서비스 플로우 엔진
본 장에서는 서비스 플로우 엔진으로 작성하는 다이어 그램의 기본 요소와 패턴에 대해서 설명한다.
1. 서비스 플로우 다이어그램
AnyLink는 다양한 어댑터와 서비스를 연계하고 오케스트레이션할 수 있는 기능을 서비스 플로우 엔진을 통해 지원한다. AnyLink는 수신 서비스들과 송신 서비스들을 서비스 플로우를 통해 연결하여 추가적인 처리를 하거나 새로운 가치를 부여한다.
AnyLink 서비스 플로우는 비즈니스 프로세스를 모델링하는 데 사용되는 표준인 BPMN(Business Process Modeling Notation)을 사용하여 그려지는 프로세스 정의를 뜻한다. BPMN 형태로 그려진 다이어그램은 내부적으로 XML 문서 형태인 SFDL(Service Flow Description Language) 서식으로 저장된다.
1.1. 서비스 플로우 다이어그램 기본 요소
다음은 서비스 플로우 다이어그램 기본 요소에 대한 설명이다.
-
서비스 플로우(Service Flow)
프로세스(Process)라고도 부르며, 액티비티, 이벤트와 트랜지션으로 구성된다.
-
액티비티(Activity)
작업(Task)이라고도 부르며, 서비스 플로우에서 해당 위치로 흐름이 도달하게 되면 실행해야 할 어떤 일들을 표현한다.
-
트랜지션(Transition)
액티비티 또는 이벤트들 간의 흐름의 순서를 나타내는 화살표이다.
-
이벤트(Event)
사건을 나타내는 특별한 액티비티로 메시지, 에러, 타임아웃 등의 사건을 나타낸다. 이벤트는 전후 트랜지션 유무에 따라 들어오는 트랜지션이 없는 시작 이벤트(Start Event), 들어오는 트랜지션과 나가는 트랜지션이 모두 있는 중간 이벤트(Intermediate Event), 나가는 트랜지션이 없는 끝 이벤트(End Event)로 구분할 수 있다.
 Start Event
Start Event중간 이벤트의 특수한 형태인 바운더리 이벤트(Boundary Event)는 액티비티나 블록의 경계에 위치하여 표현하는 이벤트이며 해당 액티비티 혹은 블록이 활성화된 시점에 발생하는 이벤트가 있으면 바운더리 이벤트로 분기가 일어난다.
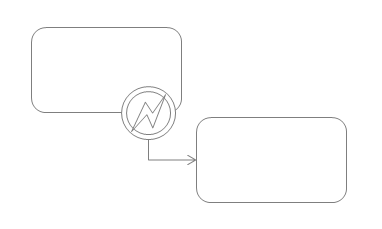 Boundary Event
Boundary Event -
게이트웨이(Gateway)
흐름을 제어하는 데 사용되는 특별한 액티비티 형태라고 생각할 수 있다. 크게 하나의 트랜지션 흐름을 여러 개의 트랜지션 흐름으로 분리시켜주는 스플릿 게이트웨이(Split Gateway)와 그 반대로 여러 개의 트랜지션 흐름을 하나의 트랜지션 흐름으로 합쳐주는 조인 게이트웨이(Join Gateway)가 있다.
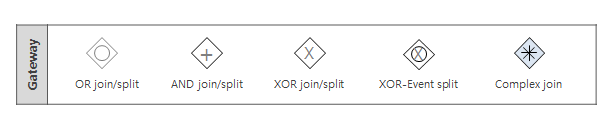 Split Gateway
Split Gateway
1.2. 서비스 플로우 병렬 처리
AnyLink 서비스 플로우는 런타임 엔진 서버의 서비스 플로우 엔진에서 실행이 된다. 보통 인바운드 어댑터를 통해서 전달된 메시지에 의해서 정의된 서비스 플로우의 인스턴스가 만들어지게 되는데 이렇게 서비스 플로우로 전달되는 메시지나 타이머 정보를 서비스 플로우에서는 트리거(trigger)라고 한다.
일반적으로 하나의 트리거에 의해서 발생하는 서비스 플로우의 흐름은 하나의 스레드에 의해 실행된다. 하지만, 서비스 플로우의 흐름을 정의하는 SFDL은 흐름의 병렬 분기나 병합이 가능하다.
AnyLink 서비스 플로우 엔진은 서비스 플로우 다이어그램의 형태에 따라 하나의 서비스 플로우 인스턴스를 동시에 다수의 스레드에서 실행하게 되는 경우도 있다. 또한 AnyLink 서비스 플로우 엔진은 서비스 플로우를 생성하고 흐름을 처리할 때 시스템 자원인 스레드의 활용을 극대화하고 다량의 동시 처리를 가능하게 설계되어 있다.
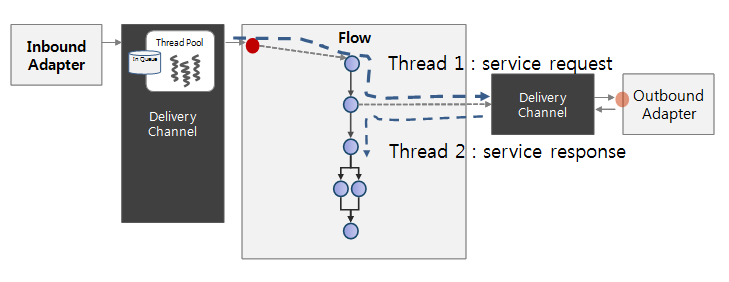
서비스 호출 스레드(thread 1)는 요청을 보낸 후 응답을 기다리지 않는다. 서비스 응답 처리 스레드(thread 2)는 응답이 올 때 어댑터에서 만들어진다.
1.3. 다이어그램 그래프와 블록 구조
AnyLink 서비스 플로우의 흐름은 기본적으로는 액티비티들을 방향이 있는 화살표로 이어서 표현하는 그래프 구조 기반이다. 그래프 구조는 사람이 사고하는 대로 흐름을 표현할 수 있어 직관적이고 유연한 장점이 있다.
AnyLink 플로우 엔진의 각 액티비티(Activity)들과 트랜지션(Transition, 화살표로 표현됨)들 그리고 각종 흐름 분기와 흐름 병합을 표현하는 게이트웨이(Gateway)들은 이러한 그래프 구조의 서비스 플로우를 잘 표현해준다.
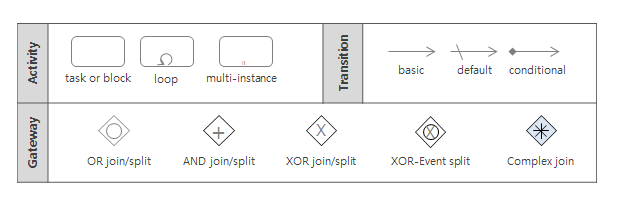
반면에 특정 구역을 진행하는 도중에 발생하는 사건들이나 예외에 대한 처리를 위해서는 특정 구역을 묶어서 표현하는 것이 효율적인데, 보통 이렇게 특정한 흐름의 단위를 묶는 것을 블록(Block)이라고 한다.
