手続き部
本書では、手続き部(Procedure Division)の構造と各ステートメントの使用方法について説明します。
1. 手続き部の構造
以下は、手続き部の基本構造です。
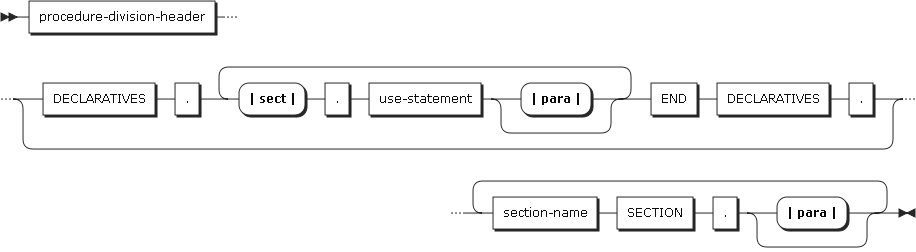

以下は、手続き部の構成要素です。
-
ヘッダー
-
宣言部分
-
プロシージャ
-
算術式
-
条件式
-
ステートメントのカテゴリ
-
ステートメントのオペレーション
1.1. ヘッダー
手続き部のヘッダーは、以下の図のように、USING句とRETURNING句で構成されます。
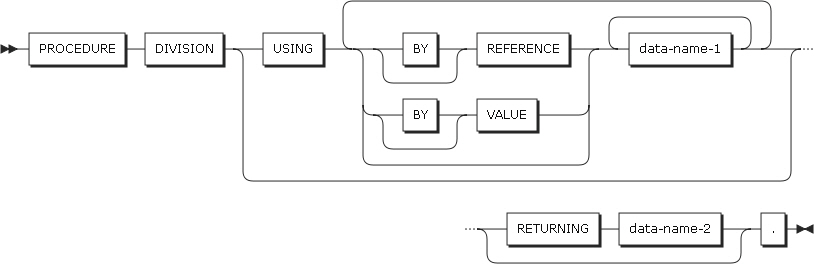
以下は、各設定項目についての説明です。
-
USING句
-
USING句は、プログラムの呼び出し時に、呼び出されたプログラムがパラメータを受け取るために指定します。
-
USINGを介してデータを受け取るためには、プログラムのLINKAGEセクションに、受け取るデータの項目をレベル01またはレベル77の項目として記述します。一方、CALLを使用してサブ・プログラムにデータを転送するためには、呼び出したプログラムのデータ部に転送するパラメータのデータ項目を記述する必要があります。
LINKAGEセクションに指定された項目を参照するには、以下の条件を満たす必要があります。
-
USAGE句に指定されたオペランド
-
SET ADDRESS OF、CALL ... BY REFERENCE ADDRESS OFのオペランド
-
上記の条件を満たしつつ、REDEFINESまたはRENAMESが定義されているオペランド
-
上記の条件を満たしている副項目
-
上記の条件を満たしている条件名と指標名
-
-
USINGを介して非COBOLプログラムとCOBOLプログラムの間でデータを送受信することができます。
-
呼び出すプログラムが渡したパラメータと、呼び出されるプログラムが受け取ったパラメータとの対応関係は、指定したパラメータの名前ではなく位置によって決定されます。呼び出すプログラムと呼び出されるプログラムにおいて、対応される識別子はデータ記述と同じである必要はありませんが、バイト数は一致する必要があります。
-
パラメータの転送方法には、BY REFERENCE(参照による)方法とBY VALUE(値による)方法があります。パラメータの転送方法についての詳細は、CALLを参照してください。
-
-
RETURNING句
-
RETURNING句は、呼び出したプログラムに値を渡すために指定します。
-
data-name2は、プログラムのLINKAGEセクションにレベル01からレベル77の項目として記述されている必要があります。
-
RETURNINGデータ項目は、出力専用のデータ項目です。プログラムの初期状態では、このデータ項目の値を予想することができません。そのため、同データ項目を参照する前に必ず初期化してください。RETURNING句についての詳細は、CALLを参照してください。
-
1.2. 宣言部分
DECLARATIVESセクションは、プログラムの実行中に例外条件が発生した場合、実行するアクションを記述します。
DECLARATIVESセクションは手続き部の冒頭に記述し、すべてのプロシージャは、セクションで分けられる必要があります。それぞれのDECLARATIVESセクションは、USEステートメントで始め、次に例外条件が発生したときに実行されるアクションを記述します。
すべてのDECLARATIVESセクションは、DECLARATIVESとEND DECLARATIVES内に記述する必要があります。
明示的にEND DECLARATIVESを指定したり、または別のDECLARATIVESセクションの始まりであるUSEステートメントがある場合は、そのDECLARATIVESセクションの最後を意味します。USEステートメント自体は実行されず、その代わり、例外が発生したときに実行されるアクションと例外条件を定義します。例外条件が発生してプロシージャが実行されると、制御は例外条件を発生させたルーチンに戻ります。
以下は、宣言型プロシージャの実行規則です。
-
宣言型プロシージャは非宣言型プロシージャから実行できます。
-
非宣言型プロシージャは宣言型プロシージャから実行できます。
-
宣言型プロシージャは、宣言型プロシージャ内に記述されたGO TOステートメントで参照できます。
-
非宣言型プロシージャは、宣言型プロシージャ内に記述されたGO TOステートメントで参照できます。
1.3. プロシージャ
手続き部内のプロシージャは、セクションまたはセクション・グループ、段落または段落グループで構成されています。プロシージャ名は、セクションまたは段落を識別するためのユーザー名です。
-
セクション
セクションは、セクション・ヘッダー、セクション名、優先順位番号、ピリオド(.)で構成されます。
項目 説明 セクション・ヘッダー
セクション・ヘッダーは、セクション名、SECTION、優先順位番号、ピリオドの順で構成されており、省略可能です。セクション・ヘッダーは、END DECLARATIVESの後、または宣言部分がない場合に使用できます
セクション名
セクションを識別するためのユーザー定義語です。手続き部の中で一意である必要があります
優先順位番号
0から99までの数字であり、プログラムの動作には影響を与えません。固定された単位のセグメントまたはセグメントが含まれているセクションを意味します。宣言部分のセクションは、0から49までの番号を有します
-
段落
段落は、段落名、ピリオド、文で構成されます。複数の段落は、必ずピリオドで区切られる必要があります。
項目 説明 段落名
段落を識別するためのユーザー定義語であり、修飾することができます
文
文は、ピリオドで区切られた1つまたは複数のステートメントで構成されます
-
ステートメント
-
ステートメントは、COBOL動詞で始まり、後ろに構文的に有効な識別子、文字列、演算子などで構成されます。
-
プログラムの実行は、手続き部の冒頭に記述されたステートメントから順次実行されます。
-
ネストされたプログラムの開始を意味する見出し部の直前、END PROGRAMまたはファイルの最後が、手続き部の終わりを意味します。
-
-
1.4. 算術式
算術式(Arithmetic expression)は、条件ステートメントや算術ステートメントのオペランドとして使用されます。算術式は、以下のように構成されます。
-
数字基本項目の識別子
-
数字リテラル
-
表意定数ZERO
-
識別子、算術演算子、数字リテラルで構成された算術式
-
算術式、算術演算子で構成された算術式
-
括弧で囲んだ算術式
単項演算子(unary arithmetic operator)は、算術式の前に記述することができます。算術式に記述した識別子とリテラルは、数字基本項目または数字リテラルのいずれかを表す必要があります。
指数式(exponential expression)の結果として正の数と負の数が存在する場合は、正の値を選択します。指数の底が0の場合、指数は0以上である必要があります。そうでなければ、サイズ・エラー条件が発生します。
算術演算子
算術演算子には、2項算術演算子と単項算術演算子があります。以下の表は、各演算子についての説明です。
-
2項演算子
演算子 意味 +
加算
-
減算
*
乗算
/
除算
**
指数
-
単項演算子
演算子 意味 +
+1を乗算する
-
-1を乗算する
演算式の演算順序は、一般的に左から右の順で計算されます。括弧がある場合は、最も内側にある括弧の演算式から行われます。
演算式の優先順位は以下のとおりです。
-
単項演算子
-
指数
-
乗算と除算(乗算演算子と除算演算子は優先順位がなく、演算は左から右へと順番に実行されます)
-
加算と減算(加算演算子と減算演算子は優先順位がなく、演算は左から右へと順番に行われます)
算術式は、単項演算子、左括弧、オペランドで始め、右括弧またはオペランドで終わらせます。1つの識別子またはリテラルで構成することもできます。算術式において、左括弧と右括弧はペアで使用する必要があります。
以下の表では、算術記号の有効な組み合わせを示しています。一番左側の列は、最初に記述される演算子またはオペランドを意味し、2番目の列以降は、次に記述される演算子またはオペランドです。
| 識別子またはリテラル | * / ** + - | 単項演算子(+、-) | 左括弧 ( | 右括弧 ) | |
|---|---|---|---|---|---|
識別子またはリテラル |
○ |
○ |
|||
* / ** + - |
○ |
○ |
○ |
||
単項演算子 +、- |
○ |
○ |
|||
左括弧 ( |
○ |
○ |
○ |
||
右括弧 ) |
○ |
○ |
1.5. 条件式
条件式は、真の値の判別に応じてプログラムで選択的に実行ロジックを変更できるようにします。条件式は、EVALUATE、IF、PERFORM、およびSEARCHステートメントに使用することができます。
条件式は、以下の2つに分けられます。
-
単純条件
-
複合条件
1.5.1. 単純条件
単純条件は、真または偽の値を持ちます。
単純条件には、以下の5種類があります。
-
クラス条件
-
条件名条件
-
比較条件
比較条件は、2つのオペランドを比較します。比較は、以下のように定義されます。
-
2つの英字クラス・オペランド
-
2つの英数字クラス・オペランド
-
2つのDBCSクラス・オペランド
-
2つの数字クラス・オペランド
-
英字クラスのオペランドと英数字クラスのオペランド
-
数字整数のオペランドと英数字クラスのオペランド
-
指標または指標データ項目の比較
-
2つのデータ・ポインター・オペランド
-
2つのプロシージャ・ポインター・オペランド
-
2つの関数ポインター・オペランド
-
英数字グループとDISPLAYまたはDISPLAY-1の使用方法を持つオペランド
比較条件には、以下の2つの形式があります。
-
一般比較条件
-
データ・ポインターの比較条件
-
-
符号条件
-
スイッチ状態条件
クラス条件
データ項目の内容が英字(alphabetic)、小文字の英字(alphabetic-lower)、大文字の英字(alphabetic-upper)、数字(numeric)、DBCS、漢字(KANJI)であるか、または環境部のSPECIAL-NAMES段落で定義されているCLASS節に指定された文字が含まれるかを判別します。
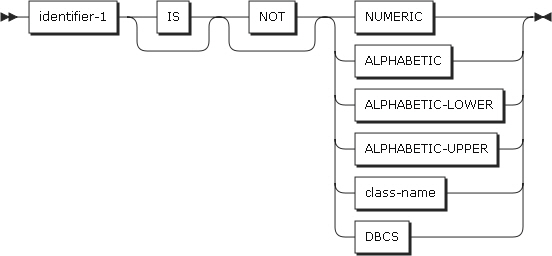
-
identifier-1
-
以下に記述されたUSAGEを持つデータ項目を参照してください。
-
NUMERICが指定された場合 : DISPLAY、COMPUTATIONAL-3、PACKED-DECIMAL
-
DBCSが指定された場合 : DISPLAY-1
-
ALPHABETIC、ALPHABETIC-UPPERまたはALPHABETIC-LOWERが指定された場合 : DISPLAY
-
クラス名が指定された場合 : DISPLAY
-
-
identifier-1が関数識別子である場合は、必ず英数字関数を参照してください。
-
以下のいずれかを設定します。
項目 説明 NOT
真の値を逆にします。
たとえば、NOT NUMERICは、NUMERICクラスの条件が偽であれば、結果が真となります。
NUMERIC
identifier-1が0から9の数字で構成されます。
ALPHABETIC
identifier-1は、大文字と小文字を区別しないアルファベットのAからZと、空白文字で構成されます。
ALPHABETIC-LOWER
identifier-1は、小文字のアルファベットaからzと、空白文字で構成されます。
ALPHABETIC-UPPER
identifier-1は、大文字のアルファベットAからZと、空白文字で構成されます。
class-name
identifier-1は、SPECIAL-NAMES段落内のクラス名に定義された文字で構成されています。
DBCS
identifier-1は、DBCS文字で構成されます。
-
以下の表は、使用可能なデータ項目のタイプとクラス条件の関係を示します。
| identifier-1が示すデータ項目のタイプ | クラス条件の有効な形式 | |
|---|---|---|
英字 |
ALPHABETIC ALPHABETIC-LOWER ALPHABETIC-UPPER クラス名 |
NOT ALPHABETIC NOT ALPHABETIC-LOWER NOT ALPHABETIC-UPPER NOTクラス名 |
英字、 英字編集、 数字編集 |
ALPHABETIC ALPHABETIC-LOWER ALPHABETIC-UPPER NUMERIC クラス名 |
NOT ALPHABETIC NOT ALPHABETIC-LOWER NOT ALPHABETIC-UPPER NOT NUMERIC NOTクラス名 |
外部10進数、 内部10進数 |
NUMERIC |
NOT NUMERIC |
DBCS |
DBCS |
NOT DBCS |
数字 |
NUMERIC クラス名 |
NOT NUMERIC NOTクラス名 |
条件名条件
条件名は、条件変数をチェックして、その値が関連付けられた条件名のどの値と等しいかを判別します。

| 項目 | 説明 |
|---|---|
condition-name-1 |
比較条件を簡単に用いるときに使用されます。条件変数と条件名の値を比較するときの規則は、比較条件の規則に従います。 条件名1が範囲を有する値の場合、条件変数はその値が範囲内にあるかどうかをチェックします。条件変数の値が条件名の値のいずれかに等しいとき、結果は真となります。 |
以下の例は、条件変数と条件名の使用方法を示しています。
01 AGE-GROUP PIC 99. 88 INFANT VALUE 0. 88 BABY VALUE 1, 2. 88 CHILD VALUE 3 THRU 12. 88 TEENAGER VALUE 13 THRU 19.
AGE-GROUPは条件変数であり、INFANT、BABY、CHILDとTEENAGERは条件名です。
以下のIFステートメントは、AGE-GROUPの値をベースにして年齢グループを決定します。
IF INFANT... (Tests for value 0) IF BABY... (Tests for values 1, 2) IF CHILD... (Tests for values 3 through 12) IF TEENAGER... (Tests for values 13 through 19)
一般比較条件
一般比較条件は、2つのオペランドを比較します。オペランドは、識別子、リテラル、算術式、または指標名のいずれかになります。
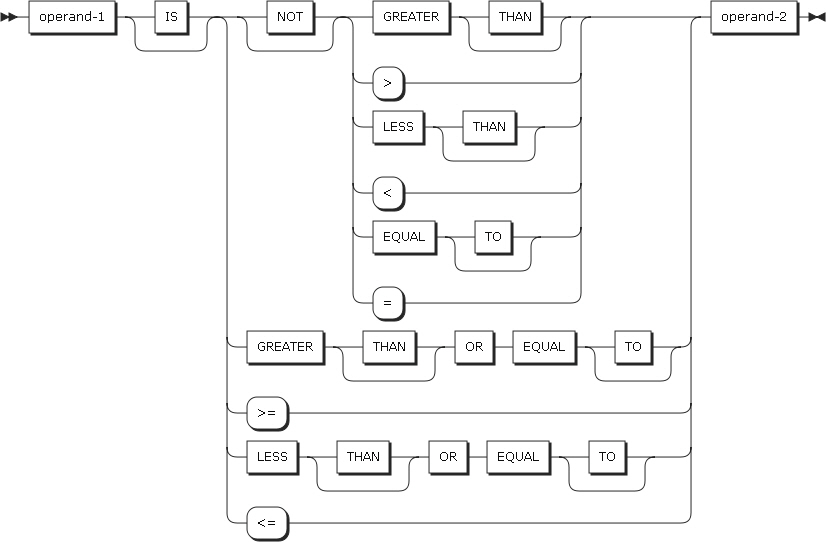
| 項目 | 説明 |
|---|---|
オペランド1 |
比較条件のサブジェクトです。識別子、リテラル、算術式、または指標名のいずれかになります。 |
オペランド2 |
比較条件のオブジェクトです。識別子、リテラル、関数識別子、算術式、または指標名のいずれかになります。 |
一般比較条件で、データ項目、リテラル、表意定数は、以下の比較形式に従って比較されます。
| 比較形式 | 説明 |
|---|---|
英数字 |
2つのオペランドの英数字文字を比較 |
DBCS |
2つのオペランドのDBCS文字を比較 |
数字 |
2つのオペランドの代数値を比較 |
グループ |
一方が英数字グループ項目の場合、2つのオペランドの英数字文字を比較 |
(Int) |
整数項目のみ比較(Alph、Num、グループの比較と結合) |
ブラック |
比較できない |
以下の表は、異なるオペランド・タイプの比較可能なペアを示します。
| データ項目またはリテラルのタイプ | 英数字グループ項目 | 英字項目と英数字項目 | ゾーン10進数項目 | ネイティブ数字項目 | 英数字浮動小数点項目 | DBCS項目 |
|---|---|---|---|---|---|---|
英数字グループ項目 |
グループ |
グループ |
グループ(Int) |
グループ |
グループ |
|
英字データ項目 |
グループ |
Alph |
Alph(Int) |
Alph |
||
英数字項目:
|
グループ |
Alph |
Alph(Int) |
Alph |
||
英数字リテラル |
グループ |
Alph |
Alph(Int) |
Alph |
||
数字リテラル |
グループ(Int) |
Alph(Int) |
Num |
Num |
Num |
|
ゾーン10進数データ項目 |
グループ(Int) |
Alph(Int) |
Num |
Num |
Num |
|
ネイティブ数字項目
数字組み込み関数と 整数組み込み関数 |
Num |
Num |
Num |
|||
Display浮動小数点項目 |
グループ |
Alph |
Num |
Num |
Num |
|
浮動小数点項目 |
Num |
Num |
Num |
|||
DBCSデータ項目 |
グループ |
DBCS |
||||
DBCSリテラル |
グループ |
DBCS |
| 表意定数 | 英数字グループ項目 | 英字項目と英数字項目 | ゾーン10進数項目 | ネイティブ数字項目 | 英数字浮動小数点項目 | DBCS項目 |
|---|---|---|---|---|---|---|
ZERO |
グループ |
Alph |
Num |
Num |
Num |
|
SPACE |
グループ |
Alph |
Alph(Int) |
Alph |
DBCS |
|
HIGH-VALUE, LOW-VALUE QUOTE |
グループ |
Alph |
Alph(Int) |
Alph |
||
シンボリック文字 |
グループ |
Alph |
Alph(Int) |
Alph |
||
ALL英数字リテラル |
グループ |
Alph |
Alph(Int) |
Alph |
||
ALL DBCSリテラル |
グループ |
DBCS |
-
英数字の比較
-
2つのオペランドの1バイト文字を比較します。比較は、照合シーケンスに定義された順序どおり実行されます。
-
2つのオペランドのいずれかが英数字でも英字でもない場合、以下のように実行されます。
-
ゾーン10進数のオペランドは同じサイズのゾーン10進数の英数字項目として扱われます。
-
display浮動小数点項目は、数値ではなく英数字項目として扱われます。
-
-
2つのオペランドのサイズが等しい場合、左端の文字から右端の文字まで比較し、初めて異なる文字が検出されたとき、その文字の照合シーケンスを比較して優先順位を決めます。
-
2つのオペランドのサイズが等しくない場合、短い方のオペランドが長い方のオペランドのサイズほど空白で拡張され、比較が行われます。
-
-
DBCSの比較
英数字比較の規則と同様です。2進照合シーケンスを使用します。
-
数字の比較
2つのオペランドの代数を比較します。
-
グループの比較
2つのオペランドの英数字比較を実行します。英数字の基本データ項目の比較と同様に処理されます。
-
指標の比較
2つの指標項目の比較は、指標項目に含まれているオカレンス番号の比較です。指標をデータ項目またはリテラルと比較する場合、オカレンス番号とデータまたはリテラルの値を比較することになります。
データ・ポインターの比較条件
ポインター・データ項目に対しては、等しいか否かについてのみ比較できます。ポインター・データ項目は、USAGE POINTERとして定義されたデータ項目であるか、ADDRESS OF特殊レジスターです。
比較条件であるIF、PERFORM、EVALUATEは、SEARCH(形式1)ステートメントに使用できます。SEARCH形式2(SEARCH ALL)には使用できません。
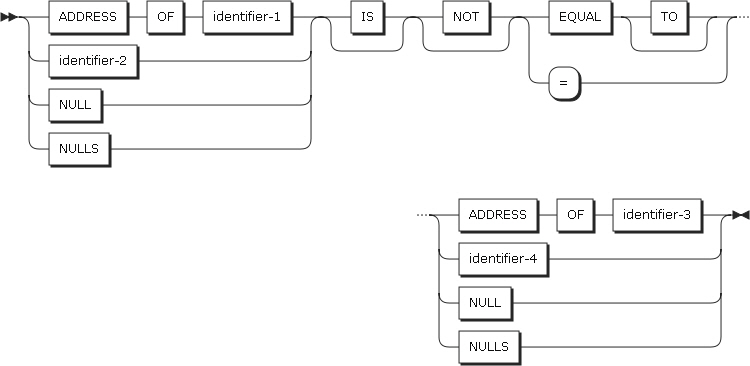
| 項目 | 説明 |
|---|---|
identifier-1、identifier-3 |
レベル66とレベル88を除いて、いかなるデータ項目も使用できます。 |
identifier-2、identifier-4 |
USAGE POINTERとして定義されたデータ項目です。 |
NULL、NULLS |
NULLポインターです。 |
プロシージャ・ポインターと関数ポインターの比較条件
等しいか否がについてのみ比較できます。

| 項目 | 説明 |
|---|---|
identifier-1、identifier-3 |
USAGE PROCEDURE-POINTERまたはFUNCTION-POINTERである必要があります。 |
NULL、NULLS |
NULLポインターです。 |
符号条件
符号条件は、数字オペランドの値が0より大きいか、小さいか、等しいかを判別します。
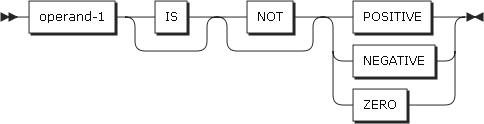
| 項目 | 説明 |
|---|---|
operand-1 |
数字識別子または算術式である必要があります。 0より大きければPOSITIVE、0より小さければNEGATIVE、0に等しければZEROとなります。 符号なしオペランドは、POSITIVEまたはZEROのいずれかです。 |
NOT |
真・偽の判別を逆にします。たとえば、NOT ZEROはオペランドが0でない正または負の値である場合、真となります。 |
スイッチ状態条件
スイッチ状態条件は、UPSIスイッチのオン/オフ状態を定義します。UPSIスイッチの値によって結果が決まります。

| 項目 | 説明 |
|---|---|
condition-name |
特殊名段落に定義されたUPSIスイッチです。 |
1.5.2. 複合条件
複合条件は、論理演算子を使用した単純条件、組合せ条件の結合、または論理否定を使用した条件の否定などで作成されます。それぞれの論理演算子は、前後に空白文字が必要です。
括弧を使用しない場合、以下の順で優先順位が決まります。
-
算術演算子
-
単純条件
-
NOT
-
AND
-
OR
複合条件の真の値は、個々の単純条件の真の値と論理演算子との相互関係に応じて判別されます。複合条件は、以下のいずれかにすることができます。
-
単純否定条件
-
組合せ条件(否定条件も可能)
単純否定条件
単純条件は、論理演算子NOTを使用して真・偽の値を否定することができます。

| 項目 | 説明 |
|---|---|
conditions-1 |
conditions-1の真・偽の判別を反対にします。 conditions-1の値が真であれば、結果は偽となり、conditions-1の値が偽であれば、結果は真となります。 |
condition-1が括弧で囲まれていても結果は同じです。たとえば、以下の2つのステートメントは同じです。
NOT A IS EQUAL TO B NOT ( A IS EQUAL TO B )
組合せ条件
2つ以上の条件が論理演算子により結合され、組合せ条件を作成します。
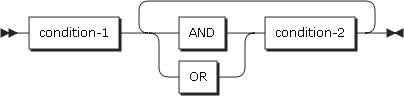
以下の条件が、condition-1またはcondition-2に位置することができます。
-
単純条件
-
単純否定条件
-
組合せ条件
-
複合否定条件(論理演算子NOTの後ろに括弧で囲まれた組合せ条件が続く場合)
以下の表は、論理演算子と条件C1、C2の関係です。
| Value for C1 | Value for C2 | C1 AND C2 | C1 OR C2 | NOT (C1 AND C2) | NOT C1 AND C2 | NOT (C1 OR C2) | NOT C1 OR C2 |
|---|---|---|---|---|---|---|---|
真 |
真 |
真 |
真 |
偽 |
偽 |
偽 |
真 |
偽 |
真 |
偽 |
真 |
真 |
真 |
偽 |
真 |
真 |
偽 |
偽 |
真 |
真 |
偽 |
偽 |
偽 |
偽 |
偽 |
偽 |
偽 |
真 |
偽 |
真 |
真 |
略記組合せ比較条件
比較条件が連続して記述された場合、最初の比較条件を除いて以降の比較条件を、以下の2つの方法のいずれかに省略することができます。
-
サブジェクトの省略
-
サブジェクトと比較演算子の省略

