COBOLの構造
本章では、COBOLの基本的な構造と構成について説明します。
1. 文字
COBOL言語の最も基本となる単位は文字です。デフォルトの文字セットは、アルファベット、数字、特殊文字を含みます。それぞれの文字の組み合わせで文字列と区切り文字を形成します。文字列と区切り文字は、それぞれワード、リテラル、句、節、および文を形成します。文字は、英数字リテラルおよびコメントで使用され、1バイトと2バイトの文字が使用されます。
以下は、ソースコード上の文字列と区切り文字を形成するデフォルトの文字セットのリストです。
| 文字 | 説明 |
|---|---|
空白 |
|
+ |
正符号 |
- |
負符号またはハイフン |
* |
アスタリスク |
/ |
スラッシュ |
= |
等号 |
$ |
通貨記号 |
, |
コンマ |
; |
セミコロン |
. |
小数点またはピリオド |
"" |
二重引用符 |
( |
左括弧 |
) |
右括弧 |
> |
より大きい |
< |
より小さい |
: |
コロン |
'' |
単一引用符 |
A-Z |
英文字(大文字) |
a-z |
英文字(小文字) |
0-9 |
数字 |
2. 文字列
文字列は、COBOLワード、リテラル、PICTURE文字列、またはコメントを形成する1文字または一連の連続した文字です。文字列は、区切り文字で区分することができます。区切り文字は、文字列を区分するために使用する連続した文字列です。
2.1. COBOLワード
COBOLワードは、ユーザー定義語、システム名、または予約語を形成する文字列です。
ほとんどのユーザー定義名(セクション名、段落名およびレベル番号を除く)は、少なくとも1つ以上の英字を含んでいる必要があります。優先順位番号とレベル番号は一意である必要はありません。COBOLワードで使用される小文字は大文字として認識されます。
特殊文字を除いて、COBOLワードは次の要素で構成されます。
-
A - Z
-
a - z
-
0 - 9
-
ハイフン(-):ハイフンは、COBOLワードの最初または最後の文字として使用することができません。
以下は、LENGTH、RANDOM、SUMを除くすべてのCOBOLワードに適用される規則です。
-
予約語のセットは、ユーザー定義語、システム名、関数名のセットと重なり合ってはなりません。
-
ユーザー定義語、システム名、関数名のそれぞれのセットは重なり合っても構いません。つまり、同じワードをユーザー定義語、システム名、関数名に使用することができます。その場合、使用されたワードがどのセットに属するかは、コンテキストによって判断されます。
COBOLワードのLENTGH、RANDOM、SUMには、次の規則が適用されます。
-
LENGTH、RANDOM、SUMは、予約語と関数名に含まれます。予約語としても関数名としても使用することができ、どちらに属するかはコンテキストによって判断されます。
-
LENGTH、RANDOM、SUMは、ユーザー定義語およびシステム名とは別のセットに属します。したがって、どのようなコンテキストにおいても、COBOLワードのLENGTH、RANDOM、SUMはユーザー定義語あるいはシステム名として使用することができません。
関数名
COBOLが基本的に提供するワード・リストの1つであり、組み込み関数を指定します。
予約語
COBOLソース単位であらかじめ定義された文字列です。ユーザー定義語またはシステム名としては使用できません。
予約語には、次のようなタイプがあります。
-
キーワード
キーワードは、節、項目、またはステートメントを記述するときに必要な予約語です。
-
オプション・ワード
項目またはステートメントを読みやすくするために含めることができる予約語です。プログラムの実行には影響を与えません。
-
表意定数
表意定数は、特定の定数値にあらかじめ付ける名前です。この名前によって値を参照します。
表意定数 意味 ZERO, ZEROS, ZEROES
コンテキストによって、数値ゼロ(0)または文字ゼロを表します。
英数字を指定する必要があるコンテキストでZERO、ZEROS、またはZEROESを使用する場合は、英数字ゼロが使用されます。コンテキストの判別が困難な場合にも、英数字ゼロが使用されます。
SPACE, SPACES
1つ以上の空白を表します。
英数字を指定する必要があるコンテキストで使用された場合は、英数字リテラルとして扱われ、2バイト文字を指定する必要があるコンテキストで使用された場合には、2バイト・スペースとして扱われます。
システムロケールがja_JP.sjis、ja_JP.SJIS、ja_JPの場合にDBCSを使用すると、2バイト・スペース(0x8140)がデフォルトとして適用されます。
HIGH-VALUE, HIGH-VALUES
使用している照合シーケンスにおいて最も大きい値を持つ文字を表します。
英数字を指定する必要があるコンテキストで使用された場合は、英数字リテラルとして扱われます。EBCDIC照合シーケンスの英数字データの値は、X’FF’です。その他の英数字データの値は、実際に使用されている照合シーケンスによって異なります。
コンテキストの判別が困難な場合には、英数字を指定する必要があるコンテキストとみなされ、値のX’FF’が使用されます。
LOW-VALUE, LOW-VALUES
使用している照合シーケンスにおいて最も小さい値を持つ文字を表します。
英数字を指定する必要があるコンテキストで使用された場合は、英数字リテラルとして扱われます。EBCDIC照合シーケンスの英数字データの値は、X'00’です。その他の英数字データの値は、実際に使用されている照合シーケンスによって異なります。
コンテキストの判別が困難な場合には、英数字を指定する必要があるコンテキストとみなされ、値のX'00’が使用されます。
QUOTE, QUOTES
次のように使用することができます。
-
二重引用符(" ")
英数字を指定する必要があるコンテキストで使用された場合は、英数字リテラルとして使用されます。
ALL literal
ALLを除く、2バイトを含む英数字リテラルを指定することができます。表意定数でない場合、ALLリテラルは、リテラルを構成する文字列が1つ以上存在することを表します。
CALL、INSPECT、INVOKE、STOPまたはSTRINGステートメントでは、ALLリテラルを使用することができません。
NULL、NULLS
USAGE POINTER、USAGE PROCEDURE-POINTER、USAGE FUNC TION-POINTER、またはADDRESS OF特殊レジスターで定義されたデータ項目に有効なアドレスがないことを示す値を指定します。
-
-
特殊文字ワード
特殊文字ワードには、次の2つのタイプがあります。
区分 種類 算術演算子
+、-、/、*、**
比較演算子
<、>、=、<、=、>、=
-
特殊レジスター
特殊レジスターは、コンパイラーによって生成されたデータ項目または一時的な値です。特殊レジスターを参照するには、そのデータ項目に対応する予約語を使用します。
以下は、各特殊レジスターの説明と使用方法です。
-
ADDRESS OF
-
LINKAGE、LOCAL-STORAGE、またはWORKING-STORAGEセクションに定義されたデータ項目のアドレスを参照します。
-
ADDRESS OF特殊レジスターは、暗黙的にUSAGE POINTERとして定義されます。
-
ADDRESS OF特殊レジスターは、オペランドとして関数IDを指定することができません。
-
-
LENGTH OF
-
LENGTH OF特殊レジスターには、データ項目によって使用されるバイト数が格納されます。
USAGE DISPLAY-1で記述された2バイト・データ項目で、各文字は2バイトの記憶領域を占めます。
-
手続き部のどこでもLENGTH OF特殊レジスターを使用することができます。
-
LENGTH関数の引数としてADDRESS OF特殊レジスターを指定した場合、ADDRESS OFの引数とは関係なく、そのコードが実行される環境で使用されるアドレス空間のサイズです。
-
LENGTH OF特殊レジスターは、以下では指定することができません。
-
受信側のデータ項目
-
添え字
-
-
LENGTH OF特殊レジスターがCALLステートメントのパラメータとして使用される場合には、BY CONTENTまたはBY VALUEを指定する必要があります。
-
表要素を指定した場合、LENGTH OF特殊レジスターは1つの要素の長さを持ちます。表要素を参照する際に、要素名に添え字を指定する必要はありません。
-
IDを指定して参照される領域がプログラムに使用できる状態でない場合でも、IDの長さが判別できれば、値を取得することができます。
-
組み込み関数のLENGTHを使用して、データ項目の長さを取得することもできます。
-
-
RETURN-CODE
-
RETURN-CODE特殊レジスターは、現在のCOBOLプログラムが終了したときに、リターン・コードを呼び出したプログラムやオペレーティング・システムにリターン・コードを渡すために使用します。
-
COBOLプログラムを終了するとき、RETURN-CODE特殊レジスターにユーザーが定義した値を保存して終了します。(ユーザーが定義した終了コードと実際の終了コードとは異なる可能性があります)
制御が呼び出し側のプログラムに戻る場合、RETURN-CODE特殊レジスターの値は呼び出し側のプログラムに渡されます。その場合、RETURN-CODE特殊レジスターは次のように定義されます。
