データセット・マイグレーション
本章では、データセットのマイグレーション方法について説明します。
1. 概要
データセットは、データ・レコードの論理的な集合体です。またレコードは、アプリケーションで使用される情報の基本単位です。データセットは大きく非VSAMデータセットとVSAMデータセットに分けられます。
|
データセットに関する詳しい説明は、OpenFrame Base『データセットガイド』を参照してください。 |
-
非VSAMデータセット
以下は、非VSAMデータセットのPDS、GDG、SAMデータセット、ISAMデータセットのマイグレーション方法です。
区分 説明 PDS
PDSは、ディレクトリとメンバーから構成されるデータセットです。PDSそのものは、pdsgenまたはdscreateツールで作成します。そしてPDSの各メンバー・ファイルは、dsmiginツールを使用して文字セットを変換します。
GDG
GDGは、世代(generation)で構成されるデータセットのグループです。GDGそのものは、gdgcreateツールを使用してカタログに登録します。そしてGDSは、SAMデータセットのマイグレーション方法に従って移行します。
SAMデータセット
一般的な非VSAMデータセットであるSAMデータセットは、COBOLコピーブックなどを参照してデータセット変換スキーマを作成した後、dsmiginツールを使用してOpenFrameデータセットにインポートします。
ISAMデータセット
ISAMデータセットはOpenFrameでサポートしており、VSAM KSDSに代替して使用することもできます。
-
VSAMデータセット
以下は、VSAMデータセットのKSDS、ESDS、RRDS、LDSのマイグレーション方法です。
区分 説明 KSDS
KSDSは、idcamsツールのDEFINE CLUSTERコマンドでOpenFrame VSAMデータセットを定義します。そして、dsmiginツールのRECATALOGオプションを使用してデータをVSAMデータセットにインポートします。
ESDS
KSDSのマイグレーション方法と同じです。
RRDS
RRDSは、レコードごとに番号が与えられます。もしデータセットの中に抜けているレコード番号がない場合は、VSAM KSDSと同じ方法で移行できますが、抜けているレコード番号がある場合は、別のRRDSインポート・プログラムを作成して移行する必要があります。
LDS
現在VSAM LDSはOpenFrameでサポートしていません。VSAM LDSへのサポートを要望される場合は、TmaxSoftのテクニカル・サポート・チームにお問い合わせください。
メインフレームのデータセットをOpenFrameにマイグレーションする方法は、以下に示したように、データセットの種類によって異なります。
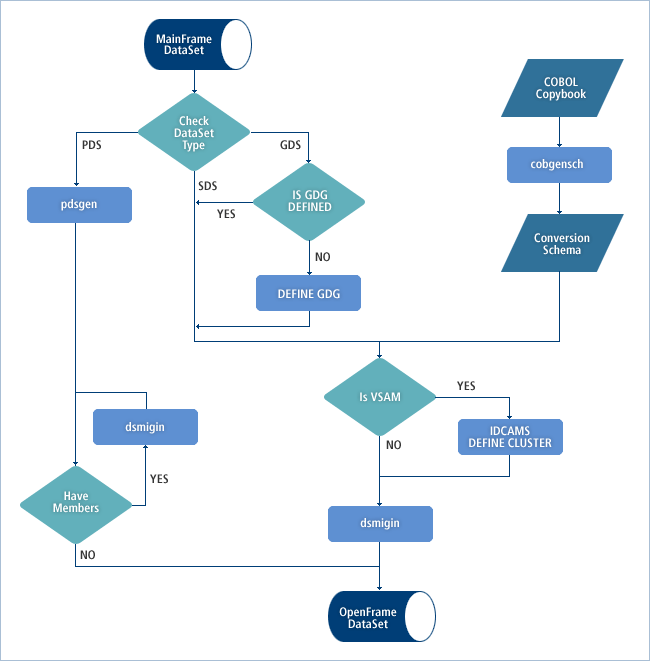
2. 非VSAMデータセットのマイグレーション
OpenFrameにおける一般的な非VSAMデータセットのマイグレーション・プロセスは以下のとおりです。
-
マイグレーション対象の確認とソース・ファイルのダウンロード
-
データセット・レイアウトの分析
-
データセット変換スキーマ
-
ターゲット・データセットのマイグレーション
-
PDSデータセットのマイグレーション
-