関連のある比較条件の中で、2つの省略形にすることができます。略記条件は、以下のように判別されます。
-
最後に記述されているサブジェクトが省略されたサブジェクトです。
-
最後に記述されている比較演算子が省略された比較演算子です。
以下の表は、省略された条件の例です。
| 略記組合せ比較条件 | 省略されていない表現 |
|---|---|
A = B AND NOT < C OR D |
((A = B) AND (A NOT < C)) OR (A NOT < D) |
A NOT > B OR C |
(A NOT > B) OR (A NOT > C) |
NOT A = B OR C |
(NOT (A = B)) OR (A = C) |
NOT (A = B OR < C) |
NOT ((A = B) OR (A < C)) |
NOT (A NOT = B AND C AND NOT D) |
NOT ((((A NOT = B) AND (A NOT = C)) AND (NOT (A NOT = D)))) |
1.6. ステートメントのカテゴリ
本節では、ステートメント・カテゴリの構成要素について説明します。
1.6.1. 命令ステートメント
命令ステートメント(Imperative statement)とは、プログラムにより無条件で実行されるステートメントです。または、END-ADD、END-DIVIDEのように明示的にステートメントの最後を表す句によって区切られる条件ステートメントです。命令ステートメントは、許可される範囲内であればどこにでも記述できます。
以下は、COBOLの命令ステートメントです。
| 項目 | 説明 |
|---|---|
算術演算 |
ON SIZE ERROR句またはNOT ON SIZE ERROR句が指定されていない場合 |
データの移動 |
[参考] (*) : ON OVERFLOW句またはNOT ON OVERFLOW句が指定されていない場合 |
終了 |
|
入出力 |
[参考] (*): INVALID KEY句またはNOT INVALID KEY句が指定されていない場合 (+): AT END句、NOT AT END句、INVALID KEY句、NOT INVALID KEY句が指定されていない場合 (-) : INVALID KEY句、NOT INVALID KEY句、END-OF-PAGE句、NOT END-OF-PAGE句が指定されていない場合 |
順序付け |
[参考] (*) : AT END句またはNOT AT END句が指定されていない場合 |
プロシージャの分岐 |
|
プログラムのリンケージ |
[参考] (*) : ON OVERFLOW句とON EXCEPTION句またはNOT ON EXCEPTION句が指定されていない場合 |
表操作 |
|
1.6.2. 条件ステートメント
条件ステートメント(conditional statement)は、ステートメントに該当する条件を指定し、それが真の場合に実行されるアクションを記述したステートメントです。
以下は、COBOLの条件ステートメントです。
| 項目 | 説明 |
|---|---|
算術演算 |
|
データの移動 |
|
判断 |
|
入出力 |
|
順序付け |
|
プログラムのリンケージ |
|
表操作 |
|
1.6.4. 明示範囲符
明示範囲符は、手続き部の特定のステートメントの範囲を示します。明示範囲符が指定された条件ステートメントは命令ステートメントとみなされ、命令ステートメントの規則に従う必要があります。
以下は、手続き部で使用される明示範囲符です。
-
END-ADD
-
END-CALL
-
END-COMPUTE
-
END-DELETE
-
END-DIVIDE
-
END-EVALUATE
-
END-IF
-
END-MULTIPLY
-
END-PERFORM
-
END-READ
-
END-REWRITE
-
END-RETURN
-
END-SEARCH
-
END-START
-
END-STRING
-
END-SUBTRACT
-
END-UNSTRING
-
END-WRITE
1.7. ステートメント操作
本節では、算術演算を実行したり、データを操作したりするステートメントで、共通して使用する句について説明します。
1.7.1. CORRESPONDING句
CORRESPONDING句をADD、SUBTRACT、MOVEステートメントに記述した場合、指定したグループ・データ項目のADD、SUBTRACT、MOVEの操作を同じ名前の基本データ項目に対して実行することができます。
CORRESPONDINGキーワードの後に記述するデータ項目は、グループ項目を指定する必要があります。以下では、識別子-1は送信グループ項目を、識別子-2は受信グループ項目を意味します。
識別子-1と識別子-2に従属されたデータ項目は、以下の条件が満たされれば操作が行われます。
-
ADDステートメントまたはSUBTRACTステートメントで、2つの基本データ項目は数字データ項目でなければなりません。それ以外のデータ項目は無視されます。
-
グループに従属された副データ項目は同じ名前を持ち、識別子-1と識別子-2の名前を除いた修飾子も同じである必要があります。
-
FILLERは除外されます。
-
識別子-1と識別子-2を、レベル66、レベル77、レベル88の指標データ項目または参照変更に記述することができません。
-
識別子-1または識別子-2を、USAGE POINTER、USAGE FUNCTION-POINTER、USAGE PROCEDURE-POINTERとして記述することができません。
-
識別子-1または識別子-2に従属された項目は、USAGE POINTER、USAGE PROCEDURE-POINTER、REDEFINES、RENAMES、OCCURSが指定されていると、処理対象から除外されます。
1.7.3. ROUNDED句
小数点位置合わせの後、算術演算の結果はその値が保存される項目に記述された桁数と比較されます。そのとき、結果の値が指定された桁数を超えると、超過分の切り捨てが行われます。ただし、ROUNDED句が指定されている場合、超えた桁数の最上位数字が5以上であれば、四捨五入が適用されます。
結果の値が保存される項目のPICTURE節の結果の値が指定された桁数を超える場合、切り捨てあるいは四捨五入が行われます。浮動小数点の算術演算は、ROUNDED句の指定と関係なく、常に四捨五入が適用されます。
1.7.4. SIZE ERROR句
サイズ・エラーは、以下の条件で発生します。
-
算術演算の結果の絶対値が、結果を保存するフィールドの最大値を越えた場合
-
0による除算が行われた場合
サイズ・エラーは、中間結果ではなく、最終結果にだけ適用されます。USAGE BINARY、COMP、COMP-4、COMP-5のデータ項目が結果として保存できる最大値は、そのデータ項目に指定されたPICTURE文字列によって決まります。
ROUNDED句が指定されている場合は、サイズ・エラーをチェックする前に丸めが行われます。
サイズ・エラー条件が発生した後の動作は、ON SIZE ERROR句の指定に応じて異なります。
-
ON SIZE ERROR句が指定されておらず、サイズ・エラーが発生した場合は、切り捨て規則が適用され、その値が結果に保存されます。
-
ON SIZE ERROR句が指定されており、サイズ・エラー条件が発生した場合、算術の結果は保存されず、ON SIZE ERROR句に指定した命令ステートメントが実行されます。その後、制御は算術ステートメントの次に記述されたステートメントに移動されます。
ADD CORRESPONDINGステートメントとSUBTRACT CORRESPONDINGステートメントに対して個々の算術演算を実行するときにサイズ・エラー条件が発生すると、それらの演算がすべて完了しない限り、ON SIZE ERROR句に指定された比較条件ステートメントは実行されません。
NOT ON SIZE ERROT句が指定されており、算術演算の処理時にサイズ・エラー条件が発生しない場合は、NOT ON SIZE ERROR句に記述された命令ステートメントが実行されます。
1.7.5. 算術ステートメント・オペランド
算術演算の間、コンパイラーは必要に応じてデータの変換や小数点の位置合わせを実行するため、算術ステートメント・オペランドが同じである必要はありません。
-
オペランドのサイズ
オペランドは、10進数の31桁まで指定可能です。
すべての算術ステートメントにおいて最終結果の精度を高めるため、整数の桁数と小数部の桁数を十分に指定する必要があります。
-
複合オペランドは、オペランドの間の小数部の桁数を合わせ、その結果により作成されるデータ項目です。コンパイラー内部で算術処理に使用されます。
たとえば、以下のようなデータ項目で加算算術を行う場合、コンパイラー内部で各オペランドをPIC 9(12)V9(7)のようなデータ項目に変換して算術を実行します。
A PIC 9(7)V9(5) c PIC 9(11)V99 B PIC 9(12)V9(3) ADD A B TO C
-
オペランドのオーバーラップ
算術ステートメントのオペランドが記憶装置を共有する場合(つまり、オペランドがオーバーラップされている場合)、算術実行結果は保証されません。
-
複数の結果
算術ステートメントが複数の項目に実行結果を保存する場合、概念的には以下のとおり処理されます。
-
TOまたはFROMの前に記述された算術演算を実行した中間結果を一時変数に保存します。
-
一時変数に保存された中間結果とオペランドで指定された項目について算術演算を実行した後、その結果を保存します。
-
1.7.6. データ操作ステートメント
以下のステートメントは、データを移動または検査します。
-
ACCEPT
-
INITIALIZE
-
INSPECT
-
MOVE
-
READ
-
RELEASE
-
RETURN
-
REWRITE
-
SET
-
STRING
-
UNSTRING
-
WRITE
|
ステートメントの送信と受信フィールドのストレージを共有している場合、結果を予測することができません。 |
1.7.7. 入出力ステートメント
入出力ステートメントは、ファイルにデータを保存したり、ファイルからデータを取得したりします。COBOLでファイルに読み書きするデータの単位はレコードです。環境部とデータ部にファイルがどのように記述されているかによって、手続き部で使用可能な入出力ステートメントが決まります。
1.7.8. 共通の処理機能
以下のような共通の処理機能があります。
-
ファイル状態キー
ファイル制御項目でFILE STATUS節を記述した場合、ファイルに対するステートメントが実行された後、その結果が記述されたファイル状態キー(FILE STATUS KEY節により指定された2文字のデータ項目)に保存されます。この値は、EXCEPTION/ERROR宣言、INVALID KEY句、またはAT END句が実行される前に保存されます。
2つのファイル状態キー・データ名があります。1つはFILE STATUS節のデータ名-1です。これは、2つの文字を持っており、最初の文字はファイル状態キー1であり、2番目の文字はファイル状態キー2となります。
以下は、ファイル状態キーの値についての説明です。
ファイル状態キー 説明 00
正常終了された場合です。
02
指標ファイルに適用されます。正常終了であり、重複キーが発生した場合です。
07
正常終了であり、NO REWIND句、REEL/UNIT句またはFOR REMOVAL句を持つCLOSEステートメント、あるいはNO REWIND句を持つOPENステートメントに対して、ファイルがテープでない場合です。
10
AT END条件です。順次READステートメントを実行しましたが、これ以上レコードが存在しない場合です。
14
AT END条件です。順次READステートメントが相対ファイルで実行されましたが、相対キーが範囲を超えた場合です。
22
無効キー条件です。相対ファイルに書き込む場合と指標ファイルに書き込みまたは再度書き込みする場合です。
23
無効キー条件です。READステートメント、STARTステートメントに対し、キーに該当するレコードがファイルに存在しない場合です。
37
順次データセットにランダム・アクセスする場合、または相対ファイルに拡張モードを使用した場合です。
38
CLOSE WITH LOCKで終了されたファイルにOPENステートメントを使用した場合です。
39
COBOLプログラムに記述されたファイルの属性と物理ファイルの属性が異なる場合です。
(RECORD FORMAT、ECORD LENGTH、FILE ORGANIZATIONなど)
41
開こうとするファイルがすでに開いている場合です。
42
開いていないファイルを閉じる場合です。
43
順次アクセス・モードで、REWRITEステートメントまたはDELETEステートメントを実行するとき、最後に実行された入出力ステートメントがREADステートメントでない場合です。
44
RECORD IS VARYING節のファイルに対し、レコード長の範囲を超えたレコードの書き込みまたは再書き込みを試みた場合です。
46
順次READステートメントを実行しようとしたが、前のREADステートメントがAT END条件で終了され、次のレコードに対するファイル位置指示子が設定されなかった場合です。
47
READステートメントを実行しようとしたが、ファイルがINPUTまたはI-Oモードでオープンされなかった場合です。
48
WRITEステートメントを実行しようとしたが、ファイルがOUTPUT、I-OまたはEXTENDモードでオープンされなかった場合です。
49
DELETEステートメントまたはREWRITEステートメントを実行しようとしたが、ファイルがI-Oモードでオープンされなかった場合です。
92
READステートメントを実行するときに読み込んだレコード長が、COBOLプログラムに記述されている長さより大きい場合です。
もう1つのファイル状態キー・データ名は、FILE STATUS節のdata-name-8です。この値は使用されません。
-
無効キー条件
START、READ、WRITE、REWRITE、またはDELETEの各ステートメントの実行中に、無効キー条件が発生する可能性があります。無効キー条件が発生すると、以下の順で動作が行われます。
-
ファイル制御項目にFILE STATUS節が記述されている場合、無効キー条件に該当する値がファイル状態キーに保存されます。
-
INVALID KEY句が記述されている場合、その句に記述されている命令ステートメントが実行されます。同ファイルに対して記述されたEXCEPTION/ERROR宣言型プロシージャは実行されません。
-
INVALID KEY句が記述されておらず、このファイルに対して記述された使用可能なEXCEPTION/ERROR宣言型プロシージャが存在する場合は、そのプロシージャが実行されます。NOT INVALID KEY句は無視されます。
-
2. ステートメント
以下は、ステートメントの一覧です。詳しい説明については、各節の内容を参照してください。
| ステートメント | 説明 |
|---|---|
記述された識別子が参照するデータ領域にデータまたはシステムの日付関連情報を転送します。 |
|
2つ以上のオペランドを加算した結果を特定のオペランドに保存します。 |
|
プログラムの実行中に特定のプログラムから別のプログラムにプログラムの制御を移します。 |
|
オペランドで指定したプログラムを初期状態にするために使用します。 |
|
ファイルの処理を終了します。 |
|
算術演算式の結果を1つ以上のデータ項目に保存します。 |
|
プログラム内でいかなる処理も実行しません。 |
|
指標ファイルまたは相対ファイルのレコードを削除します。 |
|
各オペランドの内容を出力装置に転送します。 |
|
数字データ項目またはリテラルをINTO以降に指定したデータ項目で除算を行い、商を保存します。 |
|
サブプログラムを呼び出すとき、PROGRAM-IDに指定したプログラム名やファイル名以外に、別の名前でサブプログラムを呼び出すために設定するエントリー・ポイントです。 |
|
ネストされたIFステートメントの簡単な使用を提供します。 |
|
プロシージャの最後です。 |
|
現在の段落を終了し、プログラムの制御を次のプロシージャに渡します。 |
|
呼び出されたプログラムを終了し、プログラムの制御を呼び出し側プログラムに戻します。 |
|
サブプログラム内ではプログラムの制御をメインプログラムに渡し、メインプログラムではプログラムを終了する機能を行います。 |
|
プログラムの制御を手続き部内の別の位置に移します。 |
|
条件を評価し、その結果に従って処理します。 |
|
identifier-1に記述したカテゴリに従って、特定の値をidentifier-1に設定するか、REPLACING句が指定されている場合は、identifier-2またはliteral-1の値をidentifier-1に設定します。 |
|
データ項目内で特定の文字のオカレンスを数えたり、様々なタスクを実行します。 |
|
ソートされたファイルをマージします。 |
|
特定の記憶領域から別の1つまたは複数の記憶領域に移動します。 |
|
数字項目を乗算して、その結果を指定したデータ項目に保存します。 |
|
ファイルの操作を開始します。 |
|
プログラムの実行中にプログラムの制御を明示的に1つ以上の別のプロシージャに移すときに使用します。 |
|
順次アクセスの場合、ファイル内の次のレコードを読み込みます。 |
|
ソートまたはマージ処理を開始する前に、レコードをソート処理領域に転送します。 |
|
ソートまたはマージ処理を終了した後、レコードをソート処理領域から出力プロシージャに転送します。 |
|
既存の指標ファイルまたは相対ファイルのレコードを置き換えます。 |
|
指定された条件を満たす要素を検索するために、関連する指標を変更します。 |
|
表を管理するための指標項目の値を指定するか、指標項目を指定した値で増やしたり減らしたりします。 |
|
1つ以上のファイルからレコードを受け取り、記述されたキーに従ってソートします。 |
|
指標ファイルまたは相対ファイル内で、次のレコードを読み込むためのレコードの位置を設定します。 |
|
プログラムの実行を一時的または永久的に停止します。 |
|
2つ以上のデータ項目やリテラルの内容の一部または全部をまとめて、1つのデータ項目として構成します。 |
|
1つの数字項目または、2つ以上の数字項目の合計から、FROMの後に指定された数字データ項目を減算し、その結果をFROMの後に指定されたデータ項目に保存します。 |
|
送り出しフィールドの中の連続したデータを、複数の受け取りフィールドに分割することができます。 |
|
出力ファイルにレコードを書き込みます。 |
|
データをXML形式に変換します。 |
|
XMLPARSEコンパイラー・オプションの設定によるCOBOL言語インターフェースです。 |
2.1. ACCEPT
ACCEPTステートメントは、記述された識別子が参照するデータ領域にデータまたはシステムの日付関連情報を転送します。転送により入力されるデータの編集やエラー・チェックは行われません。
データ転送
データをFROM句に記述された入力装置からidenfifier-1により参照されるデータ項目に転送します。FROM句が省略されると、システム入力装置が想定されます。
形式1は、オペレーターの介入が必要なプログラム状況で有用です。オペレーターは、応答として適切なメッセージを提供する必要があります。

以下は、ステートメントの各設定項目についての説明です。
-
identifier-1
-
データが転送される領域です。
-
以下のデータ項目になることができます。
-
英数字グループ項目
-
USAGEがDISPLAYまたはDISPLAY-1である基本データ項目
-
-
-
mnemonic-name-1
SPECIAL-NAMES段落内でenvironment-name(環境名)として記述された入力装置を指定します。
-
environment-name-1
入力データのソースを指定します。CONSOLE、SYSINとなることができます。
システム日付関連情報の転送
DATE、DATE YYYYMMDD、DAY、DAY YYYYDDD、DAY-OF-WEEKまたはTIMEデータ項目に含まれているシステム情報をidentifier-2が参照するデータ項目に転送します。この転送は、CORRESPONDING句が存在しないMOVEステートメントの規則に従います。
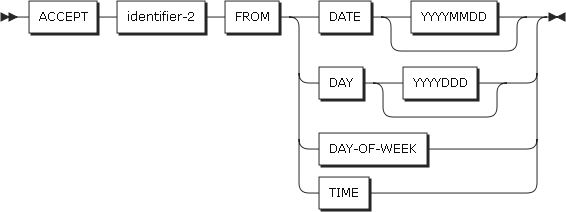
-
identifier-2
-
以下のデータ項目になることができます。
-
英数字グループ項目
-
-
以下のいずれかのカテゴリに属する基本データ項目です。
-
英数字
-
英数字編集
-
数字編集(with USAGE DISPLAY)
-
数字
-
内部浮動小数点
-
外部浮動小数点(with USAGE DISPLAY)
-
-
形式2は、曜日と時刻の2つの形式で現在の日付を取得します。現在の日付と時刻は、組み込み関数のCURRENT-DATEを使用して取得することもできます。
DATE、DATE YYYYMMDD、DAY、DAY YYYYDDD、DAY-OF-WEEK、TIME
DATE、DATE YYYYMMDD、DAY、DAY YYYYDDD、DAY-OF-WEEK、TIMEは、暗黙的にUSAGE DISPLAYを有するデータ項目です。
| 項目 | 説明 |
|---|---|
DATE |
PICTURE 9(6)と指定されます。左から2桁は年、次の2桁は月、その次の2桁は日を示します。たとえば、2012年4月30日は120430となります。 |
DATE YYYYMMDD |
PICTURE 9(8)と指定されます。4桁の年を表しており、左から4桁は年、次の2桁は月、その次の2桁は日を示します。たとえば、2012年4月30日は20120430となります。 |
DAY |
PICTURE 9(5)と指定します。左から2桁は年、次の3桁は日を示します。3桁の日は、1月1日からの日数です。たとえば、2012年4月30日は12121となります。 |
DAY YYYYDDD |
PICTURE 9(7)と指定されます。4桁の年を表しており、左から4桁は年、次の3桁は日を示します。3桁の日は、1月1日からの日数です。たとえば、2012年4月30日は2012121となります。 |
DAY-OF-WEEK |
PICTURE 9(1)と指定されます。曜日を数字で示しており、月、火、水、木、金、土、日にそれぞれ1、2、3、4、5、6、7が対応されます。たとえば、水曜日は3となります。 |
TIME |
PICTURE 9(8)と指定されます。時間を表しており、左から2桁は時、次の2桁は分、その次の2桁は100分の秒を示します。たとえば、午後2時41分は14410000となります。 |
2.2. ADD
ADDステートメントは、2つ以上のオペランドを加算した結果を特定のオペランドに保存します。
-
形式1
形式1は、TOの前に記述された識別子またはリテラルを加算した結果が、TOの後に記述されたidentifier-2と加算され、identifier-2に保存されます。このような処理は、identifier-2のに指定された識別子の数の分だけ、左から右へと繰り返されます。
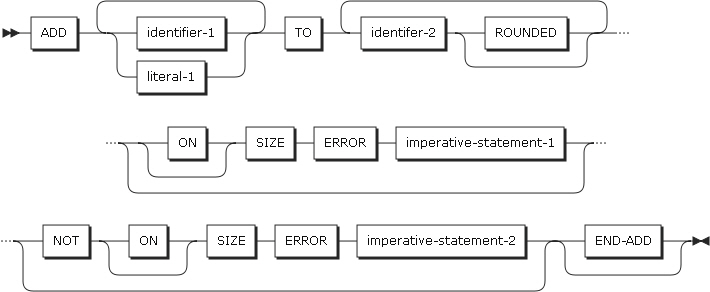 ADDステートメントの形式1
ADDステートメントの形式1 -
形式2
形式2は、GIVINGの前に記述されたオペランドを加算した結果が、identifier-3に記述されたオペランドに保存されます。
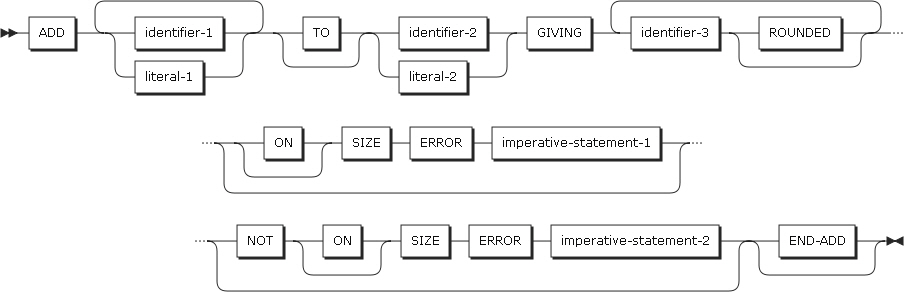 ADDステートメントの形式2
ADDステートメントの形式2 -
形式3
形式3は、identifier-1の基本データ項目が加算され、対応するidentifier-2の基本データ項目に保存されます。
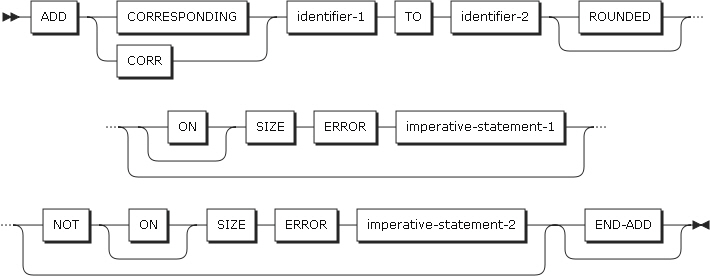 ADDステートメントの形式3
ADDステートメントの形式3
以下は、ステートメントの各設定項目についての説明です。
-
識別子(identifier)
-
形式1では、すべて基本数字項目である必要があります。
-
形式2では、GIVINGの後に記述した識別子を除き、すべて基本数字項目である必要があります。GIVINGの後に記述した識別子は、基本数字項目または、数字編集項目でなければなりません。
-
形式3では、英数字グループ項目である必要があります。
-
-
リテラル
-
すべて数字リテラルである必要があります。
-
-
ROUND句
-
ROUNDED句については、ROUNDED句を参照してください。
-
-
SIZE ERROR句
-
SIZE ERROR句については、SIZE ERROR句を参照してください。
-
-
CORRESPONDING句
-
CORRESPONDING句については、CORRESPONDING句を参照してください。
-
-
END-ADD句
-
END-ADD句は、ADDステートメントの範囲を明示的に示すときに使用します。END-ADD句は、別の条件ステートメントにADDステートメントが含まれたときに使用できます。
-
2.3. CALL
CALLステートメントは、プログラムの実行中に特定のプログラムから別のプログラムにプログラムの制御を移します。CALLステートメントを使用して別のプログラムを呼び出すプログラムを呼び出し側プログラムといい、それに対応されるのが、呼び出されるプログラムです。
呼び出されるプログラムもCALLステートメントを使用して別のプログラムを呼び出すことができます。ただし、直接または間接的に自身のプログラムを呼び出すためには、RECURSIVE節で定義されたプログラムである必要があります。
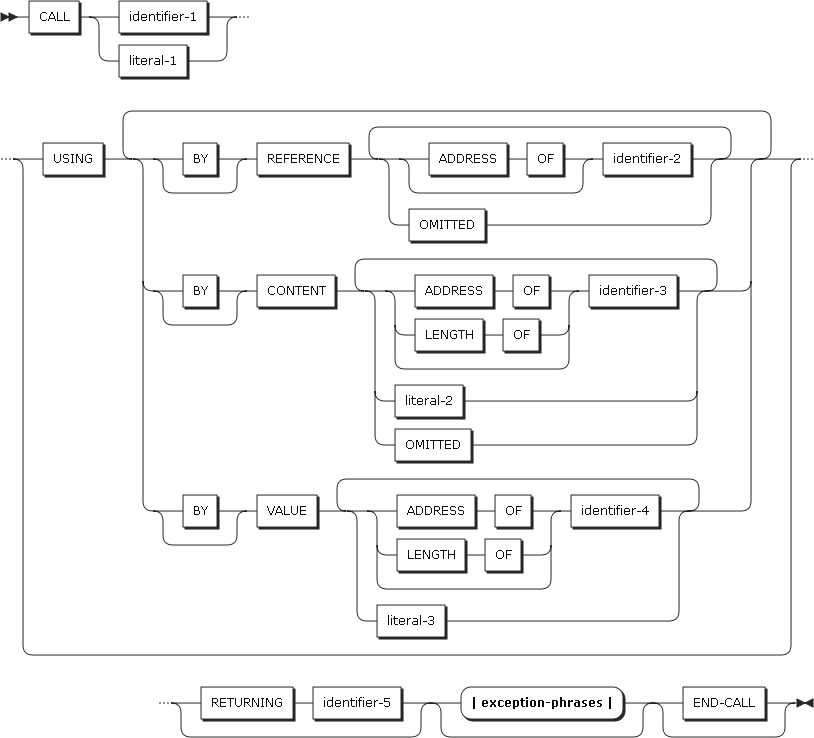


