데이터 셋 유틸리티
본 장에서는 데이터 셋 유틸리티에 대해 기술한다.
1. 개요
다음은 데이터 셋 유틸리티 목록이다. 각 유틸리티에 대한 설명은 해당 절에서 자세하게 기술한다.
| 프로그램명 | 설명 |
|---|---|
IBM Mainframe MVS 환경에서 제공하는 DFSMSdss의 기능들을 JCL에서 호출하려는 경우 사용하는 유틸리티 프로그램이다. |
|
SMF 데이터 셋에 존재하는 CICS 로그 데이터를 조회 및 처리하는 유틸리티 프로그램이다. |
|
VSAM과 Non-VSAM 데이터 셋 및 카탈로그 정보를 생성하고 관리하는 유틸리티 프로그램이다. |
|
2개의 SDS나 PDS를 비교조건을 통해 비교 후 그 결과를 출력하는 유틸리티 프로그램이다. |
|
1개 이상의 PDS에 대해서 멤버들을 전체 또는 일부만 복사하거나 병합하는 유틸리티 프로그램이다. |
|
테스트 데이터 셋을 생성하는 유틸리티 프로그램이다. |
|
JOB 스트림 데이터 셋을 작성하거나 편집하는 유틸리티 프로그램이다. |
|
순차 데이터 셋 또는 PDS의 멤버를 복사하는 유틸리티 프로그램이다. |
|
순차 데이터 셋이나 PDS의 전체 또는 일부를 실제 출력할 형식으로 데이터를 생성하는 유틸리티 프로그램이다. |
|
리소스(애플리케이션 소스, JCL 소스 등)를 신규 생성, 갱신, 복사하는 유틸리티 프로그램이다. |
|
PDS의 데이터 셋 정보와 멤버 리스트 또는 볼륨 정보와 볼륨에 포함된 데이터 셋 리스트를 제공하는 유틸리티 프로그램이다. |
|
2개의 SDS나 PDS를 비교조건을 통해 비교 후 그 결과를 출력하는 유틸리티 프로그램이다. |
|
SMF 데이터 셋을 일반 데이터 셋으로 DUMP하거나 내용을 초기화하는 유틸리티 프로그램이다. |
2. ADRDSSU
ADRDSSUは、IBMメインフレームのMVS環境で提供されるDFSMSdssの機能をJCLで呼び出す場合に使用されるユーティリティ・プログラムです。
OpenFrameでは、ADRDSSUによって提供されるCOPY、DUMP、RESTORE、CONVERT、DEFRAGなどのコマンドのうち、最も頻繁に使用されるDUMP、RESTORE、COPYのみサポートしています。DUMPとRESTOREは、災害やシステム障害が発生した場合、重要なデータを保護するためにデータセットやボリュームをバックアップおよびリカバリするために使用されます。またCOPYは、データセットを他の名前でコピーする場合に使用されます。
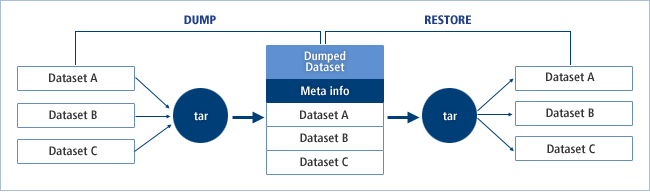
DUMPコマンドは、JCLの制御文に記述されたデータセットまたはボリュームを1つのデータセットにまとめて指定のボリューム・ディレクトリに格納します。RESTOREコマンドは、ダンプされたデータセットを元の状態に戻して指定のボリューム・ディレクトリに復元します。この際、内部的にはUNIXが提供するtarプログラムが使用されます。
OpenFrameでは、DUMPコマンドの処理時にダンプされるデータセットのカタログ情報をメタ情報ファイルとして構成し、ダンプ対象のデータセットと一緒に保存します。RESTOREコマンドを処理する際にそのメタ情報ファイルを読み込んでダンプされたときのカタログ状態に復元します。
COPYコマンドは、ターゲット・データセットを指定された他のデータセット名に変更してコピーするために使用されます。OpenFrameのADRDSSUは、現在のVSAMに対してのみサポートされます。
|
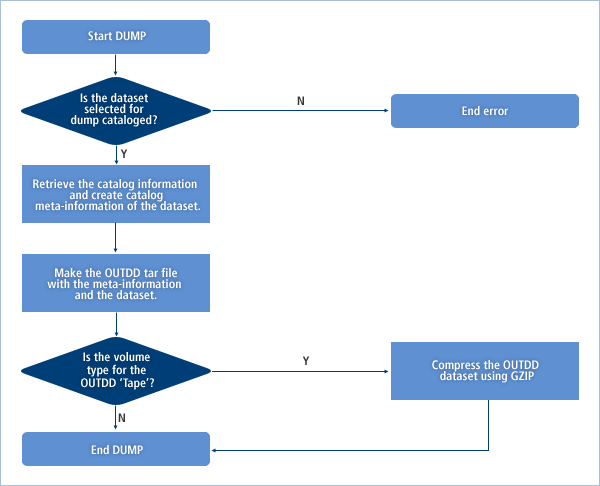
以下の図は、DUMPの処理プロセスです。
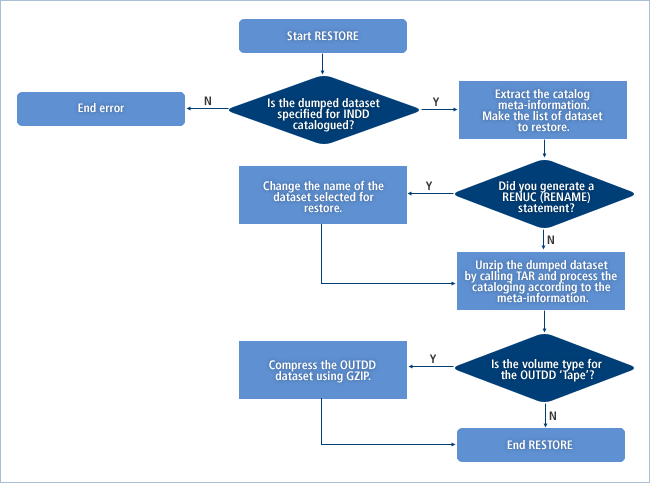
以下の図は、RESTOREの処理プロセスです。
2.1. DDの設定
以下は、COPY、DUMPとRESTOREのDD設定項目です。
-
COPY
項目 説明 SYSIN DD
COPYコマンドとオプションを指定します。
-
DUMP
項目 説明 SYSIN DD
DUMPコマンドとオプションを指定します。
INDDのためのDD
SYSIN DDに指定した制御文のINDD文で指定したDD名と同じで、ダンプされるデータセットのボリューム情報が記述されています。ダンプされるデータセットがカタログに登録されており、制御文でINDD文を記述しなかった場合は省略できます。
OUTDDのためのDD
SYSIN DDに記述した制御文のOUTDD文で指定したDD名と同じで、新規作成するダンプ・データセットの情報が記述されています。該当のDDにDUMMY文を記述した場合はダンプされません。OUTDDのRECFMは一般的に「U」に設定します。
以下は、データセット・レコード・フォーマット(RECFM)です。
-
F(Fixed) : 固定長レコード
-
FB(Fixed Blocked) : ブロック化された固定長レコード
-
V(Variable) : 可変長レコード。4バイトの可変長情報を含みます。
-
VB(Variable Blocked) : ブロック化された可変長レコード
-
U(Undefined) : 不定長レコード
-
-
RESTORE
項目 説明 SYSIN DD
RESTOREコマンドとオプションを指定します。
INDDのためのDD
SYSIN DDに記述した制御文のINDD文で指定したDD名と同じで、復元されるダンプ・データセットが記述されています。
OUTDDのためのDD
SYSIN DDに記述した制御文のOUTDD文で指定したDD名と同じで、復元されたデータセットが格納されるボリュームを指定します。OUTDDのためのDDは複数記述することが可能であり、該当のDDではDSN(Data Set Name)を記述しません。
2.2. コマンドの設定
本節では、ADRDSSUユーティリティで設定できるコマンドについて説明します。
以下は、ADRDSSUが提供するコマンド・オプションの省略形の一覧です。
| コマンド | オプション(省略形) |
|---|---|
COPY |
DATASET (DS) |
RENAMEU (RENUNC) |
|
SHARE (SHA, SHR) |
|
TOLERATE (TOL) |
|
DUMP |
ALLDATA (ALLD) |
ALLEXCP (ALLE) |
|
ALLMULTI (ALLM) |
|
DATASET (DS) |
|
DELETE (DEL) |
|
ENQFAILURE (ENQ) |
|
INCLUDE (INC) |
|
INDDNAME (INDD, IDD) |
|
INDYNAM (INDY, IDY) |
|
LOGINDDNAME (LOGINDD, LIDD) |
|
LOGINDYNAM (LOGINDY, LIDY) |
|
OUTDDNAME (OUTDD, ODD) |
|
PURGE (PUR, PRG) |
|
SHARE (SHA, SHR) |
|
TOLERATE (TOL) |
|
COMPRESS (COM) |
|
OPTIMIZE (OPT) |
|
RESTORE |
DATASET (DS) |
ENQFAILURE (ENQ) |
|
INDDNAME (INDD, IDD) |
|
OUTDDNAME (OUTDD, ODD) |
|
RENAME (REN) |
|
RENAMEU (RENUNC) |
|
REPLACE (REP) |
|
SHARE (SHA, SHR) |
|
TOLERATE (TOL) |
COPY
指定したデータセットを他のデータセット名に変更してコピーします。COPYコマンドは、現在のVSAMデータセットに対してのみ使用できます。
以下は、COPYコマンドの構文です。
COPY DATASET(INCLUDE(DSNAME,…)
[RENAMEU((OLD DATASET NAME,NEW DATASET NAME),…)]
[SHARE]
[SPHERE]
[TOL(ENQF)]
[WAIT(時間間隔, 試行回数)]
| パラメータ | 説明 |
|---|---|
DATASET |
コピー・ターゲット・データセットを指定します。 |
INCLUDE |
ダンプ処理されたデータセットから1つ以上のコピー・ターゲット・データセット名を指定します。ワイルドカード文字を使用してコピーするターゲット・データセットをフィルタリングします。詳細については、[ワイルドカード文字を使用したフィルタリング]を参照してください。 |
RENAMEU |
INCLUDE文で指定したデータセット名を新しいデータセット名に変更して復元します。そのとき、変更前の名前を持つデータセットがすでに存在する場合にのみ新しい名前に変更して復元し、存在しない場合は変更前の名前で復元します。 VSAMデータセットには使用できません。 |
SHARE |
コピー・ターゲット・データセットにアクセスする際、共有ロックを実行します。指定しない場合は、デフォルト値の排他ロックが実行されます。 |
SPHERE |
ターゲット・データセットとカタログ上で関連付けられているデータセットもコピーします。 |
TOL |
REPLACE文を指定した場合、すでに存在するコピー・ターゲット・データセットに対して共有ロックまたは排他ロックに失敗した場合でも処理を続行します。データ整合性を保つためにお勧めしません。 |
WAIT |
COPY文を指定した場合、すでに存在するコピー・ターゲット・データセットにロックを実行するための時間間隔(秒)と試行回数を指定します。 WAIT(2,99)と指定すると、2秒間隔で最大99回までロックを試みます。指定しない場合は、デフォルト値のWAIT(2,2)が使用されます。また、WAIT(0,0)と指定した場合は、待機せずに処理します。 |
DUMP
1つ以上のデータセットまたはボリュームを1つのデータセットとしてダンプします。
以下は、DUMPコマンドの構文です。
DUMP DATASET(INCLUDE(DSNAME,…)
[EXCLUDE(DSNAME,…)]
[BY(CREDT|EXPDT|REFDT,演算子,*,[-]日数)])
OUTDD(OUTDD NAME)
[INDD(INDD NAME,…)] [INDY((VOLSER,UNIT),…)]
[LIDD(LIDD NAME,…)] [LOGINDY((VOLSER,UNIT),…)]
[ALLE] [ALLD(*)] [ALLM]
[DELETE] [PURGE]
[SHARE] [TOL(ENQF)] [WAIT(時間間隔, 試行回数)]
[COMPRESS]
| パラメータ | 説明 |
|---|---|
DATASET |
ダンプされるデータセットを指定します。 INDD文でダンプされるボリュームのDD名を指定し、ボリューム単位で処理する場合はDATASET文を省略できます。INDD文でダンプされるボリュームのDD名とデータセット名を一緒に記述した場合は、データセットがカタログに登録されていなくてもダンプすることがきます。ただし、INDD文を指定せずにデータセット名のみ記述した場合は、そのデータセットが事前にカタログに登録されている必要があります。 |
INCLUDE |
1つ以上のダンプされるデータセット名を指定します。ダンプの対象となるデータセットが複数ある場合は、各データセットをコンマ(,)、空白、改行文字で区切ります。 ワイルドカード文字を使用してダンプ対象のデータセット名でフィルタリングすることができます。詳細については、[ワイルドカード文字を使用したフィルタリング]を参照してください。 |
EXCLUDE |
ダンプの対象から除外するデータセット名を1つ以上指定します。除外されるデータセットが複数ある場合は、各データセットをコンマ(,)、空白、改行文字で区切ります。 ワイルドカード文字を使用してダンプの対象から除外されるデータセット名を利用してフィルタリングすることができます。詳細については、[ワイルドカード文字を使用したフィルタリング]を参照してください。 |
BY |
INCLUDE文で指定したデータセットのうち、BY文で記述した条件と一致するデータセットのみフィルタリングして処理します。
以下は、現在の日付から3日前に作成されたデータセットをフィルタリングする例です。 (CREDT,LE,*,-3) または (REFDT,LE,*,-3) |
OUTDD |
新規作成するダンプ・データセットのDD名を指定します。 |
INDD |
ダンプされるボリュームのDD名を複数指定することができます。ダンプ対象のデータセットを指定せずにINDDのみ記述した場合は、該当のボリュームに属するすべての非VSAMデータセットをダンプします。 |
INDY |
ダンプされるボリュームを動的に指定します。ダンプされるボリュームのVOLSERとUNIT名を複数指定することができます。 |
LIDD |
メインフレームでは、論理ダンプ処理の場合、LIDD文でダンプされるDD名を指定します。ただし、OpenFrameでは不要な概念であるため、INDD文と同様に処理されます。 |
LOGINDY |
メインフレームでは、論理ダンプ処理の場合、LOGINDY文でダンプされるボリュームのVOLSERとUNIT名を指定します。ただし、OpenFrameでは不要な概念であるため、INDY文と同様に処理されます。 |
ALLE |
OpenFrameでは不要なため、指定しても無視されます。 |
ALLD |
OpenFrameでは不要なため、指定しても無視されます。 |
ALLM |
OpenFrameでは不要なため、指定しても無視されます。 |
DELETE |
正常にダンプされたデータセットを削除します。 |
PURGE |
DELETE文の記述後に指定します。OpenFrameでは無視されます。 |
SHARE |
ダンプされるデータセットにアクセスするときに共有ロックを実行します。指定しない場合は、デフォルト値として排他的ロックが設定されます。 |
TOL |
ダンプされるデータセットへの共有ロックまたは排他的ロックの設定に失敗した場合も、処理を続行します。データの整合性を維持できない可能性があるため、お勧めできません。 |
WAIT |
ダンプされるデータセットにロックを実行するための時間間隔(秒)と試行回数を指定します。WAIT(2,99)を指定すると、2秒ごとに最大99回まで試行されます。 指定しない場合のデフォルト値はWAIT(2,2)です。WAIT(0,0)に指定した場合は待機せずに、直ちに処理されます。 |
COMPRESS |
OpenFrameでは不要なため、指定しても無視されます。 |
[比較演算子]
以下は、DUMPコマンドのBY項目で使用される比較演算子です。
| 演算子 | 符号 | 意味 |
|---|---|---|
EQ |
= |
等しい |
LE |
<= |
小さいか等しい |
LT |
< |
小さい |
GT |
> |
大きい |
GE |
>= |
大きいか等しい |
NE |
!= |
等しくない |
[ワイルドカード文字を使用したフィルタリング]
ワイルドカード文字を使用してDUMPまたはRESTOREを実行するデータセット名をフィルタリングすることができます。
| フィルタキー | 説明 |
|---|---|
* (single asterisk) |
基本的には1つの修飾子とマッチします。また、1つの修飾子内の0個以上の文字とマッチできます。 |
** (double asterisk) |
0個以上の修飾子とマッチします。 |
% (percent) |
修飾子内の1つの文字とマッチします。 |
修飾子は、ピリオド(.)で区切られデータセット名を構成します。たとえば、データセット名がSYS.LIBの場合、SYS1とLIBという2つの修飾子を持つことになります。
以下は、ワイルドカード文字を使用したフィルタリングの例です。
| データセット名 | フィルタリング対象のデータセット | フィルタリング対象外のデータセット |
|---|---|---|
SYS1.*.LIST |
SYS1.TEST.LIST, SYS1.LIB.LIST |
SYS.TEST.LIST.TEMP, SYS1.LIST |
SYS1.LIB.*.* |
SYS1.LIB.LIST.TEMP, SYS1.LIB.A.B |
SYS1.LIB.LIST, SYS1.LIB.A.B.C |
SYS.*IB.LIST |
SYS.LIB.LIST, SYS1.IB.LIST |
SYS.LIBA.LIST, SYS.LIB.LIST.TEMP |
**.LIST |
SYS1.LIST, SYS1.LIB.LIST, SYS1.A.B.C.LIST |
SYS1.LIST.TEMP, SYS1.LIB.LISTA |
USER.LIB.** |
USER.LIB.LIST.TEMP, USER.LIB |
USER.LIBTEST.LIST, USER.LIBLIST |
SYS1.**.LIST |
SYS1.A.B.C.LIST, SYS1.LIST |
SYS1.LIST.ERR, SYS1.TEST.LIST.ERR |
**.*LIST |
SYS1.TEST.LIST, SYS1.TEST.A.B.OKLIST |
SYS1.LIST.ERR, SYS1.TEST.OKLIST.TEMP |
*.*.L*B |
SYS1.TEST.LIB, USER.LIB.LISTB, A.B.LB |
SYS1.TEST.LIBTEMP, SYS1.USER.LIB.TEMP |
%.LIST |
A.LIST, B.LIST |
AA.LIST, BB.LIST, LIST |
USER%.* |
USER1.LIST, USERA.LIST |
USEROK.LIST, USER1.OK.LIST, USER.LIST |
*%%* |
AA, BB, TEST, USER |
A, B, TEST.USER |
|
[ワイルドカード文字を使用したGDGのフィルタリング]
INCLUDE文でダンプされるデータセットがGDSの場合、ワイルドカード文字を使用してフィルタリングすることができます。
| フィルター・キー | 説明 |
|---|---|
GDGdsn(0) |
現在の相対世代番号の世代データセット(GDS: Generation Data Set)とマッチします。 |
GDGdsn(*) |
世代データ・グループ(GDG: Generation Data Group)で管理しているすべての世代データセット(GDS: Generation Data Set)とマッチします。 |
RESTORE
1つのファイルとしてダンプされたデータセットを元のデータセットとしてリストアします。
以下は、RESTOREコマンドの構文です。
RESTORE DATASET(INCLUDE(DSNAME,…)
[EXCLUDE(DSNAME,…)])
INDD(INDD NAME)
OUTDD(OUTDD NAME,…)
[RENAME((OLD DATASET NAME,NEW DATASET NAME),…)]
[RENUNC((OLD DATASET NAME,NEW DATASET NAME),…)]
[CATALOG]
[REPLACE]
[SHARE] [TOL(ENQF)] [WAIT(時間間隔, 試行回数)]
| パラメータ | 説明 |
|---|---|
DATASET |
リストアするデータセットを指定します。 |
INCLUDE |
ダンプされたデータセットからリストアするデータセット名を複数指定します。ワイルドカード文字を使用して、リストアするデータセットをフィルタリングします。詳細については、[ワイルドカード文字を使用したフィルタリング]を参照してください。 |
EXCLUDE |
ダンプされたデータセットから、リストアしないデータセット名を複数指定します。ワイルドカード文字を使用して、リストア対象から除外するデータセットをフィルタリングします。詳細については、[ワイルドカード文字を使用したフィルタリング]を参照してください。 |
INDD |
ダンプ・データセットを指定したDD名を指定します。 |
OUTDD |
リストアされたデータセットを格納する出力ボリュームのDD名を指定します。 |
RENAME |
INCLUDE文で指定したデータセット名を新しいデータセット名に変更して復元します。変更前の名前を持つデータセットが存在する場合は新しい名前に変更して復元し、そうでない場合は、変更前の名前で復元します。 |
RENUNC |
INCLUDE文で指定したデータセット名を新しいデータセット名に変更して復元します。変更前の名前を持つデータセットが存在するかどうかに関係なく、新しい名前で復元します。 |
CATALOG |
メインフレームでは、論理リストアの場合に指定されます。ただし、OpenFrameでは、ダンプ処理時のカタログ情報で登録されるため、無視されます。 |
REPLACE |
リストアされるデータセットがすでに存在する場合は、そのデータセットを置き換えます。 すでに存在しているデータセットへの検索順は以下のとおりです。
|
SHARE |
REPLACE文が指定された場合、すでに存在しているリストア対象のデータセットにアクセスする際、共有ロックを実行させます。指定しない場合は、デフォルトの排他的ロックが実行されます。 |
TOL |
REPLACE文が指定された場合、すでに存在するリストア対象のデータセットへの共有ロックまたは排他的ロックの設定に失敗した場合も、処理を続行します。データの整合性を維持できない可能性があるため、お勧めできません。 |
WAIT |
REPLACE文が指定された場合、すでに存在するリストア対象のデータセットにロックを実行するための時間間隔(秒)と試行回数を指定します。 WAIT(2,99)を指定すると、2秒ごとに最大99回まで試行されます。指定しない場合のデフォルト値はWAIT(2,2)です。WAIT(0,0)に指定した場合は待機せずに、直ちに処理されます。 |
IF-THEN-ELSE
IF-THEN-ELSE文は、ADRDSSUユーティリティのコマンドを処理した後、返される戻りコードを比較して論理的に後処理します。また、ネストされたIF文を記述することが可能であり、現在は、条件付き分岐の後はWTOコマンドのみサポートされます。
以下は、IF-THEN-ELSEコマンドの構文です。
IF {Condition Code} {operator} {number}
THEN [command|DO command set END]
[ELSE [command|DO command set END]]
IF条件では、次の変数名と比較できます。
| 変数名 | 説明 |
|---|---|
LASTCC |
コマンドの処理中に返された最終戻りコードです。 |
MAXCC |
コマンドの処理中に発生した最も大きい値を持つ戻りコードです。 |
条件比較で使用されるオペレーターについては、[比較演算子]を参照してください。
以下は、IF-THEN-ELSEコマンドを記述した制御文の使用例です。
DUMP INDD(IN) OUTDD(OUT) DELETE –
DATASET(INCLUDE(TEST.DATASET.**) BY (CREDT,LT,*,1) ) –
IF MAXCC > 4 –
THEN DO –
WTO ‘* DATA SETS DELETE FAILURE *’-
END
上記例では、MAXCCが4より大きい場合、WTOコマンドを使用してシステム・コンソールにメッセージを送信します。
WTO
WTOコマンドは、システム管理者のシステム・コンソールにメッセージを送信します。送信されたメッセージを確認するには、ADRDSSUユーティリティを実行する前にtconmgrを起動する必要があります。tconmgrについては、『OpenFrame Batchガイド』を参照してください。
以下は、WTOコマンドの構文です。
WTO ‘message’
| 項目 | 説明 |
|---|---|
message |
システム・コンソールに送信するメッセージを指定します。 |
2.3. 使用例
以下は、複数のデータセットを1つのデータセットとしてダンプする例です。ADRDSSU.TEST01、ADRDSSU.TEST02、ADRDSSU.TEST03データセットをOUTDDで記述したADRDSSU.DUMPED.DSデータセットとしてダンプします。
//*********************************************************************
//*** ADRDSSU LOGICAL DUMP ***
//*********************************************************************
//ADRDUM01 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JS010 EXEC PGM=ADRDSSU
//OUTDD DD DSN=ADRDSSU.DUMPED.DS,UNIT=3380,DISP=(NEW,CATLG,DELETE)
//SYSIN DD *
DUMP DATASET(INCLUDE(ADRDSSU.TEST01, -
ADRDSSU.TEST02, -
ADRDSSU.TEST03)) -
OUTDD(OUTDD)
/*
//SYSPRINT DD SYSOUT=*
*
以下は、複数の非VSAMデータセットを1つのデータセットとしてダンプした後、ダンプされたすべてのデータセットを削除する例です。
ADRDSSU.TEST01、ADRDSSU.TEST02、ADRDSSU.TEST03データセットをOUTDDで記述したデータセットのADRDSSU.DUMPED.DSとしてダンプした後、そのすべてのデータセットを削除します。
//*********************************************************************
//*** ADRDSSU LOGICAL DUMP AND DELETE ***
//*********************************************************************
//ADRDUM01 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JS010 EXEC PGM=ADRDSSU
//OUTDD DD DSN=ADRDSSU.DUMPED.DS,UNIT=3380,DISP=(NEW,CATLG,DELETE)
//SYSIN DD *
DUMP DATASET(INCLUDE(ADRDSSU.TEST01, -
ADRDSSU.TEST02, -
ADRDSSU.TEST03)) -
OUTDD(OUTDD) -
ALLE ALLD(*) -
DEL PURGE –
TOL(ENQF) -
WAIT(2,99) -
SHARE
/*
//SYSPRINT DD SYSOUT=*
以下は、INCLUDE文でワイルドカード文字を記述し、該当の条件に一致する名前を持つデータセットのみまとめてダンプする例です。
最初の修飾子が「ADRTEST」であるデータセットのみダンプします。
//********************************************************************* //*** ADRDSSU LOGICAL DUMP WITH DATA SET NAME FILTERRING *** //********************************************************************* //ADRDUM01 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //JS010 EXEC PGM=ADRDSSU //OUTDD DD DSN=ADRDSSU.DUMPED.DS,UNIT=3380,DISP=(NEW,CATLG,DELETE) //SYSIN DD * DUMP DATASET( INCLUDE(ADRTEST.**) ) - OUTDD(OUTDD) /* //SYSPRINT DD SYSOUT=*
以下は、INCLUDE文でワイルドカード文字を記述し、条件に一致する名前を持つデータセットのうち、BY条件を満たすデータセットのみをダンプする例です。
最初の修飾子が「ADRTEST」で、2番目の修飾子が「TEST」で始まるデータセットのうち、作成日が現在の日付より前のデータセットのみをダンプします。
//********************************************************************* //*** ADRDSSU LOGICAL DUMP WITH ‘BY’ FILTERING *** //********************************************************************* //ADRDUM01 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //JS010 EXEC PGM=ADRDSSU //OUTDD DD DSN=ADRDSSU.DUMPED.DS,UNIT=3380,DISP=(NEW,CATLG,DELETE) //SYSIN DD * DUMP DATASET( INCLUDE(ADRTEST.TEST*) BY (CREDT,GT,*,-1) ) - OUTDD(OUTDD) //SYSPRINT DD SYSOUT=*
以下は、INDD文で指定したボリュームに属しているすべての非VSAMデータセットをダンプする例です。
INDDで指定したボリューム・シリアル「200000」に属しているすべての非VSAMデータセットをまとめてダンプします。
//********************************************************************* //*** ADRDSSU PHYSICAL DUMP *** //********************************************************************* //ADRDUM01 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //JS010 EXEC PGM=ADRDSSU //INDD1 DD UNIT=SYSDA,DISP=SHR,VOL=SER=200000 //OUTDD DD DSN=ADRDSSU.DUMPED.DS,UNIT=3380,DISP=(NEW,CATLG,DELETE) //SYSIN DD * DUMP INDD(INDD1) OUTDD(OUTDD) //SYSPRINT DD SYSOUT=*
以下は、ダンプされたデータセットを非VSAMデータセットに復元する例です。
ダンプ・データセットから、ADRDSSU.TEST01、ADRDSSU.TEST02、ADRDSSU.TEST03データセットを復元します。
//*********************************************************************
