COBOL Structure
This chapter describes the basic structure of COBOL.
1. Characters
The most basic unit of the COBOL language is the character. The basic character set includes alphabet, digits, and special characters. Individual characters are combined to form strings and separators. The strings and separators are used to form words, literals, phrases, clauses, and sentences.
Single-byte and double-byte characters are used in alphanumeric literals and comments.
The following table shows the basic character set which forms strings and separators in source code.
| Character | Description |
|---|---|
Space |
|
+ |
Plus sign |
- |
Minus sign or hyphen |
* |
Asterisk |
/ |
Slash |
= |
Equal sign |
$ |
Currency sign |
, |
Comma |
; |
Semicolon |
. |
Decimal point or period |
" |
Double quotation mark |
( |
Left parenthesis |
) |
Right parenthesis |
> |
Greater than |
< |
Less than |
: |
Colon |
' |
Single quotation mark |
A - Z |
Alphabet (uppercase) |
a - z |
Alphabet (lowercase) |
0 - 9 |
Digit |
2. Strings
A string is one or more characters which form a COBOL word, a literal, a PICTURE string, or a comment. A string is delimited by separators. A separator is a string of consecutive characters that delimits strings.
2.1. COBOL Words
A COBOL word is a string which forms a user-defined word, a system name, or a reserved word.
Most user-defined words (except section names, paragraph names, and level numbers) must contain at least one alphabetical character. Priority numbers and level numbers do not have to be unique. Lowercase letters are regarded as uppercase letters in COBOL words.
Except for special characters, a COBOL word consists of the following.
-
A - Z
-
a - z
-
0 - 9
-
- (hyphen): cannot be used as the first or last character in COBOL words.
The following rules are for COBOL words except LENGTH, RANDOM, and SUM.
-
Reserved words cannot be for user-defined words, system names, or function names.
-
User-defined words, system names, or function names can share the same name. A single name can be used as a user-defined word, a system name, and a function name. In the case of a shared name, the meaning of the word is determined from the context.
The following rules apply to the following COBOL words: LENGTH, RANDOM, and SUM.
-
LENGTH, RANDOM, and SUM can be used as a reserved word or a function name. The meaning of the word is determined from the context.
-
LENGTH, RANDOM, and SUM cannot be used as user-defined words or system names.
Function Names
A function name specifies intrinsic functions.
Reserved Words
A reserved word is a string that is predefined and reserved in COBOL. It cannot be used as a user-defined word or a system name.
There are five types of reserved words.
-
Keywords
Keywords are reserved words that are required to represent a clause, an entry, or a statement.
-
Optional words
Optional words are reserved words that can be included in an entry or a statement to improve readability. They do not affect the execution of a program.
-
Figurative constants
Figurative constants are reserved words that can be used to name a specific value.
Figurative constant Description ZERO, ZEROS, ZEROES
Represents the numeric value 0 or the character "0", depending on the context.
If ZERO, ZEROS, or ZEROES is used in a context where an alphanumeric character is used, the alphanumeric character 0 is used.
SPACE, SPACES
Represents one or more spaces.
SPACE is treated as an alphanumeric character literal in a context where an alphanumeric character is used, or as a double-byte space in a context where a double-byte character is used.
If DBCS is used with the locale set to ja_JP.sjis, ja_JP.SJIS, or ja_JP, a double-byte space is used by default.
HIGH-VALUE, HIGH-VALUES
Represents the character that has the greatest value in the collating sequence used.
HIGH-VALUE is treated as an alphanumeric character literal in a context where an alphanumeric character is used. The value in the EBCDIC collating sequence is X’FF'. Values for other alphanumeric data depend on the collating sequence that is used.
If a context cannot be determined, an alphanumeric character with the value X’FF' is used.
LOW-VALUE, LOW-VALUES
Represents the character that has the lowest position in the collating sequence used.
LOW-VALUE is treated as an alphanumeric character literal in a context where an alphanumeric character is used. The value in the EBCDIC collating sequence is X'00'. Values for other alphanumeric data depend on the collating sequence that is used.
If a context cannot be determined, an alphanumeric character with the value X'00' is used.
QUOTE, QUOTES
Can be used as follows:
-
Double quotation mark (")
QUOTE and QUOTES are used as alphanumeric literals in a context where an alphanumeric character is used.
ALL literal
literal can specify alphanumeric characters including double-byte characters or another figurative constant. If literal is not a figurative constant, the ALL literal represents one or more occurrences of the string that makes up the literal.
The ALL literal cannot be used in CALL, INSPECT, INVOKE, STOP, or STRING statements.
NULL, NULLS
Specifies a value indicating that a data item defined in the USAGE POINTER, USAGE PROCEDURE-POINTER, USAGE FUNCTION-POINTER, or special register, such as ADDRESS OF, does not have a valid address.
-
-
Special character words
There are two types of special characters.
Type Operator Arithmetic operators
+, -, /, *, **
Comparison operators
<, >, =, <,=, >, =
-
Special registers
Special registers are data items or temporary values generated by the compiler. To refer to a special register, a reserved word corresponding to the data item is used.
The following describes each special register and its usage.
-
ADDRESS OF
-
Refers to the address of a data item defined in the LINKAGE, LOCAL-STORAGE, or WORKING-STORAGE section.
-
Implicitly defined with USAGE POINTER.
-
Cannot specify a function ID for operands.
-
-
LENGTH OF
-
Saves the number of bytes used by a data item.
In the case of a double-byte data item described with USAGE DISPLAY-1, each character takes 2 bytes of storage.
-
Can be used anywhere in the procedure division.
-
When ADDRESS OF is specified as an argument of LENGTH OF, regardless of the argument of ADDRESS OF, LENGTH OF is the size of the address used in the environment where the corresponding code is executed.
-
Cannot be specified in the following.
-
A receiving data item
-
A subscript
-
-
When LENGTH OF is used as a parameter of the CALL statement, BY CONTENT or BY VALUE must be specified.
-
When table items are specified, LENGTH OF has the length of a single item. To refer to a table item, a subscript does not need to be specified for the item name.
-
Even if the area referenced when ID is specified is not available, the length will be returned if it can be determined.
-
The length of a data item can be obtained using the intrinsic function LENGTH.
-
-
RETURN-CODE
-
Passes the return code of the current COBOL program to a calling program or OS.
-
When a COBOL program ends, a user-defined value is saved in RETURN-CODE. (A user-defined return code might be different from the actual return code.)
When control returns to the calling program, the value of RETURN-CODE is passed to the calling program. In this case, RETURN-CODE is defined as follows:
01 RETURN-CODE GLOBAL PICTURE S9(4) VALUE ZERO.
-
When RETURN-CODE is used in nested programs, it is implicitly defined with the GLOBAL clause in the outermost program.
