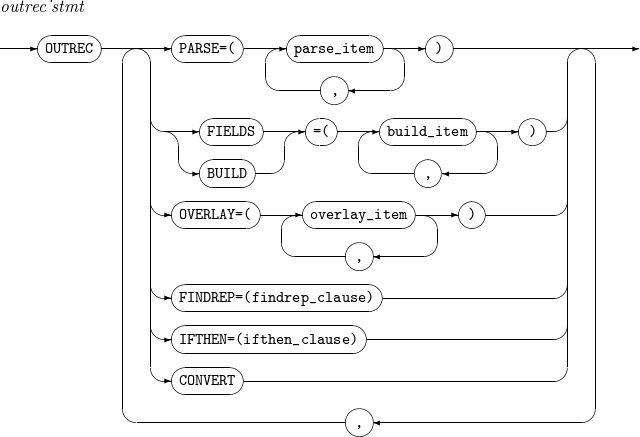 OUTREC
OUTREC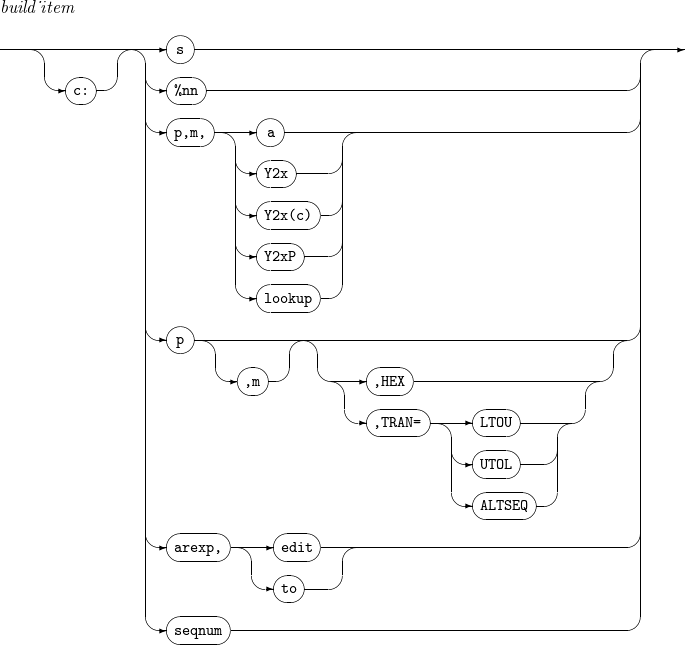
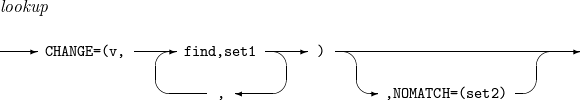

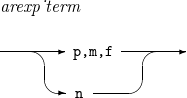

 INREC, OUTREC - build_item
INREC, OUTREC - build_item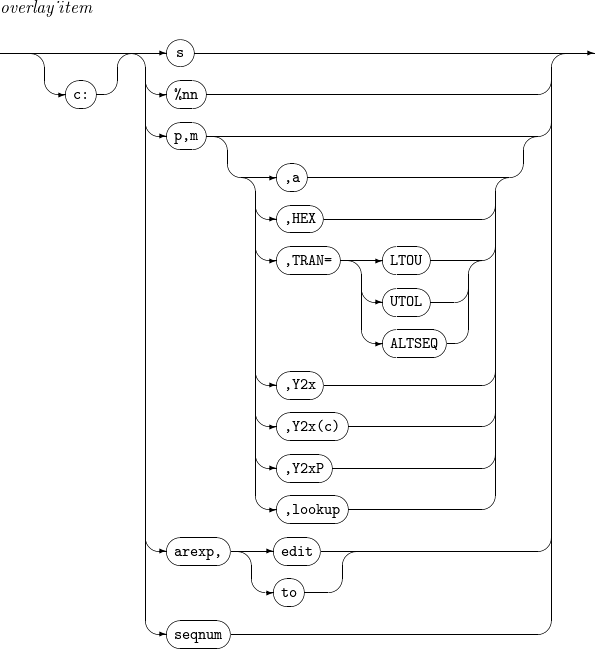 INREC, OUTREC - overlay_item
INREC, OUTREC - overlay_item INREC, OUTREC - findrep_clause
INREC, OUTREC - findrep_clause INREC, OUTREC - ifthen_clause
INREC, OUTREC - ifthen_clause -
構成要素
構成要素 説明 PARSE
parse_itemの説明を参照します。
CONVERT
可変長の入力レコードを固定長の出力レコードに変換します。
c
フィールドの位置を設定します。
フィールド前の未使用空間を空白で埋めます。たとえば、「30:C’Tmax'」を設定すると、29列まで空白で埋められ、30 ~ 33列に’Tmax’が挿入されます。また別の例で、「20:5,1」を設定すると、19列まで空白で埋められ、20列に入力フィールドの5番目のバイトが挿入されます。
s
セパレーション・フィールドを出力します。セパレーション・フィールドは次のいずれかです。
-
nX : 空白(X'20')をn個出力します。nを省略する場合、n=1と見なします。
-
nZ : Null(X'00')をn個出力します。nを省略する場合、n=1と見なします。
-
nC'...' : 単一引用符内の文字列をn回出力します。nを省略する場合、n=1と見なします。
-
nX'...' : 単一引用符内の16進数文字列をn回出力します。nを省略する場合、n=1と見なします。
-
DATE=(abcd) : 現在の日付を「C’adbdc'」形式で出力します。dは区切り子です。a,b,c∈{M,D,Y,4} であり、それぞれの意味は以下のとおりです。
-
M : 月(01~12)を2桁で出力します。
-
D : 日(01~31)を2桁で出力します。
-
Y : 年度の最後の2桁を出力します。
-
4 : 年度を4桁で出力します。
-
-
&DATE=(abcd) : DATE=(abcd)と同じです。
-
DATEまたは&DATE : DATE=(MDY/)と同じです。
-
DATENS=(abc) : 現在の日付を「C’abc'」形式で出力します。a,b,c∈{M,D,Y,4} であり、それぞれの意味は以下のとおりです。
-
M : 月(01~12)を2桁で出力します。
-
D : 日(01~31)を2桁で出力します。
-
Y : 年度の最後の2桁を出力します。
-
4 : 年度を4桁で出力します。
-
-
&DATENS=(abc) : DATENS=(abc)と同じです。
-
n/ :レコード区切り子をn個出力します。nを省略する場合、n=1と見なします。
%nn
解析済みの %nnラベルのフィールドを入力します。
p,m
既存のフィールドの位置および長さを設定します。最後のフィールドに限ってmを省略できます。mが省略された場合、既存のフィールドのp番目のバイトからレコードの最後までを意味します。
a
フィールドの位置揃えのフォーマットです。
位置揃えのフォーマットの種類は以下のとおりです。
-
H : Half word aligned(ハーフワード・アライメント)
-
F : Full word aligned(フルワード・アライメント)
-
D : Double word aligned(ダブルワード・アライメント)
HEX
16進数の値に変更された結果を出力します。
たとえば、文字列ABは、C1C2に変更されて出力されます
TRAN= [ LTOU | UTOL | ALTSEQ ]
-
TRAN=LTOUの場合、小文字を大文字に変換し、 TRAN=UTOLの場合、大文字を小文字に変換します。
-
TRAN=ALTSEQの場合、定義されたALTSEQテーブルを変換します。
lookup
フィールドで特定の文字列を探し、その結果に応じてフィールドの値を変更します。
-
v : フィールドの値を変更した後の長さを指定します。
-
find : フィールドで探す文字列を指定します。C’x1...xn'、X’x1...xn' または B’x1…xn'の形式です。
-
set1 : フィールドでfindに指定した文字列を見つけた場合、フィールドの値をここで指定した値に変更します。C’x1...xn' または X’x1...xn' 形式の定数であるか、p,m形式のフィールドです。
-
