Stored Procedure
본 부록에서는 Stored Procedure를 사용하는 방법에 대해서 설명합니다.
1. 개요
Stored procedure는 DBMS에서 DB 서버와 함께 저장되어 있는 연산(subroutine)을 말하며, 일반적으로 SQL로 작성됩니다. 특히, 복잡한 연산 수행을 Stored Procedure를 사용하여 작성하면 클라이언트 애플리케이션은 프러시저 호출을 통해 기능을 제공받을 수 있으며 프러시저가 수정되었을 때 동일한 변경사항을 적용받을 수 있습니다.
2. 일반적인 Stored Procedure 호출
Stored Procedure는 일반 룰을 이용하여 호출할 수 있으며 JDBC에서 정의된 프러시저 호출 문법을 사용합니다.
프러시저 호출 문법의 예는 다음과 같습니다.
-
반환 파라미터가 있는 경우
{<return> = call <procedure-name>[<arg1>,<arg2>, ...]} -
반환 파라미터가 없는 경우
{call <procedure-name>[<arg1>,<arg2>, ...]}
각 파라미터는 IN, IN OUT, OUT, NO_PARAM 타입 중 하나가 될 수 있으며, IN은 입력 매핑, IN OUT은 입출력 매핑, OUT은 출력 매핑, NO_PARAM 은 IN/OUT 인자가 없는 프로시저 결과값에 대한 매핑이 가능합니다. 각 타입은 [IN], [INOUT], [OUT], [NO_PARAM] Annotation으로 지정됩니다. [IN], [INOUT], [OUT] Annotation은 콜론(:)의 바로 뒤에, [NO_PARAM]은 콜론 없이 지정합니다.
-
IN 타입 변수의 경우
입력 메시지 DTO의 특정 필드와 매핑되어야 하며 일반적인 입력 매핑 방법과 동일하게 왼쪽의 DTO 트리에서 소스 필드를 드래그 앤드 드롭한 뒤 [IN] Annotation을 추가합니다.
다음은 설정 예입니다.
-
원래의 입력 매핑
{call myproc(:/path)} Annotation -
Annotation 추가 후
{call myproc(:[IN]/path)}
-
-
IN OUT 타입의 경우
IN 타입과 동일하게 드래그 앤드 드롭 후 [INOUT] Annotation을 추가합니다. IN OUT 타입은 IN 타입과 달리 출력 매핑 화면을 통한 출력 매핑도 가능합니다.
다음은 설정 예입니다.
-
원래의 입력 매핑
{call myproc(:/path)} -
Annotation 추가 후
{call myproc(:[INOUT]/path)}
-
-
OUT 타입인 경우
입력 매핑이 없기 때문에 입력 DTO의 필드와 매핑을 할 수 없으므로 직접 전체 표현식(expression)을 입력합니다. Annotation이 된 OUT 타입 변수는 출력 매핑 화면에서 지정된 레이블로 표현됩니다.
{call myproc(:[OUT]myOutputVar)}{call :[OUT]myReturnVar := myproc()}OUT 타입 파라미터 중에서 매핑되지 않은 파라미터는 [SQL 타입] 버튼을 클릭해서 수동으로 적절한 타입을 지정해야 프러시저 호출이 가능합니다.
-
NO_PARAM 타입인 경우
IN, OUT 인자가 없기 때문에 Annotation과 호출할 프로시저만 입력합니다.
[NO_PARAM] {call select_none()}NO_PARAM 타입은 vendor가 MSSQL일 경우에만 지원하고 있습니다.
3. ResultSet을 반환하는 Stored Procedure 호출
ResultSet을 반환하는 프러시저의 경우 다음과 같이 정의합니다.
-
[프러시저 결과값 맵핑] 버튼을 클릭해서 ReulstSet과 매핑을 정의합니다.
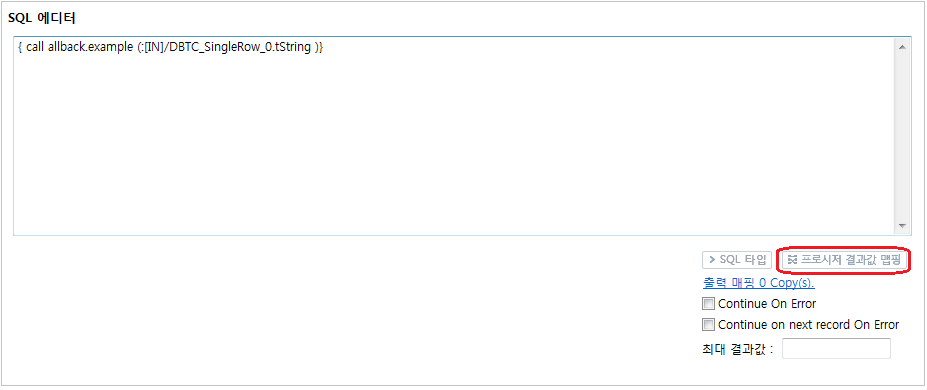 프러시저 결과값 맵핑 버튼
프러시저 결과값 맵핑 버튼 -
버튼을 클릭하면 나타나는 다음과 같은 대화상자에서 [Add] 버튼과 [Remove] 버튼을 클릭해서 ResultSet을 추가하고 제거할 수 있습니다.
