모니터링
본 장에서는 ProObject의 모니터링 모듈의 소개와 특징에 대해 설명한다.
1. 개요
ProObject의 모니터링 모듈은 여러 대의 서버를 운영 중일 때 부하가 걸리거나 장애가 발생하는 등 비정상적인 서버를 관리자가 빠르고 쉽게 파악할 수 있도록 다양한 모니터링 기능을 지원한다.
모니터링 기능은 각 서버로부터 수집한 모니터링 정보를 데이터베이스에 저장하며, 해당 데이터를 바탕으로 모니터링 기능을 제공한다. 하지만 기능별로 데이터를 수집하는 구조가 조금씩 다르므로 자세한 내용은 각 기능의 설명을 참고한다.
2. 상태 모니터링
상태 모니터링은 관제 대상인 서버의 현재 상태를 확인하는 것을 말한다. 상태 정보에는 서버가 살았는지 죽었는지 확인하는 Health Check와 CPU, RAM, Network I/O와 같은 하드웨어의 사용률 같은 정보들이 있으며, 그 밖에 할당 Thread 수, TPS, MAX Response, 표준편차, 분산같은 통계 정보들을 포함한다. 상태 모니터링은 액티브(Active) 모니터링과 통계(Statistics) 모니터링 2가지가 있다.
2.1. 액티브 모니터링
액티브 모니터링은 서버에서 수행 중인 모든 서비스들의 정보를 얻는다. 해당 기능은 시스템 서비스 형태로 제공되기 때문에 서버에 ProObject 서비스를 호출한다.
서비스 호출에 필요한 URL 및 입력값은 다음을 참고한다.
-
서버에서 수행 중인 모든 서비스들의 정보를 알고 싶은 경우
HTTP Method : GET URL : http://IP:PORT/proobject/system/CurrentServiceInfo
-
실행 중인 서비스들 중에서 특정 애플리케이션의 서비스 그룹에 해당하는 서비스들만 알고 싶은 경우
HTTP Method : POST URL : http://IP.PORT/proobject/system/CurrentServiceInfo?action=Get INPUT : { "dto" : { "applicationName" : "test", "serviceGroupName" : "main" } }'test’라는 애플리케이션에 'main’이라는 서비스 그룹에 해당하는 서비스들 중에서 수행 중인 서비스들의 목록을 조회한다. 이 처럼 특정 Application, ServiceGroup에 포함된 서비스들의 목록만 조회하려면 HTTP Request Body에 위와 같이 'applicationName’과 'serviceGroupName' 키 값에 해당 애클리케이션 이름과 서비스 그룹이름을 설정한다.
액티브 모니터링 서비스는 현재 수행 중인 서비스의 정보를 담은 리스트를 응답으로 돌려준다.
다음은 test.main.LoopCall 서비스가 수행 중일 때 액티브 모니터링 서비스의 응답의 예제이다.
{
"header": {
"service": null,
"inputMsgType": null,
"outputMsgType": null,
"transferKey": null,
"fileBaseDirectory": null,
"files": [],
"responseCode": "NON-0200",
"responseMsg": null,
"responseMsgDetails": null,
"length": 0,
"guid": null,
"tenantId": null
},
"dto": {
"infoList": [
{
"domain": "PROOBJECT",
"server": "po7main",
"application": "test",
"serviceGroup": "main",
"service": "LoopCall",
"threadId": "ProObject Service Worker[test.main-1]",
"stackTrace": "\tat com.tmax.proobject.test.runtime.application.test.servicegroup.main.service.call.LoopCall.service(LoopCall.java:29)\tat
com.tmax.proobject.test.runtime.application.test.servicegroup.main.service.call.LoopCall.service(LoopCall.java:17)\tat
com.tmax.proobject.test.runtime.application.test.servicegroup.main.service.call.LoopCallExecutor.execute(LoopCallExecutor.java:14)\tat
com.tmax.proobject.engine.service.executor.ServiceExecutor.executeService(ServiceExecutor.java:41)\tat
com.tmax.proobject.engine.servicemanager.thread.ServiceWorkerThread.executeService(ServiceWorkerThread.java:359)\tat
com.tmax.proobject.engine.servicemanager.thread.ServiceWorkerThread.run(ServiceWorkerThread.java:204)"
}
]
}
}
다음은 서비스의 응답에 담긴 키 값에 대한 설명이다.
