스케줄러 서비스 개발
본 장에서는 스케줄러의 소개와 스케줄러 내부 구성 요소 및 개발에 대해 설명한다.
1. 개요
스케줄러는 사용자가 특정 시간대에 직접 실행하지 않고 스케줄 등록을 통해 특정 시간 특정 반복 등을 통해 런타임 운영 특히 주기적인 배치 실행에 도움을 주도록 하는 시스템이다.
스케줄러는 현재 스케줄 정보를 DB로 관리하며, 스케줄 정보를 ProManager를 통해 등록 및 수정하도록 되어 있다. 또한 영구적인 스케줄이 아닌 서버 기동할 때에만 존재해야 하는 스케줄의 경우 특정 API를 통해 DB에 등록할지(영구등록), 메모리상 등록할지 결정하여 업무에 맞게 스케줄 제어를 할 수 있다.
현재 스케줄 정보는 DB와 메모리에 존재하게 되며 DB에 존재하는 스케줄은 영구적인 스케줄을 등록할 때 사용되며, 메모리상 스케줄은 서버가 기동할 때에 API를 통해 등록하고 서버가 재부팅할 때에는 삭제된다.
스케줄러는 다음과 같은 기능들을 제공한다.
-
cron 표현식을 이용한 시간 작업 실행
-
연, 월, 주, 일, 시, 분 등의 반복 및 시간 지정 가능하다.
-
cron 표현식은 Quartz의 cron format을 따른다.
-
http://www.cronmaker.com/을 통해 표현식을 간단히 생성 가능하다.
-
-
스케줄 반복
-
반복 횟수 지정 및 반복 주기 지정이 가능하다.
-
반복 횟수를 무한으로 지정하여, 일반 배치를 스케줄하여 상주배치와 동일하게 활용 가능하다.
-
-
스케줄 중복실행 여부 설정
-
등록된 스케줄이 실행 중인 경우 다음 주기가 도달하여 실행할지, 실행을 방지할지 설정할 수 있다.
-
업무상 해당 배치 혹은 서비스가 하나만 실행되어야 하는 경우 설정을 통해 스케줄 중복실행을 방지할 수 있다.
-
1.1. 스케줄 아키텍처
스케줄러는 ProObject 서버 내에 이벤트 및 시스템 서비스로 동작한다.
스케줄 설정이 된 경우에 기동할 때 ScheduleInitEvent 및 스케줄 서비스그룹이 기동되어 DB에서 스케줄을 읽어 스케줄을 구동한다.
스케줄러가 구동된 후 스케줄을 추가, 수정, 삭제하는 경우에는 ScheduleControlService를 통해 서버에 스케줄이 변경되었음을 알려 엔진에서 스케줄을 다시 읽어 동작하도록 한다.
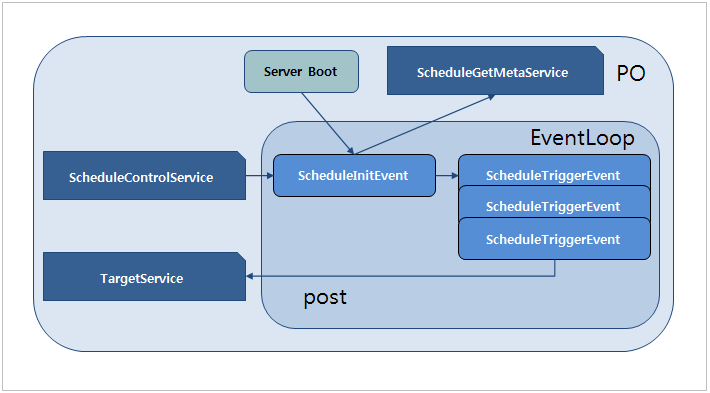
스케줄러의 서비스는 다음의 역할을 한다.
-
ScheduleControlService
proobject.schedule.ScheduleControlService는 스케줄 실행 정보가 갱신되었음을 알려주거나 스케줄 주기가 도래하지 않은 스케줄을 즉시 실행시키기 위한 명령을 수행한다. 해당 서비스는 시스템 서비스로 스케줄 서비스 그룹에 속해 있다.
입력 데이터는 다음과 같다.
-
ScheduleControlDataObject
변수명 설명 cmdName
ScheduleControlService가 처리해야 하는 동작을 정의한다(대소문자 구분하니 입력에 주의해야 한다).
-
reload : 런타임이 디비의 스케줄 정보를 읽어서 변경된 스케줄 정보를 반영한다.
-
-
-
ScheduleCmdService
proobject.schedule.ScheduleCmdService는 런타임에 스케줄의 실행에 관한 명령을 수행한다. 해당 서비스는 시스템 서비스로 스케줄 서비스 그룹에 속해있으며 입력 데이터는 다음과 같다.
변수명 설명 cmdName
ScheduleControlService가 처리해야 하는 동작을 정의한다(대소문자 구분하니 입력에 주의해야 한다).
-
RUN_IMMEDIATELY : 스케줄 주기가 도래하지 않은 스케줄을 즉시 실행시킨다.
-
EXCLUSIVE : 스케줄 플로우 기능을 사용하는 경우 플로우에 속한 스케줄들중 특정 스케줄만 런타임에서 단독 실행되도록 한다.
cmdValue
cmdName에 지정한 명령을 수행하기 위한 정보를 JSON 형태로 입력한다.
JSON 키 값은 다음과 같다.
-
sId
-
RUN_IMMEDIATELY : 스케줄을 즉시 실행시킬 대상의 스케줄 아이디
-
EXCLUSIVE : 단독 실행되야 하는 대상의 스케줄 아이디
-
-
flowId : 단독 실행을 적용할 플로우의 스케줄 플로우 아이디
-
userYN
-
y : PO_SCHEDULE_MAIN의 useryn 값을 'y’로 변경한다.
-
n : PO_SCHEDULE_MAIN의 useryn 값을 'n’으로 변경한다. 단독 실행 명령어의 대상이되는 스케줄을 제외한 나머지 스케줄들의 userYN값을 'n’으로 변경하여 스케줄링이 되지 않도록 한다.
-
-
1.2. 캘린더
캘린더는 스케줄 조건(cronExpression)으로 표현할 수 없는 휴일 및 영업일에 대한 처리를 위해 사용된다.
캘린더를 생성하여 Trigger 테이블의 biz_calId에 아이디를 입력하여 영업 캘린더로 사용할 수 있으며 Trigger 테이블의 holy_calId에 입력하여 휴일 캘린더로 활용할 수 있다. 캘린더는 baseCalendarId를 지정하여 다른 캘린더를 복합적으로 사용할 수 있다.
캘린더는 유형에 맞게 사용할 수 있도록 다양한 타입의 캘린더가 존재하며 캘린더를 조합하여 활용할 수 있다.
| 종류 | 내용 및 예제 |
|---|---|
CRON |
CronExpression으로 지정한다.
|
ANNUAL |
매 년 중 특정 월 일을 지정한다.
|
MONTHLY |
한달 중 특정 날짜를 지정한다.
|
WEEKLY |
요일 지정지정한다.
|
DAILY |
매일 하루 중 시간 지정한다.
|
RANGE |
지정일자 ~ 지정일자 범위를 지정한다.
|
DAYS |
날짜를 각각 지정한다.
|
2. 스케줄러 설정
스케줄러를 사용하기 위해서는 테이블을 생성해야 하며, 서버 기동 이전에 다음의 파일에 설정한다.
${PROOBJECT_HOME}/config/proobject.xml
스케줄러가 스케줄 테이블에 접근하기 위해서는 데이터소스 설정이 필요하다. 해당 설정은 proobject.xml의 <engine-config> 하위에 <proObject-datasource>에 설정한다.
<proObject-datasource>에 이미 ${PROOBJECT_HOME}/system/config/dbio_config.xml에 설정한 alias 중에서 사용할 alias를 설정해야 한다.
<engine-config>
<proObject-datasource>sc_ds</proObject-datasource>
</engine-config>
모든 스케줄 설정은 <schedule-config> 하위에 설정한다. <schedule-config>를 설정하게 되면 ProObject가 기동할 때 스케줄 서비스 그룹이 자동 등록되며, 스케줄 마스터 서비스(스케줄러)가 호출되어 스케줄이 동작한다.
다음은 스케줄 설정한 예이다.
<schedule-config>
<schedule-status-enable>true</schedule-status-enable>
<schedule-flow-enable>true</schedule-flow-enable>
<trigger-handler>인터페이스 구현체 클래스</trigger-handler>
<flow-handler>인터페이스 구현체 클래스</flow-handler>
<schedule-custom-type>
<main-table-name>...</main-table-name>
<trigger-table-name>...</trigger-table-name>
<target-table-name>...</target-table-name>
<status-table-name>...</status-table-name>
<history-table-name>...</history-table-name>
<calendar-table-name>...</calendar-table-name>
<main-flow-table-name>...</main-flow-table-name>
<sub-flow-table-name>...</sub-flow-table-name>
<flow-status-table-name>...</flow-status-table-name>
</schedule-custom-type>
</schedule-config>
| 태그 | 설명 |
|---|---|
<schedule-status-enable> |
스케줄 상태를 기록할지 여부를 설정한다.
|
<schedule-flow-enable> |
스케줄 플로우 기능을 사용하도록 하는 설정이다. 등록한 스케줄이 실행될 때 선행 작업과 후행 작업을 등록하여 조건에 따라 실행되게 할지 설정한다.
|
<trigger-handler> |
스케줄의 선후처리 인터페이스를 등록한다. com.tmax.proobject.schedule.handler.IScheduleTriggerHandler 인터페이스를 구현한 구현체의 패키지명을 포함한 클래스명을 설정한다. 구현한 클래스는 PO HOME 경로의 system/lib 디렉터리 안에 위치시켜야 하며 인터페이스의 API들은 스케줄이 호출되기 전, 호출되어 응답이 왔을 때, 호출된 응답에 에러가 존재할 때 불린다. |
<flow-handler> |
스케줄 플로우 기능을 사용할 때 스케줄 플로우에 의해 실행되는 서비스나 배치의 선후처리를 수행하기 위한 인터페이스를 등록한다. com.tmax.proobject.schedule.handler.IScheduleFlowSequenceHandler 인터페이스를 구현한 구현체의 패키지명을 포함한 클래스명을 설정한다. 구현한 클래스는 PO HOME 경로의 system/lib 디렉터리 안에 위치시켜야 하며 인터페이스의 API들은 스케줄의 작업 대상 서비스가 호출되기 전, 호출되어 응답이 왔을 때, 호출된 응답에 에러가 존재할 때 불린다. |
<schedule-custom-type> |
스케줄에서 사용하는 테이블 이름을 임의로 커스터마이징하여 사용할 수 있는 설정이다. 변경할 테이블에 해당하는 태그에 변경하고자 하는 이름을 설정한다. 테이블의 이름만 바뀔뿐 스키마는 동일하게 유지해야 한다.
|
3. 스케줄러 인터페이스
3.1. IScheduleTriggerHandler
사용자가 등록한 스케줄이 호출되기 전, 호출된 후, 혹은 에러 처리를 하기 위한 인터페이스다.