//*** ADRDSSU LOGICAL RESOTRE ***
//*********************************************************************
//ADRRES1 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JS010 EXEC PGM=ADRDSSU
//INDD DD DSN=ADRDSSU.DUMPED.DS,DISP=OLD
//DASD1 DD VOL=SER=100000,UNIT=3380,DISP=OLD
//SYSIN DD *
RESTORE DATASET(INCLUDE(ADRDSSU.TEST01, -
ADRDSSU.TEST02, -
ADRDSSU.TEST03)) -
CATALOG -
INDD(INDD) -
OUTDD(DASD1)
/*
//SYSPRINT DD SYSOUT=*
以下は、ダンプされたデータセットを新しい名前のデータセットに復元する例です。
ダンプ・データセットから、ADRDSSU.TEST01、ADRDSSU.TEST02、ADRDSSU.TEST03データセットをADRDSSU.TEST01.NEW、ADRDSSU.TEST02.NEW、ADRDSSU.TEST03.NEWの新しい名前で復元します。
//*********************************************************************
//*** ADRDSSU LOGICAL RESOTRE AND RENAME ***
//*********************************************************************
//ADRRES1 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JS010 EXEC PGM=ADRDSSU
//INDD DD DSN=ADRDSSU.DUMPED.DS,DISP=OLD
//DASD1 DD VOL=SER=100000,UNIT=3380,DISP=OLD
//SYSIN DD *
RESTORE DATASET(INCLUDE(ADRDSSU.TEST01, -
ADRDSSU.TEST02, -
ADRDSSU.TEST03)) -
RENUNC((ADRDSSU.TEST01,ADRDSSU.TEST01.NEW ), -
(ADRDSSU.TEST02,ADRDSSU.TEST02.NEW ), -
(ADRDSSU.TEST03,ADRDSSU.TEST03.NEW )) -
CATALOG -
INDD(INDD) -
OUTDD(DASD1)
/*
//SYSPRINT DD SYSOUT=*
以下は、ダンプされたデータセットをすべて復元する例です。
ADRDSSU.DUMPED.DSデータセットにあるすべてのダンプされたデータセットをそれぞれの名前で復元します。
//*********************************************************************
//*** ADRDSSU PHYSICAL RESOTRE ***
//*********************************************************************
//ADRRES1 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JS010 EXEC PGM=ADRDSSU
//INDD DD DSN=ADRDSSU.DUMPED.DS,DISP=OLD
//DASD1 DD VOL=SER=100000,UNIT=3380,DISP=OLD
//SYSIN DD *
RESTORE INDDNAME(INDD) OUTDDNAME(DASD1) -
DATASET(INCLUDE(**))
/*
//SYSPRINT DD SYSOUT=*
以下は、データセットをコピーする例です。ADRDSSU.TEST01をADRDSSU.TEST01.NEWとしてコピーします。
//*********************************************************************
//*** ADRDSSU PHYSICAL COPY ***
//*********************************************************************
//ADRRES1 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JS010 EXEC PGM=ADRDSSU
//SYSIN DD *
COPY DATASET(INCLUDE(ADRDSSU.TEST01)) -
WAIT(0,0) SPHERE -
RENAMEU(ADRDSSU.TEST01.NEW)
/*
//SYSPRINT DD SYSOUT=*
2.4. 環境設定
VSAMのダンプ機能は、Tiberoが提供するユーティリティを使用して実装されています。Tiberoユーティリティを使用するための情報は、OpenFrame環境設定のadrdssuサブジェクトのDUMP_VSAMセクションに設定し、コマンドの実行時に参照します。
|
adrdssuサブジェクトの設定方法については、『OpenFrame 環境設定ガイド』を参照してください。 |
2.5. 戻りコード
OpenFrameでVSAMデータセットを処理するには、TSAM RDBを使用する必要があります。ofconfigツールを使用して、OpenFrame環境設定のrcサブジェクトで戻りコード12以上はエラーとして処理されるように指定します。
以下は、ADRDSSUユーティリティの戻りコードです。
-
正常に実行された場合
バッチ・アプリケーションからの戻りコードを返します。
-
エラーが発生した場合
SYSPRINT DDにエラーメッセージを出力し、該当するエラーコードを返します。
コード 説明 8
プログラムの実行中に特定のデータセットでエラーが発生したが、他のデータセットは正常に処理された場合です。
12
回復不能エラーです。エラーが発生したため、正常に実行されなかった場合です。
|
3. DFHJUP
DFHJUPは、SMFデータセットに存在するCICSログ・データを検索および処理するユーティリティ・プログラムです。DFHJUPユーティリティを使用して、SMFデータセット内のCICSログ・レコードをさまざまな条件で選択して出力したり、他のデータセットにコピーしたりすることができます。
|
類似したユーティリティ・プログラムには、IFASMFDPがあります。 |
3.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
SYSPRINT DD |
DFHJUPで選択されたレコードのうち、SYSPRINTで出力する場合の出力データセットです。 |
SYSIN DD |
DFHJUPのコマンドを指定します。 |
SYSUT1 DD |
DFHJUPのデフォルト入力データセットを指定します。CONTROL文を使用して他のDDに変更できます。 |
SYSUT4 DD |
DFHJUPのデフォルト出力データセットを指定します。CONTROL文を使用して他のDDに変更できます。 |
|
3.2. コマンドの設定
DFHJUPユーティリティで設定可能なコマンドについて説明します。
CONTROL
入出力データセットが指定されたDDを指定するか、入力データセットの処理範囲をレコード数単位で指定します。
以下は、CONTROLコマンドの構文です。
CONTROL CNTL [{SKIP|K}={[underline]#0#|number}]
[,{STOPAFT|H}={[underline]#EOF#|number|(number,E)}]
[,{DDNAME|D}={[underline]#SYSUT1#|ddname}]
[,{DDNOUT|O}={[underline]#SYSUT4#|ddname}]
| パラメータ | 説明 |
|---|---|
SKIP|K |
入力データセットの最初のレコードからスキップするレコード数をnumberに指定します。(デフォルト値: 0) |
STOPAFT|H |
入力データセットから読み込んでテストする最大のレコード数をnumberに指定します。 (number,E)は、条件式を満たすレコード数が指定の数に達するまで処理されることを示します。(デフォルト値: EOF、レコード数に関係なく、入力ファイルの最後まで処理されます) |
DDNAME|D |
入力データセットを指定したDD名をddnameに記述します。(デフォルト値: SYSUT1) |
DDNOUT|O |
出力データセットを指定したDD名をddnameに記述します。(デフォルト値: SYSUT4) |
OPTION
レコードの選択条件を指定します。各OPTION文に記述された選択条件をテストといいます。各テストは基本的にOR条件で処理されます。COND句を適切に指定し、複数のテストをAND条件で組み合わせて使用することをテスト・シリーズといいます。
以下は、OPTIONコマンドの構文です。
OPTION {PRINT|COPY|NEGOF} [{OFFSET|O}={[underline]#1#|number}]
[,{FLDTYP|T}={[underline]#X#|C}]
[,{VALUE|V}=string]
[,{FLDLEN|L}={[underline]#1#|number}]
[,{COND|C}={[underline]#E#|M|T{Y|N}]
| パラメータ | 説明 |
|---|---|
選択されたすべてのレコードがSYSPRINT DDに出力されます。 |
|
COPY |
選択されたすべてのレコードが出力データセットにコピーされます。PRTSYSを使用すると、これらのレコードをSYSPRINT DDに出力することもできます。 |
NEGOF |
OFFSETに指定された値が、レコードの終わりからの負のオフセットとして使用されます。選択されたすべてのレコードは、SYSPRINT DDに出力されます。 |
OFFSET|O |
テストするレコード・フィールドの最初のバイトの位置を指定します。(デフォルト値: 1) NEGOFが指定された場合は、レコードの終わりからのバイト数を指定します。 |
FLDTYP|T |
VALUEとして指定された文字列のタイプを次のいずれから選択します。
|
VALUE|V |
指定されたレコード・フィールドと比較する値を文字列で定義します。 文字フィールドは255文字まで、165進数フィールドは510文字まで指定できます。 |
FLDLEN|L |
VALUEの値と比較するレコード・フィールドの長さを指定します。 デフォルト値は1であり、255まで指定できます。 |
COND|C |
テストのタイプと他のテストとの関係を定義します。
|
END
CONTROL文の終了を示します。以下は、END文の構文です。
END
3.3. 使用例
以下は、SYSUT1として与えられたSMFデータセットをSYSUT4にコピーする例です。
//DFHJUP JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //STEP EXEC PGM=DFHJUP //SYSOUT DD SYSOUT=* //SYSUT1 DD DSN=SMLOG.CICSDATA,DISP=SHR //SYSUT4 DD DSN=SMF.CICSDUMP,DISP=NEW,DCB=LRECL=32760 //SYSIN DD * OPTION COPY END /* //
以下は、SYSUT1として与えられたSMFデータセットをOPTION文の条件に従って選択し、SYSPRINTに出力する例です。後ろから4バイト目の値が「E」のレコードのみ選択されます。
//DFHJUP JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //STEP EXEC PGM=DFHJUP //SYSOUT DD SYSOUT=* //SYSUT1 DD DSN=SMLOG.CICSDATA,DISP=SHR //SYSUT4 DD DSN=SMF.CICSDUMP,DISP=NEW,DCB=LRECL=32760 //SYSPRINT DD DSN=SMF.CICSPRT,DISP=NEW,DCB=LRECL=32760 //SYSIN DD * OPTION NEGOF OFFSET=4,T=C,V=E END /* //
以下は、UTILINとして与えられたSMFデータセットをOPTION文の条件に従って選択し、UTILOUTにコピーするか、SYSPRINTに出力する例です。
//DFHJUP JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //STEP EXEC PGM=DFHJUP //SYSOUT DD SYSOUT=* //UTILIN DD DSN=SMLOG.CICSDATA,DISP=SHRv //UTILOUT DD DSN=SMF.CICSDUMP,DISP=NEW,DCB=LRECL=32760 //SYSIN DD * CONTROL CNTL SKIP=4,STOPAFT=(8,E),DDNAME=UTILIN,DDNOUT=UTILOUT OPTION COPY OFFSET=7,T=C,V=E,C=M OPTION COPY OFFSET=6,V=30,L=1 OPTION COPY OFFSET=6,FLDTYP=C,VALUE=0,FLDLEN=1,COND=M OPTION COPY O=7,V=D,C=M,L=1,T=C END /* //
-
SKIP文によって、UTILINの最初の4つのレコードは無視されます。
-
STOPAFT文によって、条件を満たす8つのレコードまでDFHJUPで処理します。
-
以下の条件を満たす場合、UTILOUTにコピーされます。
( (7バイト目の値が'E' ) AND (6バイト目の値がX'30') ) OR ( (6バイト目の値が'0') AND (7バイト目の値が'D') )
以下は、SYSUT1として与えられたSMFデータセットをSUBSYSサブパラメータの条件に従ってTRUNCATEする例です。
//DFHJUP JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //STEP EXEC PGM=DFHJUP //SYSOUT DD SYSOUT=* //SYSUT1 DD DSN=SMLOG.CICSDATA, // SUBSYS=(LOGR,DFHLGCNV,,DELBRCUR) //SYSIN DD * OPTION PRINT END /* //
4. IDCAMS
IDCAMSは、OpenFrameのVSAMと非VSAMデータセットおよびカタログ情報を管理するためのユーティリティ・プログラムです。
SYSIN DDに入力された各コマンドは、コマンド自体とオプションまたはパラメータで構成されます。IDCAMSは、実行するコマンドをSYSIN DDから読み込みます。
OpenFrameのIDCAMSユーティリティは、既存のメインフレームのIDCAMSコマンドを継承して使用しているため、ユーザーはメインフレームのIDCAMSと同様にOpenFrameのVSAMデータセット、非VSAMデータセット、およびカタログを管理することができます。
IDCAMSのコマンドは、2種類のコマンドに分類できます。
-
機能コマンド
実際にユーザーによって実行されるコマンドです。
コマンド 説明 定義済みのデータセットまたはカタログの属性を変更します。
次のようなデータセット・オブジェクト(またはカタログ・エントリ)を定義するために使用されます。
VSAMと非VSAMデータセットおよびカタログを削除します。
カタログとVSAMデータセットを移植可能なデータセットにエクスポートするか、バックアップ・データセットを作成します。
EXPORTコマンドによって作成された移植可能なカタログとVSAMデータセットをインポートするか、バックアップされたデータセットを元の状態に復元します。
カタログに登録されたVSAMと非VSAMデータセットの情報を表示します。
VSAMと非VSAMデータセットに保存されているレコードを表示します。
VSAMと非VSAMデートセットの内容をコピーします。
VSAMデータセットの異常終了(close)によってカタログされた正しくないデータセット情報を修正します。また、レコード数などの情報も正しく反映されているかどうかを確認します。
VSAMデータセットを終了する際、データセットの最後の位置やレコード数などの統計情報がカタログに保存されます。異常終了された場合は、カタログ情報と実際のデータセット情報が一致しないことがありますが、VERIFYコマンドを使用して正しく修正することができます。
-
補助コマンド
一連のIDCAMSコマンドの実行を制御するためのコマンドです。
コマンド 説明 実行されたコマンドの条件コード値(LASTCCまたはMAXCC)に従って次に実行するコマンドを分岐させるために使用します。
何もしないコマンドです。
IF-THEN-ELSEコマンドのTHENまたはELSEの後、何もしないことを明示するために使用されます。
MAXCCまたはLASTCCの値を特定の値に強制設定するために使用します。
プログラム実行中にCANCELコマンドが現れると、IDCAMSの実行が停止され、CANCELコマンドの後のコマンドは処理されません。
PARM
IDCAMSの実行中に適用される処理オプションおよびパラメータ値を指定します。現在はサポートされません。
-
機能しないコマンド
エラーが発生しないように構文解析のみサポートするコマンドです。
コマンド 説明 特定のデータセットの代替索引を作成します。
コーディング規則
IDCAMSを使用してコーディングする際、共通して適用される規則です。
-
ハイフン(-)
1つのコマンドを複数の行にまたがって記述する場合、各行の最後にハイフン(-)を入力し、次の行にコマンドの残りをコーディングします。ハイフン(-)は、キーワードまたはパラメータに含めることはできず、一般的にキーワードまたはパラメータの継続を表す場合にのみ使用します。
以下は、ハイフン(-)を使用したコーディングの例です。
LISTCAT ENT( - TEST.CLUS1 - TEST.KSDS1 - TEST.RRDS1 - TEST.SDS1)
複数行にまたがって記述されたコマンドの最終の行には、ハイフン(-)をコーディングしないように注意してください。
-
コメント
コメントは、IDCAMSコマンドの間に入力できます。ただし、キーワードまたはパラメータに含めることはできません。
コメントは、特別な機能はありませんが、1つのコマンドと見なされるため、コマンドにコメントを追加する場合は、行の最後にハイフン(-)を入力する必要があります。コメントは、空白またはコンマ(,)のようにIDCAMSのフィールドを区切ることもできるため、「/*」と「*/」の間に記述します。
以下は、コメントを正しく記述した例です。
/* This is IDCAMS Comment */ /* This is multi line Comment comment continued from above line */ LISTCAT ENT( /* Comment 1 */ - TEST.KSDS1 /* Comment 3 */ - TEST.SDS1 /* Comment 4 */ ) /* Comment 5 */
IF-THEN-ELSE文にコメントを使用する場合は、コメントによってIF-THEN-ELSEの構造が変更されないように注意してください。
4.1. DDの設定
OpenFrameのIDCAMSは、JCLを使用してバッチ・ジョブとして実行する方式と、UNIXシステムのコマンド行で直接実行するインタラクティブ方式の両方をサポートします。
JCLを使用したジョブの実行(using JCL as JOB)
JCLを使用してジョブのステップとしてIDCAMSを実行する場合、IDCAMSは次のようなDD文を使用します。
| 項目 | 説明 |
|---|---|
SYSIN DD |
IDCAMSが実行するコマンドを記述します。 データセットのレコード長は72列を超えることができません。コマンドが長くなる場合は、ハイフン(-)を使用します。 |
SYSPRINT DD または SYSOUT DD |
IDCAMSの実行結果および実行中に出力される情報メッセージ、警告メッセージ、エラーメッセージなどを保存するデータセットを記述します。 SYSPRINT DDを記述しないか、指定したデータセットの割り当て、オープンに失敗すると、IDCAMSは何もせずに終了され、条件コード16が返されます。 |
追加DD |
IDCAMSコマンドの一部はJCLに記述されたDDを使用して、対象のddnameまたはentrynameを間接的に指定することができます。この場合IDCAMSは、データセットを動的に割り当てるのではなく、ジョブの実行を制御するtjclrunによって事前にジョブ・レベルで割り当てられたデータセットを継承して使用します。 一般的にコマンドの対象となるデータセットを指定するパラメータは、JCLに記述されたddnameを使用してFILE(ddname)形式のパラメータ名を持ちます。 IDCAMSで動的割り当てを使用してデータセットを指定するパラメータは、DATASET(entryname)形式のパラメータ名を持ちます。 |
以下は、前述した追加DDに関する例です。REPRO BLDINDEX PRINTのパラメータを使用してJCLで割り当てられたデータセットを継承して実行されます。
INFILE(ddname), OUTFILE(ddname)
以下は、REPRO BLDINDEX PRINTのパラメータを使用してIDCAMSでデータセットを動的に割り当てる例です。
INDATASET(entryname), OUTDATASET(entryname)
JCLを使用してジョブのステップとしてIDCAMSを実行するには、IDCAMSを呼び出すジョブステップにDDを記述し、EXEC PGMにIDCAMSを指定した後、そのJCLをサブミットします。
//JOB01 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1)
//REPRO EXEC PGM=IDCAMS
//INDD DD DSN=VSAM.KSDS1,DISP=(OLD,KEEP)
//OUTDD DD DSN=VSAM.KSDS2,DISP=SHR
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
REPRO INFILE(INDD) -
OUTFILE(OUTDD) -
SKIP(50000) COUNT(10000)
/*
//
コマンド行での実行(using from Command line)
UNIXシステムのコマンド行でIDCAMSを直接実行します。この場合、SYSIN DDおよびSYSPRINT DDの代わりに標準入出力ストリーム(stdin/stdout/stderr)を使用して実行されます。つまり、stdinからIDCAMSコマンドを読み込んでコマンド単位で実行し、stdout/stderrには実行結果およびエラー・メッセージを出力するインタラクティブなインタプリタ方式です。
UNIXシステムのコマンド行で次のコマンドを実行すると、IDCAMSはDEFINE.TEST.CLUS1.CMDというVSAMデータセットを削除して再定義します。
$ IDCAMS < DEFINE.TEST.CLUS1.CMD
TEST.CLUS1.CMDは、一般的なUNIXテキスト・ファイルであり、以下の内容が含まれています。
DEFINE.TEST.CLUS1.CMDファイルは、IDCAMS UNIXコマンド行でのstdinリダイレクションを表示します。
DELETE TEST.CLUS1 CLUSTER
DEFINE CLUSTER -
(NAME(TEST.CLUS1) -
VOLUMES(100000) -
INDEXED -
KEYS(07 0) -
CYL (70 10) -
RECORDSIZE(200 200) -
SHR(2 3)) -
DATA (NAME(TEST.CLUS1.DATA) -
CONTROLINTERVALSIZE(4096) ) -
INDEX (NAME(TEST.CLUS1.INDEX) -
CONTROLINTERVALSIZE(4096) )
制約(Limitation)
DD(ddname)によって割り振られたデータセットを継承して使用するには、OpenFrame/Batch環境のtjclrunが必要です。ddnameを使用したデータセットの指定は、JCLを介してIDCAMSをジョブ・ステップとして実行する場合にのみ使用できるため、UNIXシステムのコマンド行では、ddnameを使用してデータセットを指定することができません。
UNIXコマンドを実行する場合は、IDCAMSコマンドの対象となるデータセットをDATASET(entryname)形式で指定する必要があります。
4.2. 機能コマンド
IDCAMSユーティリティの機能コマンドについて説明します。
ALTER
DEFINE文を使用してカタログに登録されているデータセットとカタログ・エントリの情報を変更することができます。以下は、ALTERコマンドの構文です。
ALTER entryname
[EMPTY|NOEMPTY]
[FILE(ddname)]
[LIMIT(limit)]
[NEWNAME(newname)]
[NULLIFY([OWNER][RETENTION])]
[OWNER(ownerid)]
[ROLLIN]
[SCRATCH|NOSCRATCH]
[SHAREOPTIONS(crossregion[crosssystem])]
[STORAGECLASS(class)]
[STRNO(number)]
[TO(date)|FOR(days)]
[CATALOG(catname)]
| パラメータ | 説明 |
|---|---|
entryname |
属性を変更する既存のデータセットまたはカタログ・エントリ名を指定します。 |
ROLLIN |
GDSがまだGDGベースに関連付けられていない(据え置きロールイン状態)か、ロールオフ状態にあるGDSをGDGベースに関連付けられている状態(ロールイン状態)に変更します。 |
CATALOG |
entrynameに指定されたカタログ・エントリを検索する際に使用するカタログを指定します。指定しない場合は、カタログの検索順に従って選択されます。 |
NEWNAME |
カタログに登録されているデータセット名を変更するために使用します。非VSAMデータセットにのみ使用できます。非VSAMをGDS名に変更してGDGベースに関連付けられている状態に変更できます。 |
|
その他のパラメータについては、IBMの『DFSMS Access Method Services for Catalogs』を参照してください。 |
カタログ・エントリ・タイプとカタログ・エントリに該当するユーザー・データセットにデータがロードされているかどうかによって、変更できる属性と変更できない属性に分けられます。
以下の表は、OpenFrame IDCAMSのALTERコマンドがサポートするカタログ・エントリ・タイプに応じて変更できる属性を示しています。(O=変更可能な属性)
| エントリ・タイプ 変更可能な属性 | AIX | AIX DATA | AIX INDEX | CLUS TER | CLUS TER DATA | CLUS TER INDEX | PATH | UCAT DATA | UCAT INDEX | NON- VSAM | GDG |
|---|---|---|---|---|---|---|---|---|---|---|---|
NEWNAME |
- |
- |
- |
- |
- |
- |
O |
- |
- |
O |
- |
EMPTY |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
O |
NOEMPTY |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
O |
LIMIT |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
O |
NULLIFY |
- |
- |
- |
- |
- |
- |
O |
- |
- |
O |
O |
OWNER |
- |
- |
- |
- |
- |
- |
O |
- |
- |
O |
O |
ROLLIN |
- |
- |
- |
- |
- |
- |
- |
- |
- |
O |
- |
RETENTION |
- |
- |
- |
- |
- |
- |
O |
- |
- |
O |
O |
SCRATCH |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
O |
NOSCRATCH |
- |
- |
- |
- |
- |
- |
- |
- |
- |
- |
O |
TO |
- |
- |
- |
- |
- |
- |
O |
- |
- |
O |
O |
FOR |
- |
- |
- |
- |
- |
- |
O |
- |
- |
O |
O |
|
その他のパラメータは、IBMの『DFSMS Access Method Services for Catalogs』を参照してください。 |
変更するカタログ・エントリに新しい属性値を指定するには、各パラメータのほか、変更されるカタログ・エントリを指定するためのパラメータが必要です。
以下は、カタログTESTCATに登録されたTEST.GDG1という名前のGDGの最大世代数を255に、有効期限を2006年の300番目の日付に変更する例です。
//JOB02 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1)
//ALTGDG EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
ALTER TEST.GDG1 -
LIMIT(255) -
TO(2006300) -
CATALOG(TESTCAT)
/*
//
DEFINE
以下は、DEFINEコマンドで共通して使用可能なパラメータです。
DEFINE Commands {NAME(entryname)|NAMES(entryname)} {CYLINDERS(primary[secondary])|
KILOBYTES(primary[secondary])|
MEGABYTES(primary[secondary])|
RECORDS(primary[secondary]])|
TRACKS(primary[secondary])}
VOLUMES(volser[volser...])