| Key Name | 설명 |
|---|---|
domain |
런타임 엔진 서버의 도메인 이름이다. |
server |
런타임 엔진 서버의 이름이다. |
application |
수행 중인 서비스의 애플리케이션 이름이다. |
serviceGroup |
수행 중인 서비스의 서비스 그룹 이름이다. |
service |
수행 중인 서비스의 이름이다. |
threadId |
서비스를 수행 중인 Thread ID이다. |
stackTrace |
서비스를 수행 중인 Thread의 stackTrace이다. |
2.2. 통계 모니터링
통계 모니터링은 관제 대상인 서버에서 발생하는 Request, Response, Queueing Count를 수집해서 서버의 부하를 모니터링하는 기능이다.
이 기능을 사용하게 되면 초당 몇 개의 요청이 들어왔고 몇 개의 요청을 처리했으며, 아직 처리하지 못한 이벤트가 얼마나 큐에 남아있는지 등에 대한 정보를 알 수 있다. 이러한 정보를 바탕으로 운영 서버의 Scale Out 여부를 판단하는데 사용한다.
다음은 통계 모니터링의 정보 수집 구조에 설명이다.
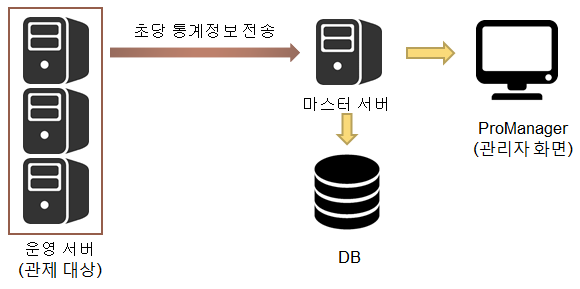
-
운영 서버
모니터링 모듈이 설치된 런타임 서버로 각 서버별로 초당 통계정보를 수집해서 마스터 서버로 전송한다.
-
마스터(MASTER) 서버
운영 서버들의 정보를 DB에 저장하고, 조합해서 의미있는 정보로 변환한다.
-
DB
통계 모니터링 정보를 저장하는 데이터베이스이다(통계 모니터링 테이블 생성 필요).
-
ProManager
마스터 서버로부터 정보를 요청해서 DB에 쌓인 정보를 시각화한다.
2.2.1. 마스터 서버 설정
관제 대상인 서버에서는 통계 모니터링 정보를 전송할 마스터 서버의 IP와 PORT를 설정해야 한다.
해당 설정은 다음 경로의 파일에 설정한다.
${PROOBJECT_HOME}/config/proobject.xml
다음은 proobject.xml의 주요 설정 항목에 대한 설명이다.
... <master-ip> x.x.x.x </master-ip> <master-port>6776</master-port> ...
| 항목 | 설명 |
|---|---|
<master-ip> |
서버 통계 정보를 보낼 마스터 서버의 IP이다. 해당 IP를 통해 Outbound TCP 통신으로 마스터의 서비스를 호출하기 때문에 반드시 설정해야 한다. |
<master-port> |
마스터 서버에서 설정한 ProObject Port를 설정한다. (기본값: 6776) |
2.2.2. 통계 모니터링 사용 설정
통계 모니터링 사용 옵션을 설정한 경우에 관제 대상 서버에서 통계 정보를 마스터 서버로 전송한다(마스터 서버는 관제 대상이 아니므로 해당 옵션을 설정하지 않는 것을 권장한다).
해당 설정은 다음 경로의 파일에 설정한다.