Java와 같은 프로그래밍 언어들은 기본 실행 단위가 여러 문장을 묶어놓은 블록이나 함수가 된다. 특정 블록이나 함수 내에서 발생한 에러들에 대해서는 에러 처리 로직에 의해 공통적으로 처리가 가능하다. AnyLink 플로우는 이러한 구역에 해당하는 액티비티 묶음을 서브 프로세스(Sub-Process) 또는 블록(Block)이라고 한다.
블록 안의 액티비티 혹은 트랜지션 수행 도중에 발생하는 에러나 타임아웃과 같은 이벤트는 블록 경계선에 붙여진 에러 이벤트나 타이머 이벤트에 의해 흐름이 이동하게 된다. 일반적으로 좋은 프로세스는 그래프 구조와 블록 구조의 복합적인 형태로 구성된다. AnyLink 서비스 플로우는 그래프 구조를 기본으로 블록 구조를 부분적으로 지원하는 형태라고 볼 수 있다.
AnyLink 서비스 플로우 다이어그램에서 블록 액티비티와 블록 액티비티의 경계에 붙여지는 바운더리 이벤트들은 블록 구조의 흐름을 구현하는 예라고 볼 수 있다.
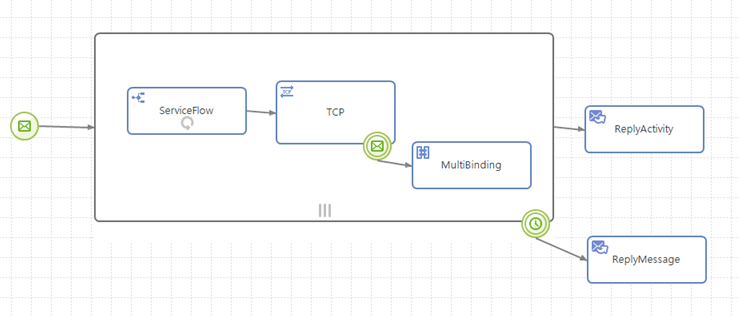
블록 액티비티 외에도 서비스 플로우에도 에러 핸들러 등을 지정할 수 있어 서비스 플로우 수행 중에 발생하는 에러를 처리할 수 있으므로 이 역시 블록 구조의 한 형태라고 볼 수 있다.
2. 기본 패턴
AnyLink 서비스 플로우 다이어그램은 앞에서 설명한 대로 BPMN 표준을 기반으로 그래프 구조와 블록 구조를 혼합하여 제어의 흐름을 표현한다. 본 절에서는 많이 사용되는 서비스 플로우 패턴에 대해서 설명한다.
2.1. 기본 흐름 패턴
다음은 기본 흐름 패턴에 대한 설명이다.
-
순차 실행(Sequence)
순차적인 흐름은 가장 기본적인 흐름이며, 각 액티비티들은 그 순서에 따라 앞의 액티비티가 끝나야 다음 액티비티가 수행된다.
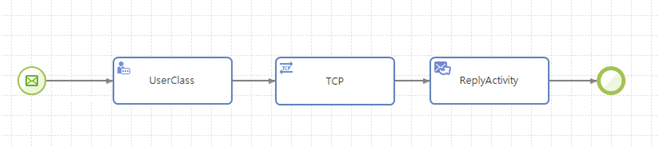 순차 실행
순차 실행 -
병렬 수행을 위한 분기(Parallel Split)
하나의 액티비티가 여러 개의 액티비티로 나누어져서 진행되며, 각각의 액티비티는 독립적으로 실행된다. 보통 And Split 게이트웨이를 사용하여 표현한다.
-
동기화(Synchronization)
병렬적으로 수행적인 스레드를 동기화하여 하나의 흐름으로 합친다. 보통 And Join 게이트웨이를 사용하여 표현한다.
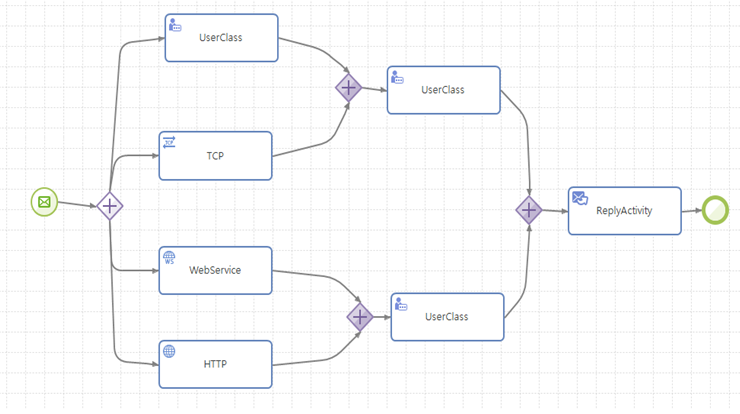 병렬 수행 분기 및 동기화
병렬 수행 분기 및 동기화 -
배타적인 분기(Exclusive Choice)
여러 실행 경로들 중 하나의 실행 경로를 선택하는 형태이다. 보통 XOR Split 게이트웨이를 사용하여 표현한다.
-
단순 병합(Simple Merge)
여러 개의 실행 경로 중 하나의 실행 경로만 허용하여 단순 병합하는 형태이다. 보통 XOR Join 게이트웨이를 사용하여 표현한다.
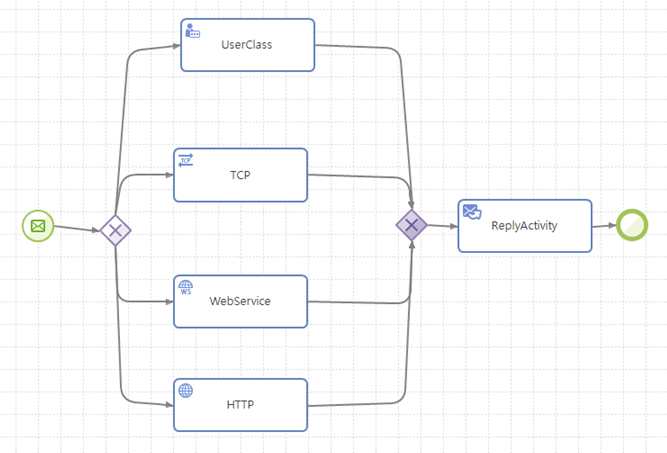 배타적인 분기와 단순 병합
배타적인 분기와 단순 병합
2.2. 확장된 분기 및 병합 패턴
다음은 확장된 분기 및 병합 패턴에 대한 설명이다.
-
다중 선택(Multiple Choice)
여러 개의 실행 경로 중 몇 개의 실행 경로를 선택하여 병렬적으로 실행하는 형태이다. 보통 OR Split 게이트웨이를 사용하여 표현한다.
-
동기 방식 병합(Synchronizing Merge)
여러 개의 실행 경로를 동기화시키면서 병합하는 형태이다. 보통 OR Join 게이트웨이를 사용하여 표현한다.