[CONTROLINTERVALSIZE(size)]
[DATACLASS(class)]
[MANAGEMENTCLASS(class)]
[OWNER(ownerid)]
[RECATALOG|NORECATALOG]
[RECORDSIZE(average maximum)]
[STORAGECLASS(class)]
[TO(date)|FOR(days)])
[DATA (...)]
[INDEX (...)]
[CATALOG(catname)]
| パラメータ | 説明 |
|---|---|
NAME | NAMES |
DEFINEコマンドを使用して作成または定義するカタログ・オブジェクト名を指定します。一部のDEFINEコマンドでは、NAMESをサポートしないことに注意してください。 |
VOLUMES |
データセットの作成時にデータセットを保存するボリュームのシリアル番号を指定します。 |
DATACLASS |
データ・クラス名(1~8文字)を指定します。データ・クラスは、SMS(ストレージ管理サブシステム)で定義され、新しいデータセットの作成時に使用されるさまざまな属性を持っています。 データ・クラスを指定した場合は、データ・クラスに定義されたDEFINEの属性を指定する必要はありません。指定したデータ・クラスに定義された属性とDEFINEコマンドに明示的に指定された属性が異なる場合は、DEFINEコマンドに指定された属性が優先されます。 |
MANAGEMENTCLASS |
管理クラス名(1~8文字)を指定します。管理クラスはSMSで定義され、作成されるデータセットの管理に影響を与えるTOやFORなどのさまざまな属性を持っています。 DEFINEコマンドにTOやFORが明示的に指定されており、管理クラスにも同じ属性が存在する場合は、管理クラスに定義された値が優先されます。 |
OWNER |
データセットの所有者を指定します。 |
RECATALOG| NORECATALOG |
既存のVVDSに保存されている情報に基づいて、クラスター、代替索引のデータおよびインデックス・コンポーネント、非VSAMデータセットに該当するカタログ・エントリを再作成します。クラスターと代替索引の場合、VVDSに存在するVVR(VSAM VOLUME RECORD)の内容がカタログ・エントリの再作成に使用されます。この際、VVRに含まれていない一部の情報は、DEFINEコマンドを使用して直接記述する必要があります。 このようなパラメータには、VSAMレコードを定義するためのINDEXED、NONINDEXED、NUMBEREDパラメータと、データセットが最初に作成されたVOLUMESパラメータ、VRDSにはRECORDSIZEパラメータ、ALTERNATEINDEXにはNAME、RELATE、VOLUMEパラメータがあります。 作成するカタログ・エントリが非VSAMデータセットの場合は、DEFINEコマンドを介してVOLUMESおよびDEVICETYPESパラメータを直接指定する必要があります。PATHの場合は、VVDSに保存される情報がないため、DEFINEコマンドにNAMEとPATHENTRYパラメータのみ指定するとRECATALOGが可能です。 |
RECORDSIZE |
CLUSTER、ALTERNATEINDEX、USERCATALOGを作成する際、データセットに保存されるレコード長を平均サイズと最大サイズで指定します。2つの値が同一の場合は、固定長レコードを意味します。
|
STORAGECLASS |
ストレージ・クラス名(1~8文字)を指定します。ストレージ・クラスは、SMSで定義され、作成されるデータセットに割り振られるストレージ・サイズに関する属性を持っています。 このパラメータを指定する場合は、ストレージ・サイズを指定するための必須パラメータであるCYLINDERSなどを指定する必要はありません。 DEFINEコマンドにストレージ・サイズが直接指定され、ストレージ・クラスに定義された値と異なる場合は、ストレージ・クラスに定義された値が優先されます。 |
TO|FOR |
データセットおよびカタログ・エントリを作成する際、オブジェクトの有効期限を指定します。
|
DATA, INDEX |
CLUSTER、ALTERNATEINDEX、USERCATALOGなどのデータ・コンポーネントとインデックス・コンポーネントを持つことができるVSAMクラスタを作成する場合、データ・コンポーネントとインデックス・コンポーネントにそれぞれパラメータ(一部該当するパラメータ)を指定することができます。 たとえば、ストレージの割り振りサイズを示すCYLINDERSパラメータは、DEFINE CLUSTERの際にクラスターのサブパラメータとして指定するか、DATAまたはINDEXコンポーネントのサブパラメータとして指定することもできます。このように別途指定した場合は、コンポーネントごとに異なる値が適用されます。 |
CATALOG |
DEFINEコマンドによって定義されるカタログ・エントリが登録されるカタログ名を指定します。 このパラメータを指定しない場合は、JOBのSTEPCATまたはJOBCATに指定されたカタログあるいはカタログ・エントリ名の一部をエイリアスとして使用するUSERCATALOGに登録されます。最後まで登録されるカタログが決まらない場合は、マスター・カタログに登録されます。詳細については、『OpenFrame データセットガイド』の「第4章 統合カタログ」の「カタログの検索順序」を参照してください。 |
|
DEFINEコマンドごとに指定できる実際のパラメータについては、各DEFINEコマンド節で説明します。本節では共通して使用するパラメタについて説明します。 |
DEFINE ALIAS
非VSAMデータセットまたはユーザー・カタログのエイリアスをカタログに作成します。
エイリアスに該当するカタログ・エントリには、元のデータセット名とエイリアスのみ含まれています。別途のユーザー・データを保存するためのデータセットは存在していません。
|
ユーザー・カタログを除くVSAMデータセットへのエイリアスは作成できません。 |
以下は、DEFINE ALIASコマンドの構文です。
DEFINE ALIAS (NAME(aliasname)
RELATE(entryname))
[CATALOG(catname)]
| パラメータ | 説明 |
|---|---|
NAME |
エイリアス名を指定します。 |
RELATE |
エイリアスが指す実際のエントリ名を指定します。 |
CATALOG |
エイリアスを登録するカタログを指定します。 |
以下は、TEST.NVSAM1のALIASにTEST.ALIAS1を作成し、TESTCATカタログに登録する例です。
//JOB04 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1)
//DEFALI EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
DEFINE ALIAS(NAME(TEST.ALIAS1) -
RELATE(TEST.NVSAM1)) -
CATALOG(TESTCAT)
/*
//
DEFINE ALTERNATEINDEX
DEFINE ALTERNATEINDEX(以下、AIX)コマンドを使用して、特定のデータセット(BASE CLUSTER)に対する代替索引(AIXデータセット)を定義します。
VSAMは、基本クラスターにレコードが追加、削除、または変更された場合、関連付けられたAIXを自動的に更新し、AIXが常に最新の状態を保つようにします。
AIXデータセットは、KSDSクラスターと同じ構造を持つため、DEFINE CLUSTERのパラメータをDEFINE AIXに使用することができます。
以下は、DEFINE AIXコマンドの構文です。
DEFINE AIX (NAME(entryname) | NAMES(entryname)
RELATE(entryname) {CYLINDERS(primary[secondary])|
KILOBYTES(primary[secondary])|
MEGABYTES(primary[secondary])|
RECORDS(primary[secondary])|
TRACKS(primary[secondary])}
VOLUMES(volser[ volser...])
[CONTROLINTERVALSIZE(size)]
[DATACLASS(class)]
[FILE(ddname)]
[KEYS(length offset|64 0)]
[OWNER(ownerid)]
[RECATALOG|NORECATALOG]
[RECORDSIZE(average maximum| 4086 32600)]
[TO(date)|FOR(days)]
[UNIQUEKEY|NONUNIQUEKEY]
[UPGRADE|NOUPGRADE])
[DATA ({CYLINDERS(primary[secondary])|
KILOBYTES(primary[secondary])|
MEGABYTES(primary[secondary])|
RECORDS(primary[secondary])|
TRACKS(primary[secondary])}
[VOLUMES(volser[volser...])]
[CONTROLINTERVALSIZE(size)]
[FILE(ddname)]
[KEYS(length offset)]
[NAME(entryname)]
[OWNER(ownerid)]
[RECORDSIZE(average maximum)]
[UNIQUEKEY|NONUNIQUEKEY])]
[INDEX ({CYLINDERS(primary[secondary])|
KILOBYTES(primary[secondary])|
MEGABYTES(primary[secondary])|
RECORDS(primary[secondary])|
TRACKS(primary[secondary])}
[VOLUMES(volser[volser...])]
[CONTROLINTERVALSIZE(size)]
[FILE(ddname)]
[NAME(entryname)]
[OWNER(ownerid)])]
[CATALOG(catname)]
| パラメータ | 説明 |
|---|---|
RELATE |
AIXに関連付けられた基本クラスター・データセット名を指定します。 基本クラスターとして使用されるデータセットは、KSDSとESDSデータ構造を持つVSAMデータセットのみ使用できます。 AIXを定義するには、DEFINE CLUSTERコマンドを使用して基本クラスターとして使用されるデータセットを事前に作成する必要があります。 |
RECORDSIZE |
AIXデータセット・クラスタのレコード・サイズを指定します。 SPANNEDパラメータは、最大32760まで指定できます。 |
UNIQUEKEY| NONUNIQUEKEY |
定義するAIXのキー値がデータセット全体で一意であるかどうかを指定します。 基本クラスターのKSDSデータセットは、常にUNIQUEKEYのみ指定することができます。ただし、AIXを作成する場合は、NONUNIQUEKEYを指定することができます。NONUNIQUEKEYが指定されると、1つの代替キーと複数の基本キーで構成されたレコードがAIXデータセット・クラスターのレコードとして保存されます。 |
UPGRADE |
定義するAIXクラスターの基本クラスターが変更された場合、AIXクラスターを同時に変更して、AIXクラスターが常に最新の状態を保つようにします。 |
以下は、VSAM.KSDS1に対して代替索引のVSAM.AIX1を作成する例です。
代替索引VSAM.AIX1レコードのオフセット44から先頭7バイトまでを代替キーにします。代替キーは一意ではなく、基本クラスターが変更されると自動的に更新されます。
//JOB05 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1)
//DEFAIX EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
DEFINE AIX (NAME(VSAM.AIX1) -
RELATE(VSAM.KSDS1) -
UPGRADE -
NUNQK -
KEYS(7 44) -
VOL(VOL100) -
SHR(2 3))
/*
//
DEFINE CLUSTER
DEFINE CLUSTERコマンドを使用してVSAMデータセットを定義し、その属性を設定することができます。
以下は、DEFINE CLUSTERコマンドの構文です。
DEFINE CLUSTER (NAME(entryname) | NAMES(entryname)
{CYLINDERS(primary[secondary])|
KILOBYTES(primary[secondary])|
MEGABYTES(primary[secondary])|
RECORDS(primary[secondary])|
TRACKS(primary[secondary])}
VOLUMES(volser[ volser...])
[CONTROLINTERVALSIZE(size)]
[DATACLASS(class)]
[FILE(ddname)]
[INDEXED|LINEAR|NONINDEXED|NUMBERED]
[KEYS(length offset| 64 0]
[MANAGEMENTCLASS(class)]
[OWNER(ownerid)]
[RECATALOG|NORECATALOG]
[RECORDSIZE(average maximum)]
[SPANNED|NONSPANNED]
[STORAGECLASS(class)]
[TO(date)|FOR(days)])
[DATA({CYLINDERS(primary[secondary])|
KILOBYTES(primary[secondary])|
MEGABYTES(primary[secondary])|
RECORDS(primary[secondary])|
TRACKS(primary[secondary])}
[VOLUMES(volser[volser...])]
[CONTROLINTERVALSIZE(size)]
[FILE(ddname)]
[KEYS(length offset)]
[NAME(entryname)]
[OWNER(ownerid)]
[RECORDSIZE(average maximum)]
[SPANNED|NONSPANNED])]
[INDEX({CYLINDERS(primary[secondary])|
KILOBYTES(primary[secondary])|
MEGABYTES(primary[secondary])|
RECORDS(primary[secondary])|
TRACKS(primary[secondary])}
[VOLUMES(volser[volser...])]
[CONTROLINTERVALSIZE(size)]
[FILE(ddname)]
[NAME(entryname)]
[OWNER(ownerid)])]
[CATALOG(catname)]
| パラメータ | 説明 |
|---|---|
VOLUMES |
データセットのターゲット・ボリュームを指定します。 |
INDEXED| NONINDEXED| NUMBERED |
データセット構造(KSDS、ESDS、RRDSなど)を指定します。 VRDSの場合は、NUMBEREDを指定してRECORDSIZEは可変長に指定します。 |
KEYS |
INDEXED構造でデータセットの1つのレコード上でキーとなる部分の位置とキー長を指定します。 |
RECORDSIZE |
データセット・レコードの平均長と最大長を設定します。 平均長と最大長が異なる場合は、可変長レコードとなります。 |
SPANNED |
SPANNEDパラメータが定義されたデータセットは、デフォルトとして指定されるCONTROLINTERVALSIZEより長いレコードを保存することができます。 NUMBERED構造のRRDSとVRDSデータセットでは、このパラメータを使用できません。 |
以下は、VSAM.KSDS1というINDEXED構造のデータセットを作成する例です。
VSAM.KSDS1に保存されるレコードは350バイトの固定長を持ち、キーフィールドはレコードの先頭の10バイトに位置します。VSAM.KSDS1データセットを構成するインデックスとデータ・コンポーネントの名前をそれぞれ明示的に指定しています。
//JOB06 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1)
//DEFCLUS EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
DEFINE CLUSTER (NAME(VSAM.KSDS1) -
INDEXED -
KEYS(10 0) -
VOL(VOL100) -
SPEED -
ORDERED -
SHR(2 3)) -
INDEX (NAME (VSAM.KSDS1.I)) -
DATA (NAME(VSAM.KSDS1.D) -
CISZ(4096) -
RECSZ(350 350))
/*
//
DEFINE GDG (Generation Data Group)
GDGに該当するカタログ・エントリをカタログに作成します。
非VSAMデータセットのGDSと違って、GDGに該当する実際のデータセットは存在しません。GDGカタログ・エントリには、今後GDGグループに属される複数のGDSを管理するための情報のみ含まれています。
したがって、DEFINE GDGの実行からデータセットは作成されず、GDGグループを管理するためのカタログ・エントリがカタログに追加されます。
以下は、DEFINE GDGコマンドの構文です。
DEFINE GENERATIONDATAGROUP (NAME(entryname)|NAMES(entryname)
LIMIT(limit)
[EMPTY|NOEMPTY]
[OWNER(ownerid)]
[SCRATCH|NOSCRATCH]
[TO(date)|FOR(days)])
[CATALOG(catname)]
| パラメータ | 説明 |
|---|---|
NAME | NAMES |
GDGベース名を指定します。 |
LIMIT |
GDGに含まれるGDSメンバーの最大数を指定します。1から255の範囲内で指定できます。 |
EMPTY| NOEMPTY |
GDGベースが格納できるGDSメンバーの最大値に達した場合、すべてのGDSとGDGベース間の関連付けを解除(ロールオフ状態)するためにEMPTYを指定します。 NOEMPTYを指定すると、最も古いGDSの関連付けを解除し、新しいGDSをGDGベースに追加します。GDGベースとロールオフ状態になったGDSは、非VSAMデータセットとして見なされます。 |
OWNER |
GDGベースの所有者を明示的に指定します。 |
SCRATCH| NOSCRATCH |
GDGベースが格納できるGDSメンバーの最大値に達した場合、EMPTYとNOEMPTYの属性に応じてすべてのまたは最も古いGDSデータセットとGDGベース間の関連付けが解除された後、該当のGDSが使用するデータを削除するかどうか(SCRATCHまたはNOSCRATCH)を指定します。 |
TO|FOR |
GDGグループの有効期限を設定します。
|
CATALOG |
GDGベースが登録されるカタログ名を指定します。 |
以下は、TEST.GDG1という名前のGDGベースを作成し、GDSメンバーの最大値を100、有効期限を2006年12月31日と指定してTESTCATカタログに登録する例です。
//JOB07 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1)
//DEFGDG EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
DEFINE GDG (NAME(TEST.GDG1) -
LIMIT(100) -
TO(2006365)) -
CATALOG(TESTCAT)
/*
//
DEFINE NONVSAM
PS(物理順次)非VSAMデータセットを作成してカタログに登録します。
|
GDGに属する1つのGDSは非VSAMデータセットであるため、DEFINE NONVSAMコマンドを使用してGDSを作成することができます。 |
以下は、DEFINE NONVSAMコマンドの構文です。
DEFINE NONVSAM ({NAME(entryname)|NAMES(entryname)}
DEVICETYPES(devtype [devtype ...])
VOLUMES(volser [volser ...])
[OWNER(ownerid)]
[RECATALOG|NORECATALOG]
[TO(date)|FOR(days)])
[CATALOG(catname)]
| パラメータ | 説明 |
|---|---|
NAME | NAMES |
非VSAMデータセット名を指定します。 GDGに属するGDSを作成するには、GDGname.GxxxxVyy形式でエントリ名を指定する必要があります。たとえば、TEST.GDG1.G0001V00の0001は世代番号であり、00はバージョン番号です。 命名規則については、『OpenFrameデータセットガイド』を参照してください。 |
DEVICETYPES |
非VSAMデータセットが格納されるボリュームのデバイス・タイプ(3380、3390、3480など)を指定します。SYSDAなどのエソテリック・デバイス・グループ(esoteric device group)は使用できません。 |
VOLUMES |
非VSAMデータセットが格納されるボリュームのシリアル番号を指定します。 |
CATALOG |
非VSAMデータセットのカタログ・エントリ情報が登録されるカタログを指定します。 |
OWNER |
非VSAMデータセットの所有者を明示的に指定します。 |
RECATALOG| NORECATALOG |
非VSAMデータセットのVVDSと既存のデータセットをカタログにのみ新規登録する場合は、RECATALOGを指定します。 (デフォルト値: NORECATALOG、データセットを新規作成) |
TO|FOR |
非VSAMデータセットの有効期限を設定します。
|
以下は、非VSAMデータセットのTEST.NVSAM1を作成してTESTCATカタログに登録する例です。
//JOB08 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1)
//DEFNVS EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
DEFINE NONVSAM (NAME(TEST.NVSAM1) -
VOLUMES(100000)) -
CATALOG(TESTCAT)
/*
//
DEFINE PATH
DEFINE PATHコマンドは、基本クラスターへの直接パスまたは代替索引を経由してアクセスする間接パスを定義することができます。
以下は、DEFINE PATHコマンドの構文です。
DEFINE PATH ({NAME(entryname) | NAMES(entryname)}
[PATHENTRY(entryname)]
[OWNER(ownerid)]
[RECATALOG|NORECATALOG]
[TO(date)|FOR(days)]
[UPDATE|NOUPDATE])
[CATALOG(catname)]
| パラメータ | 説明 |
|---|---|
NAME | NAMES |
DEFINE PATH文を使用してパス名を指定します。 |
PATHENTRY |
パスがAIXと基本クラスターで構成されている場合、entrynameはAIXデータセット名を指定します。 パスがAIXなしの基本クラスターで構成されている場合、entrynameはクラスター・データセット名を指定して、基本クラスター・データセットのエイリアスであった場合と同様に定義することができます。また、1つの基本クラスターに複数のパスを定義することができるため、必要に応じて各パスに異なる属性を指定することができます。 |
OWNER |
アクセス・パスの所有者を明示的に指定します。 |
RECATALOG| NORECATALOG |
|
TO|FOR |
アクセス・パスの有効期限を設定します。
|
UPDATE| NOUPDATE |
|
以下は、代替索引のVSAM.AIX1を経由して、VSAM.AIX1の基本クラスターにアクセスするためのパス(VSAM.PATH1)を作成する例です。
UPDATEパラメータが指定されているため、このパスを使用して基本クラスターを変更すると、VSAM.AIX1以外の他の代替索引も自動的に更新されます。
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1)
//DEFPATH EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
DEFINE PATH (NAME(VSAM.PATH1) -
PATHENTRY(VSAM.AIX1) -
UPDATE)
/*
//
以下は、代替索引を経由せずに基本クラスターに直接アクセスするためのパス(VSAM.PATH2)を定義する例です。
UPDATEパラメータが指定されているため、VSAM.KSDS1を基本クラスターとする代替索引が存在する場合は、VSAM.PATH2を介して基本クラスターが変更されるたびに自動的に更新されます。
//JOB10 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1)
//DEFPATH EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
DEFINE PATH (NAME(VSAM.PATH2) -
PATHENTRY(VSAM.KSDS1) -
UPDATE)
/*
//
|
DEFINE PATHの詳細については、『OpenFrame データセットガイド』を参照してください。 |
DEFINE USERCATALOG
システムが提供するマスター・カタログのほか、複数のユーザー・カタログを定義することができます。
すべてのデータセットに関するメタ情報をマスター・カタログに登録すると、マスター・カタログのサイズが必要以上に大きくなるため、システムのパフォーマンスが低下する可能性があります。
DEFINE USERCATALOGコマンドを使用すると、システムのマスター・カタログの代わりに使用できるユーザー・カタログを作成することができます。これはマスター・カタログのサブカタログとして見なされます。
作成されたユーザー・カタログの情報はマスター・カタログに保存されます。ただし、ユーザー・カタログのサブカタログとして別のユーザー・カタログを作成することはできません。つまり、すべてのユーザー・カタログはマスター・カタログにのみ登録でき、他のユーザー・カタログには登録できません。ユーザー・カタログは、ユーザーごとに作成するか、関連部署または業務ごとに作成するのが一般的です。
OpenFrameでは、マスター・カタログを作成するときは別途のコマンドを使用しませんが、ユーザー・カタログを追加作成する場合は、IDCAMSのDEFINE USERCATALOGコマンドを使用します。
以下は、DEFINE USERCATALOGコマンドの構文です。
DEFINE USERCATALOG ({NAME(entryname)}
{CYLINDERS(primary[secondary])|
KILOBYTES(primary[secondary])|
MEGABYTES(primary[secondary])|
RECORDS(primary[secondary])|
TRACKS(primary[secondary])}
VOLUME(volser)
[CONTROLINTERVALSIZE(size)]
[DATACLASS(class)]
[FILE(ddname)]
[MANAGEMENTCLASS(class)]
[OWNER(ownerid)]
[RECORDSIZE(average maximum|4086 32400)]
[STORAGECLASS(class)]
[TO(date)|FOR(days)])
[DATA ({CYLINDERS(primary[secondary])|
KILOBYTES(primary[secondary])|
MEGABYTES(primary[secondary])|
RECORDS(primary[secondary])|
TRACKS(primary[secondary])}
[CONTROLINTERVALSIZE(size)]
[RECORDIZE(average maximum|4086 32400)])]
[INDEX ({CYLINDERS(primary[secondary])|
KILOBYTES(primary[secondary])|
MEGABYTES(primary[secondary])|
RECORDS(primary[secondary])|
TRACKS(primary[secondary])}
[CONTROLINTERVALSIZE(size)])]
[CATALOG(mastercatname)]
| パラメータ | 説明 |
|---|---|
NAME |
ユーザー・カタログ名を指定します。 |
VOLUME |
ユーザー・カタログが保存されるボリュームを指定します。 |
RECORDSIZE |
ユーザーが指定したRECORDSIZEパラメータは無視され、基本カタログ構造を持つデータセットのデフォルト・レコード・サイズ(4086 32400)が使用されます。 |
CATALOG |
ユーザー・カタログが登録されるマスター・カタログ名を指定します。このパラメータを指定しなくても、システムのマスター・カタログに自動的に登録されます。 |
|
その他のパラメータについては、IBMの『DFSMS Access Method Services for Catalogs』を参照してください。 |
DELETE
VSAMデータセットと非VSAMデータセット、およびカタログされたデータセット項目を削除します。
DELETEコマンドは、既存の項目を削除するだけなので、多くのパラメータは必要ありません。削除されるデータセット名またはカタログ・エントリ・タイプのみ必要です。
以下は、DELETEコマンドの構文です。
DELETE (entryname [entryname ...])