-
The following example illustrates how to set RETURN-CODE.
MOVE 8 TO RETURN-CODE
-
-
SORT-CONTROL
-
Alphanumeric data item defined as follows:
01 SORT-CONTROL GLOBAL PICTURE X(8) USAGE DISPLAY.
-
OFCOBOL only checks the syntax, and does not affect the system.
-
-
SORT-CORE-SIZE
-
Binary data item defined as follows:
01 SORT-CORE-SIZE GLOBAL PICTURE S9(8) USAGE IS BINARY VALUE ZERO.
-
OFCOBOL only checks the syntax, and does not affect the system.
-
-
SORT-FILE-SIZE
-
Binary data item defined as follows:
01 SORT-FILE-SIZE GLOBAL PICTURE S9(8) USAGE IS BINARY VALUE ZERO.
-
OFCOBOL only checks the syntax, and does not affect the system.
-
-
SORT-MESSAGE
-
Alphanumeric data item defined as follows:
01 SORT-MESSAGE GLOBAL PICTURE X(8) USAGE IS DISPLAY.
-
OFCOBOL only checks the syntax, and does not affect the system.
-
-
SORT-MODE-SIZE
-
Binary data item defined as follows:
01 SORT-MODE-SIZE GLOBAL PICTURE S9(5) USAGE BINARY VALUE ZERO.
-
OFCOBOL only checks the syntax, and does not affect the system.
-
-
SORT-RETURN
-
Binary data item defined as follows:
01 SORT-RETURN GLOBAL PICTURE S9(4) USAGE BINARY VALUE ZERO.
-
OFCOBOL only checks the syntax, and does not affect the system.
-
-
TALLY
-
Binary data item defined as follows:
01 TALLY GLOBAL PICTURE S9(5) USAGE BINARY VALUE ZERO.
-
OFCOBOL only checks the syntax, and does not affect the system.
-
-
WHEN-COMPILED
-
Alphanumeric data item in which the compilation start time is saved. It is defined as follows:
01 WHEN-COMPILED GLOBAL PICTURE X(16) USAGE DISPLAY.
-
OFCOBOL only checks the syntax, and does not affect the system.
-
-
XML-CODE
-
Used for the following purposes.
-
To communicate status between the XML parser and the processing procedure that was identified in an XML PARSE statement.
-
To indicate either that an XML GENERATE statement executed successfully or that an exception occurred during XML generation.
Defined as follows:
01 XML-CODE PICTURE S9(9) USAGE BINARY VALUE 0.
-
-
When used in nested programs, this special register is implicitly defined with the global attribute in the outermost program. When the XML parser encounters an XML event, it sets XML-CODE and then passes control to the processing procedure. For all events except an EXCEPTION event, XML-CODE contains zero when the processing procedure receives control.
You can set XML-CODE before returning to the parser as follows:
-
-1 indicates that after a normal event occurs, the parser immediately ends without causing the EXCEPTION event and processing remaining XML documents.
-
1 indicates that if the XMLPARSE(XMLSS) compiler option applies, it is ready to parse the next segment in a document after the END-OF-INPUT event. If there is no longer segment to return from the processing procedure, XML-CODE must be set to 0.
If XML-CODE is set to another value before control is returned to the parser, the result is not defined. When the parser sends control to the XML PARSE statement, XML-CODE is the most recent value set by the processing procedure or the parser. When an XML GENERATE statement ends, XML-CODE is either zero, indicating successful completion of XML generation, or a nonzero error code, indicating that an exception occurred during XML generation.
-
-
-
XML-EVENT
-
Sends event information from the XML parser to the processing procedure identified in the XML PARSE statement. Specific events and relevant special registers that are set are different depending on the setting of the XMLPARSE compiler option, XMLPARSE(XMLSS) or XMLPARSE(COMPAT).
Defined as follows:
01 XML-EVENT USAGE DISPLAY PICTURE X(30) VALUE SPACE.
-
OFCOBOL supports only a part of the XMLPARSE(XMLSS) option.
The following lists XML events that can be parsed with XMLPARSE(XMLSS) and their special register data.
XML-EVENT Special Register Data ATTRIBUTE-CHARACTERS
XML-TEXT has data enclosed in quotation marks or apostrophes.
ATTRIBUTE-NAME
XML-TEXT has an attribute name.
COMMENT
XML-TEXT has comment enclosed in the opening character sequence "<!--" and the closing character sequence "-->".
CONTENT-CHARACTERS
XML-TEXT has character data of an element enclosed in start and end tags.
END-OF-DOCUMENT
All XML special registers except for XML-CODE and XML-EVENT are empty with zero length.
END-OF-ELEMENT
XML-TEXT has the local part of the end element tag or empty element tag name.
EXCEPTION
XML-CODE is a nonzero value. XML-TEXT is the document fragment up to the point of the error or anomaly that caused the exception. All other XML special registers are empty with zero length.
START-OF-DOCUMENT
All XML special registers except for XML-CODE and XML-EVENT are empty with zero length.
START-OF-ELEMENT
XML-TEXT has the local part of the start element tag or empty element tag name.
VERSION-INFORMATION
XML-TEXT has the version information in the XML declaration. The information is enclosed in quotation marks or apostrophes.
-
-
XML-TEXT
-
Defined during XML parsing to have document fragments. It is alphanumeric data item with the length of contained XML document fragment. The length varies from 0 through the XML document length. There is no equivalent COBOL data description entry.
-
When the operand of the XML PARSE statement is an alphanumeric data item, the parser sets XML-TEXT to the document fragment related to an event before transferring control to the processing procedure.
-
To check the number of bytes contained in XML-TEXT, use the LENGTH function or the LENGTH OF special register. And XML-TEXT cannot be used as receiving data.
-
-
2.2. Literals
A literal is a string defined as a sequence of characters or the use of figurative constants.
Alphanumeric Literals
The following describes each literal.
-
Basic alphanumeric literals
-
An arbitrary single-byte or double-byte character can be used as a basic alphanumeric literal.
-
All readable characters included in alphanumeric literals are literal values.
-
Double quotation marks (" ") or single quotation marks (' ') are used as a delimiter regardless of the APOST/QUOTE compiler option.
The basic format is as follows:
"alphanumeric-characters" 'alphanumeric-characters'
The enclosing quotation marks are removed when the program is compiled.
If you want to use double or single quotes within a literal, use the same code as a pair.
"THIS ISN""T WRONG" 'THIS ISN''T WRONG'
The type of quotation marks at the start and the end of a literal must be the same.
'THIS IS RIGHT' "THIS IS WRONG' 'THIS IS WRONG"
-
-
Double-byte character literals
-
A double-byte character literal has the following format.
G"<DBCS-characters>" G'<DBCS-characters>'
-
A double-byte character literal can be used in the following areas.