01 RETURN-CODE GLOBAL PICTURE S9(4) VALUE ZERO.
-
ネストされたプログラムで使用される場合、最も外側のプログラムでGLOBAL節が暗黙的に定義されます。
-
以下は、RETURN-CODE特殊レジスターの設定例です。
MOVE 8 TO RETURN-CODE
-
-
SORT-CONTROL
-
SORT-CONTROL特殊レジスターは、英数字データ項目であり、次のように定義されます。
01 SORT-CONTROL GLOBAL PICTURE X(8) USAGE DISPLAY.
-
OFCOBOLでは構文チェックだけが行われ、システムに影響を与えません。
-
-
SORT-CORE-SIZE
-
SORT-CORE-SIZE特殊レジスターは、バイナリ・データ項目であり、次のように定義されます。
01 SORT-CORE-SIZE GLOBAL PICTURE S9(8) USAGE IS BINARY VALUE ZERO.
-
OFCOBOLでは構文チェックだけが行われ、システムに影響を与えません。
-
-
SORT-FILE-SIZE
-
SORT-FILE-SIZE特殊レジスターは、バイナリ・データ項目であり、次のように定義されます。
01 SORT-FILE-SIZE GLOBAL PICTURE S9(8) USAGE IS BINARY VALUE ZERO.
-
OFCOBOLでは構文チェックだけが行われ、システムに影響を与えません。
-
-
SORT-MESSAGE
-
SORT-MESSAGE特殊レジスターは、英数字データ項目であり、次のように定義されます。
01 SORT-MESSAGE GLOBAL PICTURE X(8) USAGE IS DISPLAY.
-
OFCOBOLでは構文チェックだけが行われ、システムに影響を与えません。
-
-
SORT-MODE-SIZE
-
SORT-MODE-SIZE特殊レジスターは、バイナリ・データ項目であり、次のように定義されます。
01 SORT-MODE-SIZE GLOBAL PICTURE S9(5) USAGE BINARY VALUE ZERO.
-
OFCOBOLでは構文チェックだけが行われ、システムに影響を与えません。
-
-
SORT-RETURN
-
SORT-RETURN特殊レジスターは、バイナリ・データ項目であり、次のように定義されます。
01 SORT-RETURN GLOBAL PICTURE S9(4) USAGE BINARY VALUE ZERO.
-
OFCOBOLでは構文チェックだけが行われ、システムに影響を与えません。
-
-
TALLY
-
TALLY特殊レジスターは、バイナリ・データ項目であり、次のように定義されます。
01 TALLY GLOBAL PICTURE S9(5) USAGE BINARY VALUE ZERO.
-
OFCOBOLでは構文チェックだけが行われ、システムに影響を与えません。
-
-
WHEN-COMPILED
-
WHEN-COMPILED特殊レジスターは、コンパイルを開始する時刻を保存する英数字データ項目であり、次のように定義されます。
01 WHEN-COMPILED GLOBAL PICTURE X(16) USAGE DISPLAY.
-
OFCOBOLでは構文チェックだけが行われ、システムに影響を与えません。
-
-
XML-CODE
-
XML-CODE特殊レジスターは、以下の目的で使用されます。
-
XML PARSEステートメントで識別されたXMLパーサーと処理プロシージャ間の状態を通信するために使用します。
-
XML GENERATEステートメントが正常に実行されたのか、XMLの作成中に例外が発生したのかを示すために使用します。
XML-CODE特殊レジスターは、次のように定義されます。
01 XML-CODE PICTURE S9(9) USAGE BINARY VALUE 0.
-
-
ネストされたプログラムで使用される場合、最も外側のプログラムでGLOBAL節が暗黙的に定義されます。XMLパーサーがXMLイベントを見つけると、XML-CODEを設定した後、処理プロシージャに制御を渡します。EXCEPTIONイベントを除くすべてのイベントについて、処理プロシージャが制御を受け取ったとき、XML-CODEは0になります。
パーサーに戻る前に、以下のようにXML-CODEを設定することができます。
-
-1を設定すると、正常なイベント後に、EXCEPTIONイベントが発生せず、残りのXML文書を処理せずにパーサーが即時終了されることを示します。
-
1を設定すると、XMLPARSE(XMLSS)コンパイラー・オプションが適用された場合、END-OF-INPUTイベント後に文書の次のセグメントをパーシングする準備ができていることを示します。処理プロシージャで返すセグメントがなくなった場合、XML-CODEは0に設定する必要があります。
パーサーに戻る前にXML-CODEを他の値に設定すると、結果が定義されません。XML PARSEステートメントでパーサーを返す場合、XML-CODEには処理プロシージャまたはパーサーが最後に設定した値が含まれます。XML GENERATEステートメントが終了したとき、XML-CODEに0が設定されたら、XMLが正常に作成されたことを示し、0以外の値が設定されたら、XMLの作成中に例外が発生したことを示します。
-
-
-
XML-EVENT
-
XML-EVENT特殊レジスターは、XMLパーサーからXML PARSEステートメントで識別されたイベント情報を処理プロシージャに渡します。XMLPARSEコンパイラー・オプションがXMLPARSE(XMLSS)かXMLPARSE(COMPAT)かによって、設定されるイベントおよび関連特殊レジスターが異なります。