인터페이스 기능을 사용하기 위해서 사용자는 지정된 인터페이스를 상속받은 구현체를 작성하고 proobject.xsd의 <schedule-config>의 <trigger-handler> 항목에 설정해야 한다.
/*
* Copyright (c) 2016 by TmaxSoft co., Ltd.
* All rights reserved.
*
* This software is the confidential and proprietary information
* of TmaxSoft co., Ltd("Confidential Information"). You
* shall not disclose such Confidential Information and shall use
* it only in accordance with the terms of the license agreement
* you entered into with TmaxSoft co., Ltd.
*/
package com.tmax.proobject.schedule.handler;
import com.tmax.proobject.model.dataobject.DataObject;
import com.tmax.proobject.schedule.model.ScheduleModelSet;
/**
* 스케줄이 트리거에의해 기동했을때 선후처리 혹은 에러 처리를 위한 핸들러 인터페이스이다.</br>
* 스케줄 플로우 기능 사용시, 스케줄 플로우가 시작되고 종료될 때의 선후처리 혹은 에러 처리를 한다.</br>
* 구현후 구현체는 system/lib에 위치시켜야하며 proobject.xml의 schedule-config에 관련 설정을 추가해야 한다.
*
* @author unseok.kim
* @since 2019. 12. 4.
*/
public interface IScheduleTriggerHandler {
/**
* 스케줄이 트리거되어 실행되기 직전 처리해야하는 로직이 있다면, 이 메소드를 통해 구현한다.</br>
* 반환값이 true인 경우, 스케줄을 통한 SO,JOB,SHELL을 실행시키지 않고 다음 주기를 스케줄링한다.
*
* @since 2019. 12. 4.
* @param sid 트리거된 스케줄의 아이디
* @param exId 트리거된 스케줄의 실행 번호 혹은 플로우 기능 사용시 트리거된 스케줄 플로우의 실행번호
* @param set 트리거된 스케줄의 정보가 담겨있는 모델 객체
* @return 현재 트리거된 스케줄을 skip할지 여부를 결정한다.
*/
public boolean preProcess(String sid, String exId, ScheduleModelSet set);
/**
* 스케줄이 트리거되어 실행된후, 스케줄을 통해 실행된 SO, JOB, SHELL의 동작이 종료된후 실행할 로직
*
* @since 2019. 12. 4.
* @param sid 트리거된 스케줄의 아이디
* @param exId 트리거된 스케줄의 실행 번호 혹은 플로우 기능 사용시 트리거된 스케줄 플로우의 실행번호
* @param set 트리거된 스케줄의 정보가 담겨있는 모델 객체
* @param outputDataObject 트리건된 스케줄이 호출한 ServiceObject의 반환값.</br>
* Job 혹은 스탠드얼론으로 호출된 서비스의 경우 반환값이 존재하지 않기 때문에 데이터가 전달되지 않음을 유의.
*/
public void postProcess(String sid, String exId, ScheduleModelSet set, DataObject outputDataObject);
/**
* 스케줄이 트리거되어 실행된후, 스케줄을 통해 실행된 SO, JOB, SHELL이 에러를 발생시키며 종료된경우 실행할 로직
*
* @since 7 Fix #1
* @param sid 트리거된 스케줄의 아이디
* @param exId 트리거된 스케줄의 실행 번호 혹은 플로우 기능 사용시 트리거된 스케줄 플로우의 실행번호
* @param set 트리거된 스케줄의 정보가 담겨있는 모델 객체
* @param t 스케줄을 통해 실행된 SO, JOB, SHELL에서 발생시킨 Exception
*/
public void postProcessOnError(String sid, String exId, ScheduleModelSet set, Throwable t);
}
3.2. IScheduleFlowSequenceHandler
스케줄 플로우 기능 사용 시 스케줄 플로우에서 호출한 사용자의 서비스, 배치를 호출하기 전, 호출한 후, 호출한 서비스나 배치가 에러로 종료된 경우 처리하기 위한 인터페이스다.
인터페이스 기능을 사용하기 위해서 사용자는 지정된 인터페이스를 상속받은 구현체를 작성하고 proobject.xsd의 <schedule-config>의 <flow-handler> 항목에 설정해야 한다.
package com.tmax.proobject.schedule.handler;
import com.tmax.proobject.model.dataobject.DataObject;
import com.tmax.proobject.schedule.event.ScheduleTriggerEvent.ScheduleTriggerEventPhase;
import com.tmax.proobject.schedule.model.ScheduleModelSet;
/**
* 스케줄 플로우를 통해 실행되는 각각의 작업들에 대한 후처리 및 에러 처리를 위한 핸들러 인터페이스이다.</br>
* 구현 후 구현체는 system/lib에 위치시켜야하며, proobject.xml의 schedule-config에 관련 설정을 추가해야
* 한다.
*
* @author YimSinHyuk
* @since 2021. 2. 25.
*/
public interface IScheduleFlowSequenceHandler {
/**
* 스케줄러가 서비스 혹은 배치 잡을 호출하여, PO_SCHEDULE_STATUS에 이력을 남길때 호출되는 인터페이스
*
* @since 7 Fix #1
* @param sid 현재 실행하려는 스케줄의 아이디
* @param exId 현재 실행하려는 스케줄의 실행 번호
* @param flowExId 현재 실행하려는 스케줄이 속한 플로우의 실행 번호
* @param phase 현재 실행하려는 스케줄의 단계(PRE, MAIN, POST)
* @param seq 현재 실행하려는 스케줄의 순서
* @param repeatCnt 현재 실행하려는 스케줄의 반복횟수
* @param set 현재 실행하려는 스케줄의 정보가 담겨있는 모델 객체
*/
public void preProcess(String sid, String exId, String flowId, String flowExId, ScheduleTriggerEventPhase phase, int seq, int repeatCnt,
ScheduleModelSet set);
/**
* 스케줄러가 호출한 서비스 혹은 배치 잡에 대한 응답이 돌아와서, PO_SCHEDULE_STATUS의 이력을 지우고, </br>
* PO_SCHEDULE_HISTORY로 이력을 옮기려고 할 때 호출되는 인터페이스
*
* @since 7 Fix #1
* @param sid 실행한 스케줄의 아이디
* @param exId 실행한 스케줄의 실행 번호
* @param flowExId 실행한 스케줄이 속한 플로우의 실행 번호
* @param phase 실행한 스케줄의 단계(PRE, MAIN, POST)
* @param seq 실행한 스케줄의 순서
* @param repeatCnt 실행한 스케줄의 반복횟수
* @param set 실행한 스케줄의 정보가 담겨있는 모델 객체
* @param outputDataObject 스케줄이 호출한 ServiceObject의 응답 결과.</br>
* Job 혹은 스탠드얼론으로 실행시킨 서비스의 경우, DataObject로 결과가 반환되지 않기 때문에 데이터가 전달되지 않음을 유의.
*/
public void postProcess(String sid, String exId, String flowId, String flowExId, ScheduleTriggerEventPhase phase, int seq, int repeatCnt,
ScheduleModelSet set, DataObject outputDataObject);
/**
* 스케줄러가 호출한 서비스 혹은 배치 잡이 실패하여 응답값에 에러가 포함된 경우, PO_SCHEDULE_STATUS의 이력을 지우고,
* </br>
* PO_SCHEDULE_HISTORY로 이력을 옮기려고 할 때 호출되는 인터페이스
*
* @since 7 Fix #1
* @param sid 실행한 스케줄의 아이디
* @param exId 실행한 스케줄의 실행 번호
* @param flowExId 실행한 스케줄이 속한 플로우의 실행 번호
* @param phase 실행한 스케줄의 단계(PRE, MAIN, POST)
* @param seq 실행한 스케줄의 순서
* @param repeatCnt 실행한 스케줄의 반복횟수
* @param set 실행한 스케줄의 정보가 담겨있는 모델 객체
* @param responseException 호출한 서비스나 배치 잡에 대한 에러
*/
public void postProcessOnError(String sid, String exId, String flowId, String flowExId, ScheduleTriggerEventPhase phase, int seq, int repeatCnt,
ScheduleModelSet set, Throwable responseException);
}
4. 스케줄 플로우
ProObject의 스케줄러는 작업의 편의성을 위해 등록된 스케줄이 실행되기 전, 후에 실행되야하는 선후 처리 작업을 추가할 수 있다. 이를 스케줄의 플로우 기능이라 명하며, 스케줄은 크게 "선행 플로우 > 본 스케줄 > 후행 플로우" 순서로 동작하게 된다. 이 기능을 사용하기 위해서는 proobject.xml의 <schedule-config>에 <schedule-flow-enable>을 통해서 기능 사용을 설정해야 하며 플로우 관련 테이블들이 생성되어 있어야 한다.
4.1. 스케줄 플로우 구조
스케줄 플로우는 크게 메인 플로우와 서브 플로우로 구분할 수 있으며, 메인 플로우는 PO_SCHEDULE_MAIN을 통해 등록된 스케줄들을 의미하고 서브 플로우는 PO_SCHEDULE_SUB_FLOW에 등록한 작업 대상들을 의미한다.
스케줄 플로우에는 PO_SCHEDULE_MAIN에 등록한 스케줄들이 속할 수 있으며, 스케줄이 트리거 되어 호출될 때 플로우에 등록한 설정들을 공유한다. PO_SCHEDULE_MAIN_FLOW에는 플로우를 진행시키기 위한 조건 값등이 지정되어 있으며, 플로우 진행시 해당 조건값과 스케줄 실행 결과를 비교하여 진행하게 된다. 즉, 기존 ProObject 스케줄러 기능과 마찬가지로 트리거된 스케줄이 실행될 때 해당 스케줄이 속한 플로우의 정보를 기반으로 선후행 플로우를 실행하는 구조이다.
