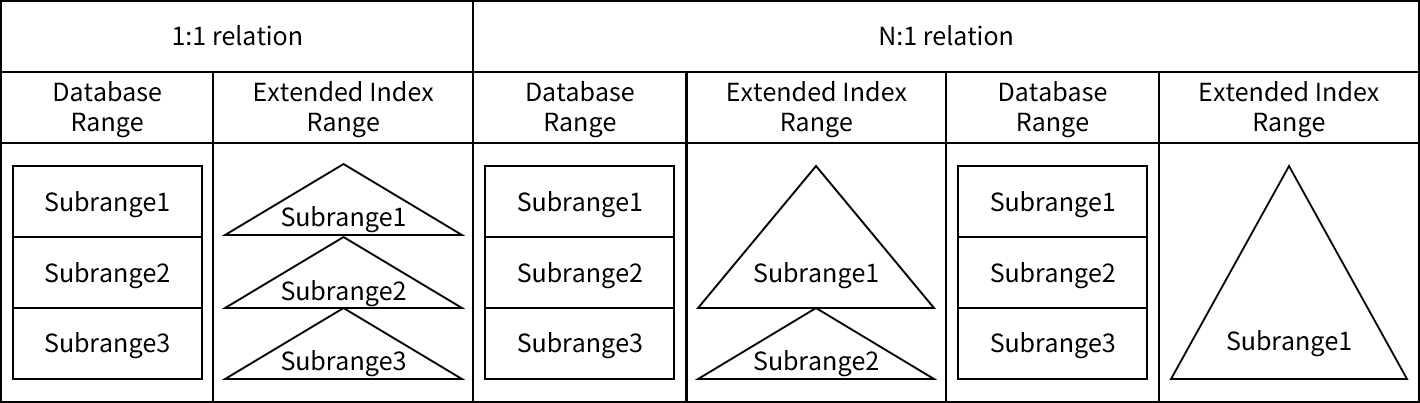
OpenFrame NDBの構造と機能
本章では、OpenFrame NDBの基本構造および機能について記述し、富士通AIM/DBと異なる構造について比較して説明します。
1. NDBの構造
NDBは、ネットワーク型データベースです。富士通メインフレームで使用されるAIM/DBをリホストするために開発されており、基本的には富士通AIM/DBの機能と構造に従います。ただし、NDBはRDBをベースにしているため、AIM/DBとは構造が若干異なります。
NDBは、データベースのDDLとDMLのSQL組み合わせで論理構造を設計しており、物理構造はDBMSに委任して処理するように構成されています。この節では、AIM/DBの構造を基にしてNDBの構造について説明します。
AIM/DBは、次の3つの構造に分けられます。
| 区分 | 説明 |
|---|---|
論理構造(Logical Structure) |
データ項目間の論理的な関係について記述します。 |
格納構造(Locative Structure) |
データが論理的に保存される場所および方法について記述します。 |
物理構造(Physical Structure) |
データが物理的に保存される場所について記述します。 |
そのほか、アプリケーションからデータベースを参照する方法を決める仮想論理構造(Virtual Logical Structure)があります。
1.1. スキーマとサブスキーマ
NDBでは、AIM/DBのデータ定義言語であるADL(AIM Description Language)のSCHEMAとSUBSCHEMAコマンドを使用してデータベースを定義します。
| 区分 | 説明 |
|---|---|
スキーマ |
データベースの論理構造、格納構造、物理構造を定義します。 |
サブスキーマ |
アプリケーションから見たデータベースの構造である仮想論理構造を定義します。 1つのスキーマは1つのデータベースのみ定義でき、1つのサブスキーマは複数のデータベースを同時に定義することができるため、複数のデータベースを含みます。 |
|
ADLを使用してスキーマとサブスキーマを作成する方法および構文については、富士通の『OS IV AIM ADL REFERENCE MANUAL(V20L10)』を参照してください。 |
2. 論理構造
論理構造は、データベースに保存されるレコードと、各レコード間の関係および保存型について定義した構造です。論理構造を構成する最も基本的な要素はレコードとセットです。そのほか、論理接続(Logical connection)などの特徴があります。NDBは、RDBのDDLとDMLのSQL組み合わせで論理構造を設計しています。