XML-EVENT特殊レジスターは、次のように定義されます。
01 XML-EVENT USAGE DISPLAY PICTURE X(30) VALUE SPACE.
-
OFCOBOLでは現在一部のXMLPARSE(XMLSS)オプションのみサポートしています。
下のテーブルは、XMLPARSE(XMLSS)オプションで解析できるXMLイベントと特殊レジスターです。XML-EVENTはデータの受信項目として使用することはできません。
XML-EVENT 特殊レジスターの内容 ATTRIBUTE-CHARACTERS
XML-TEXTは単一引用符(' ')内の値を含みます。
ATTRIBUTE-NAME
XML-TEXTは属性名を含みます。
COMMENT
XML-TEXTは開始文字の「<!--」と終了文字の「-->」の間のコメント内容を含みます。
CONTENT-CHARACTERS
XML-TEXTは開始タグと終了タグの間のエレメントの文字内容を含みます。
END-OF-DOCUMENT
XML-CODEとXML-EVENT以外のすべてのXML特殊レジスターは長さが0で、空の値を持ちます。
END-OF-ELEMENT
XML-TEXTはエレメント終了タグのローカル・パートまたは空エレメント・タグ名を含みます。
EXCEPTION
XML-CODEは0以外の値を持ちます。XML-TEXTは例外が発生したエラーまたはその地点までの文書のフラグメントを含みます。他のすべてのXML特殊レジスターは長さが0で、空の値を持ちます。
START-OF-DOCUMENT
XML-CODEとXML-EVENT以外のすべてのXML特殊レジスターは長さが0で、空の値を持ちます。
START-OF-ELEMENT
XML-TEXTはエレメント開始タグ名のローカル・パートまたは空エレメント・タグ名のローカル・パートを含みます。
VERSION-INFORMATION
XML-TEXTはXML宣言部のバージョン情報で単一引用符内の値を含みます。
-
-
XML-TEXT
-
XML-TEXT特殊レジスターは、XML解析中に文書のフラグメントを含みます。XML-TEXTは含まれているXML文書のフラグメントの長さを持ち、英数字データ項目です。長さは0からXML文書全体の長さまで持つことができます。同じCOBOLデータ記述項目はありません。
-
XML PARSEステートメントのオペランドが英数字データ項目の場合、パーサーは処理プロシージャに制御権限を転送する前にXML-TEXTにイベントと関連する文書のフラグメントを設定します。
-
XML-TEXTに含まれているバイト数を確認するには、LENGTH関数またはLENGTH OF特殊レジスターを使用します。XML-TEXTは受信項目として使用することはできません。
-
-
2.2. リテラル
リテラルは、文字列を構成する文字によって、または表意定数の使用によって、その値が決まる文字列です。
英数字リテラル
以下では、各リテラルの使用方法について説明します。
-
基本英数字リテラル
-
基本英数字リテラルには、1バイトまたは2バイトの任意の文字を使用することができます。
-
英数字リテラルに含まれている可読可能な文字はすべてリテラルの値です。
-
リテラルを区切る文字としては、二重引用符または単一引用符を使用することができます。(APOST / QUOTEコンパイル・オプションとは関係ない)
基本形式は、以下のとおりです。
"alphanumeric-characters" 'alphanumeric-characters'
リテラルを囲んでいる二重引用符または単一引用符はコンパイル時に削除されます。
リテラル内で二重引用符または単一引用符を使用する場合には、同じ符号をペアで記述します。
"THIS ISN""T WRONG" 'THIS ISN''T WRONG'
リテラルの開始区切り文字として使用する二重引用符または単一引用符は、リテラルの終了区切り文字としても使用する必要があります。
'THIS IS RIGHT' "THIS IS WRONG' 'THIS IS WRONG"
-
-
2バイト文字リテラル
-
2バイト文字リテラルは、次の形式で使用することができます。
G"<DBCS-characters>" G'<DBCS-characters>'
-
2バイト文字リテラルは、次の領域で使用することができます。
-
データ部
-
2バイト・データ項目を定義するVALUE節
-
FD項目のVALUE OF節
-
-
手続き部
-
比較ロジックで2バイト・データ項目がある場合
-
CALLステートメントのBY CONTENTで渡される引数
-
DISPLAYステートメントおよび EVALUATEステートメント
-
INITIALIZEステートメント
-
MOVEステートメント
-
STRINGステートメント
-
UNSTRINGステートメント
-
表意定数ALL
-
-
コンパイラー指示ステートメントのCOPY、REPLACE、およびTITLE
-
-
-
国別リテラル
-
国別リテラルは、基本国別リテラルと国別リテラルの16進表記で使用します。
-
以下は、基本国別リテラル形式です。
N"<character-data>" N'<character-data>' NC"<character-data>" NC'<character-data>'
-
以下は、基本国別リテラルの16進表記形式です。
NX"<hexadecimal-digits>" NX'<hexadecimal-digits>'
-
国別リテラルの16進表記形式は、NSYMBOLコンパイラー・オプションによる影響を受けません。
-
基本国別リテラルと国別リテラルの16進表記は、以下の個所に使用できます。
-
国別クラスのデータ項目に関連付けられているVALUE節
-
USAGE NATIONALで定義された条件変数の条件名に関連付けられているVALUE節
-
形象定数「ALL」
-
比較条件
-
形式2のSEARCHステートメントのWHEN句(バイナリ検索)
-
INSPECTステートメントのALL句、LEADING句またはFIRST句
-
INSPECTステートメントのBEFORE句またはAFTER句
-
STRINGステートメントのDELIMITED BY句
-
UNSTRINGステートメントのDELIMITED BY句
-
CALLステートメントのBY CONTENTで渡される引数
-
CALLステートメントのBY VALUEで渡される引数
-
DISPLAYステートメント、EVALUATEステートメント
-
プロシージャー・ステートメントの送り出し項目
-
INITIALIZE
-
INSPECT
-
MOVE
-
STRING
-
UNSTRING
-
-
組み込み関数の引数
-
DISPLAY-OF
-
LENGTH
-
LOWER-CASE
-
MAX
-
MIN
-
ORD-MAX
-
ORD-MIN
-
REVERSE
-
UPPER-CASE
-
-
COPY、REPLACE、およびTITLE
-
-
-
英数字リテラルの16進表記
-
英数字リテラルは、16進表記で使用することができます。
16進表記の形式は、以下のとおりです。
X"hexadecimal-digits" X'hexadecimal-digits'
16進数は'0’から'9'、'a’から’f'、および’A’から’F’の範囲にある文字です。2つの16進数で1バイトの文字セットに属する1つの文字を表します。4つの16進数で2バイト文字セットに属する1つの文字を表現します。16進数は偶数桁で表記する必要があり、16進リテラルの最大長は320バイトです。
-
複数行にわたって記述する場合の規則は、他の英数字リテラルの規則と同じです。ただし、リテラルの開始を示す区切り文字(X"またはX')は2行に分けて記述することができません。
-
-
NULL終了リテラル
-
英数字リテラルを次の形式で使用した場合に、NULL終了させることができます。
Z"mixed-characters" Z'mixed-characters'
-
1バイト文字のリテラル、2バイト文字のリテラル、または1バイト文字と2バイト文字の混合リテラルをすべて指定することができます。ただし、X'00’の値を含む文字は指定することができません。X'00’は、NULL終了の際に自動的に追加されるNULL文字です。
-
組み込み関数のLENGTHがNULL終了リテラルに適用される場合には、NULL文字は計算に含めません。
-
数値リテラル