GDG BASEの定義
-
可変長データセットのマイグレーション
-
データセット・マイグレーションの検証
2.1. マイグレーション対象の確認とソース・ファイルのダウンロード
マイグレーション・プロジェクトにおいて、マイグレーションの対象となるデータセットの一覧を作成することは、プロジェクトを成功させるために極めて重要な作業です。JCLやプロシージャを分析して一覧を作成することもできますが、大規模のマイグレーション・プロジェクトではOpenFrameへ移行するにあたって不要となったり、SMSポリシーやセキュリティー・ポリシーと絡んでデータセットの名前が変更されたりする場合も往々あるので、顧客企業に正確な一覧を要求することが必要です。
マイグレーションするデータセットが決まったら、ホスト(運用中のメインフレーム)で使用しているデータセットのソース・ファイルをダウンロードします。ただし、ホストからデータセットをASCII形式でダウンロードすると、特殊文字、SOSI、2バイト文字が正常に変換されない問題が生じるので、ホストで使用しているEBCDIC形式のままダウンロードします。
2.2. データセット・レイアウトの分析
データセットのレイアウト分析は、データセットのマイグレーションを正常に行うために最も重要な作業です。現在運用中のデータセットの場合は、COBOLコピーブックやデータセット・スキーマを調査してデータセット・レイアウト情報を抽出できますが、古いデータセットの場合は、データセットを直接閲覧しない限り、レイアウトを正確に分析することが難しいです。
一般的には、顧客企業がデータセットのレイアウト情報を管理しているので、顧客企業からレイアウト情報の提供を受け、データセットのマイグレーションを行います。
通常、1つのデータセットの全レコードには1つのレイアウトが適用されます。しかし、一部のデータセットは、レコードによって異なるレイアウトが適用される場合があります。たとえば、COBOLの再定義文(REDEFINE)によって複数のレイアウトが生成されたり、データセットのレコードが可変長だったりする場合です。
2.3. データセット変換スキーマ
データセットのレイアウト情報は、顧客企業側の運用上の利便性によって様々な形式で提供されます。その多様なレイアウトをすべてサポートすることは困難なことであるため、標準COBOLコピーブック形式に変換して使用します。
メインフレームでデータセットを処理するアプリケーション・プログラムはCOBOLで作成するのが一般的なので、ほとんどの場合は既存のCOBOLコピーブックをそのまま使用できます。COBOLコピーブック形式のレコード・レイアウト情報が存在しない場合は、別の形式で定義されているレコード・レイアウト情報をCOBOLコピーブック形式に書き直す必要があります。メインフレームでCOBOLコピーブック形式以外のレコード・レイアウトを定義する方法は、思想的にCOBOLコピーブックで定義する方法と似ているため、これは難しい作業ではありません。
|
追加で提供するndbgenschツールは、AIM DBのマイグレーションの利便性のため、COBOLコピーブックではなく、AIM DBスキーマ情報を参照して、AIM DBのアンロード・データセットのマイグレーションに必要なスキーマを作成します。このツールの詳細については、データベース・マイグレーションを参照してください。 |