set2 : フィールドでfindに指定した文字列を見つけられなかった場合、フィールドの値をここで指定した値に変更します。C’x1...xn' または X’x1...xn'形式の定数であるか、p,m形式のフィールドです。
arexp
式の演算結果を出力します。
arexp_term
オペランドを指定します。
-
p,m,f : フィールドの位置、長さ、フォーマットを指定します。
-
n : 整数値を指定します。
arexp_operator
演算子を指定します。
-
MIN : オペランドのうち、小さい値が演算結果になります。
-
MAX : オペランドのうち、大きい値が演算結果になります。
-
MUL : オペランドを乗算した値が演算結果になります。
-
DIV : 左オペランドを右オペランドで割った商が演算結果になります。
-
MOD : 左オペランドを右オペランドで割った余りが演算結果になります。
-
ADD : オペランドを足した値が演算結果になります。
-
SUB : 左オペランドから右オペランドを引いた値が演算結果になります。
演算子の優先順位は以下のとおりです。
-
MIN, MAX
-
MUL, DIV, MOD
-
ADD, SUB
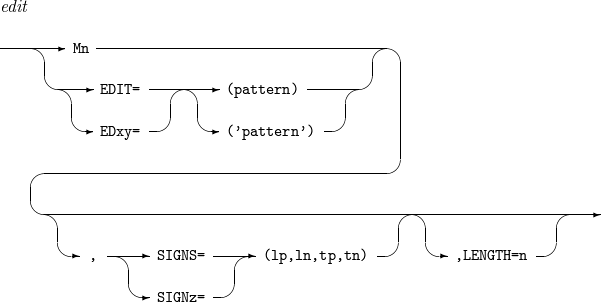
edit, to
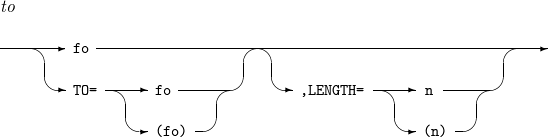
フィールドを希望する形式(fo)と長さ(n)に変更します。詳細については、エディット・マスク・パターンを参照してください。
seqnum
定められた規則に従って順番を出力します。
-
n : シーケンス番号を何桁で表示するかを指定します。
-
fs : シーケンス番号を表す文字列形式を指定します。
-
START=j : シーケンス番号の開始値を jに指定します。省略時は、START=1とみなされます。
-
INCR=i : シーケンス番号の増分値を iに指定します。省略時は、INCR=1とみなされます。
-
RESTART=(p,m) : 指定したフィールドが前のレコードのフィールドと一致しない場合、SEQNUMを1に初期化します。
findrep_clause
レコードでinconに指定された文字列を検索して、outconに指定された値に変更します。
-
incon : レコードで探す文字列を指定します。C’x1...xn'、nC’x1...xn'、X’x1...xn' または nX’x1...xn' の形式です。
-
outcon : 出力する文字列を指定します。C''、C’x1...xn'、nC’x1...xn'、X’x1...xn' または nX’x1...xn' の形式です。
-
p : 検索の開始位置を指定します。
-
q : 検索の終了位置を指定します。
WHEN=INIT, [ BUILD | OVERLAY | FINDREP ]
すべての入力レコードに対してBUILD、OVERLAY またはFINDREP演算を実行します。WHENがINITに設定されたIFTHEN文が実行された後、他のIFTHEN文が実行されます。
WHEN=(logical_expression), [ BUILD | OVERLAY | FINDREP ]
入力レコードが特定の条件(logical_expression)を満たす場合、BUILD、OVERLAYまたはFINDREP演算を実行します。
WHEN=GROUP
[,BEGIN=(logical_expression) |
,END=(logical_expression) |
,RECORDS=n]
,PUSH=(items)
すべての入力レコードに対してBEGIN、END、RECORD演算を実行します。条件を満たす場合、レコードはグループに割り当てられるか、グループから解放されます。
-
BEGIN=(logical_expression) : レコードが特定の条件(logical_expression)を満たす場合、当該レコードからグループが割り当てられます。
-
END=(logical_expression) : レコードが特定の条件(logical_expression)を満たす場合、当該レコードからグループが解放されます。
-
RECORDS=n : 1つのグループに属するレコードの数がnに達すると、グループは終了します。
-
PUSH=(items) : グループに属する場合、itemsに指定された内容をオーバーレイします。以下は、itemsの種類です。
-
c:p,m : グループの最初のレコードの p、mの値を位置 cにオーバーレイします。
-
c:ID=n : 長さ nのグループIDを表します。現在のグループIDを位置 cにオーバーレイします。
-
c:SEQ=n : 長さ nのグループのレコード・シーケンスを表します。現在のグループのレコード・シーケンスを位置 cにオーバーレイします。
-
-
-
例
以下は、同じ結果が出力される例です。
INREC FIELDS=(10,3,20,8) SORT FIELDS=(5,6,CH,A)
