その他のユーティリティ
本章では、その他のユーティリティについて説明します。
1. 概要
以下は、その他のユーティリティの一覧です。各ユーティリティの説明は、各節の内容を参照してください。
| ユーティリティ | 説明 |
|---|---|
業務処理などに使用されるデータセットを、簡単なコマンドで自由に操作するユーティリティプログラムです。 |
|
データセットのレコードごとの差異を表示するユーティリティプログラムです。 |
|
JCLのSYSINで入力されたCA-Easytrieve Plusスクリプトを実行するユーティリティプログラムです。 |
|
SORTユーティリティプログラムを利用して、1つのJOB STEPで複数のデータセットを様々な方法で出力するユーティリティプログラムです。 |
|
JCLに記述された内容が正常に実行されるかを確認するために使用するテスト用ユーティリティプログラムです。 |
|
データベースを使用するバッチアプリケーションをJCLで実行する際に、アプリケーションが実行される前にデータベースシステムへ接続するユーティリティプログラムです。 |
2. ADAPT
ADAPTは、簡単なコマンドを使用してアプリケーションの処理などに使用されるデータセットを操作できるユーティリティ・プログラムです。
コピー(COPY)、編集(EDIT)、比較(COMP)、印刷(PRINT)、ダンプ(LIST)、変更(ALTER)、追加(INSERT)、チェック(CHECK)機能があります。現在は、コピー(COPY)、編集(EDIT)、変更(ALTER)機能のみサポートしています。
2.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
SYSIN DD |
ADAPTに必要なコマンドを指定します。 |
SYSPRINT DDまたは SYSOUT DD |
ADAPTの実行中に発生したメッセージが出力されます。 |
任意のDD |
ADAPTの入力データセットまたは出力データセットを指定します。SYSINでINPUT、OUTPUT、OUT2(ddname)を使用して任意のDDを使用するように指定します。 |
2.2. コマンドの設定
SYSIN DDを使用して次の順でコマンドを指定することができます。複数を指定することも可能です。各コマンドの使用方法は、各節の説明を参照してください。
-
コマンド記述時の制限事項
-
コマンドは空白または文字(/)で始まる必要があります。
-
コマンドは70文字を超えないようにします。
-
コマンドの後の空白以降はコメントとして処理されます。
-
2.2.1. 機能制御コマンド
-
COPY
コマンドに指定された条件に従ってレコードを抽出、削除、分類します。
以下は、COPYコマンドの構文です。
COPY OUTPUT,INPUT[,OUT2(ddname)]
パラメータ 説明 OUTPUT
出力データセットのDD名を指定します。
INPUT
入力データセットのDD名を指定します。
OUT2
OUT2を指定すると、抽出条件に合わないレコードはOUT2に設定されたDD名で出力されます。ddnameには、分類用のデータセットのDD名を指定します。
-
EDIT
コマンドに指定された条件に従ってレコードを抽出し、そのレコード内の項目を編集して出力します。抽出しないレコードは出力せずにスキップします。
以下は、EDITコマンドの構文です。
EDIT OUTPUT,INPUT
パラメータ 説明 OUTPUT
出力データセットのDD名を指定します。
INPUT
入力データセットのDD名を指定します。
-
ALTER
コマンドに指定された条件に従ってレコードを抽出し、その内容をコマンドに指定された内容で変更して出力します。変更しないレコードはそのまま出力し、変更されるレコードは変更後の内容を印刷できます。
以下は、ALTERコマンドの構文です。
ALT[ER] OUTPUT,INPUT
パラメータ 説明 OUTPUT
出力データセットのDD名を指定します。
INPUT
入力データセットのDD名を指定します。
2.2.2. 条件制御コマンド
-
KEY
条件を指定するコマンドです。入出力レコード形式を指定します。
以下は、KEYコマンドの構文です。
KEY keypos,keylen,keyfmt[,keypos,keylen,keyfmt,...]
パラメータ 説明 keypos
キー・フィールドの開始位置を指定します。
keylen
キー・フィールドの長さを指定します。
keyfmt
キー・フィールドの形式を指定します。現在は、XとPのみ使用できます。
-
X : 文字(Character)
-
9 : 10進数(Decimal)
-
P : パック10進数(Packed Decimal)
-
H : 16進数(Hex Decimal)
-
HL : 2進数(Binary)
-
-
K
抽出条件を指定するコマンドです。レコードの内容を指定します。現在は、COPYとALTERコマンドでのみ使用できます。
以下は、Kコマンドの構文です。
KEY keynum,operator,value[,keynum,operator,value,...]