以下は、ステートメントの各設定項目についての説明です。
-
identifier-1、literal-1
-
identifier-1は、プログラム名を指定できるように英数字、英数または数字で宣言されている必要があります。
-
identifier-1は、ウィンドウ日付フィールドになれません。literal-1の場合は英数字リテラルでなければなりません。
-
USAGE TYPEは、DISPLAY形式である必要があります。
-
呼び出されるプログラムを手続き部の最初から実行する場合は、literal-1またはidentifier-1のデータ値には、呼び出されるプログラムの識別部門に定義したプログラム名を指定しなければなりません。
手続き部の最初ではなく、ENTRYステートメントに指定された特定の部分から実行する場合は、呼び出されるプログラムのENTRYステートメントに宣言した名前を指定する必要があります。
-
-
procedure-pointer-1、function-pointer-1
-
有効なプログラム・エントリー・ポイントを有するデータ項目である必要があります。
-
-
USING句
-
USING句は、呼び出されるプログラムに渡される引数を指定します。呼び出されるプログラムの手続き部またはENTRYステートメントの引数の数と、USING句の引数の数は同じである必要があり、引数の順序どおり渡されます。USING句で宣言された引数の値は、呼び出されるプログラムの実行中にのみ有効です。
-
BY CONTENT句、BY REFERENCE句、BY VALUE句は、別のBY CONTENT句、BY REFERENCE句、BY VALUE句が現れるまでのみ適用されます。BY CONTENT句、BY VALUE句が存在しない場合は、デフォルトとしてBY REFENCE句が想定されます。
-
-
BY REFERENCE句
-
BY REFERENCE句は、呼び出し側プログラムからデータ項目のコピーではなく、データ項目のアドレスの値を引数として渡します。したがって、呼び出されるプログラムから呼び出し側プログラムへ渡した引数の値を変更すると、呼び出されるプログラムの終了後にも変更された状態で残ることになります。
-
以下の項目を設定します。
項目 説明 identifier-2
データ部で定義された任意のレベルのデータ項目にすることができます。
file-name-1
QSAMファイルのファイル名です。
ADDRESS OF identifier-2
identifier-2は、LINKAGEセクションで定義されたレベル01またはレベル77のデータ項目である必要があります。
OMITTED
データ項目を引数として渡さないことを意味します。
-
-
BY CONTENT句
-
BY CONTENT句は、呼び出し側プログラムから呼び出されるプログラムへ引数を渡すとき、一時ストレージにコピーしてから値を渡します。したがって、呼び出されるプログラムで引数を変更しても、呼び出し側プログラムのデータは変更されません。
-
以下の項目を設定します。
項目 説明 identifier-3
データ部で定義された任意のレベルのデータ項目に指定することができます
literal-2
英数字リテラル、表意定数、DBCSリテラルに指定することができます。
LENGTH OF 特殊レジスター
LENGTH OF 特殊レジスターの詳細については、COBOLワードの特殊レジスター(Special Register)のLENGTH OFを参照してください。
ADDRESS of identifier-3
identifier-3は、LINKAGEセクション、WORKING-STORAGEセクション、LOCAL-STORAGEセクションで定義したレベル66またはレベル88でないデータ項目である必要があります。
OMITTED
データ項目を引数として渡さないことを意味します。
-
-
BY VALUE句
-
BY VALUE句は、呼び出し側プログラムから呼び出されるプログラムにデータの値自体を引数として渡します。したがって、呼び出されるプログラムで引数を変更しても、呼び出し側プログラムのデータは変更されません。
-
BY VALUE句は、COBOLプログラムと非COBOLプログラム(C言語など)とのインターフェースのために適用されましたが、COBOLプログラムとCOBOLプログラムの間にも使用することができます。
-
以下の項目を設定します。
項目 説明 identifier-4
データ部で定義された基本データ項目である必要があります。
以下のいずれかにすることができます。
-
バイナリ(USAGE BINARY、COMP、COMP-4、COMP-5)
-
浮動小数点(USAGE COMP-1、COMP-2)
-
関数ポインター(USAGE FUNCTION-POINTER)
-
ポインター(USAGE POINTER)
-
プロシージャ・ポインター(USAGE PROCEDURE-POINTER)
-
1バイトの英数字文字(PIC XまたはPIC Aなど)
BY VALUE句が使用される場合、以下の項目も可能です。
-
USAGE DISPLAYの参照変更項目と長さ1
-
SHIFT-INとSHIFT-OUT特殊レジスター
-
LINAGE-COUNTER特殊レジスター(USAGE BINARYの場合)
ADDRESS OF identifier-4
LINKAGEセクション、WORKING-STORAGEセクション、LOCAL-STORAGEセクションで宣言したレベル66、レベル88でないデータ項目である必要があります。
LENGTH OF 特殊レジスター
LENGTH OF 特殊レジスターが使用されると、BY VALUEはPIC 9(9)バイナリとして指定されます。
literal-3
以下のいずれかにする必要があります。
-
数字リテラル
-
表意定数ZERO
-
1文字の英数字リテラル
-
シンボリック文字
-
1バイトの表意定数(SPACE、QUOTE、HIGH-VALUE、LOW-VALUE)
以下の規則が適用されます。
-
ZEROは、数値として扱われます。(フルワード・バイナリのゼロが渡されます)
-
リテラルが固定小数点である場合、9桁以下の精度を持ちます。
-
リテラルが浮動小数点の場合は、8バイトの内部浮動小数点(COMP-2)の値が渡されます。
-
-
-
RETURNING句
-
以下の項目を設定します。
項目 説明 identifier-5
identifier-5は、データ部に定義されたデータ項目を指定します。呼び出されるプログラムで指定した戻り値が保存されます。
-
呼び出されるプログラムをCOBOLまたはCプログラムで作成した場合、CALLステートメントのRETURNING句を指定することができます。COBOLで作成されたサブプログラムを呼び出すCALLステートメントでRETURNING句を指定するときは、以下の内容に注意しなければなりません。
-
呼び出されるプログラムでは、手続き部にRETURNING句を必ず指定します。
-
呼び出し側プログラムのRETURNING句に指定したidentifier-5と、呼び出されるプログラムで指定したRETURNING句は、PICTURE、USAGE、SIGN、SYNCHRONIZED、JUSTIFIED、BLANK WHEN ZERO節が同じでなければなりません。(PICTURE節は通貨記号が異なる場合があり、ピリオドとコンマは、DECIMAL POINT IS COMMA節により異なる場合があります)
-
identifier-5の戻り値が、USAGE INDEX、POINTER、FUNCTION-POINTER、PROCEDURE-POINTERの場合、内部的にidentifier-5のSETステートメントを介して変更されたかのように作用します。
-
identifier-5の戻り値がその他の場合は、内部的にidentifier-5のMOVEステートメントを介して変更されたかのように作用します。
-
例外またはオーバーフローが発生すると、identifier-5は変更されません。identifier-5は、参照変更されてはなりません。
-
RETURN-CODEは、RETURNING句が存在するCALLステートメントが実行されるときは、セットされません。
-
-
-
ON EXCEPTION句
-
呼び出されるプログラムの実行中に例外が発生する場合、以下のいずれかに処理されます。
-
ON EXCEPTION句が存在する場合、プログラムの制御はimperative-statement-1に移ります。
-
CALLステートメントにON EXCEPTION句が存在しない場合、NOT ON EXCEPTIONがあっても無視されます。
-
-
-
NOT ON EXCEPTION句
-
呼び出されるプログラムが正常に実行されると、プログラムの制御はimperative-statement-2に移されます。
-
-
ON OVERFLOW句
-
ON OVERFLOW句は、ON EXCEPTION句と同じ処理を実行します。
-
-
END-CALL句
-
END-CALL句は、明示的にCALLステートメントが終了されたことを指定します。
-
2.4. CANCEL
CANCELステートメントは、オペランドで指定したプログラムを次回の呼び出し時に初期状態にするために使用します。
COBOLプログラムでCALLステートメントを使用してサブプログラムを呼び出すと、CALLステートメントが終了されても、サブプログラム内のデータ項目にはCALLステートメントの使用中に利用していた値が保存されています。CANCELステートメントは、このようなサブプログラム内のデータ項目の値を、EXTERNAL節で宣言された変数を使用する場合を除いて初期化します。したがって、CALLステートメントでサブプログラムを呼び出した後、CANCELステートメントを呼び出し、再びCALLステートメントを呼び出すと、サブプログラムを初めて呼び出したかのように使用することができます。
CANCELステートメントが呼び出されると、CANCELステートメントが参照するすべてのサブプログラムにも適用されます。すなわち、それぞれのサブプログラムに対し、CANCELステートメントを呼び出したかのような結果が得られます。
CANCELステートメントは、指定したプログラム内でオープンしたすべてのファイルを自動的にクローズします。
CALLステートメントで呼び出すサブプログラムでもCANCELステートメントを実行することができます。ただし、CANCELステートメントが実行されるとき、サブプログラムや別のプログラムに影響を与える可能性があるため、サブプログラムでCALLステートメントを実行してはなりません。
以下は、ステートメントの各設定項目についての説明です。
-
identifier-1、literal-1
-
literal-1とidentifier-1は、プログラム名を指定できる必要があります。
-
literal-1は英数字リテラルである必要があり、identifier-1は英数字、英字、またはゾーン10進数のデータ項目でなければなりません。
-
2.5. CLOSE
CLOSEステートメントは、ファイルの処理を終了します。ファイル制御項目にFILE STATUS節が記述されていればCLOSEステートメントが実行され、該当する値によりファイル状態キーが更新されます。
-
形式1
REEL、UNIT、NO REWIND句は、VSAMファイルで使用できません。
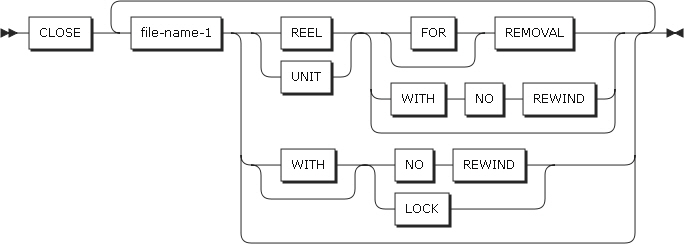 CLOSEステートメントの形式1
CLOSEステートメントの形式1 -
形式2
 CLOSEステートメントの形式2
CLOSEステートメントの形式2 -
形式3
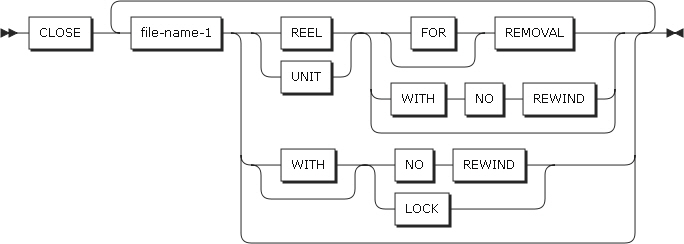 CLOSEステートメントの形式3
CLOSEステートメントの形式3
以下は、ステートメントの各設定項目についての説明です。
-
file-name-1
-
OPENステートメントに使用したファイル名を指定します。複数のファイルを指定する場合、各ファイルの編成またはアクセス・モードが同じである必要はありません。
-
ソート・ファイルまたはマージ・ファイルを使用することはできません。
-
-
REEL、UNIT
-
ファイルが保存される記憶装置の属性を指定します。
-
-
WITH NO REWIND、FOR REMOVAL
-
テープ・ファイルにのみ適用されます。これらが適用できない記憶装置に指定されている場合、CLOSEステートメントが正常に実行され、ファイルがテープ・ファイルではなかったことを示す値が保存されます。
-
2.6. COMPUTE
COMPUTEステートメントは、1つ以上のデータ項目に算術演算の結果を保存します。COMPUTEステートメントに指定する加算、減算、乗算、除算などを組み合わせる算術式には制限がありません。
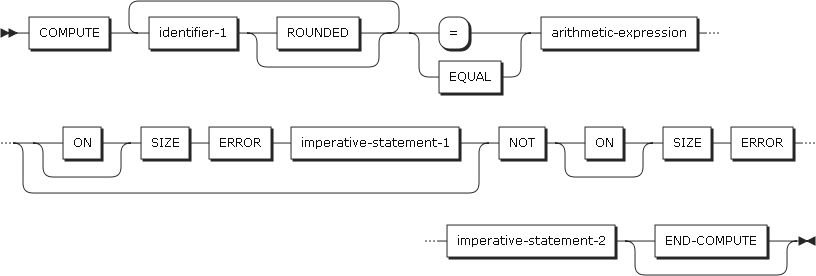
以下は、ステートメントの各設定項目についての説明です。
-
identifier-1
-
identifier-1は、基本数字項目、基本数字編集項目、または基本浮動小数点項目を指定する必要があります。
-
-
算術式
-
加算、減算、乗算、除算などを組み合わせた算術式を指定することができます。
-
COMPUTEステートメントが実行されると、算術式の値が計算された後、その結果がidentifier-1に指定されたデータ項目に保存されます。
-
算術式が1つの識別子、数字関数、リテラルでのみ構成されている場合、identifer-1により参照されるデータ項目の値を、その識別子、数字関数、リテラルの値と同じくすることができます。
-
-
ROUNDED句
-
ROUNDED句については、ROUNDED句を参照してください。
-
-
SIZE ERROR句
-
SIZE ERROR句については、SIZE ERROR句を参照してください。
-
-
END-COMPUTE句
-
END-COMPUTE句は、COMPUTEステートメントの範囲を明示的に表すために指定します。
-

2.8. DELETE
DELETEステートメントは、ファイルのレコードを削除します。
DELETEステートメントを使用するとき、対象となるファイルはI-Oモードでオープンされている必要があります。DELETEステートメントが正常に実行されると、レコードは削除され、使用できなくなります。
ファイル制御項目にFILE STATUSが記述されていると、DELETEステートメントの実行後、ファイル状態キーが更新されます。
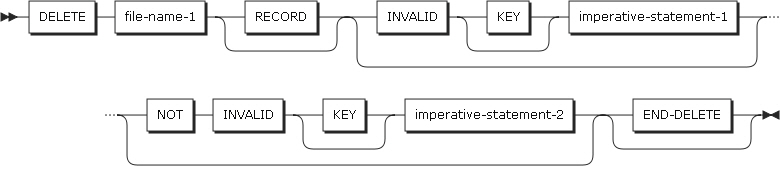
以下は、ステートメントの各設定項目についての説明です。
-
file-name-1
データ部のFD項目に記述されている必要があり、指標ファイルまたは相対ファイルの名前でなければなりません。
-
END-DELETE句
明示的にDELETEステートメントの終了を示します。
以下は、各モードでのDELETEステートメントの使用についての説明です。
-
順次アクセス・モード
-
DELETEステートメントを実行する前にREADステートメントが正常に実行されている必要があります。DELETEステートメントが実行されると、システムは直前にREADステートメントで読み込んだレコードを削除します。
-
順次アクセス・モードのファイルに対し、INVALID KEY句、NOT INVALID KEY句を使用することはできません。
-
-
ランダムまたは動的アクセス・モード
-
ランダムまたは動的アクセス・モードにおけるDELETEステートメントの実行結果は、ファイル編成(指標ファイルまたは相対ファイル)によって異なります。
-
DELETEステートメントが実行されたとき、システムは指標ファイルの基本RECORD KEYデータ項目または相対ファイルのRELATIVE KEYデータ項目によってレコードを削除します。
-
ファイルに該当するレコードが含まれていない場合は、無効キー条件が発生します。
-
2.9. DISPLAY
DISPLAYステートメントは、各オペランドの内容を出力装置に転送します。オペランドのリスト順に、左から右へ内容が出力装置に表示されます。

以下は、ステートメントの各設定項目についての説明です。
-
identifier-1
-
identifier-1は、出力装置に表示されるデータを参照します。
-
identifier-1は、USAGE INDEX、PROCEDURE-POINTER、FUNCTION-POINTER以外のすべてのデータ項目を参照することができます。identifier-1が2進数、内部10進数、または内部浮動小数点の場合、identifier-1は自動的に以下の外部形式に変更されます。
-
2進数と内部10進数項目は、ゾーン10進数に変換されます。
-
内部浮動小数点数は、以下のように外部浮動小数点数に変換されます。
-
COMP-1項目は、-.9(7)E-99のPICTURE節を持つ外部浮動小数点で表示されます。
-
COMP-2項目は、-.9(15)E-99のPICTURE節を持つ外部浮動小数点で表示されます。
-
-
-
USAGE POINTERで定義されたデータ項目は、PIC 9(10)を持つゾーン10進数に変換されます。他のカテゴリは変換が不要です。DBCSと非DBCSのオペランドを1つのDISPLAYステートメントで使用することができます。
-
-
literal-1
-
いかなるリテラルまたは表意定数にすることができます。表意定数が使用される場合、長さ1の分だけ表示されます。
-
-
UPON
-
environment-name-1またはmnemonic-name-1は、出力装置に関連付ける必要があります。environment-name-1またはmnemonic-name-1の詳細については、SPECIAL-NAMES段落を参照してください。
-
UPON句が省略されると、システム出力装置(stdoutなど)が想定されます。
-
-
WITH NO ADVANCING
-
WITH NO ADVANCING句が記述されると、DISPLAYステートメントによりオペランドの内容が出力装置に転送された後、出力装置の文字位置は、次の行の左端に移動せず、最後のオペランドにそのまま残ることになります。
-
|
OFCOBOLは、出力装置を直接制御しないため、このWITH NO ADVANCING句は意味がないかもしれません。(UPON CONSOLEなど) |
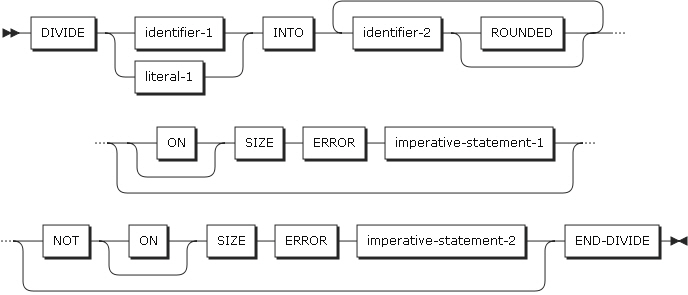
2.10. DIVIDE
DIVIDEステートメントは、数字データ項目またはリテラルをINTO以降に指定したデータ項目で除算を行い、その商を保存します
-
形式1
Format 1では、identifier-1またはliteral-1をidentifier-2で割り、その商をidentifier-2に保存します。identifier-2が複数指定されている場合は、左から右の順に除算を行い、その商をそれぞれのidentifier-2に保存します。
 DIVIDEステートメントの形式1
DIVIDEステートメントの形式1 -
形式2
形式2では、identifier-1またはliteral-1をidentifier-2またはliteral-2で割り、その商をidentifier-3に保存します。
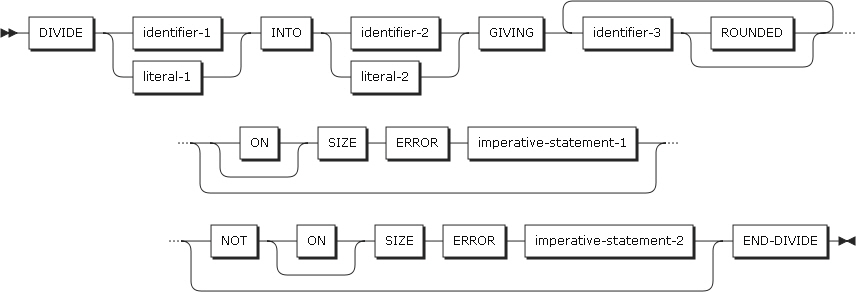 DIVIDEステートメントの形式2
DIVIDEステートメントの形式2 -
形式3
形式3では、identifier-1またはliteral-1をidentifier-2またはliteral-2で割り、その商をidentifier-3に保存します。
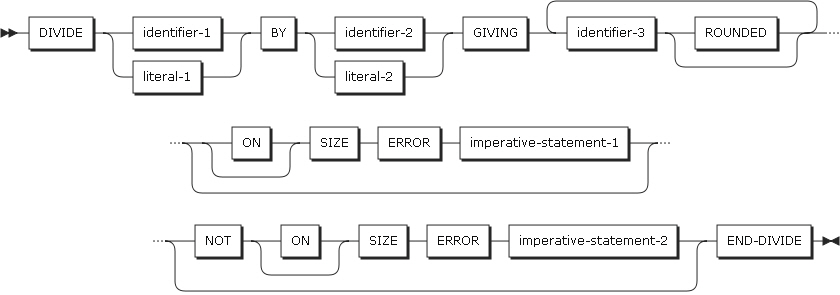 DIVIDEステートメントの形式3
DIVIDEステートメントの形式3 -
形式4
形式4では、identifier-1またはliteral-1をidentifier-2またはliteral-2で割り、その商をidentifier-3に、剰余はidentifier-4に保存します。
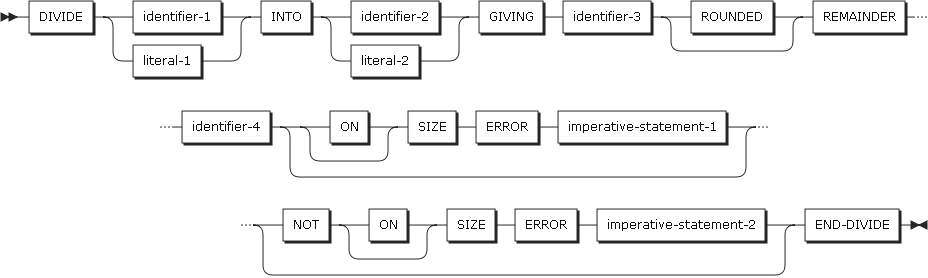 DIVIDEステートメントの形式4
DIVIDEステートメントの形式4 -
形式5
形式5では、identifier-1またはliteral-1をidentifier-2またはliteral-2で割り、その商はidentifier-3に、剰余はidentifier-4に保存します。
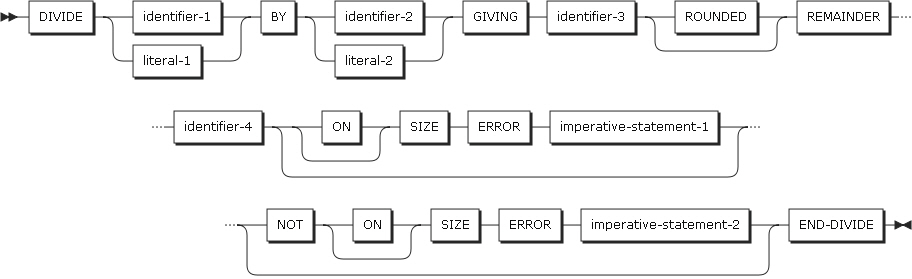 DIVIDEステートメントの形式5
DIVIDEステートメントの形式5
以下は、ステートメントの各設定項目についての説明です。
-
identifer-1、identifier-2
-
identifier-1とidentifier-2は、基本データ項目である必要があります。
-
-
identifier-3、identifier-4
-
identifier-3とidentifier-4は、基本数字項目または数字編集項目である必要があります。
-
-
literal-1、literal-2
-
literal-1とliteral-2は、数字リテラルである必要があります。
-
-
ROUNDED句
-
REMAINDER句
-
identifier-4には、商と除数を乗算した値を被除数から減算した結果が保存されます。identifier-3が数字編集項目の場合は、剰余を計算するために編集されていない中間値が商として使用されます。
-
オペランドまたは保存値として浮動小数点を使用すると、REMAINDER句は使用できません。
-
-
SIZE ERROR句
-
形式1、2、3については、ステートメント操作のSIZE ERROR句を参照してください。
-
形式4、5の場合、商にサイズ・エラーが発生すると、剰余の計算は意味がありません。したがって、商を保存するidentifier-3と剰余を保存するidentifier-4には以前の値がそのまま維持されます。
-
剰余にサイズ・エラーが発生した場合、剰余を保存するidentifier-4には以前の値がそのまま維持されます。
-
-
END-DIVIDE句
-
END-DIVIDE句は明示的にDIVIDE句の範囲を指定するために使用されます。
-
|
形式1、2、3には、データ項目として浮動小数点を使用できますが、形式4、5は、浮動小数点項目を使用できません。 |
2.11. ENTRY
ENTRYステートメントは、サブプログラムを呼び出すとき、PROGRAM-IDに指定したプログラム名やファイル名以外に、別の名前でサブプログラムを呼び出すために設定するエントリー・ポイントです。ENTRYステートメントは、手続き部にRETURNING句が指定されているか、ネストされたプログラムには指定できません。
ENTRYステートメントを指定したCALLステートメントがサブプログラムを呼び出すと、ENTRYステートメントのすぐ後ろにあるステートメントが実行されます。
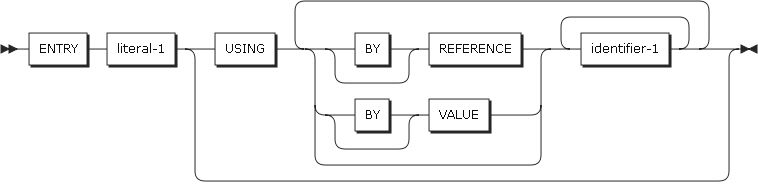
-
literal-1
-
CALLステートメントにより呼び出されるエントリー名として英数字リテラルを指定する必要があり、プログラム名の規則に従います。
-
エントリー名は、プログラム内で一意である必要があり、表意定数を指定することはできません。
-
プログラムの別のエントリー名と重複されてはなりません。
-
-
USING句
-
USING句については、CALLを参照してください。
-
2.12. EVALUATE
EVALUATEステートメントは、ネストされたIFステートメントの簡単な使用を提供します。EVALUATEステートメントは、複数の条件を判別することができます。以降の実行は、この判別結果に応じて異なります。
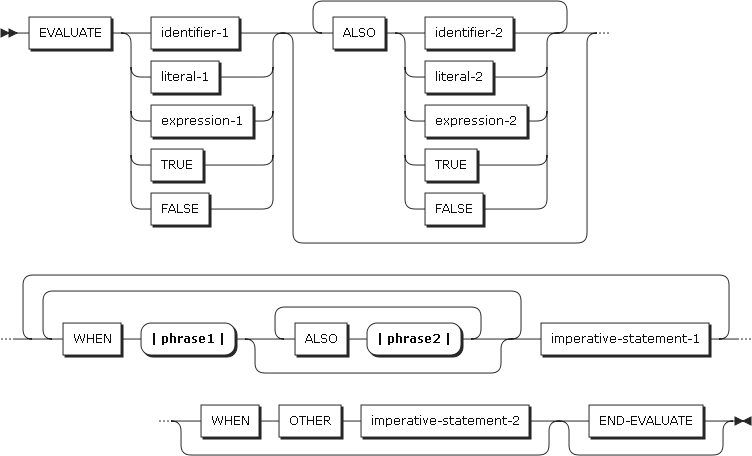
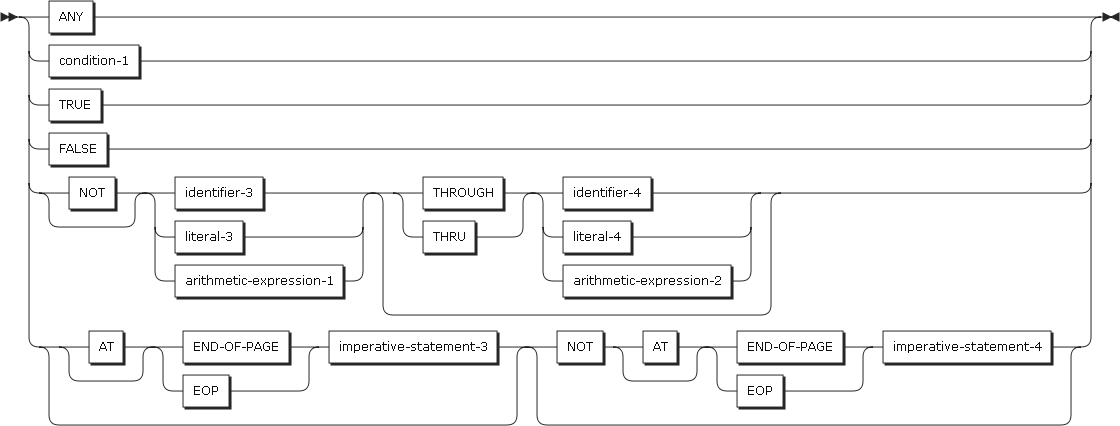
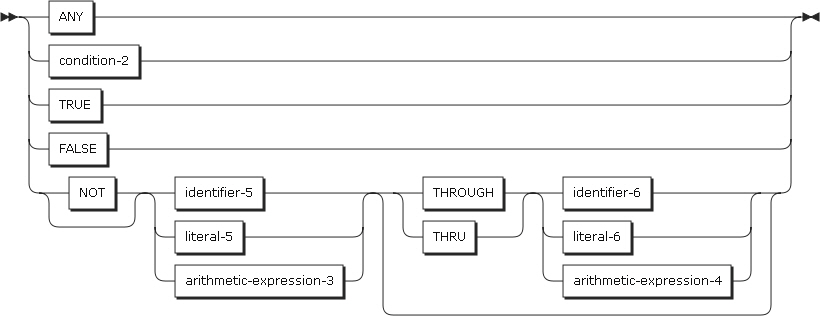
以下は、ステートメントの各設定項目についての説明です。
-
WHEN句の前にあるオペランド
-
これらのオペランドを選択サブジェクトといいます。
-
これらのオペランド全体を選択オブジェクトのセットといいます。
-
-
WHEN句の中にあるオペランド
-
これらのオペランドを選択オブジェクトといいます。
-
WHEN句に含まれているオペランド全体を選択オブジェクトのセットといいます。
-
-
ALSO
-
選択サブジェクトまたは選択オブジェクトを、それぞれのセット内で分離します。
-
-
THROUGH、THRU
-
範囲を持つ値を指定するときに使用します。
-
THRUによって結合された2つのオペランドは同じクラスに属している必要があります。選択オブジェクト・セット内の選択オブジェクトの数は、選択サブジェクトの数と一致する必要があります。また、以下の規則に従って、選択オブジェクト・セット内の各選択オブジェクトは、選択サブジェクト・セットにある同じ順序位置の選択サブジェクトに対応している必要があります。
-
選択オブジェクトに現れる識別子、リテラル、算術式は、選択サブジェクト・セットにある対応したオペランドと比較して有効なオペランドでなければなりません。
-
選択オブジェクトとして現れるcondition-1、condition-2、TRUE、FALSEは、選択サブジェクト・セットにある条件式またはTRUE、FALSEと対応する必要があります。
-
ANYは、選択サブジェクトのタイプを問わず対応することができます。
選択サブジェクトと選択オブジェクトの比較規則
選択サブジェクトと選択オブジェクトの比較は、以下のように行われます。
-
選択サブジェクトがidentifier-1、literal-1、算術式の場合、選択オブジェクト・セット内にある同じ順序位置の選択オブジェクトの値と対応されます。THRUが含まれていないとEQUAL比較を行い、THRUが含まれている場合は選択サブジェクトが選択オブジェクトの範囲内にあるのかを確認します。
-
選択サブジェクトが条件式の場合、選択オブジェクト・セット内にある同じ順序位置の選択オブジェクトの条件式またはTRUE、FALSEの値と対応されます。比較条件を満たすためには、選択サブジェクトと選択オブジェクトの両方が真である必要があり、選択オブジェクトが偽の場合は比較条件が満たされません。また、選択サブジェクトが偽のとき、選択オブジェクトが真であると比較条件が満たされず、選択オブジェクトが偽であれば、比較条件が満たされます。
-
expression-1、expression-2とオブジェクトの両方が算術式の場合は、数値を評価する規則に従います。
-
選択サブジェクトがTRUEの場合、選択オブジェクト・セット内にある同じ順序位置の選択オブジェクトの条件式またはTRUE、FALSEの値と対応されます。選択オブジェクトの条件式がTRUEであれば、比較条件が満たされます。選択オブジェクトがFALSEであると、比較条件は満たされません。
-
選択サブジェクトがFALSEの場合、選択オブジェクト・セット内にある同じ順序位置の選択オブジェクトの条件式またはTRUE、FALSEの値と対応します。選択オブジェクトの条件式がFALSEであれば、比較条件は満たされます。選択オブジェクトがTRUEであると、比較条件は満たされません。
-
選択オブジェクトがANYによって指定されると、比較条件は無条件で満たされます。
-
選択オブジェクトがNOTを伴う場合、サブジェクトとNOT EQUAL演算を行います。
-
選択サブジェクト・セット内のすべての選択サブジェクトと、選択オブジェクト・セット内のすべての選択オブジェクトとの比較条件が満たされると、WHEN句を満たすことになります。
比較条件を満たさない場合は、次のWHEN句の比較を行います。
-
満たされるWHEN句があれば、その句に記述されたimperative-statement-1が実行されます。
-
満たされるWHEN句はないが、WHEN OTHER句を指定してある場合は、imperative-statement-2が実行されます。WHEN OTHER句が指定されていない場合は、EVALUATEステートメントの次のステートメントが実行されます。
-
2.13. EXIT
EXITステートメントは、プロシージャの最後を意味しており、プログラム内でCONTINUEステートメントと同じ処理を行います。EXITステートメントの後続のステートメントを実行します。
2.14. EXIT PARAGRAPH
EXIT PARAGRAPHステートメントは、現在実行している段落を終了し、プログラムの制御を次のプロシージャに渡します。