선행 플로우
선행 플로우는 트리거된 스케줄이 실행되기전 수행되는 로직으로써, 메인이 되는 작업을 수행하기전 작업해야하는 대상들이 존재할 경우 사용한다. 스케줄에 선행 작업이 등록된 경우 PO_SCHEDULE_SUB_FLOW에 등록된 type이 'PRE’인 대상들을 seq 순서에 맞춰서 호출한다. 선행 작업들은 seq 순서에 맞춰서 호출되며, 각 작업들은 PO_SCHEDULE_SUB_FLOW에 지정된 repeatMaxCnt 횟수 만큼 반복 수행하게된다.
반복수행 시 실행한 작업의 성공, 실패 유무와 상관없이 지정된 횟수만큼의 반복을 보장하며, 가장 마지막에 실행된 작업의 결과만을 다음 seq 실행 조건으로 사용한다.
선행 작업이 다음 seq 작업을 실행하기 위한 조건은 PO_SCHEDULE_MAIN_FLOW에 지정된 innerPreCondition값을 따른다. 앞서 실행한 작업의 성공, 실패 여부와 innerPreCodition 값을 비교하여 다음 seq 작업을 진행하며 모든 seq의 작업이 호출되고 innerPreCondition 조건을 만족시켰을 때 선행 플로우가 성공했다고 결정한다.
등록된 모든 seq의 선행 작업이 호출되지 않거나 마지막 seq의 작업결과가 innerPreCodition의 조건을 만족하지 못했을 때 선행 플로우가 실패했다고 결정한다. 선행 플로우의 성공, 실패 여부는 PO_SCHEDULE_MAIN_FLOW에 지정한 preCondition 값과 비교하여 본 스케줄러를 실행할지 결정한다.
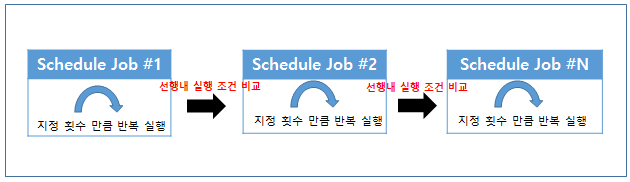
메인 플로우
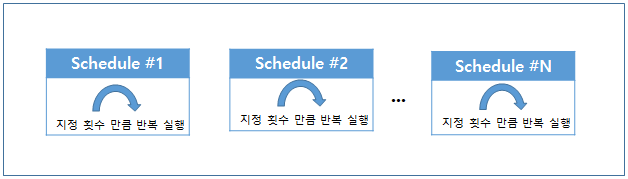
PO_SCHEDULE_MAIN에 등록한 스케줄이 실행되는 영역이다. 선후행 플로우와 달리 여러 작업이 순차로 실행되지는 않으며, 트리거에 의해 실행된 스케줄만 동작한다.
메인 스케줄의 경우 기존 ProObject의 스케줄과 동일하게 동작하며, 스케줄 동작 종료후 조건 비교를 통해 후행 플로우를 실행 시킬수 있다. 메인 스케줄이 속한 플로우에 선행 플로우가 존재하는 경우 선행 플로우의 결과가 preCondition 값을 충족시켰을 때 실행되거나, 선행 플로우가 존재하지 않은 경우 실행된다. 메인 스케줄은 수행된 스케줄을 트리거한 트리거의 repeatMaxCnt 횟수 만큼 반복 수행하게된다.
반복수행시 실행한 작업의 성공, 실패 유무와 상관없이 지정된 횟수만큼의 반복을 보장하며, 가장 마지막에 실행된 작업의 결과만을 후행 플로우 실행 조건으로 사용한다. 메인 플로우의 스케줄이 종료되면 스케줄이 호출한 작업의 성공, 실패 여부에 따라 PO_SCHEDULE_MAIN_FLOW에 지정된 postCondition 값과 비교하여 후행 플로우를 호출할지 결정한다.
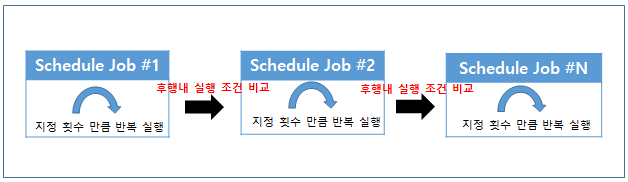
후행 플로우
사용자가 설정한 트리거에의해 호출된 스케줄의 동작이 종료되고, 이어서 수행해야하는 작업이 존재할 경우 후속으로 수행되야하는 배치나 서비스등을 등록하여 사용한다.
스케줄의 메인 플로우가 postCodition 조건을 충족시켰고, 스케줄에 후행 작업이 등록된 경우 PO_SCHEDULE_SUB_FLOW에 등록된 type이 'POST’인 대상들을 seq 순서에 맞춰서 호출한다. 후행 작업들은 seq 순서에 맞춰서 호출되며, 각 작업들은 PO_SCHEDULE_SUB_FLOW에 지정된 repeatMaxCnt 횟수 만큼 반복 수행하게된다. 반복수행 시 실행한 작업의 성공, 실패 유무와 상관없이 지정된 횟수만큼의 반복을 보장하며, 가장 마지막에 실행된 작업의 결과만을 다음 seq 실행 조건으로 사용한다.
후행 작업이 다음 seq 작업을 실행하기 위한 조건은 PO_SCHEDULE_MAIN_FLOW에 지정된 innerPostCodition값을 따른다. 앞서 실행한 작업의 성공, 실패 여부와 innerPostCodition 값을 비교하여 다음 seq 작업을 진행하며 모든 seq의 작업이 호출되고 innerPostCondition 조건을 만족시켰을 때 후행 플로우가 성공했다고 결정한다. 등록된 모든 seq의 후행 작업이 호출되지 않거나, 마지막 seq의 작업결과가 innerPostCodition의 조건을 만족하지 못했을 때 후행 플로우가 실패했다고 결정한다.
4.2. 플로우 실행 이력
스케줄 플로우 자체에 대한 이력은 PO_SCHEDULE_FLOW_STATUS에 기록된다. 스케줄 플로우가 시작되면, 실행된 플로우에는 실행번호가 부여된다. 이 실행번호를 기준으로 특정 플로우에서 수행된 스케줄 정보를 확인할 수 있으며, 스케줄 플로우 내에서 실행된 개별 작업들에 대해서는 PO_SCHEDULE_HISTORY에 이력이 남는다.
4.3. 일별 실행횟수 제한
스케줄 플로우는 하루동안 실행될수 있는 횟수를 제한할 수 있다. PO_SCHEDULE_MAIN_FLOW의 dailyExeCnt 값을 통해 설정할 수 있으며, 하루 동안 지정된 횟수만큼의 수행만을 보장한다. 설정한 값 이상으로 플로우가 실행되려 하면, 런타임 스케줄러는 해당 플로우의 실행을 제한하며, 다음날 00:00:00을 기준으로 재스케줄링하여 스케줄이 동작할 수 있도록 한다.
4.4. 단독실행
특정 스케줄 플로우에 여러 스케줄이 등록되어 있을 때 ProObject 런타임에 하나의 스케줄만 동작할 수 있도록 보장하는 기능이다. 해당 기능은 사용자가 선택한 스케줄이 속한 플로우에서 다른 스케줄들을 사용중지 상태로 만들고 재스케줄링하여 사용자가 지정한 스케줄만 런타임에서 수행할 수 있도록 한다.
단독실행은 'proobject.schedule.ScheduleCmdService' 서비스를 통해서 실행할 수 있으며 사용법은 다음과 같다.
-
단독실행 호출을 위해 proobject.schedule.ScheduleCmdService와 서비스의 입력값인 ScheduleCmdDataObject 객체를 생성한다.
String service = "proobject.schedule.ScheduleCmdService"; ScheduleCmdDataObject input = new ScheduleCmdDataObject();
-
ScheduleCmdDataObject의 cmdName은 실행시킬 명령어를 입력하는 변수로, 단독실행에 해당하는 명령어를 입력한다. 문자열로 "EXCLUSIVE"를 입력하거나 ScheduleCmdService.Cmd의 EXCLUSIVE를 선택한다.
input.setCmdName(ScheduleCmdService.Cmd.EXCLUSIVE.name());
-
ScheduleCmdService의 cmdValue는 모두 json 형식으로 입력한다.
EXCLUSIVE 수행시 필요한 json 키값은 ScheduleCmdService.SCHEDULE_FLOW_ID, ScheduleCmdService.SCHEDULE_ID, ScheduleCmdService.SCHEDULE_YN이다. SCHEDULE_FLOW_ID는 단독 실행시키려는 스케줄이 속한 플로우아이디 SCHEDULE_ID 단독실행 시키려는 스케줄의 아이디 SCHEDULE_YN 변경하려는 단독수행 값으로 단독수행을 하려면 'n’을 설정한다.
StringBuilder cmdBuilder = new StringBuilder(); cmdBuilder.append("{"); cmdBuilder.append("\""+ ScheduleCmdService.SCHEDULE_FLOW_ID + "\" : \"schedule1\","); cmdBuilder.append("\""+ ScheduleCmdService.SCHEDULE_ID + "\" : \"flowId1\","); cmdBuilder.append("\""+ ScheduleCmdService.SCHEDULE_YN + "\" : \"n\""); cmdBuilder.append("}"); String cmdValue = cmdBuilder.toString(); input.setCmdValue(cmdValue); -
서비스 매니저를 이용해서 proojbect.schedule.ScheduleCmdService를 호출한다.
입력받은 스케줄 플로우에 속하는 스케줄들 중에서 사용자가 설정한 스케줄을 제외한 나머지 스케줄들의 userYN값을 'n’으로 바꾸고 재스케줄링한다. 런타임은 userYN 값이 'n’인 스케줄들에 대해서는 스케줄링을 하지않으므로, 사용자가 선택한 스케줄만 스케줄링되게 된다. 디비 데이터를 변경후 스케줄을 reload한다.