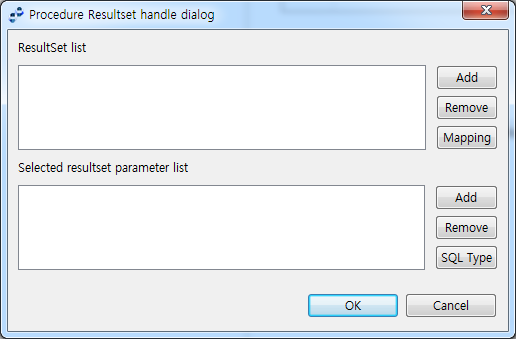 ResultSet 정의 대화 상자
ResultSet 정의 대화 상자ResultSet 정의 방식은 DBMS의 지원 방식에 따라 크게 2가지 방법으로 나뉩니다. MS SQL 서버와 같이 프러시저가 곧바로 결과 집합을 반환하는 ResultSet을 직접 추가해야 합니다. 하나의 프러시저가 복수의 ResultSet을 리턴하는 경우 해당 개수만큼 추가합니다.
ResultSet의 순서는 룰의 동작에 영향을 미칩니다. 즉, ResultSet을 리턴되는 순서대로 정의해야 합니다.
-
'ResultSet List'에서 추가한 ResultSet을 선택한 뒤 'Selected resultset parameter' 항목의 [Add] 또는 [Remove] 버튼을 클릭해서 해당하는 ResultSet의 파라미터를 정의합니다.
다음은 ‘name’과 ‘id’라는 2개의 파라미터를 가지는 하나의 ResultSet을 반환하는 예입니다.
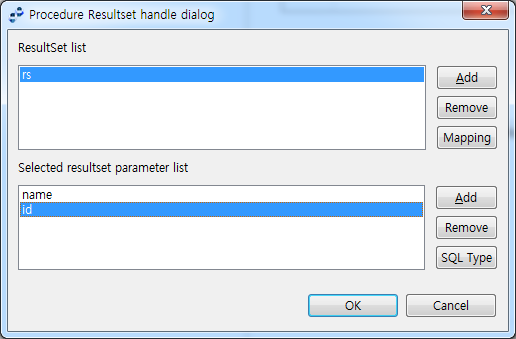 ResultSet을 추가한 예
ResultSet을 추가한 예ResultSet과 마찬가지로 파라미터도 이름이 아닌 순서가 중요합니다. 즉, ResultSet을 생성하는 SQL 문이 select id, name from.. 과 같더라도, 이 화면에서 name, id의 순서로 정의하면 이후 매핑화면의 name 파라미터가 실제 Select 문의 id 파라미터에 대응됩니다.
-
'ReulstSet List'의 [Mapping] 버튼을 클릭해서 매핑을 정의합니다. 이때 매핑의 소스는 앞서 정의한 파라미터들이 되며 타깃은 룰의 출력 메시지가 됩니다. 매핑 정의 화면은 일반적인 매핑 화면과 동일합니다. Oracle 및 Tmax Tibero는 ResultSet이 커서(Cursor) 타입의 OUT 파라미터로 넘겨지는 경우 직접 ResultSet을 추가하는 대신 [SQL 타입] 버튼을 통해 해당하는 OUT 파라미터를 CURSOR 타입으로 선언합니다.
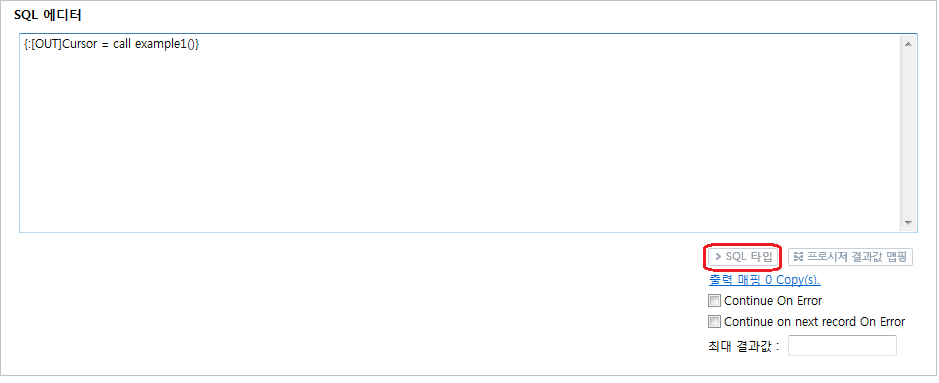 SQL 타입 버튼
SQL 타입 버튼 -
출력 파라미터를 CURSOR 타입으로 지정하면 다음과 같이 자동으로 ResultSet list에 추가됩니다. CURSOR 타입 파라미터의 경우 '(Unremovable)'이라고 표시되며 삭제가 불가능합니다.
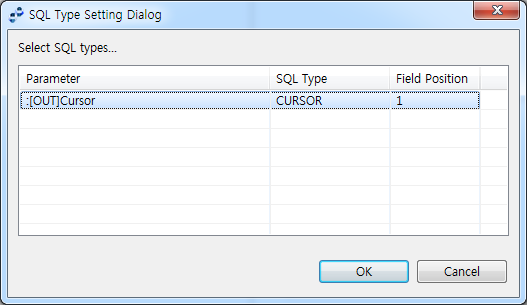 커서 타입으로 지정한 예
커서 타입으로 지정한 예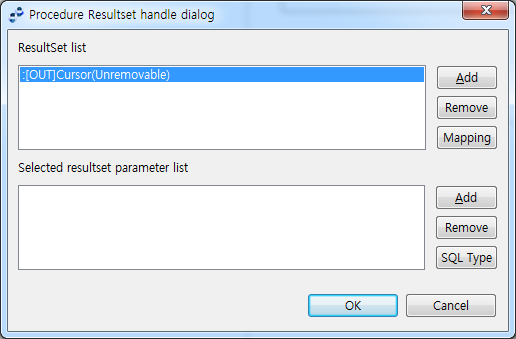 커서 타입 파라미터가 추가된 예
커서 타입 파라미터가 추가된 예 -
이후 앞서 설명한 것과 동일하게 ResultSet의 파라미터를 선언한 뒤 매핑합니다.