2.15. EXIT PROGRAM
EXIT PROGRAMステートメントは、呼び出されたプログラムを終了し、プログラムの制御を呼び出し側プログラムに戻します。EXIT PROGRAMステートメントは、プログラムの手続き部内でのみ指定可能です。

以下は、メインプログラムとサブプログラムにおけるEXIT PROGRAMステートメントの動作順です。
-
メインプログラムからCALLステートメントを使用してサブプログラムを呼び出します。
-
サブプログラムの実行中にEXIT PROGRAMステートメントが現れると、プログラムの制御はCALLステートメントに渡されます。
-
これにより、メインプログラムのCALLステートメントの次のステートメントが実行されます。
EXIT PROGRAMステートメントはプログラムの制御が移動するため、最後に指定する必要があります。サブプログラムに実行できるステートメントがない場合は、暗黙的にEXIT PROGRAMステートメントが実行されます。
2.16. GOBACK
GOBACKステートメントは、サブプログラム内ではプログラムの制御をメインプログラムに渡し、メインプログラムではプログラムを終了する機能を行います。サブプログラムでのEXIT PROGRAMステートメント、またはメインプログラムでのSTOP RUNと同様に機能します。GO BACKステートメントは、サブプログラムで論理的なプログラムの終了を意味します。
サブプログラム内でGO BACKステートメントが現れると、プログラムの制御はメインプログラムに戻されます。したがって、GO BACKステートメントは単独で使用するか、またはプログラムの最後に位置する必要があります。サブプログラム内でGO BACKステートメント以降のステートメントは実行されません。
メインプログラム内でCALLステートメントを使用してサブプログラムを呼び出すと、サブプログラム内でGO BACKステートメントを処理した後、メインプログラムのCALLステートメントのすぐ後のステートメントに制御が戻されます。
2.17. GO TO
GO TOステートメントは、プログラムの制御を手続き部内の別の位置に移します。
GO TOステートメントには、以下のような2つのタイプがあります。
-
無条件GO TOステートメント
-
条件付きGO TOステートメント
無条件GO TOステートメント
無条件GO TOステートメントは、プログラムの制御をprocedure-name-1によって定義された段落またはセクションに移します。
GO TOステートメントが現れると、プログラムの制御が他のプロシージャまたはセクションに移動するため、GO TOステートメントの後のステートメントは実行されません。

| 項目 | 説明 |
|---|---|
procedure-name-1 |
プログラムの制御が移動するプロシージャ名またはセクション名です。 |
条件付きGO TOステートメント
条件付きGO TOステートメントは、identifier-1の値に応じて、複数のprocedure-name-1のうち、プログラムの制御が移動するプロシージャ名を決めるステートメントです。

| 項目 | 説明 |
|---|---|
procedure-name-1 |
GO TOステートメントと同じ手続き部内にあるプロシージャまたはセクションです。Procedure-name-1の数は255まで可能です。 |
identifier-1 |
整数からなる数字基本データ項目である必要があります。 identifier-1が1の場合、プロシージャ名リストの最初のプロシージャにGO TOし、identifier-1が2の場合は、プロシージャ名リストの2番目のプロシージャにGO TOします。 identifier-1の値がプロシージャ名リストの数を超えると、GO TOステートメントは意味がなくなり、GO TOステートメントの次のステートメントが実行されます。 |
2.18. IF
IFステートメントは条件を評価し、その結果に従って処理します。

以下は、ステートメントの各設定項目についての説明です。
-
condition-1
-
手続き部の構造の条件式で説明する条件式です。
-
-
statement-1、statement-2
-
条件に応じて実行されるステートメントを記述します。条件が真であれば、THEN句のstatement-1に記述されたステートメントが実行されます。一方、条件が偽の場合は、ELSE句のstatement-2に記述されたステートメントが実行されるか、NEXT SENTENCEによって処理されます。
-
IFステートメントを使用することにより、ネストされたIFステートメントの使用が可能になります。ネストされたIFステートメントでは、IF、ELSE、END-IFを利用してマッチされるIFステートメントを確認します。END-IFは最も近い位置にあるIFステートメントとマッチされます。
-
-
NEXT SENTENCE
-
ピリオドの後にある文を実行します。
-
END-IFと共に記述されても、END-IFの次のステートメントが実行されるのではなく、最も近いピリオドの後のステートメントが実行されます。
-
-
END-IF句
-
IFステートメントの終了を示します。
-
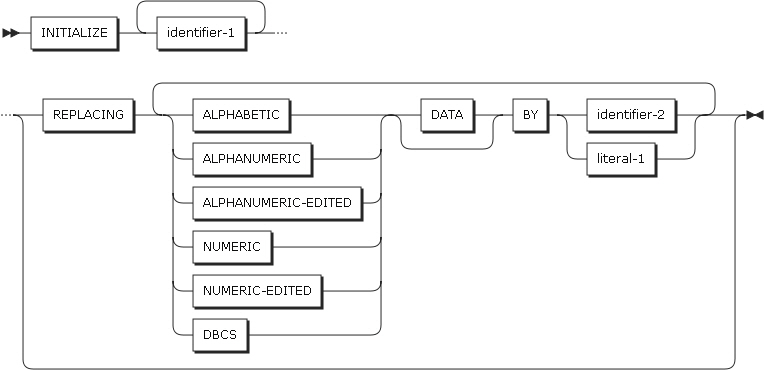
2.19. INITIALIZE
INITIALIZEステートメントは、identifier-1に記述したカテゴリに従って、特定の値をidentifier-1に設定するか、REPLACING句が指定されている場合は、identifier-2またはliteral-1の値をidentifier-1に設定します。機能的に1つ以上のMOVEステートメントと同じです。
以下は、ステートメントの各設定項目についての説明です。
-
identifier-1
-
RENAMES節を持つことはできません。
-
値が設定される受け取り領域として、以下のような項目が指定できます。
項目 説明 グループ項目
英数字データ項目が指定できます。REPLACING句が指定されている場合、identifier-1が英数字グループ項目であると、identifier-1の下部要素項目はREPLACING句の規則に従って初期化されます。
基本データ項目
英文字、英数字、英数字編集、DBCS、数字、数字編集、内部浮動小数点、外部浮動小数点のカテゴリに属するデータ項目です。
-
-
identifier-2、literal-1
-
MOVEステートメントまたはSETステートメントで送り出し領域に指定可能な基本データ項目またはリテラルを指定することができます。
identifier-1、identifier-2に特殊レジスターを指定する場合は、それぞれMOVEステートメントの受け取り領域または送り出し領域として指定が可能でなければなりません。
-
-
REPLACING句
-
REPLACING句に指定したデータ・カテゴリとidentifier-1のカテゴリが一致する場合、identifier-2またはliteral-1の値がidentifier-1に設定されます。
-
浮動小数点項目の場合、NUMERICカテゴリとして扱われます。
-
REPLACING句に同じカテゴリを重複して指定してはなりません。
-
|
identifier-1、identifier-2、REPLACING句に指定したカテゴリの有効性は内部的にチェックされません。したがって、ユーザーがMOVEステートメントまたはSETステートメントの規則に従ってデータ項目およびカテゴリを指定する必要があります。 |
以下は、REPLACING句が指定されていない場合、identifier-1に設定される値についての説明です。
-
identifier-1のカテゴリが英字、英数字、英数字編集、DBCSの場合は、表意定数SPACEが設定されます。
-
identifier-1のカテゴリが数字、数字編集、外部浮動小数点の場合は、表意定数ZEROが設定されます。
-
identifier-1のカテゴリがポインターの場合は、表意定数NULLが設定されます。
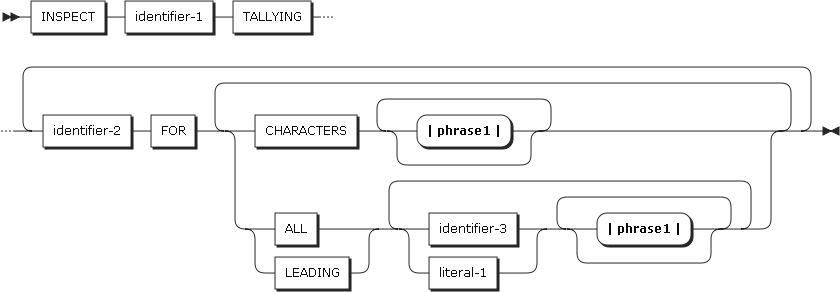
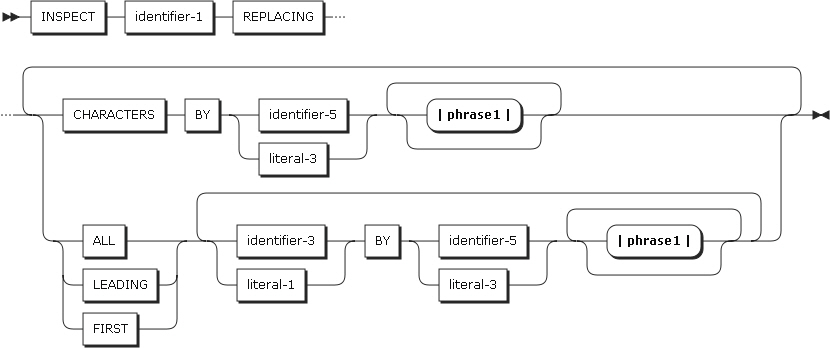
2.20. INSPECT
INSPECTステートメントは、文字列または文字列のグループを検査して以下のようなタスクを実行します。
-
データ項目内で特定の文字のオカレンスを数えます。(形式1、3)
-
特定の文字のオカレンスを数えたり、明示した文字で満たしたりします。(形式2、3)
-
特定の文字を置き換えます。