2.1. レコード
レコードは、データベースにアクセスする際に最も基本となるデータ単位です。実際に意味のあるデータが含まれている情報の単位をレコード、またはレコード・オカレンス(Record occurrence)といい、これらのレコードの集合をレコード型と呼びます。
レコード型はデータ項目で構成されます。各データ項目には一意の名前が付けられ、英字、数字、英数字を使用できます。レコード型は、名前、エントリ・メソッドなどの固有の属性を持ちます。
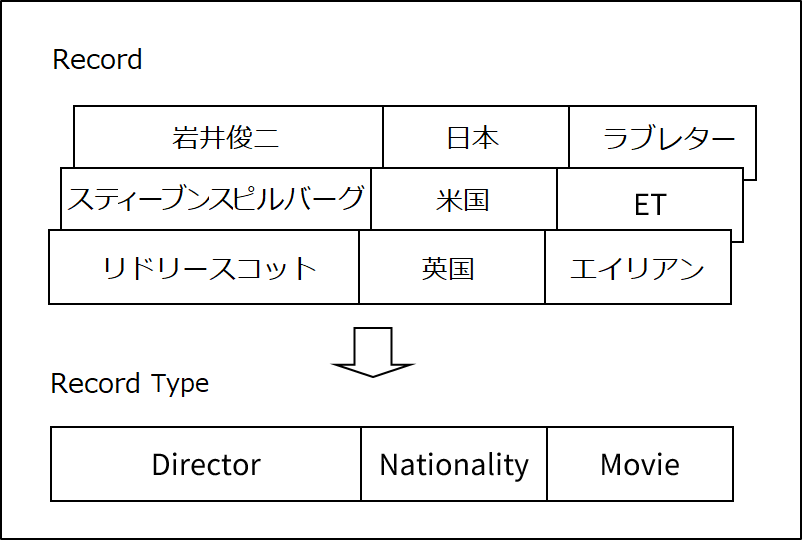
NDBのレコード型は、データベースの表として構成されます。レコードは表の行として構成され、データ項目は表の列として構成されます。
-
OCCURRENCE ID
レコード・テーブルに保存できるレコード値(行)には、レコードを識別するための8バイトID値であるOCCURRENCE ID(OCC_ID)が含まれています。この値は、NDBプログラムでレコードを識別するための位置情報であるPGCSとして使用されます。OCCURRENCE IDは、レコード・タイプを識別するためのIDと各レコード値を保存するときにRDBシーケンスによって付与されるIDを組み合わせて決定されます。したがって、各レコード・タイプごとに保存できるレコードの最大数は、4バイトの符号なし整数の最大値である4294967295です。
OCCURRENCE IDのうち、レコード値のIDはシーケンスによって付与されるため、既存のレコードを削除しても削除されたID値は再利用されません。したがって、最大値に達する前に既存のレコードを抽出して再保存する並べ替え操作が必要です。
-
エントリ・メソッド
NDBは、セットという階層型構造に従います。そのため、各レコードはセットによる階層構造へのアクセスが可能です。ただし、垂直構造の最上位に存在するレコードは、セットを利用してアクセスすることができないため、このようなレコードのアクセスをサポートするための方法として、エントリ・メソッドを使用します。
以下は、NDBがサポートする5つのエントリ・メソッドです。
-
Index entry method
レコード内のフィールドをキーとして使用し、レコード表に索引を作成します。Index entry methodを使用してレコードにアクセスする際は、索引キーに該当するフィールドの値を使用してレコード表から直接レコードを検索します。
-
Extended Index entry method