ServiceManager.call(service, input); output.setDesc(input.toString());
-
단독실행을 해제하려면 동일한 입력값에 ScheduleCmdService.SCHEDULE_YN값을 'y’로 입력한다. 이전 명령어에서 userYN이 'n’으로 변경된 스케줄들을 'y’로 복원시킨다. 모든 스케줄들이 'y’가 되므로, 단독실행용으로 추가한 스케줄이 필요없다면 수동으로 지워야한다.
cmdBuilder = new StringBuilder(); cmdBuilder.append("{"); cmdBuilder.append("\""+ ScheduleCmdService.SCHEDULE_FLOW_ID + "\" : \"schedule1\","); cmdBuilder.append("\""+ ScheduleCmdService.SCHEDULE_ID + "\" : \"flowId1\","); cmdBuilder.append("\""+ ScheduleCmdService.SCHEDULE_YN + "\" : \"y\""); cmdBuilder.append("}"); cmdValue = cmdBuilder.toString(); input.setCmdValue(cmdValue); ServiceManager.call(service, input);
5. 스케줄 관련 테이블
스케줄 관련 테이블은 등록된 스케줄 정보를 관리하는 테이블과 런타임에 스케줄 상태와 종료된 스케줄 상태를 관리하는 테이블로 구성된다.
-
스케줄 정보 테이블
테이블 설명 모든 정보의 키를 가지고 있으며 스케줄 아이디 및 유효 여부 등을 관리한다.
스케줄이 실행될 조건의 대한 정보를 저장한다.
조건에 부합한 경우 실행할 서비스 정보를 저장한다.
-
스케줄 상태 테이블
테이블 설명 실행 중인 스케줄 실행 정보를 저장한다.
종료된 스케줄 정보를 저장하는 테이블이다.
-
스케줄 플로우 테이블
테이블 설명 스케줄 플로우의 실행 조건, 제한 조건등을 설정한다.
선행, 후행 플로우를 등록하고 해당 플로우들의 설정을 저장한다.
실행된 플로우의 진행 상황을 저장하는 테이블이다.
5.1. 스케줄 정보 테이블
-
PO_Schedule_Main
스케줄 메인 테이블로서 모든 정보의 키를 가지고 있으며 스케줄 아이디 및 유효 여부 등을 관리한다.
컬럼 설명 sId
스케줄 아이디를 저장한다.
sName
스케줄 이름을 저장한다. (논리명)
userYn
스케줄 사용 여부를 저장한다. (Y|N)
startTime
스케줄 사용 가능 시작시간을 저장한다. 해당 시간 이전에는 스케줄이 동작하지 않는다.
endTime
스케줄 사용 가능 종료시간을 저장한다. 해당 시간 이후에는 스케줄이 동작하지 않는다.
sTrigerId
스케줄 트리거 아이디를 저장한다. 트리거 테이블과 매핑되는 아이디이다.
targetId
스케줄 타켓 아이디를 저장한다. 타켓 테이블과 매핑되는 아이디이다.
modifyTime
스케줄 정보 수정 시간을 저장한다.
invokeCnt
스케줄의 호출 횟수를 설정한다.
설정값이 0보다 크면 호출될 때 마다 숫자를 하나씩 줄여나가며, 0이면 해당 스케줄은 더이상 동작하지 않는다. (기본값: -1, 무한)
nodeId
어떤 노드에서 해당 스케줄을 읽어 사용할지 지정한다. 수행시키고자 하는 proobject.xml의 <server-name>에 해당하는 값과 일치해야 한다.
flowId
플로우 기능 사용 시 해당 스케줄이 속한 플로우 테이블과 매핑되는 아이디이다.
bizCode
스케줄에 부여할 특정 코드값이 존재한다면 해당 코드값을 설정한다.
description
스케줄에 대한 설명, 의견을 작성한다.
-
PO_Schedule_Trigger
스케줄이 실행될 조건의 대한 정보를 저장한다.
컬럼 설명 sTrigerId
스케줄 트리거 아이디를 저장한다.
scheduleType
스케줄 타입을 저장한다. cron 타입과 on-demand 타입으로 동작한다.
-
cron : cronExpression에 따라 동작
-
on-demand : cronExpression에 의해 특정 주기마다 실행하지 않고, 스케줄 즉시 실행 기능으로만 동작한다.
cronExpression
cronExpression를 저장한다. (예: "0 0/1 * 1/1 * ? *")
biz_calId
업무용 캘린더 아이디를 저장한다.
holy_calId
휴일용 캘린더 아이디를 저장한다.
exceptionType
cron 조건이 휴일일시를 처리할 타입을 저장한다.
-
W : 업무일 +1 -1 실행
-
WL : 가까운 업무일 실행, 동일 시 +1 -1에 따라 분기
exceptionDate
cron 조건이 휴일일시를 처리하는 방법을 저장한다.
repeatMaxCnt
해당 스케줄이 트리거되었을 때 최대 반복 횟수를 저장한다.
repeatInterval
반복 주기를 저장한다. (단위: ms)
dupleExeYn
중복실행 가능 여부를 저장한다.
invokeDelayTime
조건 만족 후 호출 딜레이 정보를 저장한다.
description
스케줄 트리거에 대한 설명, 의견을 작성한다.
-
-
PO_Schedule_TARGET
조건에 부합한 경우 실행할 서비스 정보를 저장한다.
컬럼 설명 targetId
스케줄 타겟 아이디를 저장한다.
exJobType
실행 Job 종류를 저장한다.
-
JO
-
SO
-
SHELL
exInputData
-
JO, SO : Input Json
-
SHELL : shell parameter
exHeaderData
-
JO, SO : header Json
-
SHELL : null
exNodeId
스케줄이 실행되는 노드를 저장한다. PO_NODE 테이블의 NODE_ID 값이 입력된다.
exName1
-
JO, SO : 애플리케이션 이름
-
SHELL : 셸 파일명
exName2
-
JO, SO : 서버 그룹 이름
-
SHELL : 파일 경로
exName3
-
JO, SO : 서비스 이름
-
SHELL : 사용하지 않음
description
스케줄 타겟에 대한 설명, 의견을 작성한다.
-
5.2. 스케줄 상태 테이블
-
PO_Schedule_Status
현재 실행 중인 스케줄 실행 정보를 저장하는 테이블이다.
종료 이후에는 PO_Schedule_History로 데이터가 옮겨지게 된다. 또한 서버 이상으로 스케줄 실행 중 서버가 다운된 경우 부팅할 때 PO_Schedule_Status 정보를 PO_Schedule_History로 옮기게 된다.
컬럼 설명 sId
스케줄 ID를 저장한다.
sExNum
스케줄 실행번호를 저장한다.
startTime
스케줄 시작시간을 저장한다. (형식: YYYYMMddHHmmss)
modifyTime
최근 수정시간을 저장한다. (형식: YYYYMMddHHmmss)
status
상태를 저장한다.
-
PREPARE
-
RUNNING
-
TERMINATING
type
플로우에 속한 스케줄이 실행되었을 때 해당 스케줄이 속한 플로우의 종류를 저장한다.
-
PRE
-
MAIN
-
POST
seq
실행된 스케줄이 선행이나 후행 플로우에 속한다면, 실행된 순서를 저장한다.
repeatCnt
현재 반복 회차를 저장한다.
nodeId
실행되고 있는 노드 아이디를 저장한다.
flowId
실행된 스케줄이 속한 플로우 아이디를 저장한다.
flowExNum
실행된 플로우의 실행번호를 저장한다.
run_Immediately
-
0 : cronExpression을 통해 실행된 스케줄
-
1 : 즉시실행 기능을 통해 실행된 스케줄
-
-
PO_Schedule_History
종료된 스케줄 정보를 저장하는 테이블이다.
컬럼 설명 sId
스케줄 ID를 저장한다.
sExNum
스케줄 실행번호를 저장한다.
status
상태를 저장한다.
-
TERMINATED
-
COMPLETED
-
FAILED
-
REVISED
type
플로우에 속한 스케줄이 실행되었을 때 해당 스케줄이 속한 플로우의 종류를 저장한다.
-
PRE
-
MAIN
-
POST
seq
실행된 스케줄이 선행이나 후행 플로우에 속한다면, 실행된 순서를 저장한다. 해당 값은 '1’부터 시작한다.
repeatCnt
현재 반복 회차를 저장한다.
startTime
시작시간을 저장한다. (형식: YYYYMMddHHmmss)
endTime
종료시간을 저장한다. (형식: YYYYMMddHHmmss)
errMsg
에러 메시지를 저장한다.
flowId
실행된 스케줄이 속한 플로우 아이디를 저장한다.
flowExNum
실행된 플로우의 실행번호를 저장한다.
run_Immediately
-
0 : cronExpression을 통해 실행된 스케줄
-
1 : 즉시실행 기능을 통해 실행된 스케줄
-
5.3. 스케줄 플로우 테이블
-
PO_SCHEDULE_MAIN_FLOW
스케줄 플로우의 실행 조건 및 제한 조건등을 설정한다.
컬럼 설명 flowId
스케줄 플로우 아이디를 저장한다.
preCondition
선행 플로우에서 본 스케줄로 넘어가기 위한 조건을 설정한다.
-
-1 : 스케줄 실행결과에 상관없이 항상 후행 플로우를 호출한다.
-
0 : 본 스케줄이 실패한 경우에만 후행 플로우를 호출한다.
-
1 : 본 스케줄이 성공한 경우에만 후행 플로우를 호출한다.
postCondition
본 스케줄에서 후행 플로우로 넘어가기 위한 조건을 설정한다.
-
-1 : 스케줄 실행결과에 상관없이 항상 후행 플로우를 호출한다.
-
0 : 스케줄이 실패한 경우에만 후행 플로우를 호출한다.
-
1 : 스케줄이 성공한 경우에만 후행 플로우를 호출한다.
innerPreCondition
선행 플로우 내에서 다음 차례의 선행 작업을 수행하기 위한 조건을 설정한다.
-
-1 : 스케줄 실행결과에 상관없이 항상 후행 플로우를 호출한다.
-
0 : 스케줄이 실패한 경우에만 후행 플로우를 호출한다.
-
1 : 스케줄이 성공한 경우에만 후행 플로우를 호출한다.
innerPostCondition
후행 플로우 내에서 다음 차례의 후행 작업을 수행하기 위한 조건을 설정한다.
-
-1 : 스케줄 실행결과에 상관없이 항상 후행 플로우를 호출한다.
