배치 서비스 개발
본 장에서는 배치 서비스의 소개와 Job 내부 구성 요소 및 개발에 대해 설명한다.
1. JobObject 개요
Job Object Service, 배치는 온라인 서비스와 달리 실시간 처리보다는 주로 대용량의 데이터를 쌓아놓고 주기적으로 처리하거나 조건에 의해 실행되며, 온라인 서비스 처럼 요청에 의해 실행되기도 한다. 배치 서비스는 일반적으로 대용량 데이터를 처리하기 때문에 자원 점유율이 높으며, 장시간 처리를 하게 되기 때문에 한번의 실패가 고객의 업무처리에 치명적인 손상을 입힐 수 있다.
이와 같은 문제들을 극복하기 위해 ProObject의 배치 프레임워크는 고객의 업무에 사용되는 배치 프로그램이 일관되며 안정성있게 동작할 수 있도록 개발을 표준화를 지원하기 위해 JobObject(JO)를 지원한다.
1.1. 배치 서비스 아키텍처
배치 Job 개발을 위한 표준 프레임 및 대용량 배치 처리를 위한 아키텍처를 제공한다.
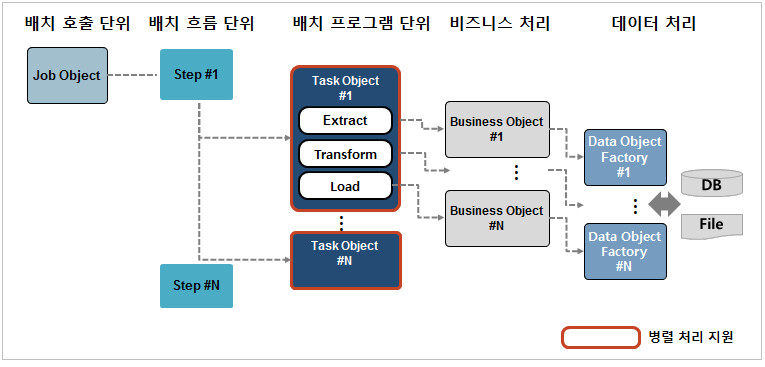
배치 프레임워크의 아키텍처는 배치 처리 업무의 개발 표준을 지원하고 다양한 배치 처리 환경을 접하더라도 배치 처리의 표준화를 통해 유용한 분석과 설계의 틀을 제공하는 중요한 역할을 담당한다.
배치 프레임 워크는 다음과 같은 설계 사상을 가진다.
-
배치 처리의 표준화
-
배치업무를 실행하는 방식을 표준화
-
온라인 서비스 연동과 같은 업무를 표준화
-
데이터베이스 처리 및 파일 처리의 표준화
-
-
배치업무 개발의 편의성
배치 JobObject(JO)를 이용하여 배치를 수행할 때 태스크를 정의하고 데이터 가공할 BizObject(BO)의 수행 순서 및 런타임에 스레드 및 데이터베이스 트랜잭션 관리를 제어할 수 있으므로 개발자는 업무 개발에만 집중하여 개발이 가능하며 배치 서비스의 거래를 제어하거나 관리적인 측면의 제어를 수행하는 데 어려움이 없도록 지원한다.
-
배치 관리의 편의성
배치 프레임워크는 개발자가 업무에 필요한 배치만 개발하도록 지원한다. 또한 BizObject(BO)를 사용하여 온라인 서비스의 업무 개발 환경과 동일한 환경을 제공함으로써 배치 프로그램 작성을 위한 별도의 교육을 받지 않아도 되는 관리적 측면의 편의를 제공한다.
배치 내에서 태스크 및 스탭 간에 데이터 공유 및 배치 정보 제공을 위해 영역별 Context를 지원한다.
-
JobContext
Job 내에 공유하는 Context로써 Job 내에 공유 데이터 및 Job 정보를 가진다.
-
StepContext
스탭 내에 공유하는 Context로써 스탭 내에 공유 데이터 및 스탭 정보를 가지며, StepContext를 통해 JobContext를 접근할 수 있다.
-
TaskContext 배치 관리의 편의성
태스크 내에 공유하는 Context로써 태스크 내에 공유 데이터 및 태스크 정보를 가지며, TaskContext를 통해 StepContext를 접근할 수 있다.
1.2. 배치 서비스 유형
배치 서비스는 일반적으로 3가지 유형이 존재한다.
-
일반 배치
일반 배치는 UNIX Command에서 실행하는 배치 프로그램의 가장 일반적인 형태이다. 그리고 일반 배치는 대용량 데이터베이스 처리 및 파일 처리 등의 반복적인 작업이 많은 경우 주로 사용된다.
ProObject에서는 일반 배치를 위하여 대용량 처리의경우 ETL Task라는 프로그래밍 모델을 지원하며, 간단한 배치의 경우 Normal Task라는 프로그래밍 모델을 제공한다.
-
상주 배치
일반 배치는 프로그램이 실행되면 작업이 끝날 때까지 지속적으로 수행하는 반면 상주 배치는 개발자(또는 프로그램 관리자)가 설정한 시간에 맞춰 프로그램을 일정시간 동안 실행했다가 중단하는 반복적인 수행 작업을 거친다.
ProObject에서는 상주 배치를 위하여 재개발하는 것이 아닌 일반 배치를 스케줄러에 등록함으로 상주 배치 동작을 할 수 있도록 제공한다. 개발자가 중복 여부를 체크하는 것이 아닌 중복 실행 설정 혹은 반복 설정을 통해 제어 가능하다.
-
온라인 배치
대용량 온라인 배치 처리는 단일 건수 처리 온라인 서비스를 병렬로 일괄 기동하여, 비즈니스 로직의 재사용성과 처리 성능을 모두 극대화하는 아키텍처를 의미한다. ProObject에서는 온라인 배치 업무 개발을 위하여 Online Task라는 프로그래밍 모델을 지원한다.
2. 배치 설정
관련된 내용은 다음의 경로에 설정한다.
${PROOBJECT_HOME}/config/proobject.xml
모든 설정은 <batch-config> 태그 아래에 설정에 존재한다. <batch-config>를 설정하면 배치 시스템의 서비스 그룹이 기동할 때 등록되게 되며, 센터컷 서비스를 호출하는데 해당 설정은 필수적이다.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<!DOCTYPE xml>
<ProObjectConfig>
...
<batch-config>
<batch-duplicate-check>false</batch-duplicate-check>
</batch-config>
...
</ProObjectConfig>
| 태그 | 설명 |
|---|---|
<batch-duplicate-check> |
배치 중복 실행 방지 여부를 설정한다.
|
<node-allocator-type> |
멀티 노드를 이용해 배치를 처리할 때 서비스를 노드에 분배하는 Node Allocator의 Type을 지정한다.
|
3. 배치 개발 모델
ProObject의 JobObject에서는 배치 업무를 개발할 수 있도록 다음의 3가지의 개발 모델을 지원한다. 유형별 개발에 대한 자세한 내용은 각 절의 설명을 참고한다.
3.1. ETL Task
전통적인 배치 프로그램에서 작업 단위를 데이터에 기준하여 분류하면 "데이터 수집 > 데이터 가공 > 데이터 적재"의 순서로 진행된다. 각 구분을 통하여 사용자가 트랜잭션 제어를 하지 않고, 수집 업무를 맡은 개발자는 수집만 가공 업무를 맡은 개발자는 가공만 신경써서 개발할 수 있도록 개발 영역을 분리한다. 또한 데이터를 적재하는 경우 가공된 데이터를 Commit-Interval만큼 모아서 적재 처리를 진행하기 때문에 DB에는 addBatch 처리가 가능하다.