Index entry methodと類似しています。レコード内のフィールドをキーとして使用し、レコード表に索引を作成します。Extended Index entry methodを使用してレコードにアクセスする際は、拡張索引キーに該当するフィールドの値を使用して、レコード表から直接レコードを検索します。
拡張索引の詳細については、拡張索引を参照してください。
-
Random entry method
Random entry methodは、User random entry methodとSystem random entry methodに分けられます。
区分 説明 User random entry method
アプリケーションでUser random functionを使用してレコードのページを直接検索します。レコード表のページ番号の列を使用してアクセスします。
System random entry method
AIM/DBでは、レコード内のフィールドをキーとして使用し、System random functionによって入力されたキー値を持つレコードを検索します。NDBでは、そのキーを使用してレコードを直接検索します。
-
System entry method
システム・セットを使用してレコードにアクセスします。システム・セットは、オーナー・レコード型なしでメンバー・レコードだけで構成されるリング構造です。したがって、オーナー・レコードにアクセスすることなく、メンバー・レコードに直接アクセスすることができます。
-
Direct retrieval method by PGCS
レコード位置のPGCS(Program Current Status)の値を使用してレコードに直接アクセスします。PGCSを使用すると、すべてのレコードに直接アクセスすることができます。
-
2.2. セット
セットは、レコード間の関係を示しており、基本的に2つのレコード型が垂直関係で構成されます。
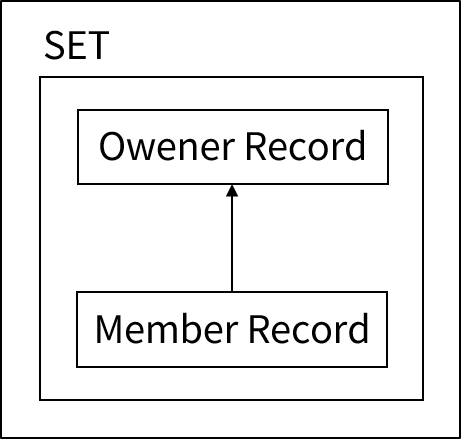
垂直関係で親に当たるレコードをオーナー・レコード型、子に当たるレコードをメンバー・レコード型といいます。また、1つ以上のメンバー・レコード型が含まれたセットを混合セット(mixed set)といいます。ただし、オーナー・レコード型には1つのレコード型のみ使用できます。
レコードと同様に、セットも、セット名や固有の属性を持っており、これをセット型といいます。