${PROOBJECT_HOME}/config/system.properties
다음은 system.properties 설정 항목에 대한 설명이다.
...
SYSTEM_MONITORING_STATISTICS_ENABLE={true|false}
...
| 항목 | 설명 |
|---|---|
SYSTEM_MONITORING_STATISTICS_ENABLE |
마스터 서버는 모니터링 대상이 아니므로 해당 옵션을 false로 설정하는 것을 권장한다. |
2.2.3. 통계 모니터링 테이블
DB에는 통계 모니터링 정보를 저장할 테이블을 생성해야 한다. 다음은 테이블을 생성하는 SQL 스크립트이다.
CREATE TABLE PO_STATISTICS_MONITORING (
DOMAIN VARCHAR(256),
SERVER VARCHAR(256),
APPLICATION VARCHAR(256),
SERVICEGROUP VARCHAR(256),
QUEUEINGCOUNT NUMBER,
REQUESTCOUNT NUMBER,
COMPLETECOUNT NUMBER,
INSERT_TIME NUMBER,
TIMEZONE VARCHAR(256),
CONSTRAINT PO_STATISTICS_MONITORING_PK PRIMARY KEY(DOMAIN,SERVER,INSERT_TIME)
);
CREATE INDEX PO_STAT_MONITORING_TIME_IDX ON PO_STATISTICS_MONITORING (INSERT_TIME);
CREATE INDEX PO_STAT_MONITORING_SERVER_IDX ON PO_STATISTICS_MONITORING (INSERT_TIME, SERVER);
COMMENT ON column PO_STATISTICS_MONITORING.DOMAIN IS '도메인 이름';
COMMENT ON column PO_STATISTICS_MONITORING.SERVER IS '서버 이름';
COMMENT ON column PO_STATISTICS_MONITORING.APPLICATION IS '어플리케이션 이름';
COMMENT ON column PO_STATISTICS_MONITORING.SERVICEGROUP IS '서비스 그룹 이름';
COMMENT ON column PO_STATISTICS_MONITORING.QUEUEINGCOUNT IS '대기중인 큐 개수 ';
COMMENT ON column PO_STATISTICS_MONITORING.REQUESTCOUNT IS '유입건수';
COMMENT ON column PO_STATISTICS_MONITORING.COMPLETECOUNT IS '완료건수';
COMMENT ON column PO_STATISTICS_MONITORING. INSERT_TIME IS '런타임 기준 시간';
COMMENT ON column PO_STATISTICS_MONITORING. TIMEZONE IS '런타임 기준 타임존';
3. E2E 모니터링
E2E(End to End) 모니터링은 사용자의 요청(거래)이 완료될 때까지 수행된 서버들의 수행 흐름을 추적하는 것을 말한다. 일반적으로 서비스를 제공하기 위해서는 아래의 그림과 같은 Layer(Web Server, WAS, DB)를 거쳐가는데, 각 서버에서 얼마만큼 시간이 걸렸는지를 쉽게 파악할 수 있다. 이로 인해 흐름이 중지된 구간을 분리하여 장애에 대해 집중 분석할 수 있게 해주는 기능이다.
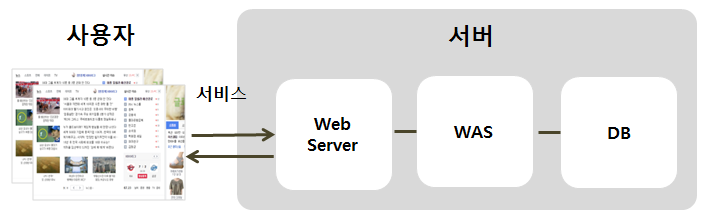
서버들이 독립적으로 업무를 수행하기 때문에 서버들간의 업무가 서로 같은 거래의 업무인지를 파악할 수 없다. 이런 문제를 해결하기 위해 Tmax 제품들간에는 FE(Front-End)부터 BE(Back-End)까지 같은 GUID(Global Unique ID)를 공유하여 같은 거래로 식별할 수 있게 처리해서 동일한 GUID로 묶어서 거래의 전반적인 흐름을 추적할 수 있다. 그 중에서 ProObject의 E2E 모니터링 모듈은 Web Server로부터 전달받은 GUID를 기준으로 WAS 내부에서 발생하는 흐름을 추적해서 서비스의 흐름을 모니터링하도록 기능을 제공한다.