<XTBC106.cpy>
01 I1.
05 KYAKUMEI-KN PIC X(0018).
05 BTN-CD PIC X(0004).
05 KYAKU-NO PIC X(0007).
05 ATUKAI-CD PIC X(0003).
05 MDY-CD PIC X(0003).
05 YAKU-YMD PIC S9(0009) COMP-3.
05 UKEW-YMD PIC S9(0009) COMP-3.
05 KOYU-MEI-CD PIC S9(0005) COMP-3.
05 KAISU PIC S9(0005) COMP-3.
05 GO .
10 GO-1 PIC X(0001).
10 GO-2 PIC X(0001).
10 GO-3 PIC X(0001).
データセットのレイアウト情報を示すCOBOLコピーブック・ファイルの<XTBC106.cpy>が存在する場合、cobgenschツールを使用して、データセット変換スキーマ・ファイルを作成することができます。
下記例では、[-r]オプションを使ってレコード長を54に指定していますが、このように設定する場合、COBOLコピーブック・ファイルの各フィールドの長さを足した実際のレコード長と一致するかを確認します。
$ cobgensch XTBC106.cpy –r 54以下は、上記のサンプル・ファイルの<XTBC106.cpy>に対し、cobgenschツールを実行して作成したデータセット変換スキーマ・ファイルの内容です。
COBOLコピーブックのPIC文で構成された各構文が、データセット変換スキーマ形式に変換されていることが確認できます。上記で使われたPIC X文は、EBCDIC文字をASCII文字に変換するためのEBC_ASCタイプに指定され、PIC S9のCOMP-3文は、PACKEDタイプに指定されていることが分かります。ここでは使用されていませんが、その外に、Zoned Decimal値を表現するZONEDタイプと2バイト文字を表現するGRAPHICタイプがあります。
<XTBC106.conv>
* Schema Version 5.1 L1, 01, I1, NULL, 0, 1, L2, 05, KYAKUMEI-KN, EBC_ASC, 18, 1, L3, 05, BTN-CD, EBC_ASC, 4, 1, L4, 05, KYAKU-NO, EBC_ASC, 7, 1, L5, 05, ATUKAI-CD, EBC_ASC, 3, 1, L6, 05, MDY-CD, EBC_ASC, 3, 1, L7, 05, YAKU-YMD, PACKED, 5, 1, L8, 05, UKEW-YMD, PACKED, 5, 1, L9, 05, KOYU-MEI-CD, PACKED, 3, 1, L10, 05, KAISU, PACKED, 3, 1, L11, 05, GO, NULL, 0, 1, L12, 10, GO-1, EBC_ASC, 1, 1, L13, 10, GO-2, EBC_ASC, 1, 1, L14, 10, GO-3, EBC_ASC, 1, 1, * Condition L0, "\0", ( L1 L2 L3 L4 L5 L6 L7 L8 L9 L10 L11 L12 L13 L14 )
|
スキーマ・ファイルの構造についてルの詳細は、スキーマ・ファイルの構造を参照してください。 |
2.4. ターゲット・データセットのマイグレーション
マイグレーション対象のソース・データセットと変換スキーマ・ファイルが準備できたら、dsmiginツールを使用してデータセットのマイグレーションを行います。dsmiginツールは、各レコード・データのコード変換作業とデータセットのカタログ登録作業などを実行します。
以下は、ソース・ファイルの<XTB.T66.raw>と変換スキーマ・ファイルの<XTB.T66.conv>を基に、dsmiginツールを使用して<XTB.T66>データセットを作成する例です。
$ dsmigin XTB.T66.raw XTB.T66 –s XTB.T66.conv –e JAK –l 800|
dsmiginツールルの詳細については、OpenFrame Base『ツールリファレンスガイド』を参照してください。 |
2.5. PDSのマイグレーション
PDSは、ディレクトリとメンバー・ファイルで構成されるデータセットです。JCL、またはPROCのDSNパラメータに、PDS名と括弧で囲まれたメンバー名を一緒に記述します。
//SYSIN DD DSN=PLNI.EDVR.SYSIN(LNIYY01), // DISP=(SHR,PASS,KEEP)
通常、PDSデータセットは、実行モジュールを管理するライブラリー・データセット、またはJCL、PROC、SYSINなどのファイルを管理するライブラリー・データセットとして使用されます。
OpenFrameにおいて、PDSはUNIXファイル・システムのディレクトリとして管理され、pdsgen 、またはdscreate ツールで作成できます。
以下は、dscreateツールを使用して、TEST.PDSという名前のPDSを作成する例です。