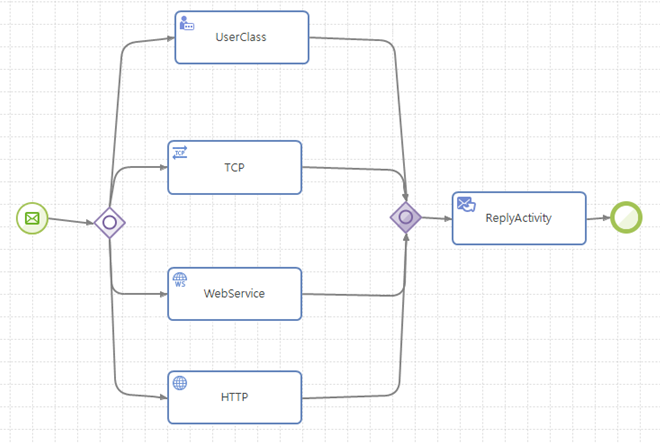 다중 선택과 동기 방식 병합
다중 선택과 동기 방식 병합 -
동기화 없는 병합(Multiple Merge)
여러 개의 실행 경로를 동기화 없이 경로만 하나로 합치는 형태이다. 여러 개의 경로가 실행되고 있는 상태라면 이후에는 하나의 경로로 여러 번 지나가게 된다. And Split 게이트웨이 다음에 XOR Join 게이트웨이로 병합하면 다음과 같이 동작한다.
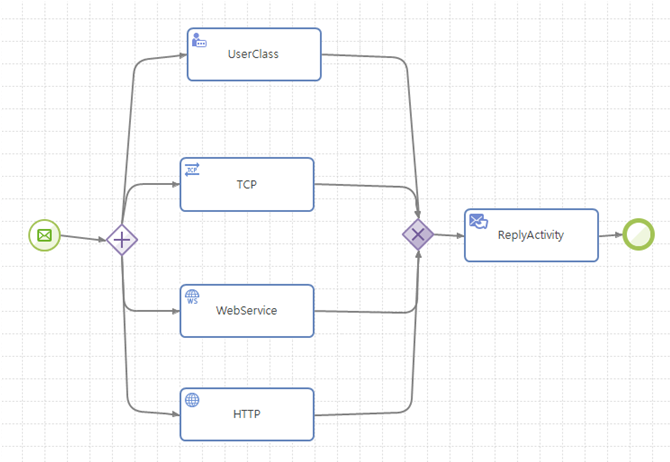 동기화 없는 병합
동기화 없는 병합 -
동기화 없이 하나만 흘림 병합(Discriminator)
여러 개의 실행 경로를 동기화 없이 첫 번째 도달하는 흐름만 계속 흘려보내는 형태이다. 여러 개의 경로가 실행되고 있는 상태라면 이후에는 하나의 경로로 가장 먼저 도달한 스레드만 지나가게 된다.
And Split 게이트웨이 다음에 Complex Join 게이트웨이로 병합할 때 Complex Join 게이트웨이의 흐름 조건(flow condition)이 1이면 다음과 같이 동작한다.
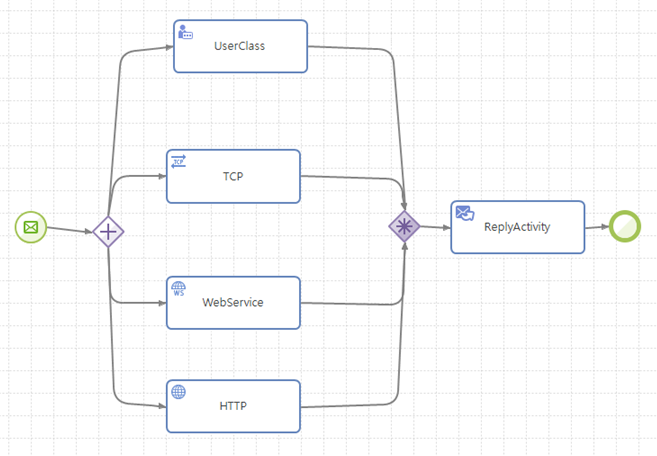 동기화 없이 하나만 흘림 병합
동기화 없이 하나만 흘림 병합 -
M 개 중 N 개 병합(N-out-of-M Join)
여러 개의 실행 경로를 지정한 갯수만큼만 도달할 때까지 동기화한 후에 하나로 흘려보내는 형태이다. 이 게이트웨이 이후의 경로는 하나의 흐름만 지나가게 된다.
And Split 게이트웨이 다음에 Complex Join 게이트웨이로 병합할 때 Complex Join 게이트웨이에 들어오는 흐름 갯수 설정이 N에 해당한다.
-
임의의 사이클 형태 반복(Arbitrary Cycle)
AnyLink에서 반복을 표현하기 위해 블록의 반복 설정을 사용할 수도 있지만 좀더 자유로운 반복을 위해 트랜지션을 통해 사이클을 형성하게 하여 반복시킬 수도 있다.
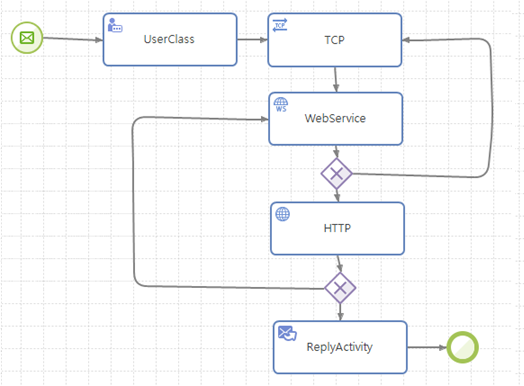 임의의 사이클 형태 반복
임의의 사이클 형태 반복 -
암묵적 종료(Implicit Termination)
서비스 플로우를 명시적으로 종료시키기 위해 Terminate 이벤트를 사용할 수 있지만 실행 중이던 각 흐름이 모두 끝나게 되면 암묵적으로 종료하게 된다.
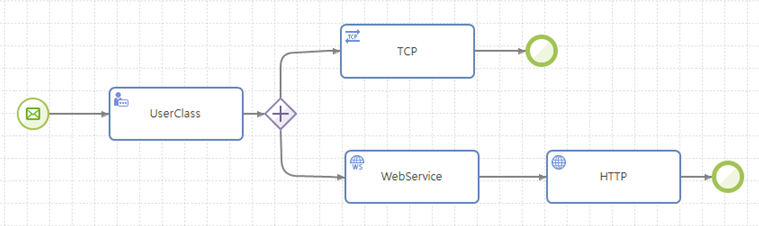 암묵적 서비스 플로우 종료
암묵적 서비스 플로우 종료 -
다중 인스턴스(Multiple Instance)
다중 인스턴스는 하나가 아니라 여러 건을 순차적으로 혹은 병렬적으로 처리하는 인스턴스를 표현하는 액티비티 실행 형태이다. 액티비티는 하나이지만 실제 인스턴스는 여러 개가 생성된다.
다중 인스턴스는 반복 완료 조건과 반복 수행 형태, 다음 액티비티로의 트랜지션 방식 속성을 설정한다.