ETL 배치는 파티셔너의 구현과 사용자의 설정에 따라 ETL Task를 병렬로 처리한다. 따라서 병렬 환경이 필요한 경우 파티셔너를 통해 ETL을 멀티로 수행할 것을 권장한다. 파티셔너에 대한 자세한 내용은 파티셔너를 참고한다.
다음은 Db To File을 작성하는 과정에 대한 설명이다.
-
ETL에서 가공 처리 및 전달자로 사용할 데이터 오브젝트를 작성한다.
-
ETL 배치의 데이터 수집 단계에서 사용할 DBDataObjectFactory 모듈을 생성한다.
-
File 데이터 오브젝트 팩토리를 작성한다. ETL 배치의 데이터 적재 단계에서 사용할 데이터 오브젝트 팩토리 모듈을 생성한다.
-
데이터 수집용 BO를 작성한다. ETL 배치의 데이터 수집에 사용되는 로직이 구현될 BO 모듈을 생성한다.
클래스를 생성한 후 com.tmax.proobject.batch.task.ItemReader를 구현한다. 이때 Generic 타입은 데이터 오브젝트를 확장한 클래스를 사용해야만 하며, 현재 작업에서는 ETLTestDataObject 클래스를 Generic 타입으로 사용한다. ETLTestDataObject는 가공처리 및 적재 처리에 사용될 데이터 전달용 데이터 오브젝트이다.
public class ItemReaderSample implements ItemReader<ETLTestDataObject>{ List<DataObject> list = new ArrayList(); Iterator<DataObject> iter; private int idx=0; @Override public void init(TaskContext context, Map<String, String> rangeContext) { SampleDataObjectDBDataObjectFactoryTest factory = new SampleDataObjectDBDataObjectFactoryTest(); factory.setSQL(SQL.SELECT1); factory.setCondition(CONDITION.EMPNO); factory.setEmpno(1); factory.setFetchSize(context.getTaskInfo().getPartitionerInfo().getChunkSize()); ForwardList<DataObject> list = factory.getForwardList(); iter = list.iterator(); } /* (non-Javadoc) * @see com.tmax.proobject.batch.task.ItemReader#read(com.tmax.proobject.batch.context.TaskContext) */ @Override public ETLTestDataObject read(TaskContext taskContext) { ServiceLogger.getLogger().info("readCall"); if(iter.hasNext()){ SampleDataObjectTest out = (SampleDataObjectTest) iter.next(); ETLTestDataObject retObj = new ETLTestDataObject(); retObj.setTestField(String.valueOf( out.getEname() + (idx++) )); return retObj ; }else{ return null; } } } -
데이터 가공용 BO를 작성한다. ETL 배치의 데이터 가공에 사용되는 로직이 구현될 BO 모듈을 생성한다.
클래스를 생성한 후 배치의 데이터 가공 인터페이스인 com.tmax.proobject.batch.task.ItemProcessor 클래스를 구현한다. 이때 Generic 타입은 첫 번째는 위의 수집에서 사용되었던 데이터 오브젝트를 받을 수 있는 타입, 두 번째는 가공에서 적재로 넘겨주는 DataObject 타입을 사용한다.
public class ItemProcessorSample implements ItemProcessor<ETLTestDataObject, ETLTestDataObject>{ public ETLTestDataObject process(ETLTestDataObject input, TaskContext taskContext) { ServiceLogger.getLogger().info("process"); return input; } public void init(TaskContext context) { } } -
ETL 배치의 데이터 적재에 사용되는 로직이 구현될 BO 모듈을 생성한다.
클래스를 생성한 후 ETL 배치의 데이터 적재 인터페이스인 com.tmax.proobject.batch.task.ItemWriter 클래스를 구현한다. 이때 Generic 타입은 가공에서 넘겨받을 데이터 오브젝트를 받을 수 있는 타입을 지정한다.
public class ItemWriterSample implements ItemWriter<ETLTestDataObject>{ public void write(List<ETLTestDataObject> items, TaskContext taskContext) { for(ETLTestDataObject data : items){ SampleDataObjectTest testObj = new SampleDataObjectTest(); testObj.setEmpno(1); testObj.setEname(data.getTestField()); testObj.setJob("jobTe"); testObj.setSal((long) 12); testObj.setDeptno(13); insertDataObject.add(testObj ); } insertDataObject.executeAll(); System.out.println( "items.size() : " + items.size() ); } SampleDataObjectDBDataObjectFactoryTest insertDataObject; /* (non-Javadoc) * @see com.tmax.proobject.batch.task.ItemWriter#init(com.tmax.proobject.batch.context.TaskContext) */ public void init(TaskContext context) { insertDataObject = new SampleDataObjectDBDataObjectFactoryTest(); insertDataObject.setSQL(SampleDataObjectDBDataObjectFactoryTest.SQL.INSERT1); } } -
ETL 배치의 파티셔닝을 위해 사용되는 로직이 구현될 BO 모듈을 생성한다.
클래스를 생성한 후 Range 파티셔너 인터페이스인 com.tmax.proobject.batch.partitioner.IRangePartitioner 클래스를 구현한다. 파티셔너에 대한 자세한 내용은 파티셔너를 참고한다.
/** * JO Editor에서 Partitioner 미 설정시, 해당 클래스로 동작 * jobParameter를 전달하고, 한번만 호출 */ public class RangePartitionerImple implements IRangePartitioner{ private Map<String,String> jobParamCopy = null; private int repeatCnt = 1; @Override public void init(TaskContext context, Map<String, String> jobParamter) { jobParamCopy = jobParamter; } @Override public Map<String, String> partition(TaskContext context) { if(repeatCnt>0){ repeatCnt--; return jobParamCopy; }else{ return null; } } } -
생성한 모듈들을 커밋한다.
3.2. Normal Task
ProObject 배치는 크게 자료의 수집/가공/적재의 사상을 가진 ETL Task와 멀티노드 환경에서의 분산 처리를 지원하는 Online Task로 구분되지만 개발자들의 개발 편의성 향상을 위해 Normal Task를 제공한다.
Normal Task 배치는 개발자에게 편의성을 제공하여 개발 생산성을 높일 수 있지만 ETL Task에 비해 제한된 튜닝 포인트를 가지게 되므로 개발자는 업무 특성을 고려하여 배치업무를 작성해야 한다.
다음은 Normal Task 배치를 작성하는 과정에 대한 설명이다.
-
Normal Task 배치 및 BO에서 사용되고 배치 입력 파라미터로 사용될 데이터 오브젝트를 생성한다.
-
BO에서 데이터 처리를 위해 DB 데이터 오브젝트 팩토리를 생성한다(선택사항).
-
Normal Task 배치의 처리하는 로직이 구현될 BO 모듈을 생성한다. 클래스를 생성한 후 NormalTask 인터페이스인 com.tmax.proobject.batch.task.IProcessor 클래스를 구현한다.
-
NormalTask의 파티셔닝 처리 로직을 구현할 BO 모듈을 생성한다.