パラメータ 説明 keynum
KEY文で設定されたキー番号を指定します。
operator
比較演算子を指定します。
-
G または > : データ > 値
-
L または < : データ < 値
-
E または = : データ = 値
-
NG または N> : データ <= 値
-
NL または N< : データ >= 値
-
NE または N= : データ != 値
value
比較するデータを指定します。単一引用符(')で囲まれた文字列または整数の値を指定できます。
-
-
R
抽出条件を指定するコマンドです。レコードの数を指定します。現在は、ALTERコマンドでのみ使用できます。
以下は、Rコマンドの構文です。
R startnum[,endnum]
パラメータ 説明 startnum
開始レコードの番号を指定します。
endnum
終了レコードの番号を指定します。データセットの最後まで処理するEOFを指定します。指定しない場合は、最初のレコードのみ処理されます。
-
ED
編集条件を指定するコマンドです。EDIT機能コマンドでのみ使用します。
以下は、EDコマンドの構文です。
ED recvnum=sendnum
パラメータ 説明 recvnum
編集するキー番号を指定します。KEY文に設定されたキー番号を指定します。
sendnum
編集する内容を含むキー番号を指定します。KEY文に設定されたキー番号を指定します。
-
A
ALTER機能コマンドを使用する際、変更項目を指定します。
以下は、Aコマンドの構文です。
A keypos,keylen,keyfmt,value
パラメータ 説明 keypos
変更項目の開始位置を指定します。
keylen
変更項目の長さを指定します。
keyfmt
変更項目の形式を指定します。KEYコマンドのkeyfmtと同じ形式です。
value
変更内容を指定します。単一引用符(')で囲まれた文字列または整数の値を指定できます。
2.3. 使用例
以下は、OPENFRAME.ADAPT.U01データセットをOPENFRAME.ADAPT.U11データセットにコピーする例です。レコードの8番目の文字が「4」で、225番目の文字が「2」のレコードをコピーし、それ以外はOPENFRAME.ADAPT.U10データセットにコピーします。
//JOB01 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //COPY EXEC PGM=ADAPT //U01 DD DSN=OPENFRAME.ADAPT.U01,DISP=SHR //U10 DD DSN=OPENFRAME.ADAPT.U10,DISP=SHR //U11 DD DSN=OPENFRAME.ADAPT.U11,DISP=SHR //SYSOUT DD SYSOUT=* //SYSPRINT DD SYSOUT=* //SYSIN DD * / COPY U11,U01,OUT2(U10) / KEY 8,1,X,225,1,X / K 1,E,'4' / K 2,E,'2' /*
以下は、OPENFRAME.ADAPT.U01データセットの内容を編集してOPENFRAME.ADAPT.U02データセットに保存する例です。レコードの179番目の文字から始まる長さ3の文字列を、147番目の文字から始まる長さ3の文字列に編集します。
//JOB02 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //COPY EXEC PGM=ADAPT //U01 DD DSN=OPENFRAME.ADAPT.U01,DISP=SHR //U02 DD DSN=OPENFRAME.ADAPT.U02,DISP=SHR //SYSOUT DD SYSOUT=* //SYSPRINT DD SYSOUT=* //SYSIN DD * / EDIT U02,U01 / KEY 147,3,X,179,3,X / ED 2=1 /*
以下は、OPENFRAME.ADAPT.U01データセットの内容を変更してOPENFRAME.ADAPT.U10データセットに保存する例です。144番目の文字から始まる長さ6の文字列が「498830」で、8番目の文字から始まる長さ3の文字列が「100」のレコードである場合、対象レコードの169番目の文字から始まる長さ5の文字列を「00100」に変更し、179番目の文字から始まる長さ6の文字列を「001000」に変更します。
144番目の文字から始まる長さ6の文字列が「498830」で、8番目の文字から始まる長さ3の文字列が「101」のレコードの場合、対象レコードの169番目の文字から始まる長さ5の文字列を「00200」に変更し、179番目の文字から始まる長さ6の文字列を「002000」に変更します。
//JOB03 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //COPY EXEC PGM=ADAPT //U01 DD DSN=OPENFRAME.ADAPT.U01,DISP=SHR //U10 DD DSN=OPENFRAME.ADAPT.U10,DISP=SHR //SYSOUT DD SYSOUT=* //SYSPRINT DD SYSOUT=* //SYSIN DD * / ALTER U10,U01 / KEY 144,6,X,8,3,X / K 1,E,'498830',2,E,'100' / A 169,5,X,'00100' / A 179,6,X,'001000' / K 1,E,'498830',2,E,'101' / A 169,5,X,'00200' / A 179,6,X,'002000' /*
3. DSDIFF
DSDIFFは、データセットの各レコードの相違点を表示するユーティリティ・プログラムです。
OpenFrameのインストール後、またはユーティリティやライブラリなどの各種モジュールを更新した後に実行する検証テストです。データセットが正常に作成されたかどうかを確認するために使用できます。
3.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
SYSIN DD |
比較するデータセットのddnameリストを定義します。 リストの区切り子としてコンマ(,)を使用します。たとえば、「AA,BB,CC」は、AA、BB、CCを比較します。 |
TARGET DD |
比較するデータセットを定義します。比較データセットは、SYSIN DDに定義されたddnameリストに含まれる必要があります。 |
3.2. コマンドの設定
以下は、データセット・リストを定義するSYSIN DDの構文です。
ddname,ddname[ddname,....]
SYSIN DDにデータセット・リストを定義するほか、別途設定が必要なコマンドはありません。
3.3. 使用例
以下は、EXPECTED、INREC、SUM DDの3つのレコードを比較して相違点を表示する例です。