オーナー・レコード型とメンバー・レコード型の上下関係により、両レコード間には1:Nの関係が成立します。1オーナー・レコードと複数のメンバー・レコードで構成されたレコードのグループをセット・オカレンス(Set occurrence)と呼びます。
セット・オカレンスを構成する方法として、リング構造とリスト構造があります。
-
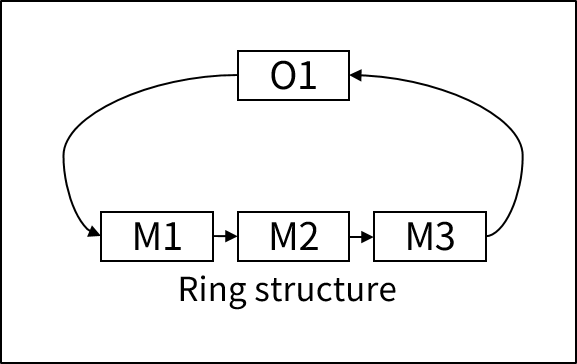
リング構造(Ring structure)
リング構造は、オーナー・レコードとメンバー・レコードがリング形式になっている構造です。
オーナー・レコードが最初のメンバー・レコードを指すポインターを持っており、各メンバー・レコードはその次のメンバー・レコードを指すポインターを持ちます。また、最後のメンバー・レコードがオーナー・レコードを指すポインターを持っています。
-
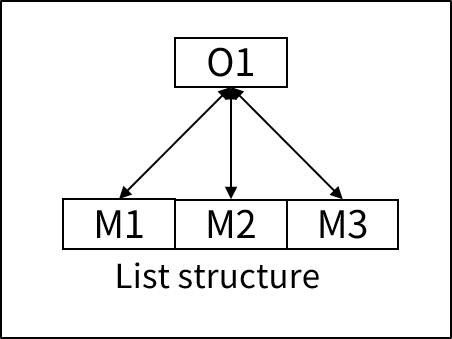
リスト構造(List structure)
リスト構造は、オーナー・レコードがメンバー・レコードをリスト形式で持っている構造です。オーナー・レコードはメンバーとして含まれているすべてのレコードのポインターを持っており、メンバー・レコードは、オーナー・レコードを指すポインターのみ持っています。
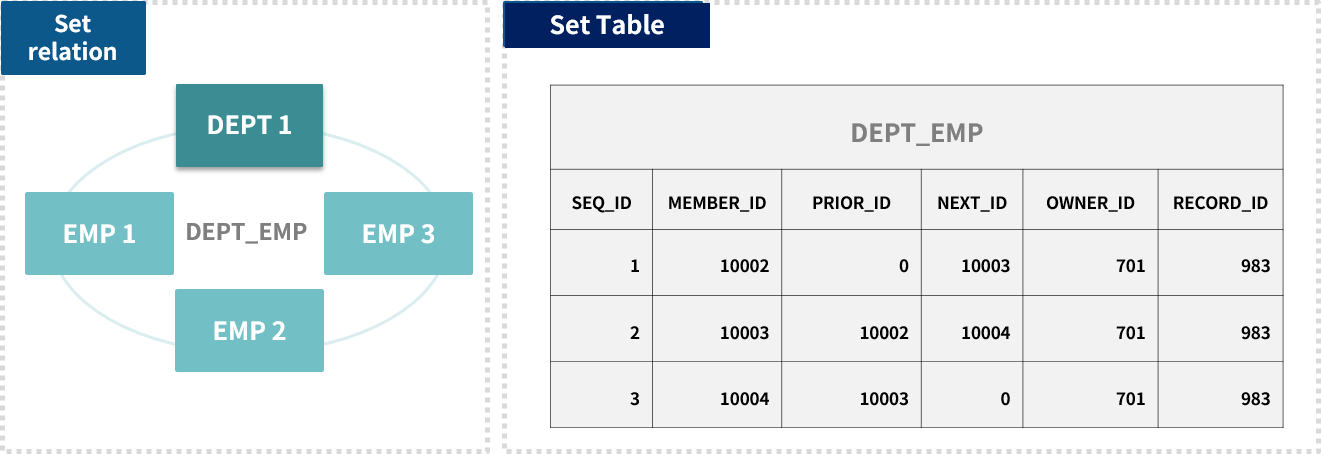
NDBでは、セット・オカレンスをRDBの表として構成しており、各レコードのポインター情報が含まれています。
2.3. 論理接続
同じレコード型内のレコードは、特定のフィールドに対して重複する値を持つことができます。ただし、重複したフィールドと値を持つレコード数が多ければ多いほど、保存領域が浪費されます。
論理接続とは、各レコードのキーを使用して互いに異なるレコード型に同時にアクセスすることです。つまり、重複が多いフィールドを新しいレコード型として作成し、これを既存のレコードと論理的に接続します。
以下の図は、論理的に接続されているレコード型を示しています。
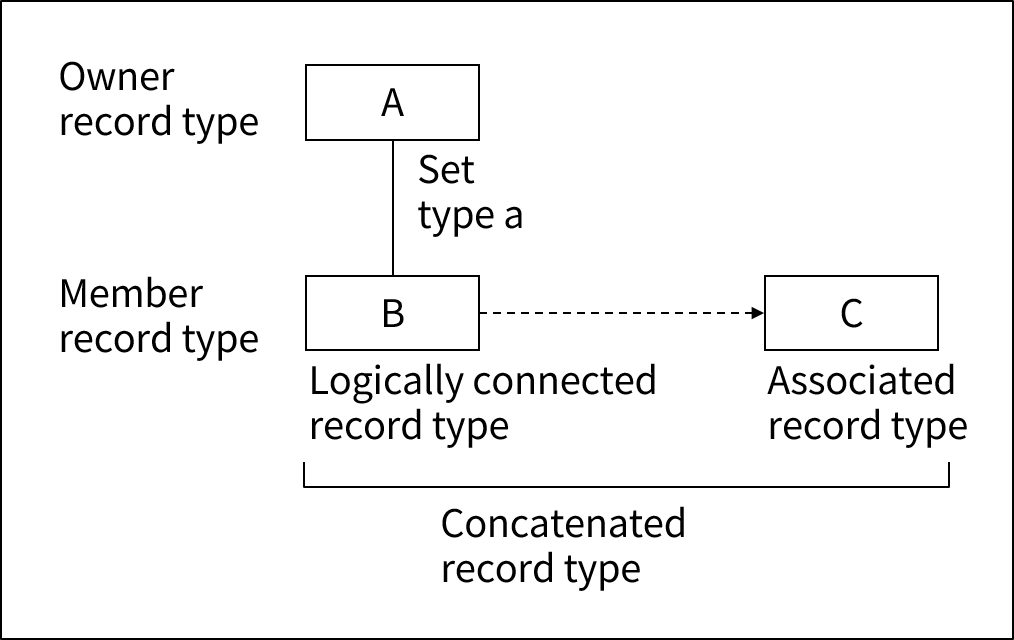
以下は、論理接続を記述する際に使用される用語についての説明です。
| 区分 | 説明 |
|---|---|
Logically connected record type |
基準となるレコードです。 |
Associated record type |
基準となるレコードと論理的に接続されるレコードです。 |
Concatenated record type |
論理的に接続されるレコード型と混合レコード型です。 |
|
上記の図で、実線はセット関係を、点線は論理接続関係を示しています。 |
3. 格納構造