[ALIAS|
ALTERNATEINDEX|
CLUSTER|
GENERATIONDATAGROUP|
NONVSAM|
PATH|
TRUENAME|
USERCATALOG]
[FILE(ddname)]
[FORCE|NOFORCE]
[PURGE|OPURGE]
[CATALOG(catname)]
| パラメータ | 説明 |
|---|---|
entryname |
削除されるデータセットまたはカタログ・エントリ名を指定します。 複数のエントリを削除する場合は、エントリ名のリストを括弧で囲みます。 entrynameで指定されたデータセットは排他的に(DISP=OLD)割り振られます |
ALIAS| ALTERNATEINDEX| CLUSTER| GENERATIONDATA GROUP| NONVSAM| PATH| TRUENAME| USERCATALOG |
ALIASエントリ・タイプです。削除されるカタログ・エントリのタイプを指定します。 エントリ・タイプの指定はオプションですが、エントリ・タイプを指定すると、同一名の項目を誤って削除することを防ぐことができます。 AIX、CLUSTER、PATH、TRUENAMEは、VSAMデータセットのエントリ・タイプであり、ALTERNATEINDEX、GENERATIONDATAGROUP、NONVSAM、USERCATALOGは、非VSAMデータセットのエントリ・タイプです。 |
FILE |
削除されるデータセットを指定します。 FILE(ddname)でデータセットを指定する場合、そのDD名は、IDCAMSを呼び出したJCLのDD文によって割り当てられたDD名を指定する必要があります。 |
FORCE|NOFORCE |
削除されるGDGがGDGメンバーを持っていても、強制的に削除するかどうかを指定します。現在は、GDGに対してのみ使用できます。
|
PURGE|NOPURGE |
データセットの定義時に指定された保存期限に関係なく、データセット・エントリを削除するかどうかを指定します。
データセットの保存期間は、DEFINEコマンドのTOおよびFORパラメータによって指定されます。 |
CATALOG |
削除されるカタログ・エントリ情報が登録されているカタログを指定します。 |
以下は、指定された保存期間に関係なく、VSAMデータセット・エントリ・タイプのVSAM.KSDS1とVSAM.KSDS2を削除する例です。
//JOB11 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1)
//DELCLUS EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
DELETE (VSAM.KSDS1 VSAM.KSDS2) -
CLUSTER -
ERASE -
PURGE
/*
//
EXPORT
EXPORTコマンドは、VSAM CLUSTERまたはALTERNATE INDEXを移植可能データセットにエクスポートします。カタログ・データセットをバックアップするために使用されます。
以下は、EXPORTコマンドの構文です。
EXPORT entryname {OUTFILE(ddname)|OUTDATASET(entryname)}
[INFILE(ddname)]
[TEMPORARY|PERMANENT]
| パラメータ | 説明 |
|---|---|
entryname |
エクスポートされるカタログ・エントリ名を指定します。 entrynameで指定されたエクスポートするデータセットは排他的(DISP=OLD)に割り振られます。 |
OUTFILE| OUTDATASET |
エクスポートによって作成されるデータセットを指定します。 作成されたデータセットをカタログに新規作成するか、すでにカタログされている場合はentrynameを使用し、実行環境でIDCAMSを呼び出す前に事前に割り振られているデータセットに作成する場合はddnameを使用します。 OUTDATASETパラメータによって指定されたデータセットは排他的(DISP=OLD)に割り振られます。 |
INFILE |
エクスポートされるデーターセットを指定します。 INFILE(ddname)でデータセットを指定する場合は、IDCAMSを呼び出したJCLのDD文によって割り振られたDD名を指定する必要があります。 |
TEMPORARY|PERMANENT |
エクスポート操作を実行した後、対象のカタログ・エントリを削除するかどうかを設定します。
|
以下は、TESTCATカタログをTESTCAT.BACKUPにエクスポートしてバックアップする例です。
//JOB12 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1)
//BACKCAT EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//BACK DD DSN=TESTCAT.BACKUP,DISP=OLD
//SYSIN DD *
EXPORT TESTCAT -
OUTFILE(BACK)
/*
//
IMPORT
IMPORTコマンドは、EXPORTコマンドによって作成されたバックアップ・データセットや移植可能データセットからデータセットを復元または新規作成します。
以下は、IMPORTコマンドの構文です。
IMPORT {INFILE(ddname)|INDATASET(entryname)}
{OUTFILE(ddname)|OUTDATASET(entryname)}
[INTOEMPTY]
[OBJECTS((entryname
[MANAGEMENTCLASS(class)]
[NEWNAME(newname)]
[STORAGECLASS(class)]
[VOLUMES(volser[ volser...])])
[(entryname...)...])]
[CATALOG(catname)]
| パラメータ | 説明 |
|---|---|
INFILE|INDATASET |
インポートされるソース・データセットを指定します。 IDCAMSを呼び出す前に実行環境で事前に割り振られているデータセットを使用する場合はddnameを使用し、IDCAMS内で割り振る場合はentrynameを使用します。 INDATASETパラメータによって指定されたソース・データセットは排他的(DISP=OLD)に割り振られます。 |
OUTFILE|OUTDATASET |
IDCAMSを呼び出す前に実行環境で事前に割り振られているデータセットを使用する場合はddnameを使用し、IDCAMS内で割り振る場合はentrynameを使用します。 OUTDATASETパラメータによって指定されたデータセットは排他的(DISP=OLD)に割り振られます。 |
INTOEMPTY |
ターゲット・データセットがカタログに登録されていないか、ストレージ・スペースが割り当てられていない場合(空のデータセット)、IMPORTコマンドは失敗します。INTOEMPTYパラメータを指定すると、インポートの実行時に必要なストレージ・スペースが割り当てられ、インポートが正常に行われます。 |
OBJECTS |
インポートされるデータセットの一部の属性を変更します。変更されるエントリ名と適用する新しい属性を指定します。複数のエントリ名を指定することもできます。 |
CATALOG |
インポート中にカタログ化が必要な場合、使用されるカタログを指定します。 |
以下は、バックアップ・データセットTESTCAT.BACKUPをカタログTESTCATにインポートする例です。TESTCAT.BACKUPを使用してTESTCATを復元します。
//JOB13 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1)
//IMPCAT EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//BACK DD DSN=TESTCAT.BACKUP,DISP=OLD
//SYSIN DD *
IMPORT INFILE(BACK) -
OUTDATASET(TESTCAT)
/*
//
LISTCAT
LISTCATコマンドは、カタログに定義された次のようなデータセット情報を表示します。
-
エントリ・オブジェクトの属性
-
作成・変更・有効期限
-
保護関連情報
-
データセット・アクセスの統計情報
-
ストレージ・スペースの割り当て
-
データセットの構造
以下は、LISTCATコマンドの構文です。
LISTCAT [ALIAS]
[ALTERNATEINDEX]
[CLUSTER]
[DATA]
[GENERATIONDATAGROUP]
[INDEX]
[NONVSAM]
[PATH]
[USERCATALOG]
[ENTRIES(entryname[ entryname...])|LEVEL(level)]
[NAME|HISTORY|VOLUME|ALLOCATION|ALL]
[CATALOG(catname)]
| パラメータ | 説明 |
|---|---|
ALIAS ALTERNATEINDEX, CLUSTER, DATA, GENERATIONDATA GROUP, INDEX, NONVSAM, PATH, USERCATALOG |
指定されたカタログ・エントリに対してのみLISTCAT情報を表示します。たとえば、LISTCAT CLUSTERが指定された場合は、CLUSTERエントリのみ表示します。 また、複数のエントリ・タイプを指定することも可能です。LISTCAT DATA INDEXが指定された場合は、DATAまたはINDEXエントリのみ表示します。 このパラメータを指定しない場合は、すべてのエントリ情報が表示されます。 ENTRIESパラメータを指定した場合は、ENTRIESパラメータに指定されたエントリ名と一致しないエントリ情報は、エントリ・タイプが一致しても表示されません。 |
ENTRIES|LEVEL |
LISTCATコマンドのターゲット・カタログ・エントリ名を指定します。
以下は、ENTRIESとLEVELの使用例です。
(*は、セグメントのすべての文字と一致します) |
NAME|HISTORY| VOLUME| ALLOCATION|ALL |
エントリ・タイプのフィルターおよびENTRIESパラメータによって指定されるエントリ名の条件を満たすカタログ・エントリの情報を表示するレベルを指定します。 NAMEを指定すると、基本的な情報のみ表示され、ALLを指定すると、すべてのエントリ情報が表示されます。 |
CATALOG |
LISTCATコマンドのターゲット・カタログ名を指定します。ENTRIESまたはLEVELで指定されたエントリ名は、指定されるカタログから検索されます。 |
以下は、VSAM.KSDS1のすべてのエントリ情報を表示する例です。
//JOB14 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //LISTC EXEC PGM=IDCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * LISTCAT ENTRIES(VSAM.KSDS1) ALL /* //
以下は、LISTCATコマンドの実行結果として表示される内容(SYSPRINT)です。
CLUSTER ------------- VSAM.KSDS1
HISTORY
CREATION -------------- (NULL) DATASET-OWNER ----------- (EMPTY)
RELEASE ------------------- 1 VSAM QUIESCED --------------- (NO)
PROTECTION-PSWD---------- (NULL)
ASSOCIATIONS
DATA ------------ VSAM.KSDS1.D
INDEX ----------- VSAM.KSDS1.I
DATA ---------------- VSAM.KSDS1.D
HISTORY
CREATION --------------- (NULL) DATASET-OWNER ---------- (EMPTY)
RELEASE -------------------- 1
PROTECTION-PSWD ---------- (NULL)
ASSOCIATION
CLUSTER ----------- VSAM.KSDS1
ATTRIBUTES
AVGLRECL ----------------- 350 MAXLRECL ------------------- 350
KEYLEN -------------------- 10 RKP -------------------------- 0
CISIZE ------------------ 4096 INDEXED
REUSE NON-SPANNED
STATISTICS
REC-DELETED ---------------- 0 REC-INSERTED ------------- 10445
REC-RETRIEVED -------------- 0 REC-TOTAL ---------------- 10445
REC-UPDATED ---------------- 0 TIMESTAMP ---------------- (NULL)
ALLOCATION
HI-A-RBA ------------------- 0 HI-U-RBA --------------------- 0
VOLUMES
VOLSER ----------------- (TSAM)
INDEX --------------- VSAM.KSDS1.I
HISTORY
CREATION --------------- (NULL) DATASET-OWNER ---------- (EMPTY)
RELEASE -------------------- 1
PROTECTION-PSWD ---------- (NULL)
ASSOCIATION
CLUSTER ----------- VSAM.KSDS1
ATTRIBUTES
AVGLRECL ----------------- 350 MAXLRECL ------------------- 350
KEYLEN -------------------- 10 RKP -------------------------- 0
CISIZE ------------------ 4096 REUSE
STATISTICS
INDEX:
ENTRIES/SECT ------------ 254 HI-LEVEL-RBA ----------- 12288
LEVELS -------------------- 2 SEQ-SET-RBA ------------- 4096
REC-DELETED ----------------- 0 REC-INSERTED ------------ 10445
REC-RETRIEVED --------------- 0 REC-TOTAL --------------- 10445
REC-UPDATED ----------------- 0 TIMESTAMP --------------- (NULL)
ALLOCATION
HI-A-RBA -------------------- 0 HI-U-RBA ------------------- 0
VOLUMES
VOLSER ---------------------- (TSAM)
VSAMおよび非VSAMデータセットに保存されているレコードを出力します。
以下は、PRINTコマンドの構文です。
PRINT {INFILE(ddname)|INDATASET(entryname)}
[CHARACTER|DUMP|HEX]
[FROMKEY(key)|FROMADDRESS(address)|FROMNUMBER(number)|SKIP(number)]
[OUTFILE(ddname)]
[TOKEY(key)|TOADDRESS(address)|TONUMBER(number)|COUNT(number)]
| パラメータ | 説明 |
|---|---|
INFILE|INDATASET |
PRINTコマンドを使用して出力するデータセットを指定します。
|
CHARACTER| DUMP| HEX |
出力フォーマットを指定します。
|
FROMKEY| FROMADDRESS| FROMNUMBER|SKIP |
REPROコマンドと同様にユーザーはこのパラメータを使用して出力するレコードの範囲を指定できます。各パラメータの詳細については、REPROコマンドのパラメータ説明を参照してください。 |
OUTFILE |
SYSPRINTではなく、他のDDにPRINTコマンドの結果を出力する場合に使用します。 PRINTコマンドによって出力されたデータセットの内容が保存されるデータセットを指定し、JCLを介して事前に割り当てられたDD名を指定します。 このパラメータを指定しないと、デフォルトとしてSYSPRINTに出力します。 |
TOKEY|TOADDRESS |TONUMBER|COUNT |
REPROと同様にユーザーはこのパラメータを使用して出力するレコードの範囲を指定できます。各パラメータの詳細については、REPROコマンドのパラメータ説明を参照してください。 |
以下は、TEST.KSDS1に保存されたレコードをDUMPフォーマットで出力する例です。キー値が0000000099である最初のレコードから10個のレコードが出力されます。
//JOB15 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1)
//PRINT EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
PRINT INDATASET(TEST.KSDS1) DUMP -
FROMKEY(0000000099) COUNT(10)
/*
//
以下は、上記のJCLの実行結果としてSYSPRINTに出力された内容です。
KEY OF RECORD = 30303030303030303939 0000: 3030 3030 3030 3030 3939 7265 636F 7264 *0000000099record* 0010: 3030 3030 3030 3030 3939 *0000000099 * KEY OF RECORD = 30303030303030313030 0000: 3030 3030 3030 3031 3030 7265 636F 7264 *0000000100record* 0010: 3030 3030 3030 3031 3030 *0000000100 * KEY OF RECORD = 30303030303030313031 0000: 3030 3030 3030 3031 3031 7265 636F 7264 *0000000101record* 0010: 3030 3030 3030 3031 3031 *0000000101 * KEY OF RECORD = 30303030303030313032 0000: 3030 3030 3030 3031 3032 7265 636F 7264 *0000000102record* 0010: 3030 3030 3030 3031 3032 *0000000102 * KEY OF RECORD = 30303030303030313033 0000: 3030 3030 3030 3031 3033 7265 636F 7264 *0000000103record* 0010: 3030 3030 3030 3031 3033 *0000000103 * KEY OF RECORD = 30303030303030313034 0000: 3030 3030 3030 3031 3034 7265 636F 7264 *0000000104record* 0010: 3030 3030 3030 3031 3034 *0000000104 * KEY OF RECORD = 30303030303030313035 0000: 3030 3030 3030 3031 3035 7265 636F 7264 *0000000105record* 0010: 3030 3030 3030 3031 3035 *0000000105 * KEY OF RECORD = 30303030303030313036 0000: 3030 3030 3030 3031 3036 7265 636F 7264 *0000000106record* 0010: 3030 3030 3030 3031 3036 *0000000106 * KEY OF RECORD = 30303030303030313037 0000: 3030 3030 3030 3031 3037 7265 636F 7264 *0000000107record* 0010: 3030 3030 3030 3031 3037 *0000000107 * KEY OF RECORD = 30303030303030313038 0000: 3030 3030 3030 3031 3038 7265 636F 7264 *0000000108record* 0010: 3030 3030 3030 3031 3038 *0000000108 * PRINT 10 record(s) IDCAMS: PRINT OK
REPRO
REPROコマンドは、DEFINEコマンドによって定義されたVSAMおよび非VSAMデータセットを他のデータセットにコピーします。そのとき、VSAMデータセットはカタログに登録されている必要がありますが、非VSAMデータセットはカタログに登録されている必要はありません。
メインフレームのカタログは、一般的に1つのKSDSクラスターに保存されているため、REPROコマンドはカタログの内容をコピーする用途で使用されます。
REPROコマンドを使用せずに一般的なアプリケーションを使用してデータセットにレコードを保存することもできます。ただし、レコードの内容に関係なく、管理目的でデータセットをコピーする場合は、REPROコマンドが使用されます。
コピーするソース・データセットとターゲット・データセットの両方をユーザー・カタログとして指定した場合、カタログ・レコードがコピーされます。
以下は、REPROコマンドの構文です。
REPRO {INFILE(ddname)|INDATASET(entryname)}
{OUTFILE(ddname)|OUTDATASET(entryname)}
[ENTRIES(entryname [entryname...])|LEVEL(level)]
[FROMKEY(key)|FROMADDRESS(address)|FROMNUMBER(number)|SKIP(number)]
[MERGECAT|NOMERGECAT]
[REPLACE|NOREPLACE]
[REUSE|NOREUSE]
[TOKEY(key)|TOADDRESS(address)|TONUMBER(number)|COUNT(number)]
| パラメータ | 説明 |
|---|---|
INFILE|INDATASET |
コピーされるソース・データセットを指定します。
|
OUTFILE|OUTDATASET |
ソース・データセットをコピーするターゲット・データセットを指定します。
|
ENTRIES|LEVEL |
REPROコマンドを使用してコピーするターゲット・カタログ・エントリ名を指定します。この場合、2つのカタログ間のカタログ・エントリ名のみがコピーされます。これは、実際にカタログ・エントリが指すデータセットのコピーを意味するものではありません。
以下は、ENTRIESとLEVELの使用例です。
(*は、セグメントのすべての文字と一致します) |
FROMKEY| FROMADDRESS| FROMNUMBER|SKIP |
データセット全体ではなく、一部のレコードのみコピーします。 最初のレコードのキー、アドレス、レコード番号を指定します。SKIPパラメータは、コピーする前にスキップするレコード数を指定します。 KSDSにFROMKEY、ESDSにFROMADDRESS、RRDSにFROMNUMBERを使用してコピーするターゲットを制御することができます。非VSAMデータセットは、SKIPのみ使用可能であり、各データセットの属性に対応していない項目を使用すると、エラーが発生します。 |
MERGECAT| NOMERGECAT |
REPROコマンドを使用してユーザー・カタログのレコードを他のユーザー・カタログにコピーします。
|
REPLACE|NOREPLACE |
ソース・データセットをターゲット・データセットにコピーする際、ターゲット・データセットに同じレコードが存在する場合、置き換えるかどうかを指定します。
|
REUSE|NOREUSE |
ターゲット・データセットがカタログではなく、VSAMデータセットの場合のみ使用します。
|
TOKEY|TOADDRESS TONUMBER|COUNT |
コピーされるターゲット・レコードを制限します。コピーが終了するレコードを指定します。 KSDSにTOKEY、ESDSにTOADDRESS、RRDSにTONUMBERを使用してコピーするターゲットを制御することができます。非VSAMデータセットは、COUNTのみ使用可能であり、各データセットの属性に対応していない項目を使用すると、エラーが発生します。 |
以下は、VSAM.KSDS1データセットの50001番のレコードから10000個のレコードをVSAM.KSDS2データセットにコピーする例です。
//JOB16 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1) //REPRO EXEC PGM=IDCAMS //INDD DD DSN=VSAM.KSDS1,DISP=(OLD,KEEP) //OUTDD DD DSN=VSAM.KSDS2,DISP=SHR //SYSPRINT DD SYSOUT=* //SYSIN DD * REPRO INFILE(INDD) - OUTFILE(OUTDD) - SKIP(50000) COUNT(10000) /* //
VERIFY
VSAMデータセットの異常終了によって、正しくないデータがカタログに書き込まれる可能性があります。
VERIFYコマンドは、このようなエラーが原因でカタログに誤りが生じた場合、問題のVSAMデータセットをチェックして誤りがある場合は正しく更新します。異常終了が発生すると、カタログのSTATISTICS/REC-TOTAL情報が実際のVSAMデータセットのレコード数と一致しないことがありますが、VERIFYコマンドを実行すると解決できます。
|
VERIFYコマンドはVSAMデータセットにのみ有効です。 |
以下は、VERIFYコマンドの構文です。
VERIFY FILE(ddname)|DATASET(entryname)
| パラメータ | 説明 |
|---|---|
FILE|DATASET |
VERIFYコマンドのターゲット・データセットを指定します。
|
以下は、TEST.CLUS1データセットのカタログ情報を確認する例です。
//JOBA JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1)
//VSTEP EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//TESTDD DD DSN=TEST.CLUS1,DISP=OLD
//SYSIN DD *
VERIFY FILE(TESTDD)
/*
//
4.3. 補助コマンド
IDCAMSを1回呼び出して複数のIDCAMSコマンドを実行することができます。補助コマンド(Modal command)は、複数のIDCAMSコマンドを実行するために必要な機能を提供します。実際にカタログ・エントリまたはオブジェクトを処理する機能コマンドとは異なります。
|
現在、IDCAMSの補助コマンドのうち、PARMはサポートしていません。 |
IF-THEN-ELSE
IF-THEN-ELSEコマンドは、条件コードの値(LASTCCまたはMAXCC)に基づいて、次に実行されるコマンドを制御します。IFとTHENの間には条件分岐の際に評価される条件を指定する必要があります。条件文は、条件コードの値と演算子の後の数字を比較して記述します。たとえば、 LASTCC > 8は、条件コードのLASTCCが8より大きいことを示します。
以下は、IF-THEN-ELSEコマンドの構文です。
IF {Condition Code} {operator} {number}
THEN[ command| DO command set END]
[ELSE[ command| DO command set END]]
-
条件コード
条件コードの値についての説明です。
値 説明 LASTCC
直前に実行された機能コマンドの結果によって生じた条件ンコードを演算子の後の数字と比較するように指定します。
コマンドが成功した場合は0、処理を続行できる警告は4、深刻な警告が発生した場合は数値が大きくなります。
MAXCC
現在実行中のコマンドと以前実行されたコマンドによって確立された条件コードを比較して最大値を保存します。
Operator
THEN文にはIF文が真である場合に実行するIDCAMSコマンドを記述し、ELSE文にはIF文が偽である場合に実行するコマンドを記述します。IF文が偽である場合に実行するコマンドがない場合はELSE文を省略することができます。
IF-THEN-ELSE文は条件に応じて異なるコマンドを実行する1つのIDCAMSコマンドとして見なされます。したがって、IF-THEN-ELSE文を複数行にまたがって記述する場合はハイフン(-)を適切に使用する必要があります。
以下の例では、LASTCCが8の場合、MAXCCを0に設定しています。条件文を真にするためにLASTCDを8に設定しているため、IF-THEN文が実行されるときは、THENに続くSET MAXCC-0が実行されます。MAXCCの値は、IDCAMSコマンドの終了時に確認できます。
SET LASTCC=8 IF LASTCC=8 THEN SET MAXCC=0
以下は、LASTCCが4より大きい場合は、TEST.SDS1のエントリ情報を取得し、LASTCCが4より大きくない場合はTEST.SDS2のエントリ情報を取得する例です。一般的には、SET LASTCCは別のIDCAMSコマンドに置き換えられ、その結果によってLASTCCが設定されます。この例では、IF-THEN-ELSE文をテストするためにLASTCCを0に設定しているため、IF文の結果によってTEST.SDS2がLISTCATされます。
SET LASTCC=0
IF LASTCC > 4 -
THEN -
LISTCAT ENT(TEST.SDS1)
ELSE -
LISTCAT ENT(TEST.SDS2)
NULL
NULLlは何も実行させずに、以下の目的でのみ使用されます。
-
THENまたはELSEの後ろにコマンドを指定しない場合に使用されます。
-
NULLがIF-THEN-ELSE文の外側で使用された場合は空の行として処理されます。
|
THENまたはELSEの後ろにハイフン(-)を指定すると、IDCAMSはTHENまたはELSE文の次にコマンドが続くと仮定して処理するので、意図したとおりコマンドが分岐されません。 |
以下は、LASTCCが4より大きい場合は何も実行せず、LASTCCが4より小さい場合はTEST.SDS2のエントリ情報を取得する例です。
SET LASTCC=0 IF LASTCC > 4 - THEN ELSE LISTCAT ENT(TEST.SDS2)
SET
SETコマンドは、MAXCCまたはLASTCCに特定の値に設定し、警告レベルの条件コードを無視してJCLでIDCAMSの後のステップを継続して実行するために使用されます。
以下は、LASTCCが8の場合、MAXCCを0に設定した例です。
DELステップでTEST.SDS1が見つからない場合は、戻りコード8が返され、DEFステップは実行されません。TJESの設定またはジョブに記述されたCONDによって異なりますが、戻りコードが8の場合はDEFステップを処理せず、ジョブがABEND処理されることを防ぐためには、MAXCCを0に設定して後続のDEFステップが実行されるように設定できます。
//JOB18 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //DEL EXEC PGM=IDCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * DELETE TEST.SDS1 IF LASTCC=8 THEN SET MAXCC=0 /* //DEF EXEC PGM=IDCAMS //SYSPRINT DD SYSOUT=* //SYSIN DD * DEFINE NONVSAM (NAME(TEST.SDS1) VOLUMES(100000)) /* //
CANCEL
CANCELコマンドはIDCAMSの実行を終了させ、残りのコマンドは処理されません。
以下は、LASTCCが4のとき、CANCELコマンドが実行され、IDCAMSの実行を終了する例です。
LISTCAT ENTRIES(MUST.EXIST.SDS) IF LASTCC=4 THEN CANCEL ...