클래스를 생성한 후 Range 파티셔너 인터페이스인 com.tmax.proobject.batch.partitioner.IRangePartitioner 클래스를 구현한다. 파티셔너에 대한 자세한 내용은 파티셔너를 참고한다.
/** * JO Editor에서 Partitioner 미 설정시, 해당 클래스로 동작 * jobParameter를 전달하고, 한번만 호출 */ public class RangePartitionerImple implements IRangePartitioner{ private Map<String,String> jobParamCopy = null; private int repeatCnt = 1; @Override public void init(TaskContext context, Map<String, String> jobParamter) { jobParamCopy = jobParamter; } @Override public Map<String, String> partition(TaskContext context) { if(repeatCnt>0){ repeatCnt--; return jobParamCopy; }else{ return null; } } } -
JO를 작성한다.
-
생성한 데이터 오브젝트 모듈, BO 모듈, JO 모듈을 커밋한다.
3.3. Online Task
동일한 업무 혹은 대용량 처리를 위해서는 배치업무로 개발하는 것이 일반적이다.
이미 각 처리에 대해 온라인 서비스로 개발되어 있어 중복 개발을 회피하거나 각 요청 하나당 트랜잭션이 필요한 경우 그리고 멀티 노드작업을 통해서 효율적으로 처리를 필요로 하는 경우에 ProObject에서 제공하는 온라인 배치라는 형태를 통해서 처리할 수 있다.
온라인 배치는 그 업무 처리를 전적으로 서비스에 위임한다. 그 업무를 호출하기 위한 Caller, 호출 결과에 따른 처리자에 의해 센터컷이 구성된다. 따라서, 업무 처리 로직을 배치 서비스로 전환할 필요가 없으며, 이에 따른 추가 작업인 데이터소스 변경, 배치용 API로의 변경 등이 필요없다. 또한, 온라인을 통해 데이터를 처리하기 때문에 데이터를 온라인 서비스의 입력값으로 변환하는 작업은 필요하지만 서비스 호출이나 기타 처리에 대해서 꼭 필요로 하지 않는한 엔진에서 대부분 처리를 지원한다.
3.3.1. 서비스 모듈 작성
온라인 배치에서 호출할 서비스 모듈을 작성한다. 서비스 모듈은 ProStudio에서 작성한다. 해당 모듈 작성에 대한 자세한 설명은 ProObject Studio 개발자 안내서를 참고한다.
3.3.2. 온라인 배치 모듈 작성
온라인 배치 모듈 클래스를 작성하기 위해서는 우선 배치 선후처리 모듈을 작성해야 한다.
-
Input Handler BizObject
DB나 File로부터 데이터를 읽어서 SO의 Input DO를 만들어주는 클래스이다. 앞에 ETL의 ItemReader과 하는 역할이 같기 때문에 동일한 인터페이스를 사용한다.
public class ItemReaderSample implements ItemReader<ETLTestDataObject>{ List<DataObject> list = new ArrayList(); Iterator<DataObject> iter; private int idx=0; @Override public void init(TaskContext context, Map<String, String> rangeContext) { SampleDataObjectDBDataObjectFactoryTest factory = new SampleDataObjectDBDataObjectFactoryTest(); factory.setSQL(SQL.SELECT1); factory.setCondition(CONDITION.EMPNO); factory.setEmpno(1); factory.setFetchSize(context.getTaskInfo().getPartitionerInfo().getChunkSize()); ForwardList<DataObject> list = factory.getForwardList(); iter = list.iterator(); } /* (non-Javadoc) * @see com.tmax.proobject.batch.task.ItemReader#read(com.tmax.proobject.batch.context.TaskContext) */ @Override public ETLTestDataObject read(TaskContext taskContext) { ServiceLogger.getLogger().info("readCall"); if(iter.hasNext()){ SampleDataObjectTest out = (SampleDataObjectTest) iter.next(); ETLTestDataObject retObj = new ETLTestDataObject(); retObj.setTestField(String.valueOf( out.getEname() + (idx++) )); return retObj ; }else{ return null; } } }
3.4. 파티셔너
태스크의 원활한 병렬 처리를 위해 파티셔너라는 모듈이 존재한다. 파티셔너 없이 병렬처리를 하는 것은 상당히 어렵다. 자신의 스레드 번호 혹은 자신이 호출된 횟수 등을 고려하여 데이터를 나눠 읽거나 처리하도록 할 수 있다.
위와 같이 복잡함을 방지하기 위하여 파티셔너가 생겨나게 되었고 태스크에서는 자신이 몇 번 스레드 혹은 몇 번째 호출 그리고 몇 번에 더 호출이 있는지는 더이상 고려할 필요없이 파티셔너가 나눠준 데이터를 통하여 처리만하도록 한다.
다음은 파티셔너를 작성하는 과정에 대한 설명이다.
-
com.tmax.proobject.batch.partitioner.IRangePartitioner를 구현한 클래스를 생성한다.
-
init()에서 데이터를 읽거나 데이터를 나눌 기준을 작성한다.
-
partition()에서 데이터 혹은 나눌 기준을 하나씩 맵에 넣어 리턴한다(리턴한 맵은 태스크에 파라미터로 전달된다).
-
아래는 예제 코드이다.
public class RangePartitionerEmp implements IRangePartitioner{ private int chunkSize; private int totalCnt; private int nowCnt; public void init(TaskContext context, Map<String,String> jobParamter) { nowCnt = 0; totalCnt = 100; ProObjectLogger logger = ServiceLogger.getLogger(); chunkSize = context.getTaskInfo().getPartitionerInfo().getChunkSize(); } public Map<String, String> partition(TaskContext context) { ProObjectLogger logger = ServiceLogger.getLogger(); logger.warning("test42"); if(nowCnt>totalCnt){ return null; } int nextCnt = nowCnt + chunkSize-1; if(nextCnt>totalCnt){ nextCnt = totalCnt; } Map<String,String> keyMap = new HashMap<String, String>(); keyMap.put("start", String.valueOf(nowCnt)); keyMap.put("end", String.valueOf(nextCnt)); nowCnt = nextCnt+1; return keyMap; } } -
태스크에서 파티셔너에서 넣은 값을 받아 추가적인 데이터를 읽거나 처리한다(병렬처리수가 1이 아니면 그 수만큼partition()이 불리며 태스크는 동시에 실행된다).
-
태스크 처리를 마치면 partition() 메소드가 다시 호출되며 partition() 메소드는 null이 리턴될 때까지 계속 호출된다.
4. 배치 호출
배치 호출하는 방법을 소개한다. 배치 호출하는 방법은 PO 외부에서 호출하는 방법, PO 내부 즉 서비스 중 호출하는 방법으로 나뉜다.