$ dscreate -o PO TEST.PDSPDSを作成するときの注意点は、SYSINタイプのデータセットの場合は、レコード形式を「L」タイプに指定する必要があるということです。Lタイプはメインフレームには存在しない形式です。UNIXプラットフォーム環境に合わせて改行(linefeed)を1つのレコード単位として認識するために、OpenFrameでサポートしている新しいレコード形式です。
実行モジュールを管理するPDSには、コンパイルされた実行モジュールを対応するPDSのディレクトリ・メンバーとして保存します。その他のJCL、PROC、SYSINなどのファイルを管理するために使用されるPDSのメンバー・ファイルは、メインフレームからダウンロードしたEBCDIC形式のソース・ファイルをdsmiginツールで文字セットを変換した後、変換されたファイルを対応するPDSのメンバーとして保存します。
2.6. GDG BASEの定義
GDG BASEは、純粋にカタログ項目であり、gdgcreateツールを使用して作成できます。GDG LIMIT値は、顧客企業から正確な情報の提供を受けて作成してください。
以下は、gdgcreateツールを使用してGDG BASEを定義する例です。
$ gdgcreate -l 255 TEST.GDG01GDG BASEが特定のユーザー・カタログに登録されると、関連するすべてのGDS(GDGグループ内のデータセット)データセットは同じユーザー・カタログに登録されます。GDG BASEを作成せずにGDSデータセットのカタログを行うと、AMS_ERR_GDG_NOT_REGISTERED (-4025)エラーが発生します。
2.7. 可変長データセットのマイグレーション
可変長データセットのマイグレーションは、一般的なデータセットのマイグレーションと同様のプロセスで行います。ただし、データセットのレイアウトを分析して変換スキーマを作成する作業は注意を払って行う必要があります。
可変長データセットの場合、メインフレームからダウンロードしたソース・データセットは下図に示すように、順次ファイルと同じ形式です。ただし、各レコードは4バイトで構成されるRDW(Record Descriptor Word)とその後に続くデータで構成されています。RDWの最初の2バイトには、RDW 4バイトを含むレコード長の情報が含まれており、残りの2バイトは0で構成されています。このようなRDWのレコード情報を利用して、レコードの先頭と末尾を区分することができます。

可変長データセットも固定長データセットと同様に、データセットのレイアウトをCOBOLコピーブック形式にまとめて、それをcobgenschツールを使用して変換スキーマを作成します。ただし、プロジェクトの状況によっては、COBOLコピーブックの形式でまとめる段階を省いて、以下のような変換スキーマ・ファイルを直接作成して使用する場合もあります。
* Schema Version 5.1 L1, 01, V-REC, NULL, 0, 1, L2, 05, REC-KEY, EBC_ASC, 8, 1, L3, 05, ODO-LEN, COPY, 2, 1, L4, 05, ODO-FLD, NULL, 0, 4000, ODO-LEN L5, 07, ODO-DAT, EBC_ASC, 1, 1, * Condition L0, "\0", ( L1 L2 L3 L4 L5 )
スキーマ・ファイルのODO-FLDが、ODO-LENフィールドの値によって長さが変わる可変長データセットの例です。各レコードの変換作業を行うとき、レコードのODO-LENフィールド値を読み込んで、ODO-FLDの繰り返し回数とデータセットの長さを決めます。ソース・データセットと変換スキーマ・ファイルの準備ができたら、固定長のデータセットと同様に、dsmiginツールを使用してデータセットをマイグレーションします。
以下は、ソース・ファイルの<TEST.VAR.raw>と変換スキーマ・ファイルの<TEST.VAR.conv>を基に、dsmiginツールを使用してデータセット<TEST.VAR>を作成する例です。
$ dsmigin TEST.VAR.raw TEST.VAR –s TEST.VAR.conv –e JP -f VB
3. VSAMデータセットのマイグレーション
OpenFrameにおける一般的なVSAMデータセットのマイグレーション・プロセスは、以下のとおりです。
-
idcamsツールのDEFINE CLUSTERコマンドで、空のVSAMデータセットを定義します。
-
dsmiginツールのRECATALOGオプションで、データをVSAMデータセットにインポートします。
上記の方法でマイグレーションできないデータセットは、別途のデータセット・インポート・プログラムを作成してマイグレーションを行う必要があります。そのようなデータセットには、データセットの中に欠落している番号があるVSAM RRDSデータセットなどがあります。
3.1. VSAMデータセットの定義
VSAMデータセットは、idcamsツールのDEFINE CLUSTERコマンドで定義できます。