//JOB01 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //DSDIFF EXEC PGM=DSDIFF,REGION=2M //SYSIN DD * EXPECTED,INREC,SUM /* //SYSOUT DD SYSOUT=* //EXPECTED DD DSN=OFTEST.SORT.OUT01.EXPECTED,DISP=OLD //INREC DD DSN=OFTEST.SORT.OUT01.INREC,DISP=OLD //SUM DD DSN=OFTEST.SORT.OUT01.SUM,DISP=OLD
4. EZTPA00
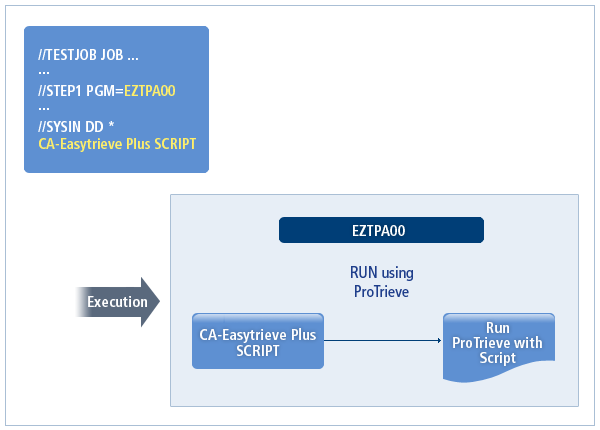
EZTPA00は、JCLのSYSINで入力されたCA-Easytrieve Plusスクリプトを実行するユーティリティ・プログラムです。
外部プログラムである弊社のProTrieveを使用してスクリプトを実行します。外部プログラムのための環境設定が必要です。CA-Easytrieve Plusスクリプトを使用してデータセットの入出力、データの加工、レポートの作成などを実行できます。
以下の図は、EZTPA00のプロセスを示しています。CA-Easytrieve PlusスクリプトがProTrieveに渡されて実行されます。
|
CA-Easytrieve Plusスクリプトの詳細については、ProTrieveガイドを参照してください。 |
4.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
SYSIN DD |
CA-Easytrieve Plusスクリプトの入力データセットを指定します。 |
SYSPRINT DD |
CA-Easytrieve Plusの結果として作成されたレポートまたはDISPLAYで記述されたメッセージの出力データセットを指定します。 |
SYSOUT DD |
CA-Easytrieve Plusの実行中にEZTPA00、ProTrieveから発生したメッセージの出力データセットを指定します。 |
anyname DD |
CA-Easytrieve Plus文でファイルを処理するために使用されるデータセットを指定します。DD名は、CA-Easytrieve Plusスクリプトのファイル名と同じである必要があります。 |
4.2. 使用例
以下は、EZTPA00を使用してFILEAからFILEBにコピーする例です。
//SAMPLE JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//EZPLUS EXEC PGM=EZTPA00
//SYSPRINT DD SYSOUT=*
//SYSOUT DD SYSOUT=*
//FILEA DD DSN=OPENFRAME.EZPLUS.FILEA,DISP=SHR
//FILEB DD DSN=OPENFRAME.EZPLUS.FILEB,DISP=(NEW,CATLG),
// DCB=(RECFM=FB,LRECL=1024,BLKSIZE=10240)
//SYSIN DD *
FILE FILEA
RECA 1 1024 A
FILE FILEB
RECB 1 1024 A
*
JOB INPUT FILEA
MOVE FILEA TO FILEB
PUT FILEB
/*
SYSOUT DDが存在しないと、ユーティリティの実行中に発生したメッセージがSYSPRINTに出力され、目的のSYSPRINTの出力結果を得られない場合があります。
5. ICETOOL
ICETOOLは、SORTユーティリティ・プログラムを使用して、1つのジョブ・ステップで複数のデータセットを出力するためのユーティリティ・プログラムです。TOOLIN DDで指定されたコマンドに従って、SORTユーティリティ・プログラムを使用してデータを処理します。
以下は、ICETOOLが提供する主要機能です。
-
ソートされた入力データセットのコピーを作成します。
-
修正または修正されていない入力データセットのコピーを作成します。
-
修正または修正されていない入力データセットのレコード数を出力します。
-
文字と数字フィールドまたは一意の値が発生した総回数などの多様な基準で入力データセットを含む出力データセットを作成します。
-
異なる形式のレコード・フィールドをマージして、1つまたは複数のレコードで出力します。
5.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
TOOLMSG |
ICETOOLの出力メッセージを格納します。 |
DFSMSG |
ICETOOLがSORTプログラムを内部的に使用中に出力されるメッセージを格納します。 |
TOOLIN |
ICETOOLコマンドを指定します。 |
indd |
ICETOOLの入力データセットを指定します。TOOLINでFROM(indd)を介してinddを使用するように指定します。 |
outdd |
ICETOOLのCOPY、SELECT、SORTの実行時に使用される出力データセットを指定します。TOOLINでTO(outdd)を介してoutddを使用するように指定します。 |
savedd |
ICETOOLのSELECTの実行時に使用される出力データセットを指定します。TOOLINでDISCARD(savedd)を介してsaveddを使用するように指定します。 |
countdd |
ICETOOLのCOUNTの実行時に使用される出力データセットを指定します。 |
xxxxCNTL |
ICETOOLが内部的に使用するSORTのコマンドを指定します。TOOLINでUSING xxxxを介してxxxxCNTL DDを使用するように指定します。 |
5.2. コマンドの設定
ICETOOLで設定できるコマンドについて説明します。
-
COPY
inddに指定されたデータを1つ以上のoutddにコピーします。USING句を介してxxxxCNTLを使用してSORTを実行することもできます。
以下は、COPYコマンドの構文です。
COPY FROM(indd) TO(outdd,[outdd,...]) | USING(xxxx) | {TO(outdd,[outdd,....]) USING(xxxx)} [VSAMTYPE(x)] [SERIAL]パラメータ 説明 FROM
COPYコマンドを実行する入力データセットを指定します。
TO
COPYコマンドの実行結果が格納される出力データセットを指定します。
outddにはすべて同じ結果が格納されます。TOとUSINGは同時に指定することが可能であり、いずれか1つを必ず指定してください。
USING
COPYで使用されるSORTのコマンドを指定します。
USINGが指定されている場合は、xxxxCNTL DDを必ず指定します。また、TOが指定されていない場合は、xxxxCNTL ddにOUTFILとして出力データセットを指定する必要があります。
VSAMTYPE
実際には機能せず、エラーの発生を防ぐためにサポートされます。
SERIAL
実際には機能せず、エラーの発生を防ぐためにサポートされます。
-
COUNT
入力データセットのレコード数を出力します。USING句がある場合は、再フォーマットされた後のレコード数を出力します。
以下は、COUNTコマンドの構文です。