-
PO 외부에서 호출하는 방법
예1) JSON_INPUT을 넣지 않은 예제 java -cp 'proobject-client-7.0.0.0-jar-with-dependencies.jar' com.tmax.proobject.client.JobMain -i 192.168.0.128 -p 8080 -a test -sg example -j JobServiceNormalSample 예2) JSON_INPUT를 포함한 예제 java -cp 'proobject-client-7.0.0.0-jar-with-dependencies.jar' com.tmax.proobject.client.JobMain -i 192.168.0.128 -p 8080 -a test -sg example -j JobServiceNormalSample -jin '{"buildVersion":0,"deployRevision":0,"count":0, "applicationConfigPath":"","serviceGroup":[],"serviceGroupBinaryPath":[],"dtoBinaryPath":[]}' 예3) 배치 호출 시 타임아웃을 지정하는 경우(60초) java -cp 'proobject-client-7.0.0.0-jar-with-dependencies.jar' com.tmax.proobject.client.JobMain -i 192.168.0.128 -p 8080 -a test -sg example -j JobServiceNormalSample -jin '{"jobStatusCode":0,"job_ex_id":"","job_id":"","err_msg":""}' -rt 60000 -
PO 내부에서 호출하는 방법
//실행번호를 얻는 예제 코드 JobExeParameter exparam = new JobExeParameter("app","svcGrp","JobServiceNormal"); //애플리케이션명, 서비스그룹명, 배치명 exparam.setJobParameter(new CCParameter()); //배치의 jobParameter exparam.setNoReply(true); //false 시에는 배치가 종료 후 응답, true 시에는 배치 실행 후 즉시 응답 exparam.setJob_exe_id("Ex_2311"); //jobExeId를 set 후 배치 호출시 해당 ExeId로 배치 실행번호를 사용하며, //기존에 사용된(테이블에 삽입되어있는) 실행번호 사용 시 에러발생 하므로 고유값을 사용해야 함 //null일 경우 엔진에서 UUID를 통해 고유값사용 WaitObject wo = JobServiceBroker.getInstance().invokeLocalJob(exparam, false); //false의 경우 내부에 call을 사용하여 해당 API에서 대기 상태이며, //true 시 내부에 acall을 사용하여 WaitObject를 반환 Object obj = wo.get() ; if(obj instanceof JobResponseDataObject){ //배치의 응답 DataObject는 JobResponseDataObject로 고정되어 있음 String exId = ((JobResponseDataObject) obj).getJob_ex_id(); } -
PO 내부에서 타노드의 PO를 호출하는 방법
JobExeParameter jobExeParameter = new JobExeParameter(); jobExeParameter.setIp("192.168.0.128"); jobExeParameter.setPort(8080);//http Port jobExeParameter.setAppName("appName"); jobExeParameter.setSvcGrpName("grpName"); jobExeParameter.setJobName("jobId"); jobExeParameter.setMsgInputData("{}"); jobExeParameter.setNoReply(false); ServiceResponse svcResponse = JobServiceRemoteBroker.getInstance().invokeRemoteJob(jobExeParameter);
5. 센터컷
본 절에서는 센터컷의 개념과 개발 방법, 설정 방법에 대해서 설명한다.
5.1. 개요
센터컷은 온라인 서비스를 통해 데이터를 처리하는 것은 온라인 배치와 동일하지만, 프레임워크가 제공하는 테이블과 서비스를 사용해 대용량의 데이터를 처리하기 위한 추가적인 개발자의 코드를 최소화하면서 온라인 배치를 처리하는 아키텍처를 의미한다.
대용량 데이터를 처리하기 위하여 멀티 노드 처리 및 로드 밸런싱을 제공하고 안정성을 위한 failover 처리, Suspend/Resume/Terminate 등 동작 제어를 지원한다. 이러한 기능들을 제공하기 위해 센터컷은 ProObject의 서비스들로 구성되어 있으며 센터컷을 사용하기 위해서는 프레임워크의 테이블 구조 및 항목들에 이해가 필요하다.
다음은 센터컷 서비스를 하는 서버와 데이터베이스 구성에 대한 설명이다.
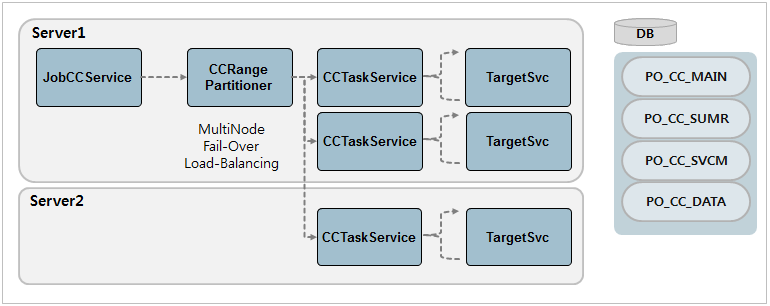
-
Service
구분 설명 JobCCService
센터컷을 처리하는 대표 시스템 서비스로 Input으로 전달 받은 CC_ID와 CC_EX_ID를 통해 센터컷을 처리한다.
CCRangePartitioner
JobCCService를 통해 호출되는 내부 서비스로 CC_MAIN과 CC_SUMR 테이블을 읽어 range를 분할하여 CCTaskService를 호출한다.
CCTaskService
실제 TargetSvc를 호출하는 서비스로 CCRangePartitioner를 통해 전달받은 seq만큼의 반복을 수행하며 TargetSvc를 호출한다.
-
DB 테이블
센터컷 관련 처리를 위한 데이터를 테이블에 저장한다. 테이블에 대한 설명은 센터컷 처리 테이블을 참고한다.
5.2. 센터컷 개발
본 절에서는 센터컷의 개발 및 실행방법과 테이블의 사용 예제를 설명한다.
5.2.1. 센터컷 개발 및 실행
센터컷은 이미 개발된 서비스를 통해 데이터를 처리하는 방식을 제공한다는 점은 온라인 배치와 동일하지만, 프레임워크의 원장을 활용하여 개발자의 코딩을 최소화한다는 점이 다르다. 센터컷은 개발자의 코딩을 최소화하기 위하여 프레임워크의 각 테이블에 대해 정확히 이해해야 한다.
다음은 센터컷의 개발 과정에 대한 설명이다.
-
PO_CC_MAIN 데이터를 삽입한다. 센터컷 ID, 서비스 이름, INPUT 클래스 이름, 병렬 처리 수, 1회 실행할 때 한번에 처리할 Chunk 수(FetchSize) 등 실행 정보를 등록
-
멀티노드 처리가 필요한 경우 PO_NODE 테이블에 노드 정보를 추가하고 PO_NODE_JOB 테이블에 데이터를 삽입한다.
센터컷의 개발이 완료된 후 다음의 과정으로 센터컷의 실행 및 준비를 한다.
-
실행하기 위해 필요한 고유값인 실행번호(아이디, 고유값, 날짜 혹은 시간)를 정의한다.
-
센터컷에 활용할 데이터를 센터컷 아이디, 센터컷 실행번호를 포함하여 프레임워크 원장(PO_CC_DATA)에 저장한다.
-
프레임워크 원장에 적재한 데이터 카운터 및 일자를 포함한 PO_CC_SUMR 테이블에 삽입한다.
-
센터컷을 센터컷 아이디와 실행번호를 INPUT으로 실행한다.
5.2.2. 예제
다음은 센터컷 테이블을 사용하는 예제이다.