-
Data division
-
A VALUE clause that defines a double-byte data item
-
A VALUE OF clause in the FD section
-
-
Procedure division
-
Comparison logic that contains a double-byte data item
-
Arguments passed from the CALL statement to BY CONTENT
-
DISPLAY and EVALUATE statements
-
INITIALIZE statements
-
MOVE statements
-
STRING statements
-
UNSTRING statements
-
Figurative constant, "ALL"
-
-
COPY and REPLACE statements, and TITLE
-
-
-
National Literal
-
National literal can have the basic or hexadecimal notation format.
-
Basic national literal formats:
N"<character-data>" N'<character-data>' NC"<character-data>" NC'<character-data>'
-
National hexadecimal literal formats:
NX"<hexadecimal-digits>" NX'<hexadecimal-digits>'
-
National hexadecimal literal is not affected by the NSYMBOL compiler option.
-
Basic national literals and national hexadecimal literals can be used:
-
in a VALUE clause associated with a data item of class national
-
in a VALUE clause associated with a condition-name for a conditional variable that is defined with usage NATIONAL
-
in figurative constant, "ALL"
-
in a relation condition
-
in the WHEN phrase of a format-2 SEARCH statement (binary search)
-
in the ALL, LEADING, or FIRST phrase of an INSPECT statement
-
in the BEFORE or AFTER phrase of an INSPECT statement
-
in the DELIMITED BY phrase of a STRING statement
-
in the DELIMITED BY phrase of an UNSTRING statement
-
as an argument passed BY CONTENT in a CALL statement
-
as an argument passed BY VALUE in a CALL statement
-
in a DISPLAYor EVALUATE statement
-
as a sending item in the following procedural statements:
-
INITIALIZE
-
INSPECT
-
MOVE
-
STRING
-
UNSTRING
-
-
as an argument of the following intrinsic functions:
-
DISPLAY-OF
-
LENGTH
-
LOWER-CASE
-
MAX
-
MIN
-
ORD-MAX
-
ORD-MIN
-
REVERSE
-
UPPER-CASE
-
-
in a COP, REPLACE, or TITLE statement
-
-
-
Hexadecimal notation for alphanumeric literals
-
An alphanumeric literal can be expressed in hexadecimal notation as follows:
X"hexadecimal-digits" X'hexadecimal-digits'
A hexadecimal digit is a character between '0' and '9', 'a' and 'f', and 'A' and 'F'. Two hexadecimal digits represent one character in a single-byte character set. Four hexadecimal digits express one character in a double-byte character set. An even number of hexadecimal digits must be specified. The maximum length is 320 bytes.
-
Writing hexadecimal characters on multiple lines works in the same way as other alphanumeric literals, except that a character that represents the start of a literal (X" or X') cannot appear separately.
-
-
NULL terminated literals
-
An alphanumeric literal can be null-terminated when it is used with the following format.
Z"mixed-characters" Z'mixed-characters'
-
A single-byte character literal, a double-byte character literal, or a literal that consists of both single-byte and double-byte characters can be specified. However, a character that contains X'00' cannot be specified. X'00' is the NULL character that is automatically added when a literal is null-terminated.
-
If the intrinsic function LENGTH is applied to the null-terminated literal, NULL characters are not calculated.
-
Numeric Literals
A numeric literal is a string that consists of digits between 0 and 9, a sign character (+ or -), and a decimal point. If a literal has no decimal point, it is an integer.
Setting a numeric literal is as follows:
-
Can be up to 31 digits.
-
Only one sign character can be used. A sign character must be the leftmost character of the literal. If a literal has no sign character, it is a positive value.
-
Only one decimal point can be used.
-
If a decimal point is used, decimal places are not calculated for the number of digits.
-
A decimal point can be placed anywhere in a literal except in the rightmost character of the literal.
-
The value of a numeric literal is the quantity in the literal. The size is equal to the number of digits specified by the user. Numeric literals can be fixed-point or floating-point numbers.
The following shows the floating-point literal format and describes the relative rules.
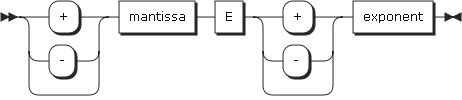
-
The sign is optional. If the sign is omitted, the compiler regards it as a positive number.
-
A mantissa is a number that has between 1 and 16 digits. A decimal point must be included in the mantissa.
-
An exponent is represented by the character E followed by an optional sign and one or two digits.
2.3. PICTURE Strings
The following rules apply to PICTURE strings.
-
A PICTURE string consists of a currency sign and a combination of characters in the COBOL character set.
-
For information on how to configure and use PICTURE strings, refer to PICTURE Clause.
-
Characters used to specify a PICTURE string are not interpreted as readable characters. Each is interpreted as a symbol for the purpose of a PICTURE string.
2.4. Comments
A comment is any combination of characters in the computer’s character set. It does not affect the execution of a program. A comment can span multiple lines, but any double-byte character must be entered on a single line. The syntax of comments is not checked.
There are two types of comments.
-
Comment entry (identification division)
Identification division comment entries are defined in the identification division entry.
-
Comment line (any division)
A line is specified as a comment line when it starts with an asterisk (*) in the Indicator area (column 7).
3. Separators
A separator is a character or a string that delimits strings.
| Character | Description |
|---|---|
b |
Space |
,b |
Comma |
.b |
Period |
;b |
Semicolon |
( |
Left parenthesis |
) |
Right parenthesis |
: |
Colon |
"b |
Double quotation mark (for quotations) |
'b |
Single quotation mark |
X" |
Start of a hexadecimal alphanumeric literal |
X' |
Start of a hexadecimal alphanumeric literal |
Z" |
Start of a null-terminated alphanumeric literal |
Z' |
Start of a null-terminated alphanumeric literal |
G" |
Start of a double-byte character literal |
G' |
Start of a double-byte character literal |
N" |
Start of a national literal |
N' |
Start of a national literal |
NC" |
Start of a national literal |
NC' |
Start of a national literal |
NX" |
Start of a national hexadecimal literal |
NX' |
Start of a national hexadecimal literal |
== |
Pseudo-text separator |
Rules for Separators
Descriptions of the rules of each separator are as follows:
|
In the following descriptions, {, } (braces) enclose a separator and b represents a blank. Multiple blanks can be used where a space is used as a separator or as part of a separator. |
-
Space {b}
A space can be used by immediately preceding or following an arbitrary separator except in the following cases.
-
A separator that indicates the start of pseudo-text
-
A space that is enclosed with quotation marks is regarded as part of an alphanumeric literal. It is not treated as a separator.
-
-
Period {.b} and Comma {,b}
-
Periods (.) and commas (,) that are used as separators consist of a combination of one separator and a following space.