속성 설명 반복 완료 조건
인스턴스 갯수를 뜻하는 숫자값이나 완료 조건을 의미하는 bool 조건식을 지정한다.
반복 수행 형태
순차(Sequential)와 병렬(Parallel) 두 가지가 있다.
순차 수행 형태는 일반적인 단순 반복문과 같은 방식으로 수행하며, 병렬 수행 형태는 동시에 여러 건이 실행된다. 병렬 수행 형태는 마치 And Split으로 여러 경로가 실행되는 것과 비슷한 방식으로 여러 인스턴스가 실행된다.
다음 액티비티로의 트랜지션 방식
다음 액티비티로의 트랜지션 방식은 네 가지 형태로 구분된다.
-
첫 번째는 모든 인스턴스들이 완료 후에 트랜지션이 일어나는 경우로 마치 And Join과 비슷한 방식으로 동작한다.
-
두 번째는 여러 인스턴스들 중 하나의 인스턴스가 완료되면 바로 트랜지션이 일어나는 경우이다.
-
세 번째는 여러 인스턴스들 중 각 인스턴스가 완료될 때마다 트랜지션이 하나씩 일어나는 경우이다. 이 경우에는 트랜지션부터는 인스턴스 갯수만큼 여러 번 흐르게 된다.
-
네 번째는 지정한 조건이 만족되면 트랜지션이 일어나는 경우이다. bool 조건식 값이 만족되면 트랜지션이 일어난다.
다음은 다중 인스턴스에 관련된 몇 가지 주요 사용 패턴이다.
-
동기화 없는 다중 인스턴스 패턴(MI Without Synchronization)
하나의 액티비티의 여러 인스턴스들을 동기화하지 않고 생성하는 경우로 MI 트랜지션 방식 중 인스턴스 완료때마다 트랜지션이 일어나는 경우가 여기에 해당한다.
-
설계 시점에 인스턴스 갯수를 알고 있는 다중 인스턴스 패턴(MI With A Priori Known Design Time Knowledge)
설계 시점에 MI 방식으로 실행할 액티비티의 생성할 인스턴스 갯수를 알고 있는 형태로 반복 완료 조건에서 MI 카운트를 상수로 지정하는 경우이다.
-
런타임 시점에 인스턴스 갯수를 미리 알 수 있는 다중 인스턴스 패턴(MI With A Priori Known Runtime Knowledge)
MI 방식으로 실행할 액티비티의 생성할 인스턴스 갯수를 실행 중 어떤 시점에서 미리 알 수 있는 형태로 반복 완료 조건을 변수값으로 지정하는 경우가 여기에 해당한다.
-
런타임에 미리 알 수 없는 다중 인스턴스 패턴(MI With No A Priori Runtime Knowledge)
MI 방식으로 실행할 액티비티의 인스턴스 갯수를 실행 중에도 미리 알 수 없는 형태로 반복 완료 조건이 bool 조건문일 경우가 대부분 여기에 해당한다.
-
-
지연 선택(Deferred Choice)
여러 개의 경로 중 하나의 경로를 선택한다는 점에서 XOR Gateway와 경로면에서는 유사하나 여러 경로의 대기중인 이벤트들 중 가장 먼저 일어나는 이벤트에 의해 실행될 하나의 경로가 결정된다는 점에서 큰 차이가 있다.
AnyLink 서비스 플로우 다이어그램에서는 주로 XOREvent Gateway가 이러한 지연 선택을 표현한다.
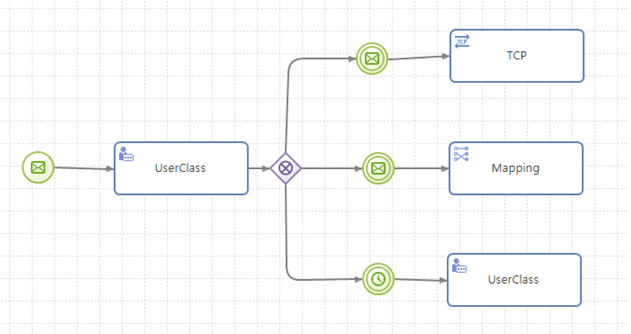 지연 선택
지연 선택
3. 서비스 구현 방식과 서비스 플로우 형태
본 절에서는 다양한 형태의 서비스 구현 방식과 서비스 플로우 형태에 대해서 설명한다.
3.1. Proxy 서비스
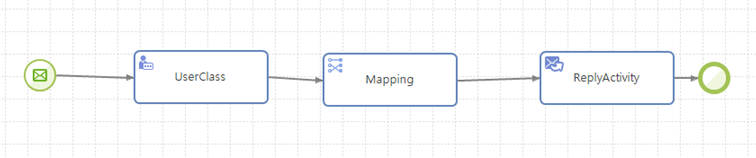
기존에 존재하거나 별도로 구축되는 서비스를 AnyLink를 통해서 서비스를 하도록 서비스 엔드포인트를 AnyLink 한 곳으로 통합하고 로깅이나 보안 등 부가적인 기능들을 기존 서비스에 추가하는 형태의 서비스 모델이다. 예를 들어 기존 서비스가 웹서비스 형태인 경우 해당 서비스의 WSDL(웹 서비스 기술 언어로 작성된 서비스 기술 문서)을 import하여 wrapper 서비스를 만드는 형태가 된다.
서비스 플로우는 Incoming 메시지 이벤트와 Outgoing 서비스 액티비티, 그리고 Reply 액티비티를 기본으로 하는 형태이며 그 가운데 필요한 로깅, 보안 등을 처리하기 위한 액티비티들이 삽입되는 형태가 기본이 된다.
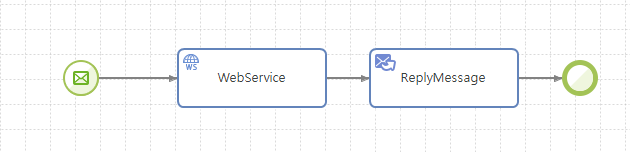
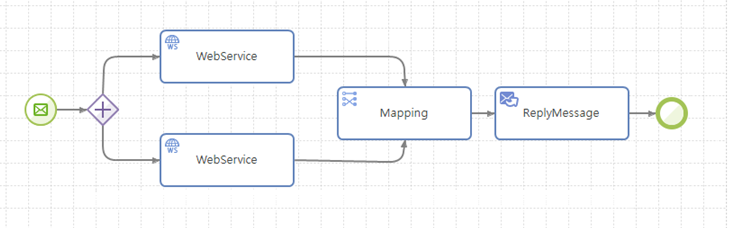
4. 서비스 플로우 변수와 액티비티 파라미터
AnyLink 서비스 플로우의 가장 기본적인 형태는 액티비티와 이벤트를 트랜지션으로 연결하여 흐름을 표현하는 것이다. 이때 액티비티는 입력, 출력에 해당하는 파라미터를 가진다.

-
입력 파라미터는 해당 액티비티가 읽기 위해 사용하는 변수로 해당 변수는 프로세스나 액티비티를 둘러싼 블록 액티비티에 선언된다.