LISCATで指定されたカタログ・エントリが存在しない場合の条件コードは4です。条件コード4はメッセージ・レベル条件コードであるため、次のIDCAMSコマンドが続行されます。
上記の例では、MUST.EXIST.SDSデーターセットが存在しない場合は次のコマンドを実行せず、IF条件を満たす場合はCANCELコマンドを実行してIDCAMSの実行を終了します。
4.4. 機能しないコマンド
IDCAMSの動作のためにエラーが発生しないように構文解析のみサポートするコマンドです。
BLDINDEX
BLDINDEXコマンドは、既存のデータセットの代替索引を作成します。
BLDINDEXコマンドは、代替索引クラスターに1つの代替キーと複数の基本キーで構成されるレコードをロードします。
OpenFrameでは、Tiberoの索引機能を使用してデータセットの代替索引を実装しているため、BLDINDEXコマンドは実際には機能しません。
以下は、BLDINDEXコマンドの構文です。
BLDINDEX {INFILE(ddname)|INDATASET(entryname)}
{OUTFILE(ddname)|OUTDATASET(entryname)}
[CATALOG(catname)]
| パラメータ | 説明 |
|---|---|
INFILE| INDATASET |
代替索引を構成するために使用されるベース・クラスターを指定します。
|
OUTFILE| OUTDATASET |
BLDINDEXの結果として構成される代替索引クラスターを指定します。BLDINDEXの前に代替索引が事前に定義されている必要があります。
|
CATALOG |
entrynameとして指定されたカタログ・エントリを検索する際に使用するカタログを指定します。指定しない場合は、カタログの検索順によって決定されます。 |
以下は、VSAM.KSDS1の代替索引であるVSAM.AIX1を構成する例です。
//JOB03 JOB OBM,CLASS=B,MSGCLASS=X,MSGLEVEL=(1,1)
//BLDAIX EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//BASE DD DSN=VSAM.KSDS1,DISP=OLD
//AIX DD DSN=VSAM.AIX1,DISP=OLD
//SYSIN DD *
BLDINDEX INFILE(BASE) -
OUTFILE(AIX)
/*
//
4.5. 環境設定
IDCAMSは、OpenFrame環境設定のidcamsサブジェクトに設定します。設定ファイルの内容を変更して、KQCAMSのいくつかの動作をカスタマイズできます。
|
idcamsサブジェクトの詳細については、『OpenFrame 環境設定ガイド』を参照してください。 |
[参考]
以下は、IDCAMSのコマンドのうち、実際には機能しないが、エラーが発生しないように処理されるパラメータです。
| コマンド | パラメータ |
|---|---|
ALTER |
[ACCOUNT(account-info)] |
[ADDVOLUMES(volser[ volser...])] |
|
[BUFFERSPACE(size)] |
|
[BUFND(number)] |
|
[BUFNI(number)] |
|
[BWO(TYPECICS│TYPEIMS│NO)] |
|
[CCSID(value)] |
|
[CODE(code)] |
|
[ECSHARING│NOECSHARING] |
|
[ERASE│NOERASE] |
|
[EXCEPTIONEXIT(entrypoint)] |
|
[FILEDATA(TEXT│BINARY)] |
|
[FREESPACE(CI-percent[ CA-percent])] |
|
[FRLOG(NONE[ REDO])] |
|
[INHIBIT│UNINHIBIT] |
|
[KEYS(length offset)] |
|
[LOCK│UNLOCK] |
|
[LOG(NONE│UNDO│ALL)] |
|
[LOGSTREAMID(logstream)] |
|
[MANAGEMENTCLASS(class)] |
|
[NULLIFY([AUTHORIZATION(MODULE│STRING)] [BWO] [CODE] [EXCEPTIONEXIT] [LOG] [LOGSTREAMID] |
|
[RECORDSIZE(average maximum)] |
|
[REMOVEVOLUMES(volser[ volser…])] |
|
[REUSE│NOREUSE] |
|
[ROLLIN] |
|
[SHAREOPTIONS(crossregion[ crosssystem])] |
|
[STORAGECLASS(class)] |
|
[STRNO(number)] |
|
[TYPE(LINEAR)] |
|
[UNIQUEKEY│NONUNIQUEKEY] |
|
[UPDATE│NOUPDATE] |
|
[UPGRADE│NOUPGRADE] |
|
[WRITECHECK│NOWRITECHECK] |
|
BLDINDEX |
[{EXTERNALSORT│INTERNALSORT}] |
[{SORTCALL│NOSORTCALL}] |
|
[SORTDEVICETYPE(device type)] |
|
[SORTFILENUMBER(number)] |
|
[SORTMESSAGEDD(ddname)] |
|
[SORTMESSAGELEVEL({ALL│CRITICAL│NONE})] |
|
[WORKFILES(ddname[ ddname...]) |
|
DEFINE command |
[ACCOUNT(account-info)] |
[BUFFERSPACE(size)] |
|
[BWO(TYPECICS│TYPEIMS│NO)] |
|
[ERASE│NOERASE] |
|
[EXCEPTIONEXIT(entrypoint)] |
|
[FILE(ddname)] |
|
[FREESPACE(CI-percent[ CA-percent])] |
|
[FRLOG(NONE[│REDO])] |
|
[LOG(NONE│UNDO│ALL)] |
|
[LOGSTREAMID(logstream)] |
|
[MODEL(entryname[ catname])] |
|
[REUSE│NOREUSE] |
|
[SHAREOPTIONS(crossregion[ crosssystem])] |
|
[SPEED│RECOVERY] |
|
[WRITECHECK│NOWRITECHECK]) |
|
[CYLINDERS(primary[secodnary])] |
|
[KILOBYTES(primary[secodnary])] |
|
[MEGABYTES(primary[secodnary])] |
|
[RECORDS(primary[secodnary])] |
|
[TRACKS(primary[secodnary])] |
|
[CONTROLINTERVALSIZE(size)] |
|
DELETE |
[LIBRARYENTRY│NVR│PAGESPACE│VOLUMEENTRY│VVR] |
[ERASE│NOERASE] |
|
[FORCE│NOFORCE] |
|
[PURGE│NOPURGE] |
|
[RECOVERY│NORECOVERY] |
|
[SCRATCH│NOSCRATCH] |
|
EXPORT |
[CIMODE│RECORDMODE] |
[ERASE│NOERASE] |
|
[INHIBITSOURCE│NOINHIBITSOURCE] |
|
[INHIBITTARGET│NOINHIBITTARGET] |
|
[PURGE│NOPURGE] |
|
[TEMPORARY│PERMANENT] |
|
IMPORT |
[ALIAS│NOALIAS] |
[ERASE│NOERASE] |
|
[LOCK│UNLOCK] |
|
[OBJECTS ([FILE(ddname)])] |
|
[PURGE│NOPURGE] |
|
[SAVRAC│NOSAVRAC] |
|
LISTCAT |
[LIBRARYENTRIES(libent)] |
[PAGESPACE] |
|
[VOLUMEENTRIES(volent)] |
|
[EXPIRATION(days)] |
|
[FILE(ddname)] |
|
[LIBRARY(libname)] |
|
[OUTFILE(ddname)] |
|
[DBCS] |
|
[INSERTSHIFT((offset1 offset2)[(offset1 offset2 )...])│INSERTALL] |
|
[SKIPDBCSCHECK((offset1 offset2) [(offset1 offset2)...])│NODBCSCHECK] |
|
REPRO |
[DBCS] |
[ERRORLIMIT(value)] |
|
[FILE(ddname)] |
|
[INSERTSHIFT((offset1 offset2)[(offset1 offset2 )...])│INSERTALL] |
|
[SKIPDBCSCHECK((offset1 offset2)[(offset1 offset2 )...])│ NODBCSCHECK] |
|
[VOLUMEENTRIES(entryname)] |
|
[ENCIPHER({EXTERNALKEYNAME(keyname)│ INTERNALKEYNAME(keyname)│PRIVATEKEY} [CIPHERUNIT(number│1)] [DATAKEYFILE(ddname)│DATAKEYVALUE(value)] [SHIPKEYNAMES(keyname[ keyname…])] [STOREDATAKEY│NOSTOREDATAKEY] [STOREKEYNAME(keyname)] [USERDATA(value)])] |
|
[DECIPHER ({DATAKEYFILE(ddname)│DATAKEYVALUE(value)│SYSTEMKEY} [SYSTEMDATAKEY(value)] [SYSTEMKEYNAME(keyname)])] |
以下は、DEFINEサブコマンドのパラメータです。
| サブコマンド | パラメータ |
|---|---|
ALIAS |
(SYMBOLICRELATE(entryname)) |
ALTERNATEINDEX |
(BUFFERSPACE(size)] |
[ERASE│NOERASE] |
|
[EXCEPTIONEXIT(entrypoint)] |
|
[FREESPACE(CI-percent[ CA-percent]│0 0)] |
|
[MODEL(entryname[ catname])] |
|
[REUSE│NOREUSE] |
|
[SHAREOPTIONS(crossregion[ crosssystem]│1 3)] |
|
[SPEED│RECOVERY] |
|
[WRITECHECK│NOWRITECHECK]) |
|
[DATA ([ATTEMPTS(number)] [AUTHORIZATION(entrypoint[ string])] [BUFFERSPACE(size)] [CODE(code)] [ERASE│NOERASE] [EXCEPTIONEXIT(entrypoint)] [FREESPACE(CI-percent[ CA-percent])] [MODEL(entryname [catname])] [REUSE│NOREUSE] [SHAREOPTIONS(crossregion[ crosssystem])] [SPEED│RECOVERY] [WRITECHECK│NOWRITECHECK])] |
|
[INDEX ([ATTEMPTS(number)] [AUTHORIZATION(entrypoint[ string])] [CODE(code)] [EXCEPTIONEXIT(entrypoint)] [MODEL(entryname[ catname ])] [REUSE│NOREUSE] [SHAREOPTIONS(crossregion[crosssystem])] [WRITECHECK│NOWRITECHECK])] |
|
CLUSTER |
([ACCOUNT(account-info)] |
[BUFFERSPACE(size)] |
|
[BWO(TYPECICS│TYPEIMS│NO)] |
|
[ERASE│NOERASE] |
|
[EXCEPTIONEXIT(entrypoint)] |
|
[FREESPACE(CI-percent[ CA-percent]│0 0)] |
|
[FRLOG(NONE[│REDO])] |
|
[LOG(NONE│UNDO│ALL)] |
|
[LOGSTREAMID(logstream)] |
|
[MODEL(entryname[ catname])] |
|
[REUSE│NOREUSE] |
|
[SHAREOPTIONS(crossregion[ crosssystem]│1 3)] |
|
[SPEED│RECOVERY] |
|
[WRITECHECK│NOWRITECHECK]) |
|
[DATA ([BUFFERSPACE(size)] [ERASE│NOERASE] [EXCEPTIONEXIT(entrypoint)] [FREESPACE(CI-percent[ CA-percent])] [MODEL(entryname [ catname ])] [REUSE│NOREUSE] [SHAREOPTIONS(crossregion[ crosssystem])] [SPEED│RECOVERY] [WRITECHECK│NOWRITECHECK])] |
|
[INDEX ([EXCEPTIONEXIT(entrypoint)] [MODEL(entryname[catname ])] [REUSE│NOREUSE] [SHAREOPTIONS(crossregion[ crosssystem])] [WRITECHECK│NOWRITECHECK])] |
|
GENERATIONDATAGROUP |
([SCRATCH│NOSCRATCH]) |
NONVSAM |
([COLLECTION] |
[FILESEQUENCENUMBERS(number[ number…])]) |
|
PATH |
([MODEL(entryname[ catname])]) |
USERCATALOG |
([BUFFERSPACE(size│3072)] |
[BUFND(number)] |
|
[BUFNI(number)] |
|
[ECSHARING│NOECSHARING] |
|
[FREESPACE(CI-percent[CA-percent]│0 0)] |
|
[ICFCATALOG│VOLCATALOG] |
|
[LOCK│UNLOCK] |
|
[MODEL(entryname[ catname])] |
|
[SHAREOPTIONS(crossregion[crosssystem]│3 4)] |
|
[STRNO(number│2)] |
|
[WRITECHECK│NOWRITECHECK]) |
|
[DATA ([BUFFERSPACE(size)] [BUFND(number)] [FREESPACE(CI-percent[ CA-percent])] [WRITECHECK│NOWRITECHECK])] |
|
[INDEX ([BUFNI(number)] [WRITECHECK│NOWRITECHECK])] |
4.6. 戻りコード
条件コードは、IDCAMSの各コマンドが正常に実行されたか、あるいはエラーが発生したかを示します。条件コードには、0、4、8、12、16があり、数値が大きいほどコマンドの実行に重大なエラーが発生したことを示します。
以下は、各条件コードについての説明です。
| コード | 意味 |
|---|---|
0 |
コマンドが正常に処理された場合です。情報メッセージが表示されることがあります。 |
4 |
いくつかのコマンドを実行できませんでしたが、次のコマンドを続行してもエラーが発生しないと判断された場合です。警告メッセージが一緒に出力されます。 たとえば、LISCATコマンドの実行時にユーザー指定のカタログ・エントリが見つからない場合は条件コード4が設定され、以下のメッセージが出力されます。 IDCAMS: No specified catalog entry found: NOT.EXIST.SDS |
8 |
いくつかのコマンドを実行できませんでしたが、実行結果が期待通りであり、次のコマンドを実行できます。 たとえば、DELETEコマンドに指定したデータセットが存在しないと、DELETEコマンドは実行されませんが、データセットが存在しないという結果は同じです。この場合、次のコマンドの実行には問題ないため、条件コード8が設定され、警告メッセージが出力されます。 IDCAMS(WARNING): No such catalog entry - 'NOT.EXIST.SDS' |
12 |
コマンドの実行中に重大なエラーが発生した場合です。このようなエラー(論理エラー)は、同時に指定できないパラメータを指定した場合や、必須パラメータが指定されていない場合、またはデータセットのキー長、レコード・サイズなどの値が正しくない場合に発生します。このような重大なエラーが発生すると、戻りコード12が設定され、エラー・メッセージが出力されます。 IDCAMS(ERROR): {error description or logical error code}
|
16 |
コマンドの実行中に次のような重大なエラーが発生し、ユーザーが指定した残りのコマンドを実行できない場合に発生します。
IDCAMS(ERROR): {error description or logical error code}
または
IDCAMS(FATAL): {error description}
|
条件コードの変数名(LASTCCとMAXCC)
IDCAMSは、LASTCCとMAXCC変数に条件コード値を保存します。
LASTCCには直前実行したコマンドの条件コードが保存され、MAXCCには既存の条件コードの最大値が保存されます。LASTCCとMAXCCは、SETコマンドを使用してユーザーが直接設定することができます。
以下は、NOT.EXIST.SDSデータセットを削除した後、LASTCCが8の場合にMAXCCを0に設定する例です。
DELETE NOT.EXIST.SDS IF LASTCC = 8 THEN SET MAXCC=0 DEFINE ...
5. IEBCOMPR
IEBCOMPRは、2つのデータセット(SDSまたはPDS)を比較して結果を表示するユーティリティ・プログラムです。
IEBCOMPRは、以下のような機能を実行します。
-
2つのSDSを比較します。
-
2つのPDSを比較します。
-
PDSの特定のメンバーを選択して比較します。
-
比較結果が一致しない場合、その結果を出力します。
5.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
SYSPRINT DD |
IEBCOMPRメッセージが保存されるデータセットを記述します。 |
SYSUT1 DD |
比較する順次データセットまたはPDSタイプの入力データセットを記述します。 |
SYSUT2 DD |
比較する順次データセットまたはPDSタイプの入力データセットを記述します。 |
SYSIN DD |
IEBCOMPRコマンドを記述します。 |
5.2. コマンドの設定
IEBCOMPRのコマンドについて説明します。
COMPARE
比較するデータセットの編成、比較処理の中断に関する指示、比較するレコードまたはフィールドなどを指定する制御文です。
以下は、COMPAREコマンドの構文です。
[label] COMPARE [FIELD=(length[,starting-location]) |
MASK=(length, starting-location)]
[,LIMIT=n]
[,MAXNAME=n]
[,STRTAFT=n]
[,STOPAFT=n]
[,TYPORG={PS|PO}]
[,DFOFFSET]
[,DFOFFSET_ALL]
[,MAXIGNORE]
[,NOLIMIT]
| パラメータ | 説明 |
|---|---|
FIELD |
レコード内のフィールドを比較するときに設定します。設定しない場合は、レコード全体が比較されます。複数設定した場合は、同時に複数のフィールドを比較します。 MASKオプションと一緒に使用できません。
|
MASK |
レコード内のフィールドを除外して比較するときに設定します。 FIELDオプションと一緒に使用できません。
|
LIMIT |
レコードの比較中に同じでない連続したレコードの数が設定した値と一致した場合、レコードの比較を中止します。 複数のメンバーを指定した場合は、次のメンバーの比較を開始します。SDSまたは1つのメンバーを比較する場合は処理を終了します。 nは、1~32760の範囲内の10進数で指定します。設定しないかゼロに設定した場合は、LIMIT=10と見なされます。 |
MAXNAME |
MEMBER制御文で指定するメンバー名の数より大きい値を設定します。 nは、1~32760の範囲内の10進数で指定します。 MEMBER制御文がない場合は、指定しても無視されます。 |
STRTAFT |
順次データセットを比較する前にスキップする論理レコードの数を設定します。 データセットのn+1番目の論理レコードから比較します。 レコードの範囲は32760を超えない必要があり、超えた場合はエラーメッセージを出力します。 設定しない場合は、最初のレコードから比較します。 |
STOPAFT |
比較する順次データセットの論理レコード数を設定します。 順次データセットまたは区分データセットの各メンバーを比較するレコード数を設定します。 レコードの範囲は32760を超えない必要があり、超えた場合はエラーメッセージを出力します。 設定しない場合は、最後のレコードまで比較します。 |
TYPORG |
入力データセットが順次データセット(PS)なのか、分割データセット(PO)なのかを設定します。 (デフォルト値: PS) |
DFOFFSET |
レコードを比較中にデータが異なる部分の最初の位置を出力します。DFOFFSET_ALLと一緒に指定すると、DFOFFSET_ALLが優先されます。 |
DFOFFSET_ALL |
レコードでデータが異なるすべての位置を出力します。 |
MAXIGNORE |
LIMIT、STRTAFT、STOPAFT項目の最大値の制限を解除します。 (指定しない場合の最大値: 32760) |
NOLIMIT |
LIMITが無視され、レコードの最後まで比較します。 |
MEMBER
入力データセットがPDSの場合、比較されるメンバー名を指定する制御文です。
-
すべてのメンバーを比較するときは省略できます
-
すべてのメンバーを比較するときは、同一名のみ比較します
この制御文で指定したメンバー名の数より大きい値を、COMPARE制御文のMAXNAMEパラメータに指定する必要があります。
[label] MEMBER NAME={member-name | (sysut1-member-name,sysut2-member-name)}[,...]