数値リテラルは、0から9までの数字、符号(+または - )および小数点で構成される文字列です。リテラルが小数点を含まない場合、そのリテラルは整数です。
以下は、数値リテラルを設定時に適用される規則です。
-
1桁から31桁まで使用することができます。
-
符号文字は1つのみ使用することができます。符号文字を付ける場合は、リテラルの左端に付けます。リテラルが符号なしの場合、そのリテラルは正数です。
-
小数点は1つのみ使用することができます。
-
小数点を入れる場合、小数点はリテラルの桁数に含まれません。
-
小数点は右端を除く、リテラル中のどこでも使用することができます。
-
数値リテラルの値は、リテラルの中の数字で構成されたリテラルです。数値リテラルのサイズは、ユーザーが指定した数の桁数です。数値リテラルには、固定小数点リテラルと浮動小数点リテラルがあります。
以下は、浮動小数点リテラルの形式と規則についての説明です。
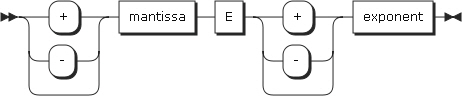
-
仮数と指数の符号は省略が可能です。符号を省略する場合、コンパイラーは正の整数を想定します。
-
仮数は1桁から16桁までの数字を指定することができます。小数点は仮数に含めます。
-
指数は、文字Eと後続のオプション符号、および1桁または2桁の数字によって表現することができます。
3. 区切り文字
区切り文字は、文字列を区切るための1つの文字または複数の連続した文字列です。(bは、1つの空白を示します)
| 文字 | 説明 |
|---|---|
b |
空白 |
,b |
コンマ |
.b |
ピリオド |
;b |
セミコロン |
( |
左括弧 |
) |
右括弧 |
: |
コロン |
"b |
二重引用符 |
'b |
単一引用符 |
X" |
16進形式英数字リテラルの開始区切り文字 |
X' |
16進形式英数字リテラルの開始区切り文字 |
Z" |
NULL終了英数字リテラルの開始区切り文字 |
Z' |
NULL終了英数字リテラルの開始区切り文字 |
G" |
2バイト文字リテラルの開始区切り文字 |
G' |
2バイト文字リテラルの開始区切り文字 |
N" |
国別リテラルの開始区切り文字 |
N' |
国別リテラルの開始区切り文字 |
NC" |
国別リテラルの開始区切り文字 |
NC' |
国別リテラルの開始区切り文字 |
NX" |
16進形式国別リテラルの開始区切り文字 |
NX' |
16進形式国別リテラルの開始区切り文字 |
== |
擬似テキスト区切り文字 |
区切り文字の規則
以下は、各区切り文字の使用規則についての説明です。
|
説明の中で中括弧({})は区切り文字を表し、bは空白を表します。空白を区切り文字または区切り文字の一部として使用できるところでは、複数の空白を使用することができます。 |
-
空白 {b}
空白は、次のような場合を除いて、任意の区切り文字の直前または直後に使用することができます。
-
擬似テキストの開始区切り文字
-
引用符で囲まれた内部。引用符と引用符の間にある空白は英数字リテラルの一部とみなされ、区切り文字として処理されません。
-
-
ピリオド {.b}、コンマ {,b}
-
区切り文字として使用されるコンマ(,)、ピリオド(.)は、1つの区切り文字と後続の空白の組み合わせで使用します。
-
区切り文字のピリオドは、1つの文の終わりを示す場合に使用するか、または指定された形式で使用しなければなりません。
-
見出し部では、それぞれの段落をピリオドで終わらせる必要があります。
-
環境部では、SPECIAL-NAMES、I-O-CONTROL段落で、それぞれのファイル制御項目をピリオドで終わらせる必要があります。
-
データ部では、FD、SD、およびデータ記述項目をそれぞれピリオドで終わらせる必要があります。
-
手続き部では、区切り文字のコンマでステートメントとステートメントの中のオペランドを区分することができます。それぞれのプロシージャは、ピリオドで終わらせる必要があります。
-
-
-
括弧 { ( } ...{ ) }
-
擬似テキストを除いて、括弧は左右をペアで使用します。
-
括弧は添え字、関数の引数のリスト、参照修飾子、算術式または条件を区切る役割をします。
-
-
コロン { : }
-
区切り文字として使用します。
-
-
二重引用符 { " } ... { " }
-
開始の二重引用符は、直前に空白または左括弧が必要です。
-
終了の二重引用符は、直後に区切り文字(空白、コンマ、セミコロン、ピリオド、右括弧または擬似テキスト区切り文字)が必要です。
-
引用符はペアで使用し、英数字リテラルを区切るために使用します。ただし、リテラルが複数行で構成されている場合は、関連規則に従います。
-
-
単一引用符 { ' } ...{ ' }
-
開始の単一引用符は、直前に空白または左括弧が必要です。
-
終了の引用符は、直後に区切り文字(空白、コンマ、セミコロン、ピリオド、右括弧または擬似テキスト区切り文字)が必要です。
-
引用符はペアで使用し、英数字リテラルを区切るために使用します。ただし、リテラルが複数行で構成されている場合は、関連規則に従います。
-
-
NULL終了リテラルの区切り文字 { Z" } ...{ " } , { Z' } ...{ ' }
-
開始区切り文字は、直前に空白または左括弧が必要です。
-
終了区切り文字は、直後に区切り文字(空白、コンマ、セミコロン、ピリオド、右括弧または擬似テキスト区切り文字)が必要です。
-
-
2バイトリテラル区切り文字 { G" } ... { " } , { G' } ... { ' }
-
開始区切り文字は、直前に空白または左括弧が必要です。
-
終了区切り文字は、直後に区切り文字(空白、コンマ、セミコロン、ピリオド、右括弧または擬似テキスト区切り文字)が必要です。
-
-
国別リテラル区切り文字 { N" } ...{ " } , { N' } ...{ ' } , { NC" } ...{ " } , { NC' } ...{ ' } , { NX" } ...{ " } , { NX' } ...{ ' }
-
リテラルの開始の区切り文字は、直前に空白または左括弧が必要です。
-
終了の区切り文字は、直後に分離文字(空白、コンマ、セミコロン、ピリオド、右括弧、または疑似テキスト区切り文字)が必要です。
-
-
擬似テキスト区切り文字 {b==} ...{==b}
-
開始区切り文字は、直前に空白が必要です。
-
終了区切り文字は、直後に区切り文字(空白、コンマ、セミコロン、ピリオド)が必要です。擬似テキストの区切り文字はペアで使用する必要があり、擬似テキストを区切ります。
-
|
PICTURE文字列、コメント、または英数字リテラルに含まれる句読記号は句読記号としてみなされず、文字列またはリテラルの一部として認識されます。 |
4. セクションと段落
プログラムは、セクションと段落で定義することができます。セクションと段落は、文、ステートメント、および項目に細分されます。文はステートメントと句に細分され、ステートメントは句に細分されます。項目は、節と句に細分されます。
以下は、各部の階層構造です。
-
見出し部
Paragraph |-- Entries |-- Clauses -
環境部
Sections |-- Paragraph |-- Entries |-- Clauses |-- Phrases -
データ部
Sections |-- Entries |-- Clauses |-- Phrases -
手続き部
Sections |-- Paragraphs |-- Sentences |-- Statements |-- Phrases
以下は、階層構造を構成する各項目の説明です。
| 区分 | 説明 |
|---|---|
項目(Entries) |
項目は、ピリオドで終わる一連の節で構成されます。 項目は、見出し部、環境部、データ部で指定することができます。 |
節(Clauses) |
節は、項目の属性を指定するために順番に記述された、連続するCOBOL文字列の集合です。 節は、見出し部、環境部、データ部で指定することができます。 |
文(Sentences) |
文は、ピリオドで終わる1つ以上のステートメントのリストです。 文は、手続き部で指定することができます。 |
ステートメント(Statements) |
ステートメントは、プログラムが処理するアクションを指定します。 ステートメントは、手続き部で指定することができます。 |