3.1. 구조
E2E 모니터링을 위해서는 서비스가 수행되는 구간의 시작과 끝 지점마다 모니터링 정보를 HyperLoader를 사용해서 DB에 저장한다.
다음은 HyperLoader를 통해 모니터링 정보 수집과 런타임 엔진에서 HyperLoader에게 모니터링 정보를 전송하는 구조에 대해서 설명한다.
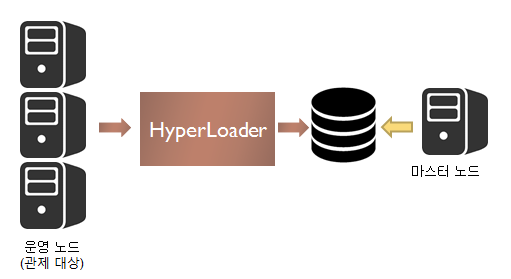
위의 그림을 보면 통계 모니터링과는 다르게 모니터링 정보를 마스터 서버가 저장하는 것이 아니라 운영 서버가 HyperLoader를 통해 직접 DB에 저장하는 것을 볼 수 있다. 통계 모니터링의 경우에는 초당 저장하는 데이터의 양이 일정하지만 E2E의 경우에는 서비스가 수행되는 구간의 시작과 끝 지점마다 모니터링 정보를 DB에 저장할 뿐만 아니라 대량 거래 상황에서는 DB에 저장하는 작업이 크게 늘어나기 때문에 동일한 방식으로 E2E 모니터링 정보를 저장하면 마스터 서버의 작업 스레드가 Blocking될 수 있기 때문에 대용량 데이터를 저장하는데는 적합하지 않은 구조이다. 이러한 문제를 해결하기 위해 운영 서버가 직접 DB에 모니터링 정보를 저장하게 하고, 마스터 서버는 저장된 데이터를 엮어서 의미있는 데이터를 관리자 UI에서 보여주는 구조를 가진다.
|
E2E 모니터링 기능을 사용하기 위해서 HyperLoader나 SysMaster와 연동을 해야 한다. 주요 동작 방식은 두 제품이 동일하나 SysMaster와 연동한 경우 모니터링 화면이 제공된다(현재 HyperLoader와 연동하는 경우에는 모니터링 화면을 제공하지 않음). SysMaster와 연동하는 방법은 커넥션 설정을 참고한다. SysMaster에 대한 자세한 설명은 해당 제품의 안내서를 참고한다. |
운영 서버에서 모니터링 정보를 저장하는 DB 작업이 매우 빈번하게 일어나기 때문에, JDBC 보다는 대용량 데이터를 처리하는데 적합한 고속 처리 데이터베이스 시스템인 HyperLoader를 사용한다. 만약에 JDBC를 사용하면 DB에 적재할 때마다 쿼리를 파싱하고 바인딩하는 작업 시간이 걸리지만, HyperLoader는 이와 같은 작업들을 생략하고 전달받은 byte 형태의 데이터를 미리 정의해둔 테이블에 직접 쓰는 방식이기 때문에 성능적으로 훨씬 더 빠른 속도를 보장한다.
다음은 모니터링 스레드의 구조이다.