--PO_CC_MAIN 데이터 삽입, 동시 요청수 1, 데이터 분할 수 10
--com.tmax.proobject.batch.dataobject.CCParameter Input 클래스를 가진
--app.svcG1.JobServiceCCTargetSample 서비스 호출
insert into po_cc_main(CC_ID, APP_NAME, SVC_GRP_NAME, SVC_NAME,
INPUT_CLZ, CONCURRENT_NUM, CHUNK_SIZE, HANDLER_CLASS, CALL_RETRY_CNT)
VALUES ('CC_ID_SAM1','app','svcG1','JobServiceCCTargetSample',
'com.tmax.proobject.batch.dataobject.CCParameter',1,10,null,0);
--ProObject7_2 노드 추가
insert into PO_NODE(NODE_ID, NODE_NAME, HOST, TCP_PORT, STATUS)
VALUES ('ProObject7_2','ProObject7_2','192.168.0.128',6778,1);
--ProObject7_3 노드 추가
insert into PO_NODE(NODE_ID, NODE_NAME, HOST, TCP_PORT, STATUS)
VALUES ('ProObject7_3','ProObject7_3','192.168.0.128',6779,1);
--ProObject7_2에 비율 1
insert into PO_NODE_JOB(NODE_ID, JOB_ID, NODE_WEIGHT)
VALUES ('ProObject7_2','CC_ID_SAM1',1);
--ProObject7_3에 비율 1
insert into PO_NODE_JOB(NODE_ID, JOB_ID, NODE_WEIGHT)
VALUES ('ProObject7_3','CC_ID_SAM1',1);
--센터컷은 ProObject7_2 노드, ProObject7_3 노드 1:1 비율로 호출
--데이터 삽입, 실행번호는 'ex_190219'으로 임의 생성
insert into po_cc_data(CC_ID, CC_EXE_ID, SEQ, DATA_STATUS, AMT, DATA1, DATA2, DATA3, DATA4, DATA5)
VALUES ('CC_ID_SAM1', 'ex_190219', 0, '0', 0, '{"cc_id":"123","cc_exe_id":"testEx0","retry_yn":"n"}', null, null, null, null);
insert into po_cc_data(CC_ID, CC_EXE_ID, SEQ, DATA_STATUS, AMT, DATA1, DATA2, DATA3, DATA4, DATA5)
VALUES ('CC_ID_SAM1', 'ex_190219', 1, '0', 0, '{"cc_id":"123","cc_exe_id":"33","retry_yn":"n"}', null, null, null, null);
--sumr 삽입
insert into po_cc_sumr(CC_ID, CC_EXE_ID, CC_STATUS, CC_STT_TIME, CC_END_TIME, TOT_DSCNT, TOT_DSAMT, NML_CNT, NML_AMT, ERR_CNT, ERR_AMT)
VALUES ('CC_ID_SAM1', 'ex_190219', '0', '', '', 2, 0, 0, 0, 0, 0);
5.3. 센터컷 설정
관련된 내용은 다음의 경로에 설정한다.
${PROOBJECT_HOME}/system/config/application.xml
해당 설정은 <center-cut> 태그 아래에 설정한다. 시스템 애플리케이션에 <center-cut>을 설정하지 않으면 설정의 기본 값을 통해 동작한다.
<center-cut>
<svcm-unit-enable>false</svcm-unit-enable>
<svcm-delete-enable>true</svcm-delete-enable>
<centercut-service-tx-policy>SEPARATE</centercut-service-tx-policy>
<cc-date-enable>false</cc-date-enable>
</center-cut>
| 태그 | 설명 |
|---|---|
<svcm-unit-enable> |
센터컷 실행 시 PO_CC_SVCM_UNIT 테이블에 데이터를 적재할지 설정한다.
|
<svcm-delete-enable> |
센터컷 chunk 단위 처리가 끝났을 때 해당하는 PO_CC_SVCM 테이블의 row를 지울지 결정한다.
|
<centercut-service-tx-policy> |
센터컷 트랜잭션 단위를 설정한다.
|
<cc-date-enable> |
센터컷에서 CC_DATE를 사용해 센터컷을 처리한다.
|
6. 배치 관련 테이블
ProObject의 배치 상태, 온라인 배치 혹은 멀티노드 처리를 위한 노드 정보, 센터컷 관련 처리를 위한 데이터를 테이블에 저장한다.
-
배치 상태 기록 테이블
테이블 설명 배치의 현재 실행 상태 및 종료 상태를 저장한다.
배치 내에 태스크 및 스탭, 파티셔너의 상태 및 종료 상태를 저장한다.
-
노드 관련 테이블
테이블 설명 온라인 배치 혹은 멀티 노드를 사용하는 노드 정보를 관리한다.
배치 내에 태스크 및 스탭, 파티셔너의 상태 및 종료 상태를 저장한다.
-
센터컷 처리 테이블
테이블 설명 센터컷 메인 테이블이다.
센터컷 정보를 집계하는 테이블이다.
센터컷 현황을 저장하는 테이블이다.
센터컷 서비스 한 건의 처리 현황을 보여주는 테이블이다.
센터컷 원장 테이블이다.
각 배치 노드의 처리 현황을 보여주는 테이블이다.
센터컷 원장 테이블이다.
센터컷 원장 테이블이다.
6.1. 배치 상태 기록 테이블
-
PO_JOB_STATUS
배치의 현재 실행 상태 및 종료 상태를 저장하는 테이블이다.
컬럼 설명 APP_NAME
배치의 애플리케이션명이다(배치도 마찬가지로 서비스와 동일하게 애플리케이션과 서비스 그룹이 존재한다).
SVC_GRP_NAME
배치의 서비스 그룹명이다(배치도 마찬가지로 서비스와 동일하게 애플리케이션과 서비스 그룹이 존재한다).
JOB_ID
배치 아이디이다.
INSTANCE_ID
배치 인스턴스 아이디이다. 해당 아이디는 배치의 Input과 고유 값의 조합으로 동일 배치 Input으로 동시 실행되는 것을 방지하는데 사용된다(디폴트는 동일 배치 Input에 대해 허용한다).
JOB_EXECUTION_ID
배치 실행번호이다. 실행할 때마다 랜덤으로 생성되며 고유한 값으로 배치에 명령들을 처리할 때 해당 번호를 통해 배치를 구분한다.
STATUS
배치의 상태코드이다.
-
14 : 처리중
-
15 : 처리완료
-
16 : 에러
START_TIME
배치 실행 시작시간이다.
END_TIME
배치 실행 종료시간이다.
NODE_ID
배치의 노드 아이디이다.
-
-
PO_TASK_STATUS
배치 내에 태스크 및 스탭, 파티셔너의 상태 및 종료 상태를 저장하는 테이블이다.
컬럼 설명 JOB_EXECUTION_ID
배치의 실행번호로 어떤 배치의 하위 태스크 스탭 파티셔너인지 구분을 위해 사용된다.
TASK_SEQ
태스크 일련번호로 EMB 상 표현 순서를 위해 사용된다.
STEP_NAME
스탭 이름이다(실제로는 아이디이다).
TASK_NAME
태스크 이름이다(실제로는 아이디이다).
TASK_TYPE
태스크 타입이다.
해당 모듈이 태스크라면 ETL인지 온라인인지 구분하며, 태스크가 아니면 스탭인지 파티셔너인지 나타낸다.
MODIFICATION_TIME
해당 태스크가 DB 값을 수정한 시간이다.
최초 실행하는 경우, 종료하는 경우, 처리량 혹은 상태값 변경하는 경우마다 갱신된다.
START_TIME
실행 시간시간이다.
END_TIME
실행 종료시간이다.
NML_CNT
정상 처리 건수이다.
파티셔너에서 태스크를 여러 개 호출하는 경우 정상 처리되면 정상 처리 건수가 올라간다.
ERR_CNT
실패 처리 건수이다.
파티셔너에서 태스크를 여러 개 호출하는 경우 실패할 때 실패 처리 건수가 올라간다.
STATUS
상태코드이다.