句(Phrases) |
プログラムの中のそれぞれの節やステートメントは、より小さな単位の句に細分化されることがあります。 |
5. ソース・テキストの形式
COBOLソースは72桁を1行とし、以下の領域で構成されます。
-
シーケンス番号領域
-
1〜6桁目の領域です。
-
シーケンス番号領域は、ソース・テキスト行にラベルを付けるために使用します。コンピュータがサポートする文字セットに属する文字を使用できます。
-
-
標識領域
-
7桁目の領域です。
-
標識領域は、次の指定を行うために使用します。
-
COBOLワードまたはリテラルが連続して表示されている
-
コメント処理
-
デバッグ行
-
-
6. 名前の適用範囲
ユーザー定義語は、データ・リソースまたはCOBOLプログラム要素に定義する名前です。
名前を定義できるリソースには、ファイル、データ項目、またはレコードがあります。COBOLプログラム要素は、プログラム、段落などに名前を定義することができます。
定義された名前は、各ソース・プログラム内で直接的または間接的に使用されます。場合によっては、他のリソース、または他のプログラム要素に定義された同じ名前を使用することができます。そのような場合、あるプログラム要素で参照する名前は、その名前を使用しているプログラム内で定義されたものであって、他のソース・プログラムで定義された名前を指すのではありません。
-
ユーザー定義語のうち次のものは、ユーザー定義語を宣言したソース・プログラム内のステートメントまたは項目でのみ参照できます。
-
段落名
-
セクション名
-
-
ユーザー定義語のうち次のものは、他のどのCOBOLプログラムからも参照できます。
-
ライブラリ名
-
テキスト名
-
-
ユーザー定義語のうち次のものは、構成セクション内で宣言されている場合、その構成セクションを含んでいるソース・プログラム内でのみ参照できます。
-
英字名
-
条件名
-
簡略名
-
記号文字
-
-
上記の条件に該当しない次のユーザー定義語は、参照ごとに個別の規則が適用されます。
ユーザー定義語 規則 プログラム名
COMMON属性や、ネストされたプログラムの有無によって属性が変わります。
ファイル名
ファイル記述項目にグローバル属性が指定されている場合、グローバル属性を持ちます。
レコード名、データ名、条件名
名前にグローバル属性が指定されている場合、グローバル属性を持ちます。
指標名
グローバル属性のデータ項目を指標で参照する場合は、その指標もグローバル属性を持ちます。また指標の範囲は、その指標により参照される表のデータ名の範囲と同じです。したがって、データ名に適用される規則が同様に適用されます。
-
プログラムAにプログラムBが直接含まれている場合、プログラムA、Bで定義される条件名、データ名、ファイル名、およびレコード名はそれぞれユーザー定義語で宣言することができます。
プログラムA、Bの両方に存在する名前をプログラムBで参照する場合は、以下の規則に従って判定されます。
-
プログラム内の宣言を優先して検索します。
-
該当する名前が見つからない場合は、プログラムAでグローバル宣言のみを検索します。
-
該当する名前が2つ以上ある場合、プログラムBで名前が2つ以上検索されることはありえません。プログラムBで名前がないか、または1つある場合は、次の規則が適用されます。
-
参照された名前がプログラムBで定義されている場合は、その名前が参照されます。
-
プログラムAのように他のプログラムに定義されている場合は、次の手順で判定されます。
-
参照された名前がプログラムAでグローバル宣言されているのであれば、プログラムAで宣言された名前を参照します。
-
プログラムAではなく、プログラムAの上位プログラムでグローバル宣言されているのであれば、そのプログラムで宣言された名前を参照します。さらに上位プログラムがある場合は、その名前の宣言があるまで、このプロセスが繰り返されます。
-
-
7. 参照
COBOLプログラムで定義されたユーザー定義語および各リソース参照のために定義された名前は一意である必要があります。本節では、一意参照の方法と各リソースの参照方法について説明します。
7.1. 修飾
ある名前が複数の階層にある場合、その階層の上位レベルの名前を1つまたは複数指定することにより、一意参照を行うことができます。上位レベルの名前を修飾子と呼び、名前を一意にするプロセスを修飾と呼びます。
データ部において修飾は、レベル番号の後に書き込まれるデータ名に対して行われます。修飾によって名前が一意になる場合や、まったく参照されない場合を除いて、同じグループに2つの同じデータ名を記述することはできません。
以下は、修飾の使用規則です。
-
レベル番号01の次に記述された名前が最上位の名前になり、以降の順序は02から49に記述された名前の順になります。
-
段落名の場合は、セクション名が最上位の名前になります。各要素の最上位の名前は修飾することができず、一意の名前を定義する必要があります。
-
添え字または指標名や条件変数も、修飾により一意参照することができます。条件変数の名前を使用して条件名を修飾することができます。
-
修飾の指定とは関係なく、データ名とプロシージャ名には同じ名前を指定することができません。
-
修飾を指定するには、データ名または条件名、段落名の後にINまたはOFと一緒に修飾子を付けます。INとOFは、同じ意味で解釈されます。
以下は、EMPLOYEE-NOというフィールドを含むレコードを持つファイルが複数あり、そのうちの1つのファイルのみMASTER-RECORDという名前のレコードで修飾した例です。
EMPLOYEE-NO OF MASTER-RECORD
以下の内容に注意して使用してください。
-
修飾子は修飾する名前より高いレベルでなければなりません。
-
複数の階層にわたって修飾する場合、低いレベルから記述します。
-
複数のデータ項目に同じデータ名または条件名を定義した場合、そのデータ名または条件名を手続き部、環境部、データ部で参照する場合は必ず修飾する必要があります。ただし、REDEFINE節では修飾することができません。
-
1つのセクションで同じ段落名を重複して記述することはできません。段落名をセクション名で修飾する場合は、SECTIONというワードを使用できません。段落名は、それが属するセクション内で参照される場合、修飾する必要がありません。
-
修飾が不要なところでも修飾することができます。修飾子が複数ある場合には、その組み合わせを選択して使用することができます。ただし、あるデータの修飾子の組み合わせが他のデータ名の修飾子の組み合わせの一部になることはできません。
7.2. 添え字付け
添え字付けは、添え字を使用して表の個別要素を参照する方法です。
添え字として、整数、データ名、データ名に「+」または「-」演算子と一緒に記述された算術式を使用できます。データ名を使用する場合は、整数を表す数字基本項目である必要があります。添え字全体は括弧で区切ります。
添え字として使用するデータには符号を付けることができますが、その場合、必ず正の符号(+)である必要があります。添え字の最小値は1であり、リストまたは表の最初のアイテムを表します。添え字の最大値は、OCCURS節で指定した最大値です。
表を識別するための添え字の組み合わせは、対象となる表要素のデータ名の後に括弧で囲んで記述します。複数の添え字を指定する場合は、データ構造階層における上位のものから記述します。つまり、ネストされた表で表現された多次元表の最も外側の表がメジャー表で、最も内側の表がマイナー表とみなされる場合は、添え字は左から右へ、すなわちメジャー、中間、マイナーの順に指定されます。
たとえば、TABLE-THREEが次のように定義されているとします。
01 TABLE-THREE.
05 ELEMENT-ONE OCCURS 3 TIMES.
10 ELEMENT-TWO OCCURS 3 TIMES.
15 ELEMENT-THREE OCCURS 2 TIMES PIC X(8).
TABLE-THREEの有効な添え字を使用した参照は、次のとおりです。
ELEMENT-THREE (2 2 1)
以下は、添え字付けの形式です。
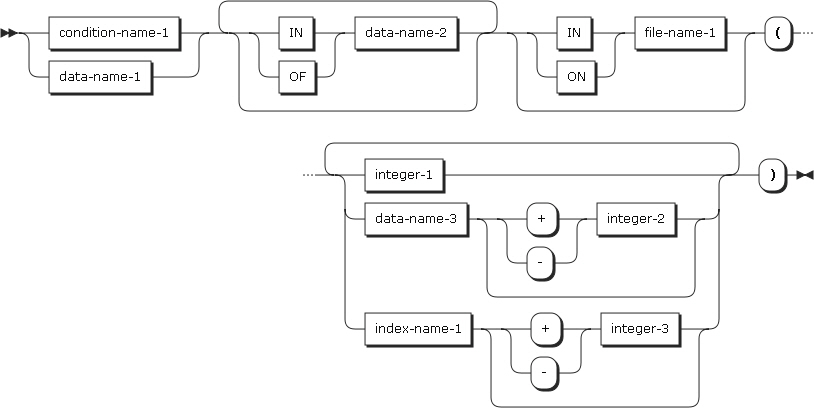
| 項目 | 説明 |
|---|---|
condition-name-1 |
condition-name-1の条件変数は、OCCURS節を含んでいるか、またはOCCURS節を含むデータ記述項目に従属している必要があります。 |