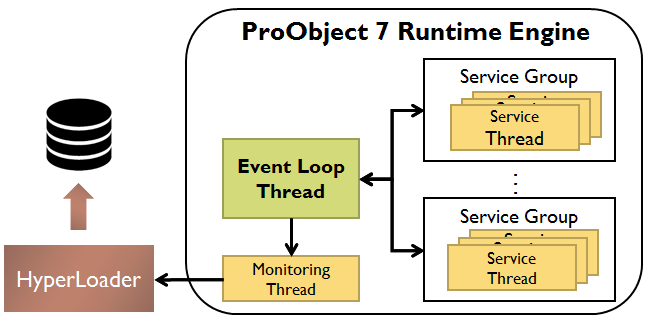
두 번째로는 런타임 엔진에서 HyperLoader에게 모니터링 데이터를 지속적으로 전송해야 하는데, 이를 모니터링 스레드를 별도로 운용해서 처리하고 있다. 별도로 모니터링 스레드를 운용하는 이유는 EM(Event Manager)은 Blocking되면 안되므로 EM에서 처리할 순 없고, 서비스 워커 스레드에서 DBIO 작업을 늘리는 것이 부담되기 때문이다. 따라서 모든 E2E 모니터링 정보는 모니터링 스레드가 HyperLoader에게 직접 전송하고, 실제 데이터는 EM을 거쳐서 모니터링 스레드로 전달하는 중앙처리 방식 구조를 취하고 있다.
중앙처리 방식이 아닌 서비스 워커 스레드가 EM을 거치지 않고 직접 모니터링 스레드로 전송한다면 서비스 워커 스레드마다 모니터링 스레드와 파이프로 연결해야 한다. 그러면 하나의 파이프를 여러 스레드가 경쟁하기 때문에 Lock 문제가 생기게 되고 이 문제를 해결하기 위해 여러 개의 파이프를 모니터링 스레드에 붙이면 너무 많은 FD를 쓰게 되며, 모니터링 스레드에서 멀티플렉싱(Multiplexing)을 처리해야 하기 때문에 복잡한 구조가 된다. 따라서 ProObject에서는 위의 그림과 같은 구조로 모니터링을 진행한다.
3.2. 데이터 타입
모니터링 모듈에서는 E2E 모니터링 정보를 데이터 타입별로 구분해서 서로 다른 테이블에 저장한다.
-
비즈니스 트랜잭션(Business Transaction)
사용자가 서비스(거래)를 요청한 순간부터 응답을 받을 때까지를 의미한다.
-
트레이스(Trace)
서비스(거래)가 완료되기까지 거쳐가는 과정들 하나하나를 의미한다.
그 이유는 기본적으로 사용자가 거래 단위로 얼마만큼 오래 걸렸는지를 확인하는 경우 트랜잭션 정보만 필요하므로 트레이스 정보까지 조회할 필요가 없기 때문이다. 따라서 모니터링 스레드 또한 데이터 타입별로 분리해서 HyperLoader에게 독립적으로 데이터를 전송한다. (실제로 모니터링 스레드는 2개)
다음은 E2E 모니터링 정보를 저장하는 트랜잭션 테이블과 트레이스 테이블의 각 컬럼에 대한 설명이다.
-
비즈니스 트랜잭션 테이블(PROOBJECT_BIZ_TRANSACTION)
컬럼 설명 GUID
거래의 ID이다.
SEQUENCE
실행 순서이다.
DOMAIN
도메인 이름이다. (현재는 PROOBJECT로만 저장)
SERVER
서버의 이름이다.
APPLICATION
실행 중인 애플리케이션의 이름이다.
SERVICEGROUP
실행 중인 서비스 그룹의 이름이다.
SERVICE
실행 중인 서비스의 이름이다.
TYPE
실행 상태이다.
-
START
-
END
-
ERROR
HEADER
ProObject 헤더 정보이다.
INOUT_DATA
전송된 IN/OUT/ EXCEPTION 정보이다.
TX_TIMESTAMP
해당 서버 기준으로 기록된 시간이다.
CLIENT_INFO
소켓으로 들어오고 나가는 트랜잭션일 때 클라이언트의 IP, PORT 정보이다.