-
0 : 스케줄이 실패한 경우에만 후행 플로우를 호출한다.
-
1 : 스케줄이 성공한 경우에만 후행 플로우를 호출한다.
dailyExeCnt
스케줄 플로우가 하루동안 실행될수 있는 최대 횟수를 제한한다.
currentExeCnt
스케줄 플로우가 하루동안 실행된 횟수를 저장한다.
lastExeDate
스케줄 플로우가 가장 최근 실행된 날짜를 저장한다.
description
스케줄 플로우의 설명, 의견을 작성한다.
-
-
PO_SCHEDULE_SUB_FLOW
스케줄 플로우의 선행, 후행 작업를 등록하고 실행 조건등을 설정한다.
컬럼 설명 flowId
선행, 후행 플로우가 속한 스케줄 플로우 아이디를 저장한다.
seq
선행, 후행 작업이 실행될 순서를 지정한다.
type
등록된 작업이 선행인지 후행인지 저장한다.
-
PRE : 선행 작업으로 본 스케줄 작업이 실행되기전 수행된다.
-
POST : 후행 작업으로 본 스케줄 작업이 실행된 후 수행된다.
targetId
PO_SCHEDULE_TARGET에 등록된 스케줄 타겟 아이디. 선행, 후행에서 실행해야 하는 작업을 저장한다.
repeatMaxCnt
선행, 후행 작업이 실행될 때 최대 반복 횟수를 저장한다.
repeatInterval
반복 주기를 저장한다. (단위: ms)
description
등록한 선,후행 작업의 설명, 의견을 작성한다.
-
-
PO_SCHEDULE_FLOW_STATUS
진행중이거나 종료된 스케줄 플로우의 정보를 저장하는 테이블이다.
컬럼 설명 flowId
스케줄 플로우 아이디를 저장한다.
flowExNum
스케줄 플로우 실행번호를 저장한다.
status
상태를 저장한다.
-
RUNNING
-
COMPLETED
-
FAILED
startTime
시작시간을 저장한다. (형식: YYYYMMddHHmmss)
endTime
종료시간을 저장한다. (형식: YYYYMMddHHmmss)
errMsg
에러 메시지를 저장한다.
run_Immediately
-
0 : cronExpression을 통해 실행된 스케줄
-
1 : 즉시실행 기능을 통해 실행된 스케줄
nodeId
실행되고 있는 노드 아이디를 저장한다.
-
5.4. 스케줄 테이블 생성 스크립트
다음은 스케줄 생성 스크립트로 스케줄 및 캘린더 등록과 상태정보를 확인하기 위한 테이블들을 나타낸다.
-- PO_Schedule_Calendar Table Create SQL
CREATE TABLE PO_SCHEDULE_CALENDAR
(
CALID VARCHAR2(64) NOT NULL,
CALNAME VARCHAR2(64) NULL,
CALENDARTYPE VARCHAR2(20) NULL,
PATTERN VARCHAR2(4000) NULL,
PARENTCALID VARCHAR2(64) NULL,
EXCLUSIVEFLAG VARCHAR2(5) NULL,
DESCRIPTION VARCHAR2(4000) NULL,
CONSTRAINT PO_SCHEDULE_CALENDAR_PK PRIMARY KEY (CALID)
);
COMMENT ON TABLE PO_SCHEDULE_CALENDAR IS '스케줄 캘린더';
COMMENT ON COLUMN PO_SCHEDULE_CALENDAR.CALID IS '캘린더 ID';
COMMENT ON COLUMN PO_SCHEDULE_CALENDAR.CALNAME IS '캘린더 명';
COMMENT ON COLUMN PO_SCHEDULE_CALENDAR.CALENDARTYPE IS '캘린더타입(일,주,월,AD)';
COMMENT ON COLUMN PO_SCHEDULE_CALENDAR.PATTERN IS '캘린더 패턴';
COMMENT ON COLUMN PO_SCHEDULE_CALENDAR.DESCRIPTION IS '캘린더에 대한설명';
-- Table Create SQL
CREATE TABLE PO_SCHEDULE_TRIGGER
(
STRIGERID VARCHAR2(64) NOT NULL,
SCHEDULETYPE VARCHAR2(20) NULL,
CRONEXPRESSION VARCHAR2(30) NULL,
BIZ_CALID VARCHAR2(64) NULL,
HOLY_CALID VARCHAR2(64) NULL,
EXCEPTIONTYPE VARCHAR2(20) NULL,
EXCEPTIONDATE VARCHAR2(20) NULL,
REPEATMAXCNT NUMBER(18, 0) NULL,
REPEATINTERVAL NUMBER(18, 0) NULL,
DUPLEEXEYN VARCHAR2(1) NULL,
INVOKEDELAYTIME NUMBER(18, 0) NULL,
DESCRIPTION VARCHAR2(4000) NULL,
CONSTRAINT PO_SCHEDULE_TRIGGER_PK PRIMARY KEY (STRIGERID)
);
COMMENT ON TABLE PO_SCHEDULE_TRIGGER IS '스케줄 실행 조건';
COMMENT ON COLUMN PO_SCHEDULE_TRIGGER.STRIGERID IS '스케줄 트리거 ID';
COMMENT ON COLUMN PO_SCHEDULE_TRIGGER.SCHEDULETYPE IS 'CRON(캘린더 만들지 않고), CALENDAR';
COMMENT ON COLUMN PO_SCHEDULE_TRIGGER.CRONEXPRESSION IS 'SCHEDULETYPE가 CRON일 경우 EXPRESSION';
COMMENT ON COLUMN PO_SCHEDULE_TRIGGER.REPEATMAXCNT IS '최대 반복 횟수';
COMMENT ON COLUMN PO_SCHEDULE_TRIGGER.REPEATINTERVAL IS '반복 주기(MS)';
COMMENT ON COLUMN PO_SCHEDULE_TRIGGER.DUPLEEXEYN IS '중복실행가능여부';
COMMENT ON COLUMN PO_SCHEDULE_TRIGGER.INVOKEDELAYTIME IS 'INVOKE 조건 만족 후, 호출 딜레이';
COMMENT ON COLUMN PO_SCHEDULE_TRIGGER.DESCRIPTION IS '스케줄 주기에 대한설명';
-- PO_SCHEDULE_MAIN TABLE CREATE SQL
CREATE TABLE PO_SCHEDULE_MAIN
(
SID VARCHAR2(64) NOT NULL,
SNAME VARCHAR2(64) NULL,
USERYN VARCHAR2(1) NULL,
STARTTIME VARCHAR2(14) NULL,
ENDTIME VARCHAR2(14) NULL,
STRIGERID VARCHAR2(64) NULL,
TARGETID VARCHAR2(64) NULL,
MODIFYTIME VARCHAR2(14) NULL,
INVOKECNT NUMBER(5, 0) DEFAULT -1,
NODEID VARCHAR2(128) NULL,
FLOWID VARCHAR2(64) NULL,
BIZCODE VARCHAR2(64) NULL,
DESCRIPTION VARCHAR2(4000) NULL,
CONSTRAINT PO_SCHEDULE_MAIN_PK PRIMARY KEY (SID)
);
COMMENT ON TABLE PO_SCHEDULE_MAIN IS '스케줄 메인';
COMMENT ON COLUMN PO_SCHEDULE_MAIN.SID IS '스케줄 ID';
COMMENT ON COLUMN PO_SCHEDULE_MAIN.SNAME IS '스케줄명';
COMMENT ON COLUMN PO_SCHEDULE_MAIN.USERYN IS '스케줄 사용여부';
COMMENT ON COLUMN PO_SCHEDULE_MAIN.STARTTIME IS '스케줄 실행 가능시간(YYYYMMDDHHMMSS)';
COMMENT ON COLUMN PO_SCHEDULE_MAIN.ENDTIME IS '스케줄 유효 만료 시간(YYYYMMDDHHMMSS)';
COMMENT ON COLUMN PO_SCHEDULE_MAIN.STRIGERID IS '스케줄 트리거 ID';
COMMENT ON COLUMN PO_SCHEDULE_MAIN.TARGETID IS '실행 JOB ID';
COMMENT ON COLUMN PO_SCHEDULE_MAIN.MODIFYTIME IS '최근 수정시간(YYYYMMDDHHMMSS)';
COMMENT ON COLUMN PO_SCHEDULE_MAIN.FLOWID IS '스케줄이 속한 FLOW의 ID';
COMMENT ON COLUMN PO_SCHEDULE_MAIN.BIZCODE IS '업무코드';
COMMENT ON COLUMN PO_SCHEDULE_MAIN.DESCRIPTION IS '스케줄에 대한 설명';
-- PO_SCHEDULE_MAIN TABLE CREATE SQL
CREATE TABLE PO_SCHEDULE_STATUS
(
SID VARCHAR2(64) NOT NULL,
SEXNUM VARCHAR2(64) NULL,
STARTTIME VARCHAR2(14) NULL,
MODIFYTIME VARCHAR2(14) NULL,
STATUS VARCHAR2(20) NULL,
TYPE VARCHAR2(20) NULL,
SEQ NUMBER(18),
REPEATCNT NUMBER(18, 0) NULL,
NODEID VARCHAR2(128) NULL,
FLOWID VARCHAR2(64) NULL,
FLOWEXNUM VARCHAR2(64) NULL,
RUN_IMMEDIATELY NUMBER(1) NULL,
CONSTRAINT PO_SCHEDULE_STATUS_PK PRIMARY KEY (SID, SEXNUM)
);
COMMENT ON TABLE PO_SCHEDULE_STATUS IS '스캐쥴 진행중에만 해당 테이블 사용하며 종료시 PO_SCHEDULE_HISTORY 로 데이터 전달';
COMMENT ON COLUMN PO_SCHEDULE_STATUS.SID IS '스케줄 ID';
COMMENT ON COLUMN PO_SCHEDULE_STATUS.SEXNUM IS '스케줄 실행번호';
COMMENT ON COLUMN PO_SCHEDULE_STATUS.MODIFYTIME IS '최근 수정시간(YYYYMMDDHHMMSS)';
COMMENT ON COLUMN PO_SCHEDULE_STATUS.STATUS IS '상태(PREPARE, RUNNING, TERMINATING)';
COMMENT ON COLUMN PO_SCHEDULE_STATUS.TYPE IS '스케줄링 대상이 JOB인 경우, 선행 배치인지 본배치인지 후행 배치인지 여부';
COMMENT ON COLUMN PO_SCHEDULE_STATUS.SEQ IS '스케줄링 대상이 JOB이면서 선/후행 배치인 경우, 실행 순서';
COMMENT ON COLUMN PO_SCHEDULE_STATUS.REPEATCNT IS '현재 반복 회차';
COMMENT ON COLUMN PO_SCHEDULE_STATUS.NODEID IS '실행되고 있는 노드 아이디';
COMMENT ON COLUMN PO_SCHEDULE_STATUS.FLOWID IS '스케줄이 속한 FLOW의 ID';
COMMENT ON COLUMN PO_SCHEDULE_STATUS.FLOWEXNUM IS '스케줄 flow 실행번호';
COMMENT ON COLUMN PO_SCHEDULE_STATUS.RUN_IMMEDIATELY IS '즉시 실행 여부'