OUTREC FIELDS=(10,3,20,8) SORT FIELDS=(21,6,CH,A)
第1例の結果は入力レコードの10~12バイト、20~27バイトを新しいレコード(11バイト)に再構成し、再構成されたレコードの5~10バイトを基準にして昇順ソートします。第2例の結果は入力レコードの21~26バイトを基準にして昇順ソートします。
以下は、INREC、OUTRECを実行した例です。
INREC FIELDS=(14,4, 6,3) SORT FIELDS=(1,4,A, 5,3,A), FORMAT=AC OUTREC FIELDS=(3X, 1,4,H, 13:1,3, 5,2, 4X'61', X'0A')
入力レコード: ABCDE567LMNOP1234
上記の例を実行すると以下の結果が表示されます。
-
INRECを実行した後の結果
区分 説明 1 ~ 4バイト
入力レコードの14 ~ 17バイト ('1234')
5 ~ 7バイト
入力レコードの6 ~ 8バイト ('567')
-
OUTRECを実行した後の結果
区分 説明 1 ~ 3バイト
空白文字(20 20 20 in HEX)
4バイト
ハーフワード・アライメントのためにヌル文字をパディング (00 in HEX)
5 ~ 8バイト
INRECを実行した結果の1 ~ 4バイト ('1234')
9 ~ 12バイト
空白文字 (20 20 20 20 in HEX)
13 ~ 15バイト
INRECを実行した結果の1 ~ 3バイト ('123')
16 ~ 17バイト
INRECを実行した結果の5 ~ 6バイト ('56')
18 ~ 21バイト
0x61 ('aaaa')
22バイト
改行文字 (0A in HEX)
-
9.1. parse_item
parse_itemの詳細は以下のとおりです。
-
構文
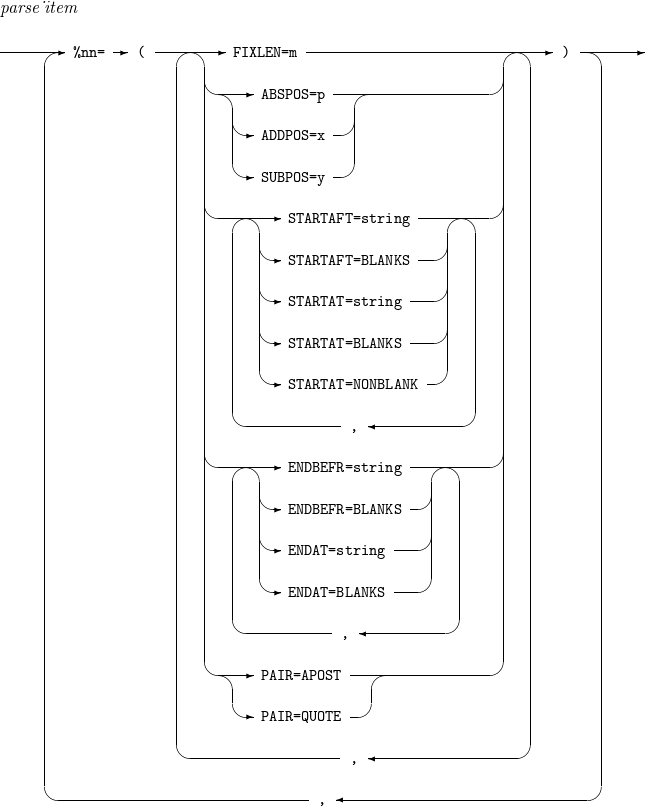 INREC, OUTREC - parse_item
INREC, OUTREC - parse_item -
構成要素
構成要素 説明 %nn
可変長の入力レコードを固定長の出力レコードに変換します。
解析済みフィールドは、BUILDまたはOVERLAY演算で(p,m)が使用される場所で使用できます。
FIXLEN=m
解析済みフィールドの長さを指定します。この属性はすべての解析フィールドに存在する必要があります。
ABSPOS=p
入力レコードで解析を開始する位置 pを指定します。
ADDPOS=x
入力レコードで解析を開始する位置を xだけ増加します。
SUBPOS=y
入力レコードで解析を開始する位置を yだけ減少します。
STARTAFT
-
STARTAFT=string : 入力レコードの最初の文字列の後から解析済みフィールドのレコードが始まります。
-
STARTAFT=BLANKS : 入力レコードの最初のブランク・グループの後から解析済みフィールドのレコードが始まります。
STARTAT
-
STARTAT=string : 入力レコードの最初の文字列から解析済みフィールドのレコードが始まります。
-
STARTAT=BLANKS : 入力レコードの最初のブランクから解析済みフィールドのレコードが始まります。
-
STARTAT=NONBLANK : 入力レコードの最初の非ブランクから解析済みフィールドのレコードが始まります。
ENDBEFR
-
ENDBEFR=string : 入力レコードの最初の文字列の前で解析済みフィールドのレコードが終わります。
-
ENDBEFR=BLANKS : 入力レコードの最初のブランクの前で解析済みフィールドのレコードが終わります。
ENDAT
-
ENDAT=string : 入力レコードの最初の文字列の最後のバイトで解析済みフィールドのレコードが終わります。
-
ENDAT=BLANKS : 入力レコードの最初のブランク・グループの終わりで解析済みフィールドのレコードが終わります。
PAIR
-
PAIR=APOST : アポストロフィ(')で囲まれた部分を文字列またはブランクとして扱いません。
-
PAIR=QUOTE : 引用符(")で囲まれた部分を文字列またはブランクとして扱いません。
-
10. INSERT
指定したファイルの内容をスクリプトに挿入します。
INSERTの詳細は以下のとおりです。
-
構文
 INSERT
INSERT -
構成要素
構成要素 説明 file_path
スクリプトに挿入するファイルのパス名です。
-
例
以下は、ins.scrファイルの内容をスクリプトに挿入する例です。
INSERT ins.scr
11. MEMORY
演算を実行するときに使用できるメモリのサイズを設定します。
MEMORYの詳細は以下のとおりです。
-
構文
 MEMORY
MEMORY -
構成要素
構成要素 説明 n
演算を実行時に使用できるメモリのサイズをバイト単位で設定します。
nK