-
14 : 처리 중
-
15 : 처리완료
-
16 : 에러
ERROR_MESSAGE
에러로 종료되었을 때에 메시지를 저장한다.
-
6.2. 노드 관련 테이블
노드 관련 설정이 없으면, 센터컷은 센터컷 서비스가 호출된 자신 노드로 CCTask를 호출한다.
-
PO_NODE
온라인 배치 혹은 멀티 노드를 사용하는 노드 정보 관리 테이블이다.
컬럼 설명 NODE_ID
노드의 아이디이다.
NODE_NAME
노드명이다.
HOST
노드의 호스트명이다.
PORT
노드의 포트명이다.
STATUS
노드의 상태이다. 현재는 미사용이나, 노드 관리를 위하여 사용된다.
UPDATE_TIME
노드 정보 업데이트 시간(등록 및 수정 시간)이다.
-
PO_NODE_JOB
배치 내에 태스크 및 스탭, 파티셔너의 상태 및 종료 상태를 나타낸다.
컬럼 설명 NODE_ID
노드의 아이디(PO_NODE에 존재하는 아이디)이다.
JOB_ID
배치의 아이디이다.
TASK_ID
배치의 태스크 아이디이다.
NODE_WEIGHT
노드의 가중치이다.
6.3. 센터컷 처리 테이블
-
PO_CC_MAIN
PO_CC_MAIN은 센터컷 메인 테이블이다.
컬럼 설명 CC_ID
센터컷 아이디이다.
APP_NAME
센터컷에서 호출할 서비스의 애플리케이션명이다.
SVC_GRP_NAME
센터컷에서 호출할 서비스의 서비스 그룹명이다.
SVC_NAME
센터컷에서 호출할 서비스명이다.
INPUT_CLZ
센터컷에서 호출할 서비스의 Input DataObject 클래스명이다.
CONCURRENT_NUM
센터컷에서 서비스 호출할 병렬 처리수이다.
CHUNK_SIZE
병렬 처리당 데이터 묶음수이다.
CALL_RETRY_CNT
요청에 실패하는 경우 재처리 횟수이다.
HANDLER_CLASS
센터컷 처리 시 선처리, 후처리를 정의한 클래스명이다.
-
PO_CC_SUMR
PO_CC_SUMR는 센터컷 정보를 집계하는 테이블이다.
컬럼 설명 CC_ID
센터컷 아이디이다.
CC_EXE_ID
센터컷 실행 아이디이다.
CC_STATUS
상태 코드이다.
-
0 : 미처리(준비됨)
-
14 : 처리중
-
15 : 처리완료
-
16 : 에러
-
20 : 일시중지
-
21 : 종료됨
CC_STT_TIME
센터컷 시작시간이다.
CC_END_TIME
센터컷 종료시간이다.
TOT_DSCNT
전체 처리수이다.
TOT_DSAMT
총 합계이다.
NML_CNT
정상 처리수이다.
NML_AMT
정상 합계이다.
ERR_CNT
에러 처리수이다.
ERR_AMT
에러 합계이다.
NODE_ID
센터컷 파티셔너가 동작하는 노드 아이디이다.
CC_DATE
센터컷 DATE이다. 설정에 따라 센터컷 실행 시 CC_ID, CC_EXE_ID와 함께 Key로 동작한다.
-
-
PO_CC_SVCM
PO_CC_SVCM은 센터컷 현황을 저장하는 테이블이다.
컬럼 설명 CC_ID
센터컷 아이디이다.
CC_EXE_ID
센터컷 실행 아이디이다.
TASK_SER
센터컷 처리 요청 일련번호이다.
STT_SER
센터컷 요청 데이터 시작 일련번호이다.
END_SER
센터컷 요청 데이터 끝 일련번호이다.
CPLT_SER
센터컷 요청 데이터 현재 처리 중 일련번호이다.
CC_TASK_STATUS
상태 코드이다.
-
0 : 미처리
-
14 : 처리중
-
15 : 처리완료
-
16 : 에러
NML_CNT
정상 처리된 건수이다.
NML_AMT
정상 처리 합계이다.
ERR_CNT
에러 건이다.
ERR_AMT
에러건 합계이다.
NODE_ID
처리 중 노드 아이디이다.
CC_DATE
센터컷 일자정보이다. 설정에 따라 센터컷 실행 시 CC_ID, CC_EXE_ID와 함께 Key로 동작한다.
-
-
PO_CC_SVCM_UNIT
PO_CC_SVCM_UNIT는 센터컷 서비스 한 건의 처리 현황을 보여주는 테이블이다.
컬럼 설명 CC_ID
센터컷 아이디이다.
CC_EXE_ID
센터컷 실행번호이다.
TASK_SER
센터컷 처리 요청 일련번호이다.
CPLT_SER
센터컷 요청 데이터 현재 처리 중 일련번호이다.
CC_TASK_STATUS
상태 코드이다.
-
0 : 미처리
-
14 : 처리중
-
15 : 처리완료
-
16 : 에러
CC_SVC_STT_TIME
센터컷 서비스 시작 시간이다.
CC_SVC_END_TIME
센터컷 서비스 종료 시간이다.
NODE_ID
처리 중 노드 아이디이다.
ERR_MSG
서비스가 에러로 종료되었을 때 에러 메시지이다.
CC_DATE
센터컷 일자정보이다. 설정에 따라 센터컷 실행 시 CC_ID, CC_EXE_ID와 함께 Key로 동작한다.
-
-
PO_CC_DATA
PO_CC_DATA는 센터컷 원장 테이블이다.
컬럼 설명 CC_ID
센터컷 아이디이다.
CC_EXE_ID
센터컷 실행번호이다.
SEQ
cally 서비스의 일련번호이다.
DATA_STATUS
cally 서비스의 상태이다. (초기값: 0)
AMT
cally 서비스의 AMT이다.
DATA1
cally 서비스의 데이터이다.
DATA2
cally 서비스의 데이터이다.
DATA3
cally 서비스의 데이터이다.
DATA4
cally 서비스의 데이터이다.
DATA5
cally 서비스의 데이터이다.
HEADER_DATA
cally 서비스의 헤더이다.
ERR_MSG
cally 서비스의 에러 메시지이다.
CC_DATE
센터컷 일자정보이다. 설정에 따라 센터컷 실행 시 CC_ID, CC_EXE_ID와 함께 Key로 동작한다.
-
PO_NODE_JOB_SUMR
각 배치 노드의 처리 현황을 보여주는 테이블이며 추후 삭제될 테이블 입니다.
컬럼 설명 JOB_ID
잡 아이디(CC_ID)이다.
JOB_EXE_ID
실행 번호이다.
NODE_ID
노드 아이디이다.
NML_CNT
성공 카운트이다.
ERR_CNT
에러 카운트이다.
UPDATE_TIME
변경시간이다.
DATA2
배치의 태스크 아이디이다.
DATA3
노드의 가중치이다.
DATA4
노드의 아이디(PO_NODE에 존재하는 아이디)이다.
DATA5
배치의 아이디이다.
ERR_MSG
배치의 태스크 아이디이다.
6.4. 테이블 생성 스크립트
다음은 배치 테이블 생성 스크립트 예제이다.