-
A period is used to indicate the end of a sentence as shown in the format.
-
In the identification division, each paragraph must end with a period (.).
-
In the environment division, each file control item in the SPECIAL-NAMES and I-O-CONTROL paragraphs must end with a period.
-
In the data division, each FD, SD, and data description entry must end with a period.
-
In the procedure division, statements and operands in a statement can be delimited by a comma and a semicolon. Each procedure must end with a period.
-
-
-
Parentheses { ( } …{ ) }
-
The number of left and the right parentheses must be the same except in pseudo-text.
-
Parentheses delimit subscriptors, arguments of a function, reference-modifiers, arithmetic expressions, or conditions.
-
-
Colon { : }
-
A colon is used as a separator.
-
-
Double quotation mark { " } … { " }
-
A double quotation mark that indicates the start of a quotation must be immediately preceded by a space or a left parenthesis.
-
A double quotation mark that indicates the end of a quotation must be immediately followed by a separator (a space, comma, semicolon, period, right parenthesis, or pseudo-text separator).
-
The number of quotation marks that indicate the start and the end of a quotation must be the same. They are used to delimit alphanumeric literals. If a literal spans multiple lines, the relevant rules apply.
-
-
Single quotation mark { ' } … { ' }
-
An opening single quotation mark must be immediately preceded by a space or a left parenthesis.
-
A closing single quotation mark must be immediately followed by a separator (a space, comma, semicolon, period, right parenthesis, or pseudo-text separator).
-
The number of opening and closing quotation marks must be the same. They are used to delimit alphanumeric literals. If a literal spans multiple lines, the relevant rules apply.
-
-
Null-terminated literal separator { Z" } … { " } , { Z' } … { ' }
-
A separator that indicates the start of a literal must be immediately preceded by a space or a left parenthesis.
-
A separator that indicates the end must be followed by another separator (a space, comma, semicolon, period, right parenthesis, or pseudo-text separator).
-
-
Double-byte literal separator { G" } … { " } , { G' } … { ' } , { N" } … { " } , { N' } … { ' }
-
A separator that indicates the start of a literal must be immediately preceded by a space or a left parenthesis.
-
A separator that indicates the end must be followed by another separator (a space, comma, semicolon, period, right parenthesis, or pseudo-text separator).
-
-
National literal separator { N" } … { " } , { N' } … { ' } , { NC" } … { " } , { NC' } … { ' } , { NX" } … { " } , { NX' } … { ' }
-
A separator that indicates the start of a literal must be immediately preceded by a space or a left parenthesis.
-
A separator that indicates the end must be followed by another separator (a space, comma, semicolon, period, right parenthesis, or pseudo-text separator).
-
-
Pseudo-text separator {b==} … {==b}
-
A starting separator must be immediately preceded by a space.
-
An ending separator must be followed by another separator (a space, comma, semicolon, or period). The number of opening and closing pseudo-text separators must be the same. These delimit pseudo-texts.
-
|
Any punctuation character that is included in a PICTURE string, a comment, or an alphanumeric literal is not treated as a punctuation character. It is regarded as a part of a string or a literal. |
4. Section and Paragraphs
A program can be defined with sections and paragraphs. Sections and paragraphs are divided into sentences, statements, and entries. Sentences are subdivided into statements and phrases, and statements are subdivided into phrases. Entries are subdivided into clauses and phrases.
Hierarchical structures for each division are as follows:
-
Identification division
Paragraph |-- Entries |-- Clauses -
Environment division
Sections |-- Paragraph |-- Entries |-- Clauses |-- Phrases -
Data division
Sections |-- Entries |-- Clauses |-- Phrases -
Procedure division
Sections |-- Paragraphs |-- Sentences |-- Statements |-- Phrases
Descriptions for each item in a hierarchical structure are as follows:
| Item | Description |
|---|---|
Entries |
An entry is a series of clauses that ends with a period. An entry can be specified in the identification, environment, and data divisions. |
Clauses |
A clause is an ordered set of COBOL strings that specifies properties of an entry. A clause can be specified in the identification, environment, and data divisions. |
Sentences |
A sentence is a series of one or more statements that ends with a period. A sentence can be specified in the procedure division. |
Statements |
A statement specifies an action to be handled by a program. A statement can be specified in the procedure division. |
Phrases |
Each clause and statement in a program can be subdivided into phrases. |
5. Source Text Format
COBOL source consists of the following areas with a single line of 72 columns.
-
Sequence number area
-
The sequence number area includes the first through sixth columns.
-
The sequence number area is used to label source text columns with the characters that are included in the character sets that the computer supports.
-
-
Indicator area
-
The indicator area is the seventh column.
-
The indicator area is used for the following.
-
The occurrence of consecutive COBOL words and literals
-
Comment handling
-
Debug lines
-
-
6. Scope of Names
A user-defined word is the name defined in a data resource or COBOL program element. A file, a data item, and a record are examples of resources that can define a name. A program and a paragraph are examples of resources that can define a name for a COBOL program element.
A defined name is directly or indirectly used by each source program. A single name can be used by more than one resource or program element. In this case, a name that is referenced by a program element is the name defined in the program that uses the corresponding name, and does not indicate a name defined in another source program.
-
The following user-defined words can be referenced only by statements or entries in the source program that declares the user-defined words.
-
Paragraph names
-
Section names
-
-
The following user-defined words can be referenced by any COBOL programs.
-
Library names
-
Text names
-
-
The following user-defined words are defined in the configuration section and can be referenced by a source program that includes the corresponding configuration section.
-
alphabet-name
-
condition-name
-
mnemonic-name
-
symbolic-character
-
-
The following user-defined words, not included in the previous lists, follow its own reference rule.
User-defined Word Rule Program name
Varies according to the COMMON attribute and whether it is nested or not.
File name
Has a global attribute if the global attribute is specified in a file descriptor.
Record, data, or condition name
Has a global attribute if the global attribute is specified in the name.
Index name
When a data item with a global attribute is referenced using an index, the index also has the global attribute. The scope of the index name is the same as that of the data name of the table referenced with the index. Therefore, the same rule for data name is applied.
-
If program A directly includes program B, each condition, data, file, and record name that is defined in program A and program B can be declared using a user-defined word.
When a name that exists in both program A and program B is referenced by program B, the name that is referenced is determined as follows:
-
The name is first searched in the declarations in program B.
-
If not found, the name is searched in the global declarations in program A.
-
When more than one name is selected, two or more names cannot be selected from program B. If zero or one name is selected from program B, the following rules are applied.
-
If the name is defined in program B, the name is referenced.
-
If the name is not defined in program B, the name to be referenced is decided as follows:
-
If the name is globally declared in program A, the name defined in program A is referenced.