-
출력 파라미터는 해당 액티비티가 쓰기 위해 사용하는 변수로 해당 변수는 역시 프로세스나 액티비티를 둘러싼 블록 액티비티에 선언된다.
서비스 플로우의 변수는 서비스 플로우 즉, 프로세스에 선언되거나 액티비티들을 묶어둔 블록 액티비티에 선언할 수 있는데 각 변수를 볼 수 있는 범위(scope)는 프로세스 변수의 경우 프로세스에 속한 모든 액티비티와 이벤트, 트랜지션 등이며 블록 변수의 경우는 해당 블록 액티비티 안에 속한 액티비티, 이벤트, 트랜지션 등이다.
5. 서비스 액티비티와 파라미터
AnyLink 서비스 플로우에서 다른 서비스를 호출하는 것은 주로 서비스를 나타내는 액티비티를 통한 호출로 표현된다.
서비스는 크게 서비스 플로우 엔진에서 관리하는 각 서비스 플로우들의 메시지 이벤트들과 어댑터의 아웃바운드 룰, 멀티바인딩 라우터 룰들로 나눌 수 있다.
서비스 중 하나의 서비스 플로우에서 다른 서비스 플로우를 호출하는 경우는 서비스 플로우 액티비티라고 한다. 어댑터의 아웃바운드 룰 호출은 각 어댑터별 액티비티(TCP, HTTP, Tmax, 웹서비스 등의 액티비티)로 각각 표현된다. 마찬가지로 멀티바인딩 라우터 룰을 호출할 때에는 멀티바인딩 액티비티를 사용한다.
서비스 호출 액티비티들은 호출하는 각 서비스의 특성은 다를 수 있지만 서비스 플로우 관점에서는 딜리버리 채널을 통해 서비스를 호출한다는 점에서 동작 방식이 모두 같다. 다만 이 중 다른 서비스 플로우를 호출하는 경우는 내부적으로 서비스 플로우 엔진 자신을 호출하기 때문에 딜리버리 채널을 통하지 않지만 논리적으로는 동일하다.
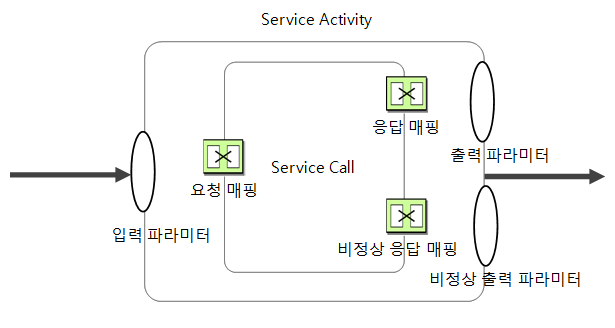
AnyLink에서 서비스는 요청과 응답, 그리고 비정상 응답 메시지를 입출력 메시지로 나뉜다. 서비스 액티비티는 액티비티들 중 서비스를 호출하는 액티비티이므로 입력, 출력 파라미터 외에 비정상 출력 파라미터를 추가적으로 선언할 수 있다.
일반적인 서비스 액티비티에서는 입력 파라미터는 서비스의 요청 메시지로 전달되며, 서비스 호출 결과인 응답 혹은 비정상 응답 메시지는 각각 출력 파라미터, 비정상 출력 파라미터에 저장된다. 입력 파라미터와 요청 메시지 서식이 다른 경우에는 서비스 액티비티의 요청 매핑을 사용하여 데이터 변환을 지정할 수 있다. 마찬가지로 응답 메시지와 출력 메시지 서식이 다른 경우에는 응답 매핑, 비정상 응답 메시지와 비정상 출력 메시지 서식이 다른 경우에는 비정상 응답 매핑을 사용하여 데이터 변환을 할 수 있다.
6. 매핑
AnyLink 서비스 플로우에서 데이터 간의 변환은 매핑(Mapping) 액티비티나 서비스 액티비티의 요청 매핑, 응답 매핑 및 비정상 응답 매핑을 통해 이루어진다.
AnyLink 서비스 플로우는 프로세스 내에서 공유하는 프로세스 변수를 선언할 수가 있다. 마찬가지로 블록 액티비티는 블록 내에서 공유하는 블록 변수를 선언할 수가 있다.
변수는 간단한 String, Float, Integer, DateTime, Boolean 자료형을 지원하고 이외에 구조화된 데이터 형태인 메시지 자료형을 지원한다. AnyLink 서비스 플로우에서 다루는 메시지 자료형은 Java 프로그래밍 언어에서 데이터를 나타내는 클래스로 표현된다. Java 프로그래밍 언어에서 Value Object 혹은 Data Transfer Object라고 부르는 형태의 클래스들이라고 생각하면 된다.
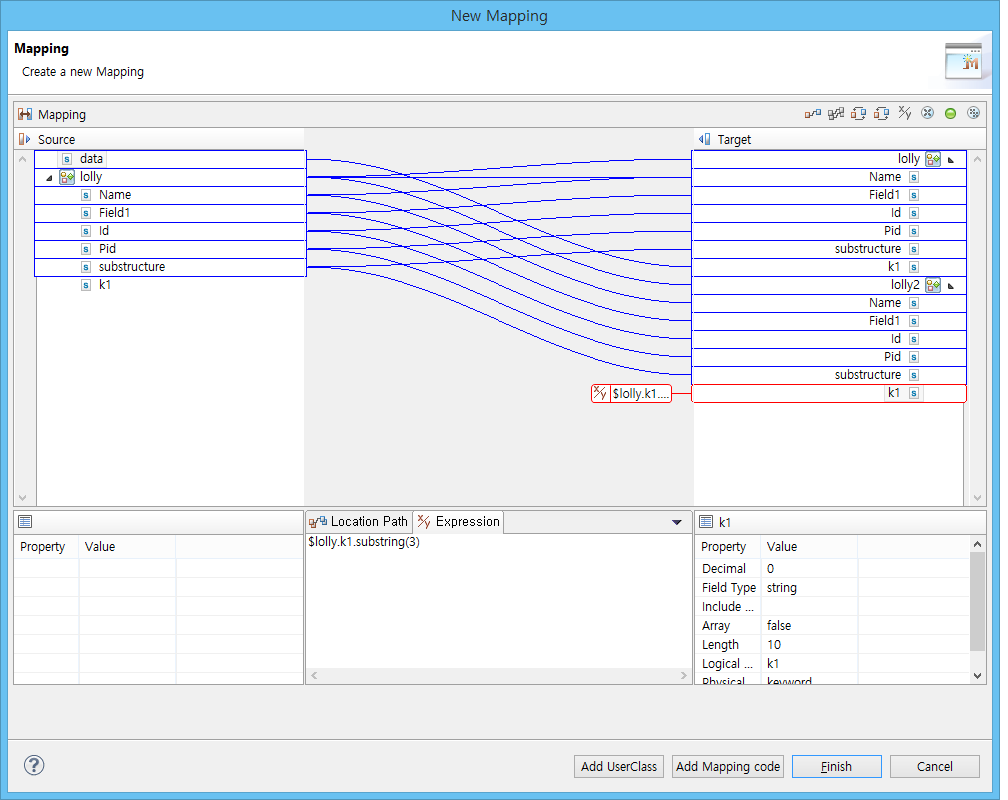
AnyLink 서비스 플로우에서 변수는 내부적으로 이렇게 Java 클래스로 변환되어 표현되고, 매핑은 실행 성능을 개선하기 위해 Java 객체들 간에 데이터를 변환하고 전달하는 Java 코드로 생성된다. 매핑의 가장 기본적인 형태는 소스 메시지와 타겟 메시지의 각 필드들을 연결하는 형태이다. 즉, 소스 메시지의 특정 필드값을 타겟 메시지의 특정 필드에 대입(assign)하는 형태가 가장 기본이다.