COUNT FROM(indd) [USING(xxxx)] [RC4] [EMPTY] [EQUAL(v)] [WRITE(countdd)] [TEXT('string')] [DIGITS(d)]パラメータ 説明 FROM
COUNTコマンドを実行する入力データセットを指定します。
USING
COUNTコマンドで使用されるSORTユーティリティのコマンドを指定します。
RC4
RC4が指定されると、EMPTY、NOTEMPTY、HIGHER(x)、LOWER(y)、EQUAL(v)、NOTEQUAL(w)などの条件を満たす場合にRC=4を返します。
OpenFrameでは、EMPTYのみサポートされます。(デフォルト値: RC=12)
EMPTY
入力データセットが空の場合は、RC=12(RC4が指定された場合はRC=4)を返し、そうでない場合は、RC=0を返します。
EQUAL(v)
COUNTコマンドの結果としてレコードの数がv個の場合、RC=12(RC4が指定された場合は、RC=4)を返します。
WRITE(countdd)
countddを指定します。countddは、レコード数を出力するデータセットのddnameを意味します。countdd DDの形式は、FBのみ指定できます。
TEXT('string')
countddデータセットに文字列を出力します。レコード数は、その文字列の後に出力されます。TEXTは、WRITEが指定された場合にのみ使用できます。
DIGITS(d)
レコード数が出力される桁数を指定します。DIGITSを指定しない場合のデフォルト値は15です。
-
DISPLAY
inddで指定された入力データを設定値に従って出力します。
以下は、DISPLAYコマンドの構文です。
DISPLAY FROM(indd) LIST(listdd) ON(p,m,f)[ ON(p,m,f) ...] ON(p,m,f,E'pattern')[ ON(p,m,f,E'pattern') ...] ON(VLEN) ON(NUM) TITLE('string1') PAGE DATE(abcd) TIME(abc) BLANK HEADER('string1') [HEADER('string1') ...] LINES(n) COUNT('string') WIDTH(n) BETWEEN(n)パラメータ 説明 FROM
入力データセット名を指定します。
LIST
出力されるリスト・データセット名を指定します。
ON(p,m,f)
DISPLAYコマンドが適用されるフィールドを定義します。pバイトからmバイトまで、f形式で適用します。
使用できるf形式については、OpenFrame Batch『SORTユーティリティリファレンスガイド』の「OUTFIL」の「OUTREC | BUILD」を参照してください。
ON(p,m,f,E’pattern')
DISPLAYコマンドが適用されるフィールドを定義します。pバイトからmバイトまでf形式に変換した後、「pattern」に指定した形でDISPLAYコマンドを適用します。
使用できるf形式は、OpenFrame Batch『SORTユーティリティリファレンスガイド』の「OUTFIL」の「OUTREC | BUILD」を参照してください。
ON(VLEN)
入力レコードが可変長レコード(VB)の場合、レコード長を表示します。
ON(1,2,BI)と同じです。VLENフィールド長のデフォルトは16バイトです。
ON(NUM)
レコード番号は1から始まり、各レコードごとに1ずつ増加した値を表示します。
TITLE('string1')
タイトル行のタイトル(string1)を出力します。タイトル行は、リスト・データセットの最初の行に出力されます。
PAGE
タイトル行に現在のページを出力します。
DATE(abcd)
タイトル行に現在の日付を表示します。
-
abc : M(月)、D(日)、Y(年)または4の組み合わせで構成されます。Yは2桁年を、4は4桁年を出力します。
-
d : 区切り文字として使用される任意の文字です。
TIME(abc)
タイトル行に現在の時刻を表示します。
-
ab : 12時間制または24時間制で表示します。
-
c : 区切り文字として使用される任意の文字です。
BLANK
数値フィールドの先行ゼロを空白で表示します。
HEADER('string1')
ONフィールドのタイトルを出力します。HEADERフィールドとONフィールドは、指定された順序に従って1対1で対応されます。
LINES(n)
1ページあたりの行数を表示します。(デフォルト値: 58、nの範囲: 10 ~ 999)
COUNT('string')
'string’を出力し、それに続いてレコード数を出力します。
WIDTH(n)
出力されるデータセットの行の長さを制限します。
BETWEEN(n)
出力されるデータセットの列スペースの数を指定します。(デフォルト値: 3、nの範囲: 0 ~ 50)
-
-
OCCUR(S)
指定されたフィールドと、そのフィールドが出現される回数を出力します。
以下は、OCCURコマンドの構文です。
OCCUR(S) FROM(indd) LIST(listdd) ON(p,m,f)[ ON(p,m,f) ...] ON(VLEN) ON(VALCNT) ON(VALCNT,Ndd) TITLE('string1') DATE(abcd) TIME(abc) BLANK HEADER('string1') [ HEADER('string1') ...] NOHEADER LINES(n)パラメータ 説明 FROM
入力データセット名を指定します。
LIST
出力されるリスト・データセット名を指定します。
ON(p,m,f)
OCCURコマンドが適用されるフィールドを定義します。pバイトからmバイトまで、f形式で適用します。
ON(VLEN)
入力レコードが可変長レコード(VB)の場合、レコード長を表示します。
ON(1,2,BI)と同じです。VLENフィールド長のデフォルトは16バイトです。
ON(VALCNT)
ON(p,m,f)で指定されたフィールドが現れる回数を表示します。VALCNTフィールド長のデフォルトは15バイトです。
ON(VALCNT,Ndd)
ON(p,m,f)で指定されたフィールドが現れる回数を表示します。VALCNTフィールドの長さはddバイトです。
TITLE('string1')
タイトル行のタイトル(string1)を出力します。タイトル行は、リスト・データセットの最初の行に出力されます。
DATE(abcd)
タイトル行に現在の日付を表示します。
-
abc : M(月)、D(日)、Y(年)または4の組み合わせで構成されます。Yは2桁年を、4は4桁年を出力します。
-
d : 区切り文字として使用される任意の文字です。
TIME(abc)
タイトル行に現在の時刻を表示します。
-
ab : 12時間制または24時間制で表示します。
-
c : 区切り文字として使用される任意の文字です。
BLANK
数値フィールドの先行ゼロを空白で表示します。
HEADER('string1')
ONフィールドのタイトルを出力します。HEADERフィールドとONフィールドは、指定された順序に従って1対1で対応されます。
NOHEADER
HEADERを表示しません。
LINES(n)
1ページあたりの行数を表示します。(デフォルト値: 58、nの範囲: 10 ~ 999)