以下は、idcamsツールを使用してVSAMデータセットを定義するJCLの例です。
$ idcams DEFINE CLUSTER -n TEST.KSDS -o KS -k 6,0 -l 250,250
|
3.2. VSAMデータセットのインポート
VSAMデータセットをインポートするには、dsmiginツールを使用します。非VSAMデータセットをマイグレーションする方法と違って、idcamsツールのDEFINE CLUSTERコマンドでVSAMデータセットを定義した後、dsmiginツールの-R(Recatalog)オプションを使ってマイグレーションします。
以下は、dsmiginツールを使用して、<XTB.XY1315>という非VSAMデータセットの全レコード・データを<TEST.VSAM.KSDS>のVSAMデータセットにインポートする例です。
$ dsmigin XTB.XY1315 TEST.KSDS –s XTB.XY1315.conv –e JP -R旧バージョンでは、マイグレーション・ツールを使用してVSAMデータセットをインポートする方式をサポートしていなかったため、IDCAMSユーティリティのREPROコマンドを使ってSAM形式の非VSAMデータセットをVSAMデータセットにコピーする方法を取っていました。
|
現在のバージョンでは、dsmiginツールを使用してVSAMデータセットをインポートする方法をサポートしているため、IDCAMSユーティリティを使用するよりも、dsmiginツールを使用することをお勧めします。 |
3.3. データセット・インポート・プログラムの作成
データセットの中に欠落しているレコード番号があるVSAM RRDSのように、dsmiginツールを使用してインポートできないデータセットの場合は、別のインポート・プログラムを作成してデータセットをインポートします。
このようなデータセットのマイグレーション・プロセスは、以下のとおりです。
-
メインフレームからダウンロードしたソース・データセットを、dsmiginツールを使用して文字セットを変換します。
-
idcamsツールのDEFINE CLUSTERコマンドを使用して、空のVSAMデータセットを定義します。
-
データセット・インポート・プログラムを実行してデータセットをインポートします。
データセット・インポート・プログラムは、UNIXプラットフォームで広く使われているC言語を使用して作成します。
|
レコードWRITE関数を呼び出して、個別レコードを正しいキーの位置にインポートするプログラムを作成する方法については、OpenFrame Base『データセットガイド』の「データセットI/O API」を参照してください。 |
4. 静的変換と動的変換
OpenFrameのデータセットの移行方法には、静的変換と動的変換の2つの処理方法があります。データセットを移行する際に、データセットのスキーマ情報を確認して、データセットを静的変換で移行するか動的変換で移行するかを決定します。
4.1. 静的変換と動的変換の比較
-
静的変換
静的変換は、データセットの移行を実行する際、ユーザーが最初に$$COND条件に指定した移行パスから1つを決定し、すべてのレコードをこのパス情報を使用して移行する方法です。
-
動的変換
動的変換は、データセットの移行時に「動的変換テーブル」を管理しながら、ユーザーが指定した$$COND条件をすべてのグループ・アイテムに対してチェックし、その情報を動的変換テーブルに適用して、$$COND条件の分析が完了した後にその情報を使用して移行する方法です。
動的変換はすべてのグループ・アイテムごとに$$COND条件を判断するため、静的変換よりパフォーマンスが低下します。ただし、動的変換のみ使用できる場合のように静的変換を使用できない場合や、動的変換の使用を推奨する場合のように静的変換は使用できるが、動的変換のほうがスキーマ情報を簡単に作成できる場合もあります。その他の場合は、必要に応じて動的変換を使用することができます。
4.2. 動的変換のみ使用できる場合
以下の場合は、動的変換を指定する必要があります。
-
スキーマ・ファイルを作成するコピーブックの$$COND条件を判断するフィールドがOCCURS内にある場合
$$COND条件を判断するフィールドがOCCURS内にある場合に静的変換を使用すると、最初のOCCURSの値によって変換する移行パスを決定しますが、最初のOCCURS以降の条件を判断するフィールドの値が最初のOCCURS値と異なる場合も最初に指定した移行パスで変換処理を行うため、正常に変換処理が行われないことがあります。
01 A OCCURS 10 TIMES. 05 KBN PIC X. 05 B1 PIC N(3) 05 B2 PIC X(6) REDEFINES B1. $$COND : KBN : "1" : B1 $$COND : KBN : !"1" : B2
4.3. 動的変換の使用を推奨する場合
以下の場合には、静的変換を使用することもできますが、動的変換を使用すると、より効率的にスキーマ・ファイルを作成することができます。