-
If the name is globally declared in an upper program of program A, the name defined in the program is referenced. If there are further container programs, this rule is applied until a valid name is found.
-
-
7. Referencing
User-defined names in a COBOL program and names defined for each resource must be unique. The following sections describe methods for unique reference and how to refer to each resource.
7.1. Qualification
A name that exists in multiple levels of a hierarchy can be referenced uniquely by specifying one or more names for the higher level. The name for the higher level is a qualifier, and the process that makes the name unique is called qualification.
In the data division, qualification is used for any data name that is preceded by a level number. If a name becomes unique after qualification, two or more data names cannot be defined in one group if one of them is never referenced.
The rules for qualification are as follows:
-
A name preceded by the level number 01 is the top level. The following levels are decided by the order of names from 02 to 49.
-
A section name is the top level name for a paragraph name. Each entry’s top level name cannot be qualified and must be unique.
-
A subscriptor or index name and a condition variable can be referenced uniquely through qualification. A condition name can be qualified using a condition variable name.
-
Regardless of qualification, a data name cannot be the same as a procedure name.
-
Qualification is specified by adding a qualifier with IN or OF to a data name, a condition name, or a paragraph name. IN and OF are equivalent.
When more than one file has records that include the field EMPLOYEE-NO, the following example qualified only one file with the record MASTER-RECORD.
EMPLOYEE-NO OF MASTER-RECORD
Note the following about qualification.
-
A qualifier must be in a higher level than the name to be qualified.
-
When qualification needs to be used for multiple levels, qualification for the lower level is performed first.
-
If a single data name or condition name is defined for more than one data item, the data name or condition name must be qualified to be referenced by the procedure division, the environment division, or the data division. But, the data name or condition name cannot be qualified in the REDEFINE clause.
-
More than one paragraph name cannot be used in one section. If a paragraph name is qualified with a section name, the word SECTION cannot be used. When a paragraph name is referenced by the same section, it does not need to be qualified.
-
Qualification can be used even when it is not needed. If there are multiple combinations of qualifiers, any of them can be used. However, a combination of qualifiers for a data name cannot be a part of a combination for another data name.
7.2. Subscripting
Subscripting is the method used to reference individual table item using a subscriptor.
A subscriptor is an integer, a data name, or an arithmetic expression that contains a data name and the "+" or "-" operator. If a data name is used, it must be an integer. A subscriptor is separated by parentheses ((, )). Data used as a subscriptor can have a positive sign (+). The minimum value of a subscriptor is 1, which indicates the first item in a list or a table. The maximum value of a subscriptor is the maximum value specified in the OCCURS clause.
A combination of subscriptors for identifying a table item is enclosed with parentheses and preceded by the data name of the table. When more than one subscriptor is specified, the subscriptors for the higher levels are used first. If the outermost and innermost tables are regarded as the major and minor tables respectively for nested multiple dimension tables, subscriptors are specified in the order of major, middle, and minor (from the left to the right).
The following example defines TABLE-THREE.
01 TABLE-THREE.
05 ELEMENT-ONE OCCURS 3 TIMES.
10 ELEMENT-TWO OCCURS 3 TIMES.
15 ELEMENT-THREE OCCURS 2 TIMES PIC X(8).
The following example shows a valid reference to TABLE-THREE with a subscriptor.
ELEMENT-THREE (2 2 1)
The following figure shows the subscripting format.
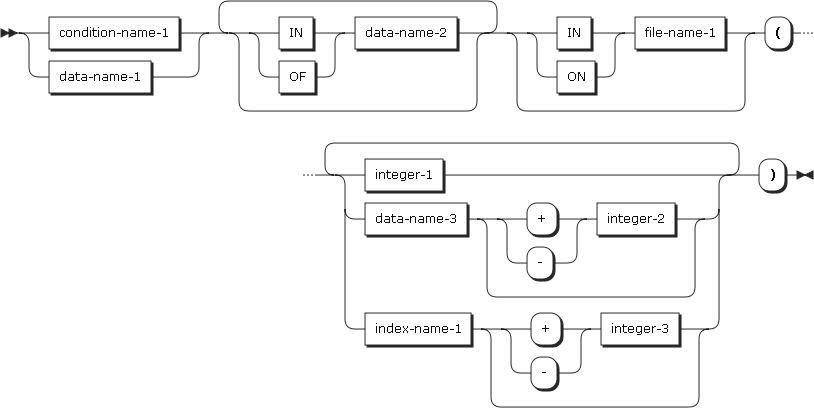
| Item | Description |
|---|---|
condition-name-1 |
The conditional variable for condition-name-1 must include an OCCURS clause or must be subordinate to a data description entry that includes an OCCURS clause. |
data-name-1 |
Must include an OCCURS clause or must be subordinate to a data description entry that includes an OCCURS clause. |
data-name-2, file-name-1 |
Must be a data item or a record that includes data-name-1. |
integer-1 |
A positive sign can be added. |
data-name-3 |
Must be a basic numeric item that represents an integer. data-name-3 can be qualified. |
index-name-1 |
Exists in the hierarchy of a table to be referenced and represents a data item in which an INDEXED BY clause is specified. |
integer-2, integer-3 |
A signed integer is invalid. |
A subscriptor must be specified for each table item reference except for the following cases.
-
It is a subject of a SEARCH statement
-
It is in a REDEFINES clause
-
The KEY is a phrase of an OCCURS clause
Subscripting for Each Subscriptor
The following describes how to use subscripting for each subscriptor.
-
Subscripting using data names
When a data name is used to represent a subscriptor, it can be used to reference items in other tables. The tables do not need to have the same number of items. The same data name can be specified as a subscriptor that indicates one item or as two or more subscriptors that indicate different items. A data name can be qualified, but it cannot be used as an index. A subscriptor cannot be added to a data name.
The following example shows a reference with a subscriptor which is valid for TABLE-THREE. It is assumed that SUB1, SUB2, and SUB3 are subordinate to SUBSCRIPT-ITEM.
ELEMENT-THREE (SUB1 SUB2 SUB3) ELEMENT-THREE IN TABLE-THREE (SUB1 OF SUBSCRIPTOR-ITEM, SUB2 OF SUBSCRIPTOR-ITEM, SUB3 OF SUBSCRIPTOR-ITEM ) -
Subscripting using index names (indexing)
Individual elements in data lists or table items that have the same type can be referenced using indexing.
An index can be specified with the INDEXED BY clause in the corresponding data item when a table is defined. A name specified using the INDEXED BY clause is called an index name. It is used to reference a defined index. The value of an index represents the occurrence number of the corresponding table or an element in the table.
An index name must be initialized before being used. Prior to initialization, the value is undefined.
An index name can be initialized with the following statements.