| パラメータ | 説明 |
|---|---|
NAME |
比較するメンバー名を設定します。
|
LABELS
ユーザー・ラベルを処理するときに記述します。解析のみサポートされます。
EXITS
出口ルーチンを使用するときに記述します。解析のみサポートされます。
5.3. 使用例
以下は、フィールドを指定してデータを比較する例です。IEBCOMPR.TEST.INPUT01とIEBCOMPR.TEST.INPUT02の最初のフィールドから11番目のフィールドと15番目のフィールドから長さが5のフィールドを比較します。
一致しない場合は、その結果を出力します。
//TEST JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JOBSTEP EXEC PGM=IEBCOMPR
//SYSUT1 DD DSNAME=IEBCOMPR.TEST.INPUT01,DISP=(SHR)
//SYSUT2 DD DSNAME=IEBCOMPR.TEST.INPUT02,DISP=(SHR)
//SYSPRINT DD SYSOUT=A
//SYSIN DD *
COMPARE FIELD=11,FIELD(5,15),TYPORG=PS
/*
以下は、除外されるフィールドを指定してデータを比較する例です。IEBCOMPR.TEST.INPUT01とIEBCOMPR.TEST.INPUT02の15番目のフィールドから長さが7のフィールドを除外して比較します。
//TEST JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JOBSTEP EXEC PGM=IEBCOMPR
//SYSUT1 DD DSNAME=IEBCOMPR.TEST.INPUT01,DISP=(SHR)
//SYSUT2 DD DSNAME=IEBCOMPR.TEST.INPUT02,DISP=(SHR)
//SYSPRINT DD SYSOUT=A
//SYSIN DD *
COMPARE MASK=(7,15),TYPORG=PS
/*
以下は、レコードを指定してデータを比較する例です。IEBCOMPR.TEST.INPUT01とIEBCOMPR.TEST.INPUT02の2番目のレコードまでスキップして、3番目のレコードから7つのレコードを比較します。
一致しない連続したレコードの数が3と一致したときに比較を中止します。
一致しない場合は、その結果を出力します。
//TEST JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JOBSTEP EXEC PGM=IEBCOMPR
//SYSUT1 DD DSNAME=IEBCOMPR.TEST.INPUT01,DISP=(SHR)
//SYSUT2 DD DSNAME=IEBCOMPR.TEST.INPUT02,DISP=(SHR)
//SYSPRINT DD SYSOUT=A
//SYSIN DD *
COMPARE LIMIT=3,STRTAFT=2,STOPAFT=7,TYPORG=PS
/*
以下は、同じ名前のメンバーを指定してデータを比較する例です。IEBCOMPR.TEST.INPUT01とIEBCOMPR.TEST.INPUT02のメンバーA、B、Cを比較します。
一致しない場合は、その結果を出力します。
//TEST JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JOBSTEP EXEC PGM=IEBCOMPR
//SYSUT1 DD DSNAME=IEBCOMPR.TEST.INPUT01,DISP=(SHR)
//SYSUT2 DD DSNAME=IEBCOMPR.TEST.INPUT02,DISP=(SHR)
//SYSPRINT DD SYSOUT=A
//SYSIN DD *
COMPARE MAXNAME=3,TYPORG=PO
MEMBER NAME=A,B,C
/*
以下は、異なる名前のメンバーを指定してデータを比較する例です。IEBCOMPR.TEST.INPUT01のメンバーA、B、DとIEBCOMPR.TEST.INPUT02のメンバーA、C、Dを比較します。
一致しない場合は、その結果を出力します。
//TEST JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JOBSTEP EXEC PGM=IEBCOMPR
//SYSUT1 DD DSNAME=IEBCOMPR.TEST.INPUT01,DISP=(SHR)
//SYSUT2 DD DSNAME=IEBCOMPR.TEST.INPUT02,DISP=(SHR)
//SYSPRINT DD SYSOUT=A
//SYSIN DD *
COMPARE MAXNAME=4,TYPORG=PO
MEMBER NAME=A,(B,C),D
/*
5.4. 戻りコード
以下は、IEBCOMPRユーティリティの戻りコードです。
-
正常に実行された場合
バッチ・アプリケーションからの戻りコードを返します。
-
エラーが発生した場合
SYSPRINT DDにエラーメッセージを出力し、該当するエラーコードを返します。
コード 説明 8
一致しないレコードが1つ以上ある場合です。
一致しないレコードの数がLIMITパラメータで指定された値より大きい場合に適用されます。
-
PDSの場合は、次のメンバーを処理します。戻りコードは8です。
12
一致しないレコードがLIMITパラメータで指定された値より大きい場合です。
-
SDSの場合のみ適用されます。
回復不能エラーです。次のようなエラーがあります。
-
データセット関連(pgmdd、open/close、read/write)エラー
-
SYSIN DDコマンドの構文エラー
-
その他のIEBCOMPRユーティリティ・プログラムのエラー
16
システム・エラーです。
-
OpenFrameシステム・ライブラリの初期化に失敗
-
6. IEBCOPY
IEBCOPYは、1つ以上のPDS全体または一部をコピーまたはマージするために使用されるユーティリティ・プログラムです。
IEBCOPYは、以下のような機能を実行します。
-
PDSのコピーまたはマージを実行します。
-
PDSの特定のメンバーを選択してコピーし、メンバー名を再定義します。
-
PDSの特定のメンバーを除いてコピーします。
-
PDSのメンバーを置き換えます。
6.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
SYSPRINT DD |
IEBCOPYメッセージを保存するデータセットを定義します。 |
SYSUT1 DDまたは user_defined_name1 DD |
PDSタイプの入力データセットを定義します。 |
SYSUT2 DDまたは user_defined_name2 DD |
PDSタイプの出力データセットを定義します。 |
SYSIN DD |
IEBCOPYコマンドを定義します。 |
6.2. コマンドの設定
IEBCOPYでは2つの方法でコマンドを設定できます。JCL EXEC文のPARMパラメータを使用するか、またはJCLのSYSIN文に記述します。
以下は、使用できるコマンドの省略形です。
| コマンド | 省略形 |
|---|---|
COPY |
C |
EXCLUDE |
E |
SELECT |
S |
OUTDD |
O |
INDD |
I |
LIST |
L |
MEMBER |
M |
EXEC PARM
以下は、EXEC文のPARMパラメータの構文です。
//[stepname] EXEC PGM=IEBCOPY[,PARM=<parms>]
| コマンド | 説明 |
|---|---|
PARM |
PARMパラメータのparmsの値です。以下のいずれかのコマンドを設定します。
|
COPY
PDSのメンバーをコピーします。
以下は、SYSIN DDのCOPYコマンドの構文です。
[label] COPY OUTDD=ddname,
INDD=[(]{ddname|(ddname,R)}[,...][)]
[,LIST={YES|NO}]
| パラメータ | 説明 |
|---|---|
OUTDD |
出力データセットのためのDD名を指定します。 |
INDD |
入力データセットのためのDD名を指定します。 出力データセットにコピーしようとするメンバーと同じ名前のメンバーが存在する場合、R(REPLACE)が指定されていれば上書きされ、指定されていない場合はコピーされません。 |
LIST |
コピーされたメンバー名をSYSPRINTに書き込みます。(デフォルト値: YES) LISTが指定されていない場合は、EXEC PARMの設定が適用されます。 |
INDD
COPY文のサブコマンドとして使用されるINDDはCOPY文の後に設定され、設定された順序で入力データセットを出力データセットにコピーします。
INDD文を使用すると、複数の入力データセットに対してそれぞれEXCLUDE文またはSELECT文を適用することができます。
EXCLUDE
EXCLUDEはCOPY文の後に設定され、COPY文の実行時に入力データセットから特定のメンバーを除外します。EXCLUDE文とSELECT文を同時に指定することはできません。EXCLUDE文とSELECT文が両方とも指定されなかった場合は、データセット全体をコピーします。
以下は、EXCLUDE文の構文です。
[label] EXCLUDE MEMBER=[(] name1[,name2][,...][)]
| パラメータ | 説明 |
|---|---|
MEMBER |
COPY文の実行時にコピーから除外するメンバー名を指定します。 |
SELECT
SELECT文はCOPY文の後に設定され、入力データセットの特定のメンバーを選択して新しい名前でコピーします。
以下は、SELECT文の構文です。
[label] SELECT MEMBER=({name1|(name1,newname1[,R])|(name1,,R)}
[,{name2|(name2,newname2[,R])|(name2,,R)}][,...])
| パラメータ | 説明 |
|---|---|
MEMBER |
nameフィールドに指定された入力データセットのメンバーをnewnameフィールドに指定された新しい名前でコピーします。 newnameフィールドが指定されていない場合は、nameフィールドに指定されたメンバー名と同じ名前が使用されます。 R(REPLACE)パラメータが設定されており、入力データセットのメンバーと同じ名前が出力データセットに存在する場合は、入力データセットのメンバー名で上書きされます。 |
6.3. 使用例
以下は、PDS DATASET1をPDS DATASET2にデータセット全体をコピーする例です。
//COPYALL JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //JOBSTEP EXEC PGM=IEBCOPY //SYSPRINT DD SYSOUT=A //SYSUT1 DD DSNAME=DATASET1,DISP=(SHR,KEEP) //SYSUT2 DD DSNAME=DATASET2,UNIT=disk,VOL=SER=200000, // DISP=(NEW,CATLG) //SYSIN DD DUMMY
以下のようにDATASET1のすべてのメンバー(A、B、F)がPDS DATASET2にコピーされます。
以下は、4つのデータセットをマージする例です。DATASET1、DATASET3、DATASET4のメンバーが既存のデータセットDATASET5にコピーおよびマージされます。SYSIN DDコマンドに定義されているINDDの順序に従って、最初にDATASET1がコピーされ、次にDATASET4、最後にDATASET3の順でコピーされます。
//MERGE JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //JOBSTEP EXEC PGM=IEBCOPY //SYSPRINT DD SYSOUT=A //IN01 DD DSNAME=DATASET1,DISP=(SHR,KEEP) //IN02 DD DSNAME=DATASET3,DISP=(SHR,KEEP) //OUT01 DD DSNAME=DATASET5,DISP=(SHR,KEEP) //IN03 DD DSNAME=DATASET4,DISP=(SHR,KEEP) //SYSIN DD * COPYOPER COPY OUTDD=OUT01,INDD=IN01,INDD=IN03,INDD=IN02 /*
IEBCOPYが実行される前に、DATASET5にはすでにAというメンバーが存在しており、REPLACEが設定されていないため、DATASET1のメンバーAはコピーされずにメンバーBとFのみがコピーされます。次にDATASET4のメンバーBはコピーされずにメンバーDとXのみがコピーされます。最後にDATASET3のメンバーFとXはコピーされずにメンバーCとYのみがコピーされます。
以下の図は、上記例の実行プロセスと最終結果を示しています。
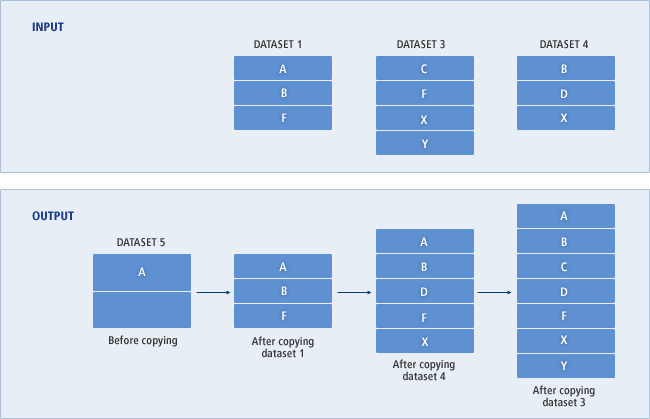
以下は、入力データセットから特定のメンバーを選択あるいは除外してコピーする例です。
//SELECT JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JOBSTEP EXEC PGM=IEBCOPY
//IN01 DD DSNAME=DATASET4,DISP=(SHR,KEEP)
//IN02 DD DSNAME=DATASET3,DISP=(SHR,KEEP)
//OUT01 DD DSNAME=DATASET6,DISP=(OLD,KEEP)
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
COPYOPER COPY OUTDD=OUT01
INDD=IN01
EXCLUDE MEMBER=X
INDD=IN02
SELECT MEMBER=((F,Z),(C,A,R),(Y,,R))
/*
IEBCOPYが実行される前に、DATASET6にはメンバーのA、K、Yが存在しています。INDD=IN01によって最初にDATASET4がコピーされます。EXCLUDE文によってメンバーXは除外され、メンバーBとDがコピーされます。次にINDD=IN02によってDATASET3がコピーされます。SELECT文によってメンバーFが新しい名前のZでコピーされ、メンバーCが新しい名前のAでコピーされます。このとき、DATASET6にはすでにメンバーAが存在しているため、上書きされます。REPLACEが設定されていない場合はコピーされず、次に進みます。最後にメンバーYが既存のメンバーYを上書きします。
以下の図は、上記例の実行プロセスと最終結果を示しています。
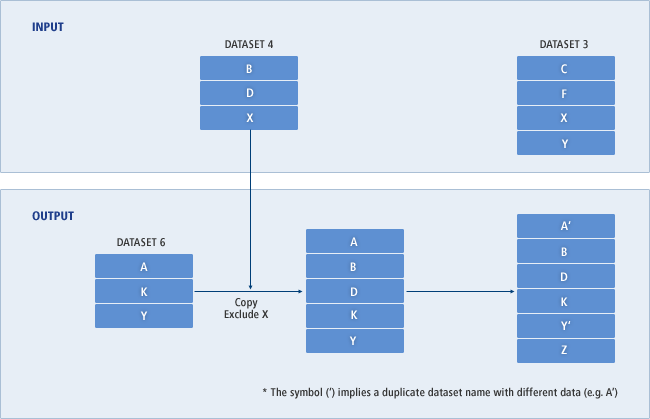
以下は、INDD文を使用して複数の入力データセットを処理する例です。
//INDD01 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//JOBSTEP EXEC PGM=IEBCOPY
//IN01 DD DSNAME=DATASET11,DISP=(SHR,KEEP)
//IN02 DD DSNAME=DATASET12,DISP=(SHR,KEEP)
//IN03 DD DSNAME=DATASET13,DISP=(SHR,KEEP)
//OUT01 DD DSNAME=DATASET14,DISP=(OLD,KEEP)
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
COPYOPER COPY OUTDD=OUT01
INDD=IN01
EXCLUDE MEMBER=B
INDD=IN02
SELECT MEMBER=((B,,R),(Y,N))
INDD=IN03
/*
IN01 DDに定義されたデータセットDATASET11からメンバーAとCのみコピーします。IN02 DDに定義されたデータセットDATASET12からメンバーB’を置き換え、メンバーYをNという名前に変更してコピーします。IN03 DDに定義されたデータセットDATASET13からはすべてのメンバーをコピーします。ただし、同じ名前のメンバーは置き換えません。
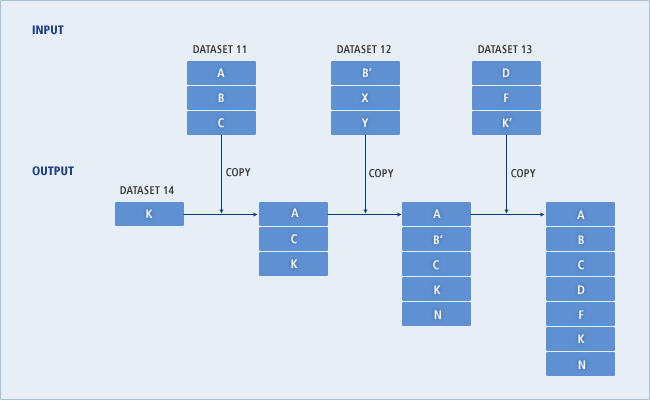
以下は、COPY文のサブコマンドとしてINDDを使用する例です。
//INDD01 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //JOBSTEP EXEC PGM=IEBCOPY //IN01 DD DSNAME=DATASET11,DISP=(SHR,KEEP) //IN02 DD DSNAME=DATASET12,DISP=(SHR,KEEP) //IN03 DD DSNAME=DATASET13,DISP=(SHR,KEEP) //OUT01 DD DSNAME=DATASET14,DISP=(OLD,KEEP) //SYSPRINT DD SYSOUT=* //SYSIN DD * COPYOPER COPY OUTDD=OUT01,INDD=(INO1,(IN02,R),IN03) /*
IN01 DDに定義されたデータセットDATASET11のすべてのメンバーをコピーします。ただし、同じ名前のメンバーは置き換えません。IN02 DDに定義されたデータセットDATASET12のすべてのメンバーをコピーします。メンバーB’は置き換えられます。IN03 DDに定義されたデータセットDATASET13からすべてのメンバーをコピーします。ただし、同じ名前のメンバーは置き換えません。
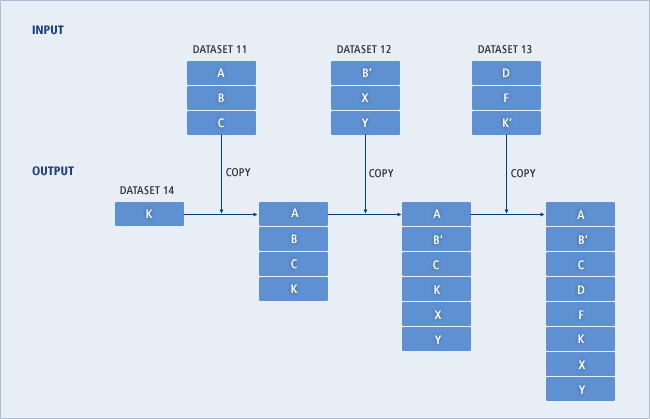
7. IEBDG
IEBDGは、SYSIN DDにデータのパターンを指定して、テスト・データセットを作成するユーティリティ・プログラムです。
7.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
SYSPRINT DD |
IEBDGメッセージを保存するデータセットを定義します。 |
user_defined_name1 DD |
JCLを保存するデータセットまたはデータセットのメンバーを記述します。 |
user_defined_name2 DD |
新しく作成されたJCLを保存するデータセットまたはデータセットのメンバーを記述します。 |
SYSIN DD |
IEBDGのコマンドを記述します。 |
7.2. コマンドの設定
以下は、SYSIN DDで設定するIEBDGのコマンドです。
DSD
DSDコマンドは、IEBDGを使用して実行するコマンドの開始を意味します。テスト・データの作成に使用する入力データセットとテスト・データが出力される出力データセットを指定します。少なくとも1つ以上のDSDが存在し、END文で終了する必要があります。
以下は、DSD文の構文です。
[label] DSD OUTPUT=(ddname)
[,INPUT=(ddname1[,ddname2][,...])]
| 項目 | 説明 |
|---|---|
OUTPUT |
出力データセットのDDを指定します。 |
INPUT |
入力として使用するデータセットのDDを指定します。 |
FD
テスト・データが出力される出力データのフィールド形式を指定します。
以下は、FD文の構文です。
[label] FD NAME=name
,LENGTH=length
[,STARTLOC=starting-location]
[,FILL={'character'|X'nn'}]
[,{FORMAT=pattern[,CHARACTER=character]
|PICTURE=length,{'character-string'|P'n'|B'n'}}]
[,SIGN=sign]
[,ACTION={FX|RO|RP|SL|SR|TL|TR|WV}
[,INDEX=n[,CYCLE=n][,RANGE=n]]
| パラメータ | 説明 |
|---|---|
NAME |
フィールド名を指定します。CREATEコマンドのNAME文を使用してフィールド名を指定するときに使用されます。 |
LENGTH |
フィールド長を指定します。 |
STARTLOC |
レコード内のフィールドの開始位置を指定します。 |
FILL |
デフォルトでフィールドを埋める値を指定します。 単一引用符(' ')で囲んで文字を入力するか、16進数の値を入力します。
|
FORMAT |
フィールドを埋めるパターンを指定します。 以下は、パターンに使用できる値です。
|
CHARACTER |
パターンの開始文字を指定します。 |
PICTURE |
ユーザーがパターンを直接定義します。LENGTHで設定されたフィールド長の分だけ指定します。LENGTHの長さより大きく指定すると、LENGTHの長さを超えるパターンは無視されます。(FORMAT文とは一緒に使用できません) |
SIGN |
パック10進数またはバイナリ・フィールドの符号を指定します。 |
ACTION |
フィールドの内容を変更する方法を指定します。現在は、PICTUREを使用してユーザーが直接指定した文字列型のフィールドまたはFORMATのAL、ANフィールドにのみ有効です。
|
INDEX |
レコードが追加されるたびにフィールド値を増やす10進数を指定します。 FORMATがZD、PD、BIであるか、PICTUREを指定した場合に使用できます。ただし、PICTUREの文字列の後ろは数値で構成される必要があります。
|
REPEAT
REPEATコマンドは、CREATEコマンド・グループが繰り返し実行される回数を指定します。
以下は、REPEATコマンドの構文です。
[label] REPEAT QUANTITY=number[,CREATE=number]
| パラメータ | 説明 |
|---|---|
QUANTITY |
CREATEコマンド・グループが繰り返される回数を指定します。 |
CREATE |
CREATEコマンド・グループを構成するCREATEコマンドの数を指定します。 (デフォルト値: 1) |
CREATE
CREATEコマンドは、出力データセットのレコードの構成を定義します。
以下は、CREATEコマンドの構文です。
[label] CREATE [QUANTITY=n]
[,FILL={'character'|X'nn'}]
[,INPUT={ddname|SYSIN[({cccc|$$$E})]}]
[,PICTURE=length,startloc,{'character-string'| P'n'|B'n'}]
[,NAME={(namelist)| (namelist-or-(copygroup))}
[,EXIT=routinename]
| パラメータ | 説明 |
|---|---|
QUANTITY |
CREATE文によって作成されるレコードの数を指定します。(デフォルト値: 1) |
FILL |
デフォルトでフィールドを埋める値を指定します。 単一引用符(' ')で囲んで文字を入力するか、16進数の値を入力します。
|
INPUT |
入力として使用するデータセットのDDを指定します。 DDの代わりにSYSINを使用して入力データを直接JCL内に記述することができ、データの最後は「$$$E」です。SYSINの「cccc」機能はサポートされません。
|
PICTURE |
ユーザーがパターンを直接定義します。 |
NAME |
入力として使用する名前リストを記述します。 namelistのみ記述するか、namelistとcopygroupを組み合わせることができます。
使用方法は、以下のとおりです。
|
EXIT |
現在はサポートされません。 |
END
ENDコマンドはDSDコマンドとペアになり、コマンドの終わりを意味します。
以下は、ENDコマンドの構文です。
[label] END
7.3. 使用例
2つのCREATEコマンドを使用して各フィールドに合わせてOUTPUT DDに保存する例です。
最初のCREATEコマンドは、計3つのフィールド名(REC01NAME、REC01FD01、REC01FD02)を持ち、1行を出力します。2番目のCREATEコマンドは、計4つのフィールド名(EC02NAME、REC02FD01、REC02FD02、REC02FD03)を持ち、2行を出力します。
//GENDAT0 JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP1 EXEC PGM=IEBDG
//OUTPUT DD DSN=IEBDG.DATASET.OUT01,DISP=(NEW,CATLG,DELETE),
// DCB=(RECFM=VB,LRECL=32760)
//SYSIN DD DATA
DSD OUTPUT=(OUTPUT)
FD NAME=REC01NAME,LENGTH=12,PICTURE=12,'RECORD01 '
FD NAME=REC01FD01,LENGTH=7,PICTURE=7,'A000001',INDEX=1
FD NAME=REC01FD02,LENGTH=4993,FORMAT=AL,ACTION=TL
FD NAME=REC02NAME,LENGTH=12,PICTURE=12,'RECORD02 '
FD NAME=REC02FD01,LENGTH=7,PICTURE=7,'A000001',INDEX=1,CYCLE=2
FD NAME=REC02FD02,LENGTH=8,PICTURE=8,'AM000001',INDEX=1
FD NAME=REC02FD03,LENGTH=4985,FORMAT=AL
REPEAT QUANTITY=131072,CREATE=2
CREATE QUANTITY=1,NAME=(REC01NAME,REC01FD01,REC01FD02)
CREATE QUANTITY=2,NAME=(REC02NAME,REC02FD01,REC02FD02,REC02FD03)
END
/*
//SYSPRINT DD SYSOUT=*
以下は、上記例の実行結果として作成された出力データセットのレコードです。総レコード数は393,216、各レコードの長さは5012バイトです。
RECORD01 A000001ABCDEFGHIJKLMNOPQRSTUVWXYZ... RECORD02 A000001AM000001ABCDEFGHIJKLMNOPQR... RECORD02 A000001AM000002ABCDEFGHIJKLMNOPQR... RECORD01 A000002 BCDEFGHIJKLMNOPQRSTUVWXYZ... RECORD02 A000002AM000003ABCDEFGHIJKLMNOPQR... RECORD02 A000002AM000004ABCDEFGHIJKLMNOPQR... RECORD01 A000003 CDEFGHIJKLMNOPQRSTUVWXYZ... RECORD02 A000003AM000005ABCDEFGHIJKLMNOPQR... RECORD02 A000003AM000006ABCDEFGHIJKLMNOPQR... RECORD01 A000004 DEFGHIJKLMNOPQRSTUVWXYZ... RECORD02 A000004AM000007ABCDEFGHIJKLMNOPQR... RECORD02 A000004AM000008ABCDEFGHIJKLMNOPQR... RECORD01 A000005 EFGHIJKLMNOPQRSTUVWXYZ... RECORD02 A000005AM000009ABCDEFGHIJKLMNOPQR... RECORD02 A000005AM000010ABCDEFGHIJKLMNOPQR... RECORD01 A000006 FGHIJKLMNOPQRSTUVWXYZ... RECORD02 A000006AM000011ABCDEFGHIJKLMNOPQR... RECORD02 A000006AM000012ABCDEFGHIJKLMNOPQR... RECORD01 A000007 GHIJKLMNOPQRSTUVWXYZ... RECORD02 A000007AM000013ABCDEFGHIJKLMNOPQR... RECORD02 A000007AM000013ABCDEFGHIJKLMNOPQR... ... RECORD01 A131071 ... RECORD02 A131071AM262141ABCDEFGHIJKLMNOPQR... RECORD02 A131071AM262142ABCDEFGHIJKLMNOPQR... RECORD01 A131072 ... RECORD02 A131072AM262143ABCDEFGHIJKLMNOPQR... RECORD02 A131072AM262144ABCDEFGHIJKLMNOPQR...
以下は、2つのCREATEコマンドを使用して2つのフィールドを指定し、それぞれのACTIONを指定する例です。
最初のFIELDコマンドは、LENGTHを10、5バイトのユーザー定義のPICTUREパターン、ACTIONとしてROを指定しています。2番目のFIELDコマンドは、LENGTHを10、5バイトのユーザー定義のPICTUREパターン、ACTIONとしてWVを指定しています。CREATE文で2つのフィールドを使用してレコードを出力します。
//IEBDGJ14 JOB //JSTEP010 EXEC PGM=IEBDG //SYSPRINT DD SYSOUT=* //OUTPUT01 DD DSN=OF71.IEBDG01.DATA01,DISP=(NEW,CATLG,CATLG), // DCB=(RECFM=FB,DSORG=PS,LRECL=40), // VOL=SER=DEFVOL //SYSIN DD * DSD OUTPUT=(OUTPUT01) FD NAME=RFDN001,LENGTH=10,PICTURE=5,'A0001',ACTION=RO FD NAME=RFDN002,LENGTH=10,PICTURE=5,'A0001',ACTION=WV REPEAT QUANTITY=1 CREATE QUANTITY=20,NAME=(RFDN001,RFDN002) END /*
以下は、上記の実行結果として作成された出力データセットのレコードとして、指定された10バイト以内で各フィールドのACTIONに従ってパターンを移動し、レコードを出力しています。
A0001 A0001....................