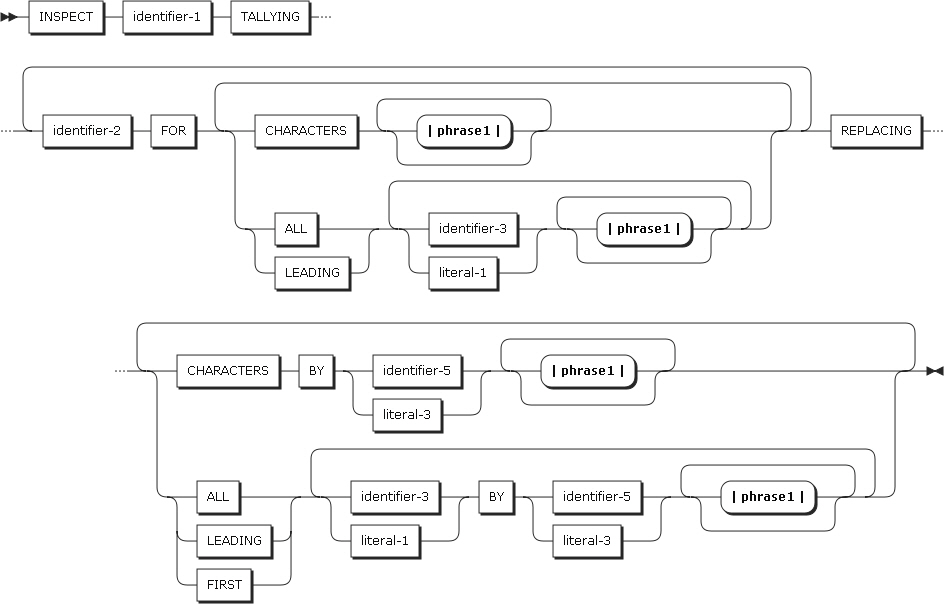

以下は、ステートメントの各設定項目についての説明です。
-
identifier-1
-
英数字グループ項目または基本データ項目であり、かつUSAGE DISPLAY、DISPLAY-1である項目、または英数字タイプの特殊レジスターを指定できます。
-
使用方法が同じであれば、データのカテゴリは特に問題にはなりません。
-
-
identifier-3、identifier-4、identifier-5、identifier-6、identifier-7
-
基本データ項目であり、USAGE DISPLAY、DISPLAY-1の項目が指定できます。
-
-
literal-1、literal-2、literal-3、literal-4
-
英数字、DBCSカテゴリでなければなりません。それぞれのリテラルは、identifier-1とカテゴリが同じである必要があります。
-
identifier-1がUSAGE DISPLAYの場合、ALLで始まらない別の表意定数にすることができます。
-
identifier-2を除いて、すべての識別子(identifier)は、identifier-1と同じ使用方法である必要があります。
-
TALLYING句(形式1、3)
-
TALLYING句は、指定した文字のオカレンスを数えます。
-
identifier-2はカウント・フィールドであり、PICTURE文字列にPを使用しない基本整数項目である必要があります。identifier-3、literal-1は集計フィールドです。
項目 説明 CHARACTERS
空白文字を含むすべてのidentifier-1項目の文字ごとに、カウント・フィールドのidentifier-2が1ずつ増加します。
ALL
identifier-1項目の文字をidentifier-3またはliteral-1と比較して一致する場合は、重複しないオカレンスごとに、identifier-2を1ずつ増加させます。左端の文字位置から右端に進みます。
LEADING
identifier-1項目の文字をidentifier-3またはliteral-1と比較して一致する場合は、重複しない連続したオカレンスごとに、identifier-2を1ずつ増加させます。左端の文字位置で最初に現れる位置から始め、連続されたオカレンスの数を比較します。
-
-
REPLACING句(形式2、3)
-
REPLACING句は、データ項目の特定の文字を置き換えます。
-
identifier-3とliteral-1は、置換できるサブジェクト項目です。identifier-5とliteral-3は、サブジェクトを置き換えする置換項目です。サブジェクトと置換項目は同じ長さである必要があります。
項目 説明 CHRACTERS BY
置換項目がサブジェクト項目の各文字を置き換えます。左端から右端へ進みます。置換項目の長さは1である必要があります。
ALL
置換項目がサブジェクトの項目を重複しないオカレンスに応じて置き換えます。左端の文字位置から右端へ進みます。
LEADING
置換項目がサブジェクトの項目を重複しない連続したオカレンスに応じて置き換えます。左端の文字位置で最初に現れる位置から始め、連続されたオカレンスの数を比較します。
FIRST
置換項目がサブジェクト項目の左端のオカレンスを置き換えます。
-
-
置換の規則
以下の置き換え規則が適用されます。
-
サブジェクト・フィールドが表意定数の場合、それと一致する各文字を置き換えます。
-
表意定数または文字列がサブジェクトの場合、重複しないオカレンスを置き換えます。
-
-
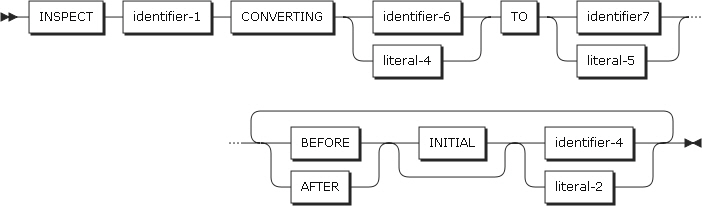
BEFORE句およびAFTER句(すべての形式)
-
identifier-4とliteral-2は区切り文字です。区切り文字はカウントに含まれず、置き換えも行われません。
-
INITIALは、指定された項目の最初のオカレンスです。
項目 説明 BEFORE
カウントまたは置換は、左端の文字位置から始まり、区切り文字が現れるまで続けられます。区切り文字が現れなければ、右端の文字位置まで進みます。
AFTER
カウントまたは置換は、区切り文字の右側にある最初の文字から始まり、右端の文字位置まで続けられます。区切り文字が現れなければ、カウントまたは置換は行われません。
-
-
CONVERTING句(形式4)
-
すべてのデータ項目の文字を、指定された置換文字に変換します。
-
identifier-6とliteral-4は、変換される文字列を指定します。identifier-7とliteral-5は、変換する文字列を指定します。置換される文字列と置換する文字列の長さは同じである必要があります。
-
2.21. MERGE
MERGEステートメントは、ソートされたファイルをマージします。各ファイルのレコードは、キーに従ってソートされている必要があります。
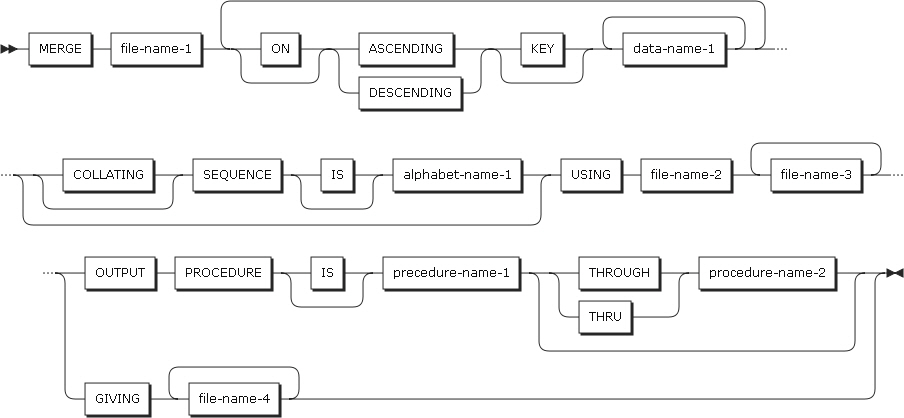
以下は、ステートメントの各設定項目についての説明です。
-
file-name-1
SD項目に記述された名前です。
-
ASCENDING KEY句およびDESCENDING KEY句
マージ・キーが昇順なのか降順なのかを指定します。
項目 説明 data-name-1
MERGEステートメントで使用されるKEYデータ項目を記述します。data-name-1は、file-name-1に関連するレコードに含まれたデータ項目である必要があります。
データ項目は、キーのレベルが高い順に左から右へ記述されます。つまり、左端に記述されたデータ項目が最もレベルの高いキーとなり、その次のデータ項目が2番目のレベルのキーとなります。
-
KEYデータ項目は、各入力ファイルの中で物理的に同じ位置に存在する必要があり、データ形式も同じである必要があります。ただし、データ名は同じである必要はありません。
-
file-name-1が1つ以上のレコード記述を有する場合、KEYデータ項目は、その中のいずれかのレコードに記述されている必要があります。
-
KEYデータ項目は、OCCURS節を含むことができず、OCCURS節を含む項目に従属されてはなりません。
-
KEYデータ項目は、修飾することができます。
KEYデータ項目は、以下のデータ・カテゴリのいずれかになります。
-
英字、英数字、英数字編集
-
数字
-
数字編集(with USAGE DISPLAY)
-
内部浮動小数点またはDISPLAY浮動小数点
-
-
-
COLLATING SEQUENCE句
MERGEステートメントの動作で、KEYデータ項目に対して行われる英数字比較で使用される照合シーケンスを指定します。
項目 説明 alphabet-name-1
SPECIAL-NAMES段落のALPHABET節に定義されている必要があります。
-
USING句
入力ファイルを記述します。
項目 説明 file-name-2、...
入力ファイルを定義します。USING句が使用されると、入力ファイル(file-name-2、...)のすべてのレコードがfile-name-1に自動転送されます。
すべての入力ファイルは、データ部のFD項目に記述されている必要があります。
-
GIVING句
出力ファイルを記述します。
項目 説明 file-name-3、...
出力ファイルを記述します。
GIVING句が記述されると、ソートされたすべてのレコードは出力ファイルに自動転送されます。
すべての出力ファイルは、データ部のFD項目に記述されている必要があります。
-
OUTPUT PROCEDURE句
マージ処理を実行した後、出力レコードを選択および変更するプロシージャ名を記述します。
項目 説明 procedure-name-1
出力プロシージャの最初の(または一意の)セクションまたは段落を記述します。
procedure-name-2
出力プロシージャの最後のセクションまたは段落を記述します。
出力プロシージャにはRETURNステートメントがあり、file-name-1が参照するファイルから一度に1つのレコードを受け取ります。そのほか、多様なステートメント(OPEN、WRITE、CLOSEなど)を使用して、出力レコードを選択、コピー、変更することができます。
|
MERGEステートメントが実行されると、file-name2、file-name3、...に含まれたすべてのレコードが、記述されたキーに従ってマージされます。 |
2.22. MOVE
MOVEステートメントは、特定の記憶領域から別の1つまたは複数の記憶領域に移動します。
MOVEステートメントの記述は、以下の2つの形式があります。
-
形式1
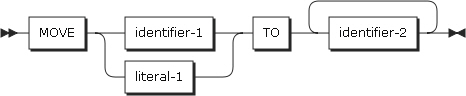 MOVEステートメントの形式1
MOVEステートメントの形式1 -
形式2
 MOVEステートメントの形式2
MOVEステートメントの形式2
以下は、ステートメントの各設定項目についての説明です。
-
identifier-1、literal-1
-
identifier-1とliteral-1は、送り出し領域です。
-
-
identifier-2
-
identifier-2は、受け取り領域であり、組み込み関数は指定できません。
区分 説明 形式1
identifier-1には、英数字グループ項目または基本項目を指定することができます。
identifier-2が複数記述されている場合は、指定された順にidentifier-2からidentifier-1に移動されます。
形式2
identifier-1とidentifier-2は、グループ項目である必要があります。
identifier-1の特定の項目がCORRESPONDING規則に従ってidentifier-2に移動されます。
-
受け取りフィールド(identifier-2)の長さ、添え字付け、参照変更は、データがその受け取りフィールドに移動する直前に評価されます。
-
-
CORRはCORRESPONDINGの略字です。
-
USAGE句
INDEX、POINTER、FUNCTION-POINTER、PROCEDURE-POINTERが指定された項目は、基本項目でidentifier-1とidentifier-2に指定することができません。
MOVE CORRESPONDINGステートメント形式では、INDEX、POINTER、FUNCTION-POINTER、PROCEDURE-POINTERが指定された項目を英数字グループ項目のメンバーとして指定することができます。ただし、これらの項目から実際にデータが移動されることはありません。送り出し項目と受け取り項目の長さは、DEPENDING ON節により決まります。
identifier-1が参照変更、添え字付きまたは英数字、関数識別子の場合、identifier-2の最初の項目への移動が行われる前にidentifier-1の参照変更、添え字、英数字、関数識別子の評価が行われます。送り出し領域と受け取り領域がオーバーラップされる場合、結果は保証されません。
基本移動
受け取り項目は基本データ項目であり、送り出し項目が基本データ項目または文字列である場合を基本移動といいます。
送り出し項目と受け取り項目に記述可能なデータ・カテゴリは、以下のいずれかになります。
-
指定可能なデータ・カタログーまたはリテラル
-
英字カテゴリのデータ項目および表意定数SPACE
-
英数字カテゴリのデータ項目、英数字関数、英数字リテラル、ALL英数字リテラル、表意定数(NULLを除く)
-
英数字編集カテゴリのデータ項目
-
DBCSカテゴリのデータ項目、DBCSリテラル、ALL DBCSリテラル
-
外部浮動小数点カテゴリのデータ項目、浮動小数点リテラル
-
内部浮動小数点カテゴリのデータ項目
-
数字カテゴリのデータ項目、数字リテラル、表意定数ZERO
-
数字編集カテゴリのデータ項目
受け取り項目には、以下の規則が適用されます。位置合わせ規則については、PICTURE節の説明を参照してください。
-
英字
-
データ変換は起きません。
-
位置合わせ規則に従って、データの位置合わせが行われ、空白で埋め込みまたは切り捨てが発生します。
-
送り出し項目と受け取り項目の長さが異なる場合、JUSTIFIED句の記述に従って受け取り項目に切り捨てが行われます。基本的に右端の文字が切り捨てられます。詳細については、JUSTIFIED節を参照してください。
-
-
英数字または英数字編集
-
位置合わせ規則に従って、データの位置合わせが行われ、空白で埋め込みまたは切り捨てが発生します。
-
送り出し項目が受け取り項目の長さより大きい場合は、送り出し項目の右端から超えた分の文字が切り捨てられます。
-
最初の送り出し項目が符号を持つ場合は、符号なしの値を使用します。符号が別の記憶領域を占めている場合、符号文字は移動されず、送り出し項目の長さは、符号が占有している長さを引いたサイズになります。
-
-
DBCS
-
データ変換は起こりません。
-
送り出し項目と受け取り項目の長さが異なる場合、送り出し項目は右端から切り捨てられるか、DBCS空白で埋められます。
-
-
外部浮動小数点
-
送り出し項目が浮動小数点の場合、その値は受け取り項目に指定された使用方法に従って変換および移動されます。
-
送り出し項目が浮動小数点ではない場合、数値が内部浮動小数点に変換され、受け取り項目の使用方法に従って変換および移動されます。
-
-
内部浮動小数点
-
送り出し項目が内部浮動小数点ではない場合、送り出し項目の数値を内部浮動小数点形式に変換して移動します。
-
-
数字または数字編集
-
位置合わせ規則に従って、小数点位置合わせまたは、ゼロによる埋め込みが行われます。
-
受け取り項目に記号が付いている場合、送り出し項目の記号は受け取り項目の記号位置に入れられます。送り出し項目が符号なしである場合は、正の符号(+)が生成され、受け取り項目の符号位置に入られます。
-
送り出し項目が英数字、英数字編集の場合、送り出し項目が符号なし整数データとして移動されます。
-
送り出し項目が浮動小数点の場合、受け取り項目のPICTURE句に合わせて固定小数点形式に変換されてから移動されます。
-
受け取り項目が数字編集項目の場合、PICTURE句に指定された形式に従って、送り出し項目の編集が行われます。
-
送り出し項目が数字編集項目の場合、編集記号を除いた数字リテラルの値だけを受け取り項目に移動します。受け取り項目も数字編集の場合は、受け取り項目のPICTURE句に指定された編集記号に合わせてデータが移動されます。
-
受け取り項目のカテゴリが英数字、英数字編集、数字編集であり、送り出し項目が数字の場合、送り出し項目のPICTURE句に指定されたP位置には、ゼロが指定されているとみなされます。
-
以下は、各カテゴリの有効なデータ項目についての説明です。
-
一番上の列は、受け取り項目のカテゴリです。
-
左端の列は、送り出し項目のカテゴリです。
| 英字 | 英数字 | 英数字編集 | 数字 | 数字編集 | 外部浮動小数点 | 内部浮動小数点 | DBCS | |
|---|---|---|---|---|---|---|---|---|
英数字とSPACE |
O |
O |
O |
X |
X |
X |
X |
X(+) |
英数字と英数字リテラル |
O |
O |
O |
O(*) |
O(*) |
O(*) |
O(*) |
X |
英数字編集 |
O |
O |
O |
X |
X |
X |
X |
X |
数字整数、ZEROと数字整数リテラル |
X |
O |
O |
O |
O |
O |
O |
X |
数字非整数と数字非整数リテラル |
X |
X |
X |
O |
O |
O |
O |
X |
数字編集 |
X |
O |
O |
O |
O |
O |
O |
X |
浮動小数点(浮動小数点リテラル、外部浮動小数点データ項目と内部浮動小数点データ項目) |
X |
X |
X |
O |
O |
O |
O |
X |
DBCS |
X |
X |
X |
X |
X |
X |
X |
O |
|
(*)表意定数と英数字リテラルは、数字でのみ構成されている必要があります。 (+)表意定数SPACEは指定可能です。 |
グループ移動
グループ移動は、送り出し項目または受け取り項目の両方が英数字グループ項目の場合です。グループ移動は、英数字から英数字への基本移動と同様に扱われます。ただし、データ変換は行われません。
-
受け取り項目が英数字グループ項目の場合、送り出し項目は、以下のような項目が使用できます。
-
有効な基本データ項目
-
文字列または数字リテラル
-
表意定数
-
-
送り出し項目が英数字グループ項目の場合、受け取り項目は、以下のような項目が使用できます。
-
有効な基本データ項目
-
英数字グループ項目
-
2.23. MULTIPLY
MULTIPLYステートメントは、数字項目を乗算して、その結果を指定したデータ項目に保存します。
-
形式1
形式1は、identifier-1またはliteral-1をidentifier-2と乗算し、その結果をidentifier-2に保存します。
identifier-2が複数指定されている場合は、左から右へidentifier-1またはliteral-1と乗算を繰り返し、その結果をidentifier-2に保存します。
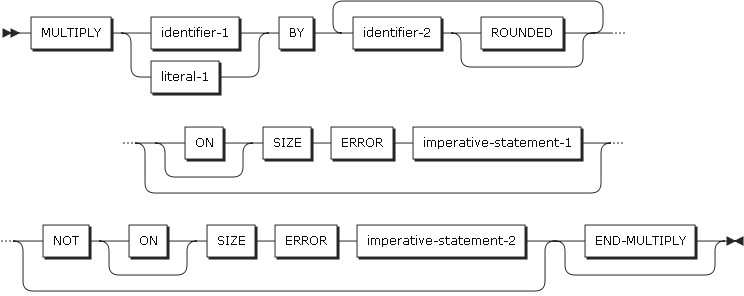 MULTIPLYステートメントの形式1
MULTIPLYステートメントの形式1 -
形式2
形式2は、identifier-1またはliteral-1の値をidetifier-2と乗算し、その結果をidentifier-3に保存します。
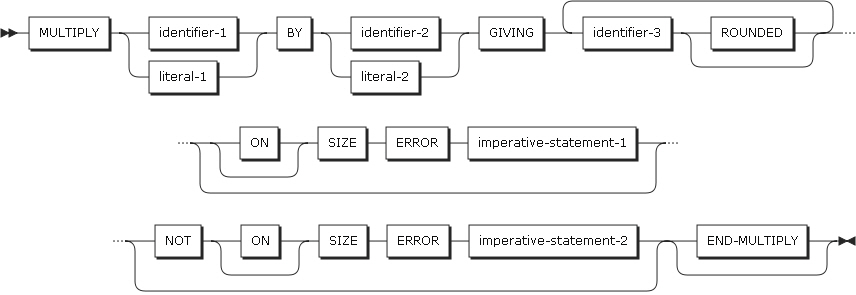 MULTIPLYステートメントの形式2
MULTIPLYステートメントの形式2
以下は、ステートメントの各設定項目についての説明です。
-
identifier-1、identifier-2
identifier-1とidentifier-2は、基本数字項目、浮動小数点データ項目である必要があります。
-
literal-1、literal-2
literal-1とliteral-2は、数字リテラルまたは浮動小数点である必要があります。
-
identifier-3
identifier-3は、基本数字データ項目または基本数字編集データ項目、浮動小数点データ項目である必要があります。
-
ROUNDED句
ROUNDED句については、ROUNDED句を参照してください。
-
SIZE ERROR句
SIZE ERROR句については、SIZE ERROR句を参照してください。
-
END-MULTIPLY句
END-MULTIPLY句は、明示的にMULTIPLYステートメントの終了を指定します。
2.24. OPEN
OPENステートメントは、ファイルの操作を開始します。
-
形式1
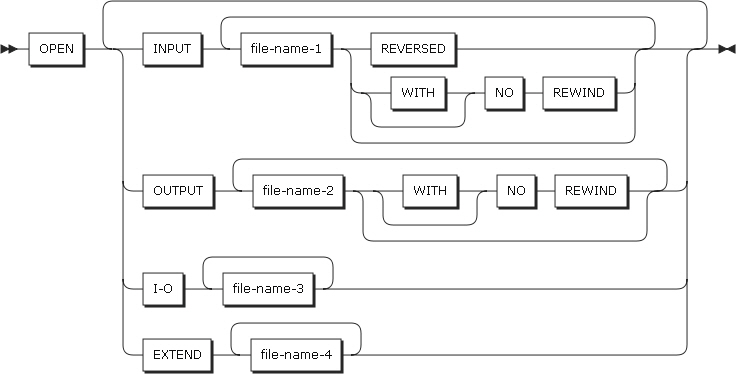 OPENステートメントの形式1
OPENステートメントの形式1 -
形式2
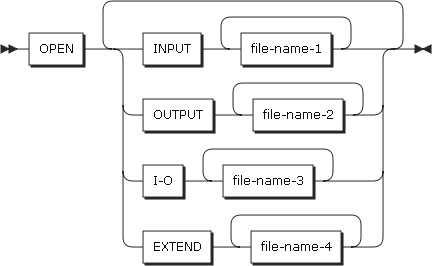 OPENステートメントの形式2
OPENステートメントの形式2 -
形式3
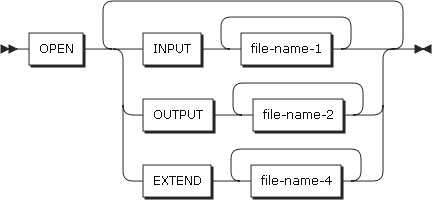 OPENステートメントの形式3
OPENステートメントの形式3
以下は、ステートメントの各設定項目についての説明です。
-
INPUT
-
入力ファイルとしてオープンします。
-
-
OUTPUT
-
出力ファイルとしてオープンします。
-
新規作成されるファイルを使用することができます。レコードが含まれているファイルを使用すると、ファイルをオープンする際に既存のレコードは削除されます。
-
-
I-O
-
入出力ファイルとしてオープンします。
-
-
EXTEND
-
ファイルを既存のレコードに追加するか、または新規作成する際に使用される出力ファイルをオープンします。
-
ファイルが存在する場合は、既存のレコードの次に追加し、存在しない場合は新規作成します。
-
-
file-name-1、file-name-2、file-name-3、file-name-4
-
オープンされるファイル名を記述します。
-
FD項目に記述されている必要があります。
-
-
REVERSED、NO REWIND
-
テープ・ファイルにのみ適用されます。
-
一般規則
OPEN INPUTステートメントまたはOPEN I-Oステートメントは、ファイル位置指示子を最初のレコード位置に設定します。
EXTEND句が記述されている場合は、ファイルの最後のレコードの後に位置付けます。以降に実行されるWRITEステートメントは、OUTPUTとしてオープンされているかのようにレコードを追加します。EXTEND句は、新規作成されるファイルにも記述できます。
VSAMファイルの場合、ファイルにレコードが存在しないと、形式1のREADステートメントの実行結果がAT END条件が発生するようにファイル位置指示子が設定されます。
以下の表は、OPENモードと使用可能な入出力ステートメントとの関係を示しています。
-
順次ファイルで使用可能なステートメント
ステートメント 入力オープン・モード 出力オープン・モード I-Oオープン・モード 拡張オープン・モード READ
X
X
WRITE
X
X
REWRITE
X
-
指標ファイルと相対ファイルで使用可能なステートメント
ファイル・アクセス・モード ステートメント 入力オープン・モード 出力オープン・モード I-Oオープン・モード 拡張オープン・モード Sequential
READ
X
X
WRITE
X
X
REWRITE
X
START
X
DELETE
X
Random
READ
X
X
WRITE
X
X
REWRITE
X
START
DELETE
X
Dynamic
READ
X
X
WRITE
X
X
X
REWRITE
X
START
X
X
DELETE
X
-
行順次ファイルで使用可能なステートメント
ステートメント 入力オープン・モード 出力オープン・モード I-Oオープン・モード 拡張オープン・モード READ
X
WRITE
X
X
REWRITE
|
X印が使用可能なステートメントです。 |
2.25. PERFORM
PERFORMステートメントは、プログラムの実行中にプログラムの制御を明示的に1つ以上の別のプロシージャに移すときに使用します。PERFORMステートメントに制御が移された位置でプロシージャが終了されると、プログラムの制御はPERFORMステートメントの次に移されます。
PERFORMステートメントの使用方法には、以下の2つの方法があります。
-
out-of-line PERFORMステートメント
out-of-line PERFORMステートメントは、PERFORMステートメント内にステートメントを記述するのではなく、記述されているプロシージャを呼び出す方法です。したがって、処理するプロシージャ名を必ず指定しなければなりません。
-
in-line PERFORMステートメント
in-line PERFORMステートメントは、プロシージャ名を指定せず、PERFORMステートメント内にステートメントを直接使用する方法です。したがって、ステートメントの終了を示すために、END-PERFORM句を必ず指定する必要があります。
PERFORMステートメントには、以下の4タイプがあります。
基本PERFORMステートメント
PERFORMステートメントの最も基本となるタイプであり、PERFORM内で呼び出したプロシージャを1回実行します。PERFORMで呼び出したプロシージャが終了されると、PERFORMステートメントの次のステートメントが順次処理されます。ただし、PERFORMステートメントで自身のプロシージャを呼び出すことはできません。
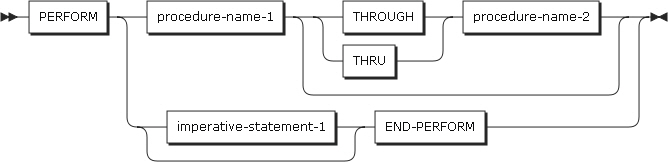
以下は、ステートメントの各設定項目についての説明です。
-
procedure-name-1、procedure-name-2
-
procedure-name-1とprocedure-name-2のいずれも手続き部内で使用するプロシージャ名である必要があります。
-
procedure-name1と2の両方が’使用される場合、それのいずれかが宣言型プロシージャ内に定義されたプロシージャであれば、もう1つのプロシージャも宣言型プロシージャ内に定義されていなければなりません。
-
procedure-name-1が使用された場合、imperative-statement-1とEND-PERFORMを指定することができません。
-
procedure-name-1を省略した場合、imperative-statement-1とEND-PERFORMを必ず指定します。
-
-
imperative-statement-1
-
PERFORMによって実行されるステートメントです。
-
プログラムの実行中にout-of-line PERFORMステートメントが現れると、プログラムの制御はprocedure-name-1の最初のステートメントに移されます。その後、procedure-name-1の実行が終わると、プログラムの制御はPERFORMステートメントの次のステートメントに移されます。
プロシージャを実行した後、制御が戻される時点は以下のとおりです。
-
procedure-name-1が段落であり、procedure-name-2が指定されていない場合、procedure-name-1の最後のステートメントを実行した後、制御はPERFORMステートメントに戻されます。
-
procedure-name-1がセクションであり、procedure-name-2が指定されていない場合、procedure-name-1セクション内にある最後の段落の最後のステートメントを実行した後、制御はPERFORMステートメントに戻されます。
-
procedure-name-2が指定されており、段落である場合、procedure-name-2の段落の最後のステートメントを実行した後、制御を戻します。
-
procedure-name-2が指定されており、セクションである場合、procedure-name-2のセクション内にある最後の段落の最後のステートメントを実行した後、制御を戻します。
procedure-name-1とprocedure-name-2の両方を指定した場合、PERFORMステートメントは、procedure-name-1から始まり、procedure-name-2まで実行します。したがって、プログラムの実行順は、procedure-name-1が先で、procedure-name-2はその後で実行される必要があります。
PERFORMステートメントは、PERFORMステートメントによって実行されるプロシージャ内に含まれることができます。
TIMES句を使用したPERFORMステートメント
PERFORMステートメントの2番目のタイプは、TIMES句に指定した識別子または整数で指定した回数だけプロシージャを呼び出すか、命令ステートメントを実行するタイプです。
PERFORMステートメントが終了すると、プログラムの制御はPERFORMステートメントの次のステートメントに移されます。procedure-name-1を指定した場合は、imperative-statement-1とEND-PERFORMを指定することはできません。
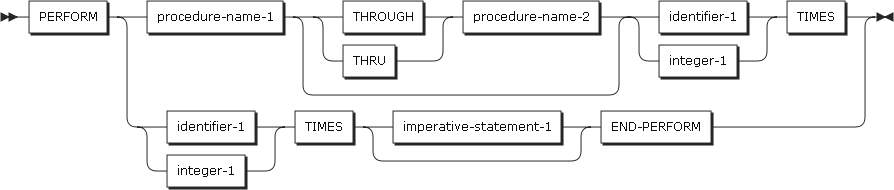
以下は、ステートメントの各設定項目についての説明です。
-
identifier-1
-
整数項目を指定する必要があります。
-
identifier-1が正数ではなく、0または負数の場合、PERFORMステートメントは実行されず、PERFORMステートメントの次のステートメントが実行されます。
-
PERFORMステートメントが実行された後は、identifier-1を変更してもプロシージャの実行回数は変更されません。
-
-
integer-1
-
正の整数である必要があります。
-
UNTIL句を使用したPERFORMステートメント
PERFORMステートメントの3番目のタイプは、UNTIL句がTRUEになるまで、プロシージャまたは命令ステートメントを実行するタイプです。
UNTIL句で指定した条件がTRUEの場合、プログラムの制御はPERFORMステートメントの次のステートメントに移されます。procedure-name-1を指定した場合は、imperative-statement-1とEND-PERFORMを指定することができません。
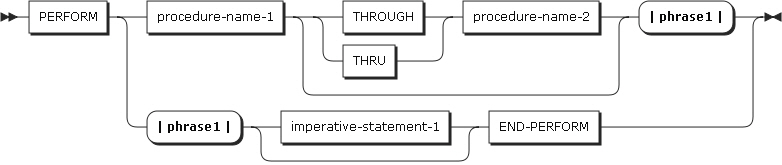

以下は、ステートメントの各設定項目についての説明です。
-
condition-1
-
OFCOBOLで共通して使用できる条件です。
-
ステートメントの条件が真であれば、PERFORMステートメントは実行されません。
-
TEST BEFORE句を指定した場合、ステートメントを実行する前に、該当する条件をチェックします。TEST AFTER句を指定した場合は、条件文を実行する前に、少なくとも1回はステートメントを実行します。TEST BEFORE句またはTEST AFTER句を指定していない場合は、TEST BEFORE句が指定されたものとみなされます。条件が真であれば、PERFORMステートメントの次の実行可能なステートメントが実行されます。
VARYING句を使用したPERFORMステートメント
PERFORMステートメントの4番目のタイプです。1つ以上の変数を使用して、該当する変数を増やしたり減らしたりしながら、指定した条件が真になるまでプロシージャまたは命令ステートメントを実行するタイプです。
procedure-name-1を指定した場合、imperative-statement-1とEND-PERFORMを指定することができません。procedure-name-1が省略されると、AFTER句を指定することができません。

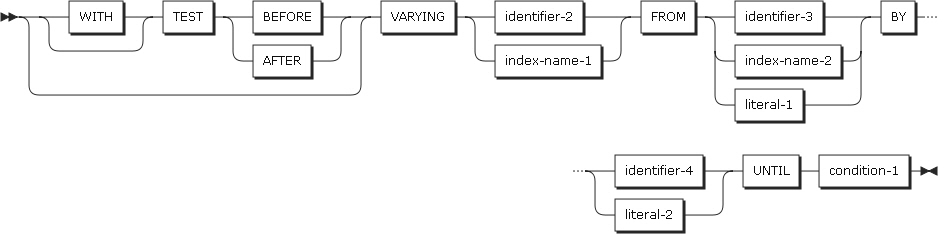
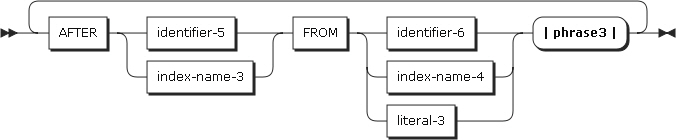

以下は、ステートメントの各設定項目についての説明です。
-
identifier-2からidentifier-7
-
数字データ項目である必要があります。
-
浮動小数点データ項目も指定可能です。
-
-
literal-1からliteral-4
-
数字リテラルである必要があります。
-
浮動小数点データ項目も指定可能です。
-
-
condition-1、condition-2
-
OFCOBOL内で共通して使用できる条件です。
-
ステートメントの条件が真であれば、PERFORMステートメントは実行されません。
-
識別子の変更
TEST BEFORE句の指定有無に応じて、ステートメントを実行する前に該当する条件をチェックします。TEST AFTER句を指定した場合は、条件文を実行する前に、少なくとも1回はステートメントを実行します。TEST BEFORE句またはTEST AFTER句を指定していない場合は、TEST BEFORE句が指定されていると想定します。
以下は、識別子の変更についての説明です。
-
1つの識別子が変更された場合
-
identifier-2またはidentifier-5に添え字が付いている場合、データ項目が設定されるか、変更されるたびに値を評価します。
-
identifier-3、identifier-4、identifier-6、identifier-7に添え字が付いている場合にも、各データの値を設定または変更するたびに値を評価します。
-
以下は、TEST BEFORE句を使用したPERFORMステートメントのフローチャートです。
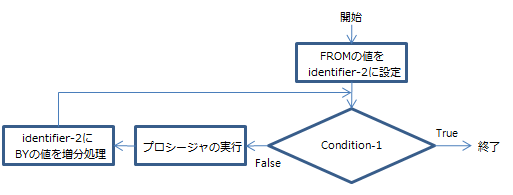 TEST BEFORE句を使用したPERFORMステートメントのフローチャート
TEST BEFORE句を使用したPERFORMステートメントのフローチャート -
以下は、TEST AFTER句を使用したPERFORMステートメントのフローチャートです。
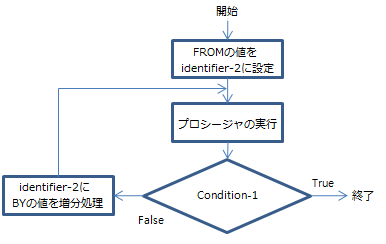 TEST AFTER句を使用したPERFORMステートメントのフローチャート
TEST AFTER句を使用したPERFORMステートメントのフローチャート
-
-
2つの識別子が変更された場合
-
以下のようなPERFORMステートメントがあると想定した場合、OFCOBOLでは、以下の順でPERFORMステートメントをチェックします。