-
-
SELECT
inddで指定された入力データを与えられた条件に従ってフィルタリングしてoutddに格納するか、またはフィルターを通過できなかったデータをsaveddに格納することができます。
以下は、SELECTコマンドの構文です。
SELECT FROM(indd) TO(outdd) | DISCARD(savedd) | {TO(outdd) DISCARD(savedd)} ON(p,m,f)[ ON(p,m,f)...] ALLDUPS | NODUPS | HIGHER(x) | LOWER(x) | EQUAL(x) | FIRST | LAST | FIRSTDUP | LASTDUP [VSAMTYPE(x)] [UZERO] [USING(xxxx)]パラメータ 説明 FROM
入力データセット名を指定します。
TO
フィルタリングされたレコードを格納する出力データセット名を指定します。
DISCARD
フィルタリング後に廃棄されるレコードを格納するデータセット名を指定します。
ON
SELECTコマンドが適用されるフィールドを定義します。pバイトからmバイトまで、f形式で適用します。
ALLDUPS
ONフィールド値が入力データセット内で複数回現れるレコードのみを保存します。
NODUPS
ONフィールド値が入力データセット内で一度だけ現れるレコードのみを保存します。
HIGHER
ONフィールド値が入力データセット内でx回数より多く出現されたレコードのみを保存します。
LOWER
ONフィールド値が入力データセット内でx回数より少なく出現されたレコードのみを保存します。
EQUAL
ONフィールドの値が入力データセット内でx回数出現されたレコードのみを保存します。
FIRST
ONフィールド値が入力データセット内で一度だけ現れるレコードと複数回現れるレコードの最初のレコードのみを保存します。
LAST
ONフィールド値が入力データセット内で一度だけ現れるレコードと複数回現れるレコードの最後のレコードのみを保存します。
FIRSTDUP
ONフィールド値が入力データセット内で複数回現れるレコードの最初のレコードのみを保存します。
LASTDUP
ONフィールド値が入力データセット内で複数回現れるレコードの最後のレコードのみを保存します。
VSAMTYPE
実際には機能せず、エラーの発生を防ぐためにサポートされます。
UZERO
実際には機能せず、エラーの発生を防ぐためにサポートされます。
USING
SELECTコマンドで使用されるSORTのコマンドを指定します。
-
SORT
入力データセットをソートし、1つ以上の出力データセットへ出力します。入力データセットをソートおよび再フォーマットするためにSORTユーティリティを呼び出します。
以下は、SORTコマンドの構文です。
SORT FROM(indd) USING(xxxx) [TO(outdd,[outdd,...])] [VSAMTYPE(x)] [SERIAL]パラメータ 説明 FROM
SORTコマンドを実行する入力データセットを指定します。
USING
SORTコマンドで使用されるSORTのコマンドを指定します。SORTではUSINGが指定される必要があり、xxxxCNTL DDには、SORTコマンドが含まれている必要があります。
TO
SORTの実行結果が保存される出力データセットを指定します。outddにはすべて同じ結果が保存されます。
VSAMTYPE
実際には機能せず、エラーの発生を防ぐためにサポートされます。
SERIAL
実際には機能せず、エラーの発生を防ぐためにサポートされます。
-
SPLICE
一致するオーバーレイ・レコード・フィールドがベース・レコードにオーバーレイされます。この機能を使用すると、異なる形式の複数の入力レコードを複数の情報を持つ1つの出力レコードとして結合することができます。
ONに基づいてマッチング・レコードをチェックします。最初のマッチング・レコードがベース・レコード、それ以外のレコードはオーバーレイ・レコードとして扱われます(このオプションが指定されていない場合は、最後のレコードがオーバーレイ・レコードとなります)。オーバーレイ・レコードにWITHが指定されたフィールドがベース・レコードのフィールドにオーバーレイされます。WITHフィールドを除いたベース・レコードのフィールドはそのまま維持されます。したがって、出力レコードはベース・レコードとオーバーレイ・レコードを組み合わせたものとなります。
SPLICE FROM(indd) TO(outdd) ON(p,m,f)[ ON(p,m,f) ...] WITH(p,m)[ WITH(p,m) ...] [WITHALL] [WITHEACH] [KEEPNODUPS] [KEEPBASE][USING(xxxx)]パラメータ 説明 FROM
入力データセット名を指定します。
TO
結合されたレコードを格納する出力データセット名を指定します。
ON
レコード・マッチングが適用されるフィールドを定義します。
レコード・マッチングは、pバイトからmバイトまでf形式で適用されます。
WITH
オーバーレイ・レコードで指定されたフィールドの位置と長さに従ってベース・レコードをオーバーレイします。
WITHを複数回使用して複数のフィールドをオーバーレイすることができます。
WITHALL
すべてのオーバーレイ・レコードに対して各ベース・レコードをオーバーレイします。
WITHALLを指定しない場合、最後のオーバーレイ・レコードのみベース・レコードにオーバーレイされます。
WITHEACH
n番目のオーバーレイ・レコードを、n番目のWITHのベース・レコードに上書きします。
オーバーレイ・レコードがWITHの数よりも多い場合は、レコードを上書きしません。
KEEPNODUPS
一致しないレコードを削除せずに出力します。
KEEPNODUPSを指定しない場合、一致しないレコードは削除されます。
KEEPBASE
一致するレコードのうち、ベース・データセット(FROMに指定したデータセット)に指定したデータセットのレコードは削除せずに出力します。
KEEPBASEを指定しない場合、ベース・データセットに指定した一致するレコードは削除されます。
USING
SPLICEコマンドで使用されるSORTユーティリティ・コマンドを指定します。
-
DATASORT
inddとして与えられた入力データを1つ以上のヘッダー・レコードと1つ以上のトレーラー・レコードを元の入力レコード順にoutddにコピーします。USING句を介してxxxxCNTLを使用してSORTユーティリティを実行することもできます。
以下は、DATASORTコマンドの構文です。
DATASORT FROM(indd) TO(outdd) USING(xxxx) | [HEADER] | [FIRST] | [HEADER(u)] | [FIRST(u)]| [TRAILER] | [LAST] | [TRAILER(v)] | [LAST(v)] | [VSAMTYPE(x)]パラメータ 説明 FROM
DATASORTコマンドを実行する入力データセットを指定します。
TO
DATASORTコマンドの実行後に保存する出力データセットを指定します。
USING(xxxx)