data-name-1 |
OCCURS節を含んでいるか、またはOCCURS節を含むデータ記述項目に従属している必要があります。 |
data-name-2, file-name-1 |
data-name-1が含まれているデータ項目またはレコードである必要があります。 |
integer-1 |
符号を付けることができます。ただし、正の符号のみ可能です。 |
data-name-3 |
整数を表す数字基本項目である必要があります。 data-name-3は、修飾することができます。 |
index-name-1 |
参照される表の階層内にあり、INDEXED BY節が指定されているデータ項目を表します。 |
integer-2, integer-3 |
符号付き整数は指定できません。 |
各表要素の参照は、次の場合を除いて、添え字を指定する必要があります。
-
SEARCHステートメントの対象
-
REDEFINES節の中
-
KEYがOCCURS節の句である場合
添え字付けの使用
以下では、それぞれの添え字に対応する添え字付けの使用方法について説明します。
-
データ名を使用した添え字付け
データ名を使用して添え字を表現する場合、そのデータ名は別の表の要素を参照するために使用できます。それぞれの表は、同じ数の要素を持つ必要はありません。同じデータ名は、1つの項目を持つ唯一の添え字として、または別の項目を持つ2つ以上の添え字の1つとして指定することができます。データ名の添え字は修飾できますが、添え字や指標を付けることはできません。
たとえば、TABLE-THREEに対する有効な添え字(SUB1、SUB2、およびSUB3はすべてSUBSCRIPT-ITEMに従属する項目であると想定)を使用して、以下のように参照することができます。
ELEMENT-THREE (SUB1 SUB2 SUB3) ELEMENT-THREE IN TABLE-THREE (SUB1 OF SUBSCRIPTOR-ITEM, SUB2 OF SUBSCRIPTOR-ITEM, SUB3 OF SUBSCRIPTOR-ITEM ) -
指標名を使用した添え字付け(指標付け)
指標付けにより、同種のデータ・リストおよび表の個別要素を参照することができます。
指標を指定するには、表を定義するときに、そのデータ項目にINDEXED BY節を指定します。指標名はINDEXED BY節により指定された名前であり、定義された指標を参照するために使用されます。指標の値は、対応する表または表内の要素の出現回数を表します。
指標名は、添え字として使用する前に初期化する必要があります。初期化する前の値は保証されません。
以下のステートメントを使用して初期化します。
-
VARYING句を伴うPERFORMステートメント
-
ALL句を伴うSEARCHステートメント
-
SETステートメント
指標名に保存された指標の値は、添え字の役割をします。添え字は、数値データ項目または整数である必要がありますが、指標は表要素の出現番号を表す特殊なタイプのデータ項目であるため、指標の値は数値としてみなされません。
-
-
相対添え字付け
相対添え字付けは、データ名または指標名の後に演算子「+」または「-」が付き、正の整数リテラルまたは符号なし整数リテラルが続く算術式を添え字として使用します。演算子「+」と「-」の前後には空白が必要です。添え字として定義された算術式の値は、表要素に対して有効な値である必要があります。
相対添え字付けを使用しても、プログラムが指標の値を変更することはありません。
7.3. 参照変更(部分参照)
参照変更は、データ項目の左端の文字位置(開始行)とデータ項目の長さ(オプション)を指定することにより、データ項目を定義する方法です。
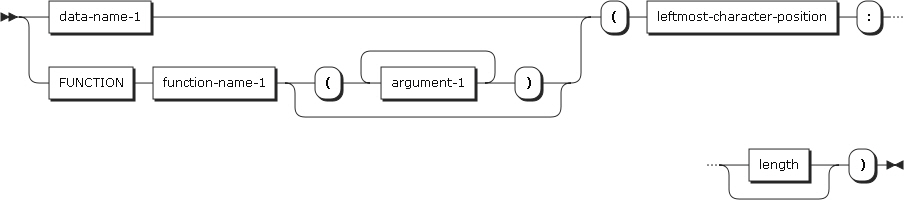
| 項目 | 説明 |
|---|---|
data-name-1 |
DISPLAY用途が明示的または暗黙的に指定されたデータ項目を参照します。 data-name-1は、修飾したり添え字を付けたりすることができます。 左端の文字位置は、data-name-1が英数字テータ項目を参照するとき、そのデータの位置を表します。参照されたデータ項目の各文字の中で一番左が1であり、右方向に1ずつ増えていきます。 data-name-1のデータ記述項目にSIGN IS SEPARATE節が指定されている場合は、符号にも順序をつけます。 |
function-name-1 |
英数字項目を指定します。 |
leftmost-character-position |
算術式である必要があります。 左端の文字の開始位置としては、data-name-1によって参照されるデータ項目の桁数以下の、0以外の正の整数を指定します。 |
length |
算術式である必要があります。算術式の結果は、0以外の正の整数である必要があります。 左端の文字の開始位置と長さの合計から1を引いた値が、data-name-1の桁数以下である必要があります。長さを省略する場合は、data-name-1に対応する桁数が使用されます。 |
参照変更は、data-name-1によって参照されるデータ項目のサブセットであるデータ項目を作成します。このデータ項目は、次の方法で参照先のデータ項目から抽出されます。
-
左端の文字の位置を先に評価した後、数値を取得します。
-
開始点が決まると、長さが計算されます。長さは参照先のデータ項目の長さを超えることはできません。長さを省略した場合、サブセットのデータ項目の位置は、指定された位置から参照先のデータ項目の右端の文字位置まで指定したものとみなされます。
|
位置の指定と長さの計算結果値が有効な範囲内にあるかを特にチェックしません。規則に記述された制限を超える値は保証しません。 |
参照先の評価時には、次の基準が適用されます。
-
参照先に添え字付けの指定がある場合は、添え字の評価の直後に参照変更が評価されます。添え字にALL指定がある場合は、指定されたすべての要素に対して与えられた参照変更が適用されます。
-
関数を参照するときは、参照変更の指定がある場合は関数が先に評価され、その直後に参照変更が評価されます。
以下の例では、WHOLE-NAMEによって参照されたデータ項目の最初の10文字を、FIRST-NAMEによって参照されたデータ項目に転送します。
77 WHOLE-NAME PIC X(25). 77 FIRST-NAME PIC X(10). ... MOVE WHOLE-NAME(1:10) TO FIRST-NAME
以下の例では、WHOLE-NAMEによって参照されたデータ項目の最後の15文字を、LAST-NAMEによって参照されたデータ項目に転送します。
77 WHOLE-NAME PIC X(25). 77 LAST-NAME PIC X(15). ... MOVE WHOLE-NAME(11:) TO LAST-NAME
以下の例では、TABの3番目の項目の4番目と5番目の文字を、SUFFIXという変数に転送します。
01 TABLE-1.
02 TAB OCCURS 10 TIMES PICTURE X(5).
77 SUFFIX PICTURE X(2).
...
MOVE TAB OF TABLE-1 (3) (4:2) TO SUFFIX
7.4. データ部の名前の参照
本節では、データ部で名前を参照する方法について説明します。
単純なデータ参照
COBOLプログラムのデータ項目を参照する最も基本的な方法です。これは、修飾、添え字付け、または参照変更をしないdata-name-1の参照を意味します。単純なデータ参照は、単一の基本項目またはグループ項目を参照できます。以下は、単純なデータ項目の参照形式です。
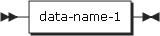
| 項目 | 説明 |
|---|---|
data-name-1 |
任意のデータ項目を記述します。data-name-1は、プログラム内で一意である必要があります。 |
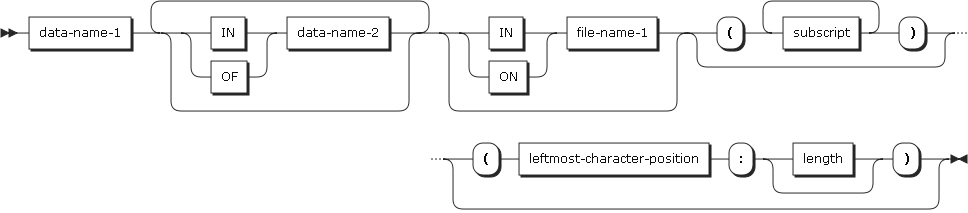
識別子
識別子は、データ項目を参照するための文字列と区切り子の組み合わせを示します。次の形式でデータ項目を参照します。
| 項目 | 説明 |
|---|---|
data-name-1, data-name-2 |
レコードの名前を指定します。 |
file-name-1 |