-
条件を判断する項目による変換対象項目がLIST形式で存在する場合
$$COND条件を満たし、変換対象項目がLIST形式で存在する場合、静的変換を使用すると、すべての項目を記述しなければなりません。理論的には最低2^n個を作成する必要があります。ただし、動的変換を使用すると、この数を2*nまでに減らすことができます。
03 A OCCURS 10 TIMES. 05 KBN1 PIC X. 05 B1 PIC N(3). 05 B2 PIC X(6) REDEFINES B1. 05 C1 PIC X(5). 05 C2 PIC 9(5) REDEFINES C1. 05 D1 PIC X(5). 05 D2 PIC 9(5) REDEFINES D1<静的変換を使用した$$COND条件の記述>
$COND : KBN1 : X"01" : B1, C1, D1 $COND : KBN1 : X"02" : B1, C1, D2 $COND : KBN1 : X"03" : B1, C2, D1 $COND : KBN1 : X"04" : B1, C2, D2 $COND : KBN1 : X"05" : B2, C1, D1 $COND : KBN1 : X"06" : B2, C1, D2 $COND : KBN1 : X"07" : B2, C2, D1 $COND : KBN1 : X"08" : B2, C2, D2<動的変換を使用した$$COND条件の記述>
$COND : KBN1 : X"01", X”02”, X”03”, X”04” : B1 $COND : KBN1 : X"04", X”05”, X”06”, X”07” : B2 $COND : KBN1 : X"01", X”02”, X”05”, X”06” : C1 $COND : KBN1 : X"03", X”04”, X”07”, X”08” : C2 $COND : KBN1 : X"01", X”03”, X”05”, X”07” : D1 $COND : KBN1 : X"02”, X”04”, X”06”, X”08” : D2
5. データセット・マイグレーションの例
本節では、固定長データセット、可変長データセット、再定義文が使用されるデータセットのマイグレーションの例を紹介します。
5.1. 固定長データセット
以下は、レコード長が16で、3つのレコードを持つメインフレームのEBCDICデータセット<FL.SAMPLE.raw>です。

以下のCOBOLコピーブック<FL.SAMPLE.cpy>の形式の例を通じて、当該データセットのレイアウト情報が把握できます。
<FL.SAMPLE.cpy>
01 FIXEDLENGTH.
05 KEY PIC X(4).
05 TYPE PIC X(6).
05 DATA.
10 EBCDATA PIC X(3).
10 ZONEDDATA PIC S9(3).
データセットのレイアウト情報が確認できたら、以下のようにcobgenschツールを使用して変換スキーマ・ファイルを作成します。
$ cobgensch FL.SAMPLE.cpy
以下は、cobgenschツールの実行結果として生成された変換スキーマ・ファイルです。
<FL.SAMPLE.conv>
* Schema Version 5.1 L1, 01, FIXEDLENGTH, NULL, 0, 1, L2, 05, KEY, EBC_ASC, 4, 1, L3, 05, TYPE, EBC_ASC, 6, 1, L4, 05, DATA, NULL, 0, 1, L5, 10, EBCDATA, EBC_ASC, 3, 1, L6, 10, ZONEDDATA, ZONED, 3, 1, * Condition L0, "\0", ( L1 L2 L3 L4 L5 L6 )
ソース・データセットと変換スキーマ・ファイルが準備できたら、dsmiginツールを使用してデータセットのマイグレーションを行います。
$ dsmigin FL.SAMPLE.raw FL.SAMPLE.TEST –s FL.SAMPLE.conv –l 16マイグレーションが完了したら、dsviewツールを使用して結果を確認します。

5.2. 可変長データセット
以下のような可変長レコードを持つメインフレームのデータセットの例を紹介します。
00000001..AAAAAAAAAAAA 00000002..BBBB 00000003..CCCCCCCCCCCCCCCCCCCCC
メインフレームからダウンロードしたデータセット<VB.SAMPLE.raw>は、以下のように各レコードの先頭に4バイトのRDW(Record Description Word)が含まれています。

上記データセットのレイアウト情報は、以下のとおりコピーブックに表示されます。
<VB.SAMPLE.cpy>
01 V-REC.
05 REC-KEY PIC X(8).
05 ODO-LEN PIC S9(4) COMP.
05 ODO-FLD OCCURS 4000 TIMES
DEPENDING ON ODO-LEN.