-
-
트레이스 테이블(PROOBJECT_SERVICE_TRACE)
컬럼 설명 GUID
거래의 ID이다.
SEQUENCE
실행 순서이다.
DOMAIN
도메인 이름이다. (현재는 PROOBJECT로만 저장)
SERVER
서버의 이름이다.
APPLICATION
실행 중인 애플리케이션의 이름이다.
SERVICEGROUP
실행 중인 서비스 그룹의 이름이다.
SERVICE
실행 중인 서비스의 이름이다.
TYPE
실행 상태이다.
-
START
-
END
-
ERROR
-
OUTBOUND
RESOURCETYPE
리소스 타입이다.
-
SERVICEMANAGER
-
EVENTSERVICEMANAGER
-
COMPLEXSERVICE
-
EVENTSERVICE
-
FLOWSERVICE
-
OUTBOUND
-
DOF
-
BO
RESOURCENAME
리소스 이름이다.
'RESOURCETYPE'이 'SERVICEMANAGER', 'EVENTSERVICEMANAGER’일 때는 Call Type을 명시한다.
-
CALL
-
ACALL
-
RCALL
-
RENDEVOUS
-
FORWARD
-
GETREPLY
나머지 리소스들에 대해서는 해당 리소스의 클래스 이름을 명시한다.
INOUT_DATA
전송된 IN/OUT/ EXCEPTION 정보이다.
DETAIL
리소스별로 필요한 기타 정보이다.
TX_TIMESTAMP
해당 서버 기준으로 기록된 시간이다.
-
3.3. 시퀀스
서버들 간에 GUID를 통해 같은 거래임을 식별했다 할지라도 실제 수행 구간들의 흐름을 정렬하는데 문제가 있다. 만약에 서비스의 수행 흐름을 시간 순으로 정렬하게 되면, 서버들 간에 시간이 동기화되어 있지 않아 실제 실행 순서와 다를 수 있다. 이러한 문제를 해결하기 위해 식별된 거래들을 시간이 아닌 시퀀스(Sequence)를 바탕으로 정렬 처리한다.
시퀀스 정책은 다음과 같다.
-
같은 컴포넌트 내에서는 시퀀스를 1씩 증가시킨다.
-
다른 컴포넌트로 이동할 때는 depth를 추가한다.
-
depth는 .(dot) 으로 표현한다.
다음은 하나의 서비스(거래) 요청이 발생했을 때 시퀀스를 사용해서 서비스의 흐름을 추적하는 예제이다.
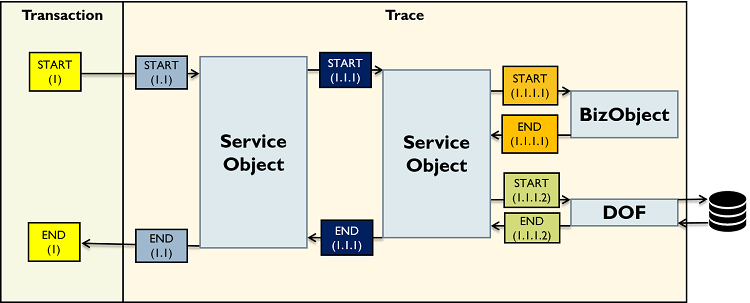
최초 거래 발생했을 때 트랜잭션 타입의 정보를 저장한다. 이때 발급한 시퀀스가 1이라고 한다면, 트레이스 정보의 최초 시작 시퀀스는 트랜잭션 시퀀스에 depth를 추가한 1.1이 되며, 다른 컴포넌트로 이동할 때마다 시퀀스의 depth를 추가한다. 또한 두 번째 ServiceObject 컴포넌트에서 BizObject를 수행한 다음에 DOF를 수행할 때 시퀀스가 1.1.1.1에서 1.1.1.2로 증가하는 것처럼 같은 컴포넌트 내에서는 시퀀스의 마지막 값을 1씩 증가시킨다.