AIM/DBでは、論理構造で定義されたレコードは、直接アクセス記憶装置(DASD: Direct Access Storage Device)に保存されます。その際、ページのサイズや直接アクセスする記憶装置の特性などを考慮する必要があります。
ただし、データベースの管理者がハードウェアの物理的な属性までを考慮するのは容易なことではないため、格納構造という概念を取り入れ、保存領域の物理的な特性を考慮せず、論理的に構成できるようにしています。格納構造では、レコードが格納アドレス領域(Locative Address Space)に格納される順番を定義します。
以下は、格納構造を定義する2つの方法です。
| 区分 | 説明 |
|---|---|
SLS(Single Locative Space) |
1つの保存領域を1つのアドレス体系で管理します。 |
MLS(Multiple Locative Space) |
1つの保存領域を複数のアドレス体系で管理します。SLSの1つの保存領域のサイズ制限を克服するために使用されます。 |
NDBでは、AIM/DBと違って論理構造で定義されたレコードがデータベースの表に保存されます。したがって、論理的に保存領域を構成する必要がないため、SLSとMLSに関係なく保存されます。
本書の格納構造は、SLSを基準にしてAIM/DBの格納構造の概念とNDBの動作を説明しています。
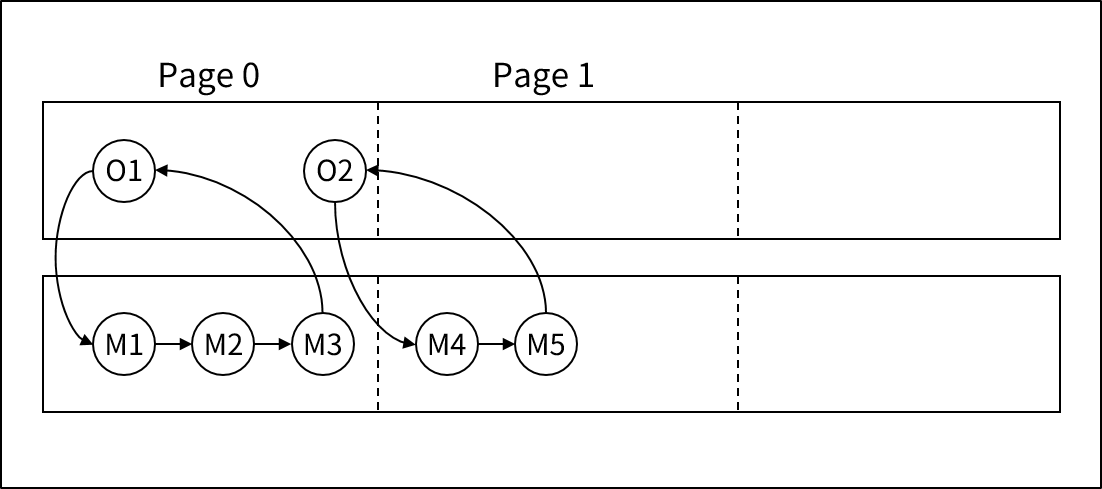
3.1. ページ
ページは、レコードを保存できる最小単位です。物理ページと論理ページに分けられ、1つ以上の物理ページの集合が論理ページを構成します。
1つのデータセットに存在するすべてのページは同じサイズである必要があります。1つのレンジが複数のデータセットに分散保存される場合は、各データセットのページ・サイズも同じでなければなりません。データベースのパフォーマンスを向上させるために、論理ページの上部に論理ページが存在しており、データベースのI/Oを物理ページ単位ではなく、論理ページ単位で実行すると、隣接するレコードへの高速アクセスが可能になります。
NDBは、AIM/DBと違って1つのレコードが表の行として構成されるため、I/Oがレコード単位で実行されます。
|
各レコードの表では、ページ番号の列が存在しており、User random entry methodの使用時に利用されます。 |
3.2. レンジ
レコードが保存される論理アドレス領域(Logical address space)を、特性とアクセス方法で区別した領域をレンジ(Range)といいます。レンジは論理ページで構成されるため、レンジのサイズは、論理ページの数および論理ページ内の物理ページの数とサイズに応じて決まります。