-
IDENTIFIER-2はIDENTIFIER-3に、IDENTIFIER-5はIDENTIFIER-6に、それぞれの値が初期化されます。
-
CONDITION-1の結果に応じて、以下のように処理されます。
-
CONDITION-1がTRUEの場合、PERFORMステートメントを終了して、PERFORMステートメントの次のステートメントを実行します。
-
CONDITION-1がFALSEの場合は、以下の3から7までのステップを実行します。
-
-
CONDITION-2の結果に応じて、以下のように処理されます。
-
CONDITION-2がTRUEの場合、IDENTIFIER-2にIDENTIFIER-4を加算し、IDENTIFIER-5がIDENTIFIER-6の現行値に設定され、ステップ2が繰り返されます。
-
CONDITION-2がFALSEの場合は、以下の4から6までのステップを実行します。
-
-
PROCEDURE-NAME-1からPROCEDURE-NAME-2までのプロシージャを実行します。
-
IDENTIFIER-5にIDENTIFIER-7を加算します。
-
CONDITION-2がTRUEになるまで、3から5までのステップを繰り返します。
-
CONDITION-1がTRUEになるまで、2から6までのステップを繰り返します。
PERFORMステートメントが終了すると、IDENTIFIER-5には、終了時点のIDENTIFIER-6の現行値が入っています。IDENTIFIER-2は、最後の増分または減分の値を持つことになります。
-
-
以下は、TEST BEFORE句を使用したPERFORMステートメントのフローチャートです。
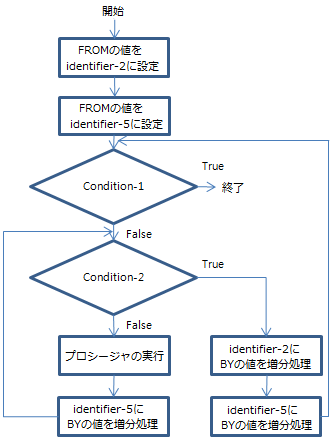 TEST BEFORE句を使用したPERFORMステートメントのフローチャート
TEST BEFORE句を使用したPERFORMステートメントのフローチャート -
以下は、TEST AFTER句を使用したPERFORMステートメントのフローチャートです。
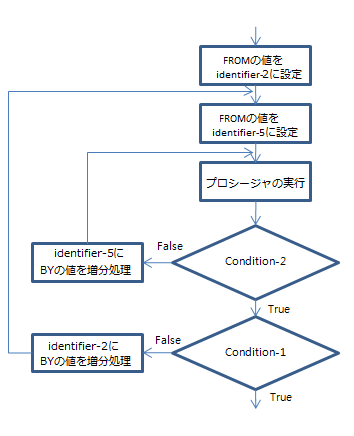 TEST AFTER句を使用したPERFORMステートメントのフローチャート
TEST AFTER句を使用したPERFORMステートメントのフローチャート
-
-
3つの識別子を変更する場合
-
3つの識別子を使用するPERFORMステートメントでの処理は、2つの識別子を使用するPERFORMステートメントでの処理と同様に動作します。ただし、IDENTIFIER-5がIDENTIFIER-7の分だけ増えるたびに、IDENTIFIER-8にIDENTIFIER-10を加算した後、CONDITION-3をチェックする手順が追加されます。

-
PERFORMステートメントが終了すると、IDENTIFIER-5とIDENTIFIER-8は、終了時点のIDENTIFIER-6とIDENTIFIER-9の現行値を持つことになります。IDENTIFIER-2は、最後に増分または減分された値を持ちます。
-
3つ以上の場合は、前述の例にAFTER句が追加された処理となります。
-
PERFORMステートメントでのVARYING句は、識別子の数とは関係なく、以下のような規則が適用されます。
-
VARYING句またはAFTER句の中に指標名を指定した場合
-
指標名に対する初期化の値を増加または減少させるときは、OFCOBOLの指標名の規則に従います。
-
FROM句では、識別子またはリテラルが正の整数である必要があります。
-
BY句の識別子は整数である必要があり、リテラルは0以外の整数でなければなりません。
-
-
FROM句の中に指標名を指定した場合
-
VARYING句またはAFTER句の識別子は必ず整数で指定します。識別子は内部的にSETステートメントを介して初期化されます。
-
BY句での識別子は正の整数である必要があり、リテラルは0以外の整数でなければなりません。
-
-
BY句での識別子とリテラルは、必ず0以外の値を指定します。
-
VARYING句、FROM句、BY句の中で識別子または指標名を変更することは、PERFROMステートメントのプロシージャを実行する回数を変更することになります。
2.26. READ
READステートメントは、順次アクセスの場合、ファイル内の次のレコードを読み込みます。
READステートメントを実行する際、関連するファイルはINPUTモードまたはI-Oモードでオープンされる必要があります。
-
形式1
順次アクセスの場合、ファイルから次のレコードを読み込みます。
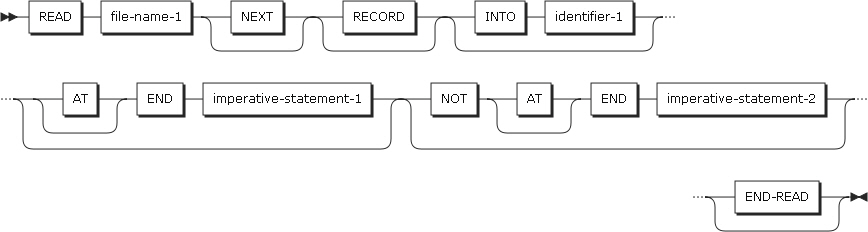 READステートメントの形式1
READステートメントの形式1 -
形式2
ランダム・アクセスの場合、指定されたキーのレコードを読み込みます。
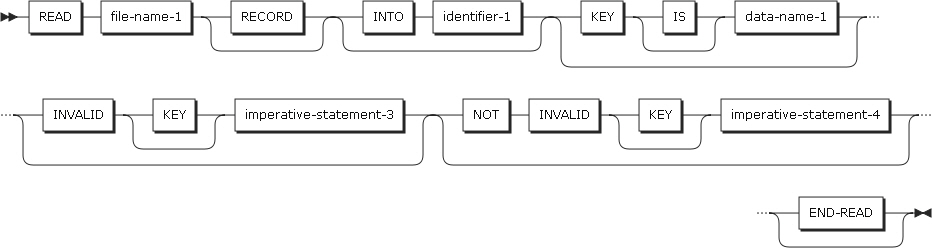 READステートメントの形式2
READステートメントの形式2
以下は、ステートメントの各設定項目についての説明です。
-
file-name-1
-
データ部のFD項目に記述されている必要があります。
-
-
NEXT RECORD
-
次のレコードを読み込みます。
-
順次アクセス・モードの場合、NEXTの存在有無に関係なく、READステートメントの実行には影響を与えません。
-
動的アクセス・モードの場合、レコードを順次に読み込むためには、NEXT RECORD句を記述する必要があります。
-
-
INTO identifier-1
-
レコードを読み込んで受け取るフィールドを指定します。
-
identifier-1は、MOVEステートメントの規則に従って、レコード名1が送り出し項目として指定された有効な受け取り項目である必要があります。
-
identifier-1とfile-name-1は、同じ記憶領域を参照してはなりません。
-
INTO句を指定したREADステートメントの実行結果は、以下の2つのステートメントを実行した結果と同じです。
READ file-name-1. MOVE record-name-1 TO identifier-1.
-
-
KEY IS句
-
指標ファイルにのみ使用できます。
-
data-name-1は、file-name-1と関連したファイルのレコード・キーを指定する必要があります。data-name-1を修飾することができますが、添え字付けはできません。
-
-
AT END句
-
順次アクセスの場合、AT END句とEXCEPTION/ERRORプロシージャを両方とも省略できます。
-
-
INVALID KEY句
-
INVALID KEY句とEXCEPTION/ERRORプロシージャを両方とも省略できます。
-
-
END-READ句
-
明示的にREADステートメントの終了を示します。
-
複数レコードの処理
file-name-1に2つ以上のレコードが記述されていると、それらのレコードは自動的に同じ記憶領域を共有します。
順次アクセス・モード
形式1は、順次アクセス・モードのすべてのファイルに使用することができます。形式1 READステートメントを実行すると、ファイルから次のレコードを読み込みます。
アクセスされる次のレコードは、ファイル編成によって決まります。
-
順次ファイル
-
論理的なシーケンスにより、次の位置にあるレコードを読み込みます。
-
NEXT RECORD句を記述する必要はありません。
-
AT END条件
読み込む次のレコードが存在しない場合、AT END条件が起こり、以下のように処理されます。
-
ファイル制御項目にFILE STATUS句が記述されていると、結果の値がファイル状態キーに保存されます。
-
READステートメントの中にAT END句が指定されていると、imperative-statement-1に記述されているステートメントが実行されます。file-name-1に関連したいかなるUSE AFTER STANDARD EXCEPTIONプロシージャも実行されません。
-
READステートメントの中にAT END句が指定されておらず、適切なUSE AFTER STANDARD EXCEPTIONプロシージャが存在していると、そのプロシージャが実行されます。
AT END句とUSE AFTER STANDARD EXCEPTIONプロシージャは両方とも省略できます。
AT END条件が起こると、READステートメントが正常に実行されなかったことになり、レコード領域の内容を定義することができません。また、ファイル位置指示子は、有効な別のレコードが指定されていないことを示すように設定されます。
AT END条件が起こらなければ、AT END句は無視され、以下のように処理されます。
-
ファイル制御項目にFILE STATUS句が記述されていると、結果の値がファイル状態キーに保存されます。
-
READステートメントの中にNOT AT END句が指定されていると、imperative-statement-2に記述されているステートメントが実行されます。file-name-1に関連したいかなるUSE AFTER STANDARD EXCEPTIONプロシージャも実行されません。
-
READステートメントの中にAT END句が指定されておらず、適切なUSE AFTER STANDARD EXCEPTIONプロシージャが存在していると、そのプロシージャが実行されます。
-
-
-
指標ファイルまたは相対ファイル
-
キー順に従って次のレコードを読み込みます。NEXT RECORD句を記述する必要があります。
-
READステートメントを実行する前に、OPEN、STARTまたはREADステートメントが正常に実行され、ファイル位置指示子が設定されている必要があります。
-
ファイルが順次アクセス・モードの場合、NEXT RECORD句を記述する必要はありません。
-
ファイルが動的アクセス・モードの場合、レコードを順次に読み込むためにNEXT RECORD句を記述する必要があります。
-
アクセスする次のレコードが存在しないと、AT END条件が起こります。
-
相対ファイルに対してRELATIVE KEY節が指定されている場合、READステートメントが実行されると、読み込んだレコードの相対キーを示すために、RELATIVE KEYデータ項目を更新します。
-
ランダム・アクセス・モード
形式2は、ランダム・アクセス・モードまたは動的アクセス・モードの指標ファイルと相対ファイルに記述する必要があります。
-
指標ファイル
-
形式2 READステートメントが実行されると、指定されたキーに対応するレコードを見つけて読み込みます。ファイル位置指示子は、このレコードを指定します。
-
指定されたキーに対応するレコードが存在しないと、INVALID KEY条件が起こり、READステートメントの実行は失敗します。
-
KEY句が記述されていないと、基本RECORD KEYがREADステートメントの実行でキーとして使用されます。KEY句が記述されていると、data-name-1がREADステートメントの実行でキーとして使用されます。
-
-
相対ファイル
-
形式2 READステートメントが実行されると、RELATIVE KEYデータ項目に含まれている相対レコード番号を持つレコードを読み込み、ファイル位置指示子はこのレコードを指定します。
-
ファイルに該当するレコードが存在しなければ、INVALID KEY条件が起こり、READステートメントの実行は失敗します。
-
相対ファイルに対してKEY句が記述されてはなりません。
-
動的アクセス・モード
指標編成または相対編成のファイルに対して動的アクセス・モードを使用することができます。同モードでは、どのような形式のREADステートメントを使用するかによって、順次またはランダムにレコードを読み込むことができます。
レコードを順次に読み込むためには、形式1にNEXT RECORD句を必ず指定します。
2.27. RELEASE
RELEASEステートメントは、ソートまたはマージ処理を開始する前に、レコードをソート処理領域に転送します。SORTステートメントまたはMERGEステートメントのINPUT PROCEDUREが実行される範囲内でのみ使用できます。
INPUT PROCEDURE句には、少なくとも1つのRELEASEステートメントが記述される必要があります。

以下は、ステートメントの各設定項目についての説明です。
-
record-name-1
-
データ部のSD項目に記述されているレコード名を使用する必要があります。
-
record-name-1は修飾することができます。
-
RELEASEステートメントが実行されると、record-name-1の現在の内容は、ソート処理フェーズに移動されます。
-
-
identifiler-1
-
identifier-1は、以下のいずれかを参照しなければなりません。
-
WORKING-STORAGE SECTION、LOCAL-STORAGE SECTION、またはLINKAGE SECTIONのデータ項目
-
すでにオープンされた別のファイルのレコード記述
-
英数字関数
-
-
identifier-1は、MOVEステートメントの規則に従って、レコード名1が受け取り項目として指定された有効な送り出し項目である必要があります。
-
identifier-1とrecord-name-1は、同じ記憶領域を参照してはなりません。
-
RELEASEステートメントの実行後にも、identifier-1の情報は依然として有効です。
-
FROM identifier-1節を使用したRELEASEステートメントの実行結果は、以下の順で記述されたステートメントの実行結果と同じです。
MOVE identifier-1 TO record-name-1. RELEASE record-name-1.
2.28. RETURN
RETURNステートメントは、ソートまたはマージ処理の終了後にレコードをソート処理領域から出力プロシージャに転送します。
SORTステートメントまたはMERGEステートメントの出力プロシージャが実行される領域でのみ使用できます。
出力プロシージャの中には、少なくとも1つのRETURNステートメントが記述される必要があります。

以下は、ステートメントの各設定項目についての説明です。
-
file-name-1
-
データ部のSD項目に記述されている必要があります。
-
1つ以上のレコードが記述されていると、それらのレコードは記憶領域を共有します。RETURNステートメントが実行された後は、現行レコードのみが使用可能です。
-
-
INTO句
-
転送されたレコードをidentifier-1に移動します。
-
-
AT END句
-
RETURNステートメントにより、file-name-1のすべてのレコードが処理されてからAT END条件が起こり、imperative-statement-1が実行されます。
-
RETURNステートメントが実行される間、AT END条件が発生しなければ、NOT AT END句で指定されたimperative-statement-2を実行します。
-
-
END-RETURN句
-
RETURNステートメントの終了を記述します。
-
2.29. REWRITE
REWRITEステートメントは、既存の指標ファイルまたは相対ファイルのレコードを置き換えます。
REWRITEステートメントが実行されるとき、ファイルはI-Oモードでオープンされる必要があります。
順次アクセス・モードでは、READステートメントを正常に実行した後、REWRITEステートメントを実行することができます。

以下は、ステートメントの各設定項目についての説明です。
-
record-name-1
-
データ部のFD項目に記述されているレコード名を使用する必要があります。
-
record-name-1は修飾することができます。
-
-
FROM identifier-1句
-
FROM identifier-1句を使用したRELEASEステートメントの実行結果は、以下の順で記述されたステートメントの実行結果と同じです。
MOVE identifier-1 TO record-name-1. REWRITE record-name-1
-
-
identifier-1
-
identifier-1は、以下のいずれかを参照する必要があります。
-
WORKING-STORAGE SECTION、LOCAL-STORAGE SECTION、またはLINKAGE SECTIONのデータ項目
-
すでにオープンされた別のファイルのレコード記述
-
英数字関数
-
-
identifier-1は、MOVEステートメントの規則に従って、レコード名1が受け取り項目として指定された有効な送り出し項目である必要があります。
-
identifier-1とrecord-name-1は、同じ記憶領域を参照してはなりません。REWRITEステートメントが実行された後も、identifier-1の情報は依然として有効です。
-
-
INVALID KEY句
-
INVALID KEY条件は、以下の場合に起こります。
-
順次アクセス・モードの場合、置き換えられるレコードの基本RECORD KEYの値が、直前のファイルから読み込んだレコードの基本RECORD KEYの値と異なる場合
-
基本RECORD KEYの値が、ファイル内のどのレコードにも含まれていない場合
-
DUPLICATESが記述されておらず、ALTERNATE RECORD KEYの値と同じレコードがすでにファイルに存在する場合
-
-
-
END-REWRITE句
-
REWRITEステートメントの終了を示します。
-
以下は、各ファイルの編成によるREWRITEステートメントの動作についての説明です。
-
順次ファイル
-
順次ファイルに対して、REWRITEステートメントが実行する前に最後に実行された入出力ステートメントは、正常なREADステートメントである必要があります。REWRITEステートメントが実行されると、READステートメントによって読み込まれたレコードが置き換えられます。
-
INVALID KEY句を記述することはできません。EXCEPTION/ERRORプロシージャは記述することができます。
-
-
指標ファイル
-
順次アクセス・モードの場合、基本RECORD KEYの値に対応するレコードが置き換えられます。REWRITEステートメントが実行されるとき、この値は、常に最後に読み込まれたレコードの基本RECORD KEYの値と一致する必要があります。つまり、順次アクセス・モードでは最後に読み込んだレコードに対してのみ更新することができます。この際、基本RECORD KEYに該当する部分は変更できず、残りのデータ部分を変更してからレコードを更新することができます。
-
INVALID KEY句とEXCEPTION/ERRORプロシージャは省略可能です。
-
アクセス・モードがランダムまたは動的の場合、基本RECORD KEYの値に該当するレコードが更新されます。
-
無効キー条件が起きると、REWRITEステートメントは失敗し、レコードは更新されません。
-
-
相対ファイル
-
順次アクセス・モードでは、INVALID KEY句を記述することができません。EXCEPTION/ERRORプロシージャは記述することができます。REWRITEステートメントが実行されると、READステートメントによって読み込まれたレコードが更新されます。
-
アクセス・モードがランダムまたは動的の場合、INVALID KEY句またはEXCEPTION/ERRORプロシージャを記述することが可能であり、両方とも省略することができます。RELATIVE KEYデータ項目のレコードが更新されるとき、該当するレコードが存在しなければ無効キー条件が起こります。
-
2.30. SEARCH
SEARCHステートメントは、指定された条件を満たす要素を検索するために、関連する指標を変更します。END-SEARCH句はSEARCHステートメントの終了を指定します。
形式1(順次検索)
形式1は、表がソートされていない状態で検索するときに使用します。また、ソートされた表を順次検索するか、添え字または指標を直接操作して検索するときも使用できます。
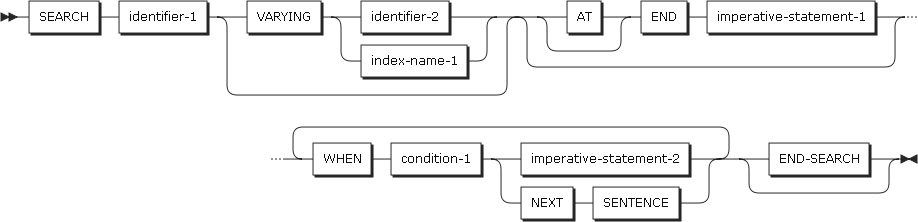
以下は、ステートメントの各設定項目についての説明です。
-
identifier-1
-
検索する表を指定します。
-
identifier-1のデータ記述項目には、INDEXED BY句を指定したOCCURS節を含める必要があります。
-
identifier-1は添え字付きまたは参照変更されてはなりません。
-
identifier-1は、多次元表に含まれている下位のデータ項目を参照することができます。この場合、表の各次元ごとにINDEXED BY句が記述されている必要があります。
-
-
AT END
-
WHEN句に記述された条件を満たすことなく、検索を終了するときの処理を指定します。AT END条件が起こると、imperative-statement-1に記述されたステートメントが実行されます。
-
順次検索を実行する前に検索対象の最初のオカレンスを指定するため、identifier-1の最初の(または一意の)指標の値を設定する必要があります。多次元表に順次検索を行う前に、上位次元の指標にも必ず値を設定します。
SEARCHステートメントは、検索指標とindex-name-1またはidentifier-2の値を変更します。したがって、2次元以上の表全体を検索するためには、各次元ごとにSEARCHステートメントを実行する必要があります。WHEN句で、すべての次元に指標を使用することができます。SEARCHステートメントを実行する前に、SETステートメントを使って関連する指標の値を設定しておく必要があります。
検索が始まると、identifier-1の指標の値は以下に従います。
-
WHEN句の中にある条件が順次に評価されます。
-
条件が1つも満たされない場合は、identifier-1の指標を1つ増加させ、ステップ1が繰り返されます。
-
条件の中で1つが満たされると、検索は即終了し、その条件に関連するimperative-statement-2のステートメントが実行されます。指標は、条件を満たしたときの値を持っています。NEXT SENTENCEが記述されている場合、近いピリオドの後にあるステートメントを実行します。
条件が満たされないまま表の最後に達した場合、検索は終了されます。この際、AT END句が指定されていると、imperative-statement-1のステートメントが実行されます。検索が開始されたとき、identifier-1の指標の値が最大値より大きい場合、検索は即終了します。
-
VARYING句
項目 説明 index-name-1
identifier-1の指標である場合、この指標は検索に使われます。そうでない場合は、検索に使用されたidentifier-1の指標が増加するとき、同量ずつindex-name-1の値も同時に増加します。index-name-1が省略されると、identifier-1の最初の指標が検索に使われます。
identifier-2
指標データ項目または整数データ項目である必要があります。指標データ項目の場合、検索に使用されたidentifier-1の指標が増加するとき、同量ずつindex-name-1の値も同時に増加します。整数データ項目の場合は、検索に使用されたidentifier-1の指標が増加するとき、1ずつ増加します。
-
WHEN句
項目 説明 condition-1
「条件式」に記述されているすべての条件を使用することができます
形式2(2進検索)
形式2(2進検索)は、表のすべてのオカレンスを効率よく検索するときに使用します。表はソートされている必要があります。
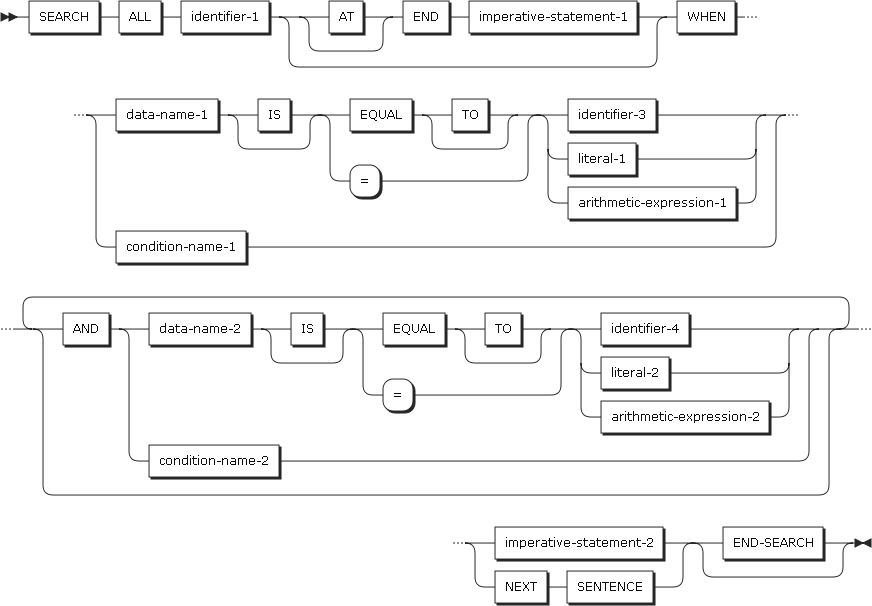
以下は、ステートメントの各設定項目についての説明です。
-
identifier-1
-
検索する表を指定します。
-
identifier-1のデータ記述項目には、INDEX BY句とKEY IS句を持つOCCURS節が含まれている必要があります。
-
identifier-1は添え字付きまたは参照変更されてはなりません。
-
identifier-1は、多次元表に含まれている下位のデータ項目を参照することができます。この場合、表の各次元ごとにINDEXED BY句が記述されている必要があります。
-
-
AT END
-
WHEN句に記述されている条件を満たすことなく、検索を終了するときの処理を指定します。
-
AT END条件が起こると、imperative-statement-1に記述されているステートメントが実行されます。
-
SEARCH ALLステートメントは、2進検索を行います。すべての表を検索するため、identifier-1の指標(検索指標)は、SETステートメントによって初期化される必要はありません。常にOCCURS節に指定された最初の指標名が使われます。多次元表に2進検索を使用する場合は、SEARCH ALLステートメントを実行する前に、SETステートメントを使用して上位次元の指標の値を設定する必要があります。
SEARCHステートメントは、検索指標の値のみ変更するため、2次元以上の(7次元まで)表に対してすべての表を検索するには、それぞれの次元にSEARCHステートメントを実行しなければなりません。表のデータがASCENDINGまたはDESCENDING KEYの順にソートされていないと結果は予測できません。
以下は、2進検索のSEARCHステートメントの形式です。
-
WHEN句
-
WHEN句の条件が満たされると、検索は終了し、imperative-statement-2のステートメントが実行されるか、NEXT SENTENCEによって近いピリオドの後にあるステートメントを実行します。
-
表の中に満足される条件がないと、検索の終了後にAT END条件が起こり、AT END句が存在すればimperative-statement-1のステートメントが実行されます。これらの場合、最後の指標の値を予測することができません。
-
以下の項目を設定します。
項目 説明 condition-name-1,
condition-name-2
指定する条件名は1つの値を持たなければなりません。また、表要素に対してASCENDING KEYまたはDESCENDING KEYデータ項目と関連付けられている必要があります。
data-name-1,
data-name-2
ASCENDING KEYまたはDESCENDING KEYデータ項目であり、identifier-1の最初の指標名で添え字付けされている必要があります。それぞれのデータ名は、修飾することができます。
data-name-1は、identifier-3、literal-1、またはarithmetic-expression-1と比較できる有効なオペランドである必要があります。
data-name-2は、identifier-4、literal-2、またはarithmetic-expression-2と比較できる有効なオペランドである必要があります。
data-name-1とdata-name-2は、浮動小数点データ項目を参照してはなりません。
data-name-1とdata-name-2は、可変オカレンス・データ項目を含むグループ項目を参照してはなりません。
identifier-3,
identifier-4
ASCENDING KEYまたはDESCENDING KEYデータ項目、またはidentifier-1の最初の指標名で添え字付けされる必要はありません。
POINTER、FUNCTION-POINTER、PROCEDURE-POINTERを使用方法として定義されたデータ項目にすることはできません。
data-name-2は、identifier4、literal-2、またはarithmetic-expression-2と比較できる有効なオペランドである必要があります。
literal-1, literal-2
literal-1はdata-name-1と比較できる有効なオペランドである必要があります。
literal-2は、data-name-2と比較できる有効なオペランドである必要があります。
arithmetic-expression
算術式に記述されている表現式にすることができます。
ただし、identifier-1のASCENDING KEYまたはDESCENDING KEYデータ項目や、identifier-1の最初の指標名で添え字付けされたデータ項目を含むことはできません。
-
SEARCHステートメントについての考慮事項
指標データ項目は、表への直接アクセスを制限するために、データの添え字として使用することはできません。
多次元表でSEARCHステートメントの正しい動作を保証するためには、OCCURS DEPENDING ON節が正確な表の長さを明示する必要があります。
NEXT SENTENCE
最も近い区切り文字ピリオドへ移動します。
2.31. SET
SETステートメントは、COBOLプログラム内で以下のような操作を行います。
-
表を管理するための指標項目の値を指定します。
-
指標項目の値を増やしたり減らしたりします。
-
外部スイッチに対してONまたはOFFを指定します。
-
条件名の条件を真または偽に指定します。
-
USAGE POINTER項目にデータ・アドレスを指定します。
-
USAGE PROCEDURE-POINTER/FUNCTION-POINTER項目にデータ・アドレスを指定します。
OFCOBOLでは、USAGE INDEX句を使用して指定した指標と、OCCURS INDEXED BY句を使用して指定した指標を区別しません。いずれの場合も、SETステートメントを使用して指標項目の値を指定することができます。
形式1
形式1は表を管理するために、index-name-1またはidentifier-1に、index-name-2、identifier-2、またはinteger-1の現行値を設定するステートメントです。
以下は、ステートメントの各設定項目についての説明です。
-
index-name-1
-
index-name-1は、値を変更するフィールドです。
-
index-name-1は、データ部のOCCURS節のINDEXED BY句で宣言した項目です。
-
-
identifier-1
-
identifier-1は、値を変更するフィールドです。
-
整数データ項目または指標データ項目である必要があります。
-
-
index-name-2
-
index-name-2は、変更する値を指定するフィールドです。
-
項目の値は、OCCURS節のINDEXED BY句によって指定される必要があります。
-
-
identifier-2
-
identifier-2は、変更する値を指定するフィールドです。
-
整数データ項目または指標データ項目である必要があります。
-
-
integer-1
-
integer-1は、変更する値を指定するフィールドです。これは、正の正数のみ指定できます。
-
形式2
形式2は、指定した値によって指標の値が変更されるのではなく、現行値に指定した値を増減するステートメントです。