A0001 A0001 ....................
A0001 A0001 ....................
A0001 A0001 ....................
A0001 A0001 ....................
A0001 A0001 ....................
A0001 A0001....................
A0001 A0001 ....................
A0001 A0001 ....................
A0001 A0001 ....................
A0001 A0001 ....................
A0001 A0001 ....................
A0001 A0001....................
A0001 A0001 ....................
A0001 A0001 ....................
A0001 A0001 ....................
A0001 A0001 ....................
A0001 A0001 ....................
A0001 A0001....................
A0001 A0001 ....................
以下は、4つのCREATE文にNAMEパラメータを指定してレコードを出力する例です。
4つの文字列フィールドを作成し、それぞれのACTIONを指定した後、CREATE文のNAMEパラメータにコピーグループを明示して繰り返し出力するフィールド名を指定しています。
//IEBDGJ03 JOB //JSTEP010 EXEC PGM=IEBDG //SYSPRINT DD SYSOUT=* //OUTPUT01 DD DSN=OF71.IEBDG01.DATA01,DISP=(NEW,CATLG,CATLG), // DCB=(RECFM=FB,DSORG=PS,LRECL=40), // VOL=SER=DEFVOL //SYSIN DD * DSD OUTPUT=(OUTPUT01) FD NAME=RFDN001,LENGTH=10,FORMAT=AL,ACTION=TL FD NAME=RFDN002,LENGTH=10,FORMAT=AL,ACTION=TR FD NAME=RFDN003,LENGTH=10,FORMAT=AL,ACTION=SL FD NAME=RFDN004,LENGTH=10,FORMAT=AL,ACTION=SR REPEAT QUANTITY=1,CREATE=4 CREATE QUANTITY=10,NAME=((COPY=4,RFDN001)) CREATE QUANTITY=10,NAME=((COPY=4,RFDN002)) CREATE QUANTITY=10,NAME=((COPY=4,RFDN003)) CREATE QUANTITY=10,NAME=((COPY=4,RFDN004)) END /*
以下は、上記の実行結果としてCREATE文のNAMEパラメータに指定したコピーグループによって、4つのフィールドが繰り返し出力されています。
ABCDEFGHIJABCDEFGHIJABCDEFGHIJABCDEFGHIJ
BCDEFGHIJ BCDEFGHIJ BCDEFGHIJ BCDEFGHIJ
CDEFGHIJ CDEFGHIJ CDEFGHIJ CDEFGHIJ
DEFGHIJ DEFGHIJ DEFGHIJ DEFGHIJ
EFGHIJ EFGHIJ EFGHIJ EFGHIJ
FGHIJ FGHIJ FGHIJ FGHIJ
GHIJ GHIJ GHIJ GHIJ
HIJ HIJ HIJ HIJ
IJ IJ IJ IJ
J J J J
ABCDEFGHIJABCDEFGHIJABCDEFGHIJABCDEFGHIJ
ABCDEFGHI ABCDEFGHI ABCDEFGHI ABCDEFGHI
ABCDEFGH ABCDEFGH ABCDEFGH ABCDEFGH
ABCDEFG ABCDEFG ABCDEFG ABCDEFG
ABCDEF ABCDEF ABCDEF ABCDEF
ABCDE ABCDE ABCDE ABCDE
ABCD ABCD ABCD ABCD
ABC ABC ABC ABC
AB AB AB AB
A A A A
ABCDEFGHIJABCDEFGHIJABCDEFGHIJABCDEFGHIJ
BCDEFGHIJ BCDEFGHIJ BCDEFGHIJ BCDEFGHIJ
CDEFGHIJ CDEFGHIJ CDEFGHIJ CDEFGHIJ
DEFGHIJ DEFGHIJ DEFGHIJ DEFGHIJ
EFGHIJ EFGHIJ EFGHIJ EFGHIJ
FGHIJ FGHIJ FGHIJ FGHIJ
GHIJ GHIJ GHIJ GHIJ
HIJ HIJ HIJ HIJ
IJ IJ IJ IJ
J J J J
ABCDEFGHIJABCDEFGHIJABCDEFGHIJABCDEFGHIJ
ABCDEFGHI ABCDEFGHI ABCDEFGHI ABCDEFGHI
ABCDEFGH ABCDEFGH ABCDEFGH ABCDEFGH
ABCDEFG ABCDEFG ABCDEFG ABCDEFG
ABCDEF ABCDEF ABCDEF ABCDEF
ABCDE ABCDE ABCDE ABCDE
ABCD ABCD ABCD ABCD
ABC ABC ABC ABC
AB AB AB AB
A A A A
|
IEBDGの詳細については、IBMの『OS/390 DFSMSdfpユーティリティ』の「IEBDG」を参照してください。 |
7.4. 戻りコード
以下は、IEBDGユーティリティの戻りコードです。
-
正常に実行された場合
バッチ・アプリケーションからの戻りコードを返します。
-
エラーが発生した場合
SYSPRINT DDにエラーメッセージを出力し、該当するエラーコードを返します。
コード 説明 08
制御文の処理中にエラーが発生した場合です。
直ちにデータの作成を中止して、次のDSD文を処理します。
12
入出力データセットの処理中にエラーが発生した場合です。
ユーティリティを直ちに停止します。
16
回復不能エラーです。ユーティリティを直ちに停止します。
-
SYSIN DDコマンドの構文エラー
-
OpenFrameシステム・ライブラリの初期化に失敗
-
その他のIEBDGユーティリティ・プログラムのエラー
-
8. IEBEDIT
IEBEDITは、ジョブ・ストリーム・データセットを作成または編集するユーティリティ・プログラムです。
SYSIN DDに記述されたコマンドに従って入力データセットに与えられたJCLからジョブとステップを抽出し、出力データセットで新しいJCLデータセットを作成できます。選択されたすべてのジョブとステップを入力データセットでの順序で出力データセットにコピーします。
8.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
SYSUT1 DD |
入力データセットを定義します。 |
SYSUT2 DD |
出力データセットを定義します。 |
SYSIN DD |
IEBEDITのコマンドを記述します。 |
|
SYSUT1、SYSUT2およびSYSINデータセットのブロック・サイズは、80の倍数である必要があります。 |
8.2. コマンドの設定
IEBEDITのコマンドについて説明します。
EDIT
出力データセットに含まれるジョブ・ステップの条件を明示します。EDITが省略された場合は、入力データセット全体が出力データセットにコピーされます。
以下は、EDITコマンドの構文す。
[label] EDIT [START=jobname]
[,TYPE={POSITION|INCLUDE|EXCLUDE}]
[,STEPNAME=(namelist)]
[,NOPRINT]
| パラメータ | 説明 |
|---|---|
START |
EDIT文を適用するジョブ名を指定します。 1つのEDIT文は1つのジョブにのみ適用されます。TYPEとSTEPNAMEなしでSTARTを指定した場合は、そのジョブとジョブ・ステップが出力データセットにコピーされます。 最初のEDIT文でSTARTのjobnameを指定しなかった場合は、最初のジョブが選択されます。2番目の場合は、前のEDIT文で指定されたジョブの次のジョブが自動的に選択されます。 ジョブが選択されると、該当のJOB文が必須で含まれるため、複数のジョブからステップを抽出して1つのジョブとして作成することはできません。 |
TYPE |
出力データセットの内容を記述します。次のいずれかのオプションを設定できます。
|
STEPNAME |
ジョブ・ステップの名前リストを指定します。 STEPNAMEのnamelistは、次の3つの方法で記述できます。
コンマ(,)またはハイフン(-)で区切って組み合わせることができます。 |
NOPRINT |
NOPRINTが指定されていない場合は、デフォルトで出力データセットの内容がSYSPRINTに出力されます。このオプションを指定すると、出力データセットがSYSPRINTに出力されないようにします。 |
8.3. 使用例
以下は、SYSUT1 DDで指定されたJCLを編集した後、SYSUT2 DDに保存する例です。
//JOB1 JOB CLASS=A
//STEP1 EXEC PGM=IEBEDIT
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
EDIT START=,TYPE=POSITION,STEPNAME=T12
EDIT START=JOB2,TYPE=INCLUDE,STEPNAME=(T22,T23)
/*
//SYSUT1 DD DATA
//JOB1 JOB CLASS=A
//T11 EXEC PGM=IEFBR14
/TEMP1 DD TEMP1
//T12 EXEC PGM=IEFBR14
//TEMP2 DD TEMP2
//T13 EXEC PGM=IEFBR14
//JOB2 JOB CLASS=B
//T21 EXEC PGM=IEBEDIT
//TEMP3 DD TEMP3
//T22 EXEC PGM=IEBEDIT
//TEMP4 DD TEMP4
//TEMP41 DD TEMP41
//T23 EXEC PGM=IEBEDIT
//TEMP5 DD TEMP5
//T24 EXEC PGM=IEBEDIT
//TEMP6 DD TEMP6
/*
//SYSUT2 DD DSNAME=OFTEST.IEBEDIT.OUT2,
// DISP=(NEW,CATLG),DCB=(RECFM=F,LRECL=80,BLKSIZE=80)
最初のEDIT文は、JOB1からT12ステップ以降のステップを出力します。2番目のEDIT文は、JOB2からT22とT23ステップのみ出力します。
以下は、上記例の実行結果として作成されたSYSUT2 JCLです。
(EDIT START=,TYPE=POSITON,STEPNAME=T12で作成) //JOB1 JOB CLASS=A //T12 EXEC PGM=IEFBR14 //TEMP2 DD TEMP2 //T13 EXEC PGM=IEFBR14 //JOB2 JOB CLASS=B (EDIT START=JOB2,TYPE=INCLUDE,STEPNAME=(T22,T23)で作成) //JOB2 JOB CLASS=B //T22 EXEC PGM=IEBEDIT //TEMP4 DD TEMP4 //TEMP41 DD TEMP41 //T23 EXEC PGM=IEBEDIT //TEMP5 DD TEMP5
|
IEBEDITの詳細については、『IBM OS/390 DFSMSdfp Utilities』の「IEBEDIT」を参照してください。 |
9. IEBGENER
IEBGENERは、順次データセットまたはPDSのメンバーをコピーするユーティリティ・プログラムです。ICEGENERユーティリティと同じ機能を提供します。
IEBGENERユーティリティは、次の機能を実行できます。
-
順次データセットまたはPDSのメンバーをコピーします。
-
順次データセットからPDSを作成します。
-
既存のPDSにメンバーを追加します。
-
入力レコードを編集します。
9.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
SYSPRINT DD |
IEBGENERのメッセージが保存されるデータセットを定義します。 |
SYSUT1 DD |
入力データセットを定義します。順次データセットまたはPDSのメンバーのコピーを定義できます。 |
SYSUT2 DD |
出力データセットを定義します。順次データセットまたはPDSのメンバーのコピーを定義できます。 |
SYSIN DD |
IEBGENERのコマンドを定義します。 |
9.2. コマンドの設定
IEBGENERユーティリティが提供する機能を実行するためのコマンドをSYSIN DDに記述します。SYSIN DDにコマンドが記述されていない場合は、SYSUT1のデータセットをSYSUT2のデータセットにコピーします。
以下は、SYSIN DDで設定するIEBGENERのコマンドです。
GENERATE
メンバーとレコードのパラメータを設定します。GENERATEコマンドの構文は以下のとおりです。
[label] GENERATE [,MAXNAME=n]
[,MAXFLDS=n]
[,MAXGPS=n]
[,MAXLITS=n]
| パラメータ | 説明 |
|---|---|
MAXNAME |
メンバーの最大数を指定します。1から3276までの範囲で指定できます。 |
MAXFLDS |
レコード・フィールドの最大数を指定します。1から4096までの範囲で指定できます。 |
MAXGPS |
レコードのIDENTの最大数を指定します。1から2520までの範囲で指定できます。 |
MAXLITS |
レコードのフィールドで使用されるリテラル文字の最大数を指定します。1から2730までの範囲で指定できます。 |
MEMBER
出力レコードが複数のPDSメンバーから作成される場合、PDSのメンバーごとにMEMBER文が必要です。
以下は、MEMBER文の構文です。
[label] MEMBER NAME=(name[,alias1][,alias2][,...])
| パラメータ | 説明 |
|---|---|
NAME |
作成するメンバー名を指定します。 |
|
現在、IEBGENERユーティリティのMEMBER文のエイリアスは実際には機能しませんが、エラーが発生しないようにサポートしています。 |
RECORD
入力レコードの処理条件を記述します。RECORDコマンドの構文は以下のとおりです。
[label] RECORD [IDENT=(length,'name',input-location)]
[,FIELD=([length],
[{input-location|'literal'}],
[conversion],
[output-location])]
[,FIELD=...]
| パラメータ | 説明 |
|---|---|
IDENT |
MEMBER文がRECORD文の前に記述された場合は、そのメンバーにコピーされる入力レコードの条件を示し、同じレコードのFIELDに適用される入力レコードを識別します。 レコードのInput-locationのlengthとname値が同じである場合は、メンバーの最後のレコードまたはFIELDが適用される最後のレコードになります。
|
FIELD |
レコードを編集するための情報を指定します。 入力レコードのinput-locationから指定されたデータ(length)のみが出力レコードのoutput-locationにコピーされます。また、length分だけのリテラルを出力レコードのoutput-locationにコピーします。
|
9.3. 使用例
以下は、順次データセットをコピーする例です。
SYSIN DDにコマンドが記述されていないため、順次データセットのTEST.INPUTをTEST.COPYにコピーし、IEBGENERのメッセージはジョブで使用するメッセージ・クラスに保存します。
//COPY JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //COPYSDS EXEC PGM=IEBGENER //SYSUT1 DD DSNAME=TEST.INPUT,DISP=(SHR,KEEP) //SYSUT2 DD DSNAME=TEST.COPY,DISP=(NEW,CATLG), // DCB=(RECFM=FB,LRECL=120 ,BLKSIZE=120) //SYSPRINT DD SYSOUT=* //SYSIN DD DUMMY
以下は、順次データセットからPDSの新しいメンバーを作成する例です。
順次データセットのTEST.INPUTをMEMBER1、MEMBER2、MEMBER3の3つのメンバーで構成してPDS TEST.PDS01に保存します。
//CREATE JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//NEWPDS EXEC PGM=IEBGENER
//SYSUT1 DD DSNAME=TEST.INPUT,DISP=(SHR,KEEP)
//SYSUT2 DD DSNAME=TEST.PDS01,DISP=(NEW,CATLG),
// DCB=(DSORG=PO,RECFM=FB,LRECL=120,BLKSIZE=120)
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
GENERATE MAXNAME=3,MAXGPS=2
MEMBER NAME=MEMBER1
GROUP1 RECORD IDENT=(8,'firstxxx',30)
MEMBER NAME=MEMBER2
GROUP2 RECORD IDENT=(8,'secondxx',30)
MEMBER NAME=MEMBER3
/*
TEST.INPUTから入力レコードの30番目から37番目までの値を順次検索し、’firstxxx’レコードが見つかったら、’firstxxx’レコードから検索されたすべてのレコードをMEMBER1にコピーします。また、’firstxxx’レコード以降のレコードから再び’secondxx’レコードを検索します。
’secondxx’レコードが検索されたら、’firstxxx’レコードから’secondxx’レコードまでのすべてのレコードをMEMBER2にコピーします。残りのレコードはMEMBER3にコピーされます。
以下は、既存のPDSにメンバーを追加する例です。
//MERGE JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//MERGEPDS EXEC PGM=IEBGENER
//SYSUT1 DD DSNAME=TEST.INPUT2,DISP=(SHR,KEEP)
//SYSUT2 DD DSNAME=IEBGENER.TEST.PDS01,DISP=(OLD,KEEP)
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
GENERATE MAXNAME=2,MAXGPS=1
MEMBER NAME=MEMX
GROUP1 RECORD IDENT=(11,'endofrecord',15)
MEMBER NAME=MEMY
/*
順次データセットTEST.INPUT2のレコードの15バイト目から25バイト目までのレコード値を’endofrecord’と比較します。値が一致した場合は、検索されたすべてのレコードをMEMXにコピーし、’endofrecord’レコード以降のすべてのレコードはMEMYにコピーします。また、既存のPDS TEST.PDS01にPDSメンバーとしてMEMXとMEMYを追加します。
以下は、入力レコードを変更する例です。
TEST.INPUT3レコードを変更してTEST.EDIT0にコピーします。
//EDIT JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//EDIT EXEC PGM=IEBGENER
//SYSUT1 DD DSNAME=TEST.INPUT3,DISP=(SHR,KEEP)
//SYSUT2 DD DSNAME=IEBGENER.TEST.EDIT01,DISP=(NEW,CATLG),
// DCB=(RECFM=FB,LRECL=80,BLKSIZE=80)
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
GENERATE MAXGPS=1,MAXFLDS=4,MAXLITS=10
RECORD IDENT=(8,'firstmem',1),FIELD=(50,76,,31),
FIELD=(30,20,,1)
RECORD FIELD=(70,41,,11),FIELD=(10,'**********',,1)
/*
上記例の2つのRECORD文の最初のRECORDのIDENT条件に従って、入力レコードの1バイト目から8バイト目まで’firstmem’が見つかるまですべてのレコードにFIELD条件を適用します。
以下の図のように、入力レコードの76バイト目の位置から50バイトの値を出力レコードの31バイト目の位置にコピーします。また、入力レコードの20バイト目から30バイトの値を出力レコードの先頭にコピーします。
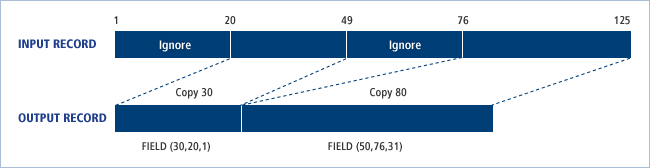
IDENT条件を満たすレコードが処理された後は、以下のように2番目のRECORD文が適用されます。入力レコードの41バイト目の位置から70バイトの値を出力レコードの11バイト目の位置にコピーし、出力レコードの最初の10バイトはリテラル‘**********'にコピーします。
9.4. 環境設定
OpenFrame環境設定のdsサブジェクトのDATASET_DEFAULTセクションのSET_OUTPUT_DCB_TO_SMSキーを使用して、出力データセットのDCBを出力データセットのACSルールに従ってSMSクラスに設定するか、入力データセットのDCB情報と同一に設定するかを指定します。
|
dsサブジェクトの設定の詳細については、『OpenFrame 環境設定ガイド』を参照してください。 |
9.5. 戻りコード
以下は、IEBGENERユーティリティの戻りコードです。
-
正常に実行された場合
バッチ・アプリケーションからの戻りコードを返します。
-
エラーが発生した場合
SYSPRINT DDにエラーメッセージを出力し、該当するエラーコードを返します。
コード 説明 12
回復不能エラーです。次のようなエラーがあります。
-
データセット関連(pgmdd、open/close、read/write)エラー
-
SYSIN DDコマンドの構文エラー
-
その他のIEBGENERユーティリティ・プログラムのエラー
16
システム・エラーです。
-
OpenFrameシステム・ライブラリの初期化に失敗
-
|
類似のユーティリティ・プログラムとしてICEGENERがあります。 |
10. IEBPTPCH
IEBPTPCHは、順次データセットまたはPDS全体または一部を印刷するために使用されるユーティリティ・プログラムです。
IEBPTPCHユーティリティは、次の場合に使用できます。
-
順次データセットまたはPDS全体を印刷します。
-
PDSの特定のメンバーを印刷します。
-
順次データセットまたはPDSのレコード・フィールドを編集して印刷します。
10.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
SYSPRINT DD |
IEBPTPCHメッセージが保存されるデータセットを指定します。 |
SYSUT1 DD |
順次データセットまたはPDSタイプの入力データセットを指定します。 |
SYSUT2 DD |
順次データセットの出力データセットを指定します。 |
SYSIN DD |
IEBPTPCHコマンドを指定します。 |
10.2. コマンドの設定
SYSIN DDで設定するIEBPTPCHユーティリティのコマンドについて説明します。
データを印刷します。PRINT文は最初に記述する必要があり、複数回指定することはできません。
以下は、PRINTコマンドの構文です。
[label] PRINT [PREFORM=A]
[,TYPORG={PS|PO}]
[,CNTRL={n|1}]
[,STRTAFT=n]
[,STOPAFT=n]
[,SKIP=n]
[,MAXNAME=n]
[,MAXFLDS=n]
[,MAXGPS=n]
[,MAXLITS=n]
[,MAXLINE=n]
| パラメータ | 説明 |
|---|---|
PREFORM |
各レコードの先頭文字を制御文字にするかどうかを指定します。 データが印刷フォーマットになっており、そのフォーマットで印刷される必要があることを示します。PREFORMが指定されると、TYPORG以外のPRINT文のすべてのパラメータは無視されます。 Aは、レコードの先頭文字をASA制御文字にすることを意味します。 |
TYPORG |
入力データセットを順次データセット(PS)にするか、区分編成データセット(PO)にするかを指定します。(デフォルト値: PS) |
CNTRL |
行スペースの値を指定します。 行スペースに3を設定する場合、最初の行にはデータを、2番目と3番目の行には空白行を印刷します。このような順序で次のデータも印刷されます。 現在は、行スペースに設定できる最大値は3です。最大値を超えた値は、1と見なされます。 |
STRTAFT |
順次データセットを印刷する前にスキップする論理レコードの数を指定します。データセットのn+1番目の論理レコードから印刷されます。処理できるレコードの最大数は32767です。 |
STOPAFT |
印刷される順次デートセットの論理レコードの数を指定します。設定できる最大値は3276です。32767を超える値を指定しても、32767に設定されます。 STOPAFT文とRECORD文のIDENTが同時に指定されている場合、STOPAFTの値に達するか、またはIDENTによって区分されるレコード・グループの最後に達すると、その時点でコマンドの実行が停止します。 |
SKIP |
n番目のレコードごとに印刷することを指定します。32767を超える値を指定しても、32767に設定されます。 |
MAXNAME |
MEMBER文の最大メンバー数を指定します。MEMBERコマンドがある場合は、必ず指定します。nは32767を超えることはできません。 |
MAXFLDS |
RECORD文のFIELDパラメータの最大数を指定します。設定値は32767を超えてはなりません。 |
MAXGPS |
RECORD文のIDENTパラメータの最大数を指定します。設定値は32767を超えてはなりません。 |
MAXLITS |
RECORD文のIDENTパラメータに含まれるリテラルの最大数を指定します。設定値は32767を超えてはなりません。 |
MAXLINE |
出力されるページの最大行数を指定します。32767を超える値を指定しても、32767に設定されます。(デフォルト値:60) |
TITLE
出力されるタイトルまたはサブタイトルを指定します。
IEBPTPCHではTITLE文に2つのITEMを指定することができます。1番目のITEM文ではタイトルを、2番目ではサブタイトルを定義します。指定されたタイトルとサブタイトルはすべてのページに印刷されます。
以下は、TITLEコマンドの構文です。
[label] TITLE ITEM=('title'[,output-location])
[,ITEM=...]