レンジは、プライム領域とオーバーフロー領域に分けられます。一般的にレコードはプライム領域に保存されます。ただし、プライム領域内の特定の論理ページに新しいレコードを保存する必要があるが、その論理ページがいっぱいになった場合は、オーバーフロー領域から1つの物理ページを取得して使用することができます。プライム領域の論理ページは、新しく追加された物理ページを含め、論理ページを再構成することになります。
NDBでのレンジは、含まれるレコード型の情報をメタデータとして管理し、レンジ単位で検索する際、該当するレコード型の情報を利用して処理することができます。したがって、プライム領域とオーバーフロー領域を区別しません。
レンジは、以下の2タイプに分けられます。
| 区分 | 説明 |
|---|---|
エントリ・レンジ |
エントリ・レコード(Index entry method、Extended index entry method、Random entry method、System entry methodに該当するレコード)が保存されるレンジです。 |
ノーマル・レンジ |
ノーマル・レコードが保存されるレンジです。 |
3.3. サブレンジ
レンジは、サブレンジという小単位で分けることができます。同じレコードであっても特性を考慮して異なるサブレンジに保存することができます。たとえば、都市というフィールドを持つレコードがあり、その都市フィールドに「東京」の値を持つレコードと「神奈川」の値を持つレコードをそれぞれ保存する場合、レンジをサブレンジに分けて保存することができます。
サブレンジのサイズは、論理ページの数および論理ページを構成する物理ページの数とサイズに応じて決まります。レンジをサブレンジで分けた場合は、サブレンジでプライム領域、オーバーフロー領域、セキュリティおよびアクセスに関する設定を行うことができます。また、レンジにはプライム領域を除く、オーバーフロー領域とその他の設定も可能です。
レンジをサブレンジで分けるときは、レンジに保存される最上位レコード内に存在するフィールドをロケーション・キーとして指定します。新しいレコードが保存される際、ロケーション・キーによって保存されるサブレンジが決まります。ロケーション・キーは、スキーマのレンジ・エントリに記述し、各サブレンジが保存するレコードに対するロケーション・キー値は、スキーマのサブレンジ・エントリに記述します。
NDBでサブレンジの保存は、レンジと同様にプライム領域とオーバーフロー領域を区別しません。レコード表のロケーション・キーに該当するフィールドの値に従ってサブレンジ単位で処理します。