以下は、ステートメントの各設定項目についての説明です。
-
index-name-3
-
SETステートメントによって値が変更されるフィールドです。したがって、index-name-3は、SETステートメントの実行前も実行後も、関連する表の指標範囲内に含まれている必要があります。
-
値を変更するフィールドであるidentifier-3は、グループ項目ではなく、基本整数データ項目である必要があり、integer-2は、0以外の整数でなければなりません。
-
形式2のSETステートメントが実行されると、index-name-3はidentifier-3またはinteger-2によって指定された値を増加(UP BY)または減少(DOWN BY)させます。index-name-3は、複数のフィールドを同時に記述することが可能であり、記述されたすべてのフィールドは左から右へ増加または減少されます。
-
形式3
形式3は、外部スイッチのためのSETステートメントです。簡略名で指定された外部スイッチの値をONまたはOFFに指定します。
以下は、ステートメントの各設定項目についての説明です。
-
memonic-name-1
状態をONとOFFに変更できる外部スイッチを指定します。
形式4
形式4は、条件を指定するためのSETステートメントです。条件名にTRUEを指定し、以降のステートメントでその条件が実行できるようにします。条件名に関連するVALUE節の値を設定します。

以下は、ステートメントの各設定項目についての説明です。
-
condition-name-1
-
条件変数を指定できるcondition-name-1を指定します。
-
condition-name-1のVALUE節内に2つ以上リテラルが指定されている場合、最初のリテラルと等しい値を指定します。2つ以上のcondition-name-1を指定した場合は、SETステートメントの中で指定されている順と同じです。
-
形式5
形式5は、USAGE IS POINTERデータ項目を指定するためのSETステートメントです。現行値は、指定した値のアドレスに変更されます。
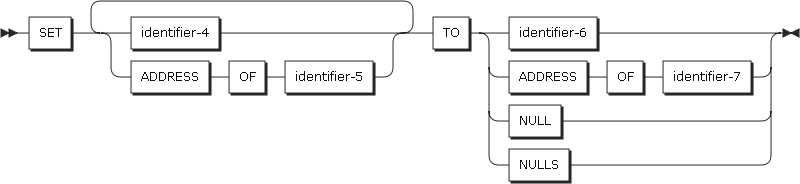
以下は、ステートメントの各設定項目についての説明です。
-
identifier-4
-
変更するフィールドです。これは、USAGE IS POINTERとして指定されている必要があります。
-
-
ADDRESS OF identifier-5
-
identifier-5は、LINKAGE SECTIONの中にレベル01またはレベル77で指定される必要があります。
-
-
identifier-6
-
変更するアドレス値です。これは、USAGE IS POINTERとして指定されている必要があります。
-
-
ADDRESS OF identifier-7
-
identifier-7は、LINKAGE SECTION、WORKING-STORAGE SECTION、またはLOCAL-STORAGE SECTIONで定義したデータ項目である必要があります。
-
レベル66またはレベル88を除いた、別のレベルを指定することができます。
-
ADDRESS OF identifier-7は、identifier-7のアドレスを指定するものであり、識別子の値そのものを意味するものではありません。
-
-
NULL、NULLS
-
identifier-4またはidentifier-5のアドレス値に無効なアドレス値を指定するために使用します。
-
2.32. SORT
SORTステートメントは、1つ以上のファイルからレコードを受け取り、記述されたキーに従ってソートします。
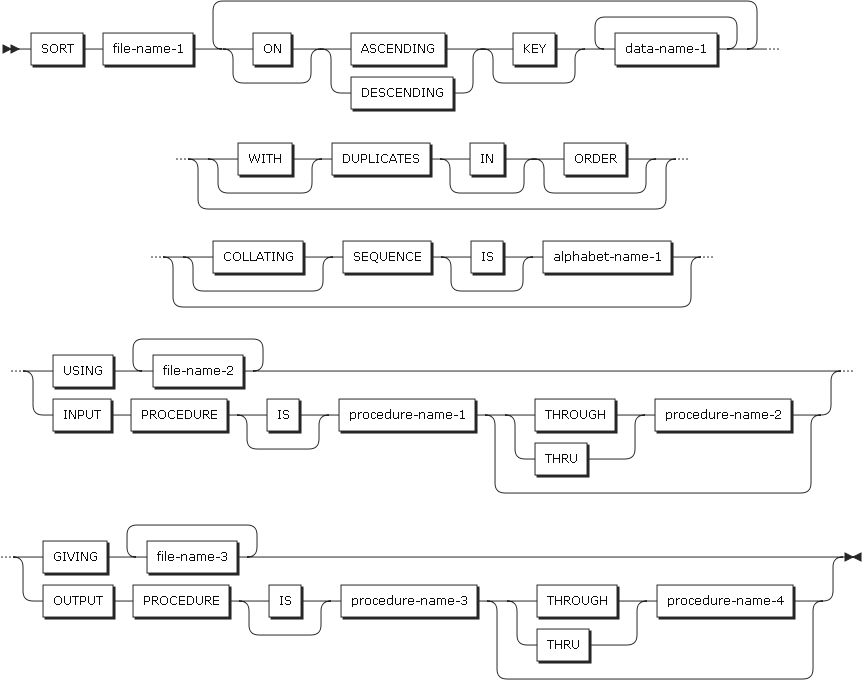
以下は、ステートメントの各設定項目についての説明です。
-
file-name-1
-
ソートされるレコードが含まれているファイル名であり、SD項目に記述されている名前です。
-
-
identifier-1
-
ソートされるレコードが含まれているデータ記述(data description)です。グループ・タイプであり、ソートしたデータが含まれている必要があります。
-
-
ASCENDING KEY句およびDESCENDING KEY句
-
ソート・キーが昇順なのか降順なのかを指定します。
項目 説明 data-name-1
SORTステートメントで使用されるKEYデータ項目を記述します。
data-name-1は、file-name-1のレコードに含まれているデータ項目である必要があります。データ項目が記述されている順に、左から右へと重要度の高いキーとなります。つまり、最初に記述されたデータ項目が最も重要なキーとなり、その次に出てくるデータ項目が2番目の重要なキーです。
-
KEYデータ項目は、各入力ファイルの中で物理的に同じ位置に存在する必要があり、データ形式も同じでなければなりません。ただし、データ名は同じである必要はありません。
-
file-name-1が1つ以上のレコード記述を有する場合、KEYデータ項目は、その中のいずれかのレコードに記述されている必要があります。
-
KEYデータ項目は、OCCURS節を含むことができず、OCCURS節を含む項目に従属されてはなりません。
-
KEYデータ項目は、修飾することが可能であり、以下のデータ・カテゴリのいずれかになります。
-
英字、、英数字、英数字編集
-
数字
-
数字編集(with USAGE DISPLAY)
-
内部浮動小数点またはDISPLAY浮動小数点
-
file-name-3が指標ファイル(indexed file)を参照している場合、data-name-1はASCENDING句で記述される必要があり、データ項目は、指標ファイルの基本レコード・キーと同じ位置を指定しなければなりません。
-
-
-
DUPLICATES句
-
DUPLICATES句が記述されてない場合、同じキーを持つレコードの順序は予測できません。
-
この句が指定されると、キーは同じレコードに対してソートされ、その後は以下のような順となります。
-
入力ファイルのレコード順と同じ順序
-
INPUT PROCEDUREが指定されているとき、RELEASEステートメントに使用されたレコードの順序
-
-
-
COLLATING SEQUENCE句
-
構文チェックのみ行われます。
-
-
USING句
-
入力ファイルを記述します。
項目 説明 file-name-2、...
入力ファイルを定義します。USING句が使用されると、入力ファイル(file-name-2、...、)のすべてのレコードがfile-name-1に自動転送されます。すべての入力ファイルは、データ部のFD項目に記述されている必要があります。
-
-
INPUT PROCEDURE句
-
INPUT PROCEDUREにはRELEASEステートメントがあり、一度に1つのレコードをfile-name-1が参照するファイルに転送します。
-
そのほか、様々なステートメント(OPEN、READ、CLOSEなど)を使用して、入力レコードを選択、コピー、変更することができます。ソート処理を実行する前に入力レコードを選択および変更するプロシージャ名を記述します。
項目 説明 procedure-name-1
INPUT PROCEDUREの最初の(または一意の)セクションまたは段落を記述します。
procedure-name-2
INPUT PROCEDUREの最後のセクションまたは段落を記述します。
-
-
GIVING句
-
出力ファイルを記述します。
項目 説明 file-name-3、...
出力ファイルを定義します。GIVING句が記述されると、ソートされたすべてのレコードは出力ファイルに自動転送されます。すべての出力ファイルはデータ部のFD項目に記述されている必要があります。
-
-
OUTPUT PROCEDURE句
-
出力プロシージャにはRETURNステートメントがあり、file-name-1が参照するファイルから一度に1つのレコードを受け取ります。そのほか、多様なステートメント(OPEN、WRITE、CLOSEなど)を使用して、出力レコードを選択、コピー、変更することができます。
-
ソート処理を実行した後、出力レコードを選択および変更するプロシージャ名を記述します。
項目 説明 procedure-name-3
出力プロシージャの最初の(または一意の)セクションまたは段落を記述します。
procedure-name-4
出力プロシージャの最後のセクションまたは段落を記述します。
-
2.33. START
STARTステートメントは、指標ファイルまたは相対ファイル内で、次のレコードを読み込むためのレコードの位置を設定します。STARTステートメントが実行されるとき、関連するファイルは、INPUTモードまたはI-Oモードのいずれかでオープンされる必要があります。
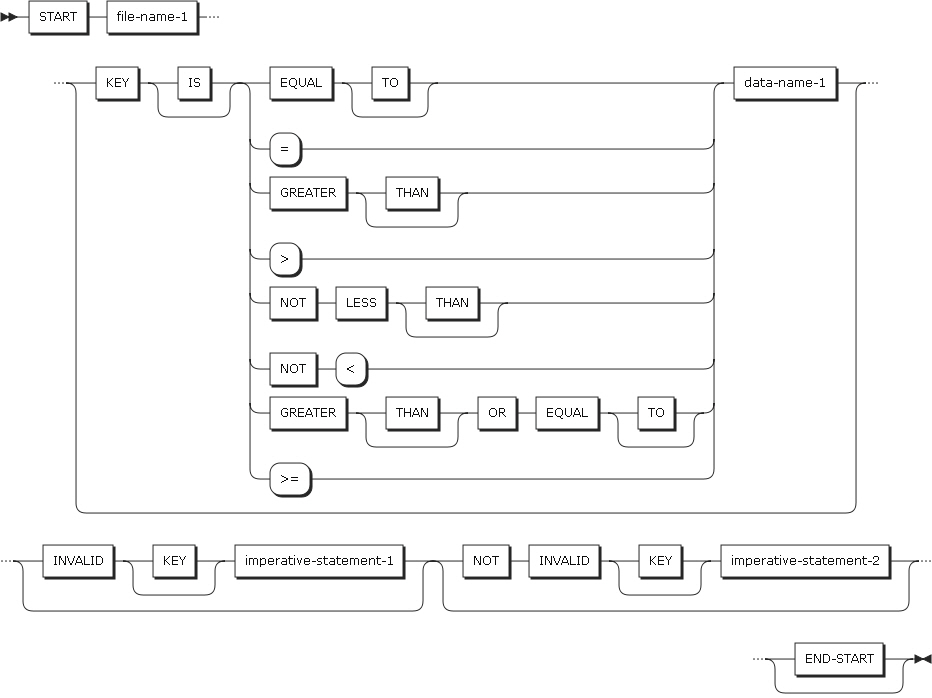
以下は、各設定項目についての説明です。
-
file-name-1
-
順次アクセス・モードまたは動的アクセス・モードのファイル名である必要があります。
-
file-name-1は、データ部のFD項目に定義されている必要があります。
-
-
KEY句
-
KEY句が記述されると、ファイル位置指示子は、条件を満たすキーを持つレコードに位置付けられます。
以降、READステートメントを使用して、次のレコードを順番に読み込むことができます。
項目 説明 data-name-1
修飾することはできますが、添え字付けにはできません。
STARTステートメントが実行されるとき、data-name-1の現行値とファイルの該当するキーを比較することになります。
-
ファイル制御項目の中にFILE STATUSが記述されていると、STARTステートメントの実行時に関連するファイル状態キーも変更されます。
-
-
INVALID KEY句
-
以下の場合、無効キー条件が起こります。
-
指標ファイルに対して順次アクセスであり、OUTPUTモードでオープンされたとき、基本レコード・キーの値が前のレコードより小さい場合
-
指標ファイルに対してI-OモードまたはOUTPUTモードでオープンされたとき、基本レコード・キーの値がすでに存在しているレコードの基本レコード・キーの値と同じである場合
-
相対ファイルに対してランダム・アクセス・モードまたは動的アクセス・モードのとき、RELATIVE KEYがすでに存在しているレコードのRELATIVE KEYと同じである場合
-
-
-
END-START句
-
STARTステートメントの終了を示します。
-
2.34. STOP
STOPステートメントは、プログラムの実行を一時的または永久的に停止します。
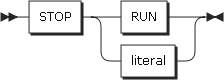
以下は、ステートメントの各設定項目についての説明です。
-
リテラル
-
浮動小数点数と英数字リテラルを指定することができます。
-
ALLリテラルを除く表意定数を指定することができます。
-
STOPステートメントでリテラルが使用された場合、プログラムの実行中にSTOPステートメントが現れると、リテラルを出力した後、プログラムの実行を一時的に停止します。この際、ユーザーがアクションを実行すると、STOPステートメントの次のステートメントが実行されます。
STOP RUNは、プログラムの実行を中断した後、制御をシステムに戻します。STOP RUNステートメントの後に他のステートメントが存在しても、そのステートメントは実行されず、プログラムの実行中にオープンされたすべてのファイルをクローズします。
以下は、STOP RUNステートメントをメインプログラムとサブプログラムで実行したときの結果です。
| 区分 | 結果 |
|---|---|
メインプログラム |
プログラムの制御をシステムに戻します。つまり、プログラムを終了することになります。 |
サブプログラム |
プログラムの制御をメインプログラムを呼び出したプログラムに渡します。つまり、プログラムを終了することになります。 |
2.35. STRING
STRINGステートメントは、2つ以上のデータ項目やリテラルの内容の一部または全部をまとめて、1つのデータ項目として構成します。複数のMOVEステートメントを使用する代わりに、1つのSTRINGステートメントを使用して、類似した作業を済ませることができます。
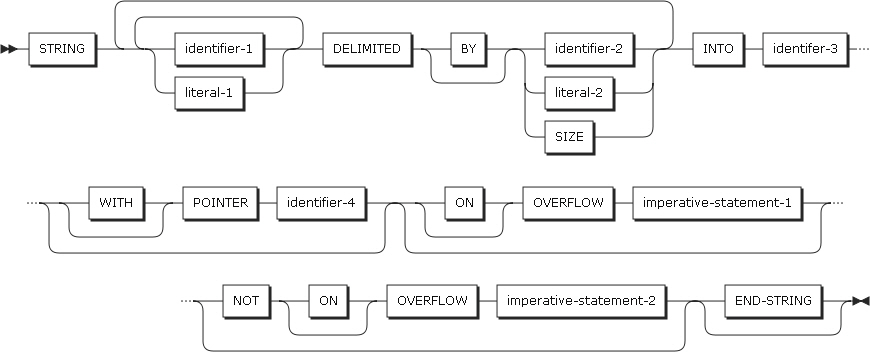
以下は、ステートメントの各設定項目についての説明です。
-
identifier-1、literal-1
-
送り出しフィールドを指定します。USAGE DISPLAYまたはUSAGE DISPLAY-1を明示的または暗黙的に指定したデータ項目である必要があります。英数字タイプの特殊レジスターを指定できます。
-
literal-1は、英数字カテゴリに属している必要があります。ALLというワードで始まらない任意の表意定数(NULLを除く)を指定することができます。表意定数は、それぞれ1文字の英数字リテラルとみなされます。
-
-
DELIMITED BY句
-
文字列を区別する区切り文字を指定します。
-
以下の項目を設定します。
項目 説明 identifier-2, literal-2
文字列を区別する区切り文字を指定します。
転送するデータを区切る文字です。サイズを指定した場合、identifier-1またはliteral-1に指定されたデータ項目がすべて転送されます。
表意定数(ALLを除く)を指定した場合は、1バイトの文字を指定したことを意味します。literal-2は、英数字である必要があります。
SIZE
文字列全体を指定したことを意味します。
-
-
INTO句
-
受け取りフィールドを指定します。
-
以下の項目を設定します。
項目 説明 identifier-3
受け取り文字列を指定します。最終的に作られた文字列が入るデータ項目を指定します。JUSTIFIED節を指定することはできません。
identifier-3がUSAGE DISPLAYの場合、identifier-1およびidentifier-2は、USAGE DISPLAYである必要があり、英数字リテラルを持たなければなりません。ALLで始まる表意定数を除いて、すべての表意定数を指定することができます。表意定数はそれぞれ1文字の英数字リテラルとみなされます。
identifier-3がUSAGE DISPLAY-1の場合、identifier-1およびidentifier-2はUSAGE DISPLAY-1で、DBCSリテラルである必要があります。指定可能な表意定数はSPACEだけです。
-
-
WITH POINTER句
-
結果データを入れるデータ・フィールドの文字の長さを指します。ポインター・フィールドは、送り出し文字列のUSAGEがDISPLAY、DISPLAY-1の場合、相対的な文字の長さを示します。
-
ポインター・フィールドは、結果データの長さに1を加えた値を入れられる十分な大きさのデータ・フィールドを指定します。
-
以下の項目を設定します。
項目 説明 identifier-4
ポインター・フィールドを指定します。指定した場合、プログラマーが明示的に利用することができますが、初期値の設定に注意を払う必要があります。
identifier-4の初期値は、1以上の値でなければなりません。初期値が設定されていないか、または1以上の値でない場合は、値を保証しません。
-
identifier-4を除くすべての項目は、USAGE DISPLAY、DISPLAY-1のいずれかである必要があります。
identifier-1またはidentifier-2が、数字カテゴリのデータ項目を参照する場合、それぞれの数字項目は、PICTURE文字列の中に記号Pを指定していない整数で記述する必要があります。
identifier-1またはidentifier-2が、USAGE DISPLAYの基本データ項目であり、数字、数字編集、英数字編集項目の場合は、英数字項目として扱われます。
添え字、参照変更、可変長、関数識別子などの評価は、STRINGステートメントの開始と同時に行われます。
-
ON OVERFLOW句
-
オーバーフローは、以下のような状況下で起こります。
-
ポインター・フィールドの値が1よりも小さい場合
-
ポインター・フィールドの値が入力として受け取ったデータ・フィールドよりも大きい場合
オーバーフローが発生すると、データはそれ以上転送されません。オーバーフローが発生した時点で、ON OVERFLOWと一緒に指定されたコマンドへ制御が移ります。
-
-
コマンドで制御の移動が明示されている場合は、そのコマンドの規則に従って継続され、そうでない場合は、コマンドを実行した後、STRINGステートメントの最後に転送されます。
-
STRINGステートメントの実行時にオーバーフロー条件が発生していなければ、ON OVERFLOW句は無視されます。このとき、プログラムの制御は、STRINGステートメントの最後に転送されます。また、NOT ON OVERFLOW句が指定されている場合は、一緒に指定されたコマンドに移されます。
-
以下の項目を設定します。
項目 説明 imperative-statement-1
オーバーフローが発生した場合、実行されるステートメントを記述します
-
-
END-STRING句
-
STRINGステートメントの範囲の終わりを明示的に指定します。
-
END-STRING句を使用して、他の条件ステートメントの中にSTRINGステートメントを条件式としてネストすることができます。
-
データ・フロー
STRINGステートメントは、送り出しフィールドから最終結果が入れられる受け取りフィールドに文字を転送します。送り出しフィールドは、STRINGステートメントに記述された順序で処理されます。
以下の規則が適用されます。
-
送り出しフィールドから受け取りフィールドへの文字転送は、以下のような方法で行われます。
-
2バイトの文字は、2バイト文字間のMOVEステートメントの規則が適用されます。
-
それ以外の場合は、英数字間の基本移動に関するMOVEステートメントの規則が適用されます。
-
-
DELIMITED BY identifier-2またはliteral-2を指定した場合、それぞれの送り出しフィールドは、左端に位置する文字から始まり、1文字ずつ次のいずれかの時点まで移動されます。
-
その送り出しフィールドの区切り文字に達した場合(区切り文字自体は移動されません)
-
その送り出しフィールドの右端の文字まで移動された場合
-
-
DELIMITED BY SIZEが指定されている場合、該当する送り出しフィールドの全体が受け取りフィールドに転送されます。
-
受け取りフィールドがいっぱいになるか、またはすべての送り出しフィールドが処理されると、データ転送操作が終了します。
-
POINTER句を指定した場合、ユーザーは、送り出しフィールドのポインターの値を明示的に設定する必要があります。
STRINGステートメントでデータの処理が完了すると、受け取りフィールドはデータが移動された部分のみが変更されます。受け取りフィールドで変更されていない部分には、STRINGステートメントを実行する前のデータが入っています。
2.36. SUBTRACT
SUBSTRACTステートメントは、FROMの後に指定された1つ以上の数字項目から、1つの数字項目または、2つ以上の数字項目の合計を減算し、その結果をFROMの後に指定されたデータ項目に保存します。
-
形式1
形式1は、FROMの前に指定された識別子またはリテラルを加算し、その結果をFROMの後に指定されたidentifier-2から減算してidentifier-2に保存します。identifier-2が複数指定されている場合は、それぞれのidentifier-2に対して左から右へ減算を行い、その結果を該当するidentifier-2に保存します。
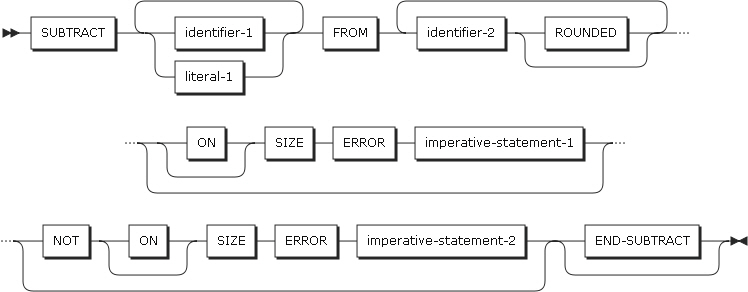 SUBTRACTステートメントの形式1
SUBTRACTステートメントの形式1 -
形式2
形式2は、FROMの前に指定された識別子またはリテラルを加算した合計を、FROMの後に指定されたidentifier-2またはliteral-2から減算し、その結果をidentifier-3に保存します。
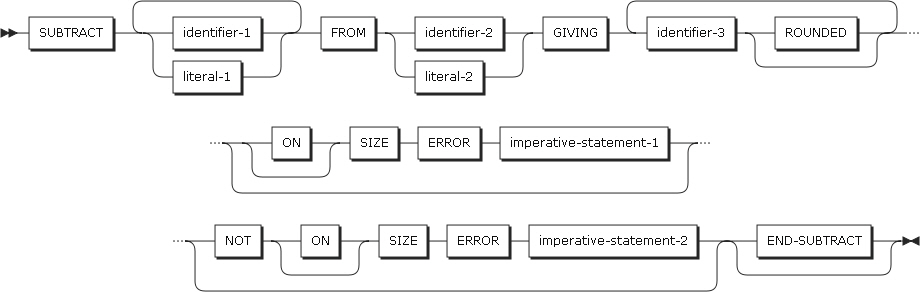 SUBTRACTステートメントの形式2
SUBTRACTステートメントの形式2 -
形式3
形式3は、identifier-2の基本データ項目から同じ名前のidentifier-1の基本データ項目を減算し、その結果を該当するidentifier-2内の基本データ項目に保存します。
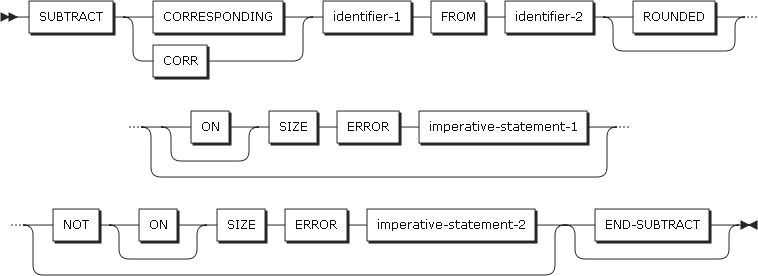 SUBTRACTステートメントの形式3
SUBTRACTステートメントの形式3
以下は、ステートメントの各設定項目についての説明です。
-
識別子
-
形式1でのidentifier-1またはidentifier-2は、基本数字データ項目、浮動小数点データ項目を指定する必要があります。
-
形式2でのidentifier-1またはidentifier-2は、基本数字データ項目、浮動小数点データ項目を指定し、identifier-3は、数字データ項目または数字編集データ項目を指定する必要があります。
-
形式3では、英数字グループ項目を指定する必要があります。
-
-
リテラル
-
数字リテラルと浮動小数点データ項目を指定する必要があります。
-
-
ROUNDED句
-
ROUNDED句については、ROUNDED句を参照してください。
-
-
SIZE ERROR句
-
SIZE ERROR句については、SIZE ERROR句を参照してください。
-
-
CORRESPONDING句
-
CORRESPONDING句については、CORRESPONDING句を参照してください。
-
-
END-SUBTRACT句
-
END-SUBTRACT句は、SUBTRACT句の範囲を明示的に示すために指定します。
-
2.37. UNSTRING
UNSTRINGステートメントを使用して、送り出しフィールドの中の連続したデータを、複数の受け取りフィールドに分割することができます。
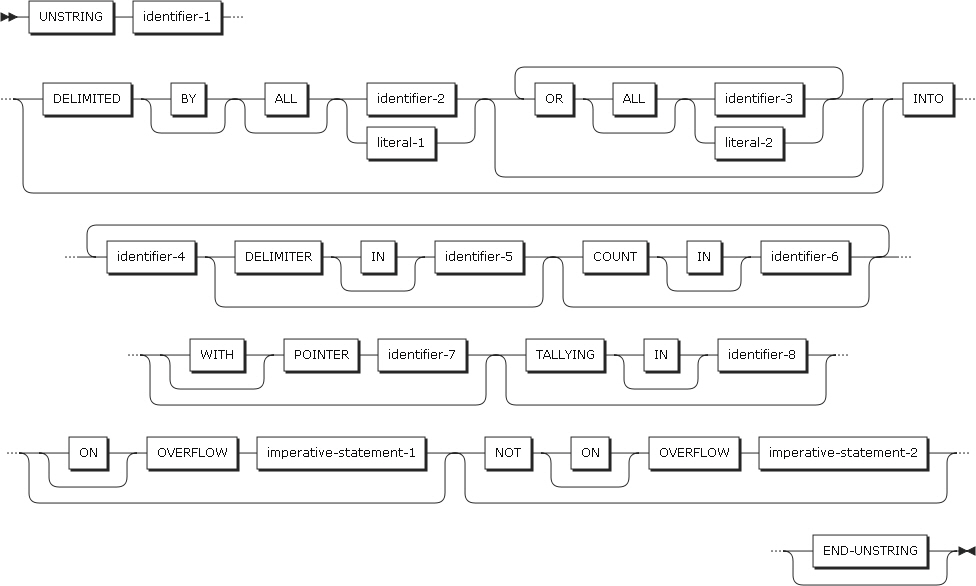
以下は、ステートメントの各設定項目についての説明です。
-
identifier-1
-
送り出しデータ・フィールドを指定します。
-
指定されたフィールドのデータがINTOと一緒に指定されたデータ受け取りフィールドのidentifier-4に転送されます。
-
identifier-1は、英字、英数字、英数字編集、DBCSのカテゴリに属するデータ項目である必要があります。
-
-
DELIMITED BY句
-
データを転送する際、データを区切るための区切り文字を指定します。
-
DELIMITED BY句を指定していない場合は、DELIMITER IN句およびCOUNT IN句を指定することができません。
-
以下の項目を設定します。
項目 説明 identifier-2、identifier-3
1つ以上の区切り文字を指定します。英字、英数字、英数字編集、DBCSのカテゴリに属するデータ項目である必要があります。
literal-1、literal-2
1つ以上の区切り文字を指定します。英数字、DBCSのデータ項目を使用することが可能であり、表意定数の中のALLリテラルを指定することはできません。
-
ALLが指定された場合
複数の連続する区切り文字は、1回だけ現れたものとみなされます。この区切り文字は、identifier-5が指定されていれば、受け取りフィールドであるidentifier-5に転送されます。複数の区切り文字は、同じ基本データ項目として扱われ、現在の区切り文字受け取りフィールドに転送されます。
-
2文字以上の区切り文字
2文字以上を区切り文字として使用する場合、連続しており、かつ送り出しフィールドで指定したデータ項目内に存在していると、区切り文字として認識されます。
-
2つ以上の区切り文字
2つ以上の区切り文字を指定すると、OR条件が適用されます。いずれかの区切り文字がオーバーラップされ現れるたびに、指定された送り出しフィールドで区切り文字として認識されます。