CREATE TABLE PO_NODE_JOB_SUMR(
JOB_ID VARCHAR2(20),
JOB_EXE_ID VARCHAR2(64 BYTE),
NODE_ID VARCHAR2(128),
NML_CNT NUMBER(10),
ERR_CNT NUMBER(10),
UPDATE_TIME TIMESTAMP DEFAULT SYSDATE, / 최종 상태 변경 시간 /
PRIMARY KEY (JOB_ID,JOB_EXE_ID,NODE_ID)
);
COMMENT ON TABLE PO_NODE_JOB_SUMR IS 'JOB 노드별 통계 테이블';
COMMENT ON column PO_NODE_JOB_SUMR.JOB_ID IS 'JOB ID';
COMMENT ON column PO_NODE_JOB_SUMR.JOB_EXE_ID IS 'JOB 실행 ID';
COMMENT ON column PO_NODE_JOB_SUMR.NODE_ID IS '노드 ID';
COMMENT ON column PO_NODE_JOB_SUMR.NML_CNT IS '정상건수';
COMMENT ON column PO_NODE_JOB_SUMR.ERR_CNT IS '실패건수';
COMMENT ON column PO_NODE_JOB_SUMR.UPDATE_TIME IS '업데이트시간';
CREATE TABLE PO_NODE(
NODE_ID VARCHAR2(128),
NODE_NAME VARCHAR2(256),
HOST VARCHAR2(256),
PORT NUMBER(5),
FILE_PORT NUMBER(5),
TCP_PORT NUMBER(5),
STATUS VARCHAR2(20),
UPDATE_TIME TIMESTAMP DEFAULT SYSDATE,
DESCRIPTION VARCHAR2(1024 BYTE),
SUCCESS_GDV NUMBER(5) ,
NODE_IS_SSL VARCHAR2(8 BYTE),
NODE_TYPE VARCHAR2(32 BYTE),
PRIMARY KEY (NODE_ID)
);
COMMENT ON TABLE PO_NODE IS 'ProObject Node 관리 테이블, 배치에서 활용';
COMMENT ON column PO_NODE.NODE_ID IS '노드 ID';
COMMENT ON column PO_NODE.NODE_NAME IS '센터컷 실행 어플리케이션명';
COMMENT ON column PO_NODE.HOST IS '호스트명, ex) 192.168.0.1';
COMMENT ON column PO_NODE.PORT IS ' HTTP 포트명 ex) 8888';
COMMENT ON column PO_NODE.FILE_PORT IS 'FILE 포트명 ex) 4444';
COMMENT ON column PO_NODE.TCP_PORT IS 'TCP 포트명 ex) 6776';
COMMENT ON column PO_NODE.STATUS IS '상태';
COMMENT ON column PO_NODE.UPDATE_TIME IS '업데이트시간';
COMMENT ON column PO_NODE.DESCRIPTION IS '설명';
COMMENT ON column PO_NODE.SUCCESS_GDV IS '해당 노드의 최신 성공 GDV';
COMMENT ON column PO_NODE.NODE_IS_SSL IS '노드 SSL 설정 유무 (true, false)';
COMMENT ON column PO_NODE.NODE_TYPE IS '노드 타입 RUNTIME, MONITORING';
CREATE TABLE PO_NODE_JOB(
NODE_ID VARCHAR2(128),
JOB_ID VARCHAR2(128),
TASK_ID VARCHAR2(128),
NODE_WEIGHT NUMBER(3) DEFAULT 0,
unique(NODE_ID,JOB_ID,TASK_ID)
);
COMMENT ON TABLE PO_NODE_JOB IS 'JOB에서 사용되는 NODE 정보 테이블';
COMMENT ON column PO_NODE_JOB.NODE_ID IS '노드 ID';
COMMENT ON column PO_NODE_JOB.JOB_ID IS 'JOB ID';
COMMENT ON column PO_NODE_JOB.TASK_ID IS 'TASK ID, CC의 경우 null';
COMMENT ON column PO_NODE_JOB.NODE_WEIGHT IS '노드 가중치';
CREATE TABLE PO_CC_MAIN
(
CC_ID VARCHAR2(20),
APP_NAME VARCHAR2(256),
SVC_GRP_NAME VARCHAR2(256),
SVC_NAME VARCHAR2(256),
INPUT_CLZ VARCHAR2(256),
CONCURRENT_NUM NUMBER(3)not null,
CHUNK_SIZE NUMBER(4) not null,
CALL_RETRY_CNT NUMBER(4)not null,
HANDLER_CLASS VARCHAR2(256 BYTE),
CONSTRAINT PO_CC_MAIN_PK PRIMARY KEY (CC_ID)
);
COMMENT ON TABLE PO_CC_MAIN IS '센터컷 메인 테이블';
COMMENT ON column PO_CC_MAIN.CC_ID IS '센터컷 ID';
COMMENT ON column PO_CC_MAIN.APP_NAME IS '센터컷 실행 어플리케이션명';
COMMENT ON column PO_CC_MAIN.SVC_GRP_NAME IS '센터컷 실행 서비스그룹명';
COMMENT ON column PO_CC_MAIN.SVC_NAME IS '센터컷 실행 서비스명';
COMMENT ON column PO_CC_MAIN.INPUT_CLZ IS '센터컷 실행 서비스 InputDO 클래스명';
COMMENT ON column PO_CC_MAIN.CONCURRENT_NUM IS '동시처리수(0일경우 일시중지, -1이하 중지)';
COMMENT ON column PO_CC_MAIN.CHUNK_SIZE IS '호출당 데이터 묶음수';
COMMENT ON column PO_CC_MAIN.HANDLER_CLASS IS '센터컷 핸들러 클래스명';
CREATE TABLE PO_CC_SUMR
(
CC_ID VARCHAR2(20),
CC_EXE_ID VARCHAR2(64 BYTE),
CC_STATUS NUMBER(2),
CC_STT_TIME VARCHAR2(14),--YYYYMMddHHmmss
CC_END_TIME VARCHAR2(14),
TOT_DSCNT NUMBER(10),
TOT_DSAMT NUMBER(18,2),
NML_CNT NUMBER(10),
NML_AMT NUMBER(18,2),
ERR_CNT NUMBER(10),
ERR_AMT NUMBER(18,2),
NODE_ID VARCHAR2(128),
CONSTRAINT PO_CC_SUMR_PK PRIMARY KEY (CC_ID, CC_EXE_ID)
);
COMMENT ON column PO_CC_SUMR.CC_ID IS '센터컷 ID';
COMMENT ON column PO_CC_SUMR.CC_EXE_ID IS '센터컷 실행 ID';
COMMENT ON column PO_CC_SUMR.CC_STATUS IS '상태(추후 상세정보)';
COMMENT ON column PO_CC_SUMR.CC_STT_TIME IS '시작시간(YYYYMMddHHmmss)';
COMMENT ON column PO_CC_SUMR.CC_END_TIME IS '종료시간(YYYYMMddHHmmss)';
COMMENT ON column PO_CC_SUMR.TOT_DSCNT IS '총처리건수';
COMMENT ON column PO_CC_SUMR.TOT_DSAMT IS '총금액';
COMMENT ON column PO_CC_SUMR.NML_CNT IS '정상건수';
COMMENT ON column PO_CC_SUMR.NML_AMT IS '정상금액';
COMMENT ON column PO_CC_SUMR.ERR_CNT IS '에러건수';
COMMENT ON column PO_CC_SUMR.ERR_AMT IS '에러금액';
CREATE TABLE PO_CC_SVCM
(