-
A PERFORM statement with the VARYING phrase
-
A SEARCH statement with the ALL phrase
-
A SET statement
An index value saved in an index name plays the same role as a subscriptor. A subscriptor must be a numeric data item or an integer, but an index is not regarded as a numeric value because it is a data item that represents the occurrence number of a table element with a special type.
-
-
Relative Subscripting
Relative subscripting uses an arithmetic expression as a subscriptor. The expression consists of a data name or an index name, the "+" or "-" operator, and a positive or unsigned integer literal. The "+" and "-" operators must be preceded and followed by a space. The value of an arithmetic expression defined as a subscriptor must be valid for a table item.
Relative subscripting does not cause a program to modify the value of an index.
7.3. Reference Modification
Reference modification defines a data item by specifying the start line, which is the leftmost character’s position, and by optionally specifying the length of the data item.
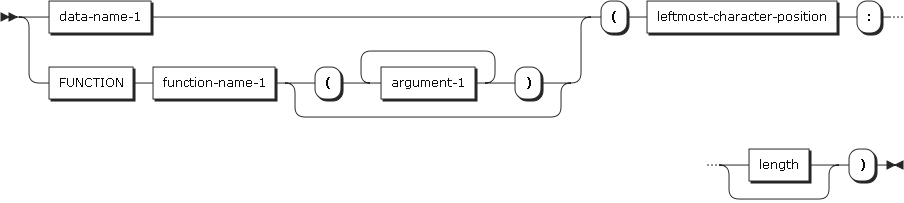
| Item | Description |
|---|---|
data-name-1 |
A data item that is specified explicitly or implicitly with USAGE DISPLAY. data-name-1 can be qualified and subscripted. When data-name-1 references an alphanumeric data item, it points to the position of the data item. The order of the referenced data item’s leftmost character is 1, and it increases by one from the leftmost position to the rightmost position. If the SIGN IS SEPARATE clause is specified in the data description entry, the order must be determined for signs. |
function-name-1 |
Specifies an alphanumeric item. |
leftmost-character-position |
Must be an arithmetic expression. The start position of the leftmost character is a positive integer less than the number of characters in the data item referenced by data-name-1. |
length |
Must be an arithmetic expression. The result of the arithmetic expression must be a positive nonzero integer. The sum of the position of the leftmost character and length minus 1 must be less than or equal to the number of characters in data-name-1. If the length is omitted, it defaults to the number of character in data-name-1. |
Reference modification creates a data item that is a subset of the data items that are referenced by data-name-1. The data item is selected from the data items to be referenced as follows:
-
A numeric value can be obtained by evaluating the position of the leftmost character.
-
After the start position has been determined, the length can be calculated. The length cannot exceed the length of the data item to be referenced. If the length is omitted, it is assumed that all characters starting from the specified position to the end of the data item are specified.
|
The validity of the result of the evaluation is not checked. The value is not guaranteed to be within the limits described in the rules. |
A data item to be referenced is evaluated as follows:
-
If a subscriptor is specified in the data item, it is evaluated before reference modification is applied. If ALL is specified for the subscriptor, the given reference modification is applied to all specified items.
-
If a function is referenced, it is evaluated first and then reference modification is applied.
The following example moves the first 10 characters of the data item referenced by WHOLE-NAME to the data item referenced by FIRST-NAME.
77 WHOLE-NAME PIC X(25). 77 FIRST-NAME PIC X(10). ... MOVE WHOLE-NAME(1:10) TO FIRST-NAME
The following example moves the last 15 characters of the data item referenced by WHOLE-NAME to the data item referenced by LAST-NAME.
77 WHOLE-NAME PIC X(25). 77 LAST-NAME PIC X(15). ... MOVE WHOLE-NAME(11:) TO LAST-NAME
The following example moves the fourth and fifth characters of the third item in TAB to the variable SUFFIX.
01 TABLE-1.
02 TAB OCCURS 10 TIMES PICTURE X(5).
77 SUFFIX PICTURE X(2).
...
MOVE TAB OF TABLE-1 (3) (4:2) TO SUFFIX
7.4. Referencing Data Division Names
The following describes how to reference a name in the data division.
Simple Data Reference
Simple data reference is the most basic method for referencing data items in a COBOL program. This uses simple data-name-1 without qualification, subscripting, or reference modification. Simple data reference is used to reference a single elementary or group item.
Simple data items can be referenced with the following format.
| Item | Description |
|---|---|
data-name-1 |
A data description entry. data-name-1 must be unique in a program. |
Identifiers
An identifier is a combination of a string and a functional identifier used to reference a data item.
Data items can be referenced with the following format.
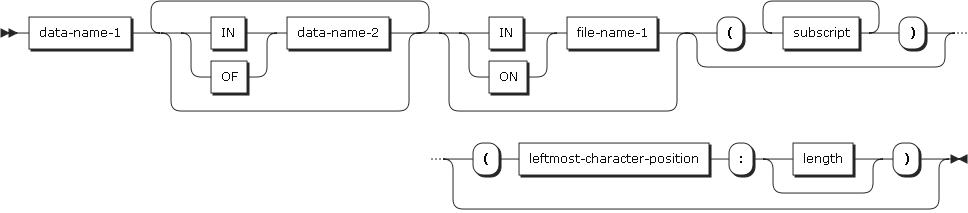
| Item | Description |
|---|---|
data-name-1, data-name-2 |
Specifies a record name. |
file-name-1 |
Must be defined in a FD or SD entry in the data division. file-name-1 must be unique in a program. |

| Item | Description |
|---|---|
data-name-1, data-name-2 |
Specifies a record name. |
condition-name-1 |
Can be referenced by statements and entries in a program that includes the configuration section or in a program that is included in the program. |
file-name-1 |
Must be defined in a FD or SD entry in the data division. file-name-1 must be unique in a program. |
Note the following when referencing data items.
-
If a data name cannot be uniquely determined through qualification, it must not be duplicated.
-
Data specified as the subject of an entry whose level number is 01 and that includes the EXTERNAL clause must not be the same as another data description entry that includes the EXTERNAL clause.
-
A data description entry for two data items for which the same data name is specified must not include the GLOBAL clause. Data division names that are explicitly referenced must be unique or made unique by qualification. Unreferenced data items do not need to be unique. The highest level in a data hierarchy (level indicator FD or SD, or level number 01) must be unique if referenced.
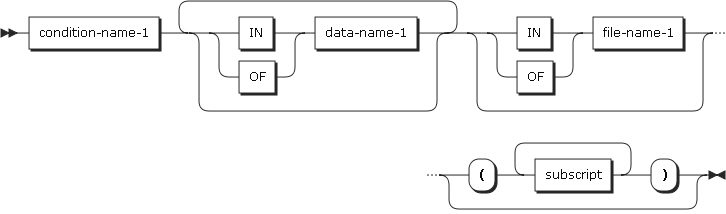
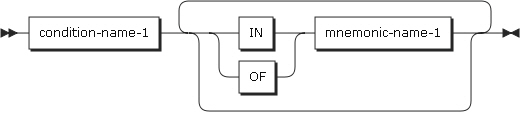
Condition-name
Condition-name must be uniquely specified in a program or made unique by qualification or subscripting. When a condition name is qualified to be unique, a relevant condition name can be used as the first qualifier.