-- PO_SCHEDULE_HISTORY TABLE CREATE SQL
CREATE TABLE PO_SCHEDULE_HISTORY
(
SID VARCHAR2(64) NOT NULL,
SEXNUM VARCHAR2(64) NULL,
STATUS VARCHAR2(20) NULL,
TYPE VARCHAR2(20) NULL,
SEQ NUMBER(18),
REPEATCNT NUMBER(18, 0) NULL,
STARTTIME VARCHAR2(14) NULL,
ENDTIME VARCHAR2(14) NULL,
NODEID VARCHAR2(128) NULL,
ERRMSG CLOB NULL,
FLOWID VARCHAR2(64) NULL,
FLOWEXNUM VARCHAR2(64) NULL,
RUN_IMMEDIATELY NUMBER(1) NULL,
CONSTRAINT PO_SCHEDULE_HISTORY_PK PRIMARY KEY (SID,SEXNUM)
);
COMMENT ON TABLE PO_SCHEDULE_HISTORY IS '스케줄 히스토리';
COMMENT ON COLUMN PO_SCHEDULE_HISTORY.SID IS '스케줄 ID';
COMMENT ON COLUMN PO_SCHEDULE_HISTORY.SEXNUM IS '스케줄 실행번호';
COMMENT ON COLUMN PO_SCHEDULE_HISTORY.TYPE IS '스케줄링 대상이 JOB인 경우, 선행 배치인지 본배치인지 후행 배치인지 여부';
COMMENT ON COLUMN PO_SCHEDULE_HISTORY.SEQ IS '스케줄링 대상이 JOB이면서 선/후행 배치인 경우, 실행 순서';
COMMENT ON COLUMN PO_SCHEDULE_HISTORY.REPEATCNT IS '현재 반복 회차';
COMMENT ON COLUMN PO_SCHEDULE_HISTORY.STATUS IS '상태(TERMINATED, COMPLETED, FAILED, REVISED)';
COMMENT ON COLUMN PO_SCHEDULE_HISTORY.STARTTIME IS '시작시간(YYYYMMDDHHMMSS)';
COMMENT ON COLUMN PO_SCHEDULE_HISTORY.ENDTIME IS '종료시간(YYYYMMDDHHMMSS)';
COMMENT ON COLUMN PO_SCHEDULE_HISTORY.FLOWID IS '스케줄이 속한 FLOW의 ID';
COMMENT ON COLUMN PO_SCHEDULE_HISTORY.FLOWEXNUM IS '스케줄 flow 실행번호';
COMMENT ON COLUMN PO_SCHEDULE_HISTORY.RUN_IMMEDIATELY IS '즉시 실행 여부'
-- PO_SCHEDULE_TARGET TABLE CREATE SQL
CREATE TABLE PO_SCHEDULE_TARGET
(
TARGETID VARCHAR2(64) NOT NULL,
EXJOBTYPE VARCHAR2(20) NULL,
EXINPUTDATA VARCHAR2(4000) NULL,
EXHEADERDATA VARCHAR2(4000) NULL,
EXNODEID VARCHAR2(128) NULL,
EXNAME1 VARCHAR2(64) NULL,
EXNAME2 VARCHAR2(64) NULL,
EXNAME3 VARCHAR2(64) NULL,
DESCRIPTION VARCHAR2(4000) NULL,
CONSTRAINT PO_SCHEDULE_TARGET_PK PRIMARY KEY (TARGETID)
);
COMMENT ON TABLE PO_SCHEDULE_TARGET IS '스케줄 실행 대상 정보';
COMMENT ON COLUMN PO_SCHEDULE_TARGET.TARGETID IS '실행 JOB ID';
COMMENT ON COLUMN PO_SCHEDULE_TARGET.EXJOBTYPE IS '실행 JOB 종류(JO,SO,SHELL)';
COMMENT ON COLUMN PO_SCHEDULE_TARGET.EXINPUTDATA IS 'JO, SO : INPUTMSGTEXT, SHELL : SHELL PARAMETER';
COMMENT ON COLUMN PO_SCHEDULE_TARGET.EXNODEID IS '스케줄이 실행되는 노드';
COMMENT ON COLUMN PO_SCHEDULE_TARGET.EXNAME1 IS 'JO, SO : APPLICATIONNAME, SHELL : SHELL파일명';
COMMENT ON COLUMN PO_SCHEDULE_TARGET.EXNAME2 IS 'JO, SO : SERVICEGROUP, SHELL : 파일 경로';
COMMENT ON COLUMN PO_SCHEDULE_TARGET.EXNAME3 IS 'JO, SO : SERVICE, SHELL : 사용하지 않음';
COMMENT ON COLUMN PO_SCHEDULE_TARGET.DESCRIPTION IS '타겟에 대한설명';
CREATE TABLE PO_SCHEDULE_MAIN_FLOW(
FLOWID VARCHAR2(64) NOT NULL,
PRECONDITION NUMBER(1),
POSTCONDITION NUMBER(1),
INNERPRECONDITION NUMBER(1),
INNERPOSTCONDITION NUMBER(1),
DAILYEXECNT NUMBER(18),
CURRENTEXECNT NUMBER(18) DEFAULT 0,
LATESTEXEDATE DATE,
DESCRIPTION VARCHAR2(4000)
);
ALTER TABLE PO_SCHEDULE_MAIN_FLOW ADD CONSTRAINT PO_SCHEDULE_MAIN_FLOW_PK PRIMARY KEY (FLOWID);
COMMENT ON COLUMN PO_SCHEDULE_MAIN_FLOW.FLOWID IS '스케줄 flow를 구분지을 아이디';
COMMENT ON COLUMN PO_SCHEDULE_MAIN_FLOW.PRECONDITION IS '선행배치가 존재할 경우, 본배치를 실행시키기 위한 조건. -1: always, 0: fail, 1: success';
COMMENT ON COLUMN PO_SCHEDULE_MAIN_FLOW.POSTCONDITION IS '후행배치가 존재할 경우, 후행배치를 실행시키기 위한 조건. -1: always, 0: fail, 1: success';
COMMENT ON COLUMN PO_SCHEDULE_MAIN_FLOW.INNERPRECONDITION IS '선행배치 내부에서 다음 선행 배치를 실행시키기 위한 조건. -1: always, 0: fail, 1: success';
COMMENT ON COLUMN PO_SCHEDULE_MAIN_FLOW.INNERPOSTCONDITION IS '후행배치 내부에서 다음 후행 배치를 실행시키기 위한 조건. -1: always, 0: fail, 1: success';
COMMENT ON COLUMN PO_SCHEDULE_MAIN_FLOW.DAILYEXECNT IS '본배치가 스케줄링됬을때 제한할 일별 실행횟수 제한';
COMMENT ON COLUMN PO_SCHEDULE_MAIN_FLOW.CURRENTEXECNT IS '본배치가 스케줄링됬을때 제한할 일별 실행횟수 제한에 해당하는 실행횟수';
COMMENT ON COLUMN PO_SCHEDULE_MAIN_FLOW.LATESTEXEDATE IS '스케줄이 실행된 가장 최신 일자';
COMMENT ON COLUMN PO_SCHEDULE_MAIN_FLOW.DESCRIPTION IS '스케줄 flow에 대한설명';
CREATE TABLE PO_SCHEDULE_SUB_FLOW(
FLOWID VARCHAR2(64) NOT NULL,
SEQ NUMBER(18) NOT NULL,
TYPE VARCHAR2(20) NOT NULL,
TARGETID VARCHAR2(64) NOT NULL,
REPEATMAXCNT NUMBER(18, 0) NULL,
REPEATINTERVAL NUMBER(18, 0) NULL,
DESCRIPTION VARCHAR2(4000) NULL
);
ALTER TABLE PO_SCHEDULE_SUB_FLOW ADD CONSTRAINT PO_SCHEDULE_SUB_FLOW_PK PRIMARY KEY (FLOWID, SEQ, TYPE);
COMMENT ON COLUMN PO_SCHEDULE_SUB_FLOW.FLOWID IS '선/후행 배치가 속한 flow의 아이디';
COMMENT ON COLUMN PO_SCHEDULE_SUB_FLOW.SEQ IS '선/후행 배치의 실행 순서';
COMMENT ON COLUMN PO_SCHEDULE_SUB_FLOW.TYPE IS '"PRE" : 선행 배치, "POST": 후행배치';
COMMENT ON COLUMN PO_SCHEDULE_SUB_FLOW.TARGETID IS '선/후행 배치가 실행시켜야 하는 JOB의 TARGETID';
COMMENT ON COLUMN PO_SCHEDULE_SUB_FLOW.REPEATMAXCNT IS '최대 반복 횟수';
COMMENT ON COLUMN PO_SCHEDULE_SUB_FLOW.REPEATINTERVAL IS '반복 주기(MS)';
COMMENT ON COLUMN PO_SCHEDULE_SUB_FLOW.DESCRIPTION IS '스케줄 선후행 flow에 대한설명';
CREATE TABLE PO_SCHEDULE_FLOW_STATUS(
FLOWID VARCHAR2(64) NOT NULL,
FLOWEXNUM VARCHAR2(64) NULL,
STATUS VARCHAR2(20) NULL,
STARTTIME VARCHAR2(14) NULL,
ENDTIME VARCHAR2(14) NULL,
NODEID VARCHAR2(128) NULL,
RUN_IMMEDIATELY NUMBER(1) NULL,
ERRMSG CLOB NULL
);
ALTER TABLE PO_SCHEDULE_FLOW_STATUS ADD CONSTRAINT PO_SCHEDULE_FLOW_STATUS_PK PRIMARY KEY (FLOWID, FLOWEXNUM);
COMMENT ON COLUMN PO_SCHEDULE_FLOW_STATUS.FLOWID IS '선/후행 배치가 속한 flow의 아이디';
COMMENT ON COLUMN PO_SCHEDULE_FLOW_STATUS.FLOWEXNUM IS '스케줄 flow 실행번호';
COMMENT ON COLUMN PO_SCHEDULE_FLOW_STATUS.STATUS IS '상태(RUNNING)';
COMMENT ON COLUMN PO_SCHEDULE_FLOW_STATUS.STARTTIME IS '시작시간(YYYYMMDDHHMMSS)';
COMMENT ON COLUMN PO_SCHEDULE_FLOW_STATUS.ENDTIME IS '종료시간(YYYYMMDDHHMMSS)';
COMMENT ON COLUMN PO_SCHEDULE_FLOW_STATUS.RUN_IMMEDIATELY IS '즉시 실행 여부';
COMMENT ON COLUMN PO_SCHEDULE_FLOW_STATUS.ERRMSG IS '플로우 실행에 관한 에러 메세지';
5.5. 스케줄 테이블 데이터 예제
ProObject는 ProManager를 통해 스케줄을 관리한다.