결과적으로 위의 예제는 1(START) → 1.1(START) → 1.1.1(START) → 1.1.1.1(START) → 1.1.1.1(END) → 1.1.1.2(START) → 1.1.1.2(END) → 1.1.1(END) → 1.1(END) → 1(END)의 흐름대로 서비스를 실행하고 있음을 알 수 있다.
3.4. 데이터 수집 설정
모니터링 데이터 타입별로 수집은 정보는 아래 파일에 설정한다.
${PROOBJECT_HOME}/config/system.propertie
다음은 system.propertie 파일의 주요 설정항목에 대한 설명이다.
...
SYSTEM_MONITORING_TRANSACTION_ENABLE={true|false}
SYSTEM_MONITORING_TRACE_ENABLE={true|false}
SYSTEM_MONITORING_HEALTH_CHECK_INTERVAL_TIME=healthcheck_interval_time
...
| Key Name | 설명 |
|---|---|
SYSTEM_MONITORING_TRANSACTION_ENABLE |
트랜잭션 정보 수집 여부이다. (필수 항목) |
SYSTEM_MONITORING_TRACE_ENABLE |
트레이스 정보 수집 여부이다. (필수 항목) |
SYSTEM_MONITORING_HEALTH_CHECK_INTERVAL_TIME |
600초마다 연결에 대한 HealthCheck를 수행한다. HealthCheck에 대한 응답이 60초 동안 없는 경우 연결이 끊어진다. (선택 항목) (기본값: 600, 단위: 초(second)) [참고] 해당 설정 정보는 HyperLoader나 SysMaster에 동일하게 적용된다. |
다음은 모니터링 데이터 수집 정보를 설정한 예이다.
... SYSTEM_MONITORING_TRANSACTION_ENABLE=true SYSTEM_MONITORING_TRACE_ENABLE=true SYSTEM_MONITORING_HEALTH_CHECK_INTERVAL_TIME=600 ...
3.5. 커넥션 설정
ProObject 서버의 JVM 옵션에 HyperLoader와 커넥션을 맺기 위해 JEUS의 domain.xml 파일에 설정을 해야 한다.
JVM 옵션은 JEUS의 WebAdmin을 통해 설정하거나, domain.xml 파일을 수정한다.
<!-- HyperLoader 전용 JVM 옵션 -->
<jvm-config>
<jvm-option> -DTRANSACTION_HL_DATABASE=${db_name} -DTRANSACTION_HL_ADDRESS=${hyperloader_ip}:${hyperloder_port} -DTRANSACTION_HL_USERID=${db_account} -DTRANSACTION_HL_PASSWORD=${db_passwd} </jvm-option>
<jvm-option> -DTRACE_HL_DATABASE=${db_name} -DTRACE_HL_ADDRESS=${hyperloader_ip}:${hyperloder_port} -DTRACE_HL_USERID=${db_account} -DTRACE_HL_PASSWORD=${db_passwd} </jvm-option>
</jvm-config>
| Key Name | 설명 |
|---|---|
TRANSACTION_HL_DATABASE |
HyperLoader가 트랜잭션 정보를 저장할 데이터베이스명이다. |
TRANSACTION_HL_ADDRESS |
연결할 HyperLoader의 주소(IP:PORT)를 설정한다. PORT는 HyperLoader에 설정한 AnyLink 어댑터의 포트 번호를 설정한다. (기본값: 22006) |
TRANSACTION_HL_USERID |
HyperLoader가 트랜잭션 정보를 저장하기 위한 데이터베이스의 계정 아이디를 설정한다. |
TRANSACTION_HL_PASSWORD |
HyperLoader가 트랜잭션 정보를 저장하기 위한 데이터베이스의 계정 비밀번호를 설정한다. |
TRACE_HL_DATABASE |
HyperLoader가 트레이스 정보를 저장할 데이터베이스명을 설정한다. |
TRACE_HL_ADDRESS |
연결할 HyperLoader의 주소(IP:PORT)를 설정한다. PORT는 HyperLoader에 설정한 AnyLink 어댑터의 포트 번호를 설정한다. (기본값: 22006) |
TRACE_HL_USERID |
HyperLoader가 트레이스 정보를 저장하기 위한 데이터베이스의 계정 아이디를 설정한다. |
TRACE_HL_PASSWORD |
HyperLoader가 트레이스 정보를 저장하기 위한 데이터베이스의 계정 비밀번호를 설정한다. |
[참고]
HyperLoader를 대체해서 SysMaster를 사용해 모니터링 정보를 수집하는 경우 JEUS의 domain.xml 파일에 SysMaster 전용 JVM 옵션을 설정한다.