3.4. ロケーション・セット
レコード型Aとレコード型Bが1つのセットとして構成されたロケーション・セットについて説明します。
Aがオーナー・レコード型で、Bがメンバー・レコード型です。レコードAはレンジAに保存され、レコードBはレンジBに保存されます。メンバー・レコードのBがレンジBに保存される際、同じセット・オカレンスに属するレコードを同じ論理ページに保存することで、データベースのパフォーマンスを向上させることができます。このようなセットをロケーション・セットといいます。
ロケーション・セットには、外部ロケーション・セット(external location set)と内部ロケーション・セット(internal location set)があります。上記例は、外部ロケーション・セットです。内部ロケーション・セットは、オーナー・レコード型とメンバー・レコード型が同じレンジに保存される場合、メンバー・レコードはオーナー・レコードが保存されている論理ページに保存された方が効率的です。
NDBは、セットをデータベースの表として構成し、SQLを使用してセット・オカレンスにアクセスします。したがって、ロケーション・セットで構成しなくても、セット・オカレンスに迅速にクセスすることができるため、ロケーション・セットはサポートしていません。
5. 仮想論理構造
1つのデータベースには多くのレコード型が含まれています。ただし、アプリケーションからすべてのレコードにアクセスする可能性は高くありません。
したがって、開発中のアプリケーションからアクセスするレコード型のみ把握できるようにサブスキーマを提供しています。サブスキーマは、スキーマに定義されたデータベース情報のうち、必要な部分についてのみ記述します。
スキーマは論理構造、格納構造、物理構造を指定しますが、サブスキーマはスキーマの論理構造からのみ取り出して作成します。したがって、データベースの構成についての詳しい知識がなくても、アプリケーションを作成することができます。これを仮想論理構造といいます。仮想論理構造は、データベースで使用するレコード型とセット型を選択することが可能であり、レコード内のフィールドも必要な部分のみ選択するか、再定義することができます。
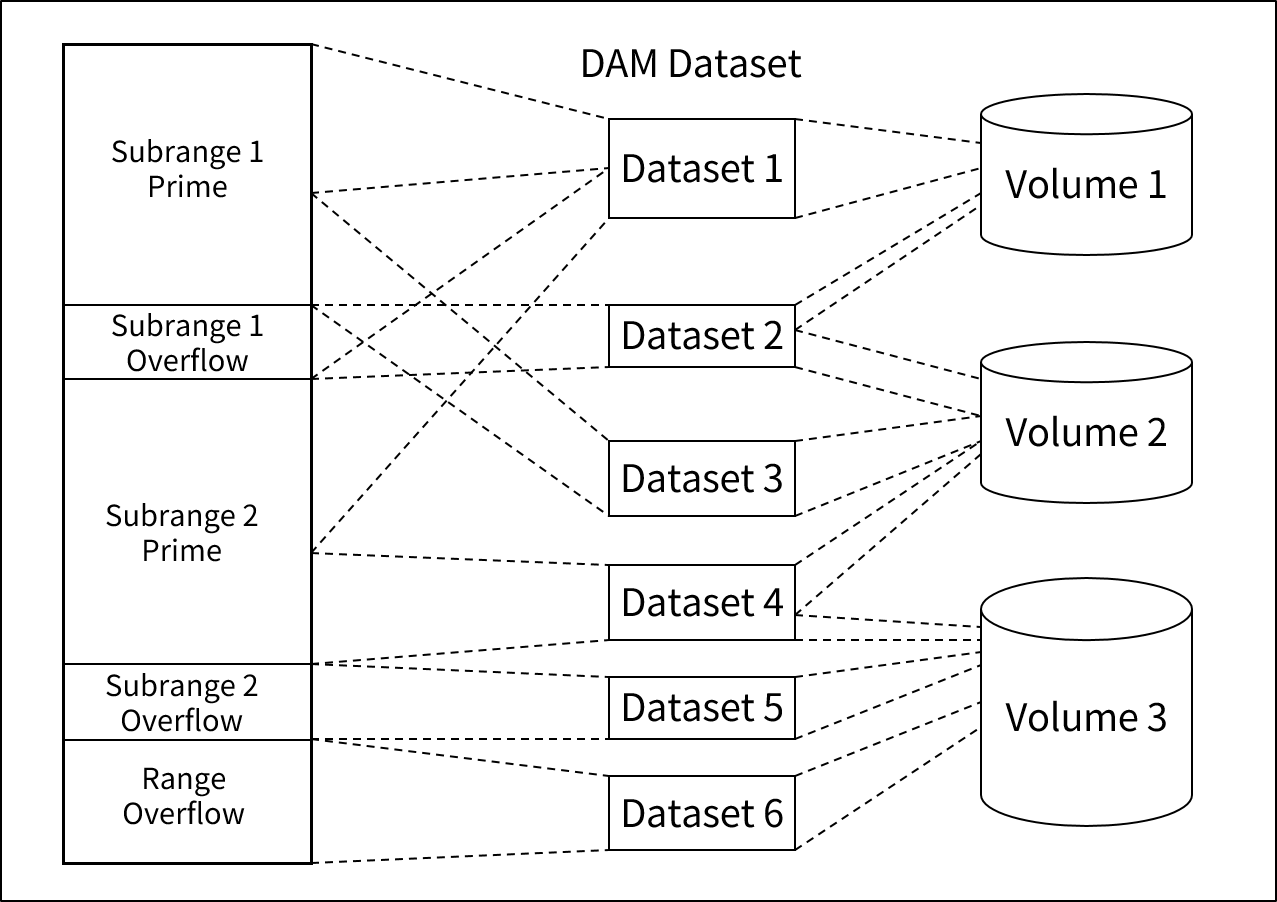
6. 多重格納空間(MLS)
NDBは、レコードを表に保存するため、レンジに対する制限がなく、1つのレコード型に1024GBのレコードを含むことができます。つまり、SLSとMLSを区別せずに大量のデータを保存することができます。この節では、MLSの特徴についてのみ説明します。