演算を実行時に使用できるメモリのサイズをKB単位で設定します。
nM
演算を実行時に使用できるメモリのサイズをMB単位で設定します。
nG
演算を実行時に使用できるメモリのサイズをGB単位で設定します。
-
例
以下は、64MBのメモリを設定する例です。
MEMORY 64M
以下は、1GBのメモリを設定する例です。
MEMORY 1G
12. MODS
ProSortのスクリプトを利用してユーザー出口関数を登録します。
|
ユーザー出口関数の詳細については、ユーザー出口関数を参照します。 |
MODSの詳細は以下のとおりです。
-
構文
 MODS
MODS -
構成要素
構成要素 説明 func_name
登録する関数名です。
lib_path
動的に参照されるライブラリ・ファイルのパス名です。
lib_type
登録する関数がCOBOL言語で作成された場合はC、それ以外の場合はNです。
-
例
以下は、ユーザー出口関数E15にexit_none関数を登録し、ユーザー出口関数E32にexit_insert関数を登録する例です。動的に参照されるライブラリ・ファイルはlib_exit.soで設定します。
MODS E15 = (exit_none, /path/lib_exit.so, N), E32 = (exit_insert, /path/lib_exit.so, N)
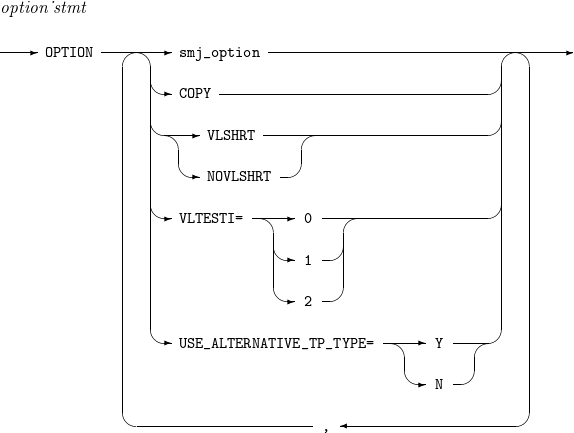
13. OPTION
USE_ALTERNATIVE_TP_TYPEなどのオプションを設定します。
OPTIONの詳細は以下のとおりです。
-
構文
 OPTION
OPTION -
構成要素
構成要素 説明 EQUALS
ソートの基準フィールドの値が同じレコードを同率(tie)レコードといいます。EQUALSオプションを指定すると、入力レコードをソートする際に同率のレコード間の相対的な順序が変更されません。
NOEQUALS
NOEQUALSオプションを指定すると、入力レコードをソートする際に同率のレコード間の相対的な順序が保存されません。
SKIPREC=n
入力レコードのうち最初のn個を除き残りのレコードをE15ユーザー出口、またはINCLUDE/OMIT文処理ルーチンに渡します。(2.4.1節の図を参照)
STOPAFT=n
INREC文処理ルーチン(INREC文が存在する場合)またはSORT/COPY文処理ルーチン(INREC文が存在しない場合)にn個のレコードを渡したら、それ以上レコードを渡しません。(2.4.1節の図を参照)
[ CENTURY | CENTWIN | Y2PAST ] = [ s | f ]
Y2xフォーマット・フィールドには4桁の年度の下の2桁だけ保存され、Y2PASTオプション値(century window)が不足する情報を補います。
CENTURYとCENTWINはY2PASTの同意語です。
Y2PASTオプション値は次の2つの形式のいずれかで記述されます
-
s : sliding century window。0~100の整数です。Y2xフォーマット・フィールドに保存された年度を、(現在の年度 - s) ~ (現在の年度 - s + 99)の値で解析します
-
f : fixed century window。1000~3000の整数です。Y2xフォーマット・フィールドに保存された年度をf ~ (f + 99)の値で解析します
COPY
COPY演算を実行します
MSGPRT
メッセージの出力対象を指定します。(別名: PRINT)
ProSortでは構文エラーのみチェックします。
VLSHRT
SORT、MERGE、FILTER(INCLUDE, OMIT)、SUM演算で指定されたフィールドが入力レコードに存在しないか一部のみ存在する場合の動作を定義します。
詳細については、例を参照してください。
NOVLSHRT
SORT、MERGE、FILTER(INCLUDE, OMIT)、SUM演算で指定されたフィールドが入力レコードに存在しないか一部のみ存在する場合の動作を定義します。
オプションを設定しない場合、デフォルト値はNOVLSHRTになります。
詳細については、例を参照してください。
VLTESTI=(0 | 1 | 2)
INCLUDEまたはOMIT演算で、指定されたフィールドが入力レコードに存在しない場合、または一部のみ存在する場合の動作を定義します。
以下は、設定値についての説明です。
-
0 : INCLUDEまたはOMIT演算で、指定されたすべてのフィールドの完全な範囲が入力レコードに存在する必要があります。そうでない場合、エラーが発生します。VLTESTIオプションが指定されていない場合は、VLTESTI=0が指定された場合と同様に動作します。
-
1 : INCLUDE演算で、指定されたフィールドが入力レコードに存在しないか、一部のみ存在する場合、レコードを出力しません。OMIT演算では、指定されたフィールドが入力レコードに存在しないか、一部のみ存在する場合、レコードを出力します。