DATASORTで使用されるSORTユーティリティ・コマンドを指定します。
USINGがある場合は、xxxxCNTL DDを指定する必要があります。
HEADER
HEADER(1)と同じです。
FIRST
HEADER(1)と同じです。
HEADER(u)
データセットの先頭のu個のレコードは、SORTユーティリティを介さずに、出力データセットに直接コピーされます。それ以外のレコードは、SORTユーティリティに渡されます。
FIRST(u)
HEADER(u)と同じです。
TRAILER
TRAILER(1)と同じです。
LAST
TRAILER(1)と同じです。
TRAILER(v)
データセットの末尾のv個のレコードは、SORTユーティリティを介さずに、出力データセットに直接コピーされます。それ以外のレコードは、SORTユーティリティに渡されます。
LAST(v)
TRAILER(v)と同じです。
VSAMTYPEは、実際には機能せず、エラーの発生を防ぐためにサポートされます。
5.3. 使用例
以下は、OFTEST.ICETOOL.IN00をCPY1CNTL DDに指定されたSORTスクリプトを使用してOFTEST. ICETOOL.OUT00.COPYにコピーする例です。
//JOB01 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //ICECOPY EXEC PGM=ICETOOL,REGION=2M //ICEIN DD DSN=OFTEST.ICETOOL.IN00, // DISP=(OLD,KEEP,KEEP),RECFM=FB,LRECL=80 //ICEOUT DD DSN=OFTEST.ICETOOL.OUT00.COPY, // DISP=(NEW,CATLG,DELETE),RECFM=FB,LRECL=80 //TOOLMSG DD SYSOUT=* //DFSMSG DD SYSOUT=* //SYSOUT DD SYSOUT=* //TOOLIN DD * COPY FROM(ICEIN) TO(ICEOUT) USING(CPY1) /* //CPY1CNTL DD * SORT FIELDS=COPY /*
以下は、OFTEST.ICETOOL.IN00をCPY1CNTL DDに指定されたSORTスクリプトを使用して再フォーマットした後、レコード数をOFTEST. ICETOOL.OUT01.COUNTに出力する例です。
レコード数は、「OUTPUT RECORD COUNT =」の後ろに9桁の数値で出力されます。条件を満たすレコードが存在しない場合はRC=4を返し、存在する場合はRC=0を返します。
//JOB02 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//ICECOUNT EXEC PGM=ICETOOL,REGION=2M
//ICEIN DD DSN=OFTEST.ICETOOL.IN00,
// DISP=(OLD,KEEP,KEEP),RECFM=FB,LRECL=80
//CNTDD DD DSN=OFTEST.ICETOOL.OUT01.COUNT,
// DISP=(NEW,CATLG,DELETE),RECFM=FB,LRECL=80
//TOOLMSG DD SYSOUT=*
//DFSMSG DD SYSOUT=*
//SYSOUT DD SYSOUT=*
//TOOLIN DD *
COUNT FROM(ICEIN) USING(CPY1) WRITE(CNTDD) -
TEXT('OUTPUT RECORD COUNT = ') DIGITS(9) -
EMPTY RC4
//CPY1CNTL DD *
SORT FIELDS=COPY
INCLUDE COND=(16,2,CH,EQ,C'08')
/*
以下は、OFTEST.ICETOOL.IN01をCPY1CNTL DDに指定されたSORTスクリプトを使用してOFTEST. ICETOOL.OUT01.ICECPY1とOFTEST.ICETOOL.OUT01.ICECPY2にコピーする例です。
OFTEST.ICETOOL.OUT01.ICECPY2で、レコードの16バイト目から2バイト(16から17バイト)を文字キーにして、データセット全体で重複しない場合はOFTEST.ICETOOL.OUT01.ICETOに格納し、重複する場合はOFTEST.ICETOOL.OUT01.ICESAVEに格納します。
//JOB03 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //ICECOPY EXEC PGM=ICETOOL,REGION=2M //ICEIN DD DSN=OFTEST.ICETOOL.IN01, // DISP=(OLD,KEEP,KEEP),RECFM=FB,LRECL=80 //ICECPY1 DD DSN=OFTEST.ICETOOL.OUT01.ICECPY1, // DISP=(NEW,CATLG,DELETE),RECFM=FB,LRECL=80 //ICECPY2 DD DSN=OFTEST.ICETOOL.OUT01.ICECPY2, // DISP=(NEW,CATLG,DELETE),RECFM=FB,LRECL=80 //ICETO DD DSN=OFTEST.ICETOOL.OUT01.ICETO, // DISP=(NEW,CATLG,DELETE),RECFM=FB,LRECL=80 //ICESAVE DD DSN=OFTEST.ICETOOL.OUT01.ICESAVE, // DISP=(NEW,CATLG,DELETE),RECFM=FB,LRECL=80 //TOOLMSG DD SYSOUT=* //DFSMSG DD SYSOUT=* //SYSOUT DD SYSOUT=* //TOOLIN DD * COPY FROM(ICEIN) TO(ICECPY1,ICECPY2) USING(CPY1) SELECT FROM(ICECPY2) TO(ICETO) DISCARD(ICESAVE) ON(16,2,CH) NODUPS /* //CPY1CNTL DD * SORT FIELDS=COPY /*
以下は、DISPLAYコマンドを実行してOFTEST.ICETOOL.IN01をOFTEST.ICETOOL.OUT01に出力する例です。
//JOB04 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//DISPLAY EXEC PGM=ICETOOL,REGION=2M
//ICEIN DD DSN=OFTEST.ICETOOL.IN01,
// DISP=(OLD,KEEP,KEEP),RECFM=FB,LRECL=80
//ICEOUT DD DSN=OFTEST.ICETOOL.OUT01,
// DISP=(NEW,CATLG,DELETE),RECFM=FB,LRECL=80
//TOOLMSG DD SYSOUT=*
//DFSMSG DD SYSOUT=*
//SYSOUT DD SYSOUT=*
//TOOLIN DD *
DISPLAY LINES(50) FROM(ICEIN) LIST(ICEOUT) -