07 ODO-DAT PIC X(1).
与えられたコピーブックを入力としてcobgenschツールを実行すると、以下のような変換スキーマ・ファイルが得られます。
* Schema Version 5.1 L1, 01, V-REC, NULL, 0, 1, L2, 05, REC-KEY, EBC_ASC, 8, 1, L3, 05, ODO-LEN, COPY, 2, 1, L4, 05, ODO-FLD, NULL, 0, 4000, ODO-LEN L5, 07, ODO-DAT, EBC_ASC, 1, 1, * Condition L0, "\0", ( L1 L2 L3 L4 L5 )
ソース・データセットと変換スキーマ・ファイルが準備できたら、dsmiginツールを使用して以下のようにマイグレーションします。
$ dsmigin VB.SAMPLE.raw VB.SAMPLE.TEST –s VB.SAMPLE.conv –e JAK -f VB<VB.SAMPLE.raw>は、ダウンロードしたソース・ファイルであり、<VB.SAMPLE.TEST>は、マイグレーション後に保存されるデータセットです。<VB.SAMPLE.conv>は、変換スキーマ・ファイルです。
5.3. 再定義文(REDEFINES)が使用されるデータセット
以下のように、再定義文(REDEFINES)が含まれているレイアウトを持つデータセットは、分岐条件に関する情報が必要です。
01 A.
05 B PIC X(01).
05 C PIC X(05).
05 D REDEFINES C.
10 E PIC X(02).
10 F PIC X(03).
フィールドBの値がAである場合のみ、再定義(REDEFINE)されたDの情報を参照し、それ以外の場合は、Cの情報を参照する場合には、コピーブックに$$CONDという条件文を追加する必要があります。
$$COND文を使用する方法は、以下のとおりです。
$$COND : NAME_01 : VALUE_01 [: NAME_02 : VALUE_02 … ] : REDEFINE_NAME [...]-
$$COND
-
ラベルであり、条件文の開始を示します。
-
-
NAME_01 : VALUE_01
-
フィールド名とそのフィールドに該当する条件値を順次に入力します。各項目を区分するために、区切り文字としてコロン(:)を使用します。dsmiginツールを使用してマイグレーションするとき、VALUE_#に使われる条件値は、すでに定義されているNAME_#フィールド項目の形式に自動変換されます。したがって、ユーザーはEBCDIC、ZONED、PACKEDなどのフィールド形式を考慮せずに、ただASCII値を引用符(")内に入力するだけで済みます。
-
NAME_# : VALUE_#条件が複数使われる場合にも、各条件を区切り文字のコロン(:)で区分します。
-
-
REDEFINE_NAME
-
該当する条件が成立した場合、実行する1つまたは複数のREDEFINEフィールド名を指定すると、条件文の作成が完了します。
-
条件文に値を入力するときに、値のタイプを明示的に指定することで、該当するフィールド形式を使用せずに、希望するタイプに変換することができます。
-
ユーザー指定のフィールド形式は、以下のとおりです。
タイプ 説明 !
NOT EQUALITYをチェックします。
'(empty)'
該当するフィールドのデフォルト・タイプに変換します。
'A'
入力値をASCII文字のまま使用します。
'E'
EBCDIC文字に変換します。
'P’or’UP'
Packed Decimal、またはUnsigned Packed Decimal形式に変換します。
'Z’or’UZ'
Zoned Decimal、またはUnsigned Zoned Decimal形式に変換します。
'G'
GRAPHIC(2Byte)文字に変換します。
'H'
入力値をHexadecimal値に変換します。(例: H"123" → 0x7B)
'X'
入力した2バイト値を1バイトのHex値に変換します。(例: X"12AB" → 0x12 0xAB)
-
Packed Decimal、またはZoned Decimalの条件値を指定する場合、該当するフィールドがSigned DecimalとUnsigned Deicalのどちらの形式を使用するかを考慮して、条件値のタイプを指定します。たとえば、Packed Decimalフィールドの最終桁のHex値が、'0x0C'(正数)、または'0x0D'(負数)に指定されている場合は、'P’タイプを指定して、Signed Packed Decimal形式に条件値を変換します。一方、最後のHex値が'0x0F’の場合は、'UP’タイプを指定してUnsigned Packed Decimal形式に変換します。
Zoned Decimalの条件値を指定する場合は、Zoned Decimalフィールドの最終桁のHex値が'0xC0'(正数)、または'0xD0'(負数)に指定されている場合、'Z’タイプを指定して、Signed Zoned Decimal形式に条件値を変換します。一方、最後のHex値が'0xF0’の場合は、'UZ’タイプを指定してUnsigned Zoned Decimal形式に変換します。