6.1. MLSの特徴
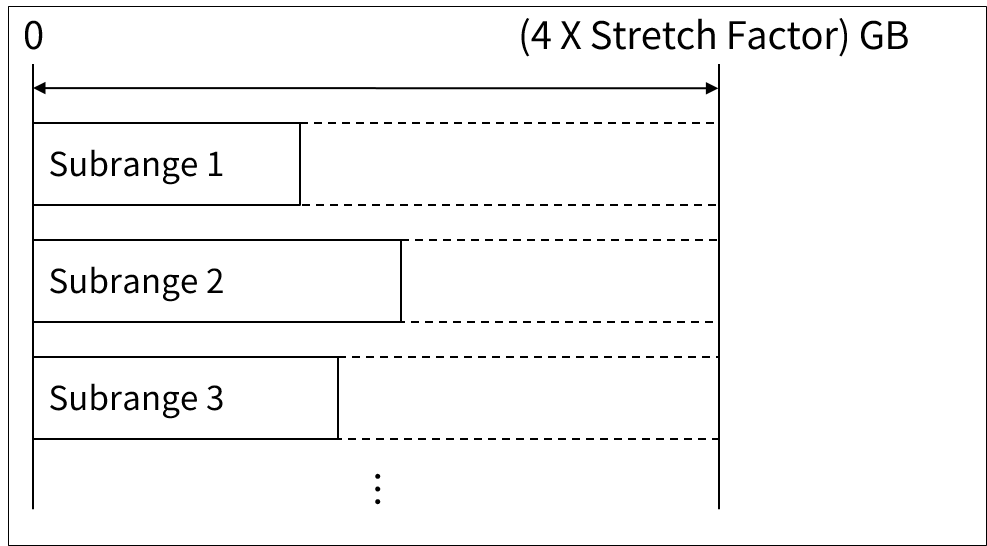
SLS/DBの最大容量は128GB(STRETCH factor 32を適用した場合)ですが、大量のデータを保存するには十分ではありません。MLS/DBでは、各サブレンジが独立したアドレス体系を持っているため、サブレンジごとに128GBを持つことができます。
ただし、膨大なサイズのMLS/DBを作成するには多くの時間が必要となるため、AIM/DBではMLS/DBを一度で作成するのではなく、サブレンジ単位で作成することができます。
6.2. MLSとSLSの違い
AIM/DBでのMLS/DBは、基本的にサブレンジ単位(再編成など)で処理できるというメリットがありますが、これにはいくつかの制約があります。
-
セット関係がレンジを超えることはできません。
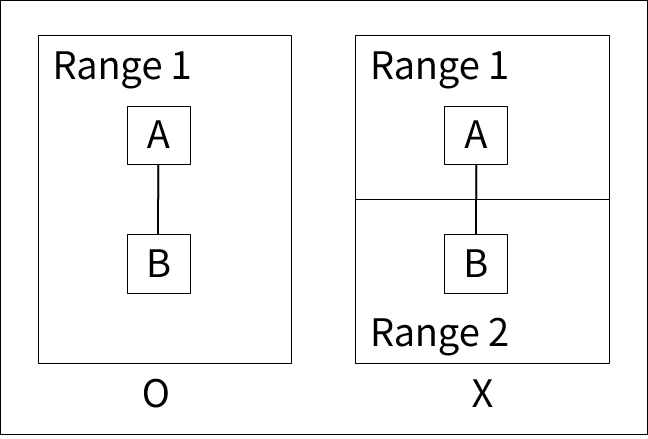 MLS/DBのセット関係
MLS/DBのセット関係 -
レンジがサブレンジで分けられた場合、レンジにはオーバーフロー領域を使用することができず、サブレンジのオーバーフロー領域のみ使用できます。
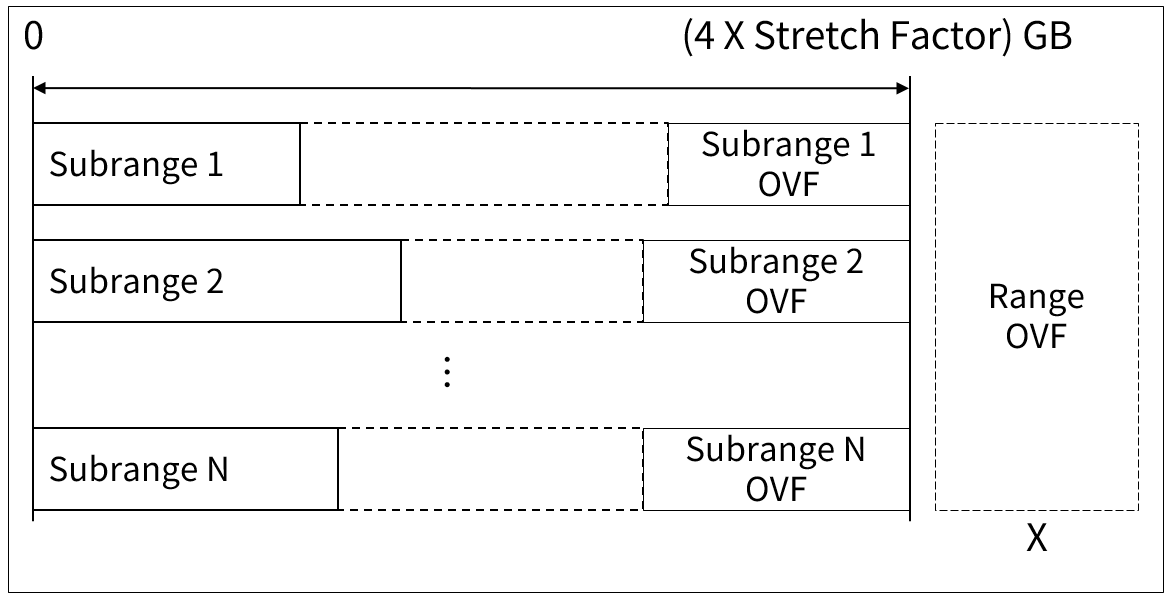 MLS/DBのオーバーフロー領域の使用
MLS/DBのオーバーフロー領域の使用 -
拡張索引(Extended index)は、各サブレンジごとにマッピングします。
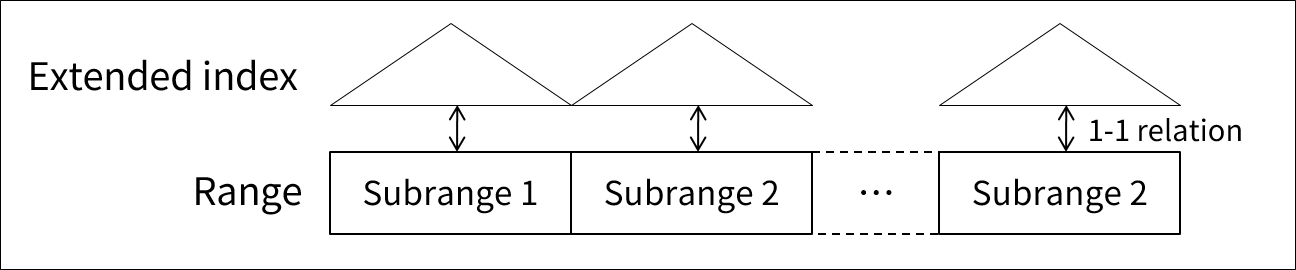 MLS/DBの拡張索引のマッピング
MLS/DBの拡張索引のマッピング
6.3. 拡張索引
特定の内容を検索する方法として、目次と索引を使用する方法があります。NDBでは、目次からの検索はIndex entry methodであり、索引から検索する方法は拡張索引です。
6.3.1. 拡張索引の構造
AIM/DBでの拡張索引の処理は、一般的なレコード処理と類似しています。ただし、レコードの内容が他のレコードの索引情報であるという点が異なります。つまり、拡張索引キーとレコードのアドレスなどがデータ項目となり、このデータ項目の集まりが拡張索引レコードになります。したがって、レコードの保存時と同様に、拡張索引も論理構造、格納構造、物理構造を持ちます。
一方、NDBでは、拡張索引に対して格納構造を持たず、物理構造に含まれるようになっています。NDBでの拡張索引レコードの構造は、レコード表の索引を作成して処理するため、AIM/DBでの検索結果と同じ結果を提供することができます。