-
2 : INCLUDEまたはOMIT演算で、指定されたフィールドが入力レコードに存在しないか、一部のみ存在する場合、関係式を「偽」と判断します。
USE_ALTERNATIVE_TP_TYPE
TPデータ型の場合、正数を表現する2つの方式があります。詳細については、その他の情報を参照してください。
-
-
例
VLSHRTを設定すると各演算は以下のように動作します。
-
SORT、MERGE
指定されたフィールドが入力レコードに存在しないか一部のみ存在する場合、バイナリゼロで埋めて演算を実行します。
SORT FIELDS=(1,2,CH,A) 入力: A B AA BB 出力: A AA B BB
-
INCLUDE, OMIT
指定されたフィールドが入力レコードに存在しないか一部のみ存在する場合、当該関係式をfalseで演算します。
INCLUDE COND=(1,2,CH,EQ,C'AA') 入力: A AA B BB 出力: AA
-
SUM
指定されたフィールドが入力レコードに存在しないか一部のみ存在する場合、当該レコードをSUM演算から除外します。
SORT FIELDS=(1,1,CH,A) SUM FIELDS=(2,2,ZD) 入力: A03 A04 B B05 C 出力: A07 B05
-
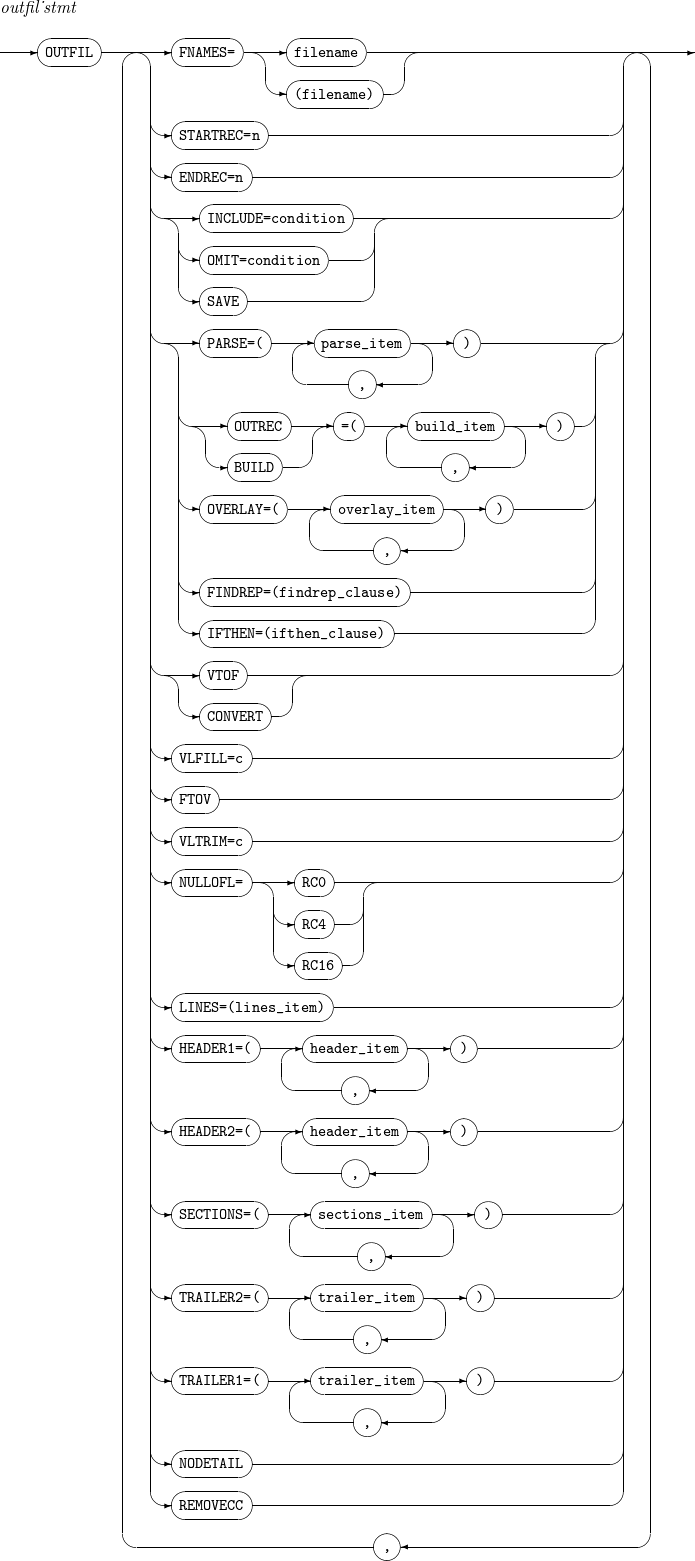
14. OUTFIL
SORT、MERGE、COPY演算の結果を多様に出力します。(別名: OUTFILE)
OUTFILの詳細は以下のとおりです。
-
構文
 OUTFIL
OUTFIL -
構成要素
outfil_elementのリストで多様な出力方法を定義します。
構成要素 説明 filename
出力するファイルの名前を定義します。
STARTREC=n
演算結果のレコードのうち、n番目レコードから出力します。
ENDREC=n
演算結果のレコードのうち、n番目のレコードまで出力します。STARTRECオプションが宣言された場合、STARTRECオプション以後からn番目のレコードまでを出力します。
INCLUDE=condition
演算結果のレコードのうち、条件に適合するレコードのみ出力します。詳細については、INCLUDE, OMITを参照します。
OMIT=condition
演算結果のレコードのうち条件に適合するレコードを除外します。詳細については、INCLUDE, OMITを参照します。
SAVE
他のOUTFILでINCLUDEまたはOMITの条件として出力されたレコードを除外して残ったレコードを出力します。
OUTREC または BUILD
INREC, OUTRECを参照します。
OVERLAY
INREC, OUTRECを参照します。
FINDREP
INREC, OUTRECを参照します。
IFTHEN
INREC, OUTRECを参照します。
VTOF または CONVERT
可変長入力レコードを固定長出力レコードに変換します。
VLFILL=c
フィールドが入力レコードに存在しないか一部のみ存在する場合、右側を文字cで埋めます。
FTOV
固定長入力レコードを可変長出力レコードに変換します。
VLTRIM=c
結果レコードの右端に1つまたはそれ以上の文字cが存在する場合、それを削除します。
NULLOFL= [ RC0 | RC4 | RC16 ]
演算結果のレコード件数が0件の場合の動作を指定します。
-
RC0 : 戻り値を0に設定し、演算を続けます。
-
RC4 : 戻り値を4に設定し、演算を続けます。
-
RC16 : 演算を中止し、16を返します。
LINES=n
レポートを出力する際に1ページに出力する行数をnで指定します。
HEADER1
文書のヘッダーを定義します。詳細については、header_itemを参照してください。
HEADER2
ページのヘッダーを定義します。詳細については、header_itemを参照してください。
SECTIONS
セクションに定義されたデータが変更されるたびにヘッダーまたはトレーラーを挿入します。SECTIONはsections_itemを使って複数定義できます。
詳細については、sections_itemを参照してください。
TRAILER2
ページのトレーラーを定義します。詳細については、trailer_itemを参照してください。
TRAILER1
文書のトレーラーを定義します。詳細については、trailer_itemを参照してください。
NODETAIL
結果レコードのうち、データ・レコードを除いてレポートのみ出力します。
REMOVECC
結果レコードでANSI制御文字を除いて出力します。
-
-
例
以下は、演算結果のうち15~20バイトがAAAのレコードはファイルAAAに、15~20バイトがBBBのレコードはファイルBBBに、それ以外のレコードはUNKNOWNに出力する例です。