<!-- SysMaster 전용 JVM 옵션 -->
<jvm-config>
<jvm-option> -DPROOBJECT_MONITORING_SYSMASTER_VERSION=${VERSION} -DPROOBJECT_MONITORING_SYSMASTER_ADDRESS=${SYSMASTER_IP} -DPROOBJECT_MONITORING_SYSMASTER_PORT=${SYSMASTER_PORT} </jvm-option>
</jvm-config>
| Key Name | 설명 |
|---|---|
PROOBJECT_MONITORING_SYSMASTER_VERSION |
연결할 SysMaster의 버전을 설정한다. |
PROOBJECT_MONITORING_SYSMASTER_ADDRESS |
연결할 SysMaster의 IP를 설정한다. |
PROOBJECT_MONITORING_SYSMASTER_PORT |
연결할 SysMaster의 PORT를 설정한다. (기본값: 42007) |
4. 모니터링 제어
모니터링 제어는 중지, 재시작, 거래제어의 3가지 기능을 제공한다. 해당 기능들은 ProObject의 시스템 서비스 형태로 제공되며, 운영 서버에 서비스 호출을 통해 모니터링 제어 기능을 사용할 수 있다.
본 절에서는 각 기능별 사용 방법을 설명한다.
4.1. 중지
모니터링 스레드를 중지시키려면 모니터링 정보를 전송할 대상과 연결을 끊는다.
다음은 서비스 호출에 필요한 URL이다.
HTTP Method : GET URL : http://IP:PORT/proobject/system/MonitoringConnection?action=Stop
4.2. 재시작
모니터링 스레드를 재시작시키 려면 모니터링 정보를 전송할 대상과 연결을 맺는다.
다음은 서비스 호출에 필요한 URL이다.
HTTP Method : GET URL : http://IP:PORT/proobject/system/MonitoringConnection?action=Resume
4.3. 거래 제어
거래 제어는 특정 서비스가 돌아가는 서비스 워커 스레드를 종료시키는 기능이다. 모니터링 화면을 통해 비정상적으로 오래걸리거나 장애가 발생했다고 판단했을 때 해당 서비스를 수행 중인 스레드 아이디 값을 통해 스레드를 종료시킨다.
다음은 서비스 호출에 필요한 URL 및 입출력이다.
HTTP Method : POST
URL : http://IP:PORT/proobject/system/ThreadTermination?action=Service
INPUT : { "dto" : { "threadId" : "ProObject Service Worker[test.main-0]",
"application" : "test", "serviceGroup" : "main",
"service" : "LoopCall", "closeDataSource" : true } }
OUTPUT : { "dto" : { "closeDataSource" : true, "result" : true } }
-
거래 제어 서비스의 입력 파라미터
Input Parameter 설명 threadId
종료할 스레드의 아이디이다.
application
종료할 서비스의 애플리케이션 이름이다.
serviceGroup
종료할 서비스의 서비스그룹 이름이다.
service
종료할 서비스의 이름이다.
closeDataSource
DBSession 및 PreparedStatement 객체의 close 여부이다.
-
거래 제어 서비스의 출력 파라미터
Output Parameter 설명 closeDataSource
DBSession 및 PreparedStatement 객체의 close 성공 여부이다.
result
서비스 강제 종료 성공 여부이다.