A condition name must be made unique for qualification using a data name or a condition variable name defined in a data group related to the condition variable. If an index or subscripting is necessary in order to reference a condition variable, the same combination of an index and subscripting is used when a condition name is referenced.
| Item | Description |
|---|---|
condition-name-1 |
Can be referenced by statements and entries in the program that include the definition or in a program included in the program. |
data-name-1 |
Specifies a record name. |
file-name-1 |
Must be defined in a FD or SD entry in the data division. file-name-1 must be unique in a program. |
mnemonic-name-1 |
For information about valid values for mnemonic-name-1, refer to the SPECIAL-NAMES paragraph. |
7.5. Referencing Procedure Division Names
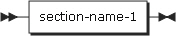
A procedure division name that is explicitly referenced in a program must be unique in a section.

| Item | Description |
|---|---|
section-name-1 |
Must be referenced with a unique qualifier that can be used for the paragraph. If paragraph-name-1 is explicitly referenced, the corresponding paragraph name cannot be duplicated in a section. |
paragraph-name-1 |
If paragraph-name-1 is qualified by section-name-1, the word SECTION cannot be included. If it is referenced in the section in which the corresponding paragraph is included, it does not need to be qualified. paragraph-name-1 or section-name-1 in a program cannot be referenced by another program. |
7.6. Referencing Function Identifiers
A function ID is a sequence of strings and separators that reference a data item created as the result of a function.

| Item | Description |
|---|---|
FUNCTION |
Includes the word FUNCTION. |
argument-1 |
Specifies an ID, literal (except figurative constants), or arithmetic expression. |
function-name-1 |
Must be one of the intrinsic function names. |
reference-modifier |
Can be specified only for alphanumeric functions. |
A function ID can be used as a receiving operand in a statement, but note the following.
-
A numeric function cannot be specified instead of an integer function, except for some numeric functions in which an integer value can be referenced.
-
A function that references integers and numbers can be used for arithmetic expressions. If another function ID can be specified when a function is used, the parentheses followed by the function ID specified as the argument mean that the function ID is the argument of the outer function.
-
Functions (such as RANDOM) for which an argument does not need to be specified require more attention to correctly understand.
In the following example, A is regarded as an argument of the RANDOM function.
FUNCTION MAX ( FUNCTION RANDOM (A) B )
The following examples set A as an argument of the MAX function.
FUNCTION MAX (( FUNCTION RANDOM () A) B )
Or
FUNCTION MAX ( (FUNCTION RANDOM) (A) B )
Or
FUNCTION MAX ( FUNCTION RANDOM A B )
The general rule for referencing using a function ID is as follows:
-
A value that is referenced using a function ID is a temporary data item that is determined when referenced.
When an intrinsic function is specified, a temporary data item is the basic data item, and details are based on the function type. For more information about the definition, refer to Intrinsic Functions.
-
When a function is referenced, its arguments are used from left to right. A function can be specified as an argument for another function that has a function argument or includes another function, which allows for recursive calls.
7.7. Explicit and Implicit Specification
An element in a COBOL program can be explicitly and implicitly specified as follows:
-
Explicit and Implicit Procedure Division References
Data can be explicitly and implicitly referenced by a statement in the procedure division of a COBOL program.
Classification Description Explicit reference
Refers to directly describing a name to be referenced in a statement of the procedure division or to copying the name using the COPY or REPLACE statement.
Implicit reference
Refers to referencing a data item without directly describing the name to be referenced in a statement of the procedure division. For example, if the VARYING, AFTER, or UNTIL clause is specified in the relevant control phrase when the PERFORM statement is used, a data item is implicitly referenced by a specified index or literal. In this case, the data item is determined and referenced when the relevant statement is executed.
-
Explicit and Implicit Transfers of Control
In the procedure division, a program is controlled according to the order that statements are described except when the control is explicitly moved or there is no next executable statement. This is called implicit transfer of control.
Control can be implicitly transferred in the following ways.
-
Control is implicitly returned when the last statement of a procedure is completely executed under the control of another COBOL statement. Examples of COBOL statements that controls a procedure’s execution are MERGE, PERFORM, SORT, and USE. When a paragraph is executed under the control of a PERFORM statement that can be repeatedly executed or a paragraph is the first paragraph in the range of the PERFORM statement, control is implicitly transferred between the control mechanism related to the PERFORM statement and the first statement in the paragraph whenever the paragraph is executed.
-
When a SORT or MERGE statement is executed, control is implicitly transferred to the I/O related definition.
-
When a COBOL statement that declares procedures is executed, control is implicitly transferred to the corresponding procedure.
-
When procedure declaration is completed, control is implicitly transferred to the control mechanism related to the statement that executes the corresponding procedure declaration.
Control can be explicitly transferred by executing a statement that branches to a procedure, program call, or condition statement. For more details, refer to Procedure Division - Statement.
The term next executable statement refers to the next COBOL statement that is executed after control is transferred according to the previous rule. In the following cases, there is no next executable statement.
-
When the program does not include the procedure division.
-
When following the last statement in a declarative section and the paragraph that includes the statement is not executed under the control of another COBOL statement.
-
When following the last statement in a program and the paragraph that includes the statement is not executed under the control of another COBOL statement.
-
When the statement is in the range of a PERFORM statement executed in another section and the last statement in a declarative section is not the last statement of the procedure that is defined as the exit of the active PERFORM statement.
-
When following a STOP RUN or EXIT PROGRAM statement that transfers control outside the COBOL program.
-
When following a GOBACK statement that transfers control outside the COBOL program.
-
When encountering END PROGRAM.
When there is no next executable statement and control is not transferred outside the COBOL program, the program flow of control cannot be predicted unless EXIT PROGRAM is implicitly executed in a calling program under the control of a CALL statement.
-
8. Program Structure
A COBOL source program is a syntactically correct set of COBOL statements.
COBOL source program statements, entries, and sections consist of the following four divisions except for COPY and REPLACE statements and END PROGRAM.
-
Identification division
-
Environment division
-
Data division
-
Procedure division
The following figure shows the format of entries and statements that compose a COBOL program, the unit of compilation.