OUTFIL INCLUDE=(15,6,AC,EQ,C'AAA'), FNAMES=AAA OUTFIL INCLUDE=(15,6,AC,EQ,C'BBB'), FNAMES=BBB OUTFIL SAVE, FNAME=UNKNOWN
14.1. header_item
header_itemの詳細は以下のとおりです。
-
構文
 OUTFIL - header_item
OUTFIL - header_item -
構成要素
構成要素 説明 s
n’xx...x’形式で文字列が何回繰り返されるかを設定します。
p,m
開始位置と長さを意味し、フィールドを表示します。
DATENS=(abc)
日付の表現形式を定義します。3文字で構成され、各文字はM、D、Y、4のうち1つの値を持ちます。ただし、各文字は2回以上定義できません。
-
M : 月(01~12)
-
D : 日(01~31)
-
Y : 年度の下の2桁
-
4 : 4桁の年度(0001~9999)
abcに表現された文字の順でトークン(年、月、日)を表示します。たとえば、DATENS=(DMY)に設定した場合、2009年6月3日は「030609」のように表現されます。
DATE=(abcd)
日付の表現形式を定義します。4文字で構成されます。
-
前の3文字 : DATENSのabcと同じです。
-
最後の文字 : 各トークン(年、月、日)の間に挿入される区切り文字です。
たとえば、DATE=(4MD-)に設定した場合、2009年6月3日は「2009-06-03」のように表現されます。
TIMENS=(ab)
時間の表現形式を定義します。12、24のうち1つの値を持ちます。
-
abが24であれば、時間はhhmmss(24-hour clock)で表現されます。
-
hh : 時(00~23)
-
mm : 分(00~59)
-
ss : 秒(00~59)
-
たとえば、午後4時15分37秒は「161537」のように表現されます。
-
abが12であれば、時間はhhmmss xx(12-hour clock)で表現されます。
-
hh : 時(01~12)
-
mm : 分(00~59)
-
ss : 秒(00~59)
-
xx : 午前であればam、午後であればpmで表現されます。
-
たとえば、午後4時15分37秒は「041537 pm」で表現されます。
TIME=(abc)
時間の表現形式を定義します。3文字で構成されます。
-
前の2文字 : TIMENSのabと同じです
-
最後の文字 : 各トークン(時、分、秒)の間に挿入される区切り文字です。
たとえば、TIME=(12.)に設定した場合、午後4時15分37秒は「04.15.37 pm」で表現されます。
PAGE
ページ番号を出力します。editとtoについては、INREC, OUTRECを参照してください
-
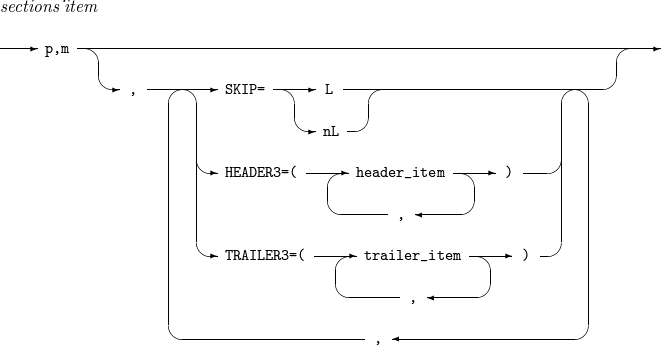
14.2. sections_item
sections_itemの詳細は以下のとおりです。
-
構文
 OUTFIL - sections_item
OUTFIL - sections_item -
構成要素
構成要素 説明 p,m
出力レコードの p ~ (p + m - 1)番目のバイトをセクション・フィールドとします。
最初のレコードを出力する前に最初のセクションのヘッダーを出力します。現在レコードのセクション・フィールドの値が直前のレコードのセクション・フィールドの値と異なる場合は、前のセクションのトレーラーと現在のセクションのヘッダーを出力します。最後のレコードを出力した後、最後のセクションのトレーラーを出力します。editとtoについては、INREC, OUTRECを参照してください。
SKIP=L
1つのセクションが終わり、次のセクションが始まる前に空行を1行出力します
SKIP=nL
1つのセクションが終わり、次のセクションが始まる前に空行をn行出力します
HEADER3
セクションのヘッダーを定義します。詳細については、header_itemを参照してください
TRAILER3
セクションのトレーラーを定義します。詳細については、trailer_itemを参照してください
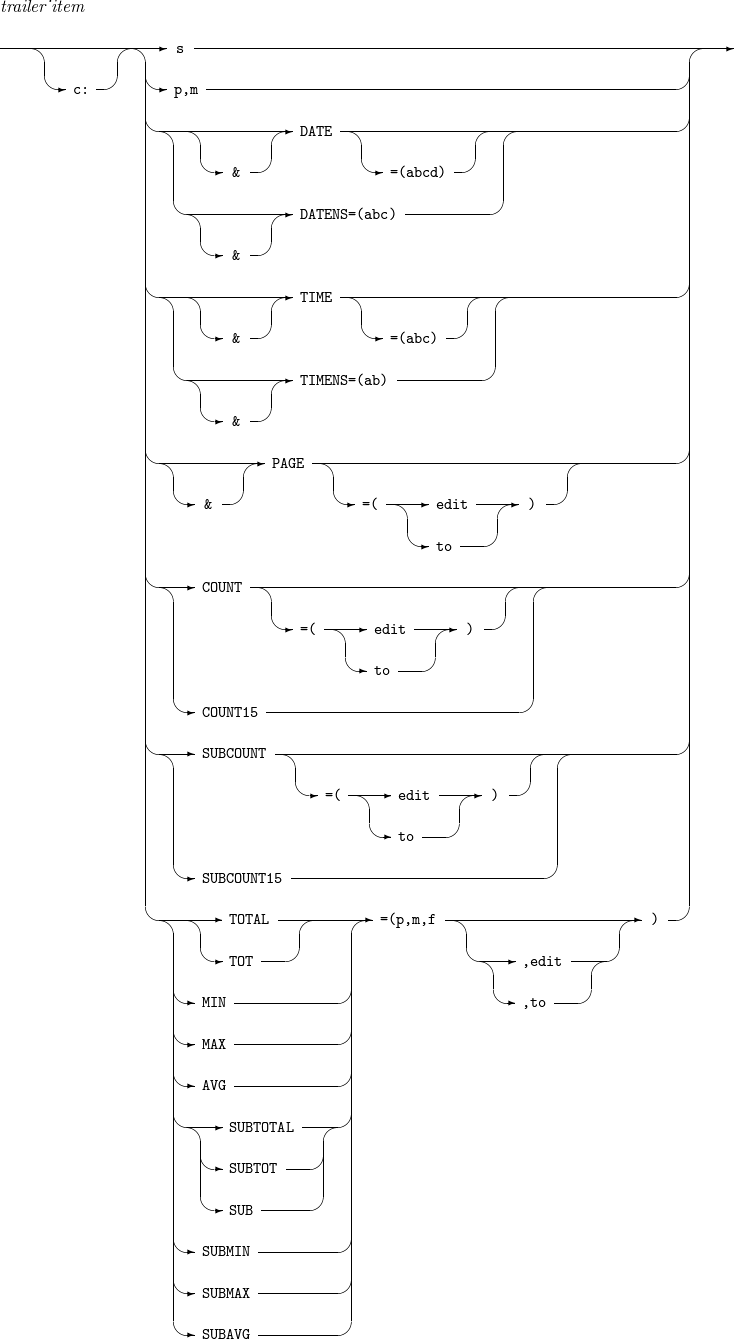
14.3. trailer_item
trailer_itemの詳細は以下のとおりです。
-
構文
 OUTFIL - trailer_item
OUTFIL - trailer_item -
構成要素
構成要素 説明 s
header_itemを参照します。
p,m
header_itemを参照します。
DATENS=(abc)
header_itemを参照します。
DATE=(abcd)
header_itemを参照します。
TIMENS=(ab)
header_itemを参照します。
TIME=(abc)
header_itemを参照します。
PAGE
header_itemを参照します。
COUNT
-
文書のトレーラー
文書全体の出力レコードの数を出力します。