TITLE('TITLE') DATE(DM4.) TIME PAGE -
HEADER('HEADER1') ON(10,3,CH) -
BLANK -
COUNT('COUNT')
/*
以下の例では、CTL1CNTL DDとCTL2CNTL DDを使用してOFTEST.ICETOOL.IN01とOFTEST.ICETOOL.IN02をそれぞれ再フォーマットした後、OFTEST.ICETOOL.TEMPに格納して再びOFTEST.ICETOOL.OUT01.COMBINEにSPLICEする例です。CTL3CNTL DDにOFTEST.ICETOOL.TEMPで15列が「1」ではないレコードは、OFTEST.ICETOOL.OUT01.FILTEREDに格納されます。
//JOB05 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //SPLICE EXEC PGM=ICETOOL,REGION=2M //IN1 DD DSN=OFTEST.ICETOOL.IN01,DISP=(OLD,KEEP,KEEP) //IN2 DD DSN=OFTEST.ICETOOL.IN02,DISP=(OLD,KEEP,KEEP) //TEMP DD DSN=OFTEST.ICETOOL.TEMP,DISP=(MOD,PASS) //COMBINE DD DSN=OFTEST.ICETOOL.OUT01.COMBINE,DISP=(NEW,CATLG,DELETE) //FILTERED DD DSN=OFTEST.ICETOOL.OUT01.FILTERED,DISP=(NEW,CATLG,DELETE) //TOOLMSG DD SYSOUT=* //DFSMSG DD SYSOUT=* //SYSOUT DD SYSOUT=* //TOOLIN DD * COPY FROM(IN1) TO(TEMP) USING(CTL1) COPY FROM(IN2) TO(TEMP) USING(CTL2) SPLICE FROM(TEMP) TO(COMBINE) ON(5,5,ZD) WITH(15,17) USING(CTL3) /* //CTL1CNTL DD * SORT FIELDS=COPY OUTREC FIELDS=(1,14,31:X) /* //CTL2CNTL DD * SORT FIELDS=COPY OUTREC FIELDS=(5:1,5,15:7,15,30:33,2) /* //CTL3CNTL DD * OUTFIL FNAMES=FILTERED,OMIT=(15,1,CH,EQ,C'1')
以下は、OFTEST.ICETOOL.IN00の先頭から2個のレコードと最後の1つのレコードをOFTEST.ICETOOL.OUT00.DATSにコピーした後、残りのレコードをDATSCNTL DDに指定されたSORTスクリプトを使用してソートし、OFTEST.ICETOOL.OUT00.DATSにコピーする例です。
//JOB01 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //ICECOPY EXEC PGM=ICETOOL,REGION=2M //ICEIN DD DSN=OFTEST.ICETOOL.IN00, // DISP=(OLD,KEEP,KEEP),RECFM=FB,LRECL=80 //ICEOUT DD DSN=OFTEST.ICETOOL.OUT00.DATS, // DISP=(NEW,CATLG,DELETE),RECFM=FB,LRECL=80 //TOOLMSG DD SYSOUT=* //DFSMSG DD SYSOUT=* //SYSOUT DD SYSOUT=* //TOOLIN DD * DATASORT FROM(ICEIN) TO(ICEOUT) HEADER(2) TRAILER USING(DATS) /* //DATSCNTL DD * SORT FIELDS=(1,8,CH,A) /*
6. KDJBR14
JCLに記述された内容が正常に実行されるかを確認するためのテスト・ユーティリティです。
ユーティリティが実際に行う処理はありません。つまり、何の処理も行わない空のプログラムをジョブ・ステップで実行することで、JCLが正しく作成されているか、またジョブ環境でDD文の処理やデータセットの割り当てなどが正常に実行されているかを確認するために使用することができます。また、データセットを新規作成したり削除したりする処理だけを実行するジョブ・ステップでも使用することができます。
7. KEQEFT01
KEQEFT01ユーティリティは、データベースを使用するバッチ・アプリケーションをJCLで実行する際、アプリケーションの実行前にデータベース・システムに接続するためのOpenFrameデータベース接続ユーティリティです。
データベースを使用する業務用のCOBOLアプリケーションのソースにデータベース・システムの接続に必要なシステムの名前、ユーザー名、パスワードなどの情報をコーディングせずに、これらの情報をKEQEFT01ユーティリティの入力スクリプトに指定します。
KEQEFT01ユーティリティで使用するTSSスクリプトのPROGRAMオプションに定義されたプログラムは、共有オブジェクトの形でコンパイルする必要があります。KEQEFT01ユーティリティはOpenFrameのデータベース接続ユーティリティとして、TSSコマンドを使用してバッチ作業を処理できるようにします。
OpenFrameで提供するKEQEFT01ユーティリティは、バッチ・アプリケーション(TSSスクリプトのPROGRAMオプションに定義されたプログラム)を実行するためのデータベース接続機能だけを提供し、DB2システム・コマンドは無視されます。
|
バッチ・アプリケーションをコンパイルする方法については、OpenFrame『マイグレーションガイド』を参照してください。 |
7.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
SYSTSPRT DD |
KEQEFT01ユーティリティの処理結果またはエラーメッセージが出力されます。ただし、SYSTSPRT DDが準備される前に発生するエラーメッセージはSYSOUT DDに出力されます |
SYSTSIN DD |
KEQEFT01ユーティリティの入力スクリプトを指定します |
7.2. コマンドの設定
本節では、KEQEFT01コマンドについて説明します。
-
DSN
TSSコマンドのDSNは、新しいDSN(DB2 Command Processor)セッションを開始します。以下のようなサブコマンドがあります。
コマンド 説明 RUN
ユーザー・アプリケーションを実行します
END
データベースの接続を終了し、TSSに復帰します
現在、KEQEFT01ユーティリティのDSNコマンドでは、以下のサブコマンドについてエラーを防ぐために構文のみサポートしています。
コマンド 説明 ABEND
DSNセッションを終了してABENDコードを返します
BIND
アプリケーションのパッケージまたはプランを作成します
DCLGEN
SQL文と定義テーブルを作成します
FREE
アプリケーションのパッケージまたはプランを削除します
REBIND