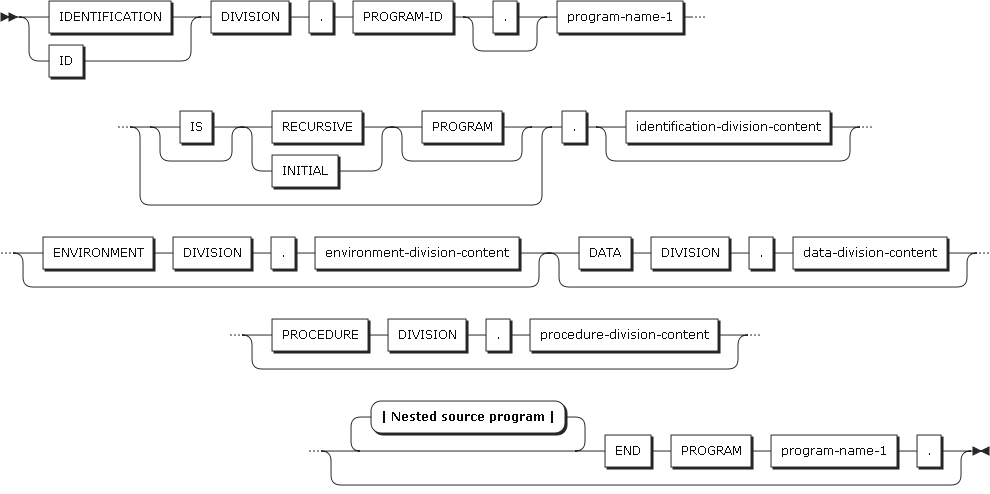
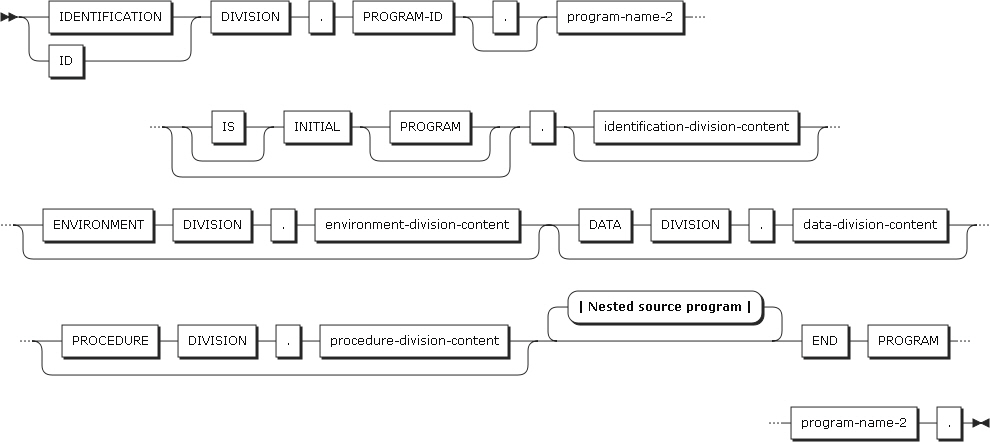
END PROGRAM
A COBOL source program ends at the position where END PROGRAM is specified. If there is no nested program, a COBOL program ends at the position where the source program ends.
-
END PROGRAM program-name
-
END PROGRAM separates programs.
-
program-name must be the same as program-name, which is defined in the identification division.
-
END PROGRAM does not need to be specified for a program that does not include another program and is exclusively executed and ended.
-
Nested Programs
A COBOL program can include another COBOL program. The included program can also include another program. The included programs are called nested programs. A nested program can be directly or indirectly included in another program.
For example, if program B is only included in program A, it is directly included in program A. If program B is included in program A and another program is included in program B, the third program is indirectly included in program A.
In the following example, Outer-program directly includes the Inner-1 program.
The Inner-1 program directly includes the Inner-1a program, and Outer-program indirectly includes the Inner-1a program.
ID division.
Program-id. Outer-program.
Procedure division.
Call "Inner-1".
Stop run.
ID division.
Program-id. Inner-1.
....
Call Inner-1a.
Stop run.
ID division.
Program-id. Inner-1a.
....
End Inner-1a.
End Inner-1.
End Outer-program.
The following example shows a more complex program structure with directly and indirectly nested programs.
Program X is the outermost program that directly includes program X1 and X2 and indirectly includes program X11 and X12.
|------- ID division. | Program-id. X. | Procedure division. | Display "I'm in X" | Call "X1" | Call "X2" | Stop run. | | |----- ID division. | | Program-id. X1. | | Procedure division. | | Display "I'm in X1" | | Call "X11" | | Call "X12" | | Exit Program. | | | | |--- ID division. | | | Program-id. X11. | | | Procedure division. | | | Display "I'm in X11" | | | Exit Program. | | |--- End Program X11. | | | | |---- ID division. | | | Program-id. X12. | | | Procedure division. | | | Display "I'm in X12" | | | Exit Program. | | |--- End Program X12. | |----- End Program X1 | | | ---- ID division. | | Program-id. X2. | | Procedure division. | | Display "I'm in X2" | | Exit Program. | | ---- End Program X2. |------- End Program X.
Rules for Program Names
A program name is defined in the PROGRAM-ID paragraph of the identification division.
Rules for the scope of program names are as follows:
-
The name of a program that is included in another program without the COMMON attribute can be referenced only by a statement in a program that calls the program.
-
The name of a program that is included in another program having the COMMON attribute can be referenced by the statement in a program that directly or indirectly calls the program.
-
The name of a program that is not included in another program can be referenced by the statement of other programs in an execution unit. However, a program that is directly or indirectly included in the program cannot reference the name.
The following example shows that ProgA includes ProgB and ProgC.
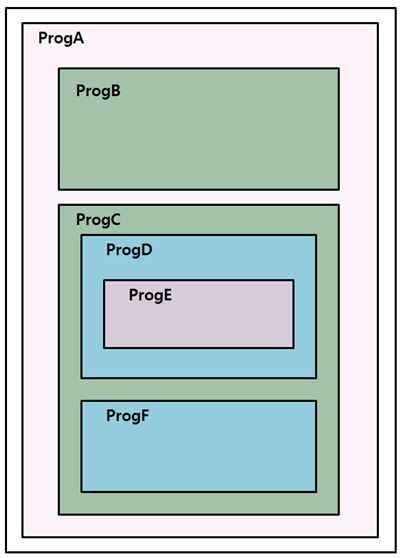
ProgC includes ProgD and ProgF, and ProgD includes ProgE. If ProgD does not have the COMMON attribute, it can only be referenced by ProgC, which directly includes ProgD.
If ProgD has the COMMON attribute, it can be referenced by ProgC, which directly includes ProgD, and ProgF, which is directly included in ProgC. ProgE, which is directly included in ProgD, can be referenced by ProgC, but cannot be referenced by ProgF. ProgD cannot be referenced by ProgA or ProgB.