다음은 ProManager 없이 사용해야 하는 경우를 위한 스케줄 테이블에 대한 데이터 예제이다.
--5초 마다 스케줄, 반복 없음, 중복실행 없음
INSERT INTO PO_Schedule_Main (sId, sName, userYn, startTime, endTime, sTrigerId, targetId, modifyTime, nodeid)
VALUES ('sId1', 'sName1', 'y', '20170101010101', '20200101010101', 'sId1_TR', 'sId1_TA', '20170101010101', 'ProObject7');
INSERT INTO PO_Schedule_Trigger (sTrigerId, scheduleType, cronExpression, repeatMaxCnt, repeatInterval, dupleExeYn, invokeDelayTime)
VALUES ('sId1_TR', 'cron', '0/5 * * * * ?', 0,0, 'n', 1);
INSERT INTO PO_Schedule_TARGET (targetId, exJobType, exInputData, exNodeId, exName1, exName2, exName3)
VALUES ('sId1_TA', 'SO', '', '', 'test', 'example', 'JobServiceCCTargetSample');
--1분 마다 스케줄, 반복 없음, 중복실행 없음
INSERT INTO PO_Schedule_Main (sId, sName, userYn, startTime, endTime, sTrigerId, targetId, modifyTime, nodeid)
VALUES ('sId2', 'sName2', 'y', '20170101010101', '20200101010101', 'sId2_TR', 'sId2_TA', '20170101010101', 'ProObject7');
INSERT INTO PO_Schedule_Trigger (sTrigerId, scheduleType, cronExpression, repeatMaxCnt, repeatInterval, dupleExeYn, invokeDelayTime)
VALUES ('sId2_TR', 'cron', '0 0/1 * 1/1 * ? *', 0,0, 'n', 1);
INSERT INTO PO_Schedule_TARGET (targetId, exJobType, exInputData, exNodeId, exName1, exName2, exName3)
VALUES ('sId2_TA', 'SO', '', '', 'test', 'example', 'JobServiceCCTargetSample');
--1분 마다 스케줄, 무한반복 2초간격, 중복실행 없음
INSERT INTO PO_Schedule_Main (sId, sName, userYn, startTime, endTime, sTrigerId, targetId, modifyTime, nodeid)
VALUES ('sId3', 'sName3', 'y', '20170101010101', '20200101010101', 'sId3_TR', 'sId3_TA', '20170101010101', 'ProObject7');
INSERT INTO PO_Schedule_Trigger (sTrigerId, scheduleType, cronExpression, repeatMaxCnt, repeatInterval, dupleExeYn, invokeDelayTime)
VALUES ('sId3_TR', 'cron', '0 0/1 * 1/1 * ? *',-1,2000, 'n', 1);
INSERT INTO PO_Schedule_TARGET (targetId, exJobType, exInputData, exNodeId, exName1, exName2, exName3)
VALUES ('sId3_TA', 'SO', '', '', 'test', 'example', 'JobServiceCCTargetSample');
--4초 마다 스케줄, 반복 없음, 중복실행 없음, input값 있음
INSERT INTO PO_Schedule_Main (sId, sName, userYn, startTime, endTime, sTrigerId, targetId, modifyTime, nodeid)
VALUES ('sId4', 'sName4', 'y', '20170101010101', '20200101010101', 'sId4_TR', 'sId4_TA', '20170101010101', 'ProObject7');
INSERT INTO PO_Schedule_Trigger (sTrigerId, scheduleType, cronExpression, repeatMaxCnt, repeatInterval, dupleExeYn, invokeDelayTime)
VALUES ('sId4_TR', 'cron', '0/4 * * * * ?',0,0, 'n', 1);
INSERT INTO PO_Schedule_TARGET (targetId, exJobType, exInputData, exNodeId, exName1, exName2, exName3)
VALUES ('sId4_TA', 'SO', '{"cc_id":"SAMPLE1","cc_exe_id":"testEx1","retry_yn":"n"}', '', 'test', 'example', 'JobServiceCCTargetSample');
--5초 마다 스케줄, 반복 없음, 중복실행 없음, 배치 실행
INSERT INTO PO_Schedule_Main (sId, sName, userYn, startTime, endTime, sTrigerId, targetId, modifyTime, nodeid)
VALUES ('sId5', 'sName5', 'y', '20170101010101', '20200101010101', 'sId5_TR', 'sId5_TA', '20170101010101', 'ProObject7');
INSERT INTO PO_Schedule_Trigger (sTrigerId, scheduleType, cronExpression, repeatMaxCnt, repeatInterval, dupleExeYn, invokeDelayTime)
VALUES ('sId5_TR', 'cron', '0/5 * * * * ?',0,0, 'n', 1);
INSERT INTO PO_Schedule_TARGET (targetId, exJobType, exInputData, exNodeId, exName1, exName2, exName3)
VALUES ('sId5_TA', 'JO', '', '', 'test', 'svcGrpTest', 'JobServiceNormalSample');
--5초 마다 스케줄, 반복 없음, 중복실행 없음, 프로배치 실행
INSERT INTO PO_Schedule_Main (sId, sName, userYn, startTime, endTime, sTrigerId, targetId, modifyTime, nodeId)
VALUES ('sId10', 'sName10', 'y', '20170101010101', '20200101010101', 'sId10_TR', 'sId10_TA', '20170101010101', 'ProObject7');
INSERT INTO PO_Schedule_Trigger (sTrigerId, scheduleType, cronExpression, repeatMaxCnt, repeatInterval, dupleExeYn, invokeDelayTime)
VALUES ('sId10_TR', 'cron', '0/5 * * * * ?',0,0, 'n', 1);
INSERT INTO PO_Schedule_TARGET (targetId, exJobType, exInputData, exNodeId, exName1, exName2, exName3)
VALUES ('sId10_TA', 'PROBATCH', '', 'ProBatch_1', '', '', 'JobServiceNormalSample');
truncate table PO_Schedule_Main;
truncate table PO_Schedule_TARGET;
truncate table PO_Schedule_Trigger;
--INSERT INTO PO_Schedule_Calendar (calId, calName, calendarType, pattern, inCalId, exCalId, exceptionType, exceptionDate)
VALUES ('calId1', '', '', '', '', '', '', '');
--INSERT INTO PO_Schedule_Calendar (calId, calName, calendarType, pattern, inCalId, exCalId, exceptionType, exceptionDate)
VALUES ('calId2', '', '', '', '', '', '', '');
--truncate table PO_Schedule_Calendar;
--정상 등록되었는지 확인하는 쿼리
SELECT *
FROM PO_Schedule_Main main, PO_Schedule_Trigger tri, PO_Schedule_TARGET tar
WHERE main.sTrigerId=tri.sTrigerId AND main.targetId=tar.targetId;
---calenar data
insert into PO_Schedule_Calendar (calId, calName, calendarType, pattern, parentCalId, exclusiveFlag)
values ('cron_daily', 'cron_daily', 'CRON', '15 0 * * * ?', '', 'false');
insert into PO_Schedule_Calendar(calId, calName, calendarType, pattern, parentCalId, exclusiveFlag)
values ('anual_daily', 'anual_daily', 'ANNUAL', '11.28,11.30,12.01,12.03,12.05', '', 'false');
insert into PO_Schedule_Calendar (calId, calName, calendarType, pattern, parentCalId, exclusiveFlag)
values ('month_daily', 'month_daily', 'MONTHLY',
'true,false,false,false,false,false,false,false,false,false,false,false,false,false,
false,false,false,false,false,false,false,false,false,false,false,false,false,false,
false,false,false', '', 'false');
insert into PO_Schedule_Calendar (calId, calName, calendarType, pattern, parentCalId, exclusiveFlag)
values('calId_weekly', 'calId_weekly', 'WEEKLY', 'false,false,false,false,false,false,false', '', 'false');
insert into PO_Schedule_Calendar (calId, calName, calendarType, pattern, parentCalId, exclusiveFlag)
values ('calId_daily', 'calId_daily', 'DAILY', '09:00,18:00', '', 'false');
insert into PO_Schedule_Calendar (calId, calName, calendarType, pattern, parentCalId, exclusiveFlag)
values ('calId_RANGE', 'calId_RANGE', 'RANGE', '2018.11.28 09:00,2018.12.02 19:00', '', 'false');
insert into PO_Schedule_Calendar (calId, calName, calendarType, pattern, parentCalId, exclusiveFlag)
values ('calId_DAYS', 'calId_DAYS', 'DAYS', '2018.11.28,2018.12.02,2018.12.03', '', 'false');
----5초 마다 스케줄, 반복 없음, 중복실행 없음
INSERT INTO PO_Schedule_Main (sId, sName, userYn, startTime, endTime, sTrigerId, targetId, modifyTime)
VALUES ('exT1', 'sName1', 'y', '20170101010101', '20200101010101', 'exT1_TR', 'exT1_TA', '20170101010101');
INSERT INTO PO_Schedule_Trigger(sTrigerId, scheduleType, cronExpression, repeatMaxCnt, repeatInterval,
dupleExeYn, invokeDelayTime, biz_calId, holy_calId)
VALUES ('exT1_TR', 'cron', '0/5 * * * * ?', 0,0, 'n', 1, 'ExCanual_daily', '');
INSERT INTO PO_Schedule_TARGET (targetId, exJobType, exInputData, exNodeId, exName1, exName2, exName3)
VALUES ('exT1_TA', 'SO', '', '', 'proobject', 'batch', 'JobServiceCCTargetSample');
INSERT INTO PO_Schedule_Calendar (calId, calName, calendarType, pattern, parentCalId, exclusiveFlag)
VALUES ( 'ExCanual_daily', 'ExCanual_daily', 'ANNUAL', '', '', 'false');
6. API 사용 예제
본 절에서는 스케줄 등록 및 관리와 스케줄 플로우 관련 API에 대해서 설명한다.