既存のパッケージまたはプランを再作成します
SPUFI
SQLファイルの入力でSQLプロセッサを実行します
DSNセッションが接続している間は、データベース・コマンドとコメントを入力できます。データベース・コマンドはハイフン(-)で始まり、コメントはアスタリスク(*)で始まります。
DSNセッションが接続されている間、OpenFrameで使用できるデータベース・コマンドは以下のとおりです。
コマンド 説明 DISPLAY
データベースの状態情報を出力します
START
指定されたデータベースを使用します
STOP
指定されたデータベースを使用しません
メインフレームが提供するデータベース・コマンドの中で頻繁に使用されるいくつかのデータベース・コマンドは、OpenFrameでは実際に機能しませんが、エラーが発生しないようにサポートしています。
以下は、DSNコマンドの構文です。
DSN [SYSTEM(DSN|subsystem-name)] [RETRY(0|integer)]項目 説明 SYSTEM
データベースのサブシステム名を指定します。
指定しない場合は、デフォルト値のSYSTEM(DSN)が使用されます。データベースのサブシステムは、OpenFrame環境設定のikjeft01サブジェクトのSYSTEM:{subsystem-name}セクションのDBTYPE、DBAUTH、DATABASE、INSTANCE、USERNAME、PASSWORDまたはENPASSWDのキー値が設定されている必要があります。
RETRY
データベース・サブシステムの接続のリトライ回数を指定します。
接続の試みは30秒ごとに起こります。指定しない場合は、デフォルト値のRETRY(0)が設定され、最大120回の接続を試みます。
-
RUN
DSNのサブコマンドであるRUNはSQL文を含んだアプリケーションを実行します。
RUNコマンドの構文は以下のとおりです。
RUN PROGRAM(program-name) [PLAN(plan-name)] [LIBRARY(library-name)] [PARMS(parameter-string)] RUN [LIBRARY(library-name)] [PARMS(parameter-string)]項目 説明 PROGRAM
実行するプログラム名を指定します。
PLAN
KEQEFT01ユーティリティでは、同パラメータについてエラーが発生しないようにサポートしています。
LIBRARY
アプリケーションが含まれている区分データセットの名前を指定します。(省略形: LIB)
PARMS
アプリケーションに渡されるパラメータの一覧を指定します。(省略形: PARM)
-
END
DSNのサブコマンドであるENDは、DSNセッションを終了してTSSに復帰します。
ENDコマンドの構文は以下のとおりです。
END
7.3. 使用例
以下はDSNセッションの例です。MYDBシステムへの接続に失敗した場合、30秒ごとに最大5回まで接続を試みます。
DSN SYSTEM (MYDB) RETRY (5)
以下は、DSNシステムにアクセスしてTEST.RUNLIB.LOADライブラリに存在するCOBTEST1プログラムを実行する例です。
DSN SYSTEM (DSN)
RUN PROGRAM (COBTEST1) LIB ('TEST.RUNLIB.LOAD')
以下は、DSNシステムに接続してTEST.RUNLIB.LOADライブラリに存在するCOBTEST2プログラムを実行し、COBTEST2プログラムのパラメータとして’1234567890’を渡す例です。
DSN SYSTEM (DSN)
RUN PROGRAM (COBTEST2) PLAN (COBTEST2) -
LIB ('TEST.RUNLIB.LOAD') PARMS ('1234567890')
7.4. 関連環境設定
サブジェクトにデータベースのシステム名とデータベースの接続に必要な情報は、OpenFrame環境設定のikjeft01サブジェクトに記述します。詳細については、OpenFrame Batch『環境設定ガイド』を参照してください。
7.5. 注意事項
KEQEFT01ユーティリティは、SYSTSIN DDにTSSスクリプトを指定する必要があります。このとき、TSSスクリプトのPROGRAMオプションに定義されたプログラムは共有オブジェクト形式である必要があります。現在、KEQEFT01ユーティリティはシェル・スクリプトや実行可能なオブジェクトはサポートしていません。
DSNコマンドとDSNのサブコマンドを使用する際には、以下のような解析ルールが適用されます。
-
1つのコマンドを次の行に続けて記述する場合は、現在のラインの最後にハイフン(-)を記述します。
以下は、複数の行にわたって作成したDSNのサブコマンドの例です。
RUN PROGRAM(TECA251) - PLAN(TECA251) - LIB('MI.PROG.CLINK') - PARM('2')
以下は、KEQEFT01ユーティリティによるバッチ・アプリケーション(TSSスクリプトのPROGRAMオプションに定義されたプログラム)の実行結果についての説明です。
-
正常に実行した場合
アプリケーションから受信したコードを返します。
-
エラーが発生した場合
エラーメッセージをSYSTSPRT DDに出力し、該当するエラーコードを返します。ただし、SYSTSPRT DDが準備される前に発生したエラーメッセージはSYSOUT DDに出力します。
以下は、KEQEFT01ユーティリティで発生する可能性のあるエラーコードです。
コード 説明 12
回復不能エラーであり、以下のような場合に該当します。
-
データセット認証の準備プロセスで失敗した場合
-
SYSTSIN DDが提供されていない場合
-
SYSTSPRT DDが提供されていない場合
-
SYSTSIN DDのファイルが見つからなかった場合
-
サポートしていないSYSTSIN DDのバイナリ形式である場合
-
SYSTSIN DDスクリプトの解析エラーが発生した場合
-
不適切なTSSコマンドが使用された場合
-
RUNコマンドにプログラムが記述されていない場合
-
RUNコマンドに記述されたプログラムが見つからなかった場合
-
実行させるアプリケーションが見つからなかった場合
-
サポートしないアプリケーションのバイナリ形式である場合
-
データベースの接続に失敗した場合
-
動的メモリのロード(dlopen)に失敗した場合
-
エントリー・ポイントの検索(dlsym)に失敗した場合
16
システム関連のエラー(System Fault)であり、以下のような場合に該当します。
-
OpenFrameシステム・ライブラリの初期化に失敗した場合
-
SYSTSPRT DDを開くことができなかった場合
-
SYSTSIN DDのバイナリ形式のチェックでエラーが発生した場合
-
SYSTSIN DDを開くことができなかった場合
-
一時ファイルを作成できなかった場合
-
SYSTSIN DDで読み込みエラーが発生した場合
-
アプリケーションのバイナリ形式のチェックでエラーが発生した場合
-
データベース・システム設定の読み込みエラー
-
プロセス分岐(fork)に失敗した場合
-
入出力リダイレクトに失敗した場合
-