메시지의 필드 외에 표현식(expression)을 소스로 사용할 수 있는데 AnyLink 서비스 플로우 내에 사용 가능한 표현식에 대해서는 다음에서 별도로 설명한다. AnyLink 서비스 플로우의 매핑 액티비티는 이러한 프로세스 변수 혹은 블록 변수들 사이의 데이터 변환을 지시하는 액티비티이다.
소스 변수와 타겟 변수들을 지정하고 이들간의 변환 규칙을 그림으로 지정할 수가 있다.
서비스 액티비티에서의 요청, 응답, 비정상 응답 매핑은 어댑터 룰이나 다른 서비스 플로우를 호출하는 액티비티, 그리고 메시지 이벤트를 통해 받은 요청 메시지에 대한 응답 메시지를 돌려주는 Reply 액티비티 등에서는 어댑터 룰이나 서비스 플로우의 서비스 요청 데이터와 응답 데이터 혹은 비정상 응답 데이터의 서식을 맞추기 위해 데이터 변환을 각각 할 수 있는 기능을 제공한다.
어댑터 룰이나 다른 서비스 플로우의 시작 이벤트를 호출할 때 필요한 요청 데이터를 위한 요청 매핑, 그리고 결과값을 받은 후 이의 서식을 변경하기 위해 필요한 응답 매핑, 그리고 비정상으로 표기된 응답 메시지가 전달되었을 때의 비정상 응답 매핑이 있다.
요청 매핑은 서비스 액티비티의 입력 파라미터를 소스로 하고 호출할 서비스(즉, 어댑터 룰이나 다른 서비스 플로우)의 요청 메시지 형태를 타겟으로 하는 매핑이다. 응답 매핑은 서비스의 응답 메시지를 소스로 하고, 서비스 액티비티의 출력 파라미터를 타겟으로 하는 매핑이다.
비정상 응답 매핑은 응답 매핑과 유사하며, 서비스에서 비정상으로 표시된 응답 메시지를 보내온 경우이다. 서비스의 비정상 응답 메시지를 소스로 하고, 서비스 액티비티의 비정상 출력 파라미터를 타겟으로 하는 매핑이다. Reply 액티비티에서는 응답 매핑과 비정상 응답 매핑을 지정할 수 있다.
7. 서비스 플로우 표현식
AnyLink 서비스 플로우의 조건 분기를 나타내는 식이나 코릴레이션 값 계산을 위한 식에서 변수에 해당하는 데이터 객체의 특정 부분값을 계층적으로 표현하기 위해 표현식(Expression)을 사용한다. 표현식은 서비스 플로우 내의 조건 분식 표현식이나 코릴레이션 계산식 외에도 멀티바인딩 라우터의 조건 표현식 등에서도 사용된다.
AnyLink 서비스 플로우 엔진은 자주 호출되는 표현식의 성능을 고려하여 표현식을 포함한 각 요소들을 Java 코드로 생성하여 컴파일하여 배포하는 방식으로 구현되어 있다.
7.1. 구조적 표현식
표현식의 가장 기본적인 서식은 ’변수 이름’.’필드 이름’ 형태이다. 예를 들어 child라는 변수가 있고 이 변수에 name이라는 필드가 정의되어 있다면 child.name으로 소스를 표현할 수 있다. 소스로 사용될 경우 child.name은 Java 코드로 변환될 때 child.getName()과 같은 형태로 변환된다. 이러한 구조적 형태를 표현하는 AnyLink 서비스 플로우의 표현식을 구조적 표현식(structured expression)이라고 한다.
매핑의 각 대입 연산(assignment operation)에서 소스와 타겟은 모두 구조적 표현식으로 지정할 수가 있다. 소스의 경우는 구조적 표현식 외에도 다양한 형태의 함수를 사용할 수가 있다. Java 코드로 생성되는 표현식의 특성을 고려하여 Java 메소드나 Java 연산자를 매핑 소스의 표현식에 사용할 수가 있게 되어 있다.
예를 들어 child라는 변수의 name 필드가 Java 코드 상으로 String 클래스라면 다음과 같은 표현식을 사용할 수가 있다.
child.name.substring(3) + "_ChildName"
위 표현식은 다음과 같은 Java 코드 형태로 변환된다.
child.getName().substring(3) + "_ChildName"
7.2. 변수 표현
변수 이름은 특별한 표기가 없으면 구조적 표현식의 시작 부분 토큰을 변수 이름으로 간주한다.
서비스 플로우에서 변수는 매핑 등의 상황에서 내부적으로 미리 정의되어 있어 이에 맞게 코드를 생성한다. 서비스 플로우 실행 도중에 서비스 플로우 변수나 블록 변수를 참조할 필요가 있을 수 있다. 이렇게 문맥 속에 정의된 변수는 ’$’ 표기를 통해 변수를 표현한다. 예를 들어 dataField1이라는 변수가 선언되어 있다면 다음과 같이 사용될 수 있다.
$dataField1.content
표현식은 앞에서도 설명한 대로 Java 코드로 생성된다. 변수나 필드의 자세한 자료형을 알 수 없으면 정확하게 Java 코드를 생성할 수가 없다.
서비스 플로우 내에 정의된 변수들은 그 정의에서 추출하여 내부적으로 표현식을 Java 코드로 변환할 때 실제 자료형을 추정하여 코드를 생성한다. 변수의 자료형을 정확하게 지정하고 싶은 경우에는 ’<>’를 사용하여 지정할 수 있다. 예를 들어 dataField1이라는 변수의 정확한 자료형이 com.tmax.anylink.ContentContainer 클래스라면 다음과 같이 표현할 수 있다. AnyLink는 내부적으로 표현식을 Java 코드로 변환하여 컴파일하기 때문에 정확한 자료형을 알 수 없는 경우에는 배포할 때 에러가 발생한다. AnyLink 내부적으로 자료형을 추정할 수 없는 경우에 이렇게 명시적으로 자료형을 지정하여 컴파일 에러를 회피할 수 있다.
$dataField1<com.tmax.anylink.ContentContainer>.content
위 표현식은 다음과 같은 Java 코드 형태로 변환된다.