6.1. 스케줄 등록 및 관리
기존 스케줄 데이터는 DB를 통해 관리되었기 때문에 DB에 데이터를 삭제하거나 수정하지 않는 한 영구적으로 지속되었다. 하지만 원하는 시점에 등록된 후 서버가 다운되었을 때 스케줄이 더이상 유효하지 않아야 하는 경우 메모리상에만 존재하도록 할 필요 있다.
이러한 경우 다음의 API를 사용할 수 있으며, DB 스케줄에 대해서도 등록이 가능하다.
////////////스케줄 데이터 생성 시작////////////
ServiceName name = new ServiceName("appName", "svcgrpName", "JobServiceNormalSample");
ScheduleBuilder builder = new ScheduleBuilder();
//appName, svcGrpName, svcName, inputJson
builder.configJob(name.getApplicationName(), name.getServiceGroupName(), name.getServiceName(),
"{\"cc_id\":\"SAMPLE1\",\"cc_exe_id\":\"testEx1\",\"retry_yn\":\"n\"}");
builder.configCron("0/5 * * * * ?");//5초마다
//builder.configValidTime("20110101235000", "20200101235000");
//builder.configRepeat(-1, 1000, false);
ScheduleModelSet set = builder.build("scheduleId1", "ScheduleName1");
////////////스케줄 데이터 생성 끝////////////
//스케줄을 등록하며, 등록한 시점부터 동작한다.
ScheduleRegister.getInstance().regist(set, Storage_Type.MEMORY);//메모리에 스케줄을 등록한다.
//ScheduleRegister.getInstance().regist(set, Storage_Type.DB);//DB에 스케줄을 등록한다.
//스케줄을 삭제한다.
ScheduleRegister.getInstance().unregist("scheduleId1");//메모리에 sid가 있으면 삭제하며, 메모리에 없으면 DB에 delete를 수행한다.
//ScheduleRegister.getInstance().unregist("scheduleId1", Storage_Type.MEMORY);//메모리에 등록된 sid를 삭제한다.
//ScheduleRegister.getInstance().unregist("scheduleId1", Storage_Type.DB);//DB에 등록된 sid를 삭제한다.
String sId = "scheduleId1";
String sName = "ScheduleName1";
ScheduleModelSet set = new ScheduleModelSet();
ScheduleBuilder builder = new ScheduleBuilder();
builder.configCron("0/30 * * 1/1 * ? 2019");
builder.configJob("test", "main","S_Callee","");
builder.configValidTime("20190819110000", "99990819111500");
set=builder.build(sId, sName);
set.getMainModel().setSid("scheduleId1");
set.getMainModel().setDisposableYn(true);
set.getMainModel().setExjobid(null);
set.getMainModel().setInvokeCnt(0);
set.getMainModel().setModifytime("20190823174150");
set.getMainModel().setNodeId("scheduleId1_TA");
set.getMainModel().setSname(sName);
set.getMainModel().setStarttime("30000819110000");
set.getMainModel().setStrigerid("scheduleId1_TR");
set.getMainModel().setUseryn("Y");
set.getTriggerModel().setCronexpression("0/30 * * 1/1 * ? 2019");
ScheduleRegister.getInstance().modify(set, Storage_Type.DB);
ScheduleControlDataObject _scheduleControlDataObject = new ScheduleControlDataObject();
try {
RequestContext requestContext = ServiceManager.getServiceRequestContext("proobject.schedule.ScheduleControlService");
ServiceManager.call(requestContext, "proobject.schedule.ScheduleControlService", _scheduleControlDataObject);
} catch (ServiceCallFailedException e){
}
6.2. 스케줄 플로우
다음은 스케줄 플로우 기능을 사용할 때 플로우를 포함한 스케줄을 API를 이용해서 등록하는 방법이다.
// 1. ScheduleModelSet 생성을 위한 ScheduleBuilder 객체 생성
ScheduleBuilder builder = new ScheduleBuilder();
// 2. 스케줄후 실행할 작업을 설정한다.
// PO_SCHEDULE_TARGET에 데이터가 저장되며, 스케줄 주기가 도래했을때 실행할 서비스 혹은 배치를 설정한다.
// 스케줄 작업의 종류는 SO, JO, SHELL로 각 종류에 맞는 문자열을 입력한다.
// test.main.service를 실행시키는 예제이다.
builder.configJob("test", "main", "service", "{\"value\":\"call\"}", "SO", "서비스");
// 3. 스케줄 주기를 설정한다.
// PO_SCHEDULE_TRIGGER에 데이터가 저장되며, 스케줄이 실행되는 조건을 설정한다.
// 스케줄 트리거를 입력하는 것이며, 스케줄 주기는 CRON EXPRESSION 문법에 맞게 입력한다.
builder.configCron("0 0/1 * 1/1 * ? *");
// 4. 스케줄이 트리거되었을때 반복실행에 관한 설정을 입력한다.
// PO_SCHEDULE_TRIGGER에 데이터가 저장된다.
// 스케줄 플로우 기능을 사용하는 경우 본배치의 반복 실행에 관한 값을 입력한다.
builder.configRepeat(0, 0, false);
// 5. 스케줄 플로우의 메인 플로우 정보를 입력한다.
// PO_SCHEDULE_MAIN_FLOW에 데이터가 저장된다.
// 메인 플로우가 등록되지 않은 경우, 메인 플로우 정보도 같이 생성하기위해 사용하는 API이다.
// 서브 플로우에 대한 실행 조건, 일별 실행횟수 제한을 설정한다.
// 서브 플로우에 대한 실행 조건은 com.tmax.proobject.schedule.repository.ScheduleBuilder.ExecuteCondition 클래스를 통해 입력한다.
builder.configScheduleMainFlow("flowId1", ExecuteCondition.SUCCESS, ExecuteCondition.SUCCESS, ExecuteCondition.SUCCESS, ExecuteCondition.SUCCESS, 1);
// 6. 스케줄 플로우의 서브 플로우 정보를 입력한다.
// PO_SCHEDULE_SUB_FLOW에 데이터가 저장되며, 서브 플로우의 실행 순서, 서브 플로우의 타입, 서브 플로우가 실행시킬 대상 아이디를 설정한다.
// 서브플로우의 순서는 항상 '1'부터 시작한다.
builder.configScheduleSubFlow("flowId1", 1, SubFlowType.PRE, "subTarget1", 0, 0);
builder.configScheduleSubFlow("flowId1", 1, SubFlowType.POST, "subTarget2", 0, 0);
// 7. 서브 플로우가 실행시킬 대상 작업의 정보를 입력한다.
// 사전에 반드시 configScheduleSubFlow api를 통해 서브 플로우 설정을 추가한다음 호출해야한다.
// configScheduleSubFlow로 추가한 서브플로우의 타겟이 존재하지않는 경우, 해당 타겟을 추가하기 위한 API이다.
// configScheduleSubFlow에 지정한 seq와 type을 기준으로 타겟 정보가 추가된다.
// 스케줄 작업의 종류는 SO, JO, SHELL로 com.tmax.proobject.schedule.repository.ScheduleBuilder.Schedule_Job_Type을 입력한다.
builder.addFlowJob(1, SubFlowType.PRE, "subTarget1", "test", "main", "service", "{\"value\":\"call2\"}", Schedule_Job_Type.SO, "선행배치1");
builder.addFlowJob(1, SubFlowType.POST, "subTarget2", "test", "main", "service", "{\"value\":\"call2\"}", Schedule_Job_Type.SO, "후행배치1");
// 8. 등록하려는 스케줄이 동작할 수 있는 유효기간을 입력한다.
// 스케줄 주기와 상관없이 등록하려는 스케줄은 설정한 기간 내에서만 동작한다.
builder.configValidTime("20210101000000", "20220101000000");
// 9. 스케줄러가 실행될수있는 횟수를 지정한다.
// 스케줄은 지정된 횟수만큼 실행하고 삭제한다.
// -1을 설정하는 경우 스케줄을 무한대로 실행한다.
builder.configInvokeCount(1);
// 10. 스케줄러를 사용가능한 상태로 등록할지 여부를 설정한다.
// 스케줄을 등록할 때 userYN값을 통해서 스케줄이 런타임으로 로드될지 말지 결정합니다.
builder.configUse(false);
// 11. ScheduleModelSet을 생성한다.
// PO_SCHEDULE_MAIN, TARGET, TRIGGER, MAIN_FLOW의 아이디 값을 입력한다.
// flowId : ScheduleBuilder를 통해 처음 main flow를 등록하시는 경우 configScheduleMainFlow API에 입력했던 flowId를 그대로 입력합니다. / 이미 메인 플로우가 등록되어있는 경우, 스케줄이 속해야하는 플로우 아이디를 입력합니다.
// sId : 스케줄을 구분지을수 있는 아이디
// sName : 스케줄 한글이름
// sTrigerId : configCron과 configRepeat을 통해 설정한 스케줄 트리거의 아이디. 입력하지 않을시 '스케줄아이디 + _TR'로 설정됩니다.
// sTargetId : configJob을 통해 설정한 스케줄 타겟의 아이디. 입력하지 않을시 '스케줄아이디 + _TA'로 설정됩니다.
// description : 스케줄 설명
ScheduleModelSet model = builder.build("flowId1", "schedule1", "예제 스케줄", "trigger1", "target1", "스케줄샘플코드");
ScheduleRegister.getInstance().regist(model, Storage_Type.DB);