データ部のFD項目またはSD項目に定義されたものを指定します。 プログラム内で一意である必要があります。 |

| 項目 | 説明 |
|---|---|
data-name-1, data-name-2 |
レコードの名前を指定します。 |
condition-name-1 |
構成セクションを含んでいるプログラム内、またはそのプログラムに含まれているプログラム内で、ステートメントおよび項目によって参照できます。 |
file-name-1 |
データ部のFD項目またはSD項目に定義されたものを指定します。 プログラム内で一意である必要があります。 |
データ項目を参照する際は、以下に注意してください。
-
修飾によってデータ名を一意にできない場合には、データ名が重複しないようにします。
-
特定のプログラムの中で、レベル番号が01、EXTERNAL節を含む項目のサブジェクトとして指定されたデータ名は、EXTERNAL節を含む他のデータ記述項目に指定されたデータ名と同じにできません。
-
データ部内で同じデータ名が指定された任意の2つのデータ項目に関するデータ記述項目にGLOBAL節を含めてはなりません。明示的に参照されるデータ部の名前は、一意に定義するか、または修飾子を使用して一意にする必要があります。参照されないデータ項目は、一意である必要はありません。データ階層の最高レベル(レベル標識のFDまたはSD、またはレベル番号01)で参照される場合は、一意の名前である必要があります。
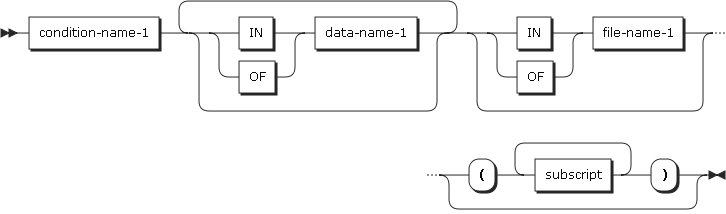
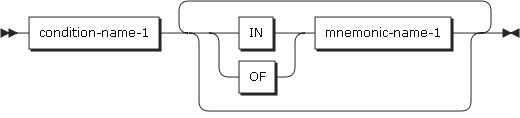
条件名
条件名は、プログラム内で一意に指定するか、または修飾や添え字付けにより一意にする必要があります。条件名を一意にするために修飾する場合は、関連する条件変数を最初の修飾子として使用できます。
修飾を使用する場合、条件変数に関連するデータ・グループ内で定義されたデータ名、または条件変数名自体を使用して、条件名を一意にする必要があります。条件変数を参照するために、指標や添え字を付ける必要がある場合は、その条件名を参照するときにも、同じ組み合わせの指標付けまたは添え字付けを使用します。
| 項目 | 説明 |
|---|---|
condition-name-1 |
定義を含んでいるプログラム内、またはそのプログラムに含まれているサブプログラム内で、ステートメントおよび項目によって参照できます。 |
data-name-1 |
レコードの名前を指定します。 |
file-name-1 |
データ部のFD項目またはSD項目に定義されたものを指定します。 プログラム内で一意である必要があります。 |
mnemonic-name-1 |
簡略名として使用できる値については、SPECIAL-NAMES段落を参照してください。 |
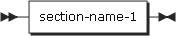
7.5. 手続き部の名前の参照
プログラム内で明示的に参照される段落の名前は、セクション内で一意である必要があります。

| 項目 | 説明 |
|---|---|
section-name-1 |
セクション名は、段落名に使用できる唯一の修飾子です。 段落名が明示的に参照される場合、その段落名はセクション内で重複することができません。 |
paragraph-name-1 |
段落名がセクション名によって修飾される場合、SECTIONというワードを含めることはできません。段落名は、それが属するセクション内で参照される場合は、修飾する必要がありません。あるプログラム内の段落名またはセクション名は、他のプログラムでは参照することができません。 |
7.6. 関数識別子の参照
関数識別子は、関数の評価結果として生成されるデータ項目を参照するための名前です。関数識別子は、文字列と区切り文字を決められた形式で組み合わせて使用します。

| 項目 | 説明 |
|---|---|
FUNCTION |
FUNCTIONというワードを含みます。 |
argument-1 |
ID、リテラル(表意定数を除く)、または算術式を指定します。 |
function-name-1 |
組み込み関数の名前のうちの1つである必要があります。 |
reference-modifier |
英数字タイプの関数に対してのみ指定できます。 |
関数識別子は、任意のステートメントの受信側のオペランドとして使用できます。ただし、以下のような場合には、注意が必要です。
-
整数タイプが必要とされるところで数字タイプを指定することはできません。ただし、特定の数字関数で整数値を参照できる場合は例外とします。
-
整数または数字タイプを参照する関数は、算術式でのみ使用できます。関数を使用するとき、関数の引数として別の関数識別子を指定できる場合、引数として指定された関数識別子の直前の左の括弧は、その関数が外側の関数の引数であることを表します。
-
特に引数を指定する必要がない関数(RANDOMなど)については、正しく解釈されるように注意が必要です。
以下のような場合、AはRANDOM関数の引数とみなされます。
FUNCTION MAX ( FUNCTION RANDOM (A) B )
以下は、AをMAX関数の引数として設定する例です。
FUNCTION MAX (( FUNCTION RANDOM () A) B )
または
FUNCTION MAX ( (FUNCTION RANDOM) (A) B )
または
FUNCTION MAX ( FUNCTION RANDOM A B )
関数識別子を使用する参照の一般的な規則は、以下のとおりです。
-
関数識別子を使用して参照される値は、実行中に参照される時点で決定される値を持つ一時的なデータ項目です。
組み込み関数が指定される場合、一時的なデータ項目は基本データ項目であり、関数のタイプによって詳細が決まります。関数の定義についての詳細は、組み込み関数を参照してください。
-
関数を参照する場合、引数は左から右の順に使用されます。引数自体が関数であるか、関数を含む関数である場合、同じ関数を引数として指定できます。つまり、再帰呼び出しが可能です。
7.7. 明示的または暗黙的な仕様
COBOLプログラム要素は、以下のような明示的または暗黙的な指定が可能です。
-
手続き部の明示的・暗黙的な参照
COBOLプログラムの手続き部のステートメントでデータを明示的または暗黙的に参照することができます。
区分 説明 明示的な参照
手続き部のステートメントで参照先の名前を直接記述する場合や、COPYステートメント、REPLACEステートメントを使用して参照先の名前をコピーしてくる場合をいいます。
暗黙的な参照
手続き部のステートメントで参照先の名前を直接記述せずに、データ項目を参照する場合です。たとえば、PERFORMステートメントを使用するとき、VARYING節、AFTER節、またはUNTIL節の指定がある場合、指定された指標またはリテラルによって参照される場合を暗黙的な参照といいます。このような場合、データ項目はステートメントが実行時に決定され、参照されます。
-
明示的・暗黙的な制御の移動
手続き部では、制御が明示的に移動される場合や、次の実行可能なステートメントがない場合を除いて、プログラムの流れは、ステートメントが記述されている順序で制御されます。このような通常のプログラムの流れを暗黙的な制御の移動と呼びます。
暗黙的な制御の移動は、記述された順序に従ってステートメントからステートメントに制御が移される場合のほかに、通常のプログラムの流れが変更される場合にも発生することがあります。次のようなケースがあります。
-
別のCOBOLステートメントの制御の下で実行されていたプロシージャの最後のステートメントの実行が終了すると、暗黙的に制御が戻ります。(プロシージャの実行を制御するCOBOLステートメントには、MERGE、PERFORM、SORT、およびUSEなどがあります。)また、繰り返し実行を起こすPERFORMステートメントの制御の下である段落が実行される場合で、しかもその段落がPERFORMステートメントの範囲内で最初の段落である場合には、その段落が繰り返し実行されるたびに、PERFORMステートメントに関連する制御メカニズムとその段落の最初のステートメントとの間で暗黙的な制御の移動が行われます。
-
SORTステートメントまたはMERGEステートメントを実行する場合、関連する入出力を定義した部分に制御が移ります。
-
宣言型プロシージャを実行させるCOBOLステートメントのうち1つを実行する場合、その宣言型プロシージャに制御が暗黙的に移ります。