たとえば、以下のように指定した場合や、ABまたはBCが入っているデータ・フィールドを入力として受け取る場合、区切り文字として認識されます。このとき、ABCが現れるとABが現れたとみなされます。
DELIMITED BY "AB" or "BC"
-
-
-
INTO句
-
分割処理されたデータを移動するフィールドを指定します。
項目 説明 identifier-4
1つ以上の受け取りフィールドを指定します。
identifier-4は、英字、数字、DBCSのカテゴリに属するデータ項目を参照します。参照されるデータ項目が数字カテゴリの場合、PICTURE文字列にPを含めることはできません。identifier-4がUSAGE DISPLAYのデータ項目を参照する場合は、identifer-1、identifier-2、identifier-3およびidentifer-5のいずれもUSAGE DISPLAYである必要があり、すべてのリテラルは英数字リテラルでなければなりません。また、USAGE DISPLAY-1の場合は、上述した項目がUSAGE DISPLAY-1またはDBCSリテラルである必要があります。
ALLというワードで始まる表意定数とNULLを除いた任意の表意定数を指定することが可能です。これは、1バイトの英数字リテラルを指定したのと同じです。
identifier-5
区切り文字によって区切られたデータを移動するフィールドを指定します。英字、英数字、DBCSのカテゴリを持つ必要があります。
identifier-6
identifier-4に移動されたデータの長さを入れるフィールドを指定します。整数データ項目であり、PICTURE記号のPが含まれてはなりません。
-
-
DELIMITER IN句
-
区切り文字によって削除されたデータを保存するフィールドを指定します。
項目 説明 identifier-5
英字、英数字のカテゴリ・データ項目である必要があります。
-
-
COUNT IN句
-
検査済みのデータの長さが保存されるフィールドをし指定します。区切り文字は長さに含まれません。
項目 説明 identifier-6
identifier-4に移動されたデータの長さを入れるフィールドを指定します。
identifier-6は、PICTURE文字列のPを使用しない整数データ項目である必要があります。
-
-
POINTER句
-
POINTER句を指定した場合、ポインター・フィールドidentifier-7の値は、データが1つずつ転送されるたびに増加します。最終的にUNSTRINGステートメントの実行が終了すると、ポインター・フィールドには、送り出しフィールド内で検査された文字の長さとその初期値を加算した値が入ります。
-
UNSTRINGステートメントの実行前に、ユーザーはポインター・フィールドの値を初期化する必要があります。
-
以下の項目を設定します。
項目 説明 identifier-7
処理データの長さを保存するデータ・フィールドを指定します。
PICTURE文字列の記号Pを指定していない整数データ項目を指定します。
identifier-1で参照されるデータの長さに1を加えた値が十分に入る大きさのデータ項目である必要があります。
-
-
TALLYING IN句
-
TALLYING句が指定されている場合、カウント・フィールドidentifier-8には、最終的に分割されたデータ項目の長さの合計に初期値を加えた値が保存されます。
-
UNSTRINGステートメントの実行前に、ユーザーはカウント・フィールドの値を初期化する必要があります。
-
以下の項目を設定します。
項目 説明 identifier-8
区切り文字によって削除されたデータ項目の長さを保存するデータ・フィールドを指定します。
PICTURE文字列の記号Pを指定していない整数データ項目を指定します。
-
-
ON OVERFLOW句
-
オーバーフローは、以下のような条件で起こります。
-
ポインター・フィールドの値が1よりも小さい場合
-
ポインター・フィールドの値が出力されるフィールドの長さを超える場合
-
すべての受け取りフィールドの処理が終わっても、送り出しフィールドにデータが残っている場合
オーバーフローが発生すると、UNSTRING処理が終了され、ON OVERFLOW句が指定されていれば、その命令ステートメントに制御が移されます。命令ステートメントに制御の移動が明示されている場合はその規則に従って実行が継続され、そうでない場合は、命令ステートメントを実行した後、制御はUNSTRINGステートメントの終わりに移動されます。
オーバーフローが発生せず、NOT ON OVERFLOW句が指定されていると、指定された命令ステートメントに制御が移されます。指定されていなければ、UNSTRING処理が終了されます。
-
-
以下の項目を設定します。
項目 説明 imperative-statement-1
オーバーフローが発生したときに実行されるステートメントを記述します。
-
-
END-UNSTRING句
-
UNSTRINGステートメントの範囲の終わりを明示的に指定します。END-UNSTRING句を使用して、他の条件ステートメントでUNSTRINGステートメントを条件式としてネストすることができます。
-
2.38. WRITE
WRITEステートメントは、出力ファイルにレコードを書き込みます。
順次ファイルは、OUTPUTまたはEXTENDモードでオープンしている必要があります。
指標ファイルまたは相対ファイルは、OUTPUT、I-O、またはEXTENDモードでオープンしている必要があります。
-
形式1
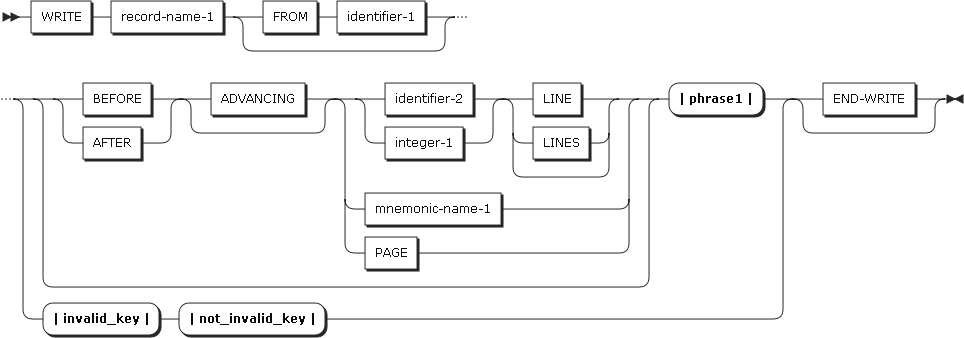 WRITEステートメントの形式1
WRITEステートメントの形式1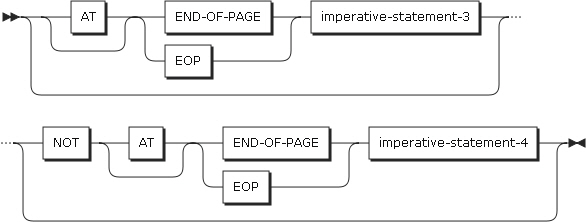 WRITEステートメントの形式1 : 句
WRITEステートメントの形式1 : 句 WRITEステートメントの形式1 : invalid_key
WRITEステートメントの形式1 : invalid_key WRITEステートメントの形式1 : not_invalid_key
WRITEステートメントの形式1 : not_invalid_key -
形式2
 WRITEステートメントの形式2
WRITEステートメントの形式2 -
形式3
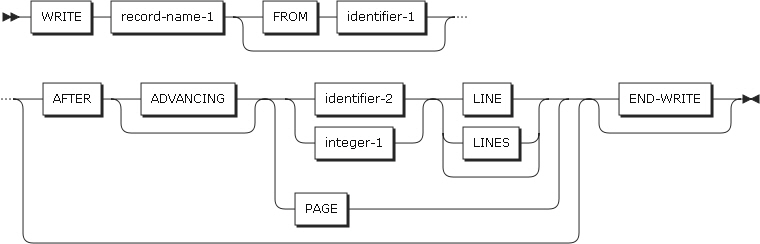 WRITEステートメントの形式3
WRITEステートメントの形式3
以下は、ステートメントの各設定項目についての説明です。
-
record-name-1
-
データ部のFD項目に記述されている必要があります。
-
record-name-1は、修飾することができます。ソート・ファイルとマージ・ファイルと関連付けることはできません。
-
-
FROM句
-
FROM句のWRITEステートメントの実行結果は、以下の2つのステートメントを実行した場合と同じです。
MOVE identifier-1 TO record-name-1. WRITE record-name-1.
-
-
identifier-1
-
identifier-1は、以下のいずれかを参照します。
-
WORKING-STORAGE SECTION、LOCAL-STORAGE SECTION、またはLINKAGE SECTIONのデータ項目
-
すでにオープンされた別のファイルのレコード記述
-
英数字関数
-
-
identifier-1は、MOVEステートメントの規則に従って、record-name-1が受け取り項目として指定された有効な送り出し項目である必要があります。
-
identifier-1とrecord-name-1は、同じ記憶領域を参照してはなりません。WRITEステートメントの実行後も、identifier-1の情報は依然として有効です。
-
-
identifier-2
整数データ項目である必要があります。
-
ADVACING句
ADVANCING句は、出力レコードのページ位置を調整します。
-
ADVANCING句の規則
ADVANCING句が記述されると、以下の規則が適用されます。
-
BEFORE ADVANCINGを指定すると、行が印刷されてからページが進みます。
-
AFTER ADVANCINGを指定すると、ページが進んでから行が印刷されます。
-
identifier-2を指定すると、ページはidentifier-2の値に等しい行数だけ進みます。identifier-2は、整数データ項目である必要があります。
-
integer-1を指定すると、ページはinteger-1の値に等しい行数だけ進みます。
-
integer-1またはidentifier-2の値を0にすることができます。
-
PAGEを指定すると、次の論理ページに進む前か、または進む後(AFTER句またはBEFORE句に応じて)にレコードが印刷されます。
-
簡略名を指定すると、チャンネル1から12までスキップしたり、または行送り抑制が起こります。簡略名は、SPECIAL-NAMES段落に記述されている必要があります。
ADVANCING句がWRITEステートメントに記述されているか、またはファイルにLINAGE節があると、紙送り制御文字が生成され、レコードに添付されます。ADVANCING句が省略されると、AFTER ADVANCING 1 LINEが記述されたかのように動作します。
-
-
LINAGE-COUNTERの規則
ファイルにLINAGE節を指定すると、LINAGE-COUNTER特殊レジスターはWRITEステートメントが実行されるたびに、以下の規則に従って変更されます。
-
ADVANCING PAGEが指定されると、LINAGE-COUNTERは1になります。
-
ADVANCING identifier-2またはinteger-1を指定すると、LINAGE-COUNTERは、identifier-2またはinteger-1の値だけ増加されます。
-
ADVANCING句を省略すると、LINAGE-COUNTERは1だけ増加されます。
-
新しいページに再配置されると、LINAGE-COUNTERは1になります。
-
-
-
END-OF-PAGE句
-
END-OF-PAGE句が指定されており、WRITEステートメントによって論理ページの最後に達すると、END-OF-PAGE句のimperative-statement-3に指定されたステートメントを実行します。END-OF-PAGE句が指定されている場合、FD項目にはLINAGE節が含まれている必要があります。
-
END-OF-PAGE条件は、ページ本体内のフッター領域にレコード行が印刷されるか、ADVANCING句によって行送りが生じた場合に発生します。
すなわち、END-OF-PAGE条件は、LINAGE-COUNTER特殊レジスターの値がLINAGE節のWITH FOOTING句で指定された値と等しくなるか、または大きくなると発生します。
-
自動ページ・オーバーフロー条件は、WRITEステートメントが現在のページ本体で最後まで処理されず、次のページに進むときに発生します。
-
END-OF-PAGE条件または自動ページ・オーバーフロー条件が起こり、END-OF-PAGE句が指定されていると、imperative-statement-3に指定されたステートメントが実行されます。
-
-
INVALID KEY句
-
以下の場合、無効キー条件が起こります。
-
指標ファイルに対して順次アクセスであり、OUTPUTモードでオープンされたとき、基本レコード・キーの値が前のレコードより小さい場合
-
指標ファイルに対してI-OモードまたはOUTPUTモードでオープンされたとき、基本レコード・キーの値がすでに存在しているレコードの基本レコード・キーの値と同じである場合
-
相対ファイルに対してランダム・アクセス・モードまたは動的アクセス・モードのとき、RELATIVE KEYがすでに存在しているレコードのRELATIVE KEYと同じである場合
-
-
-
END-WRITE句
-
明示的にWRITEステートメントの終了を示します。
-
以下は、各I-OモードにおけるWRITEステートメントの使用についての説明です。
-
順次ファイル
-
順次ファイルの最大レコード長は、ファイルが作成されたときに設定され、以降は変更できません。
-
ファイル位置指示子は、WRITEステートメントの実行に影響を与えません。
-
ファイル制御項目にFILE STATUS節が指定されていると、WRITEステートメントの実行後、その結果によりファイル状態キーが更新されます。
-
-
指標ファイル
-
指標ファイルに対してWRITEステートメントを実行する前に、基本レコード・キー(ファイル制御項目にRECORD KEYで定義されたデータ項目)を目的の値で設定する必要があります。この値は、ファイル内で一意でなければなりません。
-
ファイル制御項目にACCESS IS SEQUENTIALが指定されていると、RECORD KEY値の順にレコードが書き込まれる必要があります。
-
-
相対ファイル
-
ファイル制御項目にACCESS IS SEQUENTIALが指定されていると、最初のレードは相対レコード番号1、2番目のレコードは相対レコード番号2、3番目のレコードは相対レコード番号3、...というようにファイルに書き込まれます。このとき、ファイル制御項目にRELATIVE KEYが指定されていれば、書き込まれたレコードの相対番号がRELATIVE KEYに保存されます。
-
ファイル制御項目にACCESS IS RANDOMまたはACCESS IS DYNAMICが指定されていると、WRITEステートメントが実行される前に、RELATIVE KEYが指定された値を持っている必要があります。WRITEステートメントが実行されると、このレコードは、ファイル内の指定された相対レコード番号として保存されます。
-
2.39. XML GENERATE
XML GENERATEステートメントは、データをXML形式に変換します。
以下は、ステートメントの各設定項目についての説明です。
-
identifier-1
-
作成されたXML文書を受け取る領域です。
-
identifier-1は次のいずれかを参照する必要があります。
-
基本英数字データ項目
-
英数字グループ項目
identifier-1が英数字グループ項目を参照する場合、identifier-1は基本英数字データ項目であるかのように扱われます。
identifier-1はJUSTIFIED節を含むデータや関数識別子になることはできませんが、添え字や参照変更を持つことはできます。identifier-1はidentifier-2、identifier-3と重複してはなりません。
identifier-1は作成されたXML文書を含めるほど十分に大きい必要があります。一般的にidentifier-2のデータ名またはデータ名の長さによって、identifier-2のサイズの5倍から10倍のサイズを使用することが望ましいです。もしidentifier-1が十分に大きくない場合は、XML GENEARTEステートメントの最後にエラー条件が存在します。
-
-
-
identifier-2
-
XML形式に変換される基本データ項目またはグループ項目です。
-
identifier-2は関数識別子であったり、参照変更を持つことはできませんが、添え字は持つことができます。identifier-2はidentifier-1、identifier-3と重複してはなりません。identifier-2はRENAMES節を指定できません。
identifier-2で指定された以下のようなデータ項目は、XML GENERATEステートメントで無視されます。
-
従属する名前のない基本データ項目または基本FILLERデータ項目
-
SYNCHRONIZED項目に挿入された任意の余裕バイト
-
REDEFINES節で記述されたり、このように再定義された項目に従属するすべてのデータ項目
-
RENAMES節で記述した項目に従属するすべてのデータ項目
-
下位データ項目がすべて無視されるすべてのグループ・データ項目
-
-
上記の規則に従って無視されない、identifier-2によって指定されたすべてのデータ項目は次の条件を満たす必要があります。
-
それぞれの基本データ項目は英字、英数字、数字、または指標データ項目である必要があります。
-
このような基本データ項目が1つ以上存在する必要があります。
-
FILLERでないデータ名はネストされたグループ・データ項目内で一意の名前を持つ必要があります。
-
データ項目はDATA FORMAT節を指定できません。
-
-
-
identifier-3
-
COUNT IN句を指定した場合、identifier-3はXML GENERATEステートメントの実行後に作成されたXML文字のエンコーディングでのカウントを含みます。一般的にカウントはバイト単位です。
-
identifier-3はPICTURE文字列の記号Pなしに定義される整数データ項目である必要があります。identifier-3はidentifier-1、identifier-2と重複してはなりません。
-
-
ON EXCEPTION句
-
XML文書の作成中にエラーが発生した場合、例外条件があります。たとえば、identifier-1が作成されたXML文書を含むほど大きくない場合は、XMLの作成が中止され、identifier-1の内容は定義されません。もしCOUNT IN句が指定されていれば、idientifier-3は0からidentifier-1の長さまでの範囲で作成された文字位置のカウントを含みます。
-
ON EXCEPTION句を指定した場合、制御はimperative-statement-1に転送されます。ON EXCEPTION句を指定していない場合は、NOT ON EXCEPTION句が存在しても無視され、制御はXML GENERATEステートメントの最後に転送されます。
-
-
NOT ON EXCEPTION句
-
NOT ON EXCEPTION句を指定した場合、XML文書の作成中に例外条件が発生しなければ、制御はimperative-statement-2に転送され、例外条件が発生したら、XML GENERATEステートメントの最後に転送されます。ON EXCEPTION句を指定した場合は無視されます。
-
-
END-XML句
-
XML GENERATEステートメントまたはXML PARSEステートメントの最後を示します。
-
2.40. XML PARSE
XML PARSEステートメントは、XMLPARSEコンパイラー・オプションの設定によるCOBOL言語インターフェースです。
XMLPARSEコンパイラー・オプションには、XMLPARSE(XMLSS)とXMLPARSE(COMPAT)の2種類がありますが、OFCOBOLではXMLPARSE(XMLSS)を基準に扱います。
XML PARSEステートメントはXML文書をフラグメントごとに分析し、各文書をユーザーが作成した処理プロシージャに渡します。
以下は、ステートメントの各設定項目についての説明です。
-
識別子
-
identifier-1は、XML文書の文字列を含みます。identifier-1は英数字データ項目、または英数字グループ・データ項目である必要があります。
-
-
PROCESSING PROCEDURE句
-
XMLパーサーが作成する様々なイベントを処理するプロシージャの名前を指定します。
-
procedure-name-1, procedure-name-2
手続き部のセクションや段落を指定します。procedure-name-1とprocedure-name-2の両方を指定した場合、同じプロシージャ領域内のセクションや段落である必要があります。いずれかが宣言部分内にある名前である場合、両方共、宣言部分内にある名前である必要があります。
-
procedure-name-1
処理プロシージャの最初(または唯一)のセクションまたは段落を指定します。
-
procedure-name-2
処理プロシージャの最後のセクションまたは段落を指定します。
-
-
XMLイベントに対してパーサーはprocedure-name-1というプロシージャの最初のステートメントに制御を転送します。制御は常に処理プロシージャからXMLパーサーに返されます。
制御が返される時点は以下のように決定されます。
-
procedure-name-1が段落名で、procedure-name-2が指定されていない場合、procedure-name-1段落の最後のステートメントを実行した後返されます。
-
procedure-name-1がセクション名で、procedure-name-2が指定されていない場合、procedure-name-1セクションの最後の段落のステートメントを実行した後返されます。
-
procedure-name-2が指定され、段落名である場合、procedure-name-2段落の最後のステートメントを実行した後返されます。
-
procedure-name-2が指定され、セクション名である場合、procedure-name-2セクションの最後の段落のステートメントを実行した後返されます。
procedure-name-1とprocedure-name-2の間で必要な唯一の関係は、procedure-name-1に命名されたプロシージャから始まり、procedure-name-2に命名されたプロシージャの実行により終了する連続する実行順序を定義することです。折り返し点までのパスが2つ以上ある場合、procedure-name-2はEXITステートメントでのみ構成された段落名を指定することができ、折り返し点までのすべてのパスはこの段落で構成される必要があります。
-
-
処理プロシージャはXMLイベントが処理されるすべてのステートメントで構成されます。処理プロシージャの範囲には、処理プロシージャの範囲にあるCALL、EXIT、GO TO、GOBACK、PERFORMステートメントが実行されるすべてのステートメントが含まれます。処理プロシージャの範囲では、GOBACKまたはEXIT PROGRAMステートメントが実行されてはなりません。処理プロシージャではSTOP RUNステートメントを使用して実行装置を終了することができます。
-
-
ON EXCEPTION句
-
ON EXCEPTION句はXML PARSEステートメントで例外条件が発生したときに実行されます。
-
XMLパーサーがXML文書の処理中にエラーを検知した場合、例外条件が存在します。パーサーはまず「EXCEPTION」が含まれた特殊レジスターXML-EVENTを使用して制御を処理プロシージャに転送することで、XML例外を通知します。また一般のXMLイベントについて、パーサーに戻る前に処理プロシージャがXML-CODEを-1に設定した場合にも例外条件が存在します。この場合、パーサーがXML-EVENTを「EXCEPTION」に表示せずに句の分析が終了します。
-
ON EXCEPTION句を指定した場合、パーサーはimperative-statement-1に制御を転送します。ON EXCEPTION句を指定せずにNOT ON EXCEPTION句を指定した場合、NOT ON EXCEPTION句は無視され、制御はXML PARSEステートメントの最後に転送されます。処理プロシージャがXML例外イベントを処理し、XML-CODEを0に設定した後、制御権限をパーサーに返す場合、例外条件はそれ以上存在しません。
-
-
NOT ON EXCEPTION句
-
NOT ON EXCEOPTION句はXML PARSE処理を終了するとき、例外条件が存在しない場合に実行されます。XML PARSE処理を終了時に例外条件が存在しない場合、NOT ON EXCEPTIONが指定されていれば、制御はNOT ON EXCEPTION句のimperative-statement-2に転送されます。NOT ON EXCEPTION句が指定されていなければ、制御はXML PARSEステートメントの最後に転送され、ON EXCEPTION句が指定されていれば、無視されます。
-
特殊レジスターXML-CODEはXML PARSEステートメントを実行した後に0を含みます。
-
-
END-XML句
-
XML GENERATEステートメントまたはXML PARSEステートメントの最後を示します。
-