CC_ID VARCHAR2(20),
CC_EXE_ID VARCHAR2(64 BYTE),
TASK_SER NUMBER(10),
STT_SER NUMBER(10),
END_SER NUMBER(10),
CPLT_SER NUMBER(10),
CC_TASK_STATUS NUMBER(2) DEFAULT 0,
NML_CNT NUMBER(10) DEFAULT 0,
NML_AMT NUMBER(18,2) DEFAULT 0,
ERR_CNT NUMBER(10) DEFAULT 0,
ERR_AMT NUMBER(18,2) DEFAULT 0,
NODE_ID VARCHAR2(128),
CONSTRAINT PO_CC_SVCM_PK PRIMARY KEY (CC_ID, CC_EXE_ID,TASK_SER)
);
COMMENT ON column PO_CC_SVCM.CC_ID IS '센터컷 ID';
COMMENT ON column PO_CC_SVCM.CC_EXE_ID IS '센터컷 실행 ID';
COMMENT ON column PO_CC_SVCM.TASK_SER IS '태스크일련번호';
COMMENT ON column PO_CC_SVCM.STT_SER IS '시작일련번호';
COMMENT ON column PO_CC_SVCM.END_SER IS '끝일련번호';
COMMENT ON column PO_CC_SVCM.CPLT_SER IS '현재일련번호';
COMMENT ON column PO_CC_SVCM.CC_TASK_STATUS IS '상태(추후 상세정보)';
COMMENT ON column PO_CC_SVCM.NML_CNT IS '정상건수';
COMMENT ON column PO_CC_SVCM.NML_AMT IS '정상금액';
COMMENT ON column PO_CC_SVCM.ERR_CNT IS '에러건수';
COMMENT ON column PO_CC_SVCM.ERR_AMT IS '에러금액';
CREATE TABLE PO_CC_DATA
(
CC_ID VARCHAR2(20),
CC_EXE_ID VARCHAR2(64 BYTE),
SEQ NUMBER(10),
DATA_STATUS NUMBER(2),
AMT NUMBER(18),
DATA1 VARCHAR2(4000),
DATA2 VARCHAR2(4000),
DATA3 VARCHAR2(4000),
DATA4 VARCHAR2(4000),
DATA5 VARCHAR2(4000),
HEADER_DATA VARCHAR2(4000),
ERR_MSG VARCHAR2(4000),
CONSTRAINT PO_CC_DATA_PK PRIMARY KEY (CC_ID, CC_EXE_ID,SEQ)
);
COMMENT ON column PO_CC_DATA.CC_ID IS '센터컷 ID';
COMMENT ON column PO_CC_DATA.CC_EXE_ID IS '센터컷 실행 ID';
COMMENT ON column PO_CC_DATA.SEQ IS '일련번호(0~)';
COMMENT ON column PO_CC_DATA.DATA_STATUS IS '상태(추후 상세정보)';
COMMENT ON column PO_CC_DATA.AMT IS '금액';
COMMENT ON column PO_CC_DATA.DATA1 IS '데이터1';
COMMENT ON column PO_CC_DATA.DATA2 IS '데이터2';
COMMENT ON column PO_CC_DATA.DATA3 IS '데이터3';
COMMENT ON column PO_CC_DATA.DATA4 IS '데이터4';
COMMENT ON column PO_CC_DATA.DATA5 IS '데이터5';
COMMENT ON column PO_CC_DATA.ERR_MSG IS '에러메세지';
CREATE TABLE PO_JOB_STATUS(
APP_NAME VARCHAR2(256),
SVC_GRP_NAME VARCHAR2(256),
JOB_ID VARCHAR2(256),
INSTANCE_ID VARCHAR2(128),
JOB_EXECUTION_ID VARCHAR2(40),
STATUS VARCHAR2(20),
START_TIME VARCHAR2(14),
END_TIME VARCHAR2(14),
NODE_ID VARCHAR2(128),
CONSTRAINT PO_JOB_STATUS_OK PRIMARY KEY (APP_NAME, SVC_GRP_NAME, JOB_ID, INSTANCE_ID, JOB_EXECUTION_ID)
);
COMMENT ON column PO_JOB_STATUS.APP_NAME IS '어플리케이션 명';
COMMENT ON column PO_JOB_STATUS.SVC_GRP_NAME IS '서비스 그룹 명';
COMMENT ON column PO_JOB_STATUS.JOB_ID IS '배치 ID';
COMMENT ON column PO_JOB_STATUS.INSTANCE_ID IS '배치 잡 파라미터 ID';
COMMENT ON column PO_JOB_STATUS.JOB_EXECUTION_ID IS '배치 실행 ID';
COMMENT ON column PO_JOB_STATUS.STATUS IS '배치 상태(INITIALIZE, PROCESSING, COMPLETE_PROCESSING, PROCESSING_ERRROR, SUSPEND, TERMINATED )';
COMMENT ON column PO_JOB_STATUS.START_TIME IS '시작시간(YYYYMMddHHmmss)';
COMMENT ON column PO_JOB_STATUS.END_TIME IS '종료시간(YYYYMMddHHmmss)';
COMMENT ON column PO_JOB_STATUS.NODE_ID IS '노드 ID';
CREATE TABLE PO_TASK_STATUS
(
JOB_EXECUTION_ID VARCHAR2(40),
TASK_SEQ NUMBER(10),
STEP_NAME VARCHAR2(256),
TASK_NAME VARCHAR2(256),
TASK_TYPE VARCHAR2(20),
MODIFICATION_TIME VARCHAR2(14),
START_TIME VARCHAR2(14),
END_TIME VARCHAR2(14),
NML_CNT NUMBER(10) default 0,
ERR_CNT NUMBER(10) default 0,
STATUS VARCHAR2(20),
ERROR_MESSAGE CLOB,
CONSTRAINT PO_TASK_STATUS_PK PRIMARY KEY (JOB_EXECUTION_ID,TASK_SEQ)
);
COMMENT ON column PO_TASK_STATUS.JOB_EXECUTION_ID IS '배치 실행 ID';
COMMENT ON column PO_TASK_STATUS.TASK_SEQ IS '태스크 일련번호, 태스크 순서를 알기위해 사용';
COMMENT ON column PO_TASK_STATUS.STEP_NAME IS 'STEP NAME';
COMMENT ON column PO_TASK_STATUS.TASK_NAME IS 'TASK_NAME';
COMMENT ON column PO_TASK_STATUS.TASK_TYPE IS 'TASK_TYPE(STEP, PART, ETL, ONLINE, NORMAL)';
COMMENT ON column PO_TASK_STATUS.MODIFICATION_TIME IS '수정시간(YYYYMMddHHmmss)'; -- CNT 를 추후에 추가하지 않는다면 제거될수 있음
COMMENT ON column PO_TASK_STATUS.START_TIME IS '시작시간(YYYYMMddHHmmss)';
COMMENT ON column PO_TASK_STATUS.END_TIME IS '종료시간(YYYYMMddHHmmss)';
COMMENT ON column PO_TASK_STATUS.NML_CNT IS '정상건수';
COMMENT ON column PO_TASK_STATUS.ERR_CNT IS '실패건수';
COMMENT ON column PO_TASK_STATUS.STATUS IS '상태';
COMMENT ON column PO_TASK_STATUS.ERROR_MESSAGE IS '에러 메시지';