-
宣言型プロシージャの実行が終わると、その宣言型プロシージャを実行させたステートメントに関連する制御メカニズムに制御が暗黙的に戻ります。
+ COBOLでは、プロシージャを分岐するステートメント、プログラムの呼び出し、または条件文の実行により、制御を明示的に移動することができます。詳細については、手続き部を参照してください。
次の実行可能なステートメントとは、上述した規則に従って制御が移動される場合に実行される次のCOBOLステートメントを意味します。
以下の場合には、次に実行可能なステートメントが存在しません。
-
該当プログラムに手続き部がない場合
-
宣言セクションの最後のステートメントの後に続き、そのステートメントが含まれている段落が、他のいずれのCOBOLステートメントの制御の下でも実行されない場合
-
プログラムの最後のステートメントの後に続き、そのステートメントが含まれている段落が、他のいずれのCOBOLステートメントの制御の下でも実行されない場合
-
そのステートメントが別のセクションで実行される有効なPERFORMステートメントの範囲内にあり、宣言セクションの最後のステートメントの後に続くが、その宣言セクションの最後のステートメントが、有効なPERFORMステートメントの出口として定義されたプロシージャの最後のステートメントでない場合
-
COBOLプログラムの外に制御を移動させるSTOP RUNステートメントとEXIT PROGRAMステートメントの後に続く場合
-
COBOLプログラムの外に制御を移動させるGOBACKステートメントの後に続く場合
-
END PROGRAMマーカー
次に実行可能なステートメントがなく、制御がCOBOLプログラムの外に移動されない場合には、CALLステートメントにより実行されたプログラムが呼び出したプログラムで、暗黙的にEXIT PROGRAMステートメントが実行される場合を除いて、プログラムの制御の流れは予測できません。
-
8. プログラムの構造
COBOLソース・プログラムは、正しい構文で記述されたCOBOLステートメントのセットです。
COPYステートメントとREPLACEステートメント、END PROGRAMマーカーを除く、COBOLソース・プログラムのステートメント、項目、およびセクションは、次の4つの部で構成されます。
-
見出し部
-
環境部
-
データ部
-
手続き部
以下は、単一の独立したコンパイル単位を構成するCOBOLプログラムの形式です。
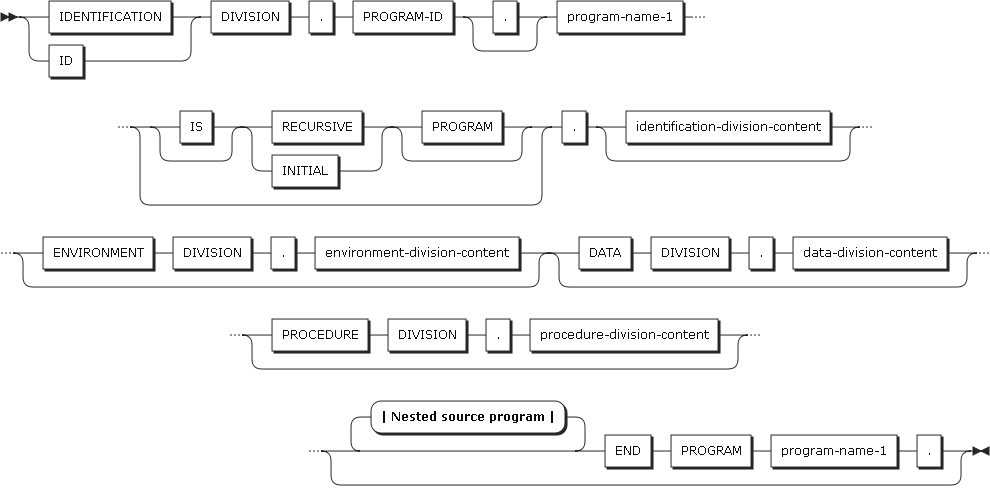
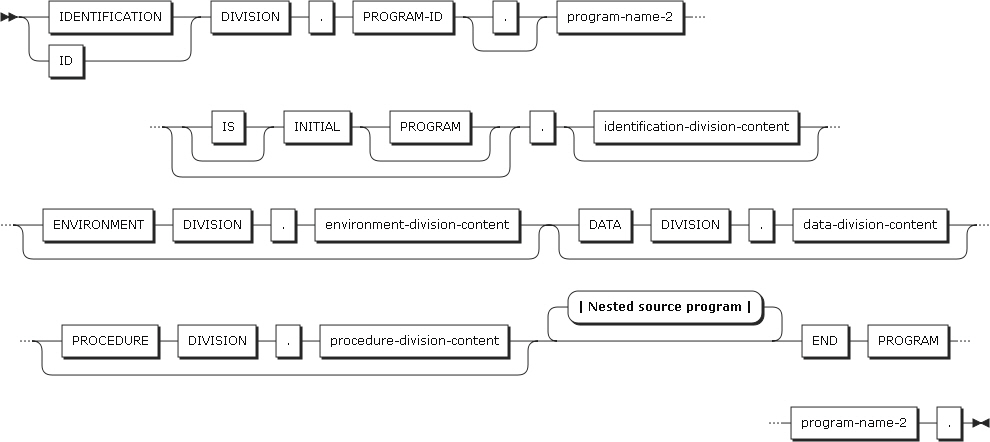
END PROGRAMマーカー
COBOLソース・プログラムは、END PROGRAMマーカーが指定された場所で終了します。ネストされたプログラムがない場合は、ソース・プログラムの記述が終わったところがCOBOLプログラムの終了になります。
-
END PROGRAM program-name
-
END PROGRAMマーカーは、一連のプログラムを区切ります。
-
プログラム名は、見出し部で宣言したプログラム名と一致する必要があります。
-
ネストされたプログラムがなく、単独で実行、終了されるプログラムでは、END PROGRAMマーカーを指定しなくても構いません。
-
ネストされたプログラム
COBOLプログラムは、他のCOBOLプログラムを含むことができ、含まれたプログラムはさらに別のプログラムを含むことができます。これらの中に含まれたプログラムを、ネストされたプログラムと呼びます。ネストされたプログラムは、それを含むプログラムに直接的または間接的に含まれます。
たとえば、プログラムBがプログラムAに含まれている場合、プログラムBを含むプログラムがプログラムAだけである場合は、プログラムBはプログラムAに直接含まれていると表現します。あるプログラムがプログラムAに含まれていて、そのプログラムがさらにプログラムBを含めている場合、プログラムBはプログラムAに間接的に含まれていると表現します。
以下は、プログラムOuter-programがプログラムInner-1を直接含めている例です。
プログラムInner-1はプログラムInner-1aを直接含めており、Outer-programはInner-1aを間接的に含めています。
ID division.
Program-id. Outer-program.
Procedure division.
Call "Inner-1".
Stop run.
ID division.
Program-id. Inner-1.
...
Call Inner-1a.
Stop run.
ID division.
Program-id. Inner-1a.
...
End Inner-1a.
End Inner-1.
End Outer-program.
以下は、ネストされたプログラムのより複雑な例です。
プログラムXは、X1とX2を直接含めており、X11とX12を間接的に含めている最も外側のプログラムです。
|------- ID division. | Program-id. X. | Procedure division. | Display "I'm in X" | Call "X1" | Call "X2" | Stop run. | | |----- ID division. | | Program-id. X1. | | Procedure division. | | Display "I'm in X1" | | Call "X11" | | Call "X12" | | Exit Program. | | | | |--- ID division. | | | Program-id. X11. | | | Procedure division. | | | Display "I'm in X11" | | | Exit Program. | | |--- End Program X11. | | | | |---- ID division. | | | Program-id. X12. | | | Procedure division. | | | Display "I'm in X12" | | | Exit Program. | | |--- End Program X12. | |----- End Program X1 | | | ---- ID division. | | Program-id. X2. | | Procedure division. | | Display "I'm in X2" | | Exit Program. | | ---- End Program X2. |------- End Program X.
プログラム名の命名規則
プログラムの名前は、見出し部のPROGRAM-ID段落で定義します。
プログラム名の命名規則は、以下のとおりです。
-
COMMON属性を持たずに、別のプログラムに直接含まれているプログラムの名前は、そのプログラムを呼び出すプログラムのステートメントでのみ参照することができます。
-
COMMON属性を持ち、別のプログラムに直接含まれているプログラムの名前は、そのプログラムを呼び出すプログラムのステートメントで、あるいはそのプログラムを呼び出すプログラムに直接的または間接的に含まれるプログラムのステートメントで参照することができます。
-
別のプログラムに従属していないプログラムの名前は、実行単位の中の他のどのプログラムのステートメントによっても参照できます。ただし、そのプログラムに直接的または間接的に含まれているプログラムは除きます。
次の例で、Prog AはProg BとProg Cを含めています。
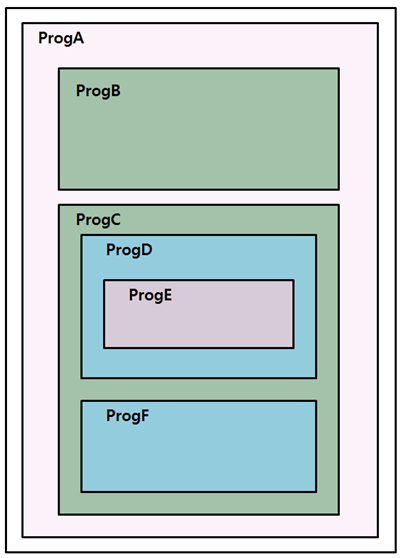
Prog CはProg DとProgFを、Prog DはProg Eを含めています。Prog DがCOMMON属性を持たない場合、Prog Dはそれを直接含めているPcog Cによってのみ参照できます。
Prog DがCOMMON属性を持つ場合は、Prog Dを直接含めているProg Cと、Prog Cが直接含めている任意のプログラムはProg Dを参照することができます。ただし、Prog Dが含めているプログラムは、Prog Dを参照することができません。つまり、Prog DがCOMMON属性を持つ場合には、Prog DはProg CとProg Fによってのみ参照できます。