-
以下は、再定義文が含まれているコピーブックに$$COND条件文を使用した例です。
01 A.
05 B PIC X(01).
05 C PIC X(05).
05 D REDEFINES C.
10 E PIC X(02).
10 F PIC X(03).
$$COND : B : "A" : D
cobgenschツールは、$$COND文の情報を参照して、dsmiginツールが使用できる変換スキーマを作成します。
以下は、作成された変換スキーマの例です。
* Schema Version 5.1 L1, 01, A, NULL, 0, 1, L2, 05, B, EBC_ASC, 1, 1, L3, 05, C, EBC_ASC, 5, 1, L4, 05, D, NULL, 0, 1, # REDEFINES C L5, 10, E, EBC_ASC, 2, 1, L6, 10, F, EBC_ASC, 3, 1, * Condition L2, "A", ( L1 L2 L4 L5 L6 ) L0, "\0", ( L1 L2 L3 )
作成されたスキーマ・ファイルを使用してデータセットのレコードをマイグレーションすると、データセットの各レコードのフィールドBの位置にある値によってマイグレーションのルールが適用され、データセットが移行されます。
上記例では、コピーブックで作成した条件以外にも、1つの条件が追加で作成されていることが確認できます。最終行に作成された「L0」というラベルを持つ条件は、デフォルトで実行される条件文です。
5.4. 複数のレイアウトを使用するデータセット
複数のレイアウトを使用するデータセットは、前述した再定義文(REDEFINES)の処理と似た方法で条件文を作成します。
01 AAA-A.
03 BBB-A.
05 DATA-1 PIC X(01).
05 DATA-2 PIC X(04).
05 DATA-A REDEFINES DATA-2.
07 DATA-A1 PIC 9(02).
07 DATA-A2 PIC X(02).
01 AAA-B.
03 BBB-B.
05 DATA-3 PIC 9(01).
05 DATA-4 PIC 9(04).
05 DATA-D REDEFINES DATA-4.
07 DATA-D1 PIC 9(01).
07 DATA-D2 PIC X(03).
上記のように01レベルの項目が複数存在する場合、1番目以降のレイアウトを使用するためには、再定義文の処理と同様に、$$COND文を使用する必要があります。
特定のレイアウトを使用するための$$COND文の作成方法は以下のとおりです。
$$COND : DATA-3 : "B" : AAA-B以下は、2番目のレイアウトにある再定義文を同時に指定するために作成した$$COND文です。
$$COND : DATA-3 : "D" : AAA-B DATA-D以下は、cobgenschツールを使用して作成したスキーマ・ファイルです。
* Schema Version 5.1 L1, 01, AAA-A, NULL, 0, 1, L2, 03, BBB-A, NULL, 0, 1, L3, 05, DATA-1, EBC_ASC, 1, 1, L4, 05, DATA-2, EBC_ASC, 4, 1, L5, 05, DATA-A, NULL, 0, 1, # REDEFINES DATA-2 L6, 07, DATA-A1, U_ZONED, 2, 1, L7, 07, DATA-A2, EBC_ASC, 2, 1, L8, 01, AAA-B, NULL, 0, 1, L9, 03, BBB-B, NULL, 0, 1, L10, 05, DATA-3, U_ZONED, 1, 1, L11, 05, DATA-4, U_ZONED, 4, 1, L12, 05, DATA-D, NULL, 0, 1, # REDEFINES DATA-4 L13, 07, DATA-D1, U_ZONED, 1, 1, L14, 07, DATA-D2, EBC_ASC, 3, 1, * Condition L10, "B", ( L8 L9 L10 L11 ) L10, "D", ( L8 L9 L10 L12 L13 L14 ) L0, "\0", ( L1 L2 L3 L4 )
作成されたスキーマ・ファイルを見ると、01レベルを含む2つのレイアウトが含まれており、デフォルト条件を除いて、$$COND文で作成した条件がすべて2番目の01レベル項目であるフィールドのAAA-Bから始まることが確認できます。
このように作成されたスキーマ・ファイルを使用すると、再定義文を使用した場合と同様に、フィールドDATA-3の位置にある値によってマイグレーション・ルールが適用され、複数のレイアウトを使用するデータセットもマイグレーションできます。