((com.tmax.anylink.ContentContainer) _varCtx.getVariable("dataField1")).getContent()
7.3. 매핑 표현식
서비스 액티비티에서 입출력 데이터를 변환하거나 서비스 플로우 내의 변수값을 변경하기 위한 매핑 액티비티에서 매핑을 사용한다. 매핑에서도 소스가 되는 데이터를 입력값이 아닌 별도의 표현식으로 표현할 수가 있는데 이때의 표현식은 지금 설명한 조건문이나 코릴레이션 값 계산식 등의 표현식과는 조금 형태가 다르다.
매핑의 소스에 사용되는 표현식의 기본 형태는 동일하게 구조적 표현식이다. 즉, 점(.)으로 구분하여 특정 객체 값의 필드를 지정한다.
점(.)으로 구분된 계층 구조에서 매핑 표현식의 첫 번째에 나타나는 부분은 소스 혹은 타겟으로 지정된 변수명이다. 매핑 표현식은 일반 표현식과 달리 '$'로 시작하는 변수명을 지원하지 않고, 구조적 표현식의 시작 부분 토큰이 변수명이 된다. 즉, 아래 예에서 input1이 변수명이다.
input1.person.name
내부적으로는 소스에 사용된 필드 객체가 null이고, 하위 필드 객체를 다시 계층적으로 지정한 경우(즉, input1.getPerson() 값이 null일 때 input1.person.name을 지정한 경우) 해당하는 객체를 빈 객체로 생성하여 에러가 발생하지 않도록 동작한다.
이외에도 매핑의 필드가 배열일 경우 소스에 사용된 필드 이름과 타겟에 사용된 필드 이름 뒤에 애스터리스크(*)를 붙여 배열 매핑을 표현할 수 있다. 소스의 중간 노드에 해당하는 필드가 null일 경우 빈 객체를 만들어주는 기능과 배열 매핑 외에도 함수를 표현하는 방법도 매핑 표현식은 일반 표현식과 형태가 다르다.
매핑 표현식에서는 '@'로 시작하는 형태로 함수를 표현한다.
@substring(input1.person.name, 0, 4)
매핑 표현식에서 사용할 수 있는 함수들은 다음과 같다.
| 함수 | 설명 |
|---|---|
@arraySize(arg1) |
배열의 크기를 리턴한다.
|
@date(arg1?) |
인자가 없을 경우 기본 서식 형태(yyyy-MM-dd)로 현재 시간을 리턴한다.
|
@time(arg1) |
인자가 나타내는 서식 형태로 현재 시간을 리턴한다.
|
@strlen(arg1) |
문자열의 길이를 리턴한다.
|
@trim(arg1) |
문자열의 앞뒤에 존재하는 공백문자들을 제거한 문자열을 리턴한다.
|
@substring(arg1, arg2, arg3?) |
구조적 표현식이 나타내는 문자열의 부분 문자열을 리턴한다.
|
@concat(arg1, arg2?, arg3?, …) |
여러 개의 문자열을 하나로 합친 문자열을 리턴한다. 각 인자들은 String, char, 혹은 숫자값을 나타내는 구조적 표현식들이다. |
@replace(arg1, arg2, arg3) |
문자열의 일부를 다른 문자열로 치환한 문자열을 리턴한다.
|
@dateformat(arg1, arg2, arg3) |
특정 날짜 서식으로 표현된 문자열을 다른 날짜 서식으로 변환한다.
|
@charAt(arg1, arg2) |
문자열의 특정 위치 문자를 리턴한다.
|
@isNull(arg1) |
구조적 표현식의 결과값이 null인지 여부를 리턴한다.
|
@numberformat(arg1, arg2) |
숫자값을 특정 서식으로 변환한다.
|
@urlEncode(arg1) |
UTF8 문자셋으로 url-encode를 한 문자열을 리턴한다.
|
@getNull() |
null 객체를 리턴한다. |
@equals(arg1, arg2) |
두 객체의 동등 여부를 비교한다.
|
@sequence(arg1, arg2, arg3) |
시퀀스를 획득한다.
|
8. 사용자 코드와 핸들러
AnyLink 서비스 플로우에서는 사용자가 직접 Java 코드를 작성하여 액티비티를 실행하거나 서비스 플로우와 액티비티의 특정 시점 혹은 에러 상황에서 추가적인 코드를 실행시키는 기능을 제공한다.
서비스 플로우 엔진에서 사용자 코드를 사용할 수 있는 부분은 다음과 같다.
-
사용자 클래스 액티비티
사용자가 작성한 Java 코드를 실행하는 액티비티.
사용자가 작성한 Java 코드는 com.tmax.anylink.api.serviceflow 패키지의 DefaultUserActivity 클래스를 상속해야 한다.
// 사용자 액티비티의 주 메소드 void action(ActivityContext ctx) throws AnyLinkException;
-
프로세스 핸들러
서비스 플로우의 시작, 종료 등의 시점에서 호출되는 핸들러 클래스이다.
사용자가 작성한 Java 코드는 com.tmax.anylink.api.serviceflow 패키지의 DefaultProcessHandler 클래스를 상속해야 한다.
// 서비스 플로우 시작 시 호출 void started(ProcessContext ctx) throws AnyLinkException; // 서비스 플로우 종료 시 호출 void finished(ProcessContext ctx) throws AnyLinkException; // 내부적으로만 정의됨. 실제 호출되지는 않음 void paused(ProcessContext ctx) throws AnyLinkException; // 내부적으로만 정의됨. 실제 호출되지는 않음 void resumed(ProcessContext ctx) throws AnyLinkException;
-
프로세스 에러 핸들러
서비스 플로우 실행 도중에 처리하지 못하는 에러가 발생할 경우 호출되는 핸들러 클래스이다.
사용자가 작성한 Java 코드는 com.tmax.anylink.api.serviceflow 패키지의 DefaultProcessErrorHandler 클래스를 상속해야 한다.
// 에러 핸들러가 정의된 서비스 플로우 실행 도중 에러가 발생할 때 호출 void handle(ProcessContext context, Throwable error) throws AnyLinkException;
-
액티비티 핸들러
액티비티의 시작, 종료, 취소 종료, 에러 종료 등의 시점에서 호출되는 핸들러 클래스이다.
사용자가 작성한 Java 코드는 com.tmax.anylink.api.serviceflow 패키지의 DefaultActivityHandler 클래스를 상속해야 한다.
// 핸들러가 정의된 액티비티의 시작 시점에 호출 void started(ActivityContext ctx) throws AnyLinkException; // 핸들러가 정의된 액티비티의 완료 시점에 호출 void finished(ActivityContext ctx) throws AnyLinkException; // 핸들러가 정의된 액티비티의 취소 완료 시점에 호출 void cancelled(ActivityContext ctx, String cause) throws AnyLinkException; // 핸들러가 정의된 액티비티의 에러 완료 시점에 호출 void errorOccurred(ActivityContext ctx, Throwable t) throws AnyLinkException;
-
액티비티 에러 핸들러
액티비티 실행 도중에 처리하지 못하는 에러가 발생할 경우 호출되는 핸들러 클래스이다.
사용자가 작성한 Java 코드는 com.tmax.anylink.api.serviceflow 패키지의 DefaultActivityErrorHandler 클래스를 상속해야 한다.