| パラメータ | 説明 |
|---|---|
ITEM |
titleとoutput-locationを次のように設定します。
|
MEMBER
入力データセットがPDSの場合、特定のメンバーのデータのみ処理したい場合に使用します。MEMBER文を使用するには、PRINT文のMAXNAMEを設定する必要があります。
以下は、MEMBERコマンドの構文です。
[label] MEMBER NAME=membername
| パラメータ | 説明 |
|---|---|
NAME |
印刷するPDSのメンバー名を指定します。 |
RECORD
印刷するレコードのグループを定義します。
以下は、RECORDコマンドの構文です。
[label] RECORD [IDENT=(length,'name',input-location)]
[,FIELD=(length,[input-location],[conversion]
[output-location])]
[,FIELD=…]
| パラメータ | 説明 |
|---|---|
IDENT |
レコード・グループの最後のレコードを識別します。レコードのinput-locationでlengthとnameの値を比較し、値が同じであればメンバーの最後のレコードまたはFIELDが適用された最後のレコードのいずれかになります。 IDENTを使用するためには、PRINT文のMAXGPSとMAXLITSが指定されている必要があります。
|
FIELD |
レコードを編集するための情報を指定します。入力レコードのinput-locationから指定されたデータ(length)のみが出力レコードのoutput-locationにコピーされます。また、length分だけのリテラルを出力レコードのoutput-locationにコピーします。 FIELDを使用するには、PRINT文のMAXFLDSが指定されている必要があります。
|
CONVERSION |
レコードを変換するための情報を指定します。以下のパラメータを使用できます。
|
10.3. 使用例
以下は、特定のメンバーのみ選択して指定の印刷フォーマットで出力する例です。IEBCOPY.TEST.INPUT01のMEMBER2メンバーのレコードがSYSUT2に定義されたSYSOUTに順次出力されます。
MEMBER2のレコードの21バイト目から8バイトの値が’ENDRECORD’である場合は、そのレコードまで印刷します。このSYSOUTはジョブが終了された後、OUTPUT PROCESSINGによってプリンターに印刷(1ページあたり30行)されます。
//TEST JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//NEWPDS EXEC PGM=IEBPTPCH
//SYSUT1 DD DSNAME=IEBCOPY.TEST.INPUT01,DISP=(SHR,CATLG)
//SYSUT2 DD SYSOUT=A
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
PRINT TYPORG=PO,CNTRL=1,MAXLINE=30,MAXNAME=1,MAXLITS=10,MAXGPS=3
MEMBER NAME=MEMBER2
RECORD IDENT=(8,'ENDRECORD',21)
/*
11. IEBUPDTE
IEBUPDTEは、リソース(アプリケーション・ソース、JCLソースなど)を新規作成、更新、コピーするためのユーティリティ・プログラムです。各レコードにシーケンス番号をつけ、その順にレコードの内容を変更、削除、挿入することができます。
IEBUPDTEユーティリティは、次の機能を実行できます。
-
PDSを新規作成します。
-
PDSのメンバーをコピーおよび置換します。
-
PDSメンバーのレコードを編集します。(レコードの置換、追加、削除、順番付け)
パラメータの設定
以下は、IEBUPDTEで設定できるパラメータです。
//EXEC PGM=IEBUPDTE[,PARM={NEW|MOD}]
| パラメータ | 説明 |
|---|---|
PARM |
|
11.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
SYSPRINT DD |
IEBUPDTEメッセージが保存されるデータセットを定義します。 |
SYSUT1 DD |
入力データセットを定義します。 |
SYSUT2 DD |
出力データセットを定義します。 |
SYSIN DD |
IEBUPDTEのコマンドを定義します。 |
11.2. コマンドの設定
SYSIN DDで設定するIEBUPDTEユーティリティのコマンドについて説明します。
|
IEBUPDTEのすべてのコマンドは「./」で始まる必要があります。そうでない場合はDATA文と見なされます。 |
ADD、REPL、REPRO、CHANGE
入力データセットのレコードを追加、置換、コピー、編集して出力データセットにレコードを作成します。
以下は、ADD、REPL、REPRO、CHANGEコマンドの構文です。
./[label] FUNC [NAME=member-name]
[,LIST=ALL]
[,SEQFLD=nnn]
[,COLUMN=n]
[,UPDATE=INPLACE]
[,NEW={PO|PS}]
[,MEMBER=member-name]
[,LEVEL=n]
[,SOURCE=x]
[,SSI=hhhhhhhh]
[,INHDR=routine-name]
[,INTLR=routine-name]
[,OUTHDR=routine-name]
[,OUTTLR=routine-name]
[,TOTAL=(routine-name, size)]
| パラメータ | 説明 |
|---|---|
FUNC |
ADD、REPL、REPRO、CHANGEを定義します。 |
NAME |
レコードを新規作成、コピー、編集、置換する出力PDSのメンバー名を指定します。 |
LIST |
すべてのレコードをSYSPRINTデータセットに出力します。(現在サポートされていません) |
SEQFLD |
シーケンス番号の位置と長さを指定します。 最初の2桁には位置を、最後の1桁には長さを指定します。位置は1から80、長さは1から8の範囲内で指定できます。(デフォルト値: 738) |
COLUMN |
レコード内のデータを置き換える位置を指定します。 |
UPDATE |
入力データセットと出力データセットが同一であり、データセットに変更が発生した場合に指定します。 |
NEW |
入力データセットと出力データセットのDSORGが異なる場合、出力データセットのDSORGを指定します。 |
MEMBER |
SDSからPDSに出力する場合、メンバー名を指定します。 |
LEVEL |
出力データセットがPDSの場合、変更レベルを指定します。(現在サポートされていません) |
SOURCE |
出力データセットがPDSの場合、ユーザーによる変更なのか、IBMによる変更なのかを指定します。(現在サポートされていません) |
SSI |
出力データセットがPDSの場合、システムの状態情報を指定します。(現在サポートされていません) |
INHDR |
ユーザー入力のヘッダー・ラベルを処理するルーチンを指定します。(現在サポートされていません) |
INTLR |
ユーザー入力の最後のラベルを処理するルーチンを指定します。(現在サポートされていません) |
OUTHDR |
ユーザー出力のヘッダー・ラベルを処理するルーチンを指定します。(現在サポートされていません) |
OUTTLR |
ユーザー出力の最後のラベルを処理するルーチンを指定します。(現在サポートされていません) |
TOTAL |
ルーチンと領域の合計を指定します。(現在サポートされていません) |
NUMBER, DELETE
NUMBER文とDELETE文は、ADD、REPL、REPRO、CHANGE文と一緒に使用されます。レコードのシーケンス番号を再度割り当てたり、指定した番号に該当するレコードを削除したりします。NUMBERは、シーケンス番号を新たにつけるか、変更する場合に使用されます。DELETEは、指定されたシーケンス番号に該当するレコードを削除するために使用されます。
以下は、NUMBERとDELETEコマンドの構文です。
./[label] NUMBER [NEW1=n]
[,INCR=n]
[,SEQ1={n|ALL}]
[,SEQ2=n]
[,INSERT=YES]
./[label] DELETE SEQ1=n
[,SEQ2=n]
| パラメータ | 説明 |
|---|---|
NEW1 |
シーケンス番号の初期値を指定します。 |
INCR |
シーケンス番号を変更します。 |
SEQ1 |
CHANGEを開始するシーケンス番号を指定します。CHANGE文でのみ有効です。 INSERT=YESと同時に指定された場合は、新しく追加されるレコードの位置を指定します。 レコード全体をターゲットにする場合は、ALLを指定します。 |
SEQ2 |
CHANGEを終了するシーケンス番号を指定します。CHANGE文でのみ有効です。 1つのレコードを削除する場合は省略できます。 |
INSERT |
シーケンス番号がないレコードを新しく追加する場合、SEQ1に指定されたシーケンス番号の次の番号からレコードを追加します。 |
ENDUP
SYSINの入力データの最後を示します。
./[label] ENDUP
ALIAS
エイリアスを処理する際に定義します。現在サポートされていません。
LABEL
ユーザー・ラベルを処理する際に定義します。現在サポートされていません。
11.3. 使用例
以下は、新しいPDSとメンバーを作成する例です。
//IEBUPDT1 JOB
//STEP1 EXEC PGM=IEBUPDTE,PARM=NEW
//SYSPRINT DD SYSOUT=A
//SYSUT2 DD DSNAME=NEWPDS,DISP=(NEW,CATLG),
// VOLUME=SER=DEFVOL,SPACE=(TRK,(50,,10)),
// DCB=(RECFM=F,LRECL=80,BLKSIZE=80)
//SYSIN DD DATA
./ ADD NAME=MEMB1
MEMB1 DATA1 00000010
MEMB1 DATA2 00000020
MEMB1 DATA3 00000030
./ ADD NAME=MEMB2
MEMB2 DATA1 00000010
MEMB2 DATA2 00000020
MEMB2 DATA3 00000030
./ ADD NAME=MEMB3
MEMB3 DATA1 00000010
MEMB3 DATA2 00000020
MEMB3 DATA3 00000030
./ ENDUP
/*
最初のADD文はMEMB1というメンバーを作成し、その次のDATA文をレコードとして持ちます。2番目のADD文はMEMB2というメンバーを作成し、その次のDATA文をレコードとして持ちます。3番目のADD文はMEMB3というメンバーを作成し、その次のDATA文をレコードとして持ちます。
以下は、新しいPDSに既存PDSのメンバーをコピーして新しく追加する例です。
//IEBUPDT2 JOB
//STEP1 EXEC PGM=IEBUPDTE
//SYSPRINT DD SYSOUT=*
//SYSUT1 DD DSNAME=OLDPDS,DISP=SHR
//SYSUT2 DD DSNAME=NEWPDS,DISP=(NEW,CATLG),
// VOL=SER=DEFVOL,SPACE=(TRK,(100,,10)),
// DCB=(RECFM=F,LRECL=80,BLKSIZE=4000)
//SYSIN DD DATA
./ REPRO NAME=MEMB1
./ REPRO NAME=MEMB2
./ ADD NAME=MEMB3
./ NUMBER NEW1=100,INCR=100
MEMB3 DATA1
MEMB3 DATA2
MEMB3 DATA3
./ ENDUP
/*
最初のREPRO文はOLDPDSのメンバーMEMB1をNEWPDSにコピーします。2番目のREPRO文はOLDPDSのメンバーMEMB2をNEWPDSにコピーします。ADD文はMEMB3というメンバーを作成し、5から7行目のDATA文をレコードとして持ちます。NUMBER文によって各レコードは100から100ずつ増加するシーケンス番号を持ちます。
以下は、既存のPDSメンバーのシーケンス番号を新しく指定し、いくつかのレコードを置き換える例です。
//IEBUPDT3 JOB
//STEP1 EXEC PGM=IEBUPDTE
//SYSPRINT DD SYSOUT=A
//SYSUT1 DD DSNAME=OLDPDS,DISP=(OLD,KEEP),VOL=SER=DEFVOL
//SYSIN DD *
./ CHANGE NAME=MEMB1,UPDATE=INPLACE
./ NUMBER SEQ1=ALL,NEW1=100,INCR=50
CHANGE DATA1 00000200
CHANGE DATA2 00000600
./ ENDUP
/*
最初のCHANGE文はMEMB1の入力データセット内で変更が発生するように指定します。NUMBER文はMEMB1のすべてのレコードに対してシーケンス番号を変更します。各レコードのシーケンス番号は、100から50ずつ増加します。各DATA文には固有のシーケンス番号があります。シーケンス番号が200と600になっている既存のレコードを置き換えます。
以下は、PDSのメンバーを編集してSDSに出力する例です。
//IEBUPDT4 JOB
//STEP1 EXEC PGM=IEBUPDTE
//SYSPRINT DD SYSOUT=A
//SYSUT1 DD DSNAME=PDS,DISP=(OLD,KEEP),VOL=SER=DEFVOL
//SYSUT2 DD DSNAME=SDS,DISP=(NEW,KEEP),VOL=SER=DEFVOL,
// DCB=(RECFM=FB,LRECL=80,BLKSIZE=2000)
//SYSIN DD *
./ CHANGE NEW=PS,NAME=MEMB1
CHANGE DATA1 00000200
./ DELETE SEQ1=250,SEQ2=300
DELETE DATA2 00000275
./ ENDUP
/*
最初のCHANGE文はPDSのメンバーMEMB1をSDSに出力します。最初のDATA文はシーケンス番号が200になっているレコードを置き換えます。最初のDELETE文はシーケンス番号が250から300までのレコードを削除します。2番目のDATA文はシーケンス番号が275になっているレコードを追加します。250から300までのレコードが削除されたため、置き換えではなく追加されます。
以下は、PDSのメンバーに新しいレコードを追加する例です。
//IEBUPDT5 JOB
//STEP1 EXEC PGM=IEBUPDTE
//SYSPRINT DD SYSOUT=A
//SYSUT1 DD DSNAME=PDS,DISP=(OLD,KEEP),VOL=SER=DEFVOL
//SYSUT2 DD DSNAME=PDS,DISP=(OLD,KEEP),VOL=SER=DEFVOL
//SYSIN DD *
./ CHANGE NAME=MEMB1
./ NUMBER SEQ1=150,NEW1=200,INCR=50,INSERT=YES
INSERT DATA1
INSERT DATA2
INSERT DATA3
/*
CHANGE文は、PDSのメンバーMEMB1を変更します。NUMBER文はシーケンス番号が150になっているレコードの次から新しいレコードを追加し、新しいレコードは200から50ずつ増加することを指定します。
DATA文は上記の条件に従って、それぞれ200、250、300のシーケンス番号が与えられ追加されます。200から300の間のシーケンス番号を持つレコードがある場合は、新しく追加されたシーケンス番号300の次から50ずつ増加された番号に変更されます。このような変更は、前に変更されたレコードのシーケンス番号が次のレコードのシーケンス番号より小さくなるまで繰り返されます。
12. IEHLIST
IEHLISTは、PDSの情報とメンバー・リストまたはボリューム情報とボリュームに含まれているデータセット・リストを提供するユーティリティ・プログラムです。
IEHLISTユーティリティは、次の機能を実行できます。
-
PDSの情報とメンバー・リストを確認します。
-
ボリュームのディスク情報またはデータセット・リストを確認します。
12.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
SYSPRINT DD |
IEHLISTメッセージが保存されるデータセットを定義します。 |
SYSIN DD |
IEHLISTコマンドを定義します。 |
12.2. コマンドの設定
SYSIN DDで設定するIEHLISTユーティリティのコマンドについて説明します。
LISTPDS
PDSの情報とメンバー・リストを示します。
以下は、LISTPDSコマンドの構文です。
[label] LISTPDS DSNAME=(name[,name[,...]])
[,VOL=anyname=serial]
| パラメータ | 説明 |
|---|---|
DSNAME |
PDSの名前を指定します。指定できる最大値は10です。 |
VOL |
DSNAMEに指定されたデータセットを含むボリューム・シリアル番号(ボリューム名)を指定します。 anynameにボリュームのデバイス名を指定するか、任意の名前を指定します。指定されたanynameは構文上の目的でのみ使用され、実際には無視されます。 |
LISTVTOC
指定されたボリュームに該当するディスク情報とデータセット・リストを表示します。
以下は、LISTVTOCコマンドの構文です。
[label] LISTVTOC [,VOL=anyname=serial]
[,DSNAME=(name[,name[,...]])
| パラメータ | 説明 |
|---|---|
VOL |
ボリュームのシリアル番号を指定します。 anynameにボリュームのデバイス名を指定するか、任意の名前を指定します。指定されたanynameは構文上の目的でのみ使用され、実際には無視されます。 |
DSNAME |
データセット・リストに含まれるデータセット名を指定します。指定できる最大値は10です。 DSNAMEが指定されていない場合は、ボリューム内のすべてのデータセット・リストが表示されます。 |
12.3. 使用例
以下は、PDSの情報とメンバー・リストを確認する例です。
PDSのDATASET1とDATASET2の情報とメンバー・リストをSYSPRINTに書き込みます。
//LISTPDS JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1),
// USER=ROOT,PASSWORD=SYS1
//STEP01 EXEC PGM=IEHLIST
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
LISTPDS DSNAME=(DATASET1,DATASET2), VOL=disk=100000
/*
以下は、ボリュームのディスク情報とデータセット・リストを確認する例です。
シリアル番号が100000であるボリュームのディスク情報とデータセット・リストをSYSPRINTに書き込みます。
//LISTVOL JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP01 EXEC PGM=IEHLIST
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
LISTVTOC VOL=disk=100000
/*
13. IEHPROGM
IEHPROGMは、非VSAMデータセットを管理するためのユーティリティ・プログラムです。
IEHPROGMユーティリティは、次の機能を実行できます。
-
ボリュームからデータセットまたはPDSのメンバーを物理的に削除します。
-
データセットをカタログまたはアンカタログします。
|
類似したユーティリティ・プログラムには、IDCAMSがあります。 |
13.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
SYSPRINT DD |
IEBGENERメッセージが保存されるデータセットを指定します。 |
SYSIN DD |
IEBGENERコマンドを指定します。 |
13.2. コマンドの設定
SYSIN DDで設定するIEHPROGMユーティリティのコマンドについて説明します。
SCRATCH
ディスク・ボリュームに保存された物理ファイル(データセットまたはPDSのメンバー)を削除します。SCRATCHコマンドが実行されるデータセットがカタログに登録されている場合は、カタログ情報も削除されます。
以下は、SCRATCHコマンドの構文です。
[label] SCRATCH {VTOC|DSNAME=name},VOL=anyname=serial
[,MEMBER=name][,SYS]
| パラメータ | 説明 |
|---|---|
VTOC |
指定されたボリューム内のすべてのデータセットを削除する場合に指定します。 |
DSNAME |
削除するデータセット名を指定します。 |
VOL |
削除するデータセットのボリュームを指定します。 anynameにボリュームのデバイス名を指定するか、任意の名前を指定します。指定されたanynameは構文上の目的でのみ使用され、実際には無視されます。 |
MEMBER |
PDSのメンバーのみ削除する場合に使用します。削除するメンバー名を指定します。 |
SYS |
一時データセットのみ削除する場合に指定します。 たとえば、名前が「&」で始まるデータセットが対象になります。 このパラメータは、VTOCを指定した場合にのみ有効です。 |
CATLG
カタログに非VSAMデータセットの基本情報を登録します。
以下は、CATLGコマンドの構文です。
[label] CATLG DSNAME=name,VOL=anyname=serial
| パラメータ | 説明 |
|---|---|
DSNAME |
カタログに登録するデータセット名を指定します。 |
VOL |
削除するデータセットのボリュームを指定します。 anynameにボリュームのデバイス名を指定するか、任意の名前を指定します。指定されたanynameは構文上の目的でのみ使用され、実際には無視されます。 |
UNCATLG
カタログに登録されている非VSAMデータセットをアンカタログします。
UNCATLG文を使用してカタログに登録された特定のデータセットを削除することができます。ただし、ボリュームに保存されている物理ファイルは削除できません。ボリュームに保存されているファイルを削除する必要がある場合は、SCRATCH文を使用して物理ファイルを削除した後、UNCATLG文を使用してカタログに登録されたデータセット情報を削除します。
以下は、UNCATLGコマンドの構文です。
[label] UNCATLG DSNAME=name
| パラメータ | 説明 |
|---|---|
DSNAME |
カタログから削除するデータセット名を指定します。 |
13.3. 使用例
以下は、ボリュームのシリアル番号が100000であるVTOCに存在する一時データセットを削除する例です。
//CATALOG JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP1 EXEC PGM=IEHPROGM
//SYSPRINT DD SYSOUT=*
//VOLDD DD VOL=SER=100000,DISP=OLD
//SYSIN DD *
SCRATCH VTOC,VOL=SER=100000,SYS
/*
以下は、シリアル番号が100000であるボリュームに存在するTEST01データセットをカタログに登録する例です。
//CATALOG JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP1 EXEC PGM=IEHPROGM
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
CATLG DSNAME=IEHPROGM.TEST01,VOL=SER=100000
/*
以下は、シリアル番号が100000であるボリュームからTEST01データセットを削除した後、カタログに登録されているTEST01データセットを削除する例です。
//CATALOG JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1)
//STEP1 EXEC PGM=IEHPROGM
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
SCRATCH DSNAME=IEHPROGM.TEST01,VOL=SER=100000
UNCATLG DSNAME=IEHPROGM.TEST01
/*
13.4. 戻りコード
以下は、IEHPROGMユーティリティの戻りコードです。
-
正常に実行された場合
バッチ・アプリケーションからの戻りコードを返します。
-
エラーが発生した場合
SYSPRINT DDにエラーメッセージを出力し、該当するエラーコードを返します。
コード 説明 8
警告エラーです。次のようなエラーがあります。
-
データセットが見つからない場合
12
回復不能エラーです。次のようなエラーがあります。
-
データセット関連(pgmdd、open/close、read/write)エラー
-
SYSIN DDコマンドの構文エラー
-
その他のIEHPROGMユーティリティ・プログラムのエラー
16
システム・エラーです。
-
OpenFrameシステム・ライブラリの初期化に失敗
-
14. IFASMFDP
IFASMFDPは、SMFデータセットを一般データセットにダンプまたは初期化するユーティリティ・プログラムです。
IFASMFDPユーティリティは、次の機能を実行できます。
-
SMFデータセットを初期化します。
-
SMFデータセットを一般ユーザー・データセットにダンプします。
|
類似のユーティリティ・プログラムにはDFHJUPがあります。 |
14.1. DDの設定
以下は、DDの設定項目です。
| 項目 | 説明 |
|---|---|
SYSOUT DD |
IFASMFDPメッセージが保存されるデータセットを指定します。 |
SYSIN DD |
IFASMFDPのコマンドを指定します。 |
14.2. コマンドの設定
SYSIN DDで設定するIFASMFDPユーティリティのコマンドについて説明します。
INDD
入力データセットと処理方法を指定します。
以下は、INDDコマンドの構文です。
INDD(ddname,OPTIONS(data))
| パラメータ | 説明 |
|---|---|
INDD |
入力データセットと処理方法を指定します。 指定されていない場合のデフォルト値は、INDD(DUMPIN,OPTIONS(ALL)) です。 |
ddname |
入力データセットのDD名を指定します |
data |
入力データセットの処理方法を指定します。次のいずれかを選択します。
|
OUTDD
出力データセットとコピーされるレコード・タイプのリストを指定します。
以下は、OUTDDコマンドの構文です。
OUTDD(ddname,{TYPE(list),NOTYPE(list)})
| パラメータ | 説明 |
|---|---|
OUTDD |
出力データセットとコピーされるレコード・タイプのリストを指定します。 指定されていない場合のデフォルト値は、OUTDD(DUMPOUT,TYPE(000:255))です。 |
ddname |
出力データセットのDD名を指定します。 |
TYPE |
出力データセットにコピーするレコード・タイプをlistに指定します。 |
NOTYPE |
出力データセットにコピーしないレコード・タイプをlistに指定します。 |
list |
レコード・タイプは次の3つの方法でリストします。区切り文字は、コンマ(,)です。
|
DATE
レコードをコピーする期間の日付範囲を指定します。
以下は、DATEコマンドの構文です。
DATE({yyddd|yyyyddd},{yyddd|yyyyddd})
| パラメータ | 説明 |
|---|---|
DATE |
指定された日付範囲内で作成されたレコードをコピーします。指定されていない場合のデフォルト値は、DATE(1900000,2099366)です。 |
yyddd |
19yy年のddd番目の日を示します。dddの範囲は001~366です。 |
yyyyddd |
yyyy年のddd番目の日を示します。dddの範囲は001~366です。 |
START
レコードをコピーする時間範囲の開始時刻を指定します。
以下は、STARTコマンドの構文です。
START(hhmm)
| パラメータ | 説明 |
|---|---|
START |
時間範囲の開始時刻をhhmm形式で指定します。 指定されていない場合のデフォルト値は、START(0000)です。 |
hhmm |
hhは時を、mmは分(24時間形式)を表します。 |
END
レコードをコピーする時間範囲の終了時刻を指定します。
以下は、ENDコマンドの構文です。
END(hhmm)
| パラメータ | 説明 |
|---|---|
END |
時間範囲の終了時刻をhhmmの形式で指定します。 指定されていない場合のデフォルト値は、END(2400) です。 |
hhmm |
hhは時を、mmは分(24時間形式)を表します。 |
SID
指定されたシステムIDを持つレコードのみコピーします。
以下は、SIDコマンドの構文です。
SID(XXXX)
| パラメータ | 説明 |
|---|---|
SID |
特定のシステムIDで書き込まれたSMFレコードのみを出力データセットにコピーします。指定されていない場合、SIDフィールドは無視されます。 |
xxxx |
1~4文字のアルファベットで構成されるシステムIDです。 |
14.3. 使用例
以下は、INDD1で指定されたSMFデータセットをダンプおよびクリアし、INDD2で指定されたSMFデータセットはダンプのみ行い、OUTDD1、OUTDD2、OUTDD3の3つの新規データセットを作成する例です。
2009年1月1日から2009年1月2日まで作成されたレコードのみが抽出され、OUTDD1にはレコード・タイプ0、2、10、15~40が、OUTDD2とOUTDD3にはレコード・タイプ10~255が保存されます。
//SMFDUMP JOB CLASS=A,MSGCLASS=X,MSGLEVEL=(1,1) //STEP EXEC PGM=IFASMFDP //SYSOUT DD SYSOUT=* //INDD1 DD DSN=SMLOG.DATA1,DISP=SHR //INDD2 DD DNS=SMLOG.DATA2.DISP=SHR //OUTDD1 DD DSN=SMF.DUMP1,DISP=SHR,DCB=LRECL=32760 //OUTDD2 DD DSN=SMF.DUMP2,DISP=SHR,DCB=LRECL=32760 //OUTDD3 DD DSN=SMF.DUMP3,DISP=SHR,DCB=LRECL=32760 //SYSIN DD * INDD(INDD1,OPTIONS(ALL)) INDD(INDD2,OPTIONS(DUMP)) OUTDD(OUTDD1,TYPE(0,2,10,15:40)) OUTDD(OUTDD2,TYPE(10:255)) OUTDD(OUTDD3,TYPE(10:255)) DATE(2009001,2009002) /* //