-
ページのトレーラー
現在のページに出力されたレコードの数を出力します。セクションのトレーラーの場合は、現在のセクションに出力されたレコードの数を出力します。
editとtoについては、INREC, OUTRECを参照してください。editとtoが記述されていない場合は、8桁の整数で出力します。
COUNT15
15桁の整数で出力することを除けば、COUNTと同じです。
SUBCOUNT
-
文書のトレーラー
文書全体の出力レコードの数を出力します。
-
ページのトレーラー
現在のページに出力されたレコードの累積数を出力します。セクションのトレーラーの場合は、現在のセクションまで出力されたレコードの累積数を出力します。
editとtoについては、INREC, OUTRECを参照してください。editとtoが記述されていない場合は、8桁の整数で出力します。
SUBCOUNT15
15桁の整数で出力することを除けば、SUBCOUNTと同じです。
TOTAL または TOT
出力レコードの p ~ (p + m - 1)番目のバイトを集計フィールドとします。
-
文書のトレーラー
文書全体の出力レコードの集計フィールドを fフォーマットで解析した値の合計を出力します。
-
ページのトレーラー
現在のページに出力されたレコードの集計フィールドを fフォーマットで解析した値の合計を出力します。
-
セクションのトレーラー
現在のセクションに出力されたレコードの集計フィールドを fフォーマットで解析した値の合計を出力します。
editとtoについては、INREC, OUTRECを参照してください。
MIN
出力レコードの p ~ (p + m - 1)番目のバイトを集計フィールドとします。
-
文書のトレーラー
文書全体の出力レコードの集計フィールドを fフォーマットで解析した値の最小値を出力します。
-
ページのトレーラー
現在のページに出力されたレコードの集計フィールドを fフォーマットで解析した値の最小値を出力します。
-
セクションのトレーラー
現在のセクションに出力されたレコードの集計フィールドを fフォーマットで解析した値の最小値を出力します。
editとtoについては、INREC, OUTRECを参照してください。
MAX
出力レコードの p ~ (p + m - 1)番目のバイトを集計フィールドとします。
-
文書のトレーラー
文書全体の出力レコードの集計フィールドを fフォーマットで解析した値の最大値を出力します。
-
ページのトレーラー
現在のページに出力されたレコードの集計フィールドを fフォーマットで解析した値の最大値を出力します。
-
セクションのトレーラー
現在のセクションに出力されたレコードの集計フィールドを fフォーマットで解析した値の最大値を出力します。
editとtoについては、INREC, OUTRECを参照してください。
AVG
出力レコードの p ~ (p + m - 1)番目のバイトを集計フィールドとします。
-
文書のトレーラー
文書全体の出力レコードの集計フィールドを fフォーマットで解析した値の平均値を出力します。
-
ページのトレーラー
現在のページに出力されたレコードの集計フィールドを fフォーマットで解析した値の平均値を出力します。
-
セクションのトレーラー
現在のセクションに出力されたレコードの集計フィールドを fフォーマットで解析した値の平均値を出力します。
editとtoについては、INREC, OUTRECを参照してください。
[ SUBTOTAL | SUBTOT | SUB ]
出力レコードの p ~ (p + m - 1)番目のバイトを集計フィールドとします。
-
文書のトレーラー
文書全体の出力レコードの集計フィールドを fフォーマットで解析した値の合計を出力します。
-
ページのトレーラー
現在のページに出力されたレコードの集計フィールドを fフォーマットで解析した値の合計を出力します。
-
セクションのトレーラー
現在のセクションに出力されたレコードの集計フィールドを fフォーマットで解析した値の合計を出力します。
editとtoについては、INREC, OUTRECを参照してください。
SUBMIN
出力レコードの p ~ (p + m - 1)番目のバイトを集計フィールドとします。
-
文書のトレーラー
文書全体の出力レコードの集計フィールドを fフォーマットで解析した値の最小値を出力します。
-
ページのトレーラー
現在のページに出力されたレコードの集計フィールドを fフォーマットで解析した値の最小値を出力します。
-
セクションのトレーラー
現在のセクションに出力されたレコードの集計フィールドを fフォーマットで解析した値の最小値を出力します。
editとtoについては、INREC, OUTRECを参照してください。
SUBMAX
出力レコードの p ~ (p + m - 1)番目のバイトを集計フィールドとします。
-
文書のトレーラー
文書全体の出力レコードの集計フィールドを fフォーマットで解析した値の最大値を出力します。