// 에러 핸들러가 정의된 액티비티 실행 도중 에러가 발생할 때 호출 void handle(ActivityContext context, Throwable error) throws AnyLinkException;
-
에러 코드 매퍼
서비스 플로우에서는 에러 이벤트를 발생시키거나 잡을 때 에러 코드를 사용한다. 즉, End 이벤트로 작성된 에러 이벤트는 지정한 에러 코드의 에러 이벤트를 발생시키는 역할을 하고, 바운더리 에러 이벤트는 해당 액티비티 내에서 발생한 에러를 에러 코드에 따라 잡는 역할을 한다. 에러 코드 매퍼는 액티비티 수행 도중 발생하는 Java Exception 객체들을 에러 코드로 변환하는 기능을 수행한다. 에러 코드 매퍼 클래스는 서비스 플로우에서 지정할 수 있다.
사용자가 작성한 Java 코드는 com.tmax.anylink.api.serviceflow 패키지의 DefaultErrorCodeMapper 클래스를 상속해야 한다.
// 발생한 Exception을 보고 에러 코드를 판별하여주는 이 메소드를 구현해야 한다. String getErrorCode(Throwable throwable);
-
서비스 액티비티 핸들러
액티비티 핸들러의 기능에 더하여 서비스를 호출하기 전과 호출한 후의 시점에서 추가로 호출되는 핸들러 클래스이다.
사용자가 작성한 Java 코드는 com.tmax.anylink.api.serviceflow 패키지의 DefaultServiceActivityHandler 클래스를 상속해야 한다.
// 핸들러가 정의된 서비스 액티비티의 서비스 호출 직전에 호출 void beforeServiceCall(ActivityContext ctx, MessageContext mctx) throws AnyLinkException; // 핸들러가 정의된 서비스 액티비티의 서비스 호출 직후에 호출 void afterServiceCall(ActivityContext ctx, MessageContext mctx) throws AnyLinkException;
9. 코릴레이션
코릴레이션(Correlation)은 독립적인 개체들을 연관시키는 것을 의미한다.
AnyLink에서 코릴레이션은 TCP 어댑터 등에서 요청 메시지와 이에 대응하는 응답 메시지를 찾아주기 위해 사용하기도 한다. AnyLink 서비스 플로우 엔진에서 얘기하는 코릴레이션은 특정한 서비스를 나타내는 이벤트가 발생하였을 때 이미 실행 중인 서비스 플로우 인스턴스들 중에서 현재 발생한 이벤트와 관련있는 인스턴스를 찾아서 이벤트를 해당 서비스 플로우 인스턴스에게 전달해주는 일을 뜻하는 것으로 서비스 플로우 인스턴스와 발생 이벤트를 연관시키는 행위라고 볼 수 있다.
보통 서비스 플로우 엔진에서 이벤트가 발생하면 이벤트가 시작 이벤트(Start Event) 즉, 서비스 플로우의 처음 이벤트일 경우에는 서비스 플로우 인스턴스를 새로 생성하는 역할을 하게 된다.
코릴레이션을 사용하는 이벤트들은 주로 서비스 플로우가 실행 도중에 이벤트 발생을 대기하게 되는 중간 이벤트(Intermediate Event)들이다. 보통의 중간 이벤트일 수도 있고, 바운더리 이벤트일 수도 있다.
서비스 플로우 엔진에서 코릴레이션 이벤트는 기대하는 코릴레이션 값을 등록(registering correlation)하는 과정과 해당 서비스에 해당하는 서비스가 발생했을 때 일치하는 코릴레이션 이벤트 인스턴스를 찾는 매칭(matching) 과정 두 가지 절차를 거쳐 서비스 플로우 인스턴스와 서비스와의 코릴레이션을 수행하게 된다.
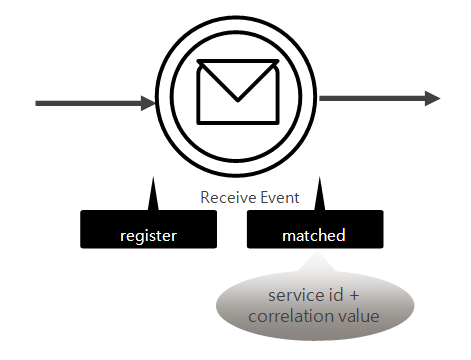
서비스 플로우가 트랜지션을 통해 코릴레이션을 사용한 중간 이벤트에 도달하게 되면 AnyLink 서비스 플로우 엔진은 내부적으로 코릴레이션을 위한 값을 계산하여 서비스 ID와 함께 내부적으로 가지고 있는 코릴레이션 정보 테이블에 등록한다.
AnyLink 딜리버리 채널을 통해 서비스 플로우 엔진으로 메시지가 전달되면 서비스 플로우 엔진은 다음의 순서로 처리한다.
-
해당 서비스가 서비스 플로우의 시작 메시지 이벤트에 해당하는 서비스인 경우에는 서비스 플로우 인스턴스를 새로 만들게 된다.
-
해당 서비스가 코릴레이션이 필요한 메시지 이벤트에 해당하는 서비스인 경우에는 코릴레이션 매칭을 시도한다. 코릴레이션 값이 매칭되는 메시지 이벤트가 발견되면 해당 이벤트가 속한 서비스 플로우 인스턴스로 메시지를 전달하여 해당 플로우 인스턴스가 다음으로 트랜지션되도록 한다.
-
코릴레이션 매칭에 실패하면 코릴레이션 없이 해당 서비스를 기다리고 있는 메시지 이벤트를 찾아서 해당 이벤트가 속한 서비스 플로우 인스턴스 메소드를 전달하여 해당 플로우 인스턴스가 다음으로 트랜지션되도록 한다.
-
해당 서비스를 기다리는 메시지 이벤트들이 하나도 등록되어 있지 않은 경우에는 서비스 플로우 엔진 내부적으로 메시지 이벤트가 등록되기 전에 먼저 도달했다고 가정하고 조기 도달 메시지 맵(Early arrived message map)에 저장해둔다. 이벤트 등록보다 먼저 도달한 메시지를 기다려주는 시간은 기본적으로 3초이다.
AnyLink 서비스 플로우 엔진에서 코릴레이션 값의 매칭이 발생하는 경우는 서비스 ID(서비스 플로우 ID와 해당 메시지 이벤트 ID의 조합으로 구성)가 같고, 계산된 코릴레이션 값이 서비스 플로우 인스턴스가 등록한 코릴레이션 값과 같을 때이다.
이를 위해 서비스 플로우의 중간 이벤트들은 코릴레이션을 위해 등록 표현식(registration expression)과 매칭 표현식(matching expression)을 지정할 수 있다.
만약 서로 다른 서비스 플로우 혹은 메시지 이벤트들 간에 코릴레이션이 필요한 경우에는 멀티바인딩 라우터를 사용할 수가 있다. 멀티바인딩 라우터의 라우팅 메소드를 서비스 플로우 코릴레이션으로 선택하면 서로 다른 서비스를 사용하여 코릴레이션 값 매칭을 할 수가 있다.