-
ページのトレーラー
現在のページに出力されたレコードの集計フィールドを fフォーマットで解析した値の最大値を出力します。
-
セクションのトレーラー
現在のセクションに出力されたレコードの集計フィールドを fフォーマットで解析した値の最大値を出力します。
editとtoについては、INREC, OUTRECを参照してください。
SUBAVG
出力レコードの p ~ (p + m - 1)番目のバイトを集計フィールドとします。
-
文書のトレーラー
文書全体の出力レコードの集計フィールドを fフォーマットで解析した値の平均値を出力します。
-
ページのトレーラー
現在のページに出力されたレコードの集計フィールドを fフォーマットで解析した値の平均値を出力します。
-
セクションのトレーラー
現在のセクションに出力されたレコードの集計フィールドを fフォーマットで解析した値の平均値を出力します。
editとtoについては、INREC, OUTRECを参照してください。
-
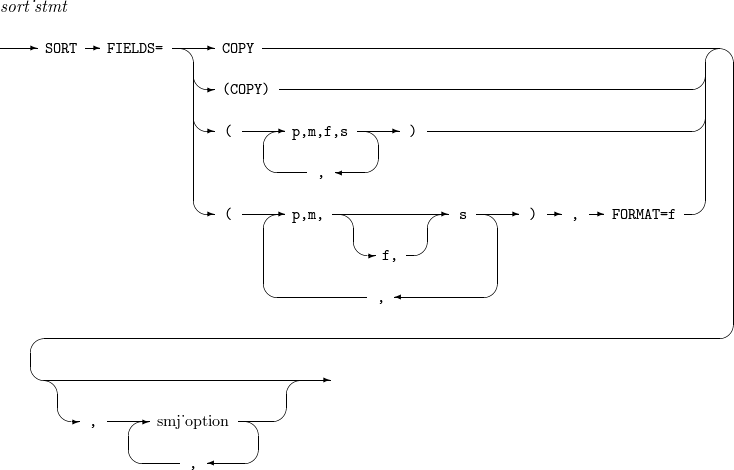
15. SORT, MERGE
SORTおよびMERGE演算はフィールド・リストと追加オプションで構成します。フィールド・リストですべて同じ形式を使用するときは、形式情報をフィールド・リストの後に一度だけ設定します。
SORT、MERGEの詳細は以下のとおりです。
-
構文
 SORT
SORT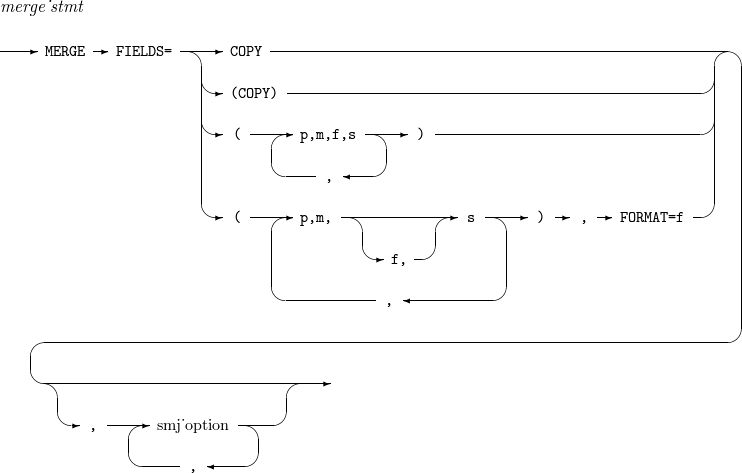 MERGE
MERGE SORT, MERGE - smj_option
SORT, MERGE - smj_option -
構成要素
構成要素 説明 COPY
SORT演算の代わりにCOPY演算を実行します。詳細については、OPTIONのCOPYオプションを参照してください。
p,m,f,s
入力レコードの p ~ (p + m - 1)番目のバイトをfフォーマットで解析した値を基準にレコードを昇順(sがAの場合)または降順(sがDの場合)でソートします。
fが省略された場合、FORMATオプションに指定されたフォーマットを使用します。
smj_option
OPTIONを参照します。
-
例
以下は、3~10バイトのZDを昇順でソートし、40~45バイトのACを降順でソートする例です。
SORT FIELDS=(3,8,ZD,A,40,6,AC,D)
以下は、3~10バイトのZDを昇順でソートし、40~45バイトのACを降順でソートする例です。同一キーの場合、入力するときにソート順序を保証する安定なソート(stable sort)で実行します。
SORT FIELDS=(3,8,ZD,A,40,6,AC,D), EQUALS
以下は、3~10バイトのZDを昇順でソートし、40~45バイトのACを降順でソートする例です。SKIPREC、STOPAFTオプションを追加適用して101~300間のレコードのみソートして出力することができます。
SORT FIELDS=(3,8,ZD,A,40,6,AC,D), SKIPREC = 100, STOPAFT = 200
以下は、25 ~ 28バイト、48 ~ 55バイトのすべてのZDを昇順でマージする例です。
MERGE FIELDS=(25,4,A,48,8,A),FORMAT=ZD
以下は、COPY演算のみを実行する例です。
MERGE FIELDS=COPY
SORT FIELDS=COPY
16. SUM
SORTまたはMERGE演算を実行した後、同率のレコードのうち1つのみを出力すると共に、指定された領域(合計フィールド)には同率のレコードの合計フィールドの合計を出力します。
SUMの詳細は以下のとおりです。
-
構文
 SUM
SUM -
構成要素
構成要素 説明 NONE
SORTまたはMERGE演算を実行した後、同率のレコードのうち1つのみを出力します。
p,m,f
入力レコードの p ~ (p + m - 1)番目のバイトを合計フィールドとして指定します。
同率のレコードのうち1つのみを出力すると共に、出力レコードの p ~ (p + m - 1)番目のバイトには、同率のレコードの合計フィールドをfフォーマットで解析した値の合計をfフォーマットで出力します。fが省略された場合、FORMATオプションに指定されたフォーマットを使用します。
-
例
以下は、21バイトに位置する8バイトPDと11バイトに位置する4バイトの固定長整数フィールド(fixed integer fields)を合計フィールドに設定する例です。
SUM FIELDS=(21,8,PD,11,4,FI)
以下は、合計フィールドを設定しない例です。同じキーを持つ重複レコードのみ削除します。
SUM FIELDS=NONE
以下は、41バイトに位置する8バイトZDと49バイトに位置する4バイトZDを合計フィールドに設定する例です。
SUM FIELDS=(41,8,49,